Zoals het blijkt, gebruik je de resultaten van differentiële vergelijkingen elke keer als je een neuraal netwerk traint of zelfs een regressiemodel fit. De wiskunde onder de motorkap is analyse, en differentiële vergelijkingen staan daar middenin. Als je je ooit hebt afgevraagd waarom gradient descent werkt of hoe een Kalman-filter een bewegend object volgt, dan zijn differentiële vergelijkingen je antwoord.
Met differentiële vergelijkingen kun je modelleren hoe dingen in de tijd veranderen - en dat is precies waar data science om draait. Zodra je de kernideeën begrijpt, zie je ze overal: in de verliesfuncties die je minimaliseert, de tijdreeksen die je voorspelt en de simulaties die je draait.
In dit artikel neem ik je mee door wat differentiële vergelijkingen zijn, de belangrijkste types die je tegenkomt, hoe je ze oplost en - het belangrijkst - hoe ze dagelijks terugkomen in echte data science en machine learning.
Wat zijn differentiële vergelijkingen?
Een differentiële vergelijking is een vergelijking die een functie relateert aan haar eigen afgeleiden.
In gewone taal: een afgeleide vertelt je hoe snel iets op een gegeven moment verandert. Een differentiële vergelijking zegt dat de veranderingssnelheid van een grootheid afhangt van de grootheid zelf, of van de tijd, of van beide.
Stel, je modelleert een bacteriënpopulatie. Hoe meer bacteriën je hebt, hoe sneller ze zich voortplanten. De groeisnelheid hangt dus af van de huidige populatieomvang. Schrijf dat als een vergelijking, en je hebt een differentiële vergelijking.
Formeel ziet het er zo uit:
Weergave van een differentiële vergelijking
Waarbij P de populatie is, t de tijd en r de groeisnelheid. De linkerkant is de afgeleide - hoe snel P in de tijd verandert. De rechterkant zegt dat die verandering evenredig is met P zelf.
Dat is het kernidee achter elke differentiële vergelijking die je zult zien.
Differentiële vergelijkingen kom je tegen in fysica, biologie en engineering - overal waar een systeem zich in de tijd ontwikkelt. Warmte die zich verspreidt door een metalen staaf, een slinger die zwaait, een virus dat zich door een populatie verspreidt. Al deze verschijnselen modelleer je met differentiële vergelijkingen.
Voor data scientists kom je differentiële vergelijkingen tegen in verliesfuncties, gradient descent, tijdreeksmodellen, neural ODE's - overal zitten differentiële vergelijkingen onder. Je ziet ze niet altijd expliciet, maar ze zijn er wel.
Als je ze begrijpt, krijg je een helderder mentaal model van waarom en hoe de tools die je elke dag gebruikt werken.
De geschiedenis van differentiële vergelijkingen
Aan het eind van de 17e eeuw ontwikkelden Isaac Newton en Gottfried Wilhelm Leibniz onafhankelijk van elkaar de analyse. Beiden hadden een manier nodig om te beschrijven hoe fysieke grootheden in de tijd veranderen, en differentiële vergelijkingen waren het resultaat. Newton gebruikte ze om beweging en zwaartekracht te modelleren. Leibniz gaf ons veel van de notatie die we vandaag nog gebruiken, inclusief de d/dt die je in elk analyseleerboek ziet.
De 18e en 19e eeuw brachten een golf aan nieuwe technieken.
Leonhard Euler ontwikkelde methoden om ODE's numeriek op te lossen - dezelfde Euler achter Eulers methode die je later in dit artikel ziet. Joseph-Louis Lagrange en Pierre-Simon Laplace breidden de theorie uit naar complexere systemen. Jean-Baptiste Joseph Fourier introduceerde een manier om functies te ontbinden in sinus- en cosinuscomponenten, wat een hoeksteen werd voor het oplossen van partiële differentiaalvergelijkingen.
Tegen de 20e eeuw waren differentiële vergelijkingen overal: van stromingsleer, kwantummechanica tot elektrotechniek. Veel realistische vergelijkingen hadden geen nette analytische oplossing. Daar namen numerieke methoden het over, en computers maakten ze schaalbaar in de praktijk.
