実は、ニューラルネットワークを学習させるときも、回帰モデルを当てはめるときも、微分方程式の成果を毎回使っています。根底にある数学は微積分であり、その中心に微分方程式があります。勾配降下法がなぜ機能するのか、カルマンフィルタが動く物体をどう追跡するのか——その答えが微分方程式です。
微分方程式を使うと、ものごとが「時間とともにどう変化するか」をモデル化できます——それこそがデータサイエンスの本質です。核となる考え方がわかれば、あらゆるところに見えてきます。最小化している損失関数、予測する時系列、実行するシミュレーションの中に。
本記事では、微分方程式とは何か、目にする主なタイプ、解き方、そして——最も重要な点として——それが日々のデータサイエンスや機械学習のどこに現れるのかを解説します。
微分方程式とは?
微分方程式とは、ある関数とその導関数を関係づける方程式です。
平たく言えば、導関数はある時点でどれだけ速く変化しているかを表します。微分方程式は、ある量の変化率が、その量自身や時間、あるいはその両方に依存することを表します。
細菌の個体群をモデル化するとします。細菌が多いほど、増殖は速くなります。つまり成長率は現在の個体数に依存します。これを方程式で書けば、微分方程式になります。
形式的には次のようになります。
微分方程式の表現
ここで、Pは個体数、tは時間、rは成長率です。左辺は導関数で、Pが時間とともにどれだけ速く変化するかを表します。右辺は、その変化がP自身に比例することを意味します。
これが、目にするあらゆる微分方程式の核となる考え方です。
微分方程式は、時間とともに系が進化するあらゆる領域——物理学、生物学、工学——に現れます。金属棒を伝わる熱、振り子の運動、集団内に広がるウイルス。いずれも微分方程式でモデル化されます。
データサイエンティストにとっては、損失関数、勾配降下法、時系列モデル、Neural ODE などに微分方程式が潜んでいます。明示的に見えないこともありますが、確かにそこにあります。
それを理解すれば、日々使うツールがなぜ、どのように機能するのかをより明確に捉えられるようになります。
微分方程式の歴史
17世紀後半、アイザック・ニュートンとゴットフリート・ライプニッツがそれぞれ独自に微積分を発展させました。両者は物理量が時間とともにどう変化するかを記述する手段を必要としており、その成果が微分方程式でした。ニュートンは運動や重力のモデル化に用い、ライプニッツは今日でも使われる多くの記法、たとえば教科書でおなじみのd/dtを導入しました。
18〜19世紀には新しい手法が次々と登場しました。
レオンハルト・オイラーは常微分方程式を数値的に解く手法を開発しました——本記事の後半で登場するオイラー法のオイラーです。ジョゼフ=ルイ・ラグランジュやピエール=シモン・ラプラスは理論をより複雑な系へ拡張しました。ジャン=バティスト・ジョゼフ・フーリエは関数を正弦・余弦成分に分解する方法を導入し、偏微分方程式を解く上での礎となりました。
20世紀になると、微分方程式は流体力学、量子力学、電気工学などあらゆる分野に広がりました。現実の多くの方程式はきれいな解析解を持たず、そこで数値解法が主役となり、コンピュータがスケール面でそれを実用的にしました。
今日もこの分野は進化を続けています。Neural ODE(ニューラル常微分方程式)は、ニューラルネットワークの層を微分方程式で記述される連続過程として扱います。これは深層学習と古典数学の境界を曖昧にする新しい発展で、現代の機械学習研究でも注目の領域です。
