Cada vez que entrenas una red neuronal o incluso ajustas un modelo de regresión estás usando resultados de ecuaciones diferenciales. Las matemáticas que hay debajo son cálculo, y las ecuaciones diferenciales están en el centro. Si alguna vez te has preguntado por qué funciona el descenso por gradiente o cómo un filtro de Kalman sigue un objeto en movimiento, la respuesta está en las ecuaciones diferenciales.
Las ecuaciones diferenciales te permiten modelar cómo las cosas cambian con el tiempo, y de eso va la ciencia de datos. Cuando entiendes las ideas clave, empiezas a verlas por todas partes: en las funciones de pérdida que minimizas, en las series temporales que pronosticas y en las simulaciones que ejecutas.
En este artículo, te explico qué son las ecuaciones diferenciales, los tipos principales que verás, cómo resolverlas y, sobre todo, cómo aparecen en el día a día de la ciencia de datos y el machine learning.
¿Qué son las ecuaciones diferenciales?
Una ecuación diferencial es una ecuación que relaciona una función con sus propias derivadas.
En pocas palabras, una derivada te dice a qué velocidad cambia algo en un momento dado. Una ecuación diferencial dice que la tasa de cambio de una magnitud depende de la propia magnitud, del tiempo o de ambos.
Imagina que modelas una población de bacterias. Cuantas más bacterias hay, más rápido se reproducen. Así que la tasa de crecimiento depende del tamaño actual de la población. Si escribes eso como una ecuación, tienes una ecuación diferencial.
Formalmente, se ve así:
Representación de una ecuación diferencial
Donde P es la población, t es el tiempo y r es la tasa de crecimiento. La parte izquierda es la derivada: a qué velocidad cambia P con el tiempo. La derecha dice que ese cambio es proporcional a la propia P.
Esa es la idea central detrás de cualquier ecuación diferencial que verás.
Aparecen en física, biología e ingeniería: en cualquier lugar donde un sistema evoluciona con el tiempo. El calor que se propaga por una varilla metálica, un péndulo que oscila, un virus que se difunde por una población. Todo eso se modela con ecuaciones diferenciales.
Para perfiles de datos, verás ecuaciones diferenciales en funciones de pérdida, descenso por gradiente, modelos de series temporales, ODEs neuronales... Todas tienen ecuaciones diferenciales debajo. No siempre las ves de forma explícita, pero están ahí.
Cuando las entiendes, tienes un modelo mental más claro de por qué y cómo funcionan las herramientas que usas a diario.
Historia de las ecuaciones diferenciales
A finales del siglo XVII, Isaac Newton y Gottfried Wilhelm Leibniz desarrollaron el cálculo de forma independiente. Ambos necesitaban describir cómo cambian las magnitudes físicas con el tiempo, y de ahí nacieron las ecuaciones diferenciales. Newton las usó para modelar el movimiento y la gravedad. Leibniz nos dio buena parte de la notación que aún usamos, incluida la d/dt que verás en cualquier manual de cálculo.
Los siglos XVIII y XIX trajeron una oleada de nuevas técnicas.
Leonhard Euler desarrolló métodos para resolver EDOs numéricamente —el mismo Euler del método de Euler que verás más adelante—. Joseph-Louis Lagrange y Pierre-Simon Laplace extendieron la teoría a sistemas más complejos. Jean-Baptiste Joseph Fourier introdujo una forma de descomponer funciones en senos y cosenos, que se convirtió en pilar para resolver ecuaciones en derivadas parciales.
Ya en el siglo XX, las ecuaciones diferenciales estaban en todo: dinámica de fluidos, mecánica cuántica, ingeniería eléctrica. Muchas ecuaciones reales no tenían solución analítica limpia. Ahí es donde entran los métodos numéricos, y los ordenadores los hicieron prácticos a gran escala.
Hoy el campo sigue avanzando. Las ecuaciones diferenciales ordinarias neuronales (Neural ODEs) tratan las capas de una red neuronal como un proceso continuo descrito por una ecuación diferencial. Es un desarrollo reciente que difumina la línea entre deep learning y matemáticas clásicas. Y es una de las áreas más interesantes de la investigación moderna en ML.
