
Curso
Trabalhar com a API da OpenAI
3 h
141.6K
A OpenAI acabou de lançar seu primeiro modelo base reentreinado desde o GPT-4.5. Pode soar contraintuitivo, mas o GPT-5 e todos os seus sucessores foram atualizações incrementais.
Desta vez é diferente: ele foi reconstruído do zero para fluxos de trabalho agentic, com desempenho forte em dois benchmarks críticos que mais importam para desenvolvedores.
Neste artigo, vou comparar o recém-lançado GPT-5.5 com o Gemini 3.1 Pro para ajudar você a decidir qual é o melhor para o seu caso. Vamos analisar os benchmarks, o custo e os casos de uso.
GPT-5.5 é o mais novo modelo omnimodal carro-chefe da OpenAI, codinome "Spud". Não é um fine-tune de um modelo anterior, mas sim um modelo reconstruído do zero para execução autônoma e multitarefa, com pouca ou nenhuma orientação.
GPT-5.5 chega em três variantes:
Saiba mais sobre o modelo no nosso artigo OpenAI GPT-5.5 e na nossa comparação Claude Opus 4.7 vs GPT-5.5.
Os recursos e capacidades centrais do GPT-5.5 são:
Um dos maiores destaques é a forte evolução em longos contextos entre 512K e 1M; o desempenho mais que dobrou, de 36,6% no GPT-5.4 para 74,0% no GPT-5.5.
O modelo também é, no momento, o mais forte em matemática. No FrontierMath Tier 4, o GPT-5.5 alcança 35,4%, e o GPT-5.5 Pro eleva isso para 39,6%. Para contexto, o GPT-5.4 marcou 27,1%, o Claude Opus 4.7 marcou 22,9% e o Gemini 3.1 Pro marcou 16,7%.
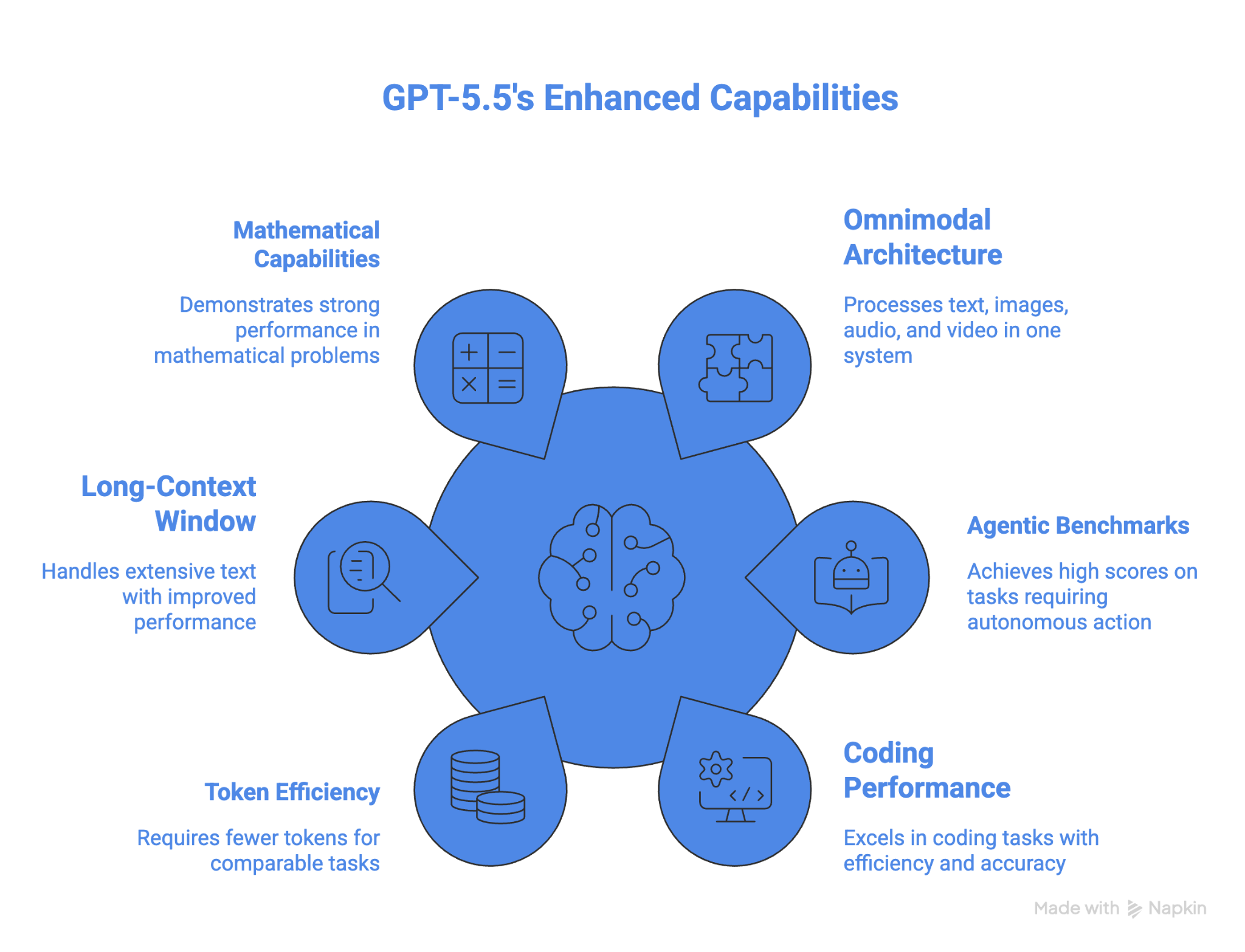
O desempenho do GPT-5.5 no OSWorld-Verified faz dele o melhor modelo para uso de computador entre aqueles que divulgaram resultados nesse benchmark. Ele também supera todos os outros modelos em matemática avançada. A eficiência de tokens é outra vantagem para tarefas agentic de longa duração.
Por outro lado, o GPT-5.5 é mais caro que o modelo anterior: US$ 5 por milhão de tokens de entrada e US$ 30 por milhão de tokens de saída. A empresa afirma que pode sair mais barato por ser mais eficiente em tokens, mas isso vai depender do seu fluxo de trabalho.
