Как ни странно, вы используете результаты дифференциальных уравнений каждый раз, когда обучаете нейронную сеть или даже подбираете регрессионную модель. Математика под капотом — это математический анализ, а дифференциальные уравнения находятся в самом его центре. Если вы когда-либо задумывались, почему работает градиентный спуск или как фильтр Калмана отслеживает движущийся объект, ответ — в дифференциальных уравнениях.
Дифференциальные уравнения позволяют моделировать, как что-то меняется во времени — а именно об этом и идет речь в data science. Поняв базовые идеи, вы начнете видеть их повсюду: в функциях потерь, которые минимизируете, в временных рядах, которые прогнозируете, и в моделях, которые симулируете.
В этой статье я расскажу, что такое дифференциальные уравнения, какие основные типы встречаются, как их решать и — что важнее всего — как они проявляются в реальной работе с данными и машинным обучением изо дня в день.
Что такое дифференциальные уравнения?
Дифференциальное уравнение — это уравнение, связывающее функцию с её собственными производными.
Проще говоря, производная показывает, насколько быстро что-то изменяется в данный момент. Дифференциальное уравнение утверждает, что скорость изменения некоторой величины зависит от самой величины, от времени или от того и другого вместе.
Допустим, вы моделируете популяцию бактерий. Чем больше бактерий, тем быстрее они размножаются. То есть скорость роста зависит от текущего размера популяции. Запишите это в виде уравнения — получите дифференциальное уравнение.
Формально это выглядит так:
Представление дифференциального уравнения
Где P — популяция, t — время, а r — скорость роста. Левая часть — это производная, то есть насколько быстро P меняется во времени. Правая часть говорит, что изменение пропорционально самой P.
Это ключевая идея, лежащая в основе каждого дифференциального уравнения, с которым вы столкнетесь.
Дифференциальные уравнения встречаются в физике, биологии, инженерии — везде, где система развивается во времени. Распространение тепла по металлическому стержню, колебание маятника, распространение вируса в популяции — всё это моделируется дифференциальными уравнениями.
Для специалистов по данным вы увидите дифференциальные уравнения в функциях потерь, градиентном спуске, моделях временных рядов, Neural ODE — везде под ними работают дифференциальные уравнения. Они не всегда видны явно, но они там есть.
Поняв их, вы получите более ясную ментальную модель того, почему и как работают инструменты, которыми вы пользуетесь каждый день.
История дифференциальных уравнений
В конце XVII века Исаак Ньютон и Готфрид Вильгельм Лейбниц независимо друг от друга разработали математический анализ. Оба искали способ описывать, как физические величины меняются во времени, и результатом стали дифференциальные уравнения. Ньютон использовал их для моделирования движения и гравитации. Лейбниц дал нам большую часть современной нотации, включая d/dt, которую вы видите в каждом учебнике по анализу.
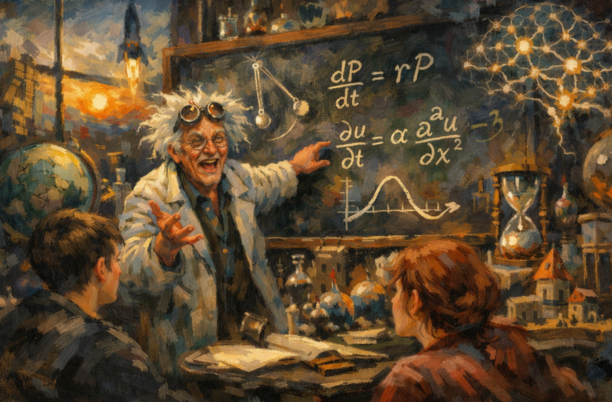
XVIII и XIX века принесли волну новых техник.