Aun así, la idea central se mantiene: si modelas cómo cambian las cosas, puedes prever hacia dónde van.
Tipos de ecuaciones diferenciales
No todas las ecuaciones diferenciales son iguales. Lo primero es saber diferenciarlas.
La división principal es entre ecuaciones diferenciales ordinarias (EDO u ODE) y ecuaciones en derivadas parciales (EDP o PDE). La diferencia está en cuántas variables independientes tiene la función.
Ecuaciones diferenciales ordinarias (EDO)
Una ecuación diferencial ordinaria implica una función de una sola variable independiente y sus derivadas.
El ejemplo de la población de bacterias es una EDO. La población P depende solo del tiempo t —una variable—. Por eso la ecuación solo tiene derivadas ordinarias, escritas como dP/dt.
Las EDO son la herramienta adecuada cuando tu sistema evoluciona a lo largo de una sola dimensión, normalmente el tiempo. Aquí van algunos ejemplos clásicos:
- Crecimiento poblacional: la tasa de cambio de una población depende de su tamaño actual
- Desintegración radiactiva: la tasa a la que se desintegra una sustancia depende de cuánto queda
- Segunda ley de Newton: la aceleración de un objeto depende de las fuerzas que actúan sobre él
En cada caso, un solo factor impulsa el cambio. Por eso se llaman "ordinarias".
Ecuaciones en derivadas parciales (EDP)
Una ecuación en derivadas parciales implica una función de varias variables independientes y sus derivadas parciales.
Imagina que quieres modelar cómo se reparte el calor en una varilla metálica. La temperatura en cualquier punto depende de dónde estás a lo largo de la varilla y del momento en el tiempo. Son dos variables independientes: posición x y tiempo t. Al escribir la ecuación, aparecen derivadas parciales: una respecto a x y otra respecto a t.
Eso es una EDP. La ecuación del calor es uno de los ejemplos más conocidos:
Ejemplo de ecuación en derivadas parciales
Donde u(x, t) es la temperatura en la posición x y el tiempo t, α es la difusividad térmica del material, ∂u/∂t es la velocidad a la que cambia la temperatura en el tiempo, y ∂²u/∂x² mide la curvatura del perfil de temperatura en el espacio. La ecuación dice que donde la curva de temperatura se dobla mucho, el calor se redistribuye rápido; donde es plana, pasa poco.
Las EDP aparecen siempre que un sistema varía en el espacio y en el tiempo:
- Distribución del calor: la temperatura cambia según la posición y el tiempo
- Propagación de ondas: las ondas sonoras o de luz se extienden por el espacio con el tiempo
- Dinámica de fluidos: la velocidad del fluido depende de la posición en el espacio 3D y del tiempo
Las EDP son más difíciles de resolver que las EDO. Las soluciones analíticas existen solo para formas específicas, y a menudo los métodos numéricos son el único camino práctico.
En la mayoría del trabajo en data science te toparás más con EDO. Aun así, las EDP aparecen en procesado de imagen, simulaciones físicas y algunas arquitecturas de deep learning, así que conviene conocer las diferencias.
Orden y grado de las ecuaciones diferenciales
Cada ecuación diferencial tiene dos propiedades que indican su complejidad: su orden y su grado.
Determinan qué métodos de solución aplican, así que conviene identificarlos antes de intentar resolver nada.
Entender el orden
El orden de una ecuación diferencial es el orden de la derivada de mayor grado que aparece en la ecuación.
Si la derivada de mayor orden es de primer orden (dy/dx), es una ecuación de primer orden. Si la de mayor orden es de segundo orden (d²y/dx²), es de segundo orden. Y así sucesivamente.
