En réalité, vous exploitez les résultats des équations différentielles chaque fois que vous entraînez un réseau de neurones ou même que vous ajustez un modèle de régression. Les mathématiques sous-jacentes relèvent de l'analyse, et les équations différentielles en sont au cœur. Si vous vous êtes déjà demandé pourquoi la descente de gradient fonctionne, ou comment un filtre de Kalman suit un objet en mouvement, la réponse se trouve dans les équations différentielles.
Les équations différentielles vous permettent de modéliser comment les choses évoluent dans le temps — et c'est précisément l'objet de la data science. Une fois les idées clés comprises, vous les verrez partout : dans les fonctions de perte que vous minimisez, les séries temporelles que vous anticipez et les simulations que vous exécutez.
Dans cet article, je vous présente ce que sont les équations différentielles, les principaux types, comment les résoudre et — surtout — comment elles apparaissent concrètement au quotidien en data science et en machine learning.
Qu'est-ce qu'une équation différentielle ?
Une équation différentielle est une équation qui relie une fonction à ses propres dérivées.
En termes simples, une dérivée indique la vitesse à laquelle quelque chose change à un instant donné. Une équation différentielle affirme que le taux de variation d'une grandeur dépend de la grandeur elle-même, du temps, ou des deux.
Supposons que vous modélisiez une population de bactéries. Plus il y a de bactéries, plus elles se reproduisent vite. Le taux de croissance dépend donc de la taille actuelle de la population. Écrivez cela sous forme d'équation : vous obtenez une équation différentielle.
Formellement, cela s'écrit ainsi :
Représentation d'une équation différentielle
Où P est la population, t le temps, et r le taux de croissance. Le membre de gauche est la dérivée — la vitesse à laquelle P évolue dans le temps. Le membre de droite dit que cette variation est proportionnelle à P lui-même.
C'est l'idée clé derrière toutes les équations différentielles que vous rencontrerez.
On les retrouve partout en physique, biologie et ingénierie — partout où un système évolue dans le temps. La diffusion de la chaleur dans une barre métallique, l'oscillation d'un pendule, la propagation d'un virus dans une population : tout cela se modélise avec des équations différentielles.
Pour un data scientist, vous croiserez des équations différentielles dans les fonctions de perte, la descente de gradient, les modèles de séries temporelles, les Neural ODEs — elles sont partout en arrière-plan. Vous ne les voyez pas toujours explicitement, mais elles sont bien là.
En les comprenant, vous aurez un modèle mental plus clair du pourquoi et du comment des outils que vous utilisez au quotidien.
L'histoire des équations différentielles
À la fin du XVIIe siècle, Isaac Newton et Gottfried Wilhelm Leibniz développent indépendamment le calcul infinitésimal. Tous deux avaient besoin de décrire comment les grandeurs physiques évoluent dans le temps ; les équations différentielles en sont issues. Newton les utilise pour modéliser le mouvement et la gravitation. Leibniz nous a légué une grande partie de la notation encore employée aujourd'hui, y compris le d/dt présent dans tout manuel d'analyse.
Les XVIIIe et XIXe siècles voient l'émergence de nombreuses techniques.
Leonhard Euler met au point des méthodes de résolution numérique des EDO — le même Euler de la « méthode d'Euler » que nous verrons plus loin. Joseph-Louis Lagrange et Pierre-Simon Laplace étendent la théorie à des systèmes plus complexes. Jean-Baptiste Joseph Fourier introduit une décomposition des fonctions en composantes sinus et cosinus, devenue une pierre angulaire de la résolution des équations aux dérivées partielles.
Au XXe siècle, les équations différentielles s'imposent partout, de la dynamique des fluides à la mécanique quantique en passant par l'électrotechnique. Nombre d'équations réelles n'ont pas de solution analytique simple. Les méthodes numériques prennent alors le relais, et l'informatique les rend praticables à grande échelle.
Aujourd'hui, le domaine continue d'évoluer. Les Neural ordinary differential equations (Neural ODEs) traitent les couches d'un réseau de neurones comme un processus continu décrit par une équation différentielle. Un développement récent qui brouille la frontière entre deep learning et mathématiques classiques. C'est aussi l'un des sujets les plus enthousiasmants de la recherche ML actuelle.
