course
OpenAI API के साथ काम करना
3 घंटा
141.6K
OpenAI ने GPT-4.5 के बाद अपना पहला पुन:प्रशिक्षित बेस मॉडल जारी किया है। यह उल्टा लग सकता है, लेकिन GPT-5 और उसके बाद के सभी संस्करण क्रमिक अपडेट थे.
यह अलग है: इसे एजेंटिक वर्कफ़्लो के लिए शुरू से बनाया गया है, और यह उन दो अहम बेंचमार्क पर मजबूत प्रदर्शन करता है जो डेवलपरों के लिए सबसे ज्यादा मायने रखते हैं।
इस लेख में, मैं नए जारी किए गए GPT-5.5 की तुलना Gemini 3.1 Pro से करूंगा ताकि आप तय कर सकें कि आपके लिए कौन‑सा बेहतर है। हम बेंचमार्क, लागत और उपयोग परिदृश्यों को देखेंगे।
GPT-5.5 OpenAI का नवीनतम फ़्लैगशिप Omnimodal मॉडल है, कोड‑नेम “Spud”。 यह किसी पिछले मॉडल का फाइन‑ट्यून नहीं है, बल्कि इसे स्वत:संचालित, बहु‑कार्य निष्पादन के लिए शुरू से फिर से बनाया गया है, जिसमें बहुत कम मार्गदर्शन की जरूरत पड़ती है।
GPT-5.5 तीन वैरिएंट्स के साथ आता है:
मॉडल के बारे में अधिक जानें हमारे OpenAI GPT-5.5 लेख में और हमारी तुलना Claude Opus 4.7 बनाम GPT-5.5 में।
GPT-5.5 की मुख्य विशेषताएं और क्षमताएं:
सबसे बड़ी खूबियों में से एक 512K और 1M के बीच लंबे संदर्भ वाले कार्यों पर बड़ा सुधार है; GPT 5.4 के 36.6% से GPT 5.5 में 74.0% तक प्रदर्शन दोगुने से अधिक हो गया।
यह मॉडल गणित में भी फिलहाल सबसे मजबूत है। FrontierMath Tier 4 पर, GPT 5.5 को 35.4% मिलता है, और GPT 5.5 Pro इसे 39.6% तक ले जाता है। संदर्भ के लिए, GPT 5.4 का स्कोर 27.1%, Claude Opus 4.7 का 22.9%, और Gemini 3.1 Pro का 16.7% था।
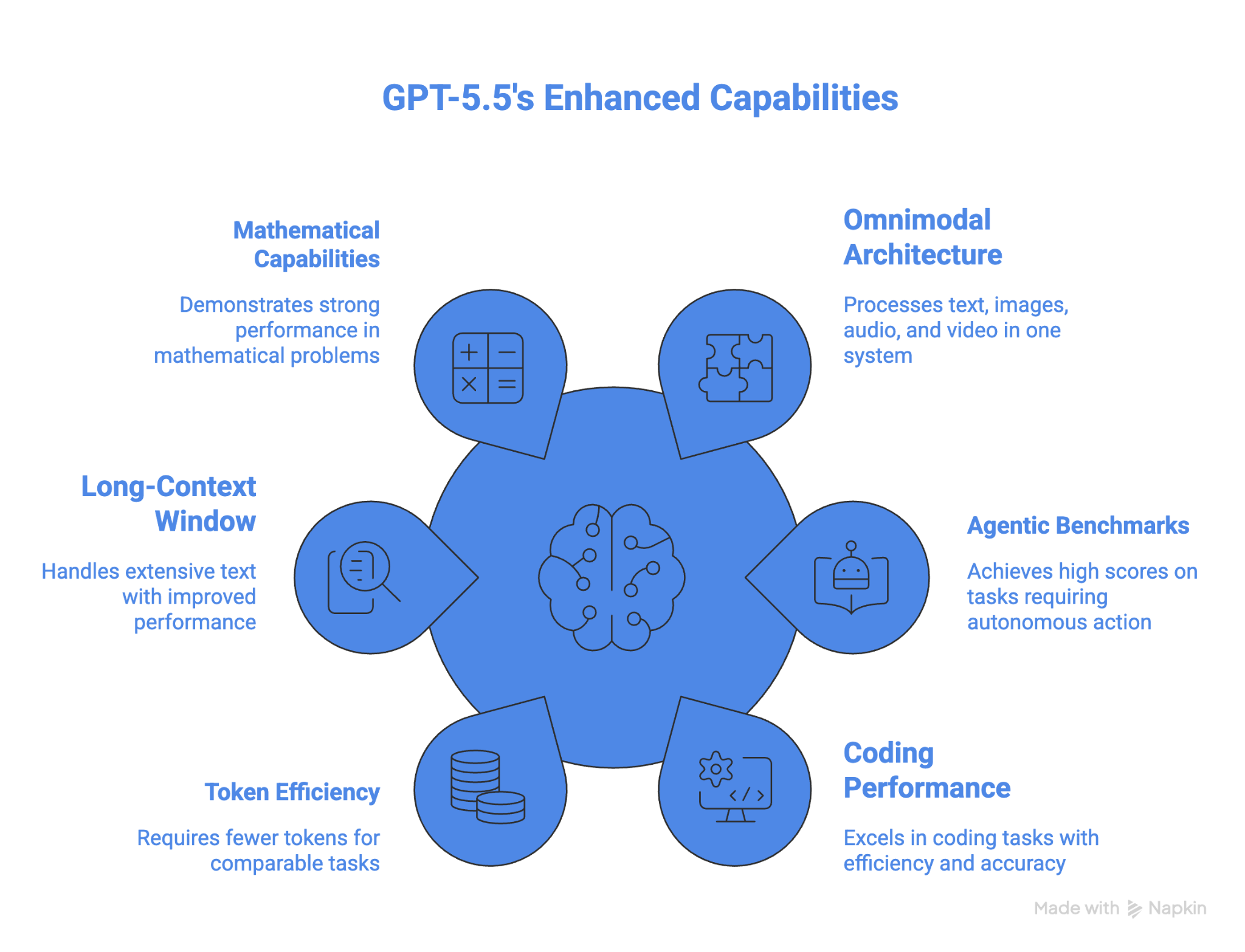
OSWorld-Verified पर GPT-5.5 का प्रदर्शन इसे कंप्यूटर उपयोग के लिए सबसे अच्छा मॉडल बनाता है—कम से कम उन मॉडलों में जिन्होंने इस बेंचमार्क के नतीजे साझा किए हैं। यह उन्नत गणित में भी सभी मॉडलों से आगे है। लंबे समय तक चलने वाले एजेंटिक कार्यों के लिए टोकन दक्षता एक और लाभ है।