Леонард Эйлер разработал методы численного решения ОДУ — тот самый Эйлер, чьё «метод Эйлера» вы увидите ниже. Жозеф-Луи Лагранж и Пьер-Симон Лаплас развили теорию для более сложных систем. Жан Батист Жозеф Фурье предложил разложение функций в компоненты синуса и косинуса, что стало краеугольным камнем при решении уравнений в частных производных.
К XX веку дифференциальные уравнения были повсюду — от гидродинамики и квантовой механики до электротехники. Многие реальные уравнения не имели аккуратного аналитического решения. Тут на первый план вышли численные методы, а компьютеры сделали их практически применимыми в больших масштабах.
Сегодня область продолжает развиваться. Neural ordinary differential equations (Neural ODE) трактуют слои нейросети как непрерывный процесс, описываемый дифференциальным уравнением. Это недавняя разработка, стирающая грань между дип‑обучением и классической математикой. Это также одна из самых интересных областей современной ML‑исследовательской повестки.
Тем не менее ключевая идея остается прежней: смоделируйте, как вещи меняются — и вы сможете предсказать, куда они движутся.
Виды дифференциальных уравнений
Не все дифференциальные уравнения одинаковы. Первое, что нужно уметь, — различать их.
Главное деление — между обыкновенными дифференциальными уравнениями (ОДУ) и уравнениями в частных производных (УЧП). Различие сводится к числу независимых переменных, от которых зависит функция.
Обыкновенные дифференциальные уравнения (ОДУ)
Обыкновенное дифференциальное уравнение связывает функцию одной независимой переменной с её производными.
Пример с популяцией бактерий — это ОДУ. Популяция P зависит только от времени t — одной переменной. Поэтому в уравнении только обыкновенные производные, записываемые как dP/dt.
ОДУ — подходящий инструмент, когда система развивается вдоль одного измерения, обычно времени. Вот несколько классических примеров:
- Рост популяции — скорость изменения популяции зависит от её текущего размера
- Радиоактивный распад — скорость распада вещества зависит от того, сколько его осталось
- Второй закон Ньютона — ускорение тела зависит от действующих на него сил
Во всех случаях изменение задается одной переменной. Это и делает уравнение «обыкновенным».
Уравнения в частных производных (УЧП)
Уравнение в частных производных связывает функцию нескольких независимых переменных с её частными производными.
Скажем, вы хотите смоделировать, как тепло распространяется по металлическому стержню. Температура в любой точке зависит и от положения вдоль стержня, и от времени. Это две независимые переменные: положение x и время t. Записав уравнение, вы получите частные производные — по x и по t.
Это и есть УЧП. Уравнение теплопроводности — один из самых известных примеров:
Пример уравнения в частных производных
Где u(x, t) — температура в точке x и момент времени t, α — температуропроводность материала, ∂u/∂t — скорость изменения температуры во времени, а ∂²u/∂x² — кривизна температурного профиля в пространстве. Уравнение говорит, что там, где кривая температуры резко изгибается, тепло перераспределяется быстрее. Где она плоская — мало что происходит.
УЧП появляются везде, где система варьируется в пространстве и времени:
- Распределение тепла — температура меняется по положению и времени
- Распространение волн — звуковые или световые волны распространяются в пространстве во времени
- Гидродинамика — скорость потока зависит от положения в 3D‑пространстве и времени
УЧП сложнее решать, чем ОДУ. Аналитические решения существуют лишь для частных форм, и часто единственно практичный путь — численные методы.
В большинстве задач data science вы чаще столкнетесь с ОДУ. Но УЧП появляются в обработке изображений, физических симуляциях и некоторых архитектурах глубокого обучения, поэтому важно понимать различия.
Порядок и степень дифференциальных уравнений
У каждого дифференциального уравнения есть два свойства, определяющие его сложность: порядок и степень.
Они определяют применимые методы решения, поэтому их нужно уметь определять до начала решения.
Понимание порядка
Порядок дифференциального уравнения — это порядок наивысшей производной в уравнении.