Aquí está de nuevo la ecuación de crecimiento bacteriano:
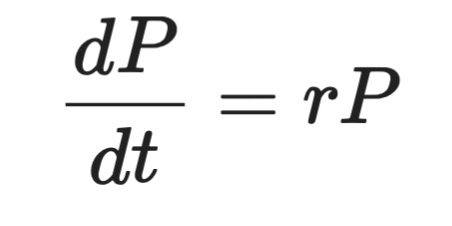
Ecuación de crecimiento bacteriano
La derivada de mayor orden es dP/dt —una primera derivada—. Es una EDO de primer orden.
Compárala ahora con la ecuación que describe un péndulo en oscilación:
Ecuación de un péndulo oscilante
La derivada de mayor orden es d²θ/dt² —una segunda derivada—. Es, por tanto, una EDO de segundo orden.
Un orden más alto implica más complejidad. Las ecuaciones de segundo orden necesitan dos condiciones iniciales en lugar de una. En la práctica, muchos sistemas físicos —movimiento mecánico, circuitos eléctricos, dinámica orbital— se modelan con ecuaciones de segundo orden.
Entender el grado
El grado de una ecuación diferencial es la potencia de la derivada de mayor orden, una vez que la ecuación está escrita en forma polinómica (sin radicales ni fracciones que involucren derivadas).
Considera esta ecuación:
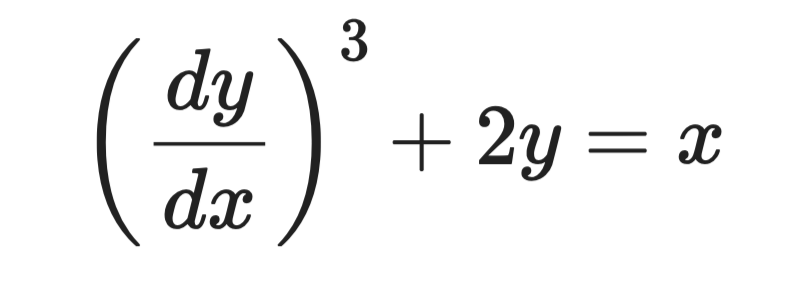
Ejemplo de ecuación diferencial
La derivada de mayor orden es dy/dx y está elevada al cubo. El orden es 1 y el grado es 3.
Ahora mira esta otra:
Ejemplo de ecuación diferencial (2)
La derivada de mayor orden es d²y/dx² y está elevada a 1. El grado es 1, aunque una derivada de menor orden aparezca con una potencia mayor.
El grado siempre se refiere a la derivada de mayor orden, no a la potencia más alta de toda la ecuación.
Hay casos límite si la ecuación contiene términos como sin(dy/dx) o e^(d²y/dx²). Entonces, el grado no está definido: esas formas no pueden expresarse como polinomios en las derivadas.
Métodos para resolver ecuaciones diferenciales
No hay un único método que sirva para todas. El enfoque adecuado depende del tipo de ecuación, su orden y de si existe una solución exacta.
En general, tienes dos grandes categorías: métodos analíticos y métodos numéricos.
Métodos analíticos
Los métodos analíticos te dan una solución exacta en forma cerrada, una fórmula que puedes evaluar en cualquier punto. Son preferibles cuando aplican porque el resultado es preciso y te revela la estructura de la solución.
Pero solo funcionan para formas específicas. Cuando la ecuación se complica, estos métodos tocan techo.
Separación de variables
La separación de variables sirve para ecuaciones en las que puedes aislar todos los términos con y a un lado y todos los términos con x (o t) al otro.
Toma esta EDO de primer orden:
Ecuación diferencial simple
Paso 1: separa las variables.
Solución analítica (paso 1)
Paso 2: integra ambos lados.
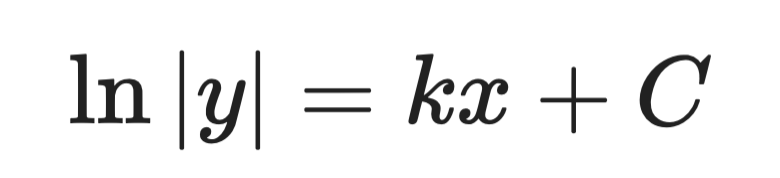
Solución analítica (paso 2)
Paso 3: despeja y.