दूसरी ओर, GPT-5.5 पिछले मॉडल से ज्यादा महंगा है—1 मिलियन इनपुट टोकन के लिए $5 और 1 मिलियन आउटपुट टोकन के लिए $30। कंपनी कहती है कि यह अधिक टोकन‑कुशल होने के कारण सस्ता पड़ सकता है, लेकिन यह आपके वर्कफ़्लो पर निर्भर करेगा कि वास्तव में ऐसा होता है या नहीं।
Gemini 3.1 Pro Google का वर्तमान अत्याधुनिक फ़्लैगशिप मॉडल है, जो Mixture‑of‑Experts (MoE) आर्किटेक्चर पर बना है। Google ने इसे मजबूत मल्टीमोडल और तर्क प्रदर्शन को प्रतिस्पर्धी कीमत पर देने के लिए डिज़ाइन किया है।
Anthropic के नवीनतम फ्रंटियर मॉडल के साथ तुलना के लिए हमारा ब्लॉग पढ़ें: Claude Opus 4.7 बनाम Gemini 3.1 Pro।
यहां Gemini 3.1 Pro की मुख्य विशेषताएं और क्षमताएं हैं:
स्वाभाविक रूप से मल्टीमोडल, टेक्स्ट और इमेज के साथ सपोर्ट। ऑडियो, वीडियो और PDFs।
तीन‑स्तरीय थिंकिंग सिस्टम, जो low, medium, और high थिंकिंग लेवल प्रदान करता है।
1M टोकन कॉन्टेक्स्ट विंडो, 65K अधिकतम आउटपुट टोकन, और एक ही प्रॉम्प्ट में 8.4 घंटे का ऑडियो या पूरे एक घंटे का वीडियो स्वीकार करता है।
ARC-AGI-2 पर 77.1%, जो अमूर्त दृश्य तर्क में मजबूती दिखाता है—यह Gemini 3 Pro के 31.1% का दोगुने से अधिक है।
APEX-Agents पर 33.5% (लंबी‑अवधि के पेशेवर कार्यों को मापता है), जो Gemini 3 Pro के 18.4% का लगभग दोगुना है।
हमारे Building with Gemini 3.1 Pro ट्यूटोरियल में, हम Gemini 3.1 Pro और Gemini CLI के साथ प्रोडक्शन‑रेडी ऐप बनाना कवर करते हैं।
