จริงๆ แล้ว ผลลัพธ์ของสมการเชิงอนุพันธ์ถูกใช้อยู่ทุกครั้งที่ฝึกเครือข่ายประสาทเทียมหรือแม้แต่การฟิตแบบจำลองรีเกรสชัน คณิตศาสตร์ใต้ฝากระโปรงคือแคลคูลัส และสมการเชิงอนุพันธ์คือหัวใจของมัน หากเคยสงสัยว่าทำไมเกรเดียนต์ดีเซนต์ถึงทำงานได้ หรือคาลมานฟิลเตอร์ติดตามวัตถุที่เคลื่อนที่ได้อย่างไร คำตอบอยู่ที่สมการเชิงอนุพันธ์
สมการเชิงอนุพันธ์ช่วยให้จำลองว่าอะไรบางอย่าง เปลี่ยนไปตามเวลา อย่างไร — ซึ่งตรงกับสิ่งที่ดาต้าไซเอนซ์ทำ เมื่อเข้าใจแนวคิดแกนกลางแล้ว จะเริ่มเห็นมันทุกที่: ในฟังก์ชันสูญเสียที่ทำให้ต่ำสุด ซีรีส์เวลา (time series) ที่พยากรณ์ และการจำลองที่รัน
บทความนี้จะพาไปรู้จักว่าสมการเชิงอนุพันธ์คืออะไร ชนิดหลักๆ ที่พบบ่อย วิธีการแก้ และที่สำคัญที่สุด — มันปรากฏในงานดาต้าไซเอนซ์และแมชชีนเลิร์นนิงจริงในแต่ละวันอย่างไร
สมการเชิงอนุพันธ์คืออะไร?
สมการเชิงอนุพันธ์คือสมการที่สัมพันธ์ฟังก์ชันหนึ่งเข้ากับอนุพันธ์ของตัวมันเอง
พูดง่ายๆ อนุพันธ์บอกว่าอะไรบางอย่างกำลังเปลี่ยนเร็วแค่ไหน ณ ชั่วขณะหนึ่ง สมการเชิงอนุพันธ์บอกว่าอัตราการเปลี่ยนแปลงของปริมาณหนึ่งขึ้นอยู่กับตัวปริมาณนั้นเอง หรือขึ้นอยู่กับเวลา หรือทั้งสองอย่าง
สมมติจะจำลองจำนวนประชากรแบคทีเรีย ยิ่งมีแบคทีเรียมาก ก็ยิ่งขยายพันธุ์เร็ว อัตราการเติบโตจึงขึ้นอยู่กับขนาดประชากรปัจจุบัน เขียนเป็นสมการก็จะได้สมการเชิงอนุพันธ์
ในรูปแบบทางการ จะมีหน้าตาแบบนี้:
ตัวอย่างการเขียนสมการเชิงอนุพันธ์
โดยที่ P คือประชากร t คือเวลา และ r คืออัตราการเติบโต ด้านซ้ายคืออนุพันธ์ — ความเร็วที่ P เปลี่ยนไปตามเวลา ด้านขวาบอกว่าการเปลี่ยนแปลงแปรผันตาม P เอง
นี่คือแนวคิดแกนกลางของสมการเชิงอนุพันธ์ทั้งหมดที่พบเห็น
สมการเชิงอนุพันธ์พบได้ในฟิสิกส์ ชีววิทยา และวิศวกรรม — ทุกที่ที่ระบบเปลี่ยนแปลงตามเวลา การแพร่กระจายของความร้อนในแท่งโลหะ ลูกตุ้มที่แกว่ง การแพร่ระบาดของไวรัสในประชากร ทั้งหมดนี้จำลองด้วยสมการเชิงอนุพันธ์
สำหรับดาต้าไซเอนติสต์ จะพบสมการเชิงอนุพันธ์ในฟังก์ชันสูญเสีย เกรเดียนต์ดีเซนต์ แบบจำลองซีรีส์เวลา neural ODE — ทั้งหมดนี้มีสมการเชิงอนุพันธ์อยู่เบื้องหลัง อาจไม่ปรากฏให้เห็นชัด แต่มีอยู่แน่นอน
