Courses
使用 OpenAI API
3小时
141.6K
OpenAI 刚刚发布了自 GPT-4.5 以来首个重新训练的基础模型。听起来有点反直觉,但 GPT-5 及其后续版本都只是增量更新。
这次不同:它自底向上专为代理式工作流而建,在两项对开发者最重要的关键基准上表现强劲。
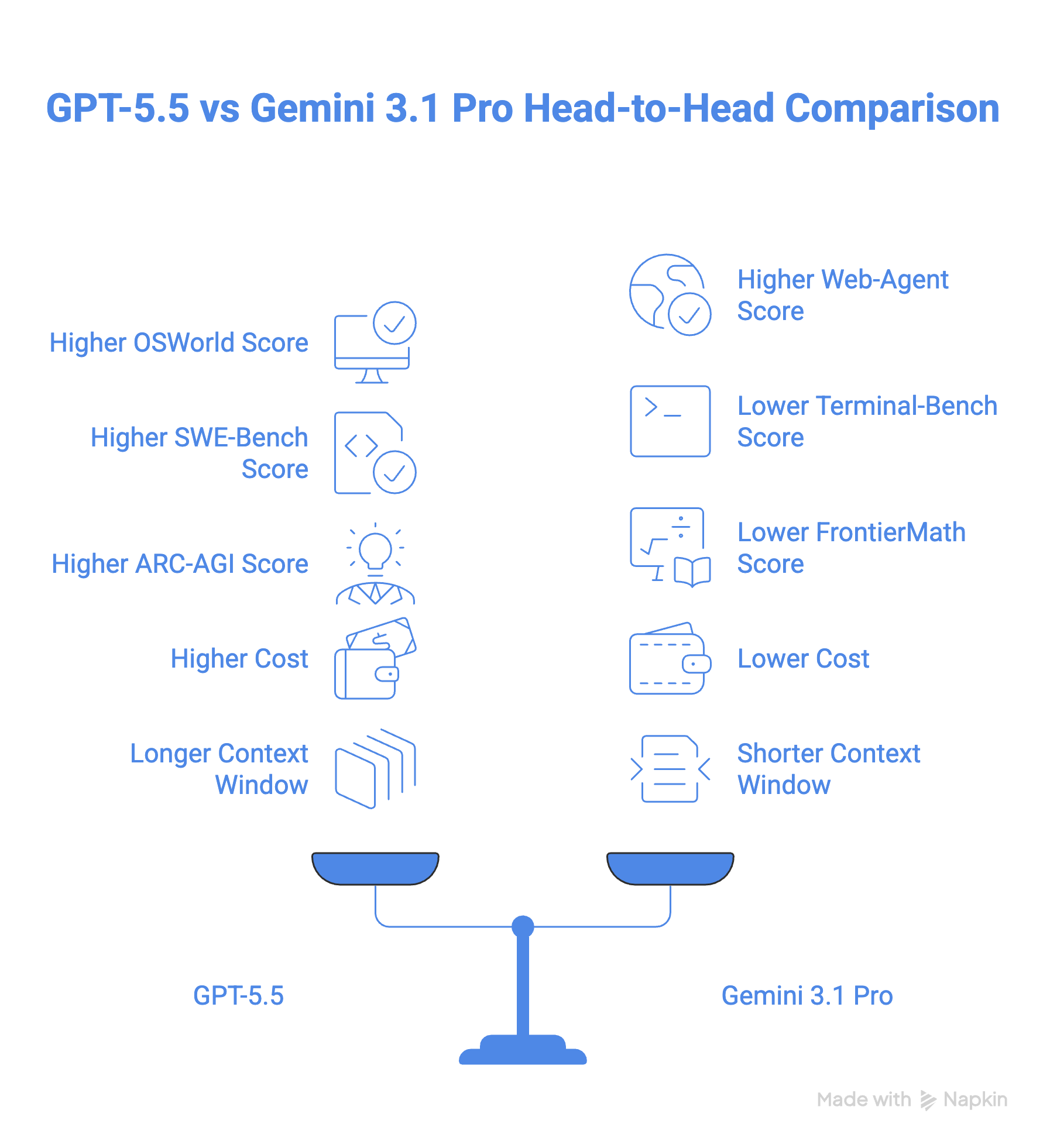
本文将把新发布的 GPT-5.5 与 Gemini 3.1 Pro 进行对比,帮助您判断哪款更适合您。我们将从基准测试、成本和使用场景等方面入手。
GPT-5.5 是 OpenAI 最新的旗舰全模态(Omnimodal)模型,代号“Spud”。它并非在旧模型基础上微调,而是自底向上重构,以最少人工干预实现自主的多任务执行。
GPT-5.5 提供三个变体:
在我们的OpenAI GPT-5.5文章以及Claude Opus 4.7 vs GPT-5.5对比中了解更多信息。
GPT-5.5 的核心特性与能力包括:
一大亮点是在 512K 到 100 万的长上下文区间表现显著提升:从 GPT 5.4 的 36.6% 翻倍至 GPT 5.5 的 74.0%。
该模型目前在数学方面也最为强劲。在 FrontierMath 第 4 档上,GPT 5.5 得分 35.4%,GPT 5.5 Pro 则提升至 39.6%。作为参考,GPT 5.4 为 27.1%,Claude Opus 4.7 为 22.9%,Gemini 3.1 Pro 为 16.7%。
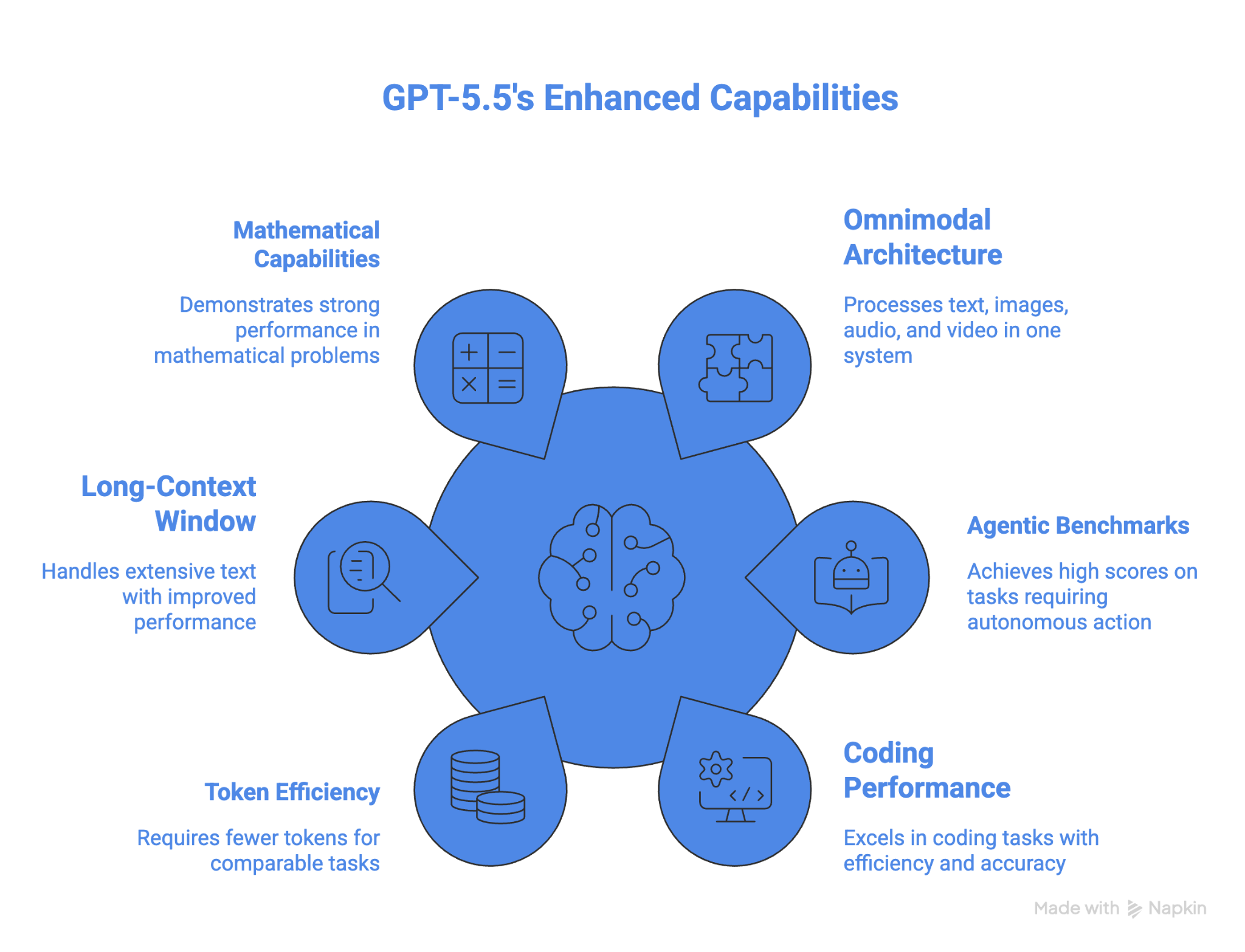
在 OSWorld-Verified 上的表现,使 GPT-5.5 成为在该基准上提交结果的模型中最适合计算机操作的选择。它也在高阶数学上领先于其他模型。对于长时间运行的代理式任务,Token 效率是另一项优势。
不足之处在于,GPT-5.5 比上一代更贵:输入每百万 Token 5 美元,输出每百万 Token 30 美元。官方称由于 Token 效率更高,实际可能更便宜,但这是否成立取决于您的具体工作流。
Gemini 3.1 Pro 是 Google 目前的最先进旗舰模型,采用专家混合(MoE)架构构建。Google 将其设计为在多模态与推理性能上表现强劲,同时具备有竞争力的价格。