Pour autant, l'idée centrale reste la même : modélisez le changement et vous pourrez anticiper la trajectoire.
Types d'équations différentielles
Toutes les équations différentielles ne se valent pas. La première chose à savoir, c'est comment les distinguer.
La grande distinction se fait entre les équations différentielles ordinaires (EDO, ODE) et les équations aux dérivées partielles (EDP, PDE). La différence tient au nombre de variables indépendantes dont dépend la fonction.
Équations différentielles ordinaires (EDO)
Une équation différentielle ordinaire met en jeu une fonction d'une seule variable indépendante et ses dérivées.
L'exemple de la population bactérienne vu plus haut est une EDO. La population P ne dépend que du temps t — une seule variable. L'équation ne contient donc que des dérivées ordinaires, notées dP/dt.
Les EDO conviennent lorsque votre système évolue selon une seule dimension, généralement le temps. Voici quelques exemples classiques :
- Croissance d'une population — le taux de variation d'une population dépend de sa taille actuelle
- Désintégration radioactive — la vitesse de désintégration d'une substance dépend de la quantité restante
- Deuxième loi de Newton — l'accélération d'un objet dépend des forces qui s'exercent sur lui
Dans chaque cas, une seule variable pilote l'évolution. C'est ce qui les rend « ordinaires ».
Équations aux dérivées partielles (EDP)
Une équation aux dérivées partielles met en jeu une fonction de plusieurs variables indépendantes et ses dérivées partielles.
Par exemple, vous voulez modéliser la diffusion de la chaleur dans une barre métallique. La température en un point dépend à la fois de la position le long de la barre et du temps. Cela fait deux variables indépendantes : la position x et le temps t. En écrivant l'équation correspondante, on obtient des dérivées partielles — l'une par rapport à x, l'autre par rapport à t.
C'est une EDP. L'équation de la chaleur en est l'un des exemples les plus connus :
Exemple d'équation aux dérivées partielles
Où u(x, t) est la température à la position x et au temps t, α est la diffusivité thermique du matériau, ∂u/∂t représente la vitesse de variation temporelle de la température, et ∂²u/∂x² la courbure du profil de température dans l'espace. L'équation dit que là où la courbe de température est fortement courbée, la chaleur se redistribue rapidement ; là où elle est plate, il se passe peu de choses.
Les EDP apparaissent dès qu'un système varie dans l'espace et le temps :
- Distribution de chaleur — la température change selon la position et le temps
- Propagation d'ondes — les ondes sonores ou lumineuses se propagent dans l'espace au fil du temps
- Dynamique des fluides — la vitesse du fluide dépend de la position en 3D et du temps
Les EDP sont plus difficiles à résoudre que les EDO. Les solutions analytiques n'existent que pour des formes particulières ; en pratique, on recourt souvent aux méthodes numériques.
En data science, vous croiserez plus fréquemment des EDO. Mais les EDP interviennent en traitement d'images, en simulations physiques et dans certaines architectures de deep learning : il est donc utile d'en connaître les différences.
Ordre et degré d'une équation différentielle
Chaque équation différentielle possède deux caractéristiques qui donnent une idée de sa complexité : son ordre et son degré.
Ils déterminent les méthodes de résolution applicables ; il faut donc les identifier avant de se lancer.
Comprendre l'ordre
L'ordre d'une équation différentielle est l'ordre de la dérivée la plus élevée présente dans l'équation.
Si la dérivée la plus élevée est une première dérivée (dy/dx), c'est une équation du premier ordre. Si c'est une seconde dérivée (d²y/dx²), c'est une équation du second ordre, etc.
Voici l'équation de croissance bactérienne évoquée plus haut :
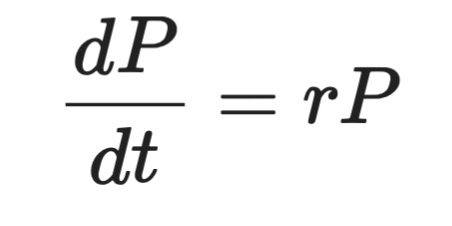
Équation de croissance bactérienne
La dérivée la plus élevée est dP/dt — une première dérivée. C'est donc une EDO du premier ordre.
Comparez maintenant avec l'équation d'un pendule oscillant :
Équation d'un pendule
La dérivée la plus élevée est d²θ/dt² — une seconde dérivée. Il s'agit donc d'une EDO du second ordre.
Plus l'ordre est élevé, plus la complexité augmente. Les équations du second ordre nécessitent deux conditions initiales au lieu d'une. En pratique, la plupart des systèmes physiques — mouvement mécanique, circuits électriques, dynamique orbitale — se modélisent par des équations du second ordre.
Comprendre le degré
Le degré d'une équation différentielle est la puissance de la dérivée d'ordre le plus élevé, une fois l'équation écrite sous forme polynomiale (sans radicaux ni fractions impliquant des dérivées).
Prenez cette équation :
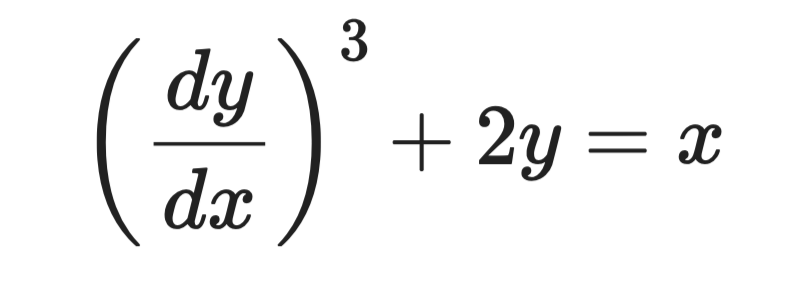
Exemple d'équation différentielle
La dérivée la plus élevée est dy/dx, élevée à la puissance 3. L'ordre est donc 1 et le degré 3.
Prenez maintenant celle-ci :
Exemple d'équation différentielle (2)
La dérivée d'ordre le plus élevé est d²y/dx², à la puissance 1. Le degré est 1, même si une dérivée d'ordre inférieur apparaît avec une puissance plus élevée.
Le degré se réfère toujours à la dérivée d'ordre le plus élevé, et non à la plus grande puissance présente dans l'équation.
Un cas limite : si une équation contient des termes comme sin(dy/dx) ou e^(d²y/dx²), le degré est indéfini — ces formes ne peuvent pas s'exprimer comme des polynômes en les dérivées.
Méthodes de résolution des équations différentielles
Il n'existe pas de méthode universelle. L'approche dépend du type d'équation, de son ordre et de l'existence ou non d'une solution exacte.
Globalement, on distingue deux familles : les méthodes analytiques et les méthodes numériques.
Méthodes analytiques
Les méthodes analytiques fournissent une solution exacte, sous forme fermée — une formule évaluable en tout point. On les préfère quand elles s'appliquent, car elles donnent un résultat précis et apportent un éclairage sur la structure de la solution.
Mais elles ne fonctionnent que pour des formes d'équations spécifiques. Dès que l'équation se complique, ces méthodes atteignent leurs limites.
Séparation des variables
La séparation des variables s'applique aux équations où l'on peut isoler tous les termes en y d'un côté et tous les termes en x (ou t) de l'autre.
Considérez cette EDO du premier ordre :
Équation différentielle simple
Étape 1 — séparer les variables :
Solution analytique (étape 1)
Étape 2 — intégrer des deux côtés :
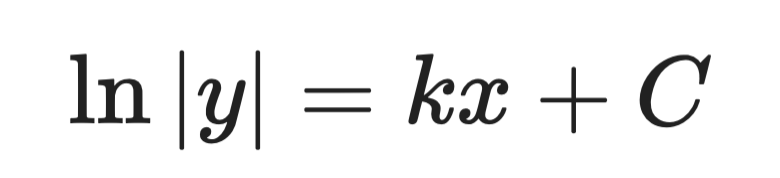
Solution analytique (étape 2)
Étape 3 — isoler y :
Solution analytique (étape 3)
Où A est une constante déterminée par les conditions initiales. C'est la solution générale.