Gemini 3.1 Pro जटिल दृश्य तर्क कार्यों में चमकता है और इसके स्वाभाविक मल्टीमोडल डिज़ाइन में बढ़त है, जो टेक्स्ट, इमेज, वीडियो और ऑडियो को एक ही प्रॉम्प्ट में संभालता है। इसे विशाल 1M टोकन कॉन्टेक्स्ट विंडो के साथ जोड़ें, और आप एक बार में पूरे कोडबेस, लंबे PDFs या घंटों के वीडियो का विश्लेषण कर सकते हैं। Gemini 3.1 Pro इमेज और वीडियो आउटपुट के लिए Nano Banana 2 और Veo 3.1 को भी संचालित करता है।
सीमा के रूप में, Gemini 3.1 Pro में 65K आउटपुट टोकन हैं, जो लंबे समय तक चलने वाले एजेंटिक कार्यों के लिए पर्याप्त नहीं हो सकते। इसका मतलब है कि यह लंबे दस्तावेज़ निर्माण और बड़े आउटपुट देने वाले एजेंटिक लूप्स के लिए उपयुक्त नहीं हो सकता।
हमारे Google Antigravity ट्यूटोरियल से जानें कि Gemini 3 के साथ फाइनेंस डैशबोर्ड और AI‑चालित ब्राउज़र टेस्टिंग कैसे बनाएं।
Artificial Analysis Intelligence Index के अनुसार, GPT 5.5 फिलहाल कुल मिलाकर सबसे अच्छा मॉडल है, और यह उनके कोडिंग और एजेंटिक इंडेक्स पर भी आगे है।
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
रिलीज़ तिथि |
23 अप्रैल, 2026 |
19 फरवरी, 2026 |
|
आर्किटेक्चर |
ओम्निमोडल (एकीकृत) |
MoE (Transformer) |
|
कॉन्टेक्स्ट विंडो |
1M टोकन |
1M टोकन |
|
अधिकतम आउटपुट |
128K टोकन |
65K टोकन |
|
OSWorld |
78.7% |
|
|
BrowseComp |
84.4% |
85.9% |
|
ARC-AGI-2 |
85.0% |
77.1% |
|
GPQA Diamond |
93.6% |
94.3% |
|
Terminal-Bench 2.0 |
82.7% |
68.5% |
|
FrontierMath Tier 4 |
35.4% (Pro 39.6%) |
16.7% |
|
SWE-Bench Pro |
58.6% |
54.2% |
|
API प्राइसिंग (इनपुट/आउटपुट प्रति 1M) |
$5/$30 (Pro $30/$180) |
$2/$12 |
आइए कुछ अलग‑अलग उपयोग मामलों पर नज़र डालते हैं।
कंप्यूटर उपयोग के लिए OSWorld-Verified बेंचमार्क पर GPT-5.5 का स्कोर 78.7% है, हालांकि इसकी तुलना के लिए कोई सार्वजनिक Gemini स्कोर उपलब्ध नहीं है। व्यवहार में, GPT-5.5 का कंप्यूटर उपयोग Codex ऐप में अंतर्निहित है, जहां यह वेबसाइट्स पर नेविगेट और टेस्ट कर सकता है। Google समान सुविधा अपनी Antigravity ऐप के माध्यम से देता है।
