Tatsächlich nutzt du die Ergebnisse von Differentialgleichungen jedes Mal, wenn du ein neuronales Netz trainierst oder sogar ein Regressionsmodell anpasst. Die zugrunde liegende Mathematik ist Analysis, und Differentialgleichungen stehen im Zentrum davon. Wenn du dich je gefragt hast, warum Gradientenabstieg funktioniert oder wie ein Kalman-Filter ein bewegtes Objekt verfolgt, liefern Differentialgleichungen die Antwort.
Mit Differentialgleichungen modellierst du, wie sich Dinge über die Zeit verändern – genau darum geht es in der Datenwissenschaft. Sobald du die Kernideen verstehst, wirst du sie überall sehen: in den Loss-Funktionen, die du minimierst, in Zeitreihen, die du prognostizierst, und in Simulationen, die du laufen lässt.
In diesem Artikel zeige ich dir, was Differentialgleichungen sind, welche Haupttypen es gibt, wie man sie löst und – am wichtigsten – wie sie im Data-Science- und Machine-Learning-Alltag auftauchen.
Was sind Differentialgleichungen?
Eine Differentialgleichung ist eine Gleichung, die eine Funktion mit ihren eigenen Ableitungen in Beziehung setzt.
Einfach gesagt, verrät dir eine Ableitung, wie schnell sich etwas in einem bestimmten Moment verändert. Eine Differentialgleichung sagt, dass die Änderungsrate einer Größe von der Größe selbst, von der Zeit oder von beidem abhängt.
Angenommen, du modellierst eine Bakterienpopulation. Je mehr Bakterien es gibt, desto schneller vermehren sie sich. Die Wachstumsrate hängt also von der aktuellen Populationsgröße ab. Schreibst du das als Gleichung auf, hast du eine Differentialgleichung.
Formal sieht das so aus:
Darstellung einer Differentialgleichung
Dabei ist P die Population, t die Zeit und r die Wachstumsrate. Die linke Seite ist die Ableitung – also wie schnell sich P über die Zeit ändert. Die rechte Seite sagt, dass diese Änderung proportional zu P selbst ist.
Das ist die Kernidee hinter jeder Differentialgleichung, der du begegnest.
Differentialgleichungen tauchen in Physik, Biologie und Ingenieurwesen auf – überall dort, wo sich ein System über die Zeit entwickelt: Wärme, die sich in einer Metallstange ausbreitet, ein schwingendes Pendel, ein Virus, der sich in einer Population verbreitet. All das wird mit Differentialgleichungen modelliert.
Für Data Scientists findest du Differentialgleichungen in Loss-Funktionen, Gradientenabstieg, Zeitreihenmodellen, Neural ODEs – überall laufen Differentialgleichungen im Hintergrund. Man sieht sie nicht immer explizit, aber sie sind da.
Wenn du sie verstehst, hast du ein klareres Mentales Modell dafür, warum und wie die Tools funktionieren, die du täglich nutzt.
Die Geschichte der Differentialgleichungen
Im späten 17. Jahrhundert entwickelten Isaac Newton und Gottfried Wilhelm Leibniz unabhängig voneinander die Analysis. Beide brauchten eine Möglichkeit, zu beschreiben, wie sich physikalische Größen über die Zeit verändern – die Differentialgleichungen waren das Resultat. Newton nutzte sie, um Bewegung und Gravitation zu modellieren. Leibniz gab uns viel von der Notation, die wir heute noch verwenden, einschließlich des d/dt, das du in jedem Analysis-Lehrbuch findest.
Das 18. und 19. Jahrhundert brachte eine Welle neuer Techniken.
Leonhard Euler entwickelte numerische Methoden zur Lösung gewöhnlicher Differentialgleichungen – derselbe Euler hinter der „Euler-Methode“, der du später in diesem Artikel begegnest. Joseph-Louis Lagrange und Pierre-Simon Laplace erweiterten die Theorie auf komplexere Systeme. Jean-Baptiste Joseph Fourier führte eine Zerlegung von Funktionen in Sinus- und Kosinuskomponenten ein, die zum Eckpfeiler beim Lösen partieller Differentialgleichungen wurde.
Im 20. Jahrhundert waren Differentialgleichungen allgegenwärtig – von Strömungsmechanik über Quantenmechanik bis Elektrotechnik. Viele reale Gleichungen hatten keine saubere analytische Lösung. Dann übernahmen numerische Methoden, und Computer machten sie in großem Maßstab praktikabel.
Heute entwickelt sich das Feld weiter. Neuronale gewöhnliche Differentialgleichungen (Neural ODEs) behandeln die Schichten eines neuronalen Netzes als kontinuierlichen Prozess, der durch eine Differentialgleichung beschrieben wird. Das ist eine jüngere Entwicklung, die die Grenze zwischen Deep Learning und klassischer Mathematik verwischt. Es ist außerdem eines der spannendsten Gebiete der modernen ML-Forschung.
Die Kernidee bleibt jedoch gleich: Wenn du modellierst, wie sich Dinge verändern, kannst du vorhersagen, wohin sie sich entwickeln.
Arten von Differentialgleichungen
Nicht alle Differentialgleichungen sind gleich. Zuerst musst du lernen, sie zu unterscheiden.
Die wichtigste Unterscheidung ist zwischen gewöhnlichen Differentialgleichungen (ODEs) und partiellen Differentialgleichungen (PDEs). Der Unterschied liegt in der Anzahl der unabhängigen Variablen, von denen die Funktion abhängt.
Gewöhnliche Differentialgleichungen (ODEs)
Eine gewöhnliche Differentialgleichung beinhaltet eine Funktion einer einzelnen unabhängigen Variablen und deren Ableitungen.
Das Beispiel mit der Bakterienpopulation von vorhin ist eine ODE. Die Population P hängt nur von der Zeit t ab – also von einer Variablen. Entsprechend enthält die Gleichung nur gewöhnliche Ableitungen, geschrieben als dP/dt.
ODEs sind das richtige Werkzeug, wenn sich dein System entlang einer einzigen Dimension entwickelt, meist der Zeit. Hier ein paar klassische Beispiele:
- Populationswachstum – die Änderungsrate einer Population hängt von der aktuellen Größe ab
- Radioaktiver Zerfall – die Zerfallsrate hängt davon ab, wie viel Substanz noch vorhanden ist
- Newtons zweites Gesetz – die Beschleunigung eines Körpers hängt von den auf ihn wirkenden Kräften ab
In all diesen Fällen treibt eine Variable die Veränderung. Das macht sie „gewöhnlich“.
Partielle Differentialgleichungen (PDEs)
Eine partielle Differentialgleichung beinhaltet eine Funktion mehrerer unabhängiger Variablen und deren partieller Ableitungen.
Willst du modellieren, wie sich Wärme in einer Metallstange ausbreitet, hängt die Temperatur an jedem Punkt sowohl davon ab, wo du dich entlang der Stange befindest, als auch davon, welche Zeit es ist. Das sind zwei unabhängige Variablen: Position x und Zeit t. Schreibst du die Gleichung dafür auf, erhältst du partielle Ableitungen – eine nach x, eine nach t.
Das ist eine PDE. Die Wärmeleitungsgleichung ist eines der bekanntesten Beispiele:
Beispiel für eine partielle Differentialgleichung
Dabei ist u(x, t) die Temperatur an Position x und zur Zeit t, α die Temperaturleitfähigkeit des Materials, ∂u/∂t beschreibt, wie schnell sich die Temperatur über die Zeit ändert, und ∂²u/∂x² wie stark die Temperaturkurve räumlich gekrümmt ist. Die Gleichung sagt: Wo die Temperaturkurve stark gekrümmt ist, verteilt sich Wärme schnell; wo sie flach ist, passiert wenig.
PDEs tauchen überall auf, wo ein System über Raum und Zeit variiert:
- Wärmeverteilung – Temperatur ändert sich über Position und Zeit
- Wellenfortpflanzung – Schall- oder Lichtwellen breiten sich räumlich über die Zeit aus
- Strömungsdynamik – die Geschwindigkeit eines Fluids hängt von der Position im 3D-Raum und der Zeit ab
PDEs sind schwieriger zu lösen als ODEs. Analytische Lösungen gibt es nur für spezielle Formen, oft sind numerische Methoden der einzige praktikable Weg.
In der meisten Data-Science-Arbeit wirst du häufiger ODEs sehen. Aber PDEs erscheinen in der Bildverarbeitung, in Physiksimulationen und in einigen Deep-Learning-Architekturen – deshalb solltest du die Unterschiede kennen.
Ordnung und Grad von Differentialgleichungen
Jede Differentialgleichung hat zwei Eigenschaften, die ihre Komplexität beschreiben: Ordnung und Grad.
Sie bestimmen, welche Lösungsverfahren anwendbar sind – du solltest sie also identifizieren, bevor du mit dem Lösen beginnst.
Die Ordnung verstehen
Die Ordnung einer Differentialgleichung ist die Ordnung der höchsten in der Gleichung vorkommenden Ableitung.
Ist die höchste Ableitung eine erste Ableitung (dy/dx), ist es eine Differentialgleichung erster Ordnung. Ist die höchste eine zweite Ableitung (d²y/dx²), ist es eine Differentialgleichung zweiter Ordnung. Und so weiter.
Hier ist die Wachstumsgleichung der Bakterien von vorhin:
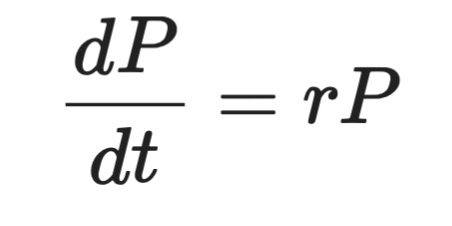
Gleichung für Bakterienwachstum
Die höchste Ableitung ist hier dP/dt – eine erste Ableitung. Es ist also eine ODE erster Ordnung.
Vergleiche das mit der Gleichung für ein schwingendes Pendel:
Gleichung für ein schwingendes Pendel
Die höchste Ableitung ist d²θ/dt² – eine zweite Ableitung. Damit ist es eine ODE zweiter Ordnung.
Höhere Ordnung bedeutet mehr Komplexität. Gleichungen zweiter Ordnung benötigen zwei Anfangsbedingungen statt einer. In der Praxis werden die meisten physikalischen Systeme – mechanische Bewegungen, elektrische Schaltkreise, Orbitdynamik – mit Gleichungen zweiter Ordnung modelliert.
Den Grad verstehen
Der Grad einer Differentialgleichung ist die Potenz der höchstordentlichen Ableitung, nachdem die Gleichung in Polynomform (ohne Wurzeln oder Brüche mit Ableitungen) geschrieben wurde.
Betrachte diese Gleichung:
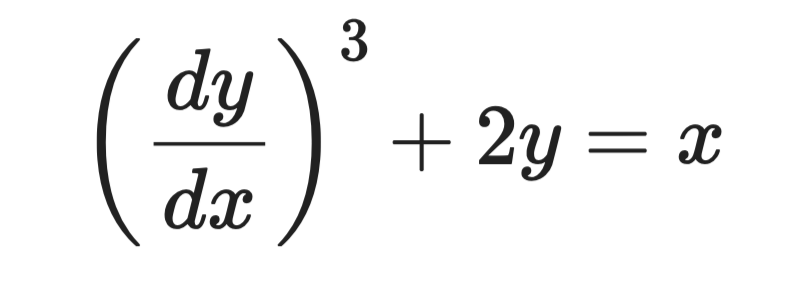
Beispiel einer Differentialgleichung
Die höchste Ableitung ist dy/dx, und sie steht in der dritten Potenz. Die Ordnung ist also 1 und der Grad 3.
Und nun diese:
Beispiel einer Differentialgleichung (2)
Die höchstordentliche Ableitung ist d²y/dx² mit der Potenz 1. Der Grad ist 1, auch wenn eine Ableitung niedrigerer Ordnung mit höherer Potenz vorkommt.
Der Grad richtet sich immer nach der höchstordentlichen Ableitung, nicht nach der höchsten Potenz irgendwo in der Gleichung.
Ein Sonderfall liegt vor, wenn Terme wie sin(dy/dx) oder e^(d²y/dx²) auftreten. Dann ist der Grad undefiniert – solche Formen lassen sich nicht als Polynome in den Ableitungen schreiben.
Methoden zum Lösen von Differentialgleichungen
Es gibt keine Methode, die für jede Differentialgleichung funktioniert. Der richtige Ansatz hängt vom Typ, der Ordnung und davon ab, ob überhaupt eine exakte Lösung existiert.
Grob unterscheidet man zwischen analytischen Methoden und numerischen Methoden.
Analytische Methoden
Analytische Methoden liefern eine exakte, geschlossene Lösung – also eine Formel, die du an jedem Punkt auswerten kannst. Wenn sie anwendbar sind, sind sie zu bevorzugen, weil das Ergebnis präzise ist und dir etwas über die Struktur der Lösung verrät.
Sie funktionieren aber nur für bestimmte Gleichungsformen. Wird die Gleichung zu komplex, stoßen analytische Methoden an ihre Grenzen.
Trennung der Variablen
Die Trennung der Variablen funktioniert bei Gleichungen, bei denen du alle Terme mit y auf eine Seite und alle Terme mit x (oder t) auf die andere Seite bringen kannst.
Betrachte diese ODE erster Ordnung:
Einfache Differentialgleichung
Schritt 1 – Variablen trennen:
Analytische Lösung (Schritt 1)
Schritt 2 – beide Seiten integrieren:
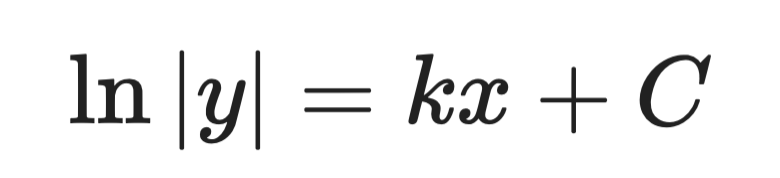
Analytische Lösung (Schritt 2)
Schritt 3 – nach y auflösen:
Analytische Lösung (Schritt 3)
Dabei ist A eine Konstante, die durch Anfangsbedingungen bestimmt wird. Das ist die allgemeine Lösung.
Das entspricht der Form der Bakterienwachstumsgleichung. Sie zeigt, dass Populationen – und alles, dessen Wachstumsrate proportional zur Größe ist – exponentiell wachsen.
Integrierende Faktoren
Integrierende Faktoren behandeln lineare ODEs erster Ordnung dieser Form:
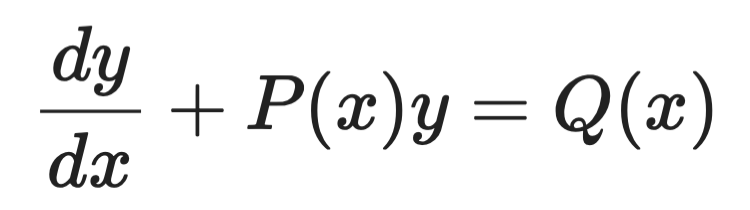
Beispiel für integrierende Faktoren (1)
Die Idee ist, beide Seiten mit einer geschickt gewählten Funktion – dem integrierenden Faktor μ(x) – zu multiplizieren, sodass die linke Seite zu einer perfekten Ableitung wird, die du direkt integrieren kannst.
Der integrierende Faktor ist immer:
Beispiel für integrierende Faktoren (2)
Nach dem Multiplizieren wird die Gleichung zu:
Beispiel für integrierende Faktoren (3)
Dann integrierst du beide Seiten und löst nach y auf. Die linke Seite fällt dank der Wahl von μ(x) stets „sauber“ zusammen – genau darum geht es bei der Methode.
Numerische Methoden
Die meisten realen Differentialgleichungen haben keine sauberen analytischen Lösungen. Numerische Methoden approximieren die Lösung schrittweise und berechnen Werte an diskreten Punkten.
Sie tauschen Exaktheit gegen Allgemeingültigkeit – und in der Praxis ist das oft genau das, was du brauchst.
Euler-Methode
Die Euler-Methode ist der einfachste numerische Ansatz. Die Idee: Starte an einem bekannten Punkt, nutze die Ableitung zur Schätzung der Steigung, gehe einen kleinen Schritt in diese Richtung und wiederhole.
Gegeben eine ODE erster Ordnung dy/dx = f(x, y) mit Anfangsbedingung y(x₀) = y₀, sieht jeder Schritt so aus:
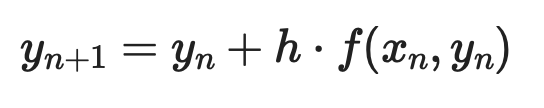
Beispiel für die Euler-Methode (1)
Dabei ist h die Schrittweite. Kleinere Schritte bedeuten höhere Genauigkeit – aber auch mehr Rechenaufwand.
Hier ist eine Python-Implementierung zur Lösung von dy/dx = y mit y(0) = 1 (die exakte Lösung ist y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Euler-Methode im Vergleich zur exakten Lösung
Die Lücke zwischen den beiden Linien ist der Approximationsfehler. Mit h=0.2 ist der Fehler anfangs klein, häuft sich über die Schritte aber an – das ist die Hauptschwäche der Euler-Methode.
Runge-Kutta-Verfahren
Runge-Kutta-Verfahren beheben dieses Aufsummieren von Fehlern, indem sie die Steigung innerhalb eines Schritts mehrfach abtasten und gewichtet mitteln. Die gängigste Variante ist RK4 – das Runge-Kutta-Verfahren 4. Ordnung.
Statt einer Steigungsschätzung pro Schritt wie bei Euler berechnet RK4 vier:
Beispiel für ein Runge-Kutta-Verfahren (1)
Und kombiniert sie dann so:
Beispiel für ein Runge-Kutta-Verfahren (2)
In der Praxis implementierst du RK4 nicht von Hand. SciPys solve_ivp übernimmt das für dich:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 im Vergleich zur exakten Lösung
Die RK45-Kurve liegt fast perfekt auf der exakten Lösung. Gleiche Schrittweite wie im Euler-Beispiel, aber deutlich höhere Genauigkeit – das bewirkt das gewichtete Abtasten der Steigung.
Für die meisten praktischen Aufgaben in Python ist solve_ivp mit dem Standard-Solver RK45 deine erste Wahl. Die Euler-Methode hilft, numerische Solver zu verstehen, würdest du aber nicht in der Produktion verwenden.
Anwendungen von Differentialgleichungen in Data Science und Machine Learning
Ingenieurinnen und Ingenieure modellieren mit Differentialgleichungen elektrische Schaltkreise und mechanische Systeme. Biologinnen und Biologen verfolgen damit Populationsdynamiken und Krankheitsverläufe. Physikerinnen und Physiker beschreiben damit alles von Wärmeübertragung bis Quantenmechanik.
Aber du bist wegen Data Science hier – also los.
Machine Learning und Optimierung
Die direkteste Verbindung zwischen Differentialgleichungen und ML ist der Gradientenabstieg – der Algorithmus hinter fast jedem Modelltraining.
Wenn du ein Modell trainierst, minimierst du eine Loss-Funktion L. Dafür musst du wissen, wie sich L ändert, wenn du jeden Parameter anpasst. Diese Änderungsrate ist eine Ableitung. Hat dein Modell mehrere Parameter, berechnest du für jeden eine partielle Ableitung – zusammen bilden sie den Gradienten.
Der Gradientenabstieg nutzt diese Ableitungen, um Parameter schrittweise zu aktualisieren:
Gradientenabstieg
Dabei ist θ der Parameter, η die Lernrate und ∂L/∂θ die partielle Ableitung der Loss-Funktion nach diesem Parameter.
Hier ein einfaches Python-Beispiel, das mit Gradientenabstieg eine Gerade an Daten anpasst:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Gradientenabstieg passt eine Linie an Daten an, daneben die Loss-Kurve über die Iterationen
Jede Iteration bewegt die Parameter in die Richtung, die die Loss reduziert. Die partiellen Ableitungen zeigen dir diese Richtung. Ohne sie funktioniert der Gradientenabstieg nicht – und Backpropagation in neuronalen Netzen ebenso wenig, denn sie ist nur die Kettenregel, wiederholt über die Schichten angewendet.
Zeitreihenanalyse
Viele Zeitreihensysteme sind dynamisch – der aktuelle Wert hängt von vergangenen Werten und deren Änderungsraten ab. Differentialgleichungen ermöglichen es, das zu beschreiben.
Der Kalman-Filter, weit verbreitet in Tracking und Forecasting, basiert auf einem System von Differentialgleichungen, das modelliert, wie sich ein verborgener Zustand über die Zeit entwickelt und wie verrauschte Beobachtungen zu diesem Zustand in Beziehung stehen. Er wird in GPS-Systemen, der Finanzwelt und der Wettervorhersage eingesetzt.
ARIMA-Modelle werden zur Zeitreihenprognose genutzt und verknüpfen sich über das Differenzieren mit Differentialgleichungen. Erste oder zweite Differenzen einer Zeitreihe sind eine diskrete Approximation erster und zweiter Ableitungen. Wenn du eine Reihe differenzierst, um sie stationär zu machen, fragst du: Wie verändert sich diese Reihe über die Zeit?
Statistische Modellierung und Regression
Das überrascht viele: Das Lösen eines Gleichungssystems aus Ableitungen ist ein Weg, die Koeffizienten der linearen Regression herzuleiten.
Wenn du ein lineares Regressionsmodell fitst, minimierst du die Summe quadrierter Residuen. Nimm die partiellen Ableitungen dieser Loss nach jedem Koeffizienten, setze sie gleich Null und löse – so erhältst du die Normalengleichung:
Normalengleichung
Jeder Regressionskoeffizient, den du je berechnet hast, stammt daraus, eine Ableitung auf Null zu setzen und zu lösen. Das ist Analysis – und dasselbe Prinzip steckt hinter jedem parametrischen Modell, das du fitst.
Bei der logistischen Regression ist die Loss-Funktion nicht quadratisch, daher gibt es keine geschlossene Lösung. Du musst iterative Verfahren wie Gradientenabstieg nutzen – die wiederum in jedem Schritt auf partiellen Ableitungen beruhen.
Die Verbindung geht weiter. Die QR-Zerlegung, eine der Standardmethoden zum Lösen der Normalengleichung, fußt auf Linearalgebra, die direkt mit dem Lösen von Gleichungssystemen – einschließlich Differentialgleichungen – verknüpft ist.
Simulation dynamischer Systeme
Wenn du modellieren musst, wie sich ein System über die Zeit entwickelt – und es keine analytische Lösung gibt – simulierst du numerisch.
Das ist in Business- und Operations-Kontexten häufig: Kundenabwanderung, Lagerbestände und Lieferkettendynamiken betreffen Größen, die sich auf Basis des aktuellen Zustands verändern. Du kannst diese Zusammenhänge als Differentialgleichungen formulieren und mit solve_ivp simulieren.
Hier ein Beispiel für ein einfaches Angebots-Nachfrage-System, in dem Lagerbestand I sich mit einer Rate abbaut, die proportional zur Nachfrage D ist, während sich die Nachfrage über die Zeit verändert:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)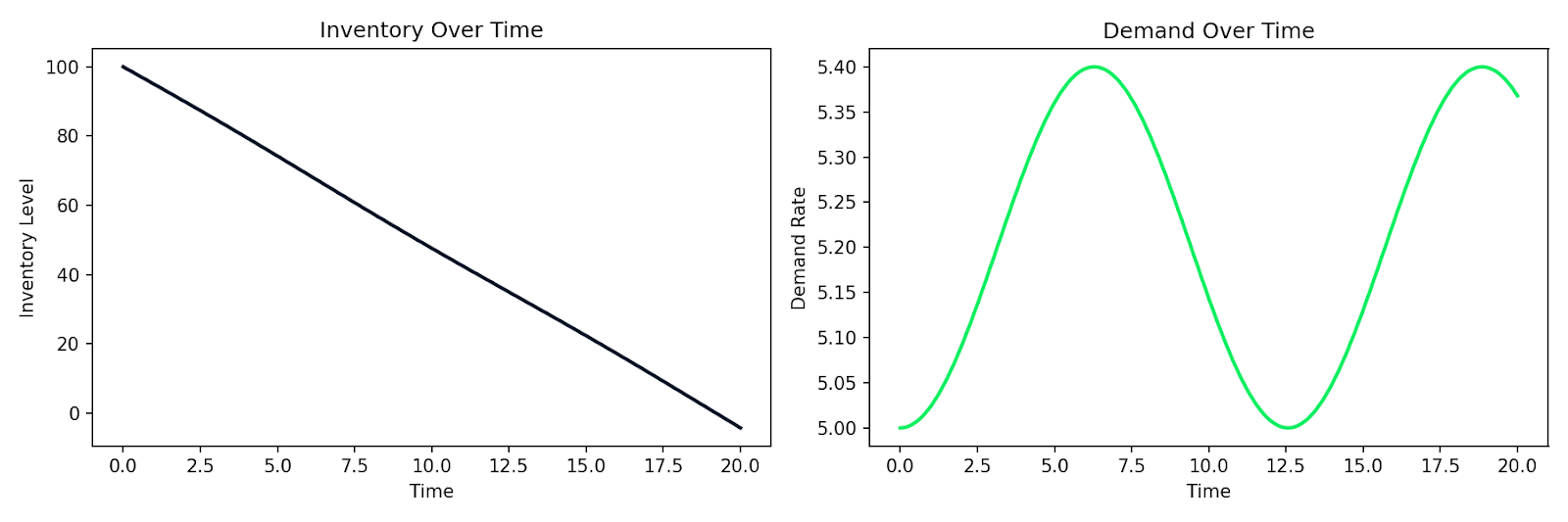
Simulierter Lagerbestandsabbau bei schwankender Nachfrage über die Zeit
Dasselbe Muster gilt für Kundenverhalten, die Ausbreitung einer Epidemie in einer Nutzerbasis oder jedes System, in dem die Änderungsrate vom aktuellen Zustand abhängt. Du formulierst die Beziehungen, übergibst sie einem numerischen Solver und bekommst eine Simulation zurück.
Und genau darin liegt die praktische Stärke von Differentialgleichungen in der Datenwissenschaft: ein direktes Werkzeug, um sich verändernde Systeme zu modellieren.
Fazit
Hinter dem Gradientenabstieg stehen partielle Ableitungen. Hinter Zeitreihenprognosen stehen dynamische Systeme. Hinter Regressionskoeffizienten stehen auf Null gesetzte Ableitungen. Du musst nur wissen, wo du hinschaust.
In diesem Artikel habe ich erklärt, was Differentialgleichungen sind, den Unterschied zwischen ODEs und PDEs, wie Ordnung und Grad sie klassifizieren und die wichtigsten Lösungsverfahren – analytisch und numerisch. Anschließend haben wir uns angeschaut, wo sie im Data-Science- und Machine-Learning-Alltag tatsächlich vorkommen.
Das ist nur die Grundlage. Wenn du weitere Mathe-Themen erkunden willst, ist der Kurs Linear Algebra for Data Science in R ein guter nächster Schritt. Für praxisnahe Übungen mit echten Datenproblemen schau dir unseren Kurs Quantitative Analyst in R an.

