A conti fatti, usi i risultati delle equazioni differenziali ogni volta che alleni una rete neurale o anche solo adatti un modello di regressione. La matematica sottostante è l’analisi, e le equazioni differenziali ne sono al centro. Se ti sei mai chiesto perché il gradient descent funziona o come un filtro di Kalman segua un oggetto in movimento, la risposta sono le equazioni differenziali.
Le equazioni differenziali ti permettono di modellare come le cose cambiano nel tempo — ed è esattamente questo di cui si occupa la data science. Una volta capiti i concetti chiave, inizierai a vederli ovunque: nelle funzioni di perdita che minimizzi, nelle serie temporali che prevedi e nelle simulazioni che esegui.
In questo articolo ti spiego cosa sono le equazioni differenziali, i principali tipi che incontrerai, come risolverle e — soprattutto — come compaiono nella pratica quotidiana della data science e del machine learning.
Cosa sono le equazioni differenziali?
Un’equazione differenziale è un’equazione che mette in relazione una funzione con le sue derivate.
In parole semplici, una derivata ti dice quanto velocemente qualcosa sta cambiando in un dato istante. Un’equazione differenziale dice che il tasso di variazione di una quantità dipende dalla quantità stessa, dal tempo o da entrambi.
Supponiamo tu stia modellando una popolazione di batteri. Più batteri hai, più velocemente si riproducono. Quindi il tasso di crescita dipende dalla dimensione attuale della popolazione. Scrivilo come equazione ed ecco un’equazione differenziale.
Formalmente, appare così:
Rappresentazione di un’equazione differenziale
Dove P è la popolazione, t è il tempo e r è il tasso di crescita. Il lato sinistro è la derivata — quanto velocemente P cambia nel tempo. Il lato destro dice che questo cambiamento è proporzionale a P stessa.
Questa è l’idea fondamentale dietro ogni equazione differenziale che incontrerai.
Le equazioni differenziali compaiono in fisica, biologia e ingegneria — ovunque un sistema evolva nel tempo. Il calore che si diffonde in una sbarra metallica, un pendolo che oscilla, un virus che si diffonde in una popolazione: tutti questi fenomeni si modellano con equazioni differenziali.
Per chi fa data science, vedrai equazioni differenziali in funzioni di perdita, gradient descent, modelli di serie temporali, ODE neurali — tutte hanno equazioni differenziali sotto il cofano. Non sempre le vedi esplicitamente, ma sono lì.
Quando le capisci, hai un modello mentale più chiaro del perché e del come funzionano gli strumenti che usi ogni giorno.
La storia delle equazioni differenziali
Alla fine del XVII secolo, Isaac Newton e Gottfried Wilhelm Leibniz svilupparono indipendentemente l’analisi matematica. Entrambi avevano bisogno di descrivere come le grandezze fisiche cambiano nel tempo, e le equazioni differenziali furono il risultato. Newton le usò per modellare il moto e la gravità. Leibniz ci ha lasciato gran parte della notazione che usiamo ancora oggi, incluso il d/dt che troverai in ogni manuale di calcolo.
Tra XVIII e XIX secolo arrivò un’ondata di nuove tecniche.
Leonhard Euler sviluppò metodi per risolvere numericamente le ODE — lo stesso Euler dietro al metodo di Eulero che vedrai più avanti. Joseph-Louis Lagrange e Pierre-Simon Laplace estesero la teoria a sistemi più complessi. Jean-Baptiste Joseph Fourier introdusse un modo per scomporre le funzioni in componenti seno e coseno, diventato un pilastro nella soluzione delle equazioni differenziali alle derivate parziali.
Nel XX secolo, le equazioni differenziali erano ovunque: dalla dinamica dei fluidi alla meccanica quantistica fino all’ingegneria elettrica. Molte equazioni reali non avevano soluzioni analitiche pulite. È qui che hanno preso il sopravvento i metodi numerici, resi pratici su larga scala dai computer.
Oggi il campo continua a evolvere. Le ODE neurali (Neural ODEs) trattano gli strati di una rete neurale come un processo continuo descritto da un’equazione differenziale. È uno sviluppo recente che sfuma i confini tra deep learning e matematica classica. Ed è una delle aree più interessanti nella ricerca ML moderna.