वेब‑एजेंट कार्यों की बात आए तो तस्वीर और दिलचस्प हो जाती है। BrowseComp पर Gemini 3.1 Pro 85.9% के साथ आगे निकलता है, जबकि GPT-5.5 84.4% पर है, और यह MCP Atlas (36 MCP सर्वरों पर टूल उपयोग का परीक्षण करने वाला बेंचमार्क) पर भी बेहतर करता है—78.2% बनाम GPT-5.5 का 75.3%।
फिर भी, Toolathon में GPT-5.5 पलटवार करता है, जो किसी मॉडल पर 600 से अधिक वास्तविक‑दुनिया टूल्स फेंकता है—यहां इसका स्कोर 55.6% है जबकि Gemini का 48.8%। GPT-5.5 Artificial Analysis Agentic Index पर भी बढ़त लेता है, जहां Gemini 3.1 Pro काफी पीछे है, जैसा कि नीचे के चार्ट में दिखाया गया है।
कोडिंग की बात आए तो GPT-5.5, SWE-Bench Pro पर 58.6% और Terminal-Bench 2.0 पर 82.7% के स्कोर के साथ Gemini 3.1 Pro (क्रमश: 54.2% और 68.5%) से आगे है। खासकर Terminal-Bench 2.0 पर GPT-5.5 बड़ी बढ़त बनाता है।
Artificial Analysis Coding Index पर GPT-5.5 आगे है और Gemini 3.1 Pro उसके ठीक पीछे।
ARC-AGI-2 पर, जो किसी मॉडल की बिना पूर्व प्रशिक्षण के सीखने और समस्याएं सुलझाने की क्षमता को मापता है, GPT-5.5 लगभग 8 अंकों के अंतर से Gemini 3.1 Pro से आगे है (85.0% बनाम 77.1%)।
उन्नत गणित में भी GPT-5.5 आगे है—FrontierMath बेंचमार्क के अनुसार Gemini 3.1 Pro की तुलना में 18 अंकों का अंतर, जो विशेषज्ञ स्तर पर मॉडल की तर्क क्षमता का परीक्षण करता है।
Gemini 3.1 Pro की कीमत 1M इनपुट टोकन पर $2 और 1M आउटपुट टोकन पर $12 है। GPT-5.5 काफी ऊंचे दर से शुरू होता है—1M इनपुट टोकन पर $5 और 1M आउटपुट टोकन पर $30 (और Pro मॉडल के लिए इसकी छह गुना)। यह GPT 5.5 को Gemini 3.1 Pro से दोगुने से अधिक महंगा बनाता है।