Если наивысшая производная — первая (dy/dx), это уравнение первого порядка. Если наивысшая — вторая (d²y/dx²), это уравнение второго порядка. И так далее.
Вот уравнение роста бактерий из предыдущего раздела:
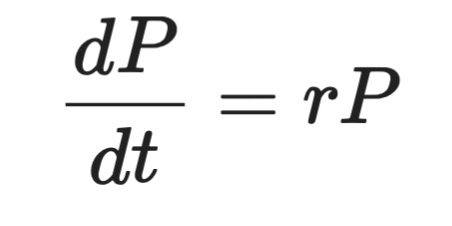
Уравнение роста бактерий
Наивысшая производная здесь — dP/dt — первая. Значит, это ОДУ первого порядка.
Теперь сравните с уравнением, описывающим колебания маятника:
Уравнение колеблющегося маятника
Наивысшая производная — d²θ/dt² — вторая. Значит, это ОДУ второго порядка.
Более высокий порядок означает большую сложность. Для уравнений второго порядка нужно две начальные условия, а не одно. На практике большинство физических систем — механическое движение, электрические цепи, орбитальная динамика — моделируются уравнениями второго порядка.
Понимание степени
Степень дифференциального уравнения — это показатель степени наивысшей по порядку производной после приведения уравнения к полиномиальному виду (без корней и дробей, содержащих производные).
Рассмотрим уравнение:
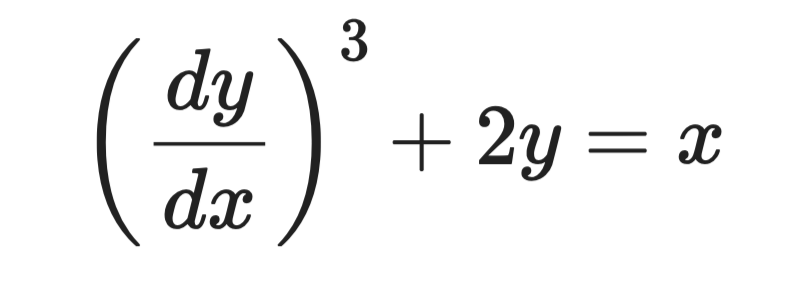
Пример дифференциального уравнения
Наивысшая производная — dy/dx, и она возведена в степень 3. Значит, порядок — 1, а степень — 3.
А теперь это:
Пример дифференциального уравнения (2)
Наивысшая производная — d²y/dx², возведенная в степень 1. Степень равна 1, хотя производная более низкого порядка встречается с большей степенью.
Степень всегда соотносится с наивысшей по порядку производной, а не с наибольшим показателем степени в уравнении.
Исключение — если в уравнении есть члены вида sin(dy/dx) или e^(d²y/dx²). Тогда степень не определена — такие формы нельзя выразить как полиномы от производных.
Методы решения дифференциальных уравнений
Нет единого метода, который работает для каждого дифференциального уравнения. Подход зависит от типа и порядка уравнения и от того, существует ли вообще точное решение.
В целом есть две категории: аналитические методы и численные методы.
Аналитические методы
Аналитические методы дают точное, замкнутое решение — формулу, которую можно вычислить в любой точке. Их предпочитают, когда они применимы, потому что результат точен и раскрывает структуру решения.
Но они работают только для специфических форм уравнений. Когда уравнение слишком сложное, аналитические методы упираются в стену.
Разделение переменных
Метод разделения переменных применим к уравнениям, где можно изолировать все члены с y по одну сторону и все члены с x (или t) — по другую.
