事实证明,每当您训练一个神经网络,甚至只是拟合一个回归模型时,您都在使用微分方程的成果。其底层数学是微积分,而微分方程正处在其核心位置。如果您曾好奇梯度下降为何有效,或卡尔曼滤波如何跟踪运动目标,答案都在微分方程中。
微分方程让您能够建模事物“随时间如何变化”——而这正是数据科学的本质。一旦理解了核心思想,您会在各处看到它们:在您最小化的损失函数里、在您预测的时间序列里、以及在您运行的模拟中。
本文将带您了解什么是微分方程、常见的主要类型、如何求解它们,以及——最重要的——它们如何在数据科学与机器学习的日常工作中出现。
什么是微分方程?
微分方程是将一个函数与其自身导数关联起来的方程。
通俗地说,导数告诉您在某一时刻某个量变化的速度。微分方程则说明,一个量的变化率取决于该量本身,或取决于时间,或两者皆有。
假设您在建模细菌种群。细菌越多,繁殖越快。因此增长率取决于当前的种群规模。将其写成方程,您就得到一个微分方程。
形式上,它看起来像这样:
微分方程表示
其中 P 是种群数量,t 是时间,r 是增长率。左侧是导数——即 P 随时间变化的快慢。右侧表示这种变化与 P 本身成正比。
这就是您会遇到的每一个微分方程背后的核心思想。
微分方程广泛出现在物理学、生物学和工程学中——凡是系统随时间演化的地方:热在金属棒中的扩散、摆的摆动、病毒在人群中的传播。所有这些都用微分方程建模。
对数据科学家来说,您会在损失函数、梯度下降、时间序列模型、神经 ODE 中看到微分方程——它们的底层都在运行微分方程。您不一定能显式地看到它们,但它们的确存在。
理解它们之后,您会更清晰地把握日常工具为何以及如何有效工作。
微分方程的历史
17 世纪末,艾萨克·牛顿与戈特弗里德·威廉·莱布尼茨分别独立发展了微积分。二者都需要一种方式来描述物理量如何随时间变化,微分方程由此产生。牛顿用它来建模运动与引力。莱布尼茨则为我们提供了沿用至今的大量记号,包括您在每本微积分教材里都会看到的 d/dt。
18 与 19 世纪带来了新技术的浪潮。
莱昂哈德·欧拉发展了数值求解常微分方程的方法——这与您稍后会看到的欧拉法出自同一位欧拉。约瑟夫-路易·拉格朗日与皮埃尔-西蒙·拉普拉斯将理论扩展到更复杂的系统。让-巴蒂斯特·约瑟夫·傅里叶提出了将函数分解为正弦与余弦分量的方法,成为求解偏微分方程的基石。
到了 20 世纪,微分方程无处不在:从流体力学、量子力学到电气工程。许多现实世界中的方程没有整洁的解析解。数值方法因此接棒,而计算机让它们在规模上变得可行。
如今,该领域仍在不断前进。神经常微分方程(Neural ODE)将神经网络的层视为由微分方程描述的连续过程。这一近期发展模糊了深度学习与经典数学之间的界限,也是现代机器学习研究中颇为令人兴奋的方向之一。
不过,核心思想始终如一:建模事物如何变化,您就能预测它们将走向何处。
微分方程的类型
并非所有微分方程都相同。首先需要学会如何区分它们。
主要的分野在于常微分方程(ODE)与偏微分方程(PDE)之间。差别归结为函数依赖多少个自变量。
常微分方程(ODE)
常微分方程涉及一个关于单一自变量的函数及其导数。
前面的细菌种群示例就是一个 ODE。种群 P 只依赖时间 t——一个变量。因此方程只包含常规导数,写作 dP/dt。
当您的系统沿着单一维度(通常是时间)演化时,ODE 就是合适的工具。以下是几个经典示例:
- 种群增长——种群变化率取决于当前种群规模
- 放射性衰变——物质衰变速率取决于其剩余量
- 牛顿第二定律——物体的加速度取决于作用在其上的力
在每种情形下,都是一个变量驱动变化。这正是“常微分”的由来。
偏微分方程(PDE)
偏微分方程涉及一个关于多个自变量的函数及其偏导数。
比如您想建模热如何在金属棒中传播。任一点的温度取决于棒上位置与时间。这是两个自变量:位置 x 与时间 t。写出方程后,您会得到偏导数——一个关于 x,一个关于 t。