若想与 Anthropic 最新前沿模型对比,请阅读我们的Claude Opus 4.7 vs Gemini 3.1 Pro博文。
Gemini 3.1 Pro 的关键特性与能力包括:
原生多模态,支持文本与图像、音频、视频及 PDF。
三档思维系统,提供 low、medium 与 high 思维级别。
100 万 Token 上下文窗口,最多 65K 输出 Token,单次提示可接收 8.4 小时音频或 1 小时完整视频。
ARC-AGI-2 得分 77.1%,在抽象视觉推理上表现强劲,较 Gemini 3 Pro 的 31.1% 提升逾一倍。
APEX-Agents 得分 33.5%,用于衡量长周期专业任务,几乎是 Gemini 3 Pro 的 18.4% 的两倍。
在我们的使用 Gemini 3.1 Pro 构建教程中,我们介绍了如何利用 Gemini 3.1 Pro 与 Gemini CLI 构建可用于生产的应用。
Gemini 3.1 Pro 在复杂视觉推理任务上表现突出,并凭借其原生多模态设计占据优势,能够在单次提示中同时处理文本、图像、视频与音频。再加上高达 100 万 Token 的上下文窗口,您可以一次性分析完整代码库、冗长 PDF 或数小时的视频。Gemini 3.1 Pro 还为图像与视频生成提供Nano Banana 2 和 Veo 3.1的底层支持。
不足之处是,Gemini 3.1 Pro 的输出上限为 65K Token,可能不足以支撑长时间运行的代理式任务。这意味着它或许不太适合长文档生成以及会产生大量输出的代理式循环。
通过我们的Google Antigravity教程,学习如何用 Gemini 3 构建金融看板与 AI 驱动的浏览器测试。
根据 Artificial Analysis Intelligence Index,GPT 5.5 目前是整体最强的模型,同时也在其编码与代理指数上领跑。
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
发布日期 |
2026 年 4 月 23 日 |
2026 年 2 月 19 日 |
|
架构 |
全模态(统一) |
MoE(Transformer) |
|
上下文窗口 |
100 万 Token |
100 万 Token |
|
最大输出 |
128K Token |