Vandaag gaat het vakgebied door. Neural ordinary differential equations (Neural ODEs) behandelen de lagen van een neuraal netwerk als een continu proces beschreven door een differentiële vergelijking. Het is een recente ontwikkeling die de grens tussen deep learning en klassieke wiskunde vervaagt. Het is ook een van de spannendere gebieden in modern ML-onderzoek.
Dat gezegd hebbende blijft het kernidee hetzelfde: modelleer hoe dingen veranderen, en je kunt voorspellen waar ze naartoe gaan.
Types differentiële vergelijkingen
Niet alle differentiële vergelijkingen zijn hetzelfde. Het eerste wat je moet weten is hoe je ze uit elkaar houdt.
De belangrijkste splitsing is tussen gewone differentiaalvergelijkingen (ODE's) en partiële differentiaalvergelijkingen (PDE's). Het verschil komt neer op hoeveel onafhankelijke variabelen de functie heeft.
Gewone differentiaalvergelijkingen (ODE's)
Een gewone differentiaalvergelijking bevat een functie van één onafhankelijke variabele en haar afgeleiden.
Het voorbeeld van de bacteriënpopulatie van eerder is een ODE. De populatie P hangt alleen af van de tijd t - één variabele. Dus de vergelijking heeft alleen gewone afgeleiden, geschreven als dP/dt.
ODE's zijn het juiste gereedschap als je systeem zich langs één dimensie ontwikkelt, meestal de tijd. Hier zijn een paar klassieke voorbeelden:
- Populatiegroei - de verandering van een populatie hangt af van de huidige populatiegrootte
- Radioactief verval - de snelheid waarmee een stof vervalt hangt af van hoeveel ervan over is
- De tweede wet van Newton - de versnelling van een object hangt af van de krachten die erop werken
In elk geval drijft één variabele de verandering. Dat maakt het "gewoon".
Partiële differentiaalvergelijkingen (PDE's)
Een partiële differentiaalvergelijking bevat een functie van meerdere onafhankelijke variabelen en haar partiële afgeleiden.
Stel dat je wilt modelleren hoe warmte zich verspreidt door een metalen staaf. De temperatuur op een punt hangt zowel af van waar je op de staaf bent als van het tijdstip. Dat zijn twee onafhankelijke variabelen: positie x en tijd t. Als je daar een vergelijking voor opschrijft, krijg je partiële afgeleiden - één naar x, één naar t.
Dat is een PDE. De warmtevergelijking is een van de bekendste voorbeelden:
Voorbeeld van een partiële differentiaalvergelijking
Waarbij u(x, t) de temperatuur is op positie x en tijd t, α de thermische diffusiviteit van het materiaal is, ∂u/∂t hoe snel de temperatuur in de tijd verandert en ∂²u/∂x² hoe gebogen het temperatuurprofiel door de ruimte is. De vergelijking zegt: waar de temperatuurscurve sterk buigt, herverdeelt de warmte snel. Waar die vlak is, gebeurt er niet veel.
PDE's kom je tegen waar een systeem varieert over ruimte en tijd:
- Warmteverdeling - temperatuur verandert zowel over positie als tijd
- Golfvoortplanting - geluid- of lichtgolven verspreiden zich door de ruimte in de tijd
- Stromingsleer - vloeistofsnelheid hangt af van positie in 3D-ruimte en tijd
PDE's zijn lastiger op te lossen dan ODE's. Analytische oplossingen bestaan alleen voor specifieke vormen, en numerieke methoden zijn vaak de enige praktische weg vooruit.
Voor de meeste data science-werkzaamheden kom je vaker ODE's tegen. Maar PDE's verschijnen in beeldverwerking, fysicasimulaties en sommige deep learning-architecturen, dus je moet het verschil kennen.
Orde en graad van differentiële vergelijkingen
Elke differentiële vergelijking heeft twee eigenschappen die aangeven hoe complex ze is: de orde en de graad.
Die bepalen welke oplossingsmethoden van toepassing zijn, dus je moet ze bepalen voordat je iets probeert op te lossen.
Orde begrijpen
De orde van een differentiële vergelijking is de orde van de hoogste afgeleide in de vergelijking.
Als de hoogste afgeleide een eerste afgeleide is (dy/dx), is het een eerste-orde vergelijking. Als de hoogste een tweede afgeleide is (d²y/dx²), is het een tweede-orde vergelijking. Enzovoort.
