De fapt, folosiți rezultatele ecuațiilor diferențiale de fiecare dată când antrenați o rețea neuronală sau chiar când potriviți un model de regresie. Matematica din spate este analiza, iar ecuațiile diferențiale se află chiar în centrul ei. Dacă v-ați întrebat vreodată de ce funcționează gradient descent sau cum urmărește un filtru Kalman un obiect în mișcare, ecuațiile diferențiale sunt răspunsul.
Ecuațiile diferențiale vă permit să modelați cum se schimbă în timp lucrurile – iar asta este exact esența științei datelor. Odată ce înțelegeți ideile de bază, le veți vedea peste tot: în funcțiile de pierdere pe care le minimizați, în seriile de timp pe care le prognozați și în simulările pe care le rulați.
În acest articol, vă voi prezenta ce sunt ecuațiile diferențiale, principalele tipuri pe care le veți întâlni, cum se rezolvă și – cel mai important – cum apar ele în practica zilnică a științei datelor și a învățării automate.
Ce sunt ecuațiile diferențiale?
O ecuație diferențială este o ecuație care leagă o funcție de derivatele ei.
Pe înțelesul tuturor, o derivată vă spune cât de repede se schimbă ceva la un moment dat. O ecuație diferențială afirmă că rata de schimbare a unei mărimi depinde de însăși mărimea respectivă, sau de timp, sau de ambele.
Să zicem că modelați o populație de bacterii. Cu cât aveți mai multe bacterii, cu atât se reproduc mai repede. Așadar, rata de creștere depinde de mărimea populației curente. Scrieți asta ca ecuație și aveți o ecuație diferențială.
Formal, arată astfel:
Reprezentare a unei ecuații diferențiale
Unde P este populația, t este timpul, iar r este rata de creștere. Partea stângă este derivata – cât de repede se schimbă P în timp. Partea dreaptă spune că acea schimbare este proporțională cu P însăși.
Aceasta este ideea de bază din spatele fiecărei ecuații diferențiale pe care o veți vedea.
Ecuațiile diferențiale apar în fizică, biologie și inginerie – oriunde un sistem evoluează în timp. Căldura care se propagă printr-o tijă metalică, un pendul care oscilează, un virus care se răspândește într-o populație. Toate acestea sunt modelate cu ecuații diferențiale.
Pentru specialiștii în știința datelor, veți întâlni ecuații diferențiale în funcțiile de pierdere, în gradient descent, în modelele de serii de timp, în ODE-uri neuronale – toate au la bază ecuații diferențiale. Nu le vedeți mereu explicit, dar ele există acolo.
Când le înțelegeți, veți avea un model mental mai clar al motivului și modului în care funcționează instrumentele pe care le folosiți zilnic.
Istoria ecuațiilor diferențiale
La sfârșitul secolului al XVII-lea, Isaac Newton și Gottfried Wilhelm Leibniz au dezvoltat independent analiza matematică. Amândoi aveau nevoie de o modalitate de a descrie cum se schimbă în timp mărimile fizice, iar rezultatul au fost ecuațiile diferențiale. Newton le-a folosit pentru a modela mișcarea și gravitația. Leibniz ne-a oferit mare parte din notația pe care o folosim și astăzi, inclusiv d/dt pe care o vedeți în orice manual de analiză.
Secolele al XVIII-lea și al XIX-lea au adus un val de tehnici noi.
Leonhard Euler a dezvoltat metode pentru rezolvarea numerică a ODE-urilor – același Euler al metodei lui Euler, pe care o veți vedea mai târziu în acest articol. Joseph-Louis Lagrange și Pierre-Simon Laplace au extins teoria la sisteme mai complexe. Jean-Baptiste Joseph Fourier a introdus o modalitate de a descompune funcțiile în componente sinus și cosinus, devenită piatră de temelie în rezolvarea ecuațiilor diferențiale parțiale.
Până în secolul al XX-lea, ecuațiile diferențiale erau peste tot: de la dinamica fluidelor, mecanica cuantică, până la ingineria electrică. Multe ecuații reale nu aveau soluții analitice curate. Acolo au preluat metoda numerice, iar computerele le-au făcut practice la scară.
