Courses
OpenAI APIを使いこなす
3時間
141.6K
OpenAI は GPT-4.5 以来となる、初の再学習ベースモデルをリリースしました。直感に反するかもしれませんが、GPT-5 とその後継群はすべて段階的な更新でした。
今回は違います。エージェント型ワークフロー向けにゼロから設計され、開発者にとって重要な2つのクリティカルなベンチマークで強力な結果を出しています。
本記事では、新しく登場した GPT-5.5 と Gemini 3.1 Pro を比較し、どちらが最適かを検討します。ベンチマーク、コスト、ユースケースを見ていきます。
GPT-5.5 は OpenAI の最新フラッグシップとなるオムニモーダルモデルで、コードネームは「Spud」。既存モデルのファインチューニングではなく、自律的かつマルチタスクの実行を、ほとんど指示なしで行えるようゼロから再構築されています。
GPT-5.5 には次の3つのバリアントがあります:
詳細は当社のOpenAI GPT-5.5の記事や、Claude Opus 4.7 と GPT-5.5 の比較をご覧ください。
GPT-5.5 の中核的な機能と特長は次のとおりです。
最大の特長の1つは、512K〜100万トークンの長文コンテキストにおける大幅な改善です。GPT 5.4 の 36.6% から GPT 5.5 では 74.0% と、性能が2倍以上になりました。
また、現時点で数学分野でも最強水準です。FrontierMath Tier 4 では GPT 5.5 が 35.4%、GPT 5.5 Pro は 39.6% を記録。参考として、GPT 5.4 は 27.1%、Claude Opus 4.7 は 22.9%、Gemini 3.1 Pro は 16.7% でした。
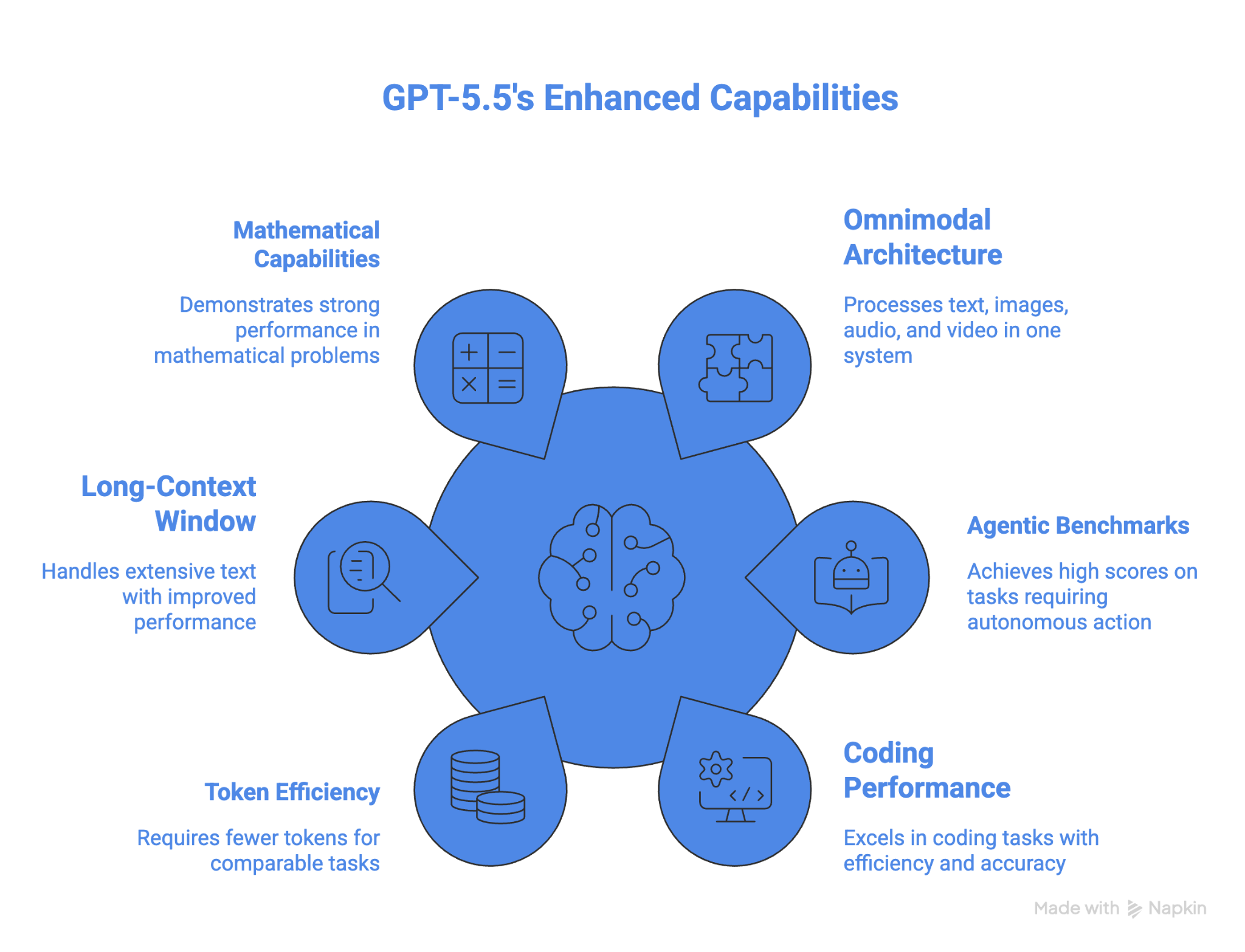
OSWorld-Verified における GPT-5.5 の成績は、本ベンチマークの結果を公表しているモデルの中で、コンピュータ操作に最適であることを示しています。高度な数学でも他モデルを上回ります。長時間稼働のエージェント系タスクでは、トークン効率の高さも強みです。
一方で、GPT-5.5 は前世代より高価です。入力 100 万トークンで $5、出力 100 万トークンで $30。よりトークン効率が高いので結果的に安くなる可能性があるとされていますが、それが当てはまるかどうかはワークフロー次第です。
Gemini 3.1 Pro は、Google の最新フラッグシップで、Mixture-of-Experts(MoE) アーキテクチャに基づく最先端モデルです。強力なマルチモーダル性能と推論力を、競争力のある価格で提供するよう設計されています。
Anthropic の最新フロンティアモデルとの比較は、Claude Opus 4.7 と Gemini 3.1 Pro のブログをご覧ください。
Gemini 3.1 Pro の主な機能と特長は次のとおりです。
ネイティブにマルチモーダル対応(テキストと画像、音声、動画、PDF に対応)。
low、medium、high の3段階の思考レベルを提供。
100万トークンのコンテキストウィンドウ。最大 65K の出力トークンに対応し、単一のプロンプトで 8.4 時間の音声または 1 時間の動画を受け付け可能。
ARC-AGI-2 で 77.1% を記録し、抽象的な視覚推論が強力。Gemini 3 Pro の 31.1% を大きく上回ります。
長期的なプロフェッショナルタスクを測る APEX-Agents で 33.5% と、Gemini 3 Pro の 18.4% のほぼ2倍。