Detto ciò, l’idea di fondo resta la stessa: modella come le cose cambiano e potrai prevedere dove stanno andando.
Tipi di equazioni differenziali
Non tutte le equazioni differenziali sono uguali. La prima cosa da sapere è come distinguerle.
La distinzione principale è tra equazioni differenziali ordinarie (ODE) ed equazioni differenziali alle derivate parziali (PDE). La differenza dipende da quante variabili indipendenti compaiono nella funzione.
Equazioni differenziali ordinarie (ODE)
Un’equazione differenziale ordinaria coinvolge una funzione di una singola variabile indipendente e le sue derivate.
L’esempio della popolazione di batteri visto prima è un’ODE. La popolazione P dipende solo dal tempo t — una variabile. Quindi l’equazione ha solo derivate ordinarie, scritte come dP/dt.
Le ODE sono lo strumento giusto quando il tuo sistema evolve lungo una singola dimensione, di solito il tempo. Ecco un paio di esempi classici:
- Crescita della popolazione — il tasso di variazione di una popolazione dipende dalla dimensione attuale
- Decadimento radioattivo — il tasso di decadimento di una sostanza dipende da quanta ne rimane
- Seconda legge di Newton — l’accelerazione di un oggetto dipende dalle forze che agiscono su di esso
In ogni caso, è una sola variabile a guidare il cambiamento. È questo che le rende “ordinarie”.
Equazioni differenziali alle derivate parziali (PDE)
Un’equazione differenziale alle derivate parziali coinvolge una funzione di più variabili indipendenti e le sue derivate parziali.
Per esempio, vuoi modellare come il calore si diffonde in una sbarra metallica. La temperatura in un punto dipende sia dalla posizione lungo la sbarra sia dal momento temporale. Sono due variabili indipendenti: posizione x e tempo t. Scrivendo l’equazione, ottieni derivate parziali — una rispetto a x e una rispetto a t.
Questa è una PDE. L’equazione del calore è uno degli esempi più noti:
Esempio di equazione alle derivate parziali
Dove u(x, t) è la temperatura alla posizione x e al tempo t, α è la diffusività termica del materiale, ∂u/∂t indica quanto velocemente la temperatura cambia nel tempo e ∂²u/∂x² indica quanto è curva la distribuzione della temperatura nello spazio. L’equazione dice che dove la curva della temperatura piega bruscamente, il calore si redistribuisce velocemente. Dove è piatta, succede poco.
Le PDE compaiono ovunque un sistema vari nello spazio e nel tempo:
- Distribuzione del calore — la temperatura cambia rispetto a posizione e tempo
- Propagazione delle onde — onde sonore o luminose si propagano nello spazio nel tempo
- Dinamica dei fluidi — la velocità del fluido dipende dalla posizione nello spazio 3D e dal tempo
Le PDE sono più difficili da risolvere delle ODE. Le soluzioni analitiche esistono solo per forme specifiche e spesso i metodi numerici sono l’unica via praticabile.
Nel lavoro di data science incontrerai più spesso le ODE. Ma le PDE compaiono in image processing, simulazioni fisiche e in alcune architetture di deep learning, quindi è utile conoscerne le differenze.
Ordine e grado delle equazioni differenziali
Ogni equazione differenziale ha due proprietà che indicano quanto è complessa: il suo ordine e il suo grado.
Determinano quali metodi di soluzione sono applicabili, quindi devi identificarle prima di provare a risolvere qualsiasi cosa.
Capire l’ordine
L’ordine di un’equazione differenziale è l’ordine della derivata di grado più alto presente nell’equazione.
Se la derivata più alta è una prima derivata (dy/dx), l’equazione è di primo ordine. Se la più alta è una seconda derivata (d²y/dx²), è di secondo ordine. E così via.