とはいえ、核となる考え方は変わりません。変化をモデル化できれば、その先を予測できるのです。
微分方程式の種類
微分方程式は一様ではありません。まずはそれらを見分ける方法を知る必要があります。
大きく分けると、常微分方程式(ODE)と偏微分方程式(PDE)に分かれます。違いは、その関数が依存する独立変数の数にあります。
常微分方程式(ODE)
常微分方程式は、単一の独立変数の関数とその導関数を含みます。
先ほどの細菌の個体群の例は ODE です。個体数Pは時間tのみに依存します——独立変数は1つです。したがって、方程式に現れるのはdP/dtのような常微分のみです。
ODE は、通常は時間という単一の次元に沿って系が進化する場合に適しています。代表例をいくつか挙げます。
- 個体群の成長——個体数の変化率は現在の個体数に依存する
- 放射性崩壊——崩壊の速度は残存量に依存する
- ニュートンの第二法則——物体の加速度は作用する力に依存する
いずれも、1つの変数が変化を駆動しています。これが「常微分」である理由です。
偏微分方程式(PDE)
偏微分方程式は、複数の独立変数の関数と、その偏導関数を含みます。
金属棒を伝わる熱の広がりをモデル化したいとします。任意の点の温度は、棒のどの位置にいるかと、どの時刻かの双方に依存します。独立変数は位置xと時間tの2つです。これを方程式にすると、xに関するものとtに関するものという2種類の偏導関数が現れます。
これが PDE です。熱方程式は最もよく知られた例の1つです。
偏微分方程式の例
ここで、u(x, t)は位置x・時刻tにおける温度、αは材料の熱拡散率、∂u/∂tは温度の時間変化の速さ、∂²u/∂x²は空間における温度分布の曲率を表します。温度曲線の曲がりが急なところでは熱が速く再分配され、平坦なところでは変化が小さい、ということを方程式が述べています。
PDE は、空間と時間にわたり系が変動する場面で現れます。
- 熱の分布——温度は位置と時間の両方で変化する
- 波の伝播——音波や光波が時間とともに空間へ広がる
- 流体力学——流速は3次元空間内の位置と時間に依存する
PDE を解くのは ODE より難しく、解析解は特定の形に限られます。実用的には多くの場合、数値解法が唯一の現実的な手段です。
データサイエンスの現場では ODE に出会うことの方が多いでしょう。しかし、画像処理や物理シミュレーション、一部の深層学習アーキテクチャでは PDE も登場するため、両者の違いは押さえておく必要があります。
微分方程式の階数と次数
すべての微分方程式には、その複雑さを示す2つの属性——階数(order)と次数(degree)——があります。
これらは適用できる解法を決めるため、解き始める前に見極める必要があります。
階数の理解
微分方程式の階数は、その式に含まれる最高次の導関数の階数です。
最高次の導関数が一次導関数(dy/dx)なら一階の方程式、二次導関数(d²y/dx²)なら二階の方程式、という具合です。
先ほどの細菌増殖の方程式をもう一度見てみましょう。
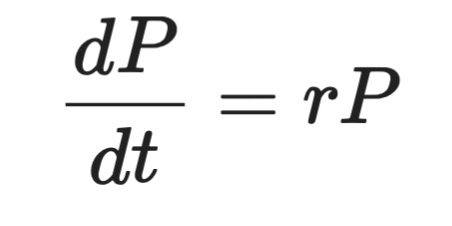
細菌増殖の方程式
ここでの最高次の導関数はdP/dt、つまり一次導関数です。したがって、これは一階の ODE です。
これと、振り子の運動を表す方程式を比べてみましょう。
振り子の運動方程式