当社のチュートリアル Building with Gemini 3.1 Pro では、Gemini 3.1 Pro と Gemini CLI を使って本番運用可能なアプリを構築する手順を解説しています。
Gemini 3.1 Pro は複雑な視覚推論タスクに強く、テキスト・画像・動画・音声を単一プロンプトで扱えるネイティブなマルチモーダル設計で優位性があります。さらに 100 万トークンの巨大なコンテキストウィンドウと組み合わせれば、大規模なコードベースや長文 PDF、数時間の動画も一度に分析できます。Gemini 3.1 Pro は、画像・動画生成用の Nano Banana 2 や Veo 3.1 も支えています。
短所としては、Gemini 3.1 Pro の最大出力が 65K トークンであり、長時間のエージェント系タスクには不足する可能性がある点です。長いドキュメント生成や、大量出力を伴うエージェントループには不向きかもしれません。
Gemini 3 と AI 駆動のブラウザテストでファイナンス・ダッシュボードを作る方法は、Google Antigravity のチュートリアルをご覧ください。
Artificial Analysis Intelligence Index によれば、GPT 5.5 は現時点で総合的に最良のモデルであり、コーディングとエージェント系の指標でも首位を獲得しています。
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
リリース日 |
April 23, 2026 |
February 19, 2026 |
|
アーキテクチャ |
オムニモーダル(統合型) |
MoE(Transformer) |
|
コンテキストウィンドウ |
100万トークン |
100万トークン |
|
最大出力 |
128K トークン |
65K トークン |
|
OSWorld |
78.7% |
|
|
BrowseComp |
84.4% |
85.9% |
|
ARC-AGI-2 |
85.0% |
77.1% |
|
GPQA Diamond |
93.6% |
94.3% |
|
Terminal-Bench 2.0 |
82.7% |
68.5% |
|
FrontierMath Tier 4 |
35.4%(Pro 39.6%) |
16.7% |
|
SWE-Bench Pro |
58.6% |
54.2% |
|
API 料金(入力/出力・100万単位) |
$5/$30(Pro $30/$180) |
$2/$12 |
それでは、いくつかのユースケースを見ていきましょう。
コンピュータ操作のベンチマーク OSWorld-Verified で GPT-5.5 は 78.7% を記録していますが、Gemini の公開スコアはありません。実運用では、GPT-5.5 のコンピュータ操作は Codex アプリに組み込まれており、ウェブサイトのナビゲーションやテストが可能です。Google も Antigravity アプリで類似の機能を提供しています。
一方、ウェブエージェント系タスクでは状況が少し変わります。Gemini 3.1 Pro は BrowseComp で 85.9%(GPT-5.5 は 84.4%)とわずかにリードし、36 の MCP サーバーにまたがるツール使用を測る MCP Atlas でも 78.2% と、GPT-5.5 の 75.3% を上回ります。