Ecco l’equazione di crescita batterica vista prima:
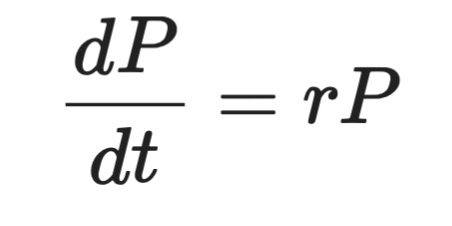
Equazione di crescita batterica
La derivata più alta qui è dP/dt — una prima derivata. Quindi è una ODE di primo ordine.
Ora confrontala con l’equazione che descrive un pendolo oscillante:
Equazione del pendolo oscillante
La derivata più alta è d²θ/dt² — una seconda derivata. Questo la rende una ODE di secondo ordine.
Un ordine più alto significa maggiore complessità. Le equazioni di secondo ordine richiedono due condizioni iniziali invece di una. Nella pratica, la maggior parte dei sistemi fisici — moto meccanico, circuiti elettrici, dinamica orbitale — si modella con equazioni di secondo ordine.
Capire il grado
Il grado di un’equazione differenziale è la potenza della derivata di ordine più alto, una volta che l’equazione è scritta in forma polinomiale (senza radicali o frazioni che coinvolgano derivate).
Considera questa equazione:
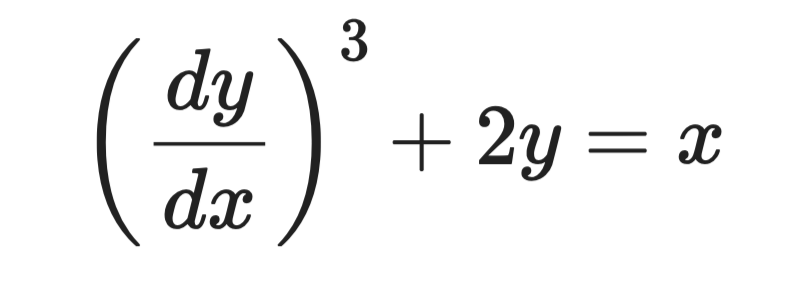
Esempio di equazione differenziale
La derivata più alta è dy/dx, ed è elevata alla potenza 3. Quindi l’ordine è 1 e il grado è 3.
Ora guarda quest’altra:
Esempio di equazione differenziale (2)
La derivata di ordine più alto è d²y/dx², elevata alla potenza 1. Il grado è 1, anche se una derivata di ordine inferiore compare con potenza maggiore.
Il grado segue sempre la derivata di ordine più alto, non la potenza massima nell’equazione.
Un caso limite è quando un’equazione contiene termini come sin(dy/dx) o e^(d²y/dx²). In tal caso, il grado è indefinito — queste forme non possono essere espresse come polinomi nelle derivate.
Metodi per risolvere le equazioni differenziali
Non esiste un metodo unico valido per ogni equazione differenziale. L’approccio giusto dipende dal tipo di equazione, dall’ordine e dal fatto che esista o meno una soluzione esatta.
In generale, hai due categorie: metodi analitici e metodi numerici.
Metodi analitici
I metodi analitici ti danno una soluzione esatta in forma chiusa — una formula valutabile in qualsiasi punto. Sono preferibili quando applicabili perché il risultato è preciso e rivela la struttura della soluzione.
Ma funzionano solo per forme specifiche. Quando l’equazione si fa troppo complessa, i metodi analitici arrivano al capolinea.
Separazione delle variabili
La separazione delle variabili funziona per equazioni in cui puoi isolare tutti i termini che coinvolgono y da un lato e tutti i termini che coinvolgono x (o t) dall’altro.
Considera questa ODE di primo ordine:
Equazione differenziale semplice
Passo 1 — separa le variabili:
Soluzione analitica (passo 1)
Passo 2 — integra entrambi i membri:
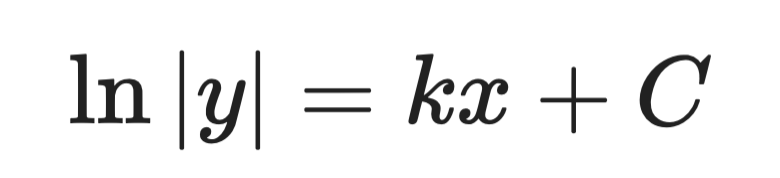
Soluzione analitica (passo 2)
Passo 3 — risolvi per y:
Soluzione analitica (passo 3)
Dove A è una costante determinata dalle condizioni iniziali. Questa è la soluzione generale.
