Som det visar sig använder du resultaten av differentialekvationer varje gång du tränar ett neuralt nätverk eller till och med anpassar en regressionsmodell. Matten under ytan är analys, och differentialekvationer står i dess centrum. Om du någonsin har undrat varför gradientnedstigning fungerar, eller hur ett Kalmanfilter spårar ett rörligt objekt, så är differentialekvationer ditt svar.
Differentialekvationer låter dig modellera hur saker förändras över tid – och det är precis vad data science handlar om. När du väl förstår grundidéerna kommer du att se dem överallt: i förlustfunktionerna du minimerar, i tidsserierna du prognostiserar och i simuleringarna du kör.
I den här artikeln går jag igenom vad differentialekvationer är, de huvudtyper du kommer att stöta på, hur man löser dem och – viktigast av allt – hur de visar sig i verklig data science och maskininlärning i vardagen.
Vad är differentialekvationer?
En differentialekvation är en ekvation som relaterar en funktion till dess egna derivator.
Enkelt uttryckt talar en derivata om hur snabbt något förändras i ett givet ögonblick. En differentialekvation säger att förändringstakten för en storhet beror på storheten själv, eller på tiden, eller på båda.
Säg att du modellerar en population av bakterier. Ju fler bakterier du har, desto snabbare förökar de sig. Så tillväxthastigheten beror på den aktuella populationsstorleken. Skriver du det som en ekvation har du en differentialekvation.
Formellt ser det ut så här:
Representation av en differentialekvation
Där P är populationen, t är tiden och r är tillväxthastigheten. Vänsterledet är derivatan – hur snabbt P förändras över tid. Högerledet säger att förändringen är proportionell mot P självt.
Det är kärnidén bakom varje differentialekvation du stöter på.
Differentialekvationer dyker upp inom fysik, biologi och teknik – överallt där ett system utvecklas över tid. Värme som sprider sig genom en metallstav, en pendel som svänger, ett virus som sprids i en population. Allt detta modelleras med differentialekvationer.
För data scientists ser du differentialekvationer i förlustfunktioner, gradientnedstigning, tidsseriemodeller, neurala ODE:er – de har alla differentialekvationer under huven. Du ser dem inte alltid explicit, men de finns där.
När du förstår dem får du en tydligare mental modell av varför och hur de verktyg du använder varje dag fungerar.
Differentialekvationernas historia
I slutet av 1600-talet utvecklade Isaac Newton och Gottfried Wilhelm Leibniz oberoende av varandra infinitesimalkalkylen. Båda behövde ett sätt att beskriva hur fysiska storheter förändras över tid, och differentialekvationer blev resultatet. Newton använde dem för att modellera rörelse och gravitation. Leibniz gav oss mycket av den notation vi fortfarande använder idag, inklusive d/dt som du ser i varje lärobok i analys.
1700- och 1800-talen förde med sig en våg av nya tekniker.
Leonhard Euler utvecklade metoder för att lösa ODE:er numeriskt – samme Euler bakom Eulers metod som du ser senare i den här artikeln. Joseph-Louis Lagrange och Pierre-Simon Laplace utvidgade teorin till mer komplexa system. Jean-Baptiste Joseph Fourier introducerade ett sätt att dekomponera funktioner i sinus- och cosinuskomponenter, vilket blev en hörnsten i lösningen av partiella differentialekvationer.
Under 1900-talet fanns differentialekvationer överallt, från strömningsdynamik och kvantmekanik till elektroteknik. Många verkliga ekvationer hade ingen snygg analytisk lösning. Där tog numeriska metoder över, och datorer gjorde dem praktiskt användbara i stor skala.
Idag rör sig fältet vidare. Neurala ordinära differentialekvationer (Neural ODEs) betraktar lagren i ett neuralt nätverk som en kontinuerlig process beskriven av en differentialekvation. Det är en nyare utveckling som suddar ut gränsen mellan djupinlärning och klassisk matematik. Det är också ett av de mer spännande områdena inom modern ML-forskning.
Med det sagt förblir kärnidén densamma: modellera hur saker förändras, så kan du förutsäga vart de är på väg.
Typer av differentialekvationer
Alla differentialekvationer är inte likadana. Det första du behöver veta är hur du skiljer dem åt.
Den huvudsakliga uppdelningen är mellan ordinära differentialekvationer (ODE) och partiella differentialekvationer (PDE). Skillnaden handlar om hur många oberoende variabler funktionen beror på.