เมื่อเข้าใจแล้ว แบบจำลองทางความคิดเกี่ยวกับเหตุและผลของเครื่องมือที่ใช้ทุกวันจะชัดเจนยิ่งขึ้น
ประวัติของสมการเชิงอนุพันธ์
ปลายศตวรรษที่ 17 ไอแซก นิวตัน และกอทท์ฟรีด วิลเฮล์ม ไลบ์นิซ พัฒนาแคลคูลัสอย่างอิสระต่อกัน ทั้งสองต้องการวิธีอธิบายว่า ปริมาณทางกายภาพเปลี่ยนไปตามเวลาอย่างไร และได้สมการเชิงอนุพันธ์เป็นผลลัพธ์ นิวตันใช้จำลองการเคลื่อนที่และแรงโน้มถ่วง ไลบ์นิซให้สัญลักษณ์ที่ยังใช้กันจนวันนี้ รวมถึง d/dt ที่เห็นในตำราแคลคูลัสทุกเล่ม
ศตวรรษที่ 18 และ 19 นำมาซึ่งเทคนิคใหม่ๆ จำนวนมาก
เลออนฮาร์ด ออยเลอร์ พัฒนาวิธีแก้ ODE แบบเชิงตัวเลข — คือออยเลอร์คนเดียวกับ “วิธีของออยเลอร์” ที่จะเห็นต่อไป โจแซฟ-หลุยส์ ลากร็องจ์ และปิแยร์-ซีมง ลาปลาซ ขยายทฤษฎีไปสู่ระบบที่ซับซ้อนยิ่งขึ้น ฌ็อง-บาติสต์ โจแซฟ ฟูริเยร์ แนะนำการแยกฟังก์ชันเป็นองค์ประกอบไซน์และโคไซน์ ซึ่งกลายเป็นรากฐานของการแก้สมการเชิงอนุพันธ์ย่อย (PDE)
เข้าสู่ศตวรรษที่ 20 สมการเชิงอนุพันธ์พบได้ทั่วไปตั้งแต่พลศาสตร์ของไหล กลศาสตร์ควอนตัม ไปจนถึงวิศวกรรมไฟฟ้า สมการโลกจริงจำนวนมากไม่มีวิธีแก้เชิงวิเคราะห์ที่สะอาดชัดเจน วิธีเชิงตัวเลขจึงเข้ามามีบทบาท และคอมพิวเตอร์ทำให้ใช้งานได้ในสเกลใหญ่
ปัจจุบันสาขานี้ยังพัฒนาอย่างต่อเนื่อง Neural ordinary differential equations (Neural ODEs) มองเลเยอร์ของโครงข่ายประสาทเป็นกระบวนการต่อเนื่องที่อธิบายด้วยสมการเชิงอนุพันธ์ เป็นความก้าวหน้าล่าสุดที่เบลอเส้นแบ่งระหว่างดีปเลิร์นนิงกับคณิตศาสตร์คลาสสิก และเป็นหนึ่งในหัวข้อที่น่าตื่นเต้นในงานวิจัย ML สมัยใหม่
กระนั้น แนวคิดแกนกลางยังเหมือนเดิม: จำลองว่าของเปลี่ยนอย่างไร แล้วจะทำนายได้ว่ามันกำลังไปทางไหน
ชนิดของสมการเชิงอนุพันธ์
สมการเชิงอนุพันธ์ไม่ได้เหมือนกันทั้งหมด สิ่งแรกที่ต้องรู้คือจะแยกแยะอย่างไร
การแบ่งหลักคือระหว่างสมการเชิงอนุพันธ์สามัญ (ODE) และสมการเชิงอนุพันธ์ย่อย (PDE) ความแตกต่างอยู่ที่จำนวนตัวแปรอิสระที่ฟังก์ชันขึ้นอยู่ด้วย
สมการเชิงอนุพันธ์สามัญ (ODE)
สมการเชิงอนุพันธ์สามัญเกี่ยวข้องกับฟังก์ชันของตัวแปรอิสระเพียงตัวเดียวและอนุพันธ์ของมัน