È la stessa forma dell’equazione di crescita dei batteri. Ti dice che le popolazioni — e tutto ciò il cui tasso di crescita è proporzionale alla propria dimensione — crescono esponenzialmente.
Fattori integranti
I fattori integranti gestiscono ODE lineari di primo ordine di questa forma:
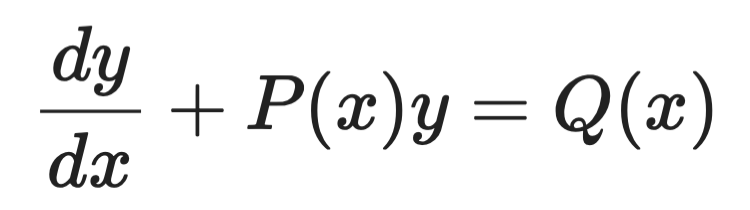
Esempio di fattori integranti (1)
L’idea è moltiplicare entrambi i membri per una funzione scelta con cura — il fattore integrante μ(x) — che renda il lato sinistro una derivata perfetta, integrabile direttamente.
Il fattore integrante è sempre:
Esempio di fattori integranti (2)
Dopo aver moltiplicato, l’equazione diventa:
Esempio di fattori integranti (3)
Poi integra entrambi i membri e risolvi per y. Il lato sinistro si semplifica sempre in modo pulito grazie a come è stato scelto μ(x) — è proprio il punto del metodo.
Metodi numerici
La maggior parte delle equazioni differenziali reali non ha soluzioni analitiche pulite. I metodi numerici approssimano la soluzione passo dopo passo, calcolando valori in punti discreti.
Scambiano esattezza con generalità. E nella pratica è spesso esattamente ciò che serve.
Metodo di Eulero
Il metodo di Eulero è l’approccio numerico più semplice. L’idea è partire da un punto noto, usare la derivata per stimare la pendenza, fare un piccolo passo in quella direzione e ripetere.
Data una ODE di primo ordine dy/dx = f(x, y) con condizione iniziale y(x₀) = y₀, ogni passo è:
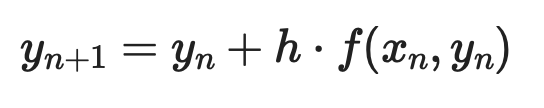
Esempio del metodo di Eulero (1)
Dove h è l’ampiezza del passo. Passi più piccoli significano maggiore accuratezza — ma più calcolo.
Ecco un’implementazione Python che risolve dy/dx = y con y(0) = 1 (la soluzione esatta è y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Metodo di Eulero rispetto alla soluzione esatta
Lo scarto tra le due linee è l’errore di approssimazione. Con h=0.2 l’errore è piccolo all’inizio ma si accumula passo dopo passo — è il principale limite del metodo di Eulero.
Metodi di Runge-Kutta
I metodi di Runge-Kutta risolvono quel problema di accumulo dell’errore campionando la pendenza in più punti all’interno di ogni passo e facendone una media pesata. La versione più comune è RK4 — il metodo di Runge-Kutta di quarto ordine.
Invece di una sola stima della pendenza per passo come in Eulero, RK4 ne calcola quattro:
Esempio del metodo di Runge-Kutta (1)
Poi le combina:
Esempio del metodo di Runge-Kutta (2)
In pratica, non implementi RK4 a mano. solve_ivp di SciPy se ne occupa per te:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 rispetto alla soluzione esatta
La linea RK45 si sovrappone quasi perfettamente alla soluzione esatta. Stessa ampiezza di passo dell’esempio con Eulero, ma accuratezza molto migliore — questa è la differenza che fa il campionamento pesato delle pendenze.
Per la maggior parte del lavoro pratico in Python, solve_ivp con il solver RK45 predefinito è la scelta giusta. Il metodo di Eulero è utile per capire come funzionano i solver numerici, ma non lo useresti in produzione.