GPT-5.5 और Gemini 3.1 Pro दोनों में 1M का कॉन्टेक्स्ट विंडो है। हालांकि, GPT 5.5 में 128K आउटपुट टोकन हैं, जबकि Gemini में 65K।
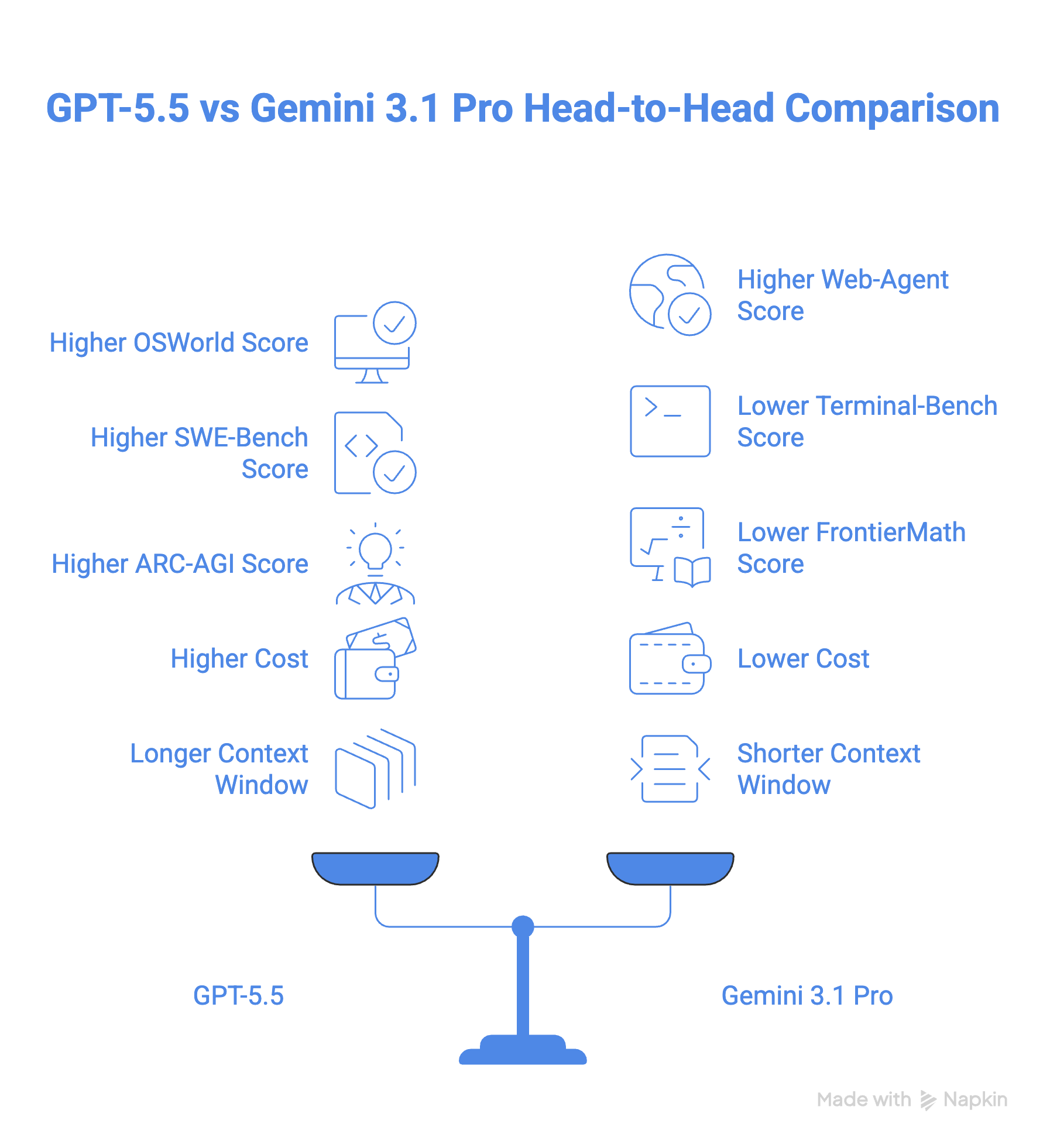
अब सवाल आता है कि इन दोनों मॉडलों में से किसे चुना जाए।

कागज़ पर GPT-5.5 ज्यादा मजबूत मॉडल है, और अधिकतर डेवलपरों के लिए व्यवहार में भी शायद यही सच होगा—खासकर यदि आपका काम टर्मिनल परिवेशों में होता है या जटिल गणित का उपयोग करता है। शुरू से किया गया पुनर्निर्माण सफल रहा: यह ऐसा मॉडल नहीं है जिसे बाद में पैच करके ठीक किया गया हो, और Terminal-Bench 2.0 तथा FrontierMath पर बेंचमार्क अंतर यह साफ बताता है।
लेकिन “ज्यादा मजबूत” हमेशा “आपके लिए बेहतर” नहीं होता। Gemini 3.1 Pro की तुलना में 2.5 गुना कीमत पर, GPT-5.5 एक वास्तविक बजट प्रतिबद्धता है, और टोकन दक्षता वाला दलील तभी लागू होता है जब आपके वर्कफ़्लो इतने लंबे हों कि उसका लाभ मिल सके।
Gemini 3.1 Pro यहां रनर‑अप नहीं है। यह एक प्रतिस्पर्धी मॉडल है जो BrowseComp, MCP Atlas और GPQA Diamond पर आगे है, और इसका स्वदेशी वीडियो और ऑडियो हैंडलिंग अब भी GPT-5.5 के नैटिव ऑफ़रिंग से आगे है।
अधिकांश टीमों के लिए समझदारी भरा तरीका शायद बाइनरी चुनाव नहीं है: उच्च‑वॉल्यूम या मीडिया‑हेवी कार्यों के लिए Gemini 3.1 Pro को वर्कहॉर्स बनाएं, और जहां मार्जिन वास्तव में मायने रखता है वहां GPT-5.5 लाएं। यह हाइब्रिड तरीका आपको दोनों का सर्वश्रेष्ठ देता है, बिना हर जगह फ्रंटियर कीमतें चुकाए।
यदि आप LLMs, प्रॉम्प्ट्स, चेन्स और एजेंट्स का उपयोग करते हुए LangChain में AI‑समर्थित एप्लिकेशन बनाना सीखना चाहते हैं, तो मैं हमारे Developing LLM Applications with LangChain कोर्स की जोरदार अनुशंसा करता/करती हूं।
DataCamp के साथ AI सीखें!
course
course
course