ตัวอย่างประชากรแบคทีเรียก่อนหน้าคือ ODE ประชากร P ขึ้นอยู่กับเวลา t เพียงตัวแปรเดียว ดังนั้นสมการจึงมีอนุพันธ์สามัญ เขียนเป็น dP/dt
ODE เหมาะเมื่อระบบของเปลี่ยนไปตามมิติเดียว โดยมากคือเวลา ตัวอย่างคลาสสิก:
- การเติบโตของประชากร — อัตราการเปลี่ยนแปลงของประชากรขึ้นอยู่กับขนาดประชากรปัจจุบัน
- การสลายกัมมันตรังสี — อัตราการสลายของสารขึ้นอยู่กับปริมาณที่เหลืออยู่
- กฎข้อที่สองของนิวตัน — ความเร่งของวัตถุขึ้นอยู่กับแรงที่กระทำต่อมัน
ในแต่ละกรณี มีตัวแปรตัวเดียวที่ขับเคลื่อนการเปลี่ยนแปลง นั่นคือเหตุผลที่เรียกว่า “สามัญ”
สมการเชิงอนุพันธ์ย่อย (PDE)
สมการเชิงอนุพันธ์ย่อยเกี่ยวข้องกับฟังก์ชันของตัวแปรอิสระหลายตัวและอนุพันธ์ย่อยของมัน
สมมติอยากจำลองการแพร่กระจายของความร้อนในแท่งโลหะ อุณหภูมิ ณ จุดใดขึ้นอยู่ทั้งกับตำแหน่งตามความยาวแท่งและเวลา นั่นคือตัวแปรอิสระสองตัว: ตำแหน่ง x และเวลา t เมื่อเขียนสมการ จะได้อนุพันธ์ย่อย — ตัวหนึ่งตาม x และอีกตัวตาม t
นั่นคือ PDE สมการความร้อนเป็นตัวอย่างที่รู้จักกันดี:
ตัวอย่างสมการเชิงอนุพันธ์ย่อย
โดยที่ u(x, t) คืออุณหภูมิที่ตำแหน่ง x และเวลา t, α คือสัมประสิทธิ์การแพร่ความร้อนของวัสดุ, ∂u/∂t คืออัตราการเปลี่ยนของอุณหภูมิตามเวลา และ ∂²u/∂x² คือความโค้งของโปรไฟล์อุณหภูมิในเชิงพื้นที่ สมการบอกว่าจุดที่เส้นโค้งอุณหภูมิโค้งมาก ความร้อนจะกระจายตัวเร็ว จุดที่ราบเรียบ การเปลี่ยนแปลงจะน้อย
PDE ปรากฏในทุกที่ที่ระบบแปรผันทั้งตามพื้นที่และเวลา:
- การกระจายความร้อน — อุณหภูมิเปลี่ยนทั้งตามตำแหน่งและเวลา
- การแพร่กระจายของคลื่น — คลื่นเสียงหรือแสงแผ่ไปในอวกาศตามเวลา
- พลศาสตร์ของไหล — ความเร็วของของไหลขึ้นอยู่กับตำแหน่งในอวกาศสามมิติและเวลา
PDE แก้ยากกว่า ODE วิธีเชิงวิเคราะห์มีเฉพาะบางรูปแบบ และวิธีเชิงตัวเลขมักเป็นหนทางปฏิบัติที่ใช้ได้จริง
ในงานดาต้าไซเอนซ์ส่วนใหญ่ จะเจอ ODE บ่อยกว่า แต่ PDE ก็พบในงานประมวลผลภาพ การจำลองทางฟิสิกส์ และสถาปัตยกรรมดีปเลิร์นนิงบางประเภท จึงควรรู้ความแตกต่างไว้
อันดับ (Order) และดีกรี (Degree) ของสมการเชิงอนุพันธ์
สมการเชิงอนุพันธ์แต่ละสมการมีสองคุณสมบัติที่บอกระดับความซับซ้อน: อันดับและดีกรี