Hier is de bacteriegroeivergelijking van eerder:
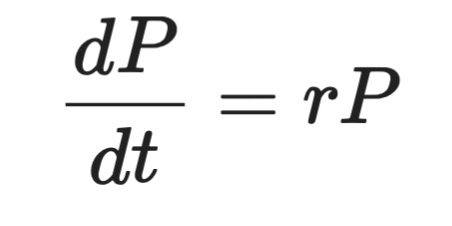
Bacteriegroeivergelijking
De hoogste afgeleide hier is dP/dt - een eerste afgeleide. Dit is dus een ODE van de eerste orde.
Vergelijk dat nu met de vergelijking die een zwaaiende slinger beschrijft:
Vergelijking van een zwaaiende slinger
De hoogste afgeleide is d²θ/dt² - een tweede afgeleide. Dat maakt het een ODE van de tweede orde.
Een hogere orde betekent meer complexiteit. Tweede-orde vergelijkingen hebben twee beginvoorwaarden nodig in plaats van één. In de praktijk worden de meeste fysische systemen - mechanische beweging, elektrische circuits, baandynamica - gemodelleerd met vergelijkingen van de tweede orde.
Graad begrijpen
De graad van een differentiële vergelijking is de macht van de hoogste-orde afgeleide, zodra de vergelijking is geschreven in polynomiale vorm (geen wortels of breuken met afgeleiden).
Neem deze vergelijking:
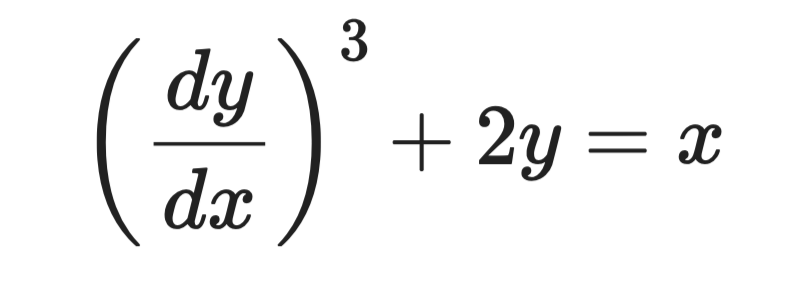
Voorbeeld van een differentiële vergelijking
De hoogste afgeleide is dy/dx, en die staat tot de macht 3. Dus de orde is 1 en de graad is 3.
Neem nu deze:
Voorbeeld van een differentiële vergelijking (2)
De hoogste-orde afgeleide is d²y/dx², tot de macht 1. De graad is 1, ook al komt een afgeleide van lagere orde met een hogere macht voor.
De graad volgt altijd de hoogste-orde afgeleide, niet de hoogste macht in de vergelijking.
Een randgeval is wanneer een vergelijking termen bevat als sin(dy/dx) of e^(d²y/dx²). Dan is de graad ongedefinieerd - die vormen zijn niet als polynoom in de afgeleiden te schrijven.
Methoden om differentiële vergelijkingen op te lossen
Er is geen enkele methode die voor elke differentiële vergelijking werkt. De juiste aanpak hangt af van het type, de orde en of er überhaupt een exacte oplossing bestaat.
Grofweg heb je twee categorieën: analytische methoden en numerieke methoden.
Analytische methoden
Analytische methoden geven je een exacte, gesloten-vorm oplossing - een formule die je op elk punt kunt evalueren. Ze hebben de voorkeur wanneer ze toepasbaar zijn, omdat het resultaat precies is en iets vertelt over de structuur van de oplossing.
Maar ze werken alleen voor specifieke vergelijkingsvormen. Als de vergelijking te complex wordt, lopen analytische methoden vast.
Scheiding der variabelen
Scheiding der variabelen werkt voor vergelijkingen waarbij je alle termen met y aan de ene kant kunt isoleren en alle termen met x (of t) aan de andere kant.
Neem deze eerste-orde ODE:
Eenvoudige differentiële vergelijking
Stap 1 - scheid de variabelen:
Analytische oplossing (stap 1)
Stap 2 - integreer beide kanten:
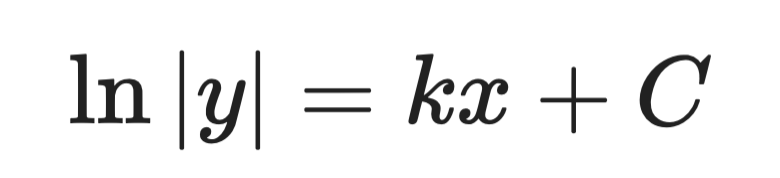
Analytische oplossing (stap 2)
Stap 3 - los op naar y:
Analytische oplossing (stap 3)
Waarbij A een constante is bepaald door beginvoorwaarden. Dat is de algemene oplossing.
Dit is dezelfde vorm als de bacteriegroeivergelijking. Het vertelt je dat populaties - en alles met een groeisnelheid evenredig aan de omvang - exponentieel groeien.
Integrerende factoren
Integrerende factoren behandelen eerste-orde lineaire ODE's van deze vorm:
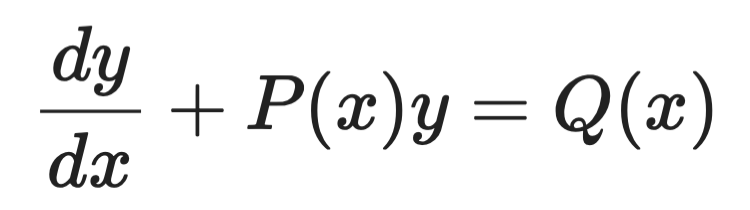
Voorbeeld integrerende factoren (1)
Het idee is om beide kanten te vermenigvuldigen met een zorgvuldig gekozen functie - de integrerende factor μ(x) - die ervoor zorgt dat de linkerkant een perfecte afgeleide wordt die je direct kunt integreren.
De integrerende factor is altijd:
Voorbeeld integrerende factoren (2)
Na doorvermenigvuldigen wordt de vergelijking:
Voorbeeld integrerende factoren (3)
Integreer vervolgens beide kanten en los op naar y. De linkerkant klapt altijd netjes in elkaar dankzij de keuze van μ(x) - dat is precies het punt van de methode.
Numerieke methoden
De meeste realistische differentiële vergelijkingen hebben geen nette analytische oplossing. Numerieke methoden benaderen de oplossing stap voor stap en berekenen waarden op discrete punten.
Ze ruilen exactheid in voor algemeenheid. En in de praktijk is dat vaak precies wat je nodig hebt.
Eulers methode
Eulers methode is de eenvoudigste numerieke aanpak. Het idee: begin bij een bekend punt, gebruik de afgeleide om de helling te schatten, neem een kleine stap in die richting en herhaal.
Gegeven een eerste-orde ODE dy/dx = f(x, y) met beginvoorwaarde y(x₀) = y₀, ziet elke stap er zo uit:
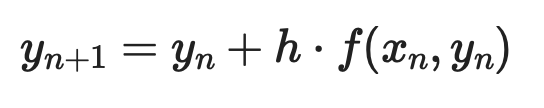
Voorbeeld van Eulers methode (1)
Waarbij h de stapgrootte is. Kleinere stappen betekenen betere nauwkeurigheid - maar meer rekenwerk.
Hier is een Python-implementatie die dy/dx = y oplost met y(0) = 1 (de exacte oplossing is y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Eulers methode versus de exacte oplossing
Het gat tussen de twee lijnen is de benaderingsfout. Met h=0.2 is de fout in het begin klein maar stapelt die op - dat is de belangrijkste zwakte van Eulers methode.
Runge-Kutta-methoden
Runge-Kutta-methoden pakken dat probleem van foutopbouw aan door de helling meerdere keren per stap te bemonsteren en een gewogen gemiddelde te nemen. De meest gebruikte versie is RK4 - de Runge-Kutta-methode van de vierde orde.
In plaats van één hellingschatting per stap zoals Euler, berekent RK4 er vier:
Voorbeeld Runge-Kutta-methode (1)
En combineert die vervolgens:
Voorbeeld Runge-Kutta-methode (2)
In de praktijk implementeer je RK4 niet met de hand. SciPy's solve_ivp regelt dat voor je:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 versus de exacte oplossing
De RK45-lijn ligt bijna perfect boven op de exacte oplossing. Met dezelfde stapgrootte als in het Euler-voorbeeld, maar veel nauwkeuriger - dat is het verschil dat gewogen hellingsbemonstering maakt.
Voor de meeste praktische werkzaamheden in Python is solve_ivp met de standaard RK45-oplosser je go-to. Eulers methode is nuttig om te begrijpen hoe numerieke oplossers werken, maar je zou het niet in productie gebruiken.
Toepassingen van differentiële vergelijkingen in data science en machine learning
Ingenieurs gebruiken differentiële vergelijkingen om elektrische circuits en mechanische systemen te modelleren. Biologen gebruiken ze om populatiedynamiek en ziektoverspreiding te volgen. Fysici beschrijven er alles mee, van warmtetransport tot kwantummechanica.
Maar je bent hier voor data science, dus laten we daarheen gaan.
Machine learning en optimalisatie
De meest directe link tussen differentiële vergelijkingen en ML is gradient descent - het algoritme achter het trainen van vrijwel elk model dat je bouwt.
Als je een model traint, minimaliseer je een verliesfunctie L. Om dat te doen, moet je weten hoe L verandert als je elke parameter aanpast. Die veranderingssnelheid is een afgeleide. Als je model meerdere parameters heeft, bereken je een partiële afgeleide voor elk - samen vormen ze de gradiënt.
Gradient descent gebruikt die afgeleiden om parameters stap voor stap bij te werken:
Gradient descent
Waarbij θ de parameter is, η de learning rate en ∂L/∂θ de partiële afgeleide van het verlies naar die parameter.
Hier is een eenvoudig Python-voorbeeld dat een lijn fit op data met gradient descent:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Gradient descent die een lijn fit op data, en de verliescurve over iteraties
Elke iteratie verplaatst de parameters in de richting die het verlies vermindert. De partiële afgeleiden vertellen je welke richting dat is. Zonder die afgeleiden werkt gradient descent niet - en backpropagation in neurale netwerken evenmin, wat simpelweg de kettingregel is die herhaald wordt door de lagen.
Tijdreeksanalyse
Veel systemen in tijdreeksen zijn dynamisch - de huidige waarde hangt af van vorige waarden en van hoe snel dingen veranderen. Differentiële vergelijkingen laten je dat beschrijven.
De Kalman-filter, veelgebruikt in tracking en forecasting, is gebaseerd op een systeem van differentiële vergelijkingen dat modelleert hoe een verborgen toestand zich in de tijd ontwikkelt en hoe ruisige observaties zich tot die toestand verhouden. Het wordt gebruikt in gps-systemen, financiën en weersvoorspelling.
ARIMA-modellen worden gebruikt voor tijdreeksvoorspellingen en zijn verwant aan differentiële vergelijkingen via het concept van differencing. Eerste of tweede verschillen van een tijdreeks nemen is een discrete benadering van eerste en tweede afgeleiden. Als je een reeks differentieert om die stationair te maken, vraag je: hoe verandert deze reeks in de tijd?
Statistische modellering en regressie
Hier is er eentje die mensen vaak verrast: het oplossen van een systeem differentiële vergelijkingen is één manier om lineaire regressie-coëfficiënten af te leiden.
Als je een lineair regressiemodel fit, minimaliseer je de som van de kwadratische residuen. Neem de partiële afgeleide van dat verlies naar elke coëfficiënt, zet ze gelijk aan nul en los op. Dat levert de normale vergelijking op:
Normale vergelijking
Elke regressiecoëfficiënt die je ooit hebt berekend, komt voort uit het gelijkstellen van een afgeleide aan nul en oplossen. Dat is analyse - en hetzelfde principe achter elk parametrisch model dat je fit.
Voor logistische regressie is de verliesfunctie niet kwadratisch, dus er is geen gesloten-vorm oplossing. Je moet iteratieve methoden zoals gradient descent gebruiken, die opnieuw bij elke stap steunen op partiële afgeleiden.
De link gaat verder. QR-decompositie, een van de standaard numerieke methoden om de normale vergelijking op te lossen, is geworteld in lineaire algebra die direct raakt aan hoe stelsels vergelijkingen - inclusief differentiële - in de praktijk worden opgelost.
Simulatie van dynamische systemen
Als je moet modelleren hoe een systeem zich in de tijd ontwikkelt - en er geen analytische oplossing bestaat - simuleer je het numeriek.
Dit is gebruikelijk in business- en operationele contexten. Klantverloop, voorraadniveaus en supply chain-dynamiek omvatten allemaal grootheden die veranderen op basis van de huidige toestand. Je kunt die relaties als differentiële vergelijkingen opschrijven en met solve_ivp simuleren.