65K Token |
|
OSWorld |
78.7% |
|
|
BrowseComp |
84.4% |
85.9% |
|
ARC-AGI-2 |
85.0% |
77.1% |
|
GPQA Diamond |
93.6% |
94.3% |
|
Terminal-Bench 2.0 |
82.7% |
68.5% |
|
FrontierMath 第 4 档 |
35.4%(Pro 39.6%) |
16.7% |
|
SWE-Bench Pro |
58.6% |
54.2% |
|
API 定价(输入/输出,每百万) |
$5/$30(Pro $30/$180) |
$2/$12 |
接下来我们来看几个不同的使用场景。
GPT-5.5 在 OSWorld-Verified 计算机操作基准上得分 78.7%,尽管目前没有公开的 Gemini 对比分数。实践中,GPT-5.5 的计算机操作被集成在Codex 应用中,能够导航与测试网站。Google 则通过其 Antigravity 应用提供类似功能。
在网页代理任务方面,情况更有意思。Gemini 3.1 Pro 在 BrowseComp 上以 85.9% 小幅领先 GPT-5.5 的 84.4%,并且在 MCP Atlas(跨 36 个 MCP 服务器测试工具使用的基准)上表现更好,得分 78.2%,而 GPT-5.5 为 75.3%。
话虽如此,GPT-5.5 在 Toolathon 上扳回一城。该基准向模型抛出 600 多种真实世界工具,GPT-5.5 得分 55.6%,而 Gemini 为 48.8%。GPT-5.5 也在 Artificial Analysis Agentic Index 上领跑,而 Gemini 3.1 Pro 明显落后,如下图所示。
在编码方面,GPT-5.5 以 SWE-Bench Pro 的 58.6% 和 Terminal-Bench 2.0 的 82.7% 领先于 Gemini 3.1 Pro 的 54.2% 与 68.5%。尤其是在 Terminal-Bench 2.0 上,GPT-5.5 以较大优势领先。
在 Artificial Analysis Coding Index 上,GPT-5.5 领先,Gemini 3.1 Pro 紧随其后。
在 ARC-AGI-2 上(衡量模型无需预训练即可学习与解决问题的能力),GPT-5.5 以近 8 分的差距(85.0% vs 77.1%)领先 Gemini 3.1 Pro。
在高阶数学方面,GPT-5.5 也以 FrontierMath 基准测得的 18 分差距领先 Gemini 3.1 Pro,该基准用于测试模型的专家级推理能力。
Gemini 3.1 Pro 的价格为每百万输入 Token 2 美元、每百万输出 Token 12 美元。GPT-5.5 的起价明显更高:每百万输入 Token 5 美元、每百万输出 Token 30 美元(Pro 版本为其 6 倍)。这使得 GPT 5.5 的价格超过 Gemini 3.1 Pro 的 2.5 倍。
GPT-5.5 与 Gemini 3.1 Pro 均为 100 万上下文窗口。不过,GPT 5.5 提供 128K 输出 Token,而 Gemini 为 65K。
问题回到选择哪一个模型更合适。

从纸面上看,GPT-5.5 更强;对多数开发者而言,实践中可能也如此,尤其当您的工作涉及终端环境或复杂数学时。自底向上的重构收到了回报:这不是一个“打补丁凑出来”的模型,Terminal-Bench 2.0 与 FrontierMath 上的差距已经说明了一切。
但“更强”不总是“更适合您”。相较 Gemini 3.1 Pro 贵 2.5 倍的 GPT-5.5 是一笔实打实的预算投入,而所谓 Token 效率的论点只有在您的工作流足够长、能从中受益时才站得住脚。
Gemini 3.1 Pro 并非简单的“亚军”。它在 BrowseComp、MCP Atlas 与 GPQA Diamond 上领先,且其原生视频与音频处理依然走在 GPT-5.5 的原生能力之前。
对多数团队而言,更明智的做法可能不是二选一:用 Gemini 3.1 Pro 作为高吞吐或媒体密集型任务的主力,再在真正需要拉开差距的地方引入 GPT-5.5。这样混合使用,既能各取所长,又无需为所有任务都支付前沿模型的高价。
如果您想学习如何在 LangChain 中使用大语言模型、提示、链与代理来构建 AI 应用,我强烈推荐我们的Developing LLM Applications with LangChain课程。
在 DataCamp 学习 AI!
Courses
Courses
Courses