这就是 PDE。热传导方程是最著名的例子之一:
偏微分方程示例
其中 u(x, t) 是位置 x 与时间 t 下的温度,α 是材料的热扩散率,∂u/∂t 表示温度随时间变化的快慢,∂²u/∂x² 表示温度在空间上的曲率。该方程表明:在温度曲线弯曲剧烈处,热量重新分布得更快;在曲线平缓处,变化不大。
PDE 出现在系统随空间与时间共同变化的场景中:
- 热分布——温度随位置与时间共同变化
- 波的传播——声波或光波随时间在空间中扩散
- 流体力学——流体速度取决于三维空间中的位置与时间
PDE 比 ODE 更难求解。解析解只在特定形式下存在,数值方法往往是唯一可行之道。
在大多数数据科学工作中,您更常遇到 ODE。但 PDE 会出现在图像处理、物理仿真以及部分深度学习架构中,因此需要了解它们的差异。
微分方程的阶与次
每个微分方程都有两个决定其复杂度的属性:阶(order)与次(degree)。
它们决定了适用的求解方法,因此在尝试求解之前,您需要先识别它们。
理解“阶”
微分方程的阶是方程中最高阶导数的阶数。
如果最高导数是一阶导数(dy/dx),那么它是一条一阶方程;如果最高导数是二阶导数(d²y/dx²),则为二阶方程;以此类推。
以下是前面的细菌增长方程:
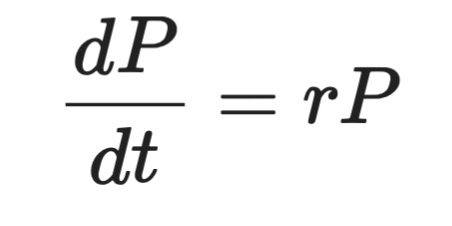
细菌增长方程
这里的最高导数是 dP/dt——一阶导数。因此这是一个一阶 ODE。
再看看描述摆动摆的方程:
摆动方程
最高导数是 d²θ/dt²——二阶导数。这使它成为一个二阶 ODE。
阶越高,复杂度越大。二阶方程需要两个初始条件才能求解,而不是一个。实践中,大多数物理系统——机械运动、电路、轨道动力学——都用二阶方程建模。
理解“次”
微分方程的次是指在方程写成多项式形式(不含关于导数的根式或分式)后,最高阶导数的幂次。
看这个方程:
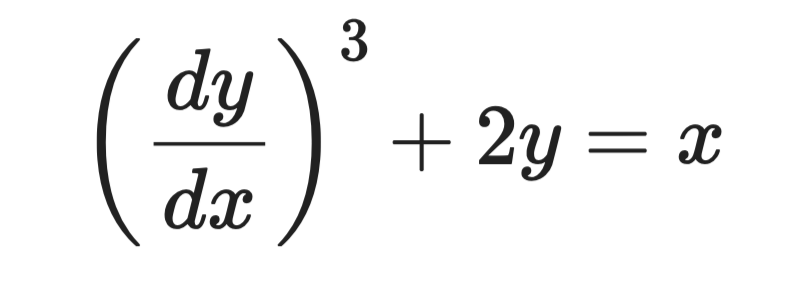
示例微分方程
最高导数是 dy/dx,其指数为 3。因此阶为 1,次为 3。
再看这个:
示例微分方程(2)
最高阶导数是 d²y/dx²,指数为 1。即便较低阶导数以更高幂出现,次仍为 1。
“次”始终以最高阶导数为准,而非方程中出现的最高幂。
一个边界情况是,若方程包含如 sin(dy/dx) 或 e^(d²y/dx²) 之类的项,则“次”未定义——这些形式无法表示为导数的多项式。
求解微分方程的方法
没有一种方法能适用于所有微分方程。合适的思路取决于方程的类型、阶数,以及是否存在精确解。
总体而言,您可以分为两大类:解析方法与数值方法。
解析方法
解析方法给出精确的闭式解——一个可以在任意点计算的公式。若适用,它们是首选,因为结果精确且能揭示解的结构。
但它们只适用于特定形式的方程。一旦方程变得过于复杂,解析方法就会碰壁。
变量分离法
变量分离法适用于可以把所有涉及 y 的项放在一侧、所有涉及 x(或 t)的项放在另一侧的方程。
看这条一阶 ODE:
简单微分方程
第 1 步——分离变量:
解析解(第 1 步)
第 2 步——两侧积分:
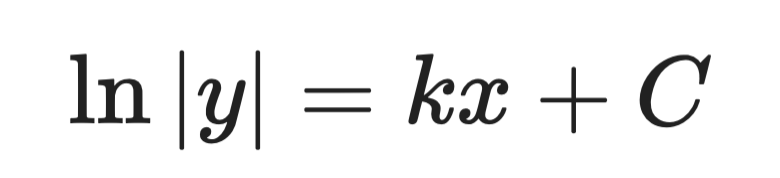
解析解(第 2 步)
第 3 步——解出 y:
解析解(第 3 步)
其中 A 是由初始条件确定的常数。这就是通解。
这与细菌增长方程的形式相同。它告诉您,种群——以及任何增长率与其规模成正比的事物——呈指数增长。
积分因子法
积分因子法用于这类一阶线性 ODE:
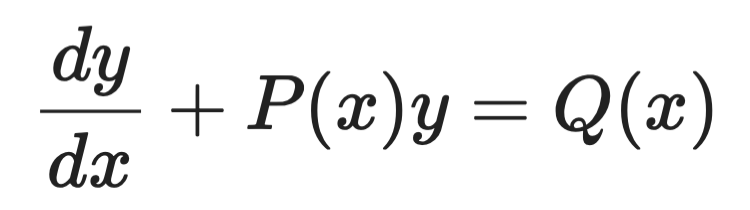
积分因子示例(1)
思路是将方程两侧同乘以一个精心选择的函数——积分因子 μ(x),使得左侧成为一个可直接积分的完全导数。