Astăzi, domeniul evoluează în continuare. Ecuațiile diferențiale ordinare neuronale (Neural ODEs) tratează straturile unei rețele neuronale ca pe un proces continuu descris de o ecuație diferențială. Este o dezvoltare recentă care estompează granița dintre deep learning și matematica clasică. De asemenea, este una dintre cele mai interesante direcții din cercetarea ML modernă.
Cu toate acestea, ideea de bază rămâne aceeași: modelați cum se schimbă lucrurile și veți putea prezice încotro se îndreaptă.
Tipuri de ecuații diferențiale
Nu toate ecuațiile diferențiale sunt la fel. Primul lucru pe care trebuie să-l știți este cum să le deosebiți.
Împărțirea principală este între ecuațiile diferențiale ordinare (ODE) și ecuațiile diferențiale parțiale (PDE). Diferența ține de câte variabile independente are funcția.
Ecuații diferențiale ordinare (ODE)
O ecuație diferențială ordinară implică o funcție a unei singure variabile independente și derivatele acesteia.
Exemplul cu populația de bacterii de mai devreme este o ODE. Populația P depinde doar de timp t – o variabilă. Așadar, ecuația are doar derivate ordinare, scrise ca dP/dt.
ODE-urile sunt instrumentul potrivit când sistemul dumneavoastră evoluează de-a lungul unei singure dimensiuni, de obicei timpul. Iată câteva exemple clasice:
- Creșterea populației – rata de schimbare a unei populații depinde de mărimea populației curente
- Dezintegrarea radioactivă – rata la care o substanță se dezintegrează depinde de cantitatea rămasă
- A doua lege a lui Newton – accelerația unui obiect depinde de forțele care acționează asupra lui
În fiecare caz, o singură variabilă determină schimbarea. Asta o face „ordinară”.
Ecuații diferențiale parțiale (PDE)
O ecuație diferențială parțială implică o funcție a mai multor variabile independente și derivatele parțiale ale acesteia.
Să spunem că vreți să modelați cum se propagă căldura printr-o tijă metalică. Temperatura în orice punct depinde atât de poziția de-a lungul tijei, cât și de momentul în timp. Asta înseamnă două variabile independente: poziția x și timpul t. Când scrieți ecuația, apar derivate parțiale – una în raport cu x, una în raport cu t.
Aceasta este o PDE. Ecuația căldurii este unul dintre cele mai cunoscute exemple:
Exemplu de ecuație diferențială parțială
Unde u(x, t) este temperatura la poziția x și momentul t, α este difuzivitatea termică a materialului, ∂u/∂t reprezintă viteza de variație a temperaturii în timp, iar ∂²u/∂x² reprezintă cât de curbat este profilul temperaturii în spațiu. Ecuația spune că acolo unde curba temperaturii se încovoaie puternic, căldura se redistribuie rapid. Unde este plată, nu se întâmplă mare lucru.
PDE-urile apar oriunde un sistem variază în spațiu și timp:
- Distribuția căldurii – temperatura se schimbă atât în funcție de poziție, cât și de timp
- Propagarea undelor – undele sonore sau luminoase se propagă în spațiu în timp
- Dinamica fluidelor – viteza fluidului depinde de poziția din spațiul 3D și de timp
PDE-urile sunt mai greu de rezolvat decât ODE-urile. Soluții analitice există doar pentru forme specifice, iar metodele numerice sunt adesea singura cale practică.
Pentru majoritatea activităților în știința datelor, veți întâlni mai des ODE-uri. Dar PDE-urile apar în procesarea imaginilor, simulări fizice și unele arhitecturi de deep learning, deci este util să cunoașteți diferențele.
Ordinul și gradul ecuațiilor diferențiale
Fiecare ecuație diferențială are două proprietăți care indică nivelul ei de complexitate: ordinul și gradul.
Acestea determină ce metode de rezolvare se aplică, așa că trebuie să le identificați înainte de a încerca să rezolvați ceva.
Înțelegerea ordinului
Ordinul unei ecuații diferențiale este ordinul celei mai înalte derivate din ecuație.
Dacă cea mai înaltă derivată este una de ordinul întâi (dy/dx), este o ecuație de ordinul întâi. Dacă cea mai înaltă este o derivată de ordinul al doilea (d²y/dx²), este o ecuație de ordinul al doilea. Și așa mai departe.