สองอย่างนี้กำหนดว่าวิธีแก้ใดใช้ได้ จึงควรระบุก่อนลงมือแก้
ทำความเข้าใจ “อันดับ”
อันดับของสมการเชิงอนุพันธ์คืออันดับของอนุพันธ์ที่มีลำดับสูงสุดในสมการนั้น
ถ้าอนุพันธ์สูงสุดเป็นอนุพันธ์อันดับหนึ่ง (dy/dx) ก็เป็นสมการอันดับหนึ่ง ถ้าอนุพันธ์สูงสุดเป็นอนุพันธ์อันดับสอง (d²y/dx²) ก็เป็นสมการอันดับสอง และต่อไปเรื่อยๆ
นี่คือสมการการเติบโตของแบคทีเรียจากก่อนหน้า:
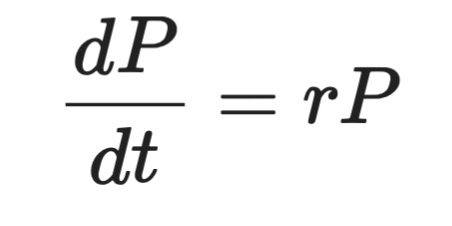
สมการการเติบโตของแบคทีเรีย
อนุพันธ์สูงสุดคือ dP/dt — อนุพันธ์อันดับหนึ่ง จึงเป็น ODE อันดับหนึ่ง
เปรียบเทียบกับสมการที่อธิบายลูกตุ้มที่แกว่ง:
สมการลูกตุ้มที่แกว่ง
อนุพันธ์สูงสุดคือ d²θ/dt² — อนุพันธ์อันดับสอง จึงเป็น ODE อันดับสอง
อันดับที่สูงขึ้นหมายถึงความซับซ้อนมากขึ้น สมการอันดับสองต้องมีเงื่อนไขเริ่มต้นสองค่าแทนที่จะเป็นหนึ่ง ค่า ในทางปฏิบัติ ระบบทางกายภาพส่วนใหญ่ — การเคลื่อนที่เชิงกล วงจรไฟฟ้า กลศาสตร์วงโคจร — มักจำลองด้วยสมการอันดับสอง
ทำความเข้าใจ “ดีกรี”
ดีกรีของสมการเชิงอนุพันธ์คือกำลังของอนุพันธ์ที่มีอันดับสูงสุด เมื่อเขียนสมการอยู่ในรูปพหุนาม (ไม่มีรากที่สองหรือเศษส่วนที่เกี่ยวกับอนุพันธ์)
พิจารณาสมการนี้:
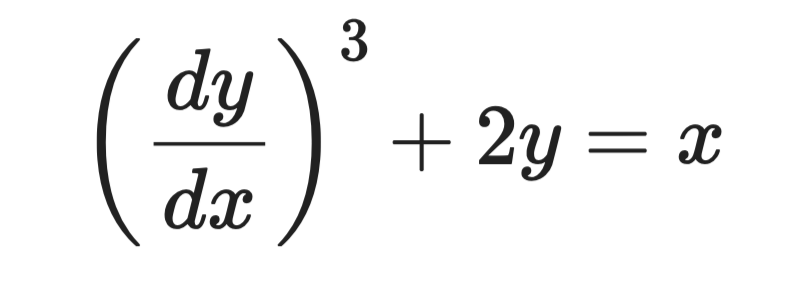
ตัวอย่างสมการเชิงอนุพันธ์
อนุพันธ์สูงสุดคือ dy/dx และถูกยกกำลัง 3 ดังนั้นอันดับคือ 1 และดีกรีคือ 3
ต่อไปดูสมการนี้:
ตัวอย่างสมการเชิงอนุพันธ์ (2)
อนุพันธ์อันดับสูงสุดคือ d²y/dx² ที่มีกำลัง 1 ดีกรีจึงเป็น 1 แม้ว่าอนุพันธ์อันดับต่ำกว่าจะปรากฏด้วยกำลังที่สูงกว่า
ดีกรีจะอิงกับอนุพันธ์อันดับสูงสุดเสมอ ไม่ใช่กำลังสูงสุดในสมการ
กรณีขอบคือเมื่อสมการมีพจน์อย่าง sin(dy/dx) หรือ e^(d²y/dx²) ดีกรีจะไม่ถูกกำหนด — รูปเหล่านี้ไม่สามารถเขียนเป็นพหุนามของอนุพันธ์ได้
วิธีการแก้สมการเชิงอนุพันธ์
ไม่มีวิธีเดียวที่ใช้ได้กับสมการเชิงอนุพันธ์ทุกสมการ วิธีที่เหมาะขึ้นอยู่กับชนิด อันดับ และว่าสามารถหาวิธีแก้เชิงวิเคราะห์ได้หรือไม่
โดยกว้างๆ แบ่งเป็นสองกลุ่ม:วิธีเชิงวิเคราะห์ และวิธีเชิงตัวเลข
วิธีเชิงวิเคราะห์
วิธีเชิงวิเคราะห์ให้วิธีแก้แบบปิดรูปที่แน่นอน — สูตรที่คำนวณค่าได้ทุกจุด มักเลือกใช้เมื่อทำได้ เพราะผลลัพธ์แม่นยำและบอกโครงสร้างของวิธีแก้ได้
แต่ใช้ได้เฉพาะสมการบางรูปแบบ เมื่อสมการซับซ้อนเกินไป วิธีเชิงวิเคราะห์จะไปต่อไม่ได้
การแยกตัวแปร (Separation of variables)
ใช้ได้กับสมการที่สามารถแยกพจน์ทั้งหมดที่เกี่ยวกับy ไว้ด้านหนึ่ง และพจน์ที่เกี่ยวกับ x (หรือ t) ไว้อีกด้านหนึ่ง
พิจารณา ODE อันดับหนึ่งนี้:
สมการเชิงอนุพันธ์อย่างง่าย
ขั้นที่ 1 — แยกตัวแปร:
วิธีเชิงวิเคราะห์ (ขั้นที่ 1)
ขั้นที่ 2 — อินทิเกรตทั้งสองข้าง:
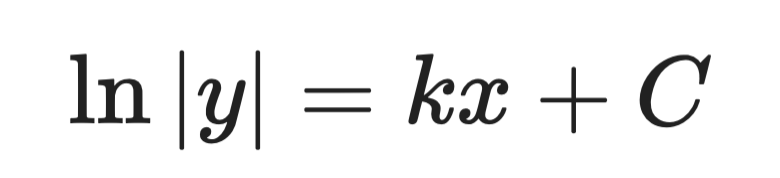
วิธีเชิงวิเคราะห์ (ขั้นที่ 2)
ขั้นที่ 3 — จัดรูปหาy:
วิธีเชิงวิเคราะห์ (ขั้นที่ 3)
โดยที่ A เป็นค่าคงที่กำหนดโดยเงื่อนไขตั้งต้น นี่คือวิธีแก้ทั่วไป
รูปแบบนี้เหมือนกับสมการการเติบโตของแบคทีเรีย บอกว่าประชากร — และสิ่งใดๆ ที่อัตราเติบโตแปรผันตามขนาด — จะเติบโตแบบเอ็กซ์โปเนนเชียล
ตัวประกอบอินทิเกรต (Integrating factors)
ใช้กับ ODE อันดับหนึ่งเชิงเส้นในรูปแบบนี้:
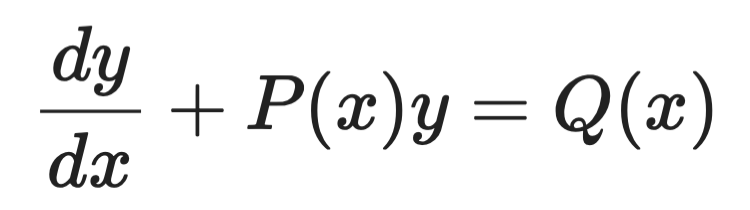
ตัวอย่างตัวประกอบอินทิเกรต (1)
แนวคิดคือคูณทั้งสองข้างด้วยฟังก์ชันที่เลือกอย่างเหมาะสม — ตัวประกอบอินทิเกรต μ(x) — เพื่อทำให้ฝั่งซ้ายกลายเป็นอนุพันธ์สมบูรณ์ที่อินทิเกรตได้โดยตรง
ตัวประกอบอินทิเกรตคือ:
ตัวอย่างตัวประกอบอินทิเกรต (2)
หลังจากคูณ จะได้สมการ:
ตัวอย่างตัวประกอบอินทิเกรต (3)
จากนั้นอินทิเกรตทั้งสองข้างและจัดรูปหา y ฝั่งซ้ายจะยุบตัวอย่างเป็นระเบียบเพราะเราเลือก μ(x) มาให้เป็นเช่นนั้น — นี่คือแก่นของวิธีนี้
วิธีเชิงตัวเลข
สมการเชิงอนุพันธ์โลกจริงส่วนใหญ่ไม่มีวิธีแก้เชิงวิเคราะห์ที่สวยงาม วิธีเชิงตัวเลขจะประมาณวิธีแก้ทีละขั้น โดยคำนวณค่าที่จุดไม่ต่อเนื่อง
เป็นการแลกความแม่นเป๊ะกับความทั่วไป ซึ่งในทางปฏิบัติมักเป็นสิ่งที่ต้องการ
วิธีของออยเลอร์ (Euler's method)
วิธีของออยเลอร์เป็นแนวทางเชิงตัวเลขที่ง่ายที่สุด เริ่มจากจุดที่ทราบ ใช้อนุพันธ์ประมาณความชัน ก้าวเล็กๆ ไปในทิศนั้น แล้วทำซ้ำ
ให้ ODE อันดับหนึ่ง dy/dx = f(x, y) พร้อมเงื่อนไขตั้งต้น y(x₀) = y₀ แต่ละก้าวคำนวณดังนี้:
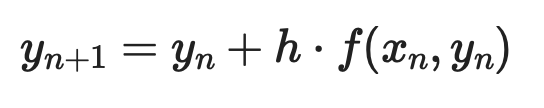