积分因子恒为:
积分因子示例(2)
乘入后,方程变为:
积分因子示例(3)
随后对两侧积分并解出 y。左侧总能因 μ(x) 的选择而整齐地折叠——这正是该方法的要点。
数值方法
大多数现实世界的微分方程没有整洁的解析解。数值方法通过逐步近似,在离散点上计算取值来逼近解。
它们用通用性换取精确性。而在实践中,这往往正是您所需要的。
欧拉法
欧拉法是最简单的数值方法。思路是从一个已知点出发,用导数估计斜率,沿该方向迈出一个小步,再重复这一过程。
给定一阶 ODE dy/dx = f(x, y) 与初始条件 y(x₀) = y₀,每一步如下:
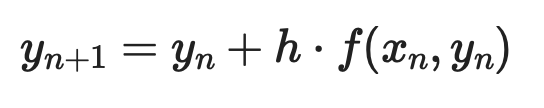
欧拉法示例(1)
其中 h 为步长。步长越小,精度越高——但计算也越多。
以下是用 Python 求解 dy/dx = y 且 y(0) = 1 的实现(精确解为 y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
欧拉法与精确解对比
两条曲线之间的间隙就是近似误差。取 h=0.2 时,误差一开始很小,但会在步进中累计——这是欧拉法的主要弱点。
龙格-库塔方法
龙格-库塔方法通过在每一步内对多个点的斜率取样并加权平均,修正了那种误差累积的问题。最常见的版本是RK4——四阶龙格-库塔方法。
与欧拉法每步只用一个斜率估计不同,RK4 会计算四个:
龙格-库塔方法示例(1)
然后将它们组合:
龙格-库塔方法示例(2)
在实践中,您无需手写 RK4。SciPy 的 solve_ivp 会为您处理:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 与精确解对比
RK45 曲线几乎与精确解完全重合。与欧拉示例相同步长,但精度大幅提升——这就是对斜率加权取样带来的差异。
在 Python 的大多数实际工作中,带有默认 RK45 求解器的 solve_ivp 是您的首选。欧拉法有助于理解数值求解器的工作原理,但不建议在生产中使用。
微分方程在数据科学与机器学习中的应用
工程师用微分方程建模电路与机械系统。生物学家用它们跟踪种群动态与疾病传播。物理学家用它们描述从热传导到量子力学的一切。
但您来此是为了数据科学,让我们进入正题。
机器学习与优化
微分方程与机器学习最直接的联系是梯度下降——几乎每个您会训练的模型背后的算法。
训练模型时,您要最小化损失函数 L。为此,您需要知道当调整每个参数时 L 如何变化。这个变化率就是导数。当模型有多个参数时,您为每个参数计算一个偏导数——它们共同组成了梯度。
梯度下降使用这些导数逐步更新参数:
梯度下降
其中 θ 是参数,η 是学习率,∂L/∂θ 是损失对该参数的偏导数。
以下是用 Python 通过梯度下降对数据拟合直线的简单示例:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
梯度下降对数据拟合直线及损失随迭代的变化曲线
每次迭代都会将参数朝着降低损失的方向推进。偏导数告诉您方向所在。没有它们,梯度下降就无法工作——而反向传播同样如此,后者只是将链式法则在各层中反复应用。
时间序列分析
许多时间序列系统具有动态特性——当前值取决于过去的取值以及变化的速度。微分方程能对此加以刻画。
卡尔曼滤波在跟踪与预测中被广泛使用,其建立在一组微分方程之上,这些方程刻画了隐含状态如何随时间演化,以及带噪观测如何与该状态相关。它被用于 GPS、金融与天气预报等领域。
ARIMA 模型用于时间序列预测,并通过差分的概念与微分方程相关联。对时间序列取一阶或二阶差分,是对一阶与二阶导数的离散近似。当您对序列做差分以使其平稳时,您在问的其实是:该序列随时间如何变化?