Iată din nou ecuația de creștere a bacteriilor:
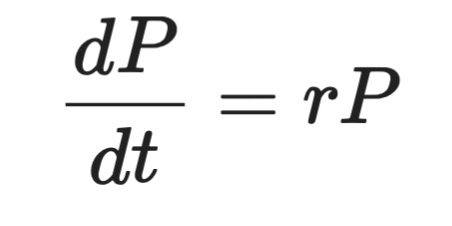
Ecuația de creștere a bacteriilor
Cea mai înaltă derivată aici este dP/dt – o derivată de ordinul întâi. Deci este o ODE de ordinul întâi.
Acum comparați cu ecuația care descrie oscilația unui pendul:
Ecuația pendulului în oscilație
Cea mai înaltă derivată este d²θ/dt² – o derivată de ordinul al doilea. Așadar, este o ODE de ordinul al doilea.
Un ordin mai înalt înseamnă mai multă complexitate. Ecuațiile de ordinul al doilea au nevoie de două condiții inițiale pentru a fi rezolvate, în loc de una. În practică, majoritatea sistemelor fizice – mișcare mecanică, circuite electrice, dinamică orbitală – sunt modelate cu ecuații de ordinul al doilea.
Înțelegerea gradului
Gradul unei ecuații diferențiale este puterea celei mai înalte derivate, odată ce ecuația este scrisă într-o formă polinomială (fără radicali sau fracții care implică derivate).
Luați această ecuație:
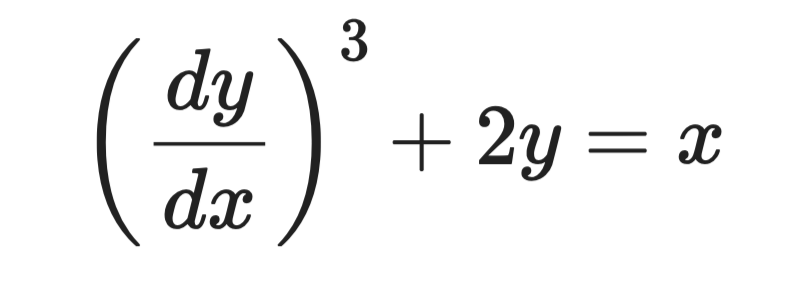
Exemplu de ecuație diferențială
Cea mai înaltă derivată este dy/dx, ridicată la puterea 3. Deci ordinul este 1, iar gradul este 3.
Acum luați aceasta:
Exemplu de ecuație diferențială (2)
Cea mai înaltă derivată este d²y/dx², la puterea 1. Gradul este 1, chiar dacă o derivată de ordin inferior apare cu o putere mai mare.
Gradul urmărește întotdeauna cea mai înaltă derivată, nu cea mai mare putere din ecuație.
Un caz-limită este când o ecuație conține termeni precum sin(dy/dx) sau e^(d²y/dx²). Atunci gradul este nedefinit – aceste forme nu pot fi exprimate ca polinoame în derivate.
Metode de rezolvare a ecuațiilor diferențiale
Nu există o singură metodă care să funcționeze pentru orice ecuație diferențială. Abordarea potrivită depinde de tipul, ordinul ecuației și de existența sau nu a unei soluții exacte.
În linii mari, aveți două categorii: metode analitice și metode numerice.
Metode analitice
Metodele analitice oferă o soluție exactă, în formă închisă – o formulă pe care o puteți evalua în orice punct. Sunt preferate când se aplică, deoarece rezultatul este precis și relevă ceva despre structura soluției.
Dar funcționează doar pentru forme specifice de ecuații. Când ecuația devine prea complexă, metodele analitice își ating limita.
Separarea variabilelor
Separarea variabilelor funcționează pentru ecuațiile în care puteți izola toți termenii care implică y de o parte și toți termenii care implică x (sau t) de cealaltă parte.
Luați această ODE de ordinul întâi:
Ecuație diferențială simplă
Pasul 1 – separați variabilele:
Soluție analitică (pasul 1)
Pasul 2 – integrați ambele părți:
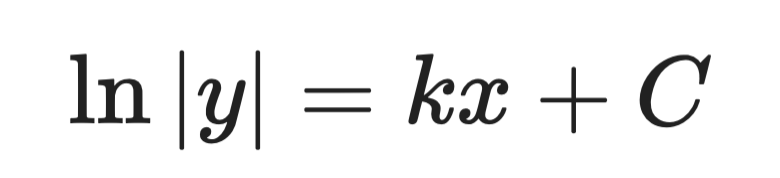
Soluție analitică (pasul 2)
Pasul 3 – rezolvați pentru y:
Soluție analitică (pasul 3)
Unde A este o constantă determinată de condițiile inițiale. Aceasta este soluția generală.