最高次の導関数はd²θ/dt²、つまり二次導関数です。したがって二階の ODE になります。
階数が高いほど複雑になります。二階の方程式を解くには、一次では1つでよい初期条件が2つ必要です。実務では、機械運動、電気回路、軌道力学など多くの物理系が二階の方程式でモデル化されます。
次数の理解
微分方程式の次数は、その方程式を導関数に関する多項式の形(導関数を含む根号や分数を含まない形)に書いたときの、最高階の導関数のべきです。
次の方程式を考えます。
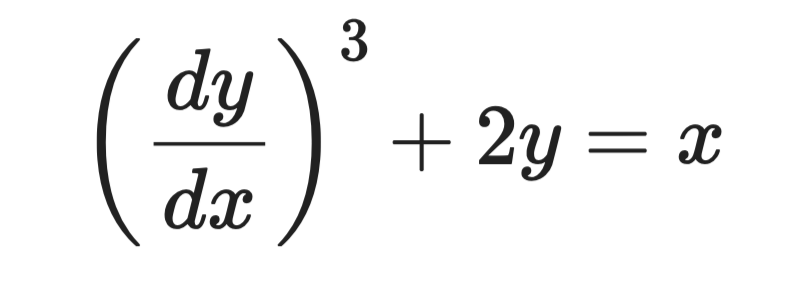
微分方程式の例
最高次の導関数はdy/dxで、その三乗が現れます。したがって階数は1、次数は3です。
では次の方程式ではどうでしょうか。
微分方程式の例(2)
最高階の導関数はd²y/dx²で、そのべきは1です。低い階の導関数がより高いべきで現れていても、次数は1のままです。
次数は常に、式中で最も高い階の導関数に対して定まります。式中の最大のべきそのものではありません。
特殊な例として、sin(dy/dx)やe^(d²y/dx²)のような項が含まれる場合があります。このとき次数は定義できません——それらは導関数に関する多項式として表せないからです。
微分方程式の解法
すべての微分方程式に通用する単一の解法はありません。適切なアプローチは、方程式の種類や階数、そもそも厳密解が存在するかどうかに依存します。
大別すると、解析的手法と数値的手法があります。
解析的手法
解析的手法は厳密な閉形式解——任意の点で評価できる公式——を与えます。適用できるなら望ましく、結果が正確で解の構造についての洞察も得られます。
ただし適用範囲は特定の形に限られ、方程式が複雑になると解析的手法は行き詰まります。
変数分離法
変数分離法は、yに関する項を一方に、x(またはt)に関する項をもう一方に分離できる方程式に有効です。
次の一次 ODE を考えます。
単純な微分方程式
ステップ1 —— 変数を分離します。
解析解(ステップ1)
ステップ2 —— 両辺を積分します。
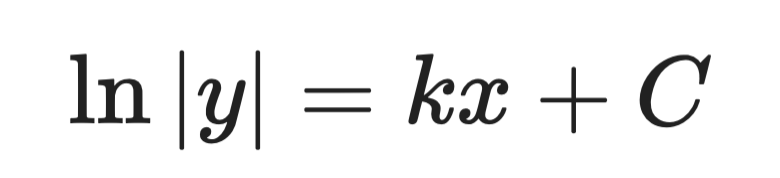
解析解(ステップ2)
ステップ3 —— yについて解きます。
解析解(ステップ3)
ここでAは初期条件で定まる定数です。これが一般解です。
これは細菌増殖の方程式と同じ形で、個体群——および成長率がその大きさに比例するあらゆるもの——が指数関数的に増えることを示します。
積分因子法
積分因子法は、次の形の一次線形 ODE を扱います。
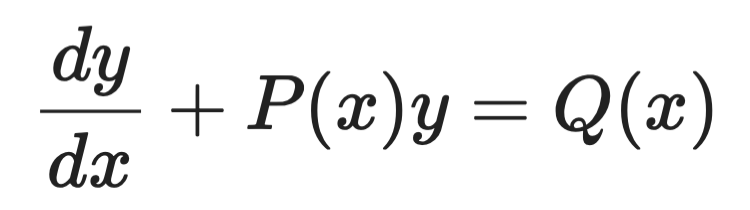
積分因子の例(1)
ポイントは、両辺に慎重に選んだ関数——積分因子μ(x)——を掛け、左辺を直ちに積分できる完全微分の形にすることです。
積分因子は常に次の形です。
積分因子の例(2)
これを掛けると、方程式は次のようになります。
積分因子の例(3)
あとは両辺を積分してyについて解きます。左辺がすっきりと崩れるのはμ(x)の選び方ゆえで——それこそがこの手法の狙いです。
数値的手法
現実世界の多くの微分方程式は、きれいな解析解を持ちません。数値的手法は解を離散点で逐次的に近似していきます。
厳密性を一般性と引き換えにしますが、実務ではそれが必要なことが多いのです。
オイラー法
オイラー法は最も単純な数値解法です。既知の点から始め、導関数で傾きを見積もり、その方向に小さく進み、これを繰り返します。
一次 ODE dy/dx = f(x, y)と初期条件y(x₀) = y₀が与えられたとき、各ステップは次のようになります。
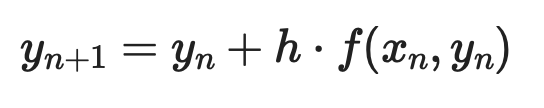
オイラー法の例(1)
ここでhは刻み幅です。刻みを小さくすれば精度は上がりますが、計算量も増えます。
次は、y(0) = 1のもとでdy/dx = yを解く Python 実装です(厳密解はy = eˣ)。
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
オイラー法と厳密解の比較
2本の線の間の差が近似誤差です。h=0.2では、誤差は当初は小さいもののステップを重ねると蓄積します——これがオイラー法の主な弱点です。
ルンゲ=クッタ法
ルンゲ=クッタ法は、各ステップ内で複数点の傾きをサンプリングして加重平均することで、その誤差の蓄積を抑えます。最も一般的なのはRK4(四次のルンゲ=クッタ法)です。
オイラー法がステップごとに1つの傾き推定しか使わないのに対し、RK4 は4つ計算します。
ルンゲ=クッタ法の例(1)
そして次のように組み合わせます。
ルンゲ=クッタ法の例(2)
実務では RK4 を自前実装する必要はありません。SciPy のsolve_ivpが面倒を見てくれます。
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 と厳密解の比較
RK45 の線は厳密解のほぼ真上に重なっています。刻み幅はオイラー法の例と同じでも、精度は大きく向上します——傾きの加重サンプリングの効果です。
Python 実務の多くでは、既定の RK45 ソルバーを用いたsolve_ivpが第一選択となるでしょう。オイラー法は数値解法の仕組みを理解するには有用ですが、本番では通常使いません。
データサイエンスと機械学習における微分方程式の応用
エンジニアは電気回路や機械システムのモデル化に、⽣物学者は個体群動態や感染拡大の追跡に、物理学者は熱伝導から量子力学までの記述に微分方程式を使います。
ただ、ここではデータサイエンスの話に絞りましょう。
機械学習と最適化
微分方程式と ML の最も直接的な結びつきは、ほぼすべてのモデル学習の根幹にある勾配降下法です。
モデルを学習させるとき、損失関数Lを最小化します。そのためには、各パラメータを調整したときにLがどう変わるかを知る必要があります。これが導関数(微分)です。パラメータが複数ある場合は、それぞれについて偏微分を計算し、それらをまとめたものが勾配になります。
勾配降下法は、これらの導関数を使ってパラメータを逐次更新します。
勾配降下法
ここでθはパラメータ、ηは学習率、∂L/∂θはそのパラメータに関する損失の偏微分です。
以下は勾配降下法でデータに直線を当てはめる簡単な Python の例です。
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
勾配降下法でデータに直線を当てはめた様子と、反復ごとの損失曲線
各反復で、損失が減る方向へパラメータが動きます。どちらの方向かを教えるのが偏微分です。これがなければ勾配降下法は機能せず、層をまたいで連鎖律を繰り返し適用するだけの誤差逆伝播法(バックプロパゲーション)も同様に成り立ちません。
時系列分析
多くの時系列システムは動的です——現在の値は過去の値や変化の速さに依存します。微分方程式はそれを記述する手段を与えます。