统计建模与回归
有一件事常让人意外:通过求解一组微分方程可以推出线性回归系数。
拟合线性回归模型时,您在最小化残差平方和。对每个系数分别求该损失的偏导数、令其为零并求解。这会得到正规方程:
正规方程
您曾经计算过的每一个回归系数,都是通过令某个导数为零并求解而来。这就是微积分——也是每个参数化模型背后的同一原理。
对于逻辑回归,损失函数并非二次型,因此没有闭式解。您必须使用迭代方法,如梯度下降,而这同样在每一步都依赖偏导数。
联系还不止于此。QR 分解是求解正规方程的标准数值方法之一,其基于的线性代数与解方程组(包括微分方程组)的实际做法直接相交。
动态系统的仿真
当您需要建模一个系统如何随时间演化、而解析解不存在时,您会选择数值仿真。
这在商业与运营场景中很常见。客户流失、库存水平与供应链动态都涉及依据当前状态而变化的量。您可以将这些关系写成微分方程,并用 solve_ivp 进行仿真。
以下示例仿真一个简单的供需系统:库存 I 以与需求 D 成正比的速率消耗,且需求随时间变化:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)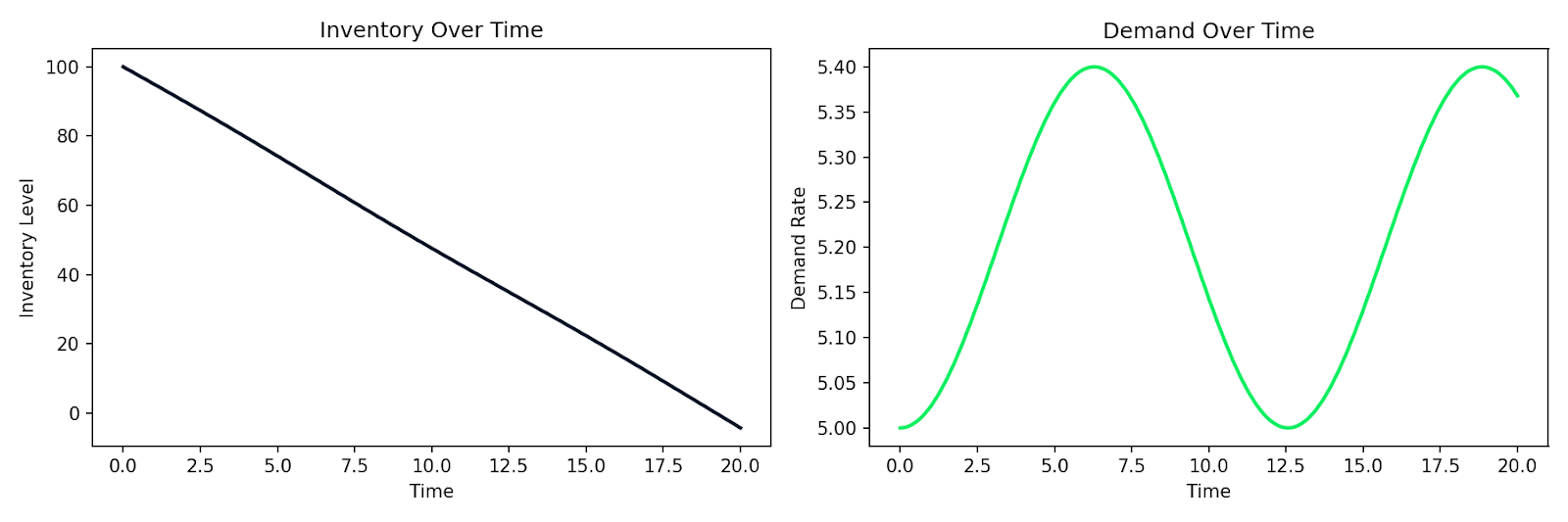
随时间波动的需求与库存消耗的仿真
相同的模式也适用于客户行为建模、用户群体中的流行病传播,或任何变化率取决于当前状态的系统。您写下这些关系,交给数值求解器,便能获得一份仿真结果。
这就是微分方程在数据科学中的实用价值:它是一种直接建模变化系统的工具。
结语
梯度下降背后是偏导数;时间序列预测背后是动态系统;线性回归系数背后是令导数为零的解法。您只需知道该从何处着眼。
本文介绍了什么是微分方程、ODE 与 PDE 的区别、如何用阶与次对其分类,以及解析与数值两类主要求解方法。随后我们查看了它们在数据科学与机器学习日常工作中的实际身影。
这只是基础。如果您想继续探索更多数学主题,Linear Algebra for Data Science in R 课程是不错的下一步。若想将这些概念动手应用到真实数据问题,欢迎查看我们的 Quantitative Analyst in R 课程。