Gemini 3.1 Pro é o atual modelo carro-chefe de ponta do Google, construído sobre uma arquitetura Mixture-of-Experts (MoE). O Google o projetou para oferecer forte desempenho multimodal e de raciocínio a um preço competitivo.
Para uma comparação com o mais recente modelo frontier da Anthropic, confira nosso blog sobre Claude Opus 4.7 vs Gemini 3.1 Pro.
Aqui estão os principais recursos e capacidades do Gemini 3.1 Pro:
Multimodal nativo com suporte a texto e imagens. Áudio, vídeo e PDFs.
Sistema de pensamento em três níveis, oferecendo níveis low, medium e high.
Janela de contexto de 1M de tokens, com 65K tokens máximos de saída e aceitação, em um único prompt, de 8,4 horas de áudio ou uma hora completa de vídeo.
77,1% no ARC-AGI-2, mostrando forte raciocínio visual abstrato, mais que o dobro dos 31,1% do Gemini 3 Pro.
33,5% no APEX-Agents, que mede tarefas profissionais de longo horizonte, quase o dobro dos 18,4% do Gemini 3 Pro.
No nosso tutorial Building with Gemini 3.1 Pro, mostramos como criar um app pronto para produção com o Gemini 3.1 Pro e o Gemini CLI.
O Gemini 3.1 Pro brilha em tarefas complexas de raciocínio visual e tem vantagem pela arquitetura nativamente multimodal, que processa texto, imagens, vídeo e áudio em um único prompt. Combinado a uma janela de contexto gigante de 1M de tokens, você pode analisar bases de código inteiras, PDFs extensos ou horas de vídeo de uma só vez. O Gemini 3.1 Pro também alimenta o Nano Banana 2 e o Veo 3.1 para geração de imagem e vídeo.
Por outro lado, o Gemini 3.1 Pro limita a saída a 65K tokens, o que pode não ser suficiente para tarefas agentic de longa duração. Isso significa que pode não ser a melhor escolha para geração de documentos longos e ciclos agentic que produzem grandes volumes de saída.
Aprenda a criar um dashboard financeiro com o Gemini 3 e testes de navegador orientados por IA no nosso tutorial Google Antigravity.