Aceeași formă ca ecuația de creștere a bacteriilor. Ne spune că populațiile – și orice altceva cu o rată de creștere proporțională cu dimensiunea – cresc exponențial.
Factori integranți
Factorii integranți tratează ODE-urile liniare de ordinul întâi de forma:
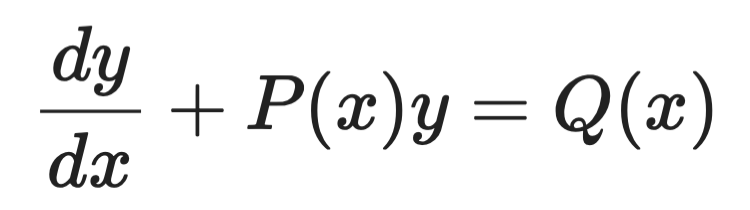
Exemplu factori integranți (1)
Ideea este să înmulțiți ambele părți cu o funcție aleasă cu grijă – factorul integrant μ(x) – care face ca partea stângă să devină o derivată perfectă pe care o puteți integra direct.
Factorul integrant este întotdeauna:
Exemplu factori integranți (2)
După înmulțire, ecuația devine:
Exemplu factori integranți (3)
Apoi integrați ambele părți și rezolvați pentru y. Partea stângă se simplifică întotdeauna elegant datorită modului în care a fost ales μ(x) – acesta este întregul scop al metodei.
Metode numerice
Majoritatea ecuațiilor diferențiale reale nu au soluții analitice curate. Metodele numerice aproximează soluția pas cu pas, calculând valori în puncte discrete.
Ele schimbă exactitatea pe generalitate. Iar în practică, adesea exact asta vă trebuie.
Metoda lui Euler
Metoda lui Euler este cea mai simplă abordare numerică. Ideea este să porniți dintr-un punct cunoscut, să folosiți derivata pentru a estima panta, să faceți un pas mic în acea direcție și să repetați.
Dată o ODE de ordinul întâi dy/dx = f(x, y) cu condiția inițială y(x₀) = y₀, fiecare pas arată așa:
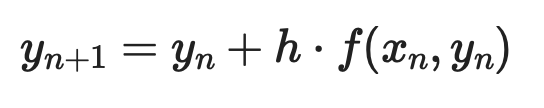
Exemplu metoda lui Euler (1)
Unde h este pasul. Pași mai mici înseamnă acuratețe mai bună – dar mai multă calcul.
Iată o implementare Python care rezolvă dy/dx = y cu y(0) = 1 (soluția exactă este y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Metoda lui Euler comparată cu soluția exactă
Diferența dintre cele două linii este eroarea de aproximare. Cu h=0.2, eroarea este mică la început, dar se acumulează pe parcursul pașilor – aceasta este principala slăbiciune a metodei lui Euler.
Metode Runge–Kutta
Metodele Runge–Kutta rezolvă problema erorilor acumulate prin eșantionarea pantei în mai multe puncte din cadrul fiecărui pas și luând o medie ponderată. Cea mai comună versiune este RK4 – metoda Runge–Kutta de ordinul al patrulea.
În loc de o singură estimare a pantei per pas, ca la Euler, RK4 calculează patru:
Exemplu metodă Runge–Kutta (1)
Apoi le combină:
Exemplu metodă Runge–Kutta (2)
În practică, nu implementați RK4 manual. Funcția solve_ivp din SciPy se ocupă de asta pentru dumneavoastră:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 comparat cu soluția exactă
Curba RK45 se suprapune aproape perfect peste soluția exactă. Același pas ca în exemplul cu Euler, dar acuratețe mult mai bună – aceasta este diferența pe care o aduce eșantionarea ponderată a pantei.
Pentru majoritatea activităților practice în Python, solve_ivp cu solverul implicit RK45 este alegerea de bază. Metoda lui Euler este utilă pentru a înțelege cum funcționează solverele numerice, dar nu ați folosi-o în producție.