Рассмотрим ОДУ первого порядка:
Простое дифференциальное уравнение
Шаг 1 — разделите переменные:
Аналитическое решение (шаг 1)
Шаг 2 — проинтегрируйте обе части:
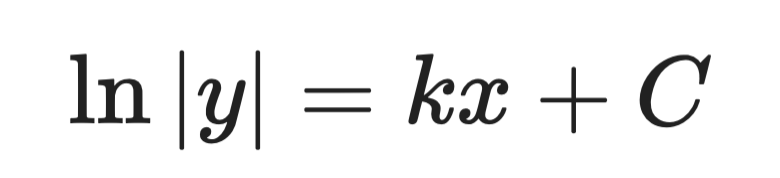
Аналитическое решение (шаг 2)
Шаг 3 — выразите y:
Аналитическое решение (шаг 3)
Где A — константа, задаваемая начальными условиями. Это общее решение.
Это та же форма, что и у уравнения роста бактерий. Она говорит, что популяции — и всё, где скорость роста пропорциональна размеру — растут экспоненциально.
Интегрирующие множители
Интегрирующие множители применимы к линейным ОДУ первого порядка вида:
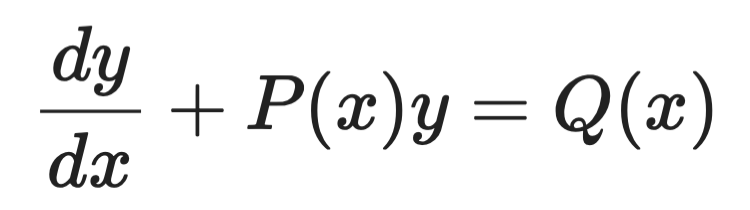
Пример интегрирующих множителей (1)
Идея — умножить обе части на специально подобранную функцию — интегрирующий множитель μ(x) — так, чтобы левая часть стала полной производной, которую можно напрямую проинтегрировать.
Интегрирующий множитель всегда равен:
Пример интегрирующих множителей (2)
После умножения уравнение принимает вид:
Пример интегрирующих множителей (3)
Затем проинтегрируйте обе части и выразите y. Левая часть всегда аккуратно «схлопывается» благодаря тому, как выбран μ(x) — в этом и суть метода.
Численные методы
Большинство реальных дифференциальных уравнений не имеют аккуратных аналитических решений. Численные методы приближенно находят решение пошагово, вычисляя значения в дискретных точках.
Они жертвуют точностью ради универсальности. И на практике это часто именно то, что нужно.
Метод Эйлера
Метод Эйлера — самый простой численный подход. Идея: стартовать из известной точки, использовать производную для оценки наклона, сделать маленький шаг в этом направлении и повторять.
Для ОДУ первого порядка dy/dx = f(x, y) с начальным условием y(x₀) = y₀ каждый шаг выглядит так:
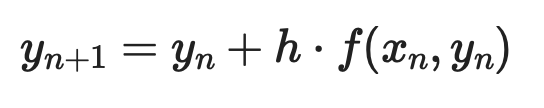
Пример метода Эйлера (1)
Где h — шаг. Меньший шаг даёт большую точность — но требует больше вычислений.
Вот реализация на Python для уравнения dy/dx = y с y(0) = 1 (точное решение — y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Метод Эйлера по сравнению с точным решением
Зазор между двумя линиями — это ошибка аппроксимации. При h=0.2 ошибка поначалу мала, но накапливается с шагами — это главный недостаток метода Эйлера.
Методы Рунге — Кутты
Методы Рунге — Кутты исправляют проблему накопления ошибки, оценивая наклон в нескольких точках внутри шага и беря взвешенное среднее. Самая распространенная версия — RK4 — метод Рунге — Кутты четвертого порядка.
Вместо одной оценки наклона на шаг, как в методе Эйлера, RK4 вычисляет четыре:
Пример метода Рунге — Кутты (1)
Затем объединяет их:
Пример метода Рунге — Кутты (2)
На практике RK4 вы вручную не реализуете. За вас это делает solve_ivp из SciPy:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 по сравнению с точным решением
Линия RK45 почти полностью совпадает с точным решением. Тот же шаг, что и в примере с Эйлером, но точность значительно выше — это эффект взвешенного усреднения наклонов.
В большинстве практических задач на Python ваш инструмент по умолчанию — solve_ivp с солвером RK45. Метод Эйлера полезен, чтобы понять, как работают численные решатели, но в продакшене его обычно не используют.
Применения дифференциальных уравнений в data science и машинном обучении
Инженеры используют дифференциальные уравнения для моделирования электрических цепей и механических систем. Биологи — для анализа динамики популяций и распространения заболеваний. Физики — для описания всего: от теплообмена до квантовой механики.
Но вы здесь ради data science, так что перейдём к делу.
Машинное обучение и оптимизация
Самая прямая связь между дифференциальными уравнениями и ML — это градиентный спуск — алгоритм, лежащий в основе обучения почти каждой модели.
Обучая модель, вы минимизируете функцию потерь L. Чтобы это сделать, нужно знать, как L изменяется при изменении каждого параметра. Эта скорость изменения — производная. Когда в модели несколько параметров, вы считаете частную производную по каждому — вместе они образуют градиент.
Градиентный спуск использует эти производные, чтобы обновлять параметры пошагово:
Градиентный спуск
Где θ — параметр, η — скорость обучения, а ∂L/∂θ — частная производная функции потерь по этому параметру.
Вот простой пример на Python — подгонка прямой к данным с помощью градиентного спуска:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Градиентный спуск подгоняет прямую к данным и кривая потерь по итерациям
Каждая итерация сдвигает параметры в сторону уменьшения потерь. Частные производные подсказывают, в каком направлении двигаться. Без них градиентный спуск не работает — как и обратное распространение ошибки в нейросетях, которое по сути многократное применение правила цепочки через слои.
Анализ временных рядов
Многие системы временных рядов динамические — текущее значение зависит от прошлых и от скоростей изменений. Дифференциальные уравнения позволяют это описать.
Широко используемый для отслеживания и прогнозирования фильтр Калмана основан на системе дифференциальных уравнений, моделирующих, как скрытое состояние эволюционирует во времени и как зашумленные наблюдения с ним связаны. Его применяют в GPS‑системах, финансах и метеопрогнозировании.
Модели ARIMA используются для прогнозирования временных рядов и связаны с дифференциальными уравнениями через идею дифференцирования. Взятие первых или вторых разностей ряда — это дискретная аппроксимация первых и вторых производных. Когда вы дифференцируете ряд, чтобы сделать его стационарным, вы фактически спрашиваете: как этот ряд меняется во времени?
Статистическое моделирование и регрессия
Вот что часто удивляет: вывести коэффициенты линейной регрессии можно, решив систему дифференциальных уравнений.
При подгонке линейной регрессии вы минимизируете сумму квадратов остатков. Берете частные производные этой функции потерь по каждому коэффициенту, приравниваете к нулю и решаете. Так получается нормальное уравнение:
Нормальное уравнение
Каждый коэффициент регрессии, который вы когда-либо считали, получается из условия равенства производной нулю и решения системы. Это математический анализ — та же идея лежит в основе любой параметрической модели.
Для логистической регрессии функция потерь не является квадратичной, поэтому замкнутого решения нет. Приходится использовать итерационные методы, такие как градиентный спуск, который снова и снова опирается на частные производные.
Связь ещё глубже. QR‑разложение, один из стандартных численных методов решения нормального уравнения, основано на линейной алгебре, которая напрямую пересекается с практикой решения систем уравнений — в том числе дифференциальных.
Симуляция динамических систем
Если нужно смоделировать, как система меняется во времени, а аналитического решения нет — используйте численную симуляцию.
Это часто встречается в бизнесе и операционной деятельности. Отток клиентов, уровни запасов, динамика цепочек поставок — всё это величины, меняющиеся в зависимости от текущего состояния. Эти связи можно записать как дифференциальные уравнения и промоделировать с помощью solve_ivp.