De acordo com o Artificial Analysis Intelligence Index, o GPT-5.5 é hoje o melhor modelo geral e também lidera os índices de código e agentic deles.
|
GPT-5.5 |
Gemini 3.1 Pro |
|
|---|---|---|
|
Data de lançamento |
23 de abril de 2026 |
19 de fevereiro de 2026 |
|
Arquitetura |
Omnimodal (unificada) |
MoE (Transformer) |
|
Janela de contexto |
1M de tokens |
1M de tokens |
|
Saída máxima |
128K tokens |
65K tokens |
|
OSWorld |
78,7% |
|
|
BrowseComp |
84,4% |
85,9% |
|
ARC-AGI-2 |
85,0% |
77,1% |
|
GPQA Diamond |
93,6% |
94,3% |
|
Terminal-Bench 2.0 |
82,7% |
68,5% |
|
FrontierMath Tier 4 |
35,4% (Pro 39,6%) |
16,7% |
|
SWE-Bench Pro |
58,6% |
54,2% |
|
Preço da API (entrada/saída por 1M) |
US$ 5/US$ 30 (Pro US$ 30/US$ 180) |
US$ 2/US$ 12 |
Vamos dar uma olhada em alguns casos de uso diferentes.
O GPT-5.5 marca 78,7% no benchmark OSWorld-Verified para uso de computador, embora não haja pontuação pública do Gemini para comparar. Na prática, o uso de computador do GPT-5.5 vem embutido no app Codex, onde ele pode navegar e testar sites. O Google oferece funcionalidade semelhante no app Antigravity.
Quando falamos de tarefas como agente web, o cenário fica mais interessante. O Gemini 3.1 Pro fica na frente com 85,9% no BrowseComp contra 84,4% do GPT-5.5, e também vai melhor no MCP Atlas (um benchmark que testa o uso de ferramentas em 36 servidores MCP), com 78,2% contra 75,3% do GPT-5.5.
Dito isso, o GPT-5.5 dá o troco no Toolathon, que coloca mais de 600 ferramentas reais diante do modelo, marcando 55,6% contra 48,8% do Gemini. O GPT-5.5 também lidera no Artificial Analysis Agentic Index, onde o Gemini 3.1 Pro fica bem atrás, como mostra o gráfico abaixo.
Em programação, o GPT-5.5 supera o Gemini 3.1 Pro com 58,6% no SWE-Bench Pro e 82,7% no Terminal-Bench 2.0, contra 54,2% e 68,5% do Gemini 3.1 Pro, respectivamente. Especialmente no Terminal-Bench 2.0, o GPT-5.5 lidera com ampla vantagem.
O GPT-5.5 lidera o Artificial Analysis Coding Index, com o Gemini 3.1 Pro logo atrás.
No ARC-AGI-2, que mede a capacidade de um modelo aprender e resolver problemas sem treinamento prévio, o GPT-5.5 supera o Gemini 3.1 Pro com diferença de quase 8 pontos (85,0% vs 77,1%).
O GPT-5.5 também lidera em matemática avançada com uma diferença de 18 pontos em relação ao Gemini 3.1 Pro, medida pelo benchmark FrontierMath, que testa a capacidade de raciocínio em nível de especialista.
O Gemini 3.1 Pro custa US$ 2 por 1M de tokens de entrada e US$ 12 por 1M de tokens de saída. O GPT-5.5 parte de um valor significativamente maior, cobrando US$ 5 por 1M de tokens de entrada e US$ 30 por 1M de tokens de saída (e seis vezes isso no modelo Pro). Isso torna o GPT-5.5 mais que o dobro do preço do Gemini 3.1 Pro.
GPT-5.5 e Gemini 3.1 Pro têm janela de contexto de 1M. Porém, o GPT-5.5 oferece 128K tokens de saída, contra 65K do Gemini.