とはいえ、現実の 600 以上のツールで性能を試す Toolathon では GPT-5.5 が 55.6% と、Gemini の 48.8% を上回ります。さらに、Artificial Analysis Agentic Index でも GPT-5.5 がリードし、Gemini 3.1 Pro は大きく後れを取っています(以下のチャート参照)。
コーディングでは、GPT-5.5 は SWE-Bench Pro で 58.6%、Terminal-Bench 2.0 で 82.7% と、Gemini 3.1 Pro の 54.2%、68.5% を上回ります。特に Terminal-Bench 2.0 では大きな差をつけています。
Artificial Analysis Coding Index では GPT-5.5 が首位で、Gemini 3.1 Pro がすぐ後を追っています。
事前学習なしで学習・問題解決する能力を測る ARC-AGI-2 では、GPT-5.5 が 85.0% と、Gemini 3.1 Pro の 77.1% を約 8 ポイント差で上回ります。
また、専門家レベルの推論力を測る FrontierMath ベンチマークでも、GPT-5.5 は Gemini 3.1 Pro に対して 18 ポイントの差をつけ、上位に立っています。
Gemini 3.1 Pro は入力 100 万トークンで $2、出力 100 万トークンで $12。GPT-5.5 は大幅に高く、入力 100 万トークンで $5、出力 100 万トークンで $30(Pro はその6倍)。入力・出力の双方で、GPT-5.5 は Gemini 3.1 Pro の 2.5 倍超のコストになります。
GPT-5.5 と Gemini 3.1 Pro は、いずれもコンテキストウィンドウが 100 万トークンです。ただし、GPT 5.5 は 128K の出力トークンに対応し、Gemini の 65K を上回ります。
では、2 つのモデルのうちどちらを選ぶべきでしょうか。

紙面上では GPT-5.5 がより強力で、実務でもおそらく多くの開発者にとってはそうでしょう。特にターミナル環境での作業や複雑な数学を扱う場合は顕著です。ゼロからの再構築は功を奏しました。継ぎはぎで整えたモデルではなく、Terminal-Bench 2.0 や FrontierMath の明確な差がそれを示しています。
しかし、「強力」であることが「自分にとって最適」とは限りません。Gemini 3.1 Pro の 2.5 倍の価格である GPT-5.5 は、予算面でのコミットメントが大きく、トークン効率の理屈が成り立つのは、ワークフローが十分に長大でその恩恵を受けられる場合に限られます。
Gemini 3.1 Pro は単なる次点ではありません。BrowseComp、MCP Atlas、GPQA Diamond でリードし、ネイティブな動画・音声処理は、GPT-5.5 のネイティブ機能より依然として先行しています。
多くのチームにとって賢明なのは二者択一にしないことです。大規模・メディア中心のタスクには Gemini 3.1 Pro を基幹として使い、差が効く場面で GPT-5.5 を投入する。このハイブリッド戦略なら、全面的にフロンティア価格を払わずに双方の強みを享受できます。
LLM、プロンプト、チェーン、エージェントを用いた AI アプリ構築を学ぶなら、当社のDeveloping LLM Applications with LangChain コースを強くおすすめします。
DataCamp で AI を学ぼう!
Courses
Courses
Courses