C'est la même forme que l'équation de croissance bactérienne. Elle montre que les populations — et tout phénomène dont le taux de croissance est proportionnel à sa taille — croissent exponentiellement.
Facteurs intégrants
La méthode du facteur intégrant s'applique aux EDO linéaires du premier ordre de la forme :
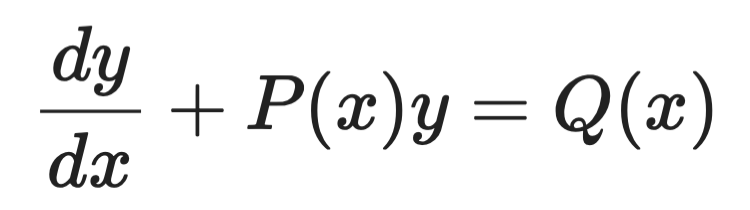
Exemple de facteur intégrant (1)
L'idée est de multiplier les deux membres par une fonction soigneusement choisie — le facteur intégrant μ(x) — de sorte que le membre de gauche devienne une dérivée parfaite, intégrable directement.
Le facteur intégrant vaut toujours :
Exemple de facteur intégrant (2)
Après multiplication, l'équation devient :
Exemple de facteur intégrant (3)
Il suffit alors d'intégrer les deux côtés et d'isoler y. Le membre de gauche se simplifie proprement grâce au choix de μ(x) — c'est tout l'intérêt de la méthode.
Méthodes numériques
La plupart des équations différentielles réelles n'ont pas de solution analytique simple. Les méthodes numériques approchent la solution pas à pas en calculant des valeurs en des points discrets.
Elles sacrifient l'exactitude au profit de la généralité. Et dans les faits, c'est souvent exactement ce qu'il faut.
Méthode d'Euler
La méthode d'Euler est l'approche numérique la plus simple. L'idée : partir d'un point connu, utiliser la dérivée pour estimer la pente, faire un petit pas dans cette direction, et répéter.
Étant donnée une EDO du premier ordre dy/dx = f(x, y) avec condition initiale y(x₀) = y₀, chaque pas s'écrit :
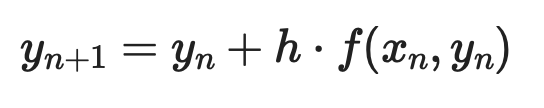
Méthode d’Euler (1)
Où h est le pas. Plus le pas est petit, meilleure est la précision — mais le calcul augmente.
Voici une implémentation Python qui résout dy/dx = y avec y(0) = 1 (la solution exacte est y = eˣ) :
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Méthode d'Euler versus solution exacte
L'écart entre les deux courbes correspond à l'erreur d'approximation. Avec h=0.2, l'erreur est faible au départ mais se cumule au fil des pas — c'est la principale faiblesse de la méthode d'Euler.
Méthodes de Runge-Kutta
Les méthodes de Runge-Kutta corrigent ce problème d'erreur cumulative en échantillonnant la pente à plusieurs points au sein de chaque pas, puis en prenant une moyenne pondérée. La version la plus courante est RK4 — la méthode de Runge-Kutta d'ordre 4.
Au lieu d'une seule estimation de pente par pas comme Euler, RK4 en calcule quatre :
Méthode de Runge-Kutta (1)
Puis les combine :
Méthode de Runge-Kutta (2)
En pratique, vous n'implémentez pas RK4 à la main. solve_ivp de SciPy s'en charge pour vous :
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 versus solution exacte
La courbe RK45 se superpose quasiment à la solution exacte. Même pas que dans l'exemple Euler, mais une précision bien supérieure — c'est l'apport de l'échantillonnage pondéré des pentes.
Pour la plupart des usages en Python, solve_ivp avec le solveur RK45 par défaut est votre meilleur choix. La méthode d'Euler est utile pour comprendre le principe des solveurs numériques, mais on l'utilise rarement en production.