カルマンフィルタは、隠れ状態が時間とともにどう進化するか、またノイズを含む観測がその状態にどう結びつくかを表す微分方程式系に基づいており、追跡や予測で広く使われます。GPS、金融、天気予報などで用いられます。
ARIMA モデルは時系列予測に使われ、差分という概念を通じて微分方程式とつながります。一次・二次差分をとることは、一次・二次導関数の離散的な近似です。系列を定常化するために差分をとるとき、「この系列は時間とともにどう変化しているか?」と問うているのです。
統計モデリングと回帰
しばしば驚かれる点ですが、連立微分方程式を解くことは、線形回帰の係数を導出する1つの方法でもあります。
線形回帰モデルを当てはめるときは、残差平方和を最小化します。その損失を各係数で偏微分し、ゼロに等置して解くと、正規方程式が得られます。
正規方程式
これまでに計算したすべての回帰係数は、導関数をゼロに置いて解くことから得られています。これが微積分であり、あらゆるパラメトリックモデルに共通する原理です。
ロジスティック回帰では損失関数が二次式ではないため、閉形式解は存在しません。勾配降下法のような反復法を使う必要があり、ここでも毎ステップで偏微分に依存します。
この関係はさらに広がります。正規方程式を解く標準的な数値手法の1つであるQR 分解は、連立方程式——微分方程式を含む——の実務的な解法と直結する線形代数に基づいています。
動的システムのシミュレーション
系が時間とともにどう進化するかをモデル化する必要があり、解析解が存在しない場合は、数値的にシミュレーションします。
これはビジネスやオペレーションの文脈で一般的です。顧客離反、在庫水準、サプライチェーンのダイナミクスなど、いずれも現在の状態に依存して変化します。これらの関係を微分方程式として書き下し、solve_ivpでシミュレーションできます。
次は、在庫Iが需要Dに比例した速度で減少し、需要が時間とともに変動するという単純な需給システムのシミュレーション例です。
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)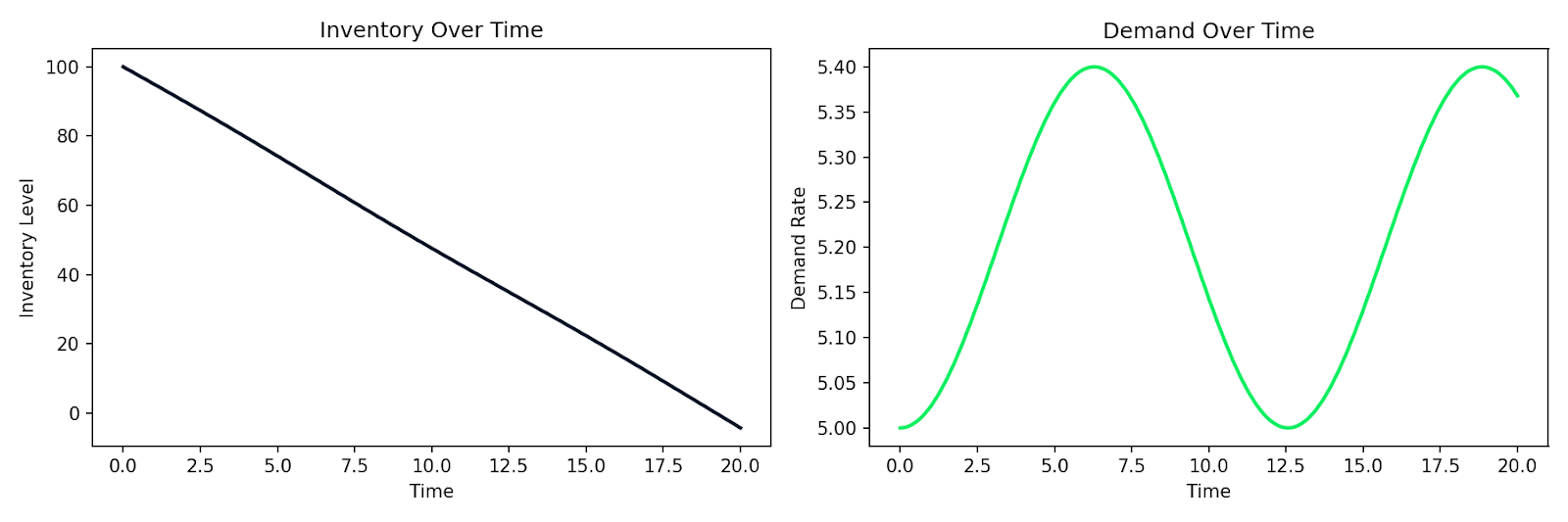
需要の変動に伴う在庫減少のシミュレーション
同じパターンは、顧客行動のモデル化、ユーザーベースでの疫学的拡大、あるいは状態に依存して変化率が決まるあらゆるシステムに当てはまります。関係式を書き、数値ソルバーに渡し、シミュレーション結果を得るのです。
これが、データサイエンスにおける微分方程式の実践的な力です。変化する系を直接モデル化できる道具なのです。
まとめ
勾配降下法の背後には偏微分があり、時系列予測の背後には動的システムがあり、線形回帰の係数の背後には導関数をゼロに置く操作があります。見るべき場所がわかれば見えてきます。
本記事では、微分方程式とは何か、ODE と PDE の違い、階数と次数による分類、解析的・数値的の主要な解法を説明しました。さらに、日々のデータサイエンスや機械学習のどこに登場するのかを見てきました。
ここは土台にすぎません。数学トピックをさらに学ぶなら、Linear Algebra for Data Science in R コースが次の一歩として適しています。これらの概念を実データ問題に適用するハンズオン練習には、Quantitative Analyst in R コースをご覧ください。