Aplicații ale ecuațiilor diferențiale în știința datelor și învățarea automată
Inginerii folosesc ecuațiile diferențiale pentru a modela circuite electrice și sisteme mecanice. Biologii le folosesc pentru a urmări dinamica populațiilor și răspândirea bolilor. Fizicienii le folosesc pentru a descrie totul, de la transferul de căldură la mecanica cuantică.
Dar sunteți aici pentru știința datelor, așa că să trecem la subiect.
Învățare automată și optimizare
Cea mai directă legătură dintre ecuațiile diferențiale și ML este gradient descent – algoritmul din spatele antrenării aproape fiecărui model pe care îl veți construi.
Când antrenați un model, minimizați o funcție de pierdere L. Pentru asta, trebuie să știți cum se schimbă L când ajustați fiecare parametru. Acea rată de schimbare este o derivată. Când modelul are mai mulți parametri, calculați o derivată parțială pentru fiecare – iar împreună, ele formează gradientul.
Gradient descent folosește aceste derivate pentru a actualiza parametrii pas cu pas:
Gradient descent
Unde θ este parametrul, η este rata de învățare, iar ∂L/∂θ este derivata parțială a pierderii în raport cu acel parametru.
Iată un exemplu simplu în Python care potrivește o dreaptă pe date folosind gradient descent:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Gradient descent care potrivește o dreaptă pe date și curba pierderii pe iterații
Fiecare iterație deplasează parametrii în direcția care reduce pierderea. Derivatele parțiale vă spun care este acea direcție. Fără ele, gradient descent nu funcționează – și nici backpropagation în rețelele neuronale, care este doar regula lanțului aplicată repetat prin straturi.
Analiza seriilor de timp
Multe sisteme de serii de timp sunt dinamice – valoarea curentă depinde de valorile trecute și de viteza de schimbare. Ecuațiile diferențiale permit descrierea acestui comportament.
Filtrul Kalman, utilizat pe scară largă în urmărire și prognoză, se bazează pe un sistem de ecuații diferențiale care modelează cum evoluează în timp o stare ascunsă și cum se raportează observațiile zgomotoase la acea stare. Este folosit în sisteme GPS, finanțe și prognoza meteo.
Modelele ARIMA sunt folosite pentru prognoza seriilor de timp și se leagă de ecuațiile diferențiale prin conceptul de diferențiere. A lua diferențe de ordinul întâi sau al doilea ale unei serii de timp este o aproximare discretă a derivatelor de ordinul întâi și al doilea. Când diferențiați o serie pentru a o face staționară, întrebați: cum se schimbă această serie în timp?
Modelare statistică și regresie
Iată un aspect care îi surprinde pe mulți: rezolvarea unui sistem de ecuații diferențiale este o modalitate de a deduce coeficienții de regresie liniară.
Când potriviți un model de regresie liniară, minimizați suma pătratelor reziduurilor. Luați derivata parțială a acelei pierderi în raport cu fiecare coeficient, le egalați cu zero și rezolvați. Asta vă oferă ecuația normală:
Ecuația normală
Fiecare coeficient de regresie pe care l-ați calculat vreodată provine din egalarea la zero a unei derivate și rezolvare. Asta este analiză matematică – și același principiu stă la baza fiecărui model parametric pe care îl potriviți.
Pentru regresia logistică, funcția de pierdere nu este cuadratică, astfel că nu există soluție în formă închisă. Trebuie să folosiți metode iterative precum gradient descent, care, din nou, se bazează pe derivate parțiale la fiecare pas.
Legătura merge mai departe. Descompunerea QR, una dintre metodele numerice standard pentru rezolvarea ecuației normale, se bazează pe algebră liniară care intersectează direct modul în care sistemele de ecuații – inclusiv cele diferențiale – sunt rezolvate în practică.
Simularea sistemelor dinamice
Când trebuie să modelați cum evoluează un sistem în timp – iar o soluție analitică nu există – îl simulați numeric.
Acest lucru este comun în contexte de business și operațiuni. Rata de renunțare a clienților, nivelurile de stoc și dinamica lanțului de aprovizionare implică toate mărimi care se schimbă în funcție de starea curentă. Puteți scrie aceste relații ca ecuații diferențiale și le puteți simula cu solve_ivp.