Solución analítica (paso 3)
Donde A es una constante determinada por las condiciones iniciales. Esa es la solución general.
Tiene la misma forma que la ecuación de crecimiento bacteriano. Te dice que las poblaciones —y cualquier cosa cuya tasa de crecimiento sea proporcional a su tamaño— crecen exponencialmente.
Factores integrantes
Los factores integrantes se aplican a EDOs lineales de primer orden de esta forma:
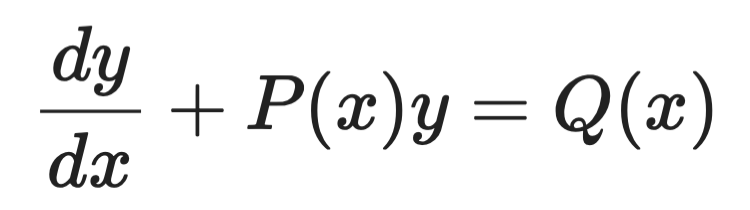
Ejemplo de factores integrantes (1)
La idea es multiplicar ambos lados por una función elegida cuidadosamente —el factor integrante μ(x)— que convierte el lado izquierdo en una derivada perfecta que puedes integrar directamente.
El factor integrante siempre es:
Ejemplo de factores integrantes (2)
Tras multiplicar, la ecuación queda:
Ejemplo de factores integrantes (3)
Luego integras ambos lados y despejas y. El lado izquierdo se simplifica justo por cómo elegiste μ(x): ese es el truco del método.
Métodos numéricos
La mayoría de ecuaciones diferenciales reales no tienen soluciones analíticas limpias. Los métodos numéricos aproximan la solución paso a paso, calculando valores en puntos discretos.
Cambian exactitud por generalidad. Y en la práctica, suele ser justo lo que necesitas.
Método de Euler
El método de Euler es el enfoque numérico más sencillo. Empiezas en un punto conocido, usas la derivada para estimar la pendiente, das un pequeño paso en esa dirección y repites.
Dada una EDO de primer orden dy/dx = f(x, y) con condición inicial y(x₀) = y₀, cada paso es:
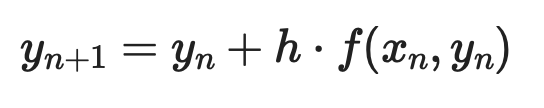
Ejemplo del método de Euler (1)
Donde h es el tamaño de paso. Pasos más pequeños implican más precisión, pero más cómputo.
Aquí tienes una implementación en Python para resolver dy/dx = y con y(0) = 1 (la solución exacta es y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Método de Euler frente a la solución exacta
La distancia entre ambas líneas es el error de aproximación. Con h=0.2, el error es pequeño al principio pero se acumula con los pasos: esa es la principal debilidad del método de Euler.
Métodos de Runge-Kutta
Los métodos de Runge-Kutta corrigen ese problema de acumulación de error muestreando la pendiente en varios puntos dentro de cada paso y haciendo un promedio ponderado. La versión más común es RK4 —el método de Runge-Kutta de cuarto orden—.
En lugar de una única estimación de pendiente por paso como Euler, RK4 calcula cuatro:
Ejemplo del método de Runge-Kutta (1)
Y luego las combina:
Ejemplo del método de Runge-Kutta (2)
En la práctica, no implementas RK4 a mano. solve_ivp de SciPy lo resuelve por ti:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 frente a la solución exacta
La línea de RK45 queda prácticamente encima de la solución exacta. Con el mismo tamaño de paso que en el ejemplo de Euler, pero mucha más precisión: esa es la diferencia que aporta el muestreo ponderado de pendientes.
Para la mayoría de trabajos en Python, tu opción por defecto es solve_ivp con el solver RK45. El método de Euler es útil para entender cómo funcionan los solvers numéricos, pero no lo usarías en producción.
Aplicaciones de las ecuaciones diferenciales en data science y machine learning
Las ecuaciones diferenciales las usan ingenieros para modelar circuitos y sistemas mecánicos. Biólogos para poblaciones y propagación de enfermedades. Físicos para describir desde transferencia de calor hasta mecánica cuántica.
Pero tú estás aquí por la ciencia de datos, así que vamos a ello.
Machine learning y optimización
La conexión más directa entre ecuaciones diferenciales y ML es el descenso por gradiente, el algoritmo detrás del entrenamiento de casi cualquier modelo que construyas.
Al entrenar un modelo, minimizas una función de pérdida L. Para lograrlo, necesitas saber cómo cambia L cuando ajustas cada parámetro. Esa tasa de cambio es una derivada. Cuando el modelo tiene varios parámetros, calculas una derivada parcial para cada uno: juntas forman el gradiente.
El descenso por gradiente usa esas derivadas para actualizar parámetros paso a paso:
Descenso por gradiente
Donde θ es el parámetro, η la tasa de aprendizaje y ∂L/∂θ la derivada parcial de la pérdida respecto a ese parámetro.
Aquí tienes un ejemplo sencillo en Python que ajusta una recta a datos con descenso por gradiente:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Descenso por gradiente ajustando una recta y la curva de pérdida por iteraciones
Cada iteración mueve los parámetros en la dirección que reduce la pérdida. Las derivadas parciales te dicen cuál es esa dirección. Sin ellas, el descenso por gradiente no funciona, y tampoco el backpropagation en redes neuronales, que no es más que aplicar la regla de la cadena capa a capa.
Análisis de series temporales
Muchas series temporales son dinámicas: el valor actual depende del pasado y de a qué velocidad cambian las cosas. Las ecuaciones diferenciales permiten describirlo.
El filtro de Kalman, muy usado en seguimiento y forecasting, se basa en un sistema de ecuaciones diferenciales que modela cómo evoluciona un estado oculto con el tiempo y cómo las observaciones ruidosas se relacionan con ese estado. Se usa en GPS, finanzas y meteorología.
Los modelos ARIMA se emplean para pronosticar series temporales y se conectan con ecuaciones diferenciales a través del concepto de diferenciación. Tomar diferencias de primer o segundo orden es una aproximación discreta de derivadas primera y segunda. Cuando diferencias una serie para hacerla estacionaria, te preguntas: ¿cómo está cambiando esta serie con el tiempo?
Modelado estadístico y regresión
Esto suele sorprender: resolver un sistema de ecuaciones te lleva a derivar los coeficientes de regresión lineal.
Al ajustar una regresión lineal, minimizas la suma de residuos al cuadrado. Tomas la derivada parcial de esa pérdida respecto a cada coeficiente, la igualas a cero y resuelves. Eso te da la ecuación normal:
Ecuación normal
Cada coeficiente de regresión que has calculado sale de poner una derivada a cero y resolver. Eso es cálculo, y es el mismo principio detrás de cualquier modelo paramétrico que ajustas.
En regresión logística, la función de pérdida no es cuadrática, así que no hay solución cerrada. Tienes que usar métodos iterativos como descenso por gradiente, que, de nuevo, dependen de derivadas parciales en cada paso.
La conexión va más allá. La descomposición QR, uno de los métodos numéricos estándar para resolver la ecuación normal, se basa en álgebra lineal que conecta directamente con cómo se resuelven en la práctica los sistemas de ecuaciones, incluidas las diferenciales.
Simulación de sistemas dinámicos
Cuando necesitas modelar cómo evoluciona un sistema en el tiempo y no existe solución analítica, lo simulas numéricamente.
Esto es común en negocios y operaciones. La pérdida de clientes, los niveles de inventario y la dinámica de la cadena de suministro implican magnitudes que cambian según el estado actual. Puedes escribir esas relaciones como ecuaciones diferenciales y simularlas con solve_ivp.