Вот пример симуляции простой системы спроса‑предложения, где запас I убывает со скоростью, пропорциональной спросу D, а спрос со временем меняется:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)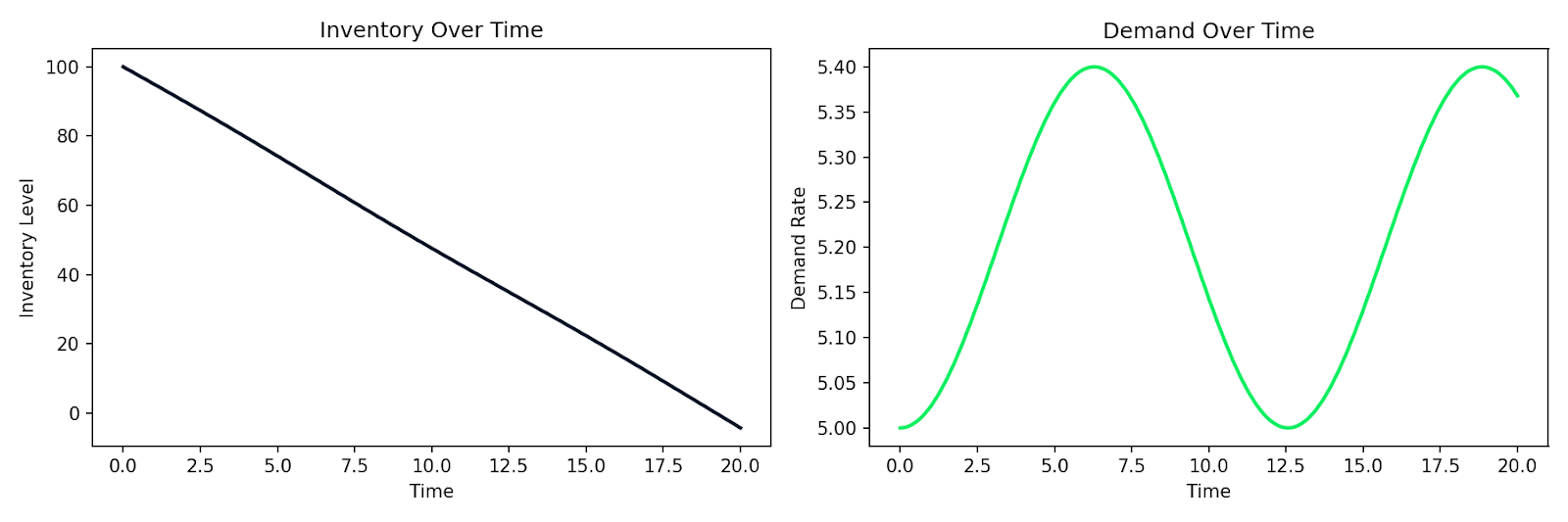
Симуляция уменьшения запасов на фоне колеблющегося спроса во времени
Тот же шаблон применим к моделированию поведения клиентов, распространению эпидемии в пользовательской базе или любой системе, где скорость изменений зависит от текущего состояния. Вы записываете связи, передаете их численному решателю — и получаете симуляцию.
В этом и состоит практическая сила дифференциальных уравнений в data science. Это прямой инструмент для моделирования систем, которые меняются.
Заключение
За градиентным спуском стоят частные производные. За прогнозированием временных рядов — динамические системы. За коэффициентами линейной регрессии — производные, приравненные нулю. Нужно лишь знать, где это увидеть.
В этой статье я объяснил, что такое дифференциальные уравнения, разницу между ОДУ и УЧП, как порядок и степень их классифицируют, и основные методы решения — аналитические и численные. Затем мы посмотрели, где они на деле встречаются в data science и машинном обучении каждый день.
Это лишь фундамент. Если хотите продолжить изучение математики, курс Linear Algebra for Data Science in R — хороший следующий шаг. А для практики применения этих идей к реальным задачам посмотрите наш курс Quantitative Analyst in R.