ตัวอย่างวิธีของออยเลอร์ (1)
โดยที่ h คือขนาดก้าว ก้าวเล็กลงแม่นยำขึ้น — แต่ต้องคำนวณมากขึ้น
นี่คือตัวอย่าง Python แก้ dy/dx = y ที่ y(0) = 1 (วิธีแก้จริงคือ y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
วิธีของออยเลอร์เทียบกับวิธีแก้จริง
ช่องว่างระหว่างสองเส้นคือความคลาดเคลื่อนจากการประมาณ ด้วย h=0.2 ความผิดพลาดจะน้อยในตอนแรกแต่สะสมต่อเนื่องในแต่ละก้าว — นี่คือจุดอ่อนหลักของวิธีออยเลอร์
วิธีรุนเก–คุตตา (Runge-Kutta)
วิธีรุนเก–คุตตาช่วยลดปัญหาความผิดพลาดที่สะสม โดยสุ่มตัวอย่างความชันหลายจุดในแต่ละก้าวแล้วถัวเฉลี่ยถ่วงน้ำหนัก รุ่นที่พบบ่อยที่สุดคือRK4 — Runge-Kutta อันดับสี่
แทนที่จะใช้ค่าประมาณความชันเพียงจุดเดียวแบบออยเลอร์ RK4 คำนวณสี่ค่า:
ตัวอย่างวิธีรุนเก–คุตตา (1)
จากนั้นรวมกันเป็นหนึ่งค่า:
ตัวอย่างวิธีรุนเก–คุตตา (2)
ในทางปฏิบัติ ไม่ต้องลงมือเขียน RK4 เอง SciPy solve_ivp จัดการให้:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 เทียบกับวิธีแก้จริง
เส้น RK45 ซ้อนทับวิธีแก้จริงแทบสนิท ใช้ขนาดก้าวเท่ากับตัวอย่างออยเลอร์ แต่ได้ความแม่นยำดีกว่ามาก — นั่นคือผลของการเฉลี่ยความชันแบบถ่วงน้ำหนัก
สำหรับงาน Python ส่วนใหญ่ solve_ivp พร้อมตัวแก้ RK45 ดีฟอลต์คือเครื่องมือหลัก วิธีของออยเลอร์มีประโยชน์เพื่อทำความเข้าใจหลักการของตัวแก้เชิงตัวเลข แต่ไม่ควรใช้ในงานโปรดักชัน
การประยุกต์ใช้สมการเชิงอนุพันธ์ในดาต้าไซเอนซ์และแมชชีนเลิร์นนิง
วิศวกรใช้สมการเชิงอนุพันธ์จำลองวงจรไฟฟ้าและระบบเชิงกล นักชีววิทยาใช้ติดตามไดนามิกส์ของประชากรและการแพร่โรค นักฟิสิกส์ใช้บรรยายทุกอย่างตั้งแต่การถ่ายเทความร้อนไปจนถึงกลศาสตร์ควอนตัม
แต่นี่เรามาในมุมดาต้าไซเอนซ์ มาดูกันตรงๆ
แมชชีนเลิร์นนิงและการทำให้เหมาะที่สุด
ความเชื่อมโยงที่ชัดที่สุดระหว่างสมการเชิงอนุพันธ์และ ML คือเกรเดียนต์ดีเซนต์ — อัลกอริทึมเบื้องหลังการฝึกแทบทุกโมเดล
เมื่อฝึกโมเดล กำลังทำให้ฟังก์ชันสูญเสีย L ต่ำสุด เพื่อทำเช่นนั้น ต้องรู้ว่า L เปลี่ยนอย่างไรเมื่อปรับแต่ละพารามิเตอร์ อัตราการเปลี่ยนนี้คืออนุพันธ์ เมื่อโมเดลมีหลายพารามิเตอร์ จะคำนวณอนุพันธ์ย่อยสำหรับแต่ละตัว และรวมกันเป็นเกรเดียนต์
เกรเดียนต์ดีเซนต์ใช้อนุพันธ์เหล่านั้นอัปเดตพารามิเตอร์ทีละก้าว:
เกรเดียนต์ดีเซนต์
โดยที่ θ คือพารามิเตอร์ η คือค่าเรียนรู้ และ ∂L/∂θ คืออนุพันธ์ย่อยของฟังก์ชันสูญเสียต่อพารามิเตอร์นั้น
ตัวอย่าง Python ง่ายๆ ฟิตเส้นตรงกับข้อมูลโดยใช้เกรเดียนต์ดีเซนต์:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
การฟิตเส้นด้วยเกรเดียนต์ดีเซนต์และกราฟการลดลงของค่า loss ตามรอบ
แต่ละรอบจะขยับพารามิเตอร์ไปในทิศที่ลดค่า loss อนุพันธ์ย่อยจะบอกทิศทางนั้น ถ้าไม่มีมัน เกรเดียนต์ดีเซนต์จะทำงานไม่ได้ — และการถ่ายทอดย้อนกลับ (backpropagation) ในโครงข่ายประสาทก็เช่นกัน ซึ่งแท้จริงคือการใช้กฎลูกโซ่ซ้ำๆ ผ่านเลเยอร์
การวิเคราะห์อนุกรมเวลา
หลายระบบของซีรีส์เวลาเป็นไดนามิก — ค่าปัจจุบันขึ้นอยู่กับค่าที่ผ่านมาและอัตราการเปลี่ยน สมการเชิงอนุพันธ์ช่วยอธิบายสิ่งนี้ได้
คาลมานฟิลเตอร์ ซึ่งใช้กันกว้างขวางในการติดตามและพยากรณ์ สร้างบนระบบสมการเชิงอนุพันธ์ที่จำลองสถานะแฝงซึ่งเปลี่ยนไปตามเวลา และความสัมพันธ์ของการสังเกตที่มีสัญญาณรบกวนกับสถานะนั้น ใช้ในระบบ GPS การเงิน และพยากรณ์อากาศ
แบบจำลอง ARIMA ใช้สำหรับการพยากรณ์ซีรีส์เวลา และเชื่อมกับสมการเชิงอนุพันธ์ผ่านแนวคิดของการหาความต่าง (differencing) การหาความต่างอันดับหนึ่งหรือสองคือการประมาณเชิงไม่ต่อเนื่องของอนุพันธ์อันดับหนึ่งและสอง เมื่อทำ differencing เพื่อทำให้ซีรีส์นิ่ง กำลังถามว่า: ซีรีส์นี้กำลังเปลี่ยนไปตามเวลาอย่างไร?
แบบจำลองเชิงสถิติและรีเกรสชัน
มีเรื่องหนึ่งที่หลายคนแปลกใจ: การแก้ระบบสมการเชิงอนุพันธ์เป็นหนึ่งในวิธีอนุมานค่าสัมประสิทธิ์ของ รีเกรสชันเชิงเส้น
เมื่อฟิตโมเดลรีเกรสชันเชิงเส้น กำลังทำให้ผลรวมกำลังสองของเศษเหลือน้อยที่สุด หาอนุพันธ์ย่อยของฟังก์ชันสูญเสียต่อแต่ละสัมประสิทธิ์ ตั้งให้เป็นศูนย์ แล้วแก้ จะได้ สมการปกติ (Normal Equation):
สมการปกติ
ค่าสัมประสิทธิ์รีเกรสชันทุกค่าที่เคยคำนวณมาจากการตั้งอนุพันธ์ให้เป็นศูนย์แล้วแก้ นั่นคือแคลคูลัส — และเป็นหลักเดียวกับโมเดลเชิงพารามิเตอร์ทุกแบบที่ฟิต
สำหรับ โลจิสติกรีเกรสชัน ฟังก์ชันสูญเสียไม่เป็นกำลังสอง จึงไม่มีวิธีแก้แบบปิดรูป ต้องใช้วิธีวนซ้ำอย่างเกรเดียนต์ดีเซนต์ ซึ่งอีกครั้ง อาศัยอนุพันธ์ย่อยในทุกก้าว
ความเชื่อมโยงไปได้ไกลกว่านั้น การแยกตัวประกอบ QR ซึ่งเป็นวิธีเชิงตัวเลขมาตรฐานในการแก้สมการปกติ ตั้งอยู่บนพีชคณิตเชิงเส้นที่ตัดกับวิธีการแก้ระบบสมการ — รวมถึงสมการเชิงอนุพันธ์ — ในทางปฏิบัติโดยตรง
การจำลองระบบไดนามิก
เมื่อจำเป็นต้องจำลองว่าระบบเปลี่ยนไปตามเวลาอย่างไร — และไม่มีวิธีแก้เชิงวิเคราะห์ — ให้จำลองด้วยวิธีเชิงตัวเลข
พบบ่อยในบริบทธุรกิจและปฏิบัติการ การสูญเสียลูกค้า ระดับสินค้าคงคลัง และไดนามิกของซัพพลายเชน ต่างเกี่ยวข้องกับปริมาณที่เปลี่ยนตามสถานะปัจจุบัน สามารถเขียนความสัมพันธ์เหล่านี้เป็นสมการเชิงอนุพันธ์และจำลองด้วย solve_ivp ได้
ตัวอย่างนี้จำลองระบบอุปสงค์–อุปทานอย่างง่ายที่สินค้าคงคลัง I ลดลงตามอัตราอุปสงค์ D และอุปสงค์เปลี่ยนไปตามเวลา:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)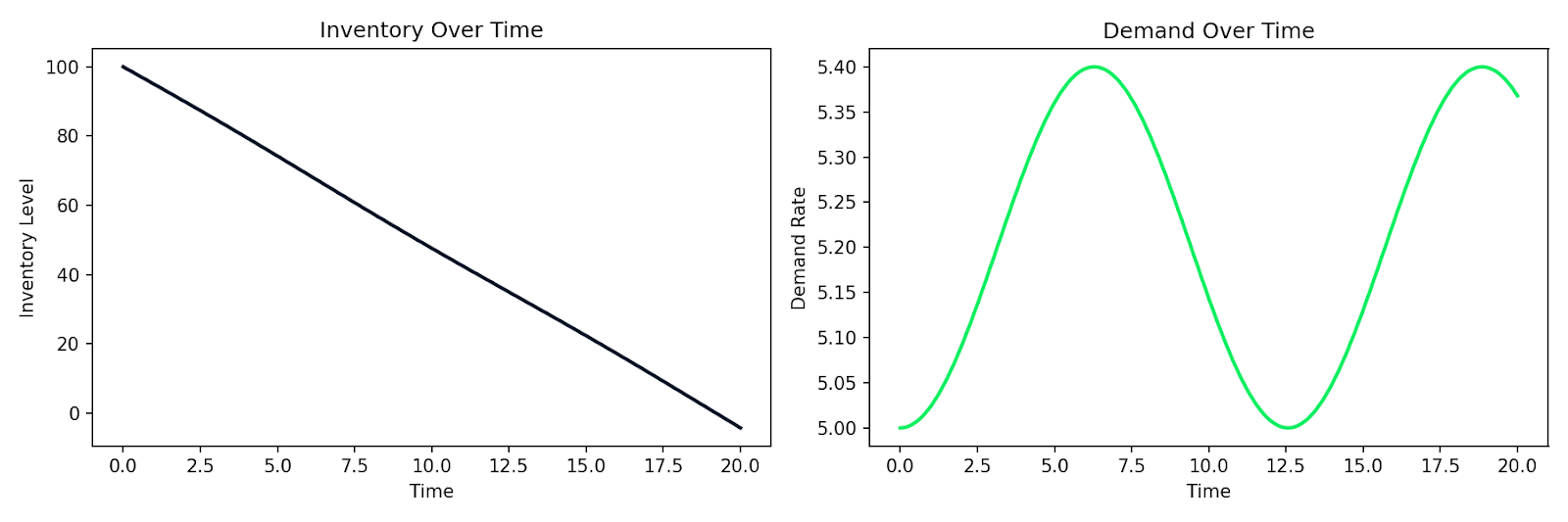
การจำลองการลดลงของสินค้าคงคลังควบคู่กับอุปสงค์ที่ผันผวนตามเวลา
รูปแบบเดียวกันนี้ใช้กับการจำลองพฤติกรรมลูกค้า การแพร่ระบาดในฐานผู้ใช้ หรือระบบใดๆ ที่อัตราการเปลี่ยนขึ้นอยู่กับสถานะปัจจุบัน เขียนความสัมพันธ์ ส่งให้ตัวแก้เชิงตัวเลข แล้วได้ผลการจำลองกลับมา
และนี่คือพลังเชิงปฏิบัติของสมการเชิงอนุพันธ์ในดาต้าไซเอนซ์ เป็นเครื่องมือโดยตรงในการจำลองระบบที่เปลี่ยนแปลง
สรุป
เบื้องหลังเกรเดียนต์ดีเซนต์มีอนุพันธ์ย่อย เบื้องหลังการพยากรณ์ซีรีส์เวลามีระบบไดนามิก เบื้องหลังค่าสัมประสิทธิ์รีเกรสชันมีอนุพันธ์ที่ถูกตั้งให้เป็นศูนย์ แค่ต้องรู้ว่าจะมองหาอย่างไร
บทความนี้อธิบายว่าสมการเชิงอนุพันธ์คืออะไร ความต่างระหว่าง ODE และ PDE การจัดประเภทด้วยอันดับและดีกรี และวิธีแก้หลักทั้งเชิงวิเคราะห์และเชิงตัวเลข จากนั้นดูว่ามันปรากฏในงานดาต้าไซเอนซ์และแมชชีนเลิร์นนิงทุกวันอย่างไร
นี่เป็นเพียงรากฐาน หากต้องการสำรวจหัวข้อคณิตศาสตร์ต่อไป คอร์ส Linear Algebra for Data Science in R เป็นก้าวถัดไปที่ดี สำหรับการลงมือปฏิบัติใช้แนวคิดเหล่านี้แก้ปัญหาจริง ลองดูคอร์ส Quantitative Analyst in R