Hier is een voorbeeld van een eenvoudig vraag- en aanbodmodel waarbij voorraad I afneemt met een snelheid evenredig aan de vraag D, en de vraag in de tijd verschuift:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)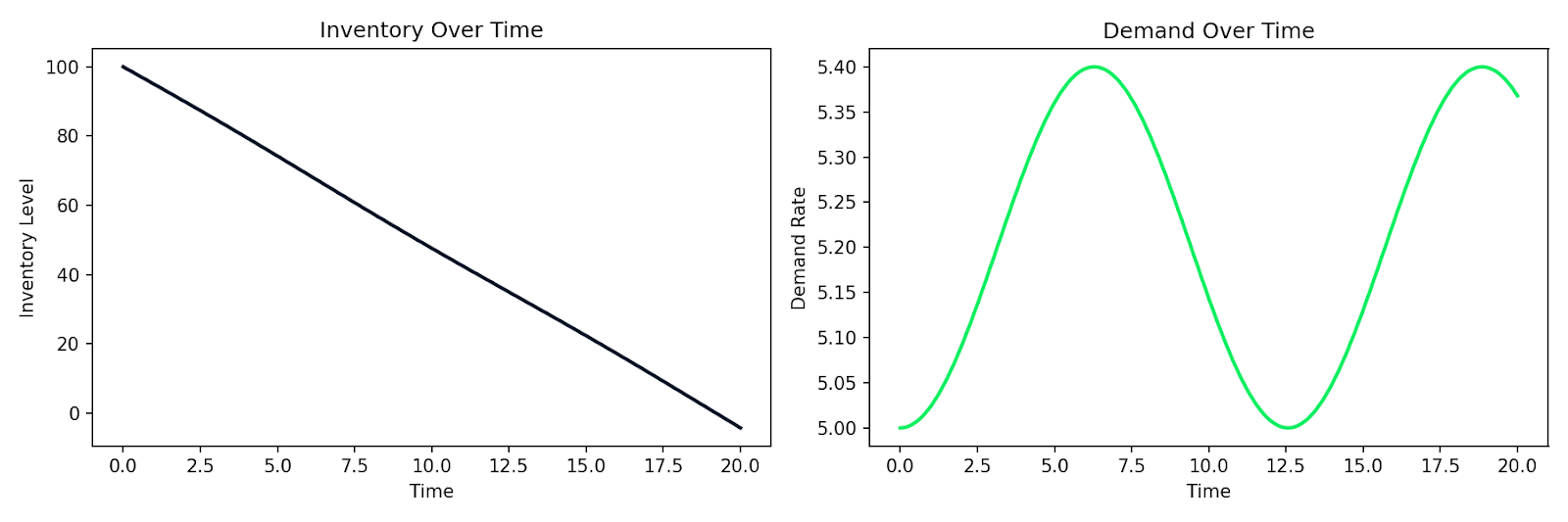
Gesimuleerde voorraadafname naast fluctuerende vraag in de tijd
Hetzelfde patroon geldt voor het modelleren van klantgedrag, epidemische verspreiding in een gebruikersbasis of elk systeem waarin de veranderingssnelheid afhangt van de huidige toestand. Je schrijft de relaties op, geeft ze aan een numerieke oplosser en krijgt een simulatie terug.
En dat is de praktische kracht van differentiële vergelijkingen in data science. Het is een direct hulpmiddel om systemen die veranderen te modelleren.
Conclusie
Achter gradient descent zitten partiële afgeleiden. Achter tijdreeksvoorspellingen zitten dynamische systemen. Achter lineaire regressiecoëfficiënten zitten afgeleiden die op nul worden gezet. Je hoeft alleen te weten waar je moet kijken.
In dit artikel legde ik uit wat differentiële vergelijkingen zijn, het verschil tussen ODE's en PDE's, hoe orde en graad ze classificeren en de belangrijkste methoden om ze op te lossen - zowel analytisch als numeriek. Daarna bekeken we waar ze in de dagelijkse praktijk van data science en machine learning voorkomen.
Dit is slechts de basis. Als je meer wiskundige onderwerpen wilt verkennen, is de cursus Linear Algebra for Data Science in R een goede volgende stap. Voor hands-on oefenen met het toepassen van deze concepten op echte dataproblemen, bekijk onze cursus Quantitative Analyst in R.