Aquí tienes un ejemplo que simula un sistema simple de oferta y demanda donde el inventario I se agota a un ritmo proporcional a la demanda D, y la demanda varía con el tiempo:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)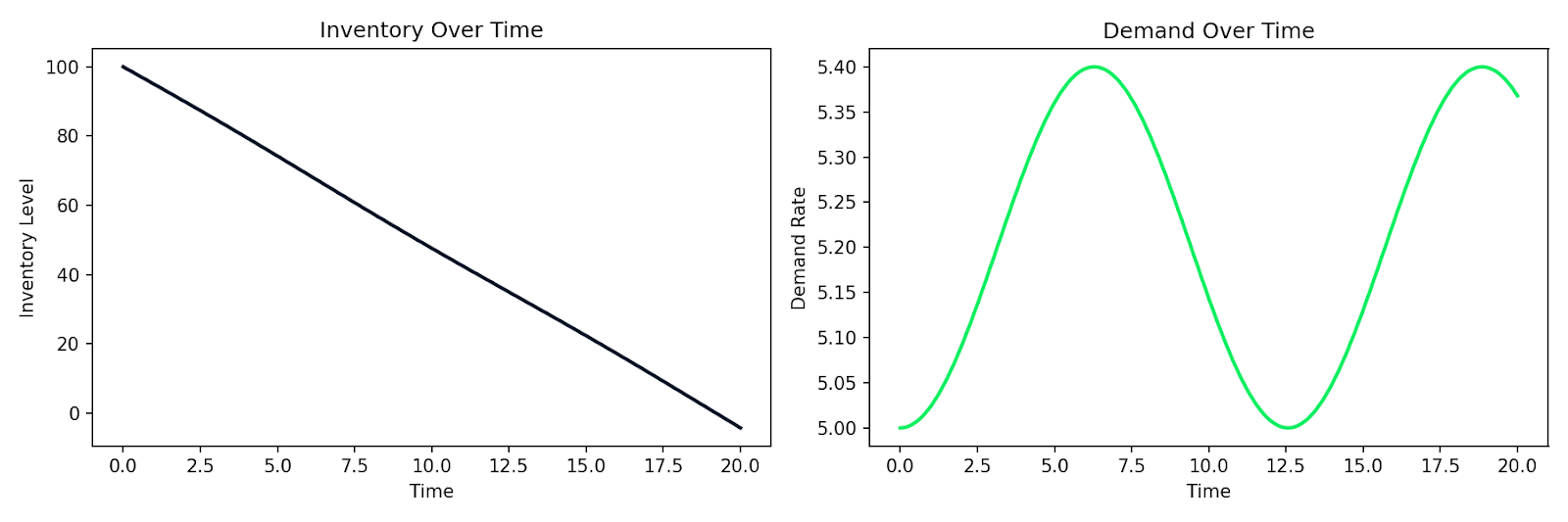
Simulación del agotamiento del inventario junto con la demanda fluctuante en el tiempo
El mismo patrón aplica al modelado del comportamiento de clientes, la propagación de una epidemia en una base de usuarios o cualquier sistema donde la tasa de cambio depende del estado actual. Escribes las relaciones, se las pasas a un solver numérico y obtienes una simulación.
Esa es la fuerza práctica de las ecuaciones diferenciales en data science: una herramienta directa para modelar sistemas que cambian.
Conclusión
Detrás del descenso por gradiente hay derivadas parciales. Detrás del forecasting de series temporales hay sistemas dinámicos. Detrás de los coeficientes de regresión lineal hay derivadas igualadas a cero. Solo necesitas saber dónde mirar.
En este artículo he explicado qué son las ecuaciones diferenciales, la diferencia entre EDO y EDP, cómo el orden y el grado las clasifican y los métodos principales para resolverlas —tanto analíticos como numéricos—. Luego hemos visto dónde aparecen realmente en la ciencia de datos y el machine learning del día a día.
Esto es solo la base. Si quieres explorar más matemáticas, el curso Linear Algebra for Data Science in R es un buen siguiente paso. Para practicar con datos reales, echa un vistazo a nuestro curso Quantitative Analyst in R.