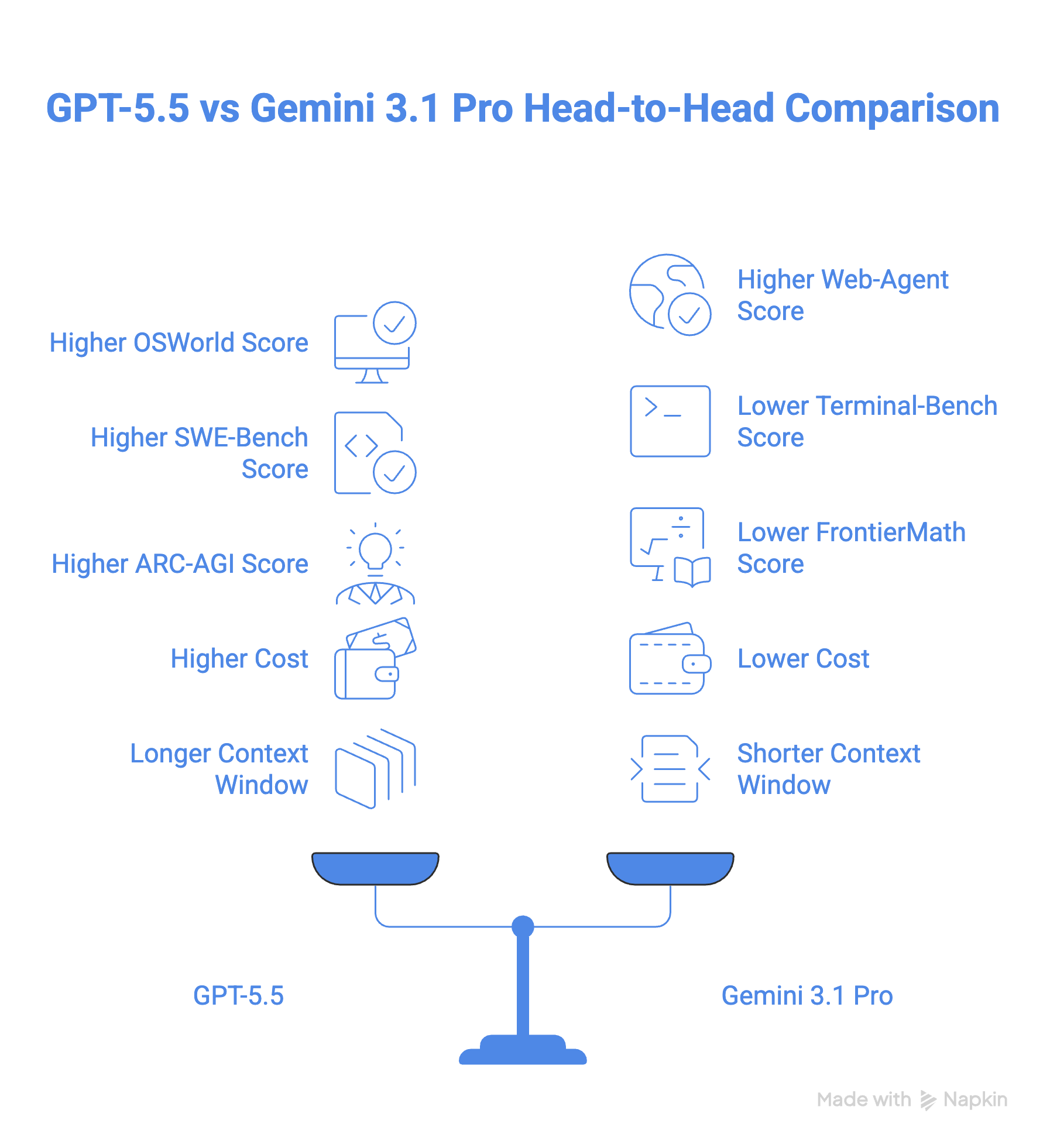
Chegamos então à pergunta: qual dos dois modelos escolher?

No papel, o GPT-5.5 é o modelo mais forte e, para a maioria dos desenvolvedores, provavelmente também na prática — especialmente se seu trabalho vive em ambientes de terminal ou usa matemática complexa. A reconstrução do zero valeu a pena: não é um modelo "remendado", e as diferenças nos benchmarks Terminal-Bench 2.0 e FrontierMath deixam isso claro.
Mas "mais forte" nem sempre significa "melhor para você". Custando 2,5x o preço do Gemini 3.1 Pro, o GPT-5.5 é um compromisso orçamentário real, e o argumento de eficiência de tokens só vale se seus fluxos forem longos o suficiente para se beneficiarem disso.
O Gemini 3.1 Pro não é coadjuvante aqui. É um modelo competitivo que lidera no BrowseComp, MCP Atlas e GPQA Diamond, e seu tratamento nativo de vídeo e áudio ainda está à frente do que o GPT-5.5 oferece nativamente.
Para a maioria dos times, a jogada mais inteligente provavelmente não é uma escolha binária: use o Gemini 3.1 Pro como cavalo de batalha para tarefas de alto volume ou ricas em mídia e traga o GPT-5.5 quando a margem realmente importar. Essa abordagem híbrida dá o melhor dos dois mundos sem pagar preço de frontier em tudo.
Se você quer aprender a construir aplicações com IA usando LLMs, prompts, chains e agentes no LangChain, recomendo muito o nosso curso Developing LLM Applications with LangChain.
Aprenda IA com a DataCamp!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
blog
Richie Cotton
7 min
blog
Khalid Abdelaty
15 min
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan



