Jak się okazuje, korzystają Państwo z wyników równań różniczkowych za każdym razem, gdy trenują sieć neuronową lub nawet dopasowują model regresji. Matematyka pod spodem to rachunek różniczkowy, a równania różniczkowe stoją w jego centrum. Jeśli kiedykolwiek zastanawiali się Państwo, dlaczego działa spadek gradientowy albo jak filtr Kalmana śledzi poruszający się obiekt, odpowiedzią są równania różniczkowe.
Równania różniczkowe pozwalają modelować, jak rzeczy zmieniają się w czasie — a właśnie o to chodzi w data science. Gdy zrozumieją Państwo kluczowe idee, zaczną je Państwo dostrzegać wszędzie: w funkcjach straty, które minimalizują Państwo na co dzień, w szeregach czasowych, które Państwo prognozują, i w symulacjach, które Państwo uruchamiają.
W tym artykule wyjaśnię, czym są równania różniczkowe, jakie główne typy można spotkać, jak je rozwiązywać i — co najważniejsze — jak pojawiają się one w codziennej pracy w data science i uczeniu maszynowym.
Czym są równania różniczkowe?
Równanie różniczkowe to równanie, które wiąże funkcję z jej pochodnymi.
Mówiąc prościej, pochodna mówi, jak szybko coś się zmienia w danej chwili. Równanie różniczkowe stwierdza, że tempo zmiany danej wielkości zależy od niej samej, od czasu lub od obu tych czynników.
Załóżmy, że modelują Państwo populację bakterii. Im więcej bakterii, tym szybciej się rozmnażają. A więc tempo wzrostu zależy od bieżącej liczebności populacji. Zapisanie tego jako równania daje równanie różniczkowe.
Formalnie wygląda to tak:
Reprezentacja równania różniczkowego
Gdzie P to populacja, t to czas, a r to tempo wzrostu. Lewa strona to pochodna — jak szybko P zmienia się w czasie. Prawa strona mówi, że ta zmiana jest proporcjonalna do samego P.
To jest kluczowa idea stojąca za każdym równaniem różniczkowym, jakie Państwo spotkają.
Równania różniczkowe pojawiają się w fizyce, biologii i inżynierii — wszędzie tam, gdzie system ewoluuje w czasie. Rozchodzenie się ciepła w metalowym pręcie, kołyszące się wahadło, rozprzestrzenianie się wirusa w populacji. Wszystko to modeluje się równaniami różniczkowymi.
W pracy data scientistów równania różniczkowe zobaczą Państwo w funkcjach straty, spadku gradientowym, modelach szeregów czasowych, Neural ODE — pod spodem wszędzie pracują równania różniczkowe. Nie zawsze są widoczne wprost, ale tam są.
Gdy je Państwo zrozumieją, zyskają Państwo jaśniejszy model mentalny tego, dlaczego i jak działają narzędzia, których używają Państwo na co dzień.
Historia równań różniczkowych
Pod koniec XVII wieku Isaac Newton i Gottfried Wilhelm Leibniz niezależnie opracowali rachunek różniczkowy i całkowy. Obu potrzebny był sposób opisu, jak wielkości fizyczne zmieniają się w czasie, a rezultatem były równania różniczkowe. Newton używał ich do modelowania ruchu i grawitacji. Leibniz dał nam dużą część notacji używanej do dziś, w tym d/dt, które zobaczą Państwo w każdym podręczniku rachunku różniczkowego.
W XVIII i XIX wieku pojawiła się fala nowych technik.
Leonhard Euler opracował metody numerycznego rozwiązywania ODE — ten sam Euler, którego metodę zobaczą Państwo później w tym artykule. Joseph-Louis Lagrange i Pierre-Simon Laplace rozwinęli teorię dla bardziej złożonych systemów. Jean-Baptiste Joseph Fourier wprowadził sposób rozkładu funkcji na składowe sinus i cosinus, co stało się kamieniem węgielnym rozwiązywania równań różniczkowych cząstkowych.
Do XX wieku równania różniczkowe były wszędzie — od dynamiki płynów, poprzez mechanikę kwantową, po inżynierię elektryczną. Wiele równań ze świata rzeczywistego nie miało eleganckich rozwiązań analitycznych. Wtedy do gry weszły metody numeryczne, a komputery uczyniły je praktycznymi na dużą skalę.
Dziś dziedzina nadal się rozwija. Neural ordinary differential equations (Neural ODE) traktują warstwy sieci neuronowej jako proces ciągły opisany równaniem różniczkowym. To niedawny rozwój, który zaciera granicę między deep learningiem a klasyczną matematyką. To także jeden z ciekawszych obszarów współczesnych badań nad ML.
Niezależnie od tego rdzeń pozostaje ten sam: zamodelować, jak rzeczy się zmieniają, a można przewidzieć, dokąd zmierzają.
Rodzaje równań różniczkowych
Nie wszystkie równania różniczkowe są takie same. Najpierw trzeba umieć je od siebie odróżnić.
Główny podział to zwyczajne równania różniczkowe (ODE) oraz równania różniczkowe cząstkowe (PDE). Różnica sprowadza się do tego, od ilu zmiennych niezależnych zależy funkcja.
Zwyczajne równania różniczkowe (ODE)
Zwyczajne równanie różniczkowe obejmuje funkcję jednej zmiennej niezależnej i jej pochodne.
Przykład populacji bakterii z wcześniejszej części to ODE. Populacja P zależy tylko od czasu t — jednej zmiennej. Dlatego równanie ma tylko zwyczajne pochodne, zapisane jako dP/dt.
ODE są właściwym narzędziem, gdy system ewoluuje wzdłuż jednego wymiaru, zwykle czasu. Oto kilka klasycznych przykładów:
- Wzrost populacji — tempo zmiany populacji zależy od jej bieżącej liczebności
- Rozpad promieniotwórczy — tempo rozpadu substancji zależy od tego, ile jej pozostało
- Drugie prawo Newtona — przyspieszenie obiektu zależy od działających na niego sił
W każdym przypadku jedna zmienna napędza zmiany. To czyni je „zwyczajnymi”.
Równania różniczkowe cząstkowe (PDE)
Równanie różniczkowe cząstkowe obejmuje funkcję wielu zmiennych niezależnych i jej pochodne cząstkowe.
Załóżmy, że chcą Państwo zamodelować, jak ciepło rozchodzi się w metalowym pręcie. Temperatura w dowolnym punkcie zależy zarówno od położenia wzdłuż pręta, jak i od czasu. To dwie zmienne niezależne: położenie x i czas t. Zapisując to równaniem, otrzymuje się pochodne cząstkowe — jedną względem x, drugą względem t.
To jest PDE. Równanie przewodnictwa ciepła to jeden z najbardziej znanych przykładów:
Przykład równania różniczkowego cząstkowego
Gdzie u(x, t) to temperatura w położeniu x i czasie t, α to dyfuzyjność cieplna materiału, ∂u/∂t opisuje, jak szybko temperatura zmienia się w czasie, a ∂²u/∂x² — jak zakrzywiony jest profil temperatury w przestrzeni. Równanie mówi, że tam, gdzie krzywa temperatury ostro się wygina, ciepło szybko się rozprowadza. Gdzie jest płaska — niewiele się dzieje.
PDE pojawiają się wszędzie tam, gdzie system zmienia się w przestrzeni i czasie:
- Rozkład ciepła — temperatura zmienia się zarówno w funkcji położenia, jak i czasu
- Propagacja fal — fale dźwiękowe lub świetlne rozchodzą się w przestrzeni w czasie
- Dynamika płynów — prędkość płynu zależy od położenia w przestrzeni 3D i czasu
PDE są trudniejsze do rozwiązania niż ODE. Rozwiązania analityczne istnieją tylko dla określonych form, a metody numeryczne często są jedyną praktyczną drogą naprzód.
W większości prac data science częściej napotkają Państwo ODE. Ale PDE pojawiają się w przetwarzaniu obrazów, symulacjach fizycznych i niektórych architekturach deep learningowych, więc warto znać różnice.
Rząd i stopień równań różniczkowych
Każde równanie różniczkowe ma dwie właściwości informujące o jego złożoności: rząd i stopień.
To one determinują, które metody rozwiązywania mają zastosowanie, dlatego trzeba je zidentyfikować, zanim przystąpi się do rozwiązywania.
Zrozumienie rzędu
Rząd równania różniczkowego to rząd najwyższej pochodnej występującej w równaniu.
Jeśli najwyższa pochodna to pierwsza pochodna (dy/dx), mamy do czynienia z równaniem pierwszego rzędu. Jeśli najwyższa to druga pochodna (d²y/dx²), mamy drugiego rzędu. I tak dalej.
Oto równanie wzrostu bakterii z wcześniejszej części:
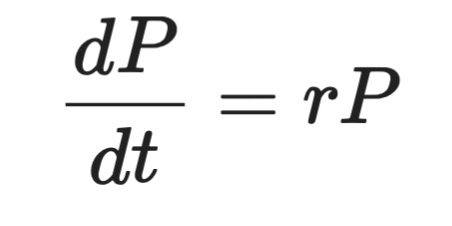
Równanie wzrostu bakterii
Najwyższą pochodną jest tutaj dP/dt — pierwsza pochodna. To więc ODE pierwszego rzędu.
Porównajmy to teraz z równaniem opisującym kołyszące się wahadło:
Równanie kołyszącego się wahadła
Najwyższą pochodną jest d²θ/dt² — druga pochodna. To czyni je ODE drugiego rzędu.
Wyższy rząd oznacza większą złożoność. Równania drugiego rzędu wymagają do rozwiązania dwóch warunków początkowych zamiast jednego. W praktyce większość systemów fizycznych — ruch mechaniczny, obwody elektryczne, dynamika orbitalna — modeluje się równaniami drugiego rzędu.
Zrozumienie stopnia
Stopień równania różniczkowego to wykładnik najwyższej pochodnej, po zapisaniu równania w postaci wielomianowej (bez pierwiastków i ułamków zawierających pochodne).
Rozważmy to równanie:
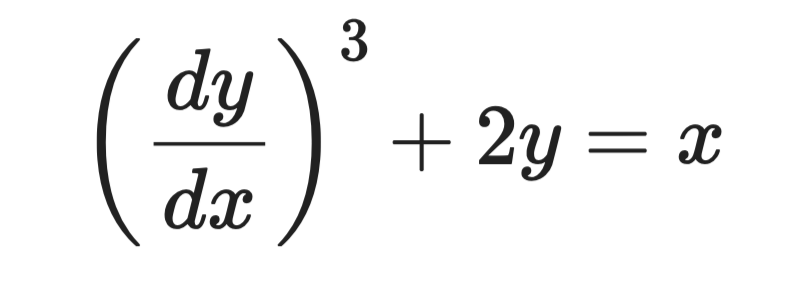
Przykładowe równanie różniczkowe
Najwyższą pochodną jest dy/dx i jest podniesiona do potęgi 3. Zatem rząd wynosi 1, a stopień 3.
A teraz to:
Przykładowe równanie różniczkowe (2)
Najwyższą pochodną jest d²y/dx², podniesiona do potęgi 1. Stopień wynosi 1, nawet jeśli pochodna niższego rzędu występuje z wyższą potęgą.
Stopień zawsze odnosi się do najwyższej pochodnej w sensie rzędu, a nie do najwyższej potęgi w równaniu.
Pewnym przypadkiem brzegowym są równania z wyrażeniami typu sin(dy/dx) czy e^(d²y/dx²). Wtedy stopień jest nieokreślony — takich form nie da się zapisać jako wielomianów w pochodnych.
Metody rozwiązywania równań różniczkowych
Nie ma jednej metody działającej dla każdego równania różniczkowego. Właściwe podejście zależy od typu równania, jego rzędu oraz tego, czy istnieje rozwiązanie ścisłe.
W dużym uproszczeniu mamy dwie kategorie: metody analityczne i metody numeryczne.
Metody analityczne
Metody analityczne dają dokładne, zamknięte rozwiązanie — wzór, który można obliczyć w dowolnym punkcie. Gdy mają zastosowanie, są preferowane, bo wynik jest precyzyjny i odsłania strukturę rozwiązania.
Działają jednak tylko dla określonych form równań. Gdy równanie staje się zbyt złożone, metody analityczne dochodzą do ściany.
Rozdzielanie zmiennych
Rozdzielanie zmiennych działa dla równań, w których da się wydzielić wszystkie wyrażenia z y po jednej stronie, a wszystkie wyrażenia z x (lub t) po drugiej.
Rozważmy to ODE pierwszego rzędu:
Proste równanie różniczkowe
Krok 1 — rozdzielić zmienne:
Rozwiązanie analityczne (krok 1)
Krok 2 — scałkować obie strony:
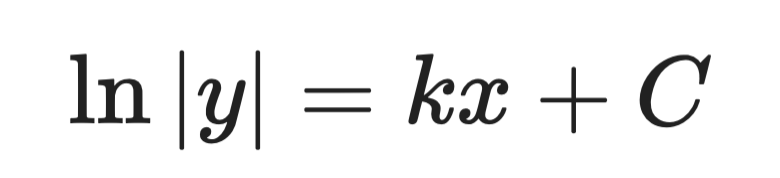
Rozwiązanie analityczne (krok 2)
Krok 3 — rozwiązać względem y:
Rozwiązanie analityczne (krok 3)
Gdzie A jest stałą wyznaczaną przez warunki początkowe. To rozwiązanie ogólne.
To ta sama postać, co równanie wzrostu bakterii. Mówi, że populacje — i wszystko inne, czego tempo wzrostu jest proporcjonalne do wielkości — rosną wykładniczo.
Współczynnik całkujący
Współczynnik całkujący stosuje się do liniowych ODE pierwszego rzędu w postaci:
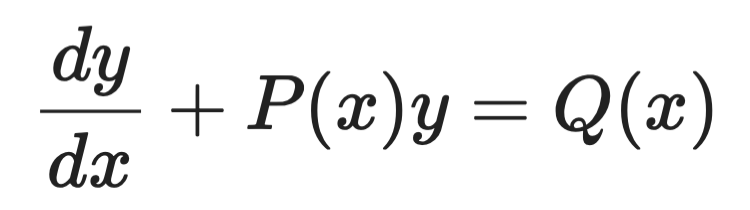
Przykład współczynnika całkującego (1)
Idea polega na przemnożeniu obu stron przez starannie dobraną funkcję — współczynnik całkujący μ(x) — który sprawia, że lewa strona staje się doskonałą pochodną, możliwą do bezpośredniego scałkowania.
Współczynnik całkujący ma zawsze postać:
Przykład współczynnika całkującego (2)
Po przemnożeniu równanie przyjmuje postać:
Przykład współczynnika całkującego (3)
Następnie całkujemy obie strony i rozwiązujemy względem y. Lewa strona upraszcza się elegancko dzięki temu, jak dobrano μ(x) — to cały sens metody.
Metody numeryczne
Większość równań różniczkowych ze świata rzeczywistego nie ma prostych rozwiązań analitycznych. Metody numeryczne przybliżają rozwiązanie krok po kroku, licząc wartości w punktach dyskretnych.
Zamieniają dokładność na ogólność. A w praktyce często właśnie tego potrzeba.
Metoda Eulera
Metoda Eulera to najprostsze podejście numeryczne. Idea polega na rozpoczęciu w znanym punkcie, użyciu pochodnej do oszacowania nachylenia, zrobieniu małego kroku w tym kierunku i powtarzaniu procesu.
Dla ODE pierwszego rzędu dy/dx = f(x, y) z warunkiem początkowym y(x₀) = y₀ każdy krok wygląda tak:
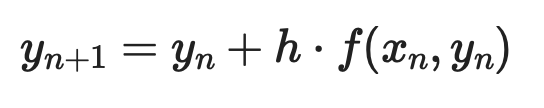
Przykład metody Eulera (1)
Gdzie h to krok. Mniejsze kroki oznaczają lepszą dokładność — ale większe koszty obliczeniowe.
Oto implementacja w Pythonie rozwiązująca dy/dx = y z y(0) = 1 (rozwiązanie dokładne to y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Metoda Eulera a rozwiązanie dokładne
Odstęp między dwiema liniami to błąd aproksymacji. Przy h=0.2 błąd na początku jest mały, ale kumuluje się z krokami — to główna słabość metody Eulera.
Metody Rungego-Kutty
Metody Rungego-Kutty rozwiązują problem kumulacji błędów, próbkując nachylenie w wielu punktach w obrębie kroku i biorąc średnią ważoną. Najpowszechniejszą wersją jest RK4 — metoda Rungego-Kutty czwartego rzędu.
Zamiast jednego oszacowania nachylenia na krok jak u Eulera, RK4 wylicza cztery:
Przykład metody Rungego-Kutty (1)
Następnie łączy je w całość:
Przykład metody Rungego-Kutty (2)
W praktyce nie implementuje się RK4 ręcznie. SciPy solve_ivp załatwia to za Państwa:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 a rozwiązanie dokładne
Krzywa RK45 niemal idealnie pokrywa się z rozwiązaniem dokładnym. Ten sam krok co w przykładzie Eulera, ale znacznie lepsza dokładność — to różnica wynikająca z ważonego próbkowania nachyleń.
W większości praktycznych zastosowań w Pythonie domyślny solver RK45 w solve_ivp będzie najczęstszym wyborem. Metoda Eulera jest przydatna, by zrozumieć działanie solverów numerycznych, ale w produkcji się jej nie stosuje.
Zastosowania równań różniczkowych w data science i uczeniu maszynowym
Inżynierowie używają równań różniczkowych do modelowania obwodów elektrycznych i systemów mechanicznych. Biolodzy — do śledzenia dynamiki populacji i rozprzestrzeniania się chorób. Fizyków — do opisu wszystkiego, od przewodnictwa ciepła po mechanikę kwantową.
Ale Państwo są tu dla data science, więc przejdźmy do sedna.
Uczenie maszynowe i optymalizacja
Najbardziej bezpośredni związek między równaniami różniczkowymi a ML to spadek gradientowy — algorytm stojący za trenowaniem niemal każdego budowanego modelu.
Podczas trenowania modelu minimalizują Państwo funkcję straty L. Aby to zrobić, trzeba wiedzieć, jak L zmienia się przy dostrajaniu każdego parametru. To tempo zmiany to pochodna. Gdy model ma wiele parametrów, liczy się pochodną cząstkową dla każdego z nich — razem tworzą gradient.
Spadek gradientowy używa tych pochodnych do aktualizacji parametrów krok po kroku:
Spadek gradientowy
Gdzie θ to parametr, η to współczynnik uczenia, a ∂L/∂θ to pochodna cząstkowa straty względem tego parametru.
Oto prosty przykład w Pythonie dopasowujący prostą do danych przy użyciu spadku gradientowego:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Dopasowanie prostej metodą spadku gradientowego i krzywa straty w iteracjach
Każda iteracja przesuwa parametry w kierunku, który zmniejsza stratę. Pochodne cząstkowe wskazują, który to kierunek. Bez nich spadek gradientowy nie działa — podobnie jak backpropagacja w sieciach neuronowych, która jest niczym innym, jak wielokrotnym zastosowaniem reguły łańcuchowej przez warstwy.
Analiza szeregów czasowych
Wiele systemów szeregów czasowych jest dynamicznych — bieżąca wartość zależy od wartości z przeszłości i tempa zmian. Równania różniczkowe pozwalają to opisać.
Filtr Kalmana, szeroko stosowany w śledzeniu i prognozowaniu, opiera się na systemie równań różniczkowych, które modelują, jak ukryty stan ewoluuje w czasie i jak szumne obserwacje odnoszą się do tego stanu. Wykorzystuje się go w systemach GPS, finansach i prognozowaniu pogody.
Modele ARIMA służą do prognozowania szeregów czasowych i łączą się z równaniami różniczkowymi poprzez pojęcie różnicowania. Branie różnic pierwszego lub drugiego rzędu to dyskretne przybliżenie pochodnych pierwszej i drugiej. Gdy różniczkują Państwo szereg, by uczynić go stacjonarnym, pytają Państwo: jak ten szereg zmienia się w czasie?
Modelowanie statystyczne i regresja
To często zaskakuje: rozwiązanie układu równań różniczkowych to jeden ze sposobów wyprowadzenia współczynników regresji liniowej.
Podczas dopasowywania modelu regresji liniowej minimalizuje się sumę kwadratów reszt. Bierzemy pochodne cząstkowe tej straty względem każdego współczynnika, przyrównujemy do zera i rozwiązujemy. To daje równanie normalne:
Równanie normalne
Każdy współczynnik regresji, jaki kiedykolwiek Państwo policzyli, pochodził z przyrównania pochodnej do zera i rozwiązania. To rachunek różniczkowy — i ta sama zasada stoi za każdym modelem parametrycznym, który Państwo dopasowują.
W przypadku regresji logistycznej funkcja straty nie jest kwadratowa, więc nie ma rozwiązania w postaci zamkniętej. Trzeba użyć metod iteracyjnych, takich jak spadek gradientowy, który znów w każdym kroku opiera się na pochodnych cząstkowych.
Związek sięga dalej. Rozkład QR, jedna ze standardowych metod numerycznych rozwiązywania równania normalnego, bazuje na algebrze liniowej, która bezpośrednio przecina się ze sposobami rozwiązywania układów równań — w tym różniczkowych — w praktyce.
Symulacja systemów dynamicznych
Gdy trzeba zamodelować, jak system ewoluuje w czasie — a rozwiązanie analityczne nie istnieje — symuluje się go numerycznie.
To powszechne w biznesie i operacjach. Odpływ klientów, poziomy zapasów i dynamika łańcucha dostaw obejmują wielkości zmieniające się w zależności od stanu bieżącego. Można zapisać te zależności jako równania różniczkowe i zasymulować je za pomocą solve_ivp.
Oto przykład symulujący prosty układ popyt–podaż, w którym zapas I wyczerpuje się w tempie proporcjonalnym do popytu D, a sam popyt zmienia się w czasie:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)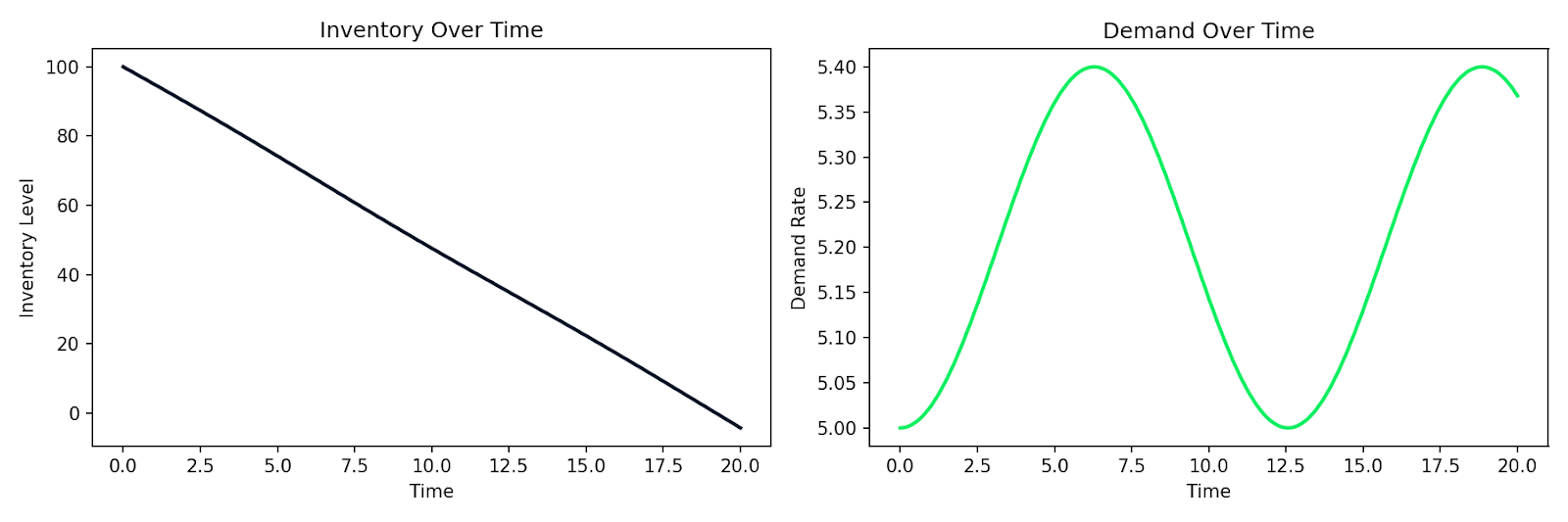
Symulowane wyczerpywanie zapasów wraz ze zmieniającym się popytem w czasie
Ten sam schemat dotyczy modelowania zachowań klientów, rozprzestrzeniania się epidemii w bazie użytkowników czy dowolnego systemu, w którym tempo zmian zależy od bieżącego stanu. Spisują Państwo zależności, przekazują je solverowi numerycznemu i otrzymują symulację.
I to jest praktyczna siła równań różniczkowych w data science. To bezpośrednie narzędzie do modelowania systemów, które się zmieniają.
Podsumowanie
Za spadkiem gradientowym stoją pochodne cząstkowe. Za prognozowaniem szeregów czasowych — systemy dynamiczne. Za współczynnikami regresji liniowej — pochodne przyrównane do zera. Trzeba tylko wiedzieć, gdzie patrzeć.
W tym artykule wyjaśniłem, czym są równania różniczkowe, różnicę między ODE a PDE, jak rząd i stopień je klasyfikują oraz główne metody ich rozwiązywania — analityczne i numeryczne. Następnie zobaczyliśmy, gdzie faktycznie pojawiają się one na co dzień w data science i uczeniu maszynowym.
To dopiero podstawa. Jeśli chcą Państwo zgłębić więcej tematów matematycznych, dobrym kolejnym krokiem jest kurs Algebra liniowa dla data science w R. Aby poćwiczyć praktycznie stosowanie tych koncepcji do realnych problemów danych, prosimy zajrzeć do kursu Analityk ilościowy w R.