Applicazioni delle equazioni differenziali in Data Science e Machine Learning
Gli ingegneri usano le equazioni differenziali per modellare circuiti elettrici e sistemi meccanici. I biologi le usano per tracciare dinamiche di popolazione e diffusione delle malattie. I fisici le usano per descrivere tutto, dalla conduzione del calore alla meccanica quantistica.
Ma tu sei qui per la data science, quindi andiamo al punto.
Machine learning e ottimizzazione
Il collegamento più diretto tra equazioni differenziali e ML è il gradient descent — l’algoritmo alla base dell’addestramento di quasi ogni modello che costruirai.
Quando alleni un modello, stai minimizzando una funzione di perdita L. Per farlo, devi sapere come L cambia quando regoli ciascun parametro. Questo tasso di variazione è una derivata. Quando il tuo modello ha più parametri, calcoli una derivata parziale per ciascuno — insieme formano il gradiente.
Il gradient descent usa queste derivate per aggiornare i parametri passo dopo passo:
Gradient descent
Dove θ è il parametro, η è il learning rate e ∂L/∂θ è la derivata parziale della loss rispetto a quel parametro.
Ecco un semplice esempio in Python che adatta una retta ai dati usando il gradient descent:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Gradient descent che adatta una retta ai dati, e la curva della loss nel tempo
Ogni iterazione muove i parametri nella direzione che riduce la loss. Le derivate parziali ti dicono qual è quella direzione. Senza di esse, il gradient descent non funziona — e nemmeno il backpropagation nelle reti neurali, che è solo la regola della catena applicata ripetutamente attraverso gli strati.
Analisi delle serie temporali
Molti sistemi di serie temporali sono dinamici — il valore corrente dipende dai valori passati e da quanto velocemente le cose stanno cambiando. Le equazioni differenziali ti permettono di descriverlo.
Il filtro di Kalman, ampiamente usato nel tracking e nel forecasting, si basa su un sistema di equazioni differenziali che modellano come uno stato nascosto evolve nel tempo e come le osservazioni rumorose si relazionano a quello stato. È usato nei sistemi GPS, in finanza e nelle previsioni meteo.
I modelli ARIMA si usano per il forecasting di serie temporali e si collegano alle equazioni differenziali tramite il concetto di differenziazione. Prendere differenze prime o seconde di una serie è un’approssimazione discreta di derivate prime e seconde. Quando differenzi una serie per renderla stazionaria, stai chiedendo: come cambia questa serie nel tempo?
Modellazione statistica e regressione
Ecco qualcosa che spesso sorprende: risolvere un sistema di equazioni differenziali è uno dei modi per derivare i coefficienti della regressione lineare.
Quando adatti un modello di regressione lineare, stai minimizzando la somma dei residui quadratici. Prendi la derivata parziale di quella loss rispetto a ciascun coefficiente, poni uguale a zero e risolvi. Questo ti dà la Equazione Normale:
Equazione normale
Ogni coefficiente di regressione che hai mai calcolato deriva dall’aver posto una derivata uguale a zero e aver risolto. Questa è analisi — ed è lo stesso principio dietro ogni modello parametrico che adatti.
Per la regressione logistica, la funzione di perdita non è quadratica, quindi non esiste una soluzione in forma chiusa. Devi usare metodi iterativi come il gradient descent, che di nuovo si basa sulle derivate parziali a ogni passo.
Il collegamento va oltre. La decomposizione QR, uno dei metodi numerici standard per risolvere l’Equazione Normale, poggia su algebra lineare che si interseca direttamente con il modo in cui si risolvono in pratica i sistemi di equazioni — incluse quelle differenziali.
Simulazione di sistemi dinamici
Quando devi modellare come un sistema evolve nel tempo — e una soluzione analitica non esiste — lo simuli numericamente.
È comune in ambito business e operations. Churn dei clienti, livelli di inventario e dinamiche della supply chain coinvolgono quantità che cambiano in base allo stato corrente. Puoi scrivere queste relazioni come equazioni differenziali e simularle con solve_ivp.
Ecco un esempio che simula un semplice sistema domanda-offerta in cui l’inventario I si esaurisce a un tasso proporzionale alla domanda D, e la domanda varia nel tempo:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)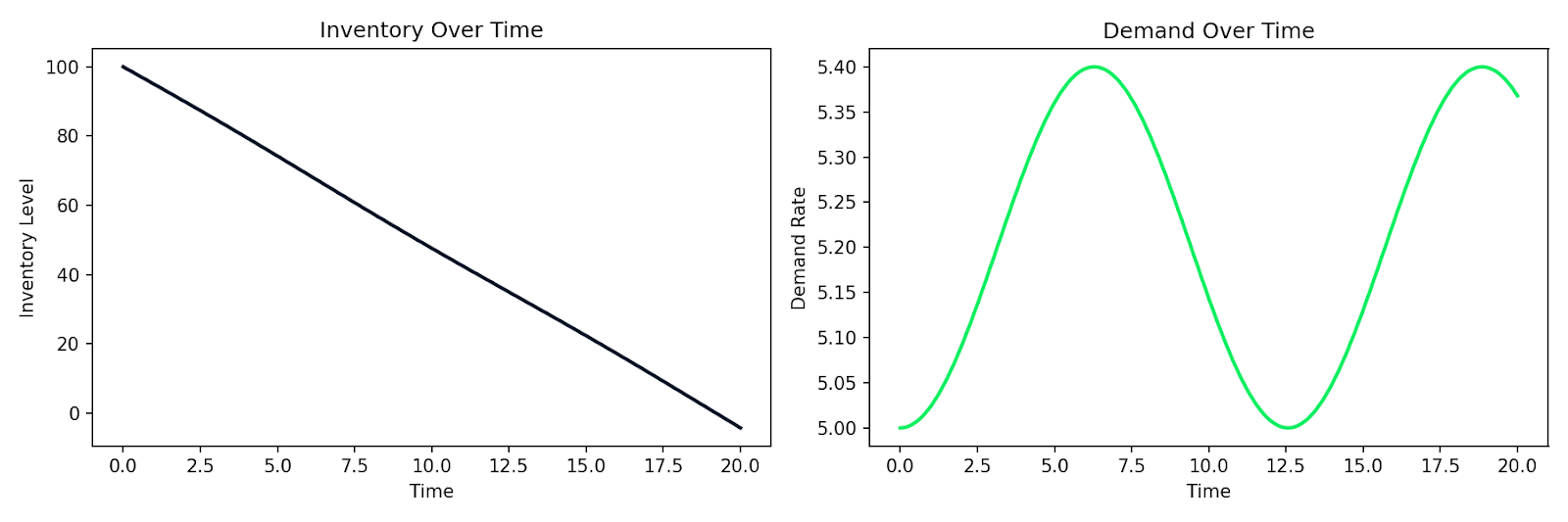
Deplezione dell’inventario simulata insieme alla domanda fluttuante nel tempo
Lo stesso schema si applica alla modellazione del comportamento dei clienti, alla diffusione epidemica in una base utenti o a qualsiasi sistema in cui il tasso di variazione dipende dallo stato corrente. Scrivi le relazioni, le passi a un solver numerico e ottieni una simulazione.
Ed è questo il potere pratico delle equazioni differenziali in data science. È uno strumento diretto per modellare sistemi che cambiano.
Conclusione
Dietro il gradient descent ci sono derivate parziali. Dietro il forecasting nelle serie temporali ci sono sistemi dinamici. Dietro i coefficienti della regressione lineare ci sono derivate poste a zero. Devi solo sapere dove guardare.
In questo articolo ho spiegato cosa sono le equazioni differenziali, la differenza tra ODE e PDE, come ordine e grado le classificano e i principali metodi per risolverle — sia analitici che numerici. Poi abbiamo visto dove compaiono davvero nella data science e nel machine learning di tutti i giorni.
Questa è solo la base. Se vuoi approfondire altri argomenti matematici, il corso Algebra lineare per Data Science in R è un buon passo successivo. Per fare pratica hands-on applicando questi concetti a problemi reali, dai un’occhiata al nostro corso Quantitative Analyst in R.