Applications des équations différentielles en data science et machine learning
Les ingénieurs s'en servent pour modéliser des circuits électriques et des systèmes mécaniques. Les biologistes pour suivre des dynamiques de population et la propagation de maladies. Les physiciens pour décrire de la conduction thermique à la mécanique quantique.
Mais si vous lisez ceci pour la data science, allons droit au but.
Machine learning et optimisation
Le lien le plus direct entre équations différentielles et ML, c'est la descente de gradient — l'algorithme derrière l'entraînement de quasiment tous vos modèles.
Lorsque vous entraînez un modèle, vous minimisez une fonction de perte L. Pour cela, vous devez savoir comment L varie quand vous ajustez chaque paramètre. Ce taux de variation est une dérivée. Si votre modèle a plusieurs paramètres, vous calculez une dérivée partielle pour chacun — ensemble, elles forment le gradient.
La descente de gradient utilise ces dérivées pour mettre à jour les paramètres pas à pas :
Descente de gradient
Où θ est le paramètre, η le taux d'apprentissage, et ∂L/∂θ la dérivée partielle de la perte par rapport à ce paramètre.
Voici un exemple Python d'ajustement d'une droite aux données par descente de gradient :
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Descente de gradient ajustant une droite aux données, et courbe de perte au fil des itérations
Chaque itération déplace les paramètres dans la direction qui réduit la perte. Les dérivées partielles vous indiquent cette direction. Sans elles, la descente de gradient ne fonctionne pas — et la rétropropagation dans les réseaux de neurones non plus, puisqu'elle n'est rien d'autre que la règle de la chaîne appliquée couche après couche.
Analyse des séries temporelles
De nombreux systèmes de séries temporelles sont dynamiques — la valeur courante dépend des valeurs passées et des vitesses de variation. Les équations différentielles permettent de les décrire.
Le filtre de Kalman, largement utilisé pour le suivi et la prévision, repose sur un système d'équations différentielles qui modélisent l'évolution d'un état latent dans le temps et la relation entre des observations bruitées et cet état. On l'emploie dans les systèmes GPS, la finance et la météorologie.
Les modèles ARIMA servent à prévoir des séries temporelles et se rattachent aux équations différentielles via la notion de différenciation. Prendre les premières ou secondes différences d'une série est une approximation discrète des dérivées première et seconde. Quand vous différenciez une série pour la rendre stationnaire, vous posez la question : comment cette série évolue-t‑elle dans le temps ?
Modélisation statistique et régression
Surprise fréquente : résoudre un système d'équations différentielles est l'une des pistes qui mènent aux coefficients de la régression linéaire.
Quand vous ajustez une régression linéaire, vous minimisez la somme des résidus au carré. Prenez la dérivée partielle de cette perte par rapport à chaque coefficient, annulez-la et résolvez. Vous obtenez ainsi l'équation normale :
Équation normale
Chaque coefficient de régression que vous avez calculé résulte d'une dérivée annulée puis résolue. C'est de l'analyse — et c'est le même principe derrière tout modèle paramétrique que vous ajustez.
Pour la régression logistique, la fonction de perte n'est pas quadratique ; il n'existe donc pas de solution fermée. Il faut utiliser des méthodes itératives comme la descente de gradient, qui reposent à nouveau sur des dérivées partielles à chaque étape.
Le lien va plus loin. La décomposition QR, l'une des méthodes numériques standard pour résoudre l'équation normale, s'appuie sur l'algèbre linéaire et rejoint directement la manière dont on résout en pratique des systèmes d'équations — y compris différentielles.
Simulation de systèmes dynamiques
Quand il faut modéliser l'évolution d'un système dans le temps — sans solution analytique disponible — on le simule numériquement.
C'est courant en contexte business et opérations. L'attrition clients, les niveaux d'inventaire, la dynamique des chaînes d'approvisionnement : autant de quantités qui évoluent en fonction de l'état courant. Vous pouvez écrire ces relations sous forme d'équations différentielles et les simuler avec solve_ivp.
Voici un exemple simulant un système offre-demande simple, où l'inventaire I se réduit à un rythme proportionnel à la demande D, et où la demande évolue dans le temps :
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)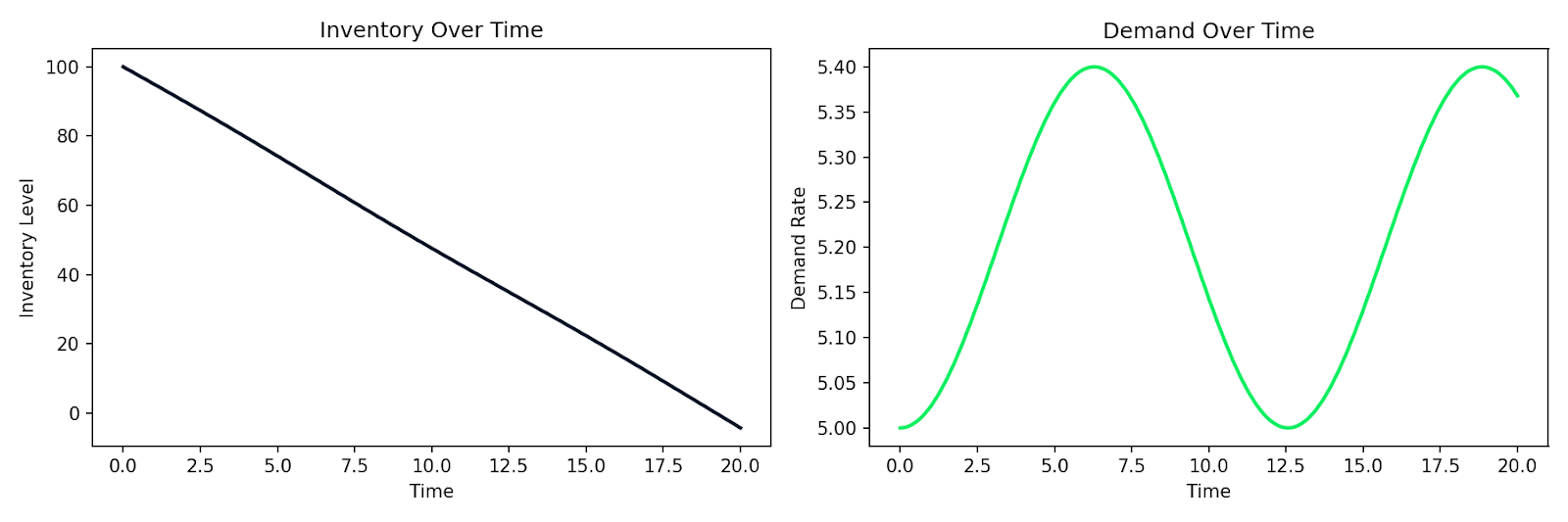
Diminution simulée de l'inventaire et fluctuations de la demande dans le temps
La même logique s'applique à la modélisation du comportement client, à la propagation d'une épidémie au sein d'une base d'utilisateurs, ou à tout système où le taux de variation dépend de l'état courant. Vous décrivez les relations, vous les confiez à un solveur numérique, et vous obtenez une simulation exploitable.
C'est là toute la puissance pratique des équations différentielles en data science : un outil direct pour modéliser des systèmes en évolution.
Conclusion
Derrière la descente de gradient, il y a des dérivées partielles. Derrière la prévision de séries temporelles, des systèmes dynamiques. Derrière les coefficients de régression linéaire, des dérivées annulées. Il suffit de savoir où regarder.
Dans cet article, j'ai expliqué ce que sont les équations différentielles, la différence entre EDO et EDP, comment l'ordre et le degré les classifient, et les principales méthodes de résolution — analytiques et numériques. Puis nous avons vu où elles se manifestent concrètement en data science et en machine learning.
Ce n'est qu'un socle. Pour approfondir d'autres notions mathématiques, le cours Linear Algebra for Data Science in R est une bonne étape suivante. Pour vous exercer concrètement sur des problèmes réels, consultez notre cours Quantitative Analyst in R.