Iată un exemplu care simulează un sistem simplu cerere–ofertă în care stocul I se epuizează cu o rată proporțională cu cererea D, iar cererea se modifică în timp:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)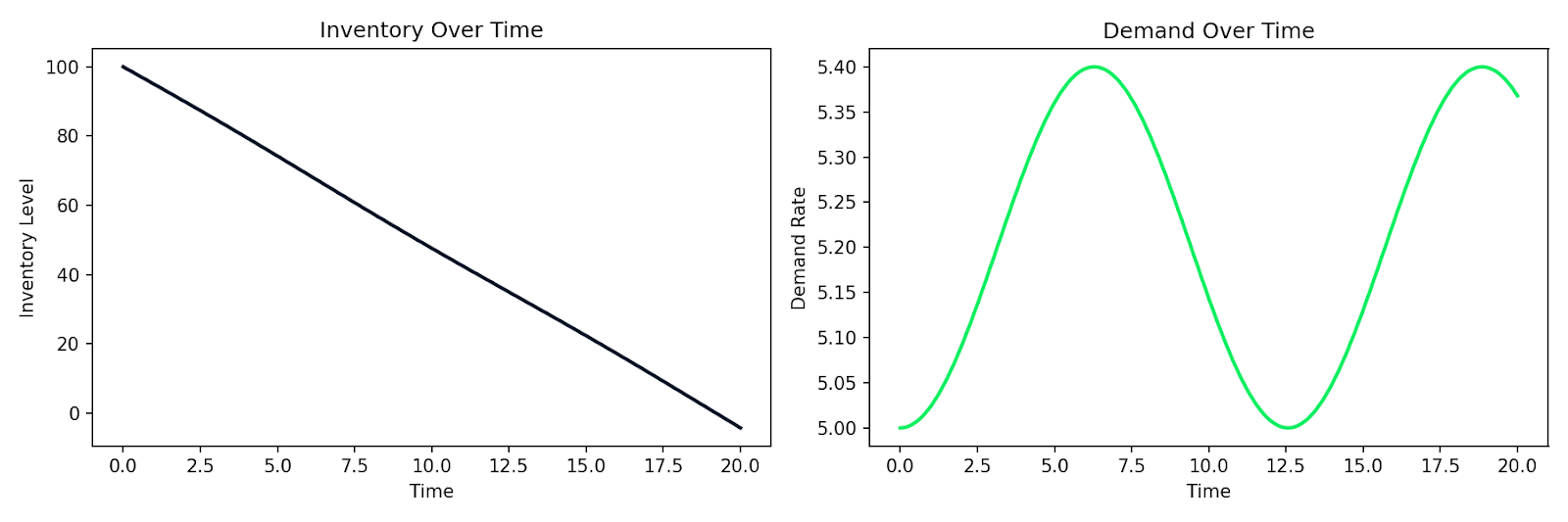
Simulare a epuizării stocurilor alături de o cerere fluctuantă în timp
Același tipar se aplică modelării comportamentului clienților, răspândirii epidemice într-o bază de utilizatori sau oricărui sistem în care rata de schimbare depinde de starea curentă. Notați relațiile, le dați unui solver numeric și obțineți o simulare.
Și aceasta este puterea practică a ecuațiilor diferențiale în știința datelor. Este un instrument direct pentru modelarea sistemelor care se schimbă.
Concluzie
În spatele gradient descent se află derivate parțiale. În spatele prognozării seriilor de timp se află sisteme dinamice. În spatele coeficienților de regresie liniară se află derivate aduse la zero. Trebuie doar să știți unde să priviți.
În acest articol, am explicat ce sunt ecuațiile diferențiale, diferența dintre ODE-uri și PDE-uri, cum ordinul și gradul le clasifică și principalele metode de rezolvare – atât analitice, cât și numerice. Apoi am analizat unde apar efectiv în știința datelor și în învățarea automată, zi de zi.
Aceasta este doar fundația. Dacă doriți să explorați mai multe subiecte de matematică, cursul Algebră liniară pentru știința datelor în R este un pas următor bun. Pentru exerciții practice aplicând aceste concepte la probleme reale, consultați cursul nostru Analist cantitativ în R.