Ordinära differentialekvationer (ODE)
En ordinär differentialekvation involverar en funktion av en enda oberoende variabel och dess derivator.
Exemplet med bakteriepopulationen ovan är en ODE. Populationen P beror bara på tiden t – en variabel. Så ekvationen har bara ordinära derivator, skrivna som dP/dt.
ODE är rätt verktyg när ditt system utvecklas längs en enda dimension, oftast tiden. Här är ett par klassiska exempel:
- Populationstillväxt – förändringstakten i en population beror på den nuvarande populationsstorleken
- Radioaktivt sönderfall – takten med vilken ett ämne sönderfaller beror på hur mycket som återstår
- Newtons andra lag – ett objekts acceleration beror på de krafter som verkar på det
I varje fall är det en variabel som driver förändringen. Det är det som gör den ordinär.
Partiella differentialekvationer (PDE)
En partiell differentialekvation involverar en funktion av flera oberoende variabler och dess partiella derivator.
Säg att du vill modellera hur värme sprider sig genom en metallstav. Temperaturen vid en punkt beror både på var du är längs staven och på vilken tidpunkt det är. Det är två oberoende variabler: position x och tid t. När du skriver en ekvation för det får du partiella derivator – en med avseende på x, en med avseende på t.
Det är en PDE. Värmeekvationen är ett av de mest kända exemplen:
Exempel på partiell differentialekvation
Där u(x, t) är temperaturen vid position x och tid t, α är materialets värmediffusivitet, ∂u/∂t är hur snabbt temperaturen förändras över tid, och ∂²u/∂x² beskriver hur krökt temperaturprofilen är i rummet. Ekvationen säger att där temperaturkurvan böjer kraftigt, omfördelas värme snabbt. Där den är platt händer inte mycket.
PDE dyker upp varhelst ett system varierar över rum och tid:
- Värmefördelning – temperaturen förändras över både position och tid
- Vågutbredning – ljud- eller ljusvågor sprider sig i rummet över tid
- Strömningsdynamik – vätskans hastighet beror på position i 3D-rum och tid
PDE är svårare att lösa än ODE. Analytiska lösningar finns bara för specifika former, och numeriska metoder är ofta den enda praktiska vägen framåt.
För de flesta data science-uppgifter kommer du oftare att stöta på ODE. Men PDE förekommer i bildbehandling, fysikaliska simuleringar och vissa djupinlärningsarkitekturer, så du behöver känna till skillnaderna.
Ordning och grad hos differentialekvationer
Varje differentialekvation har två egenskaper som säger något om dess komplexitet: dess ordning och dess grad.
Dessa avgör vilka lösningsmetoder som kan användas, så du behöver identifiera dem innan du försöker lösa något.
Förstå ordning
Ordningen hos en differentialekvation är ordningen på den högsta derivatan i ekvationen.
Om den högsta derivatan är en första derivata (dy/dx) är det en första ordningens ekvation. Om den högsta är en andra derivata (d²y/dx²) är det en andra ordningens ekvation. Och så vidare.
Här är bakterietillväxtekvationen från tidigare:
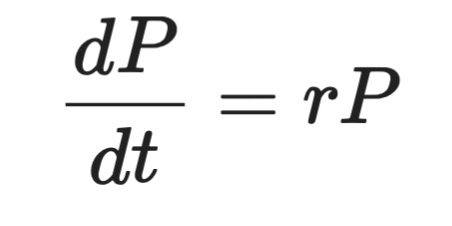
Bakterietillväxtekvation
Den högsta derivatan här är dP/dt – en första derivata. Så detta är en ODE av första ordningen.
Jämför det med ekvationen som beskriver en svängande pendel:
Ekvation för svängande pendel
Den högsta derivatan är d²θ/dt² – en andra derivata. Det gör den till en ODE av andra ordningen.
Högre ordning betyder mer komplexitet. Andra ordningens ekvationer behöver två begynnelsevillkor för att lösas i stället för ett. I praktiken modelleras de flesta fysiska system – mekanisk rörelse, elektriska kretsar, banmekanik – med ekvationer av andra ordningen.
Förstå grad
Graden hos en differentialekvation är exponenten på den högsta ordningens derivata, när ekvationen skrivs i polynomform (inga rötter eller bråk som involverar derivator).
Ta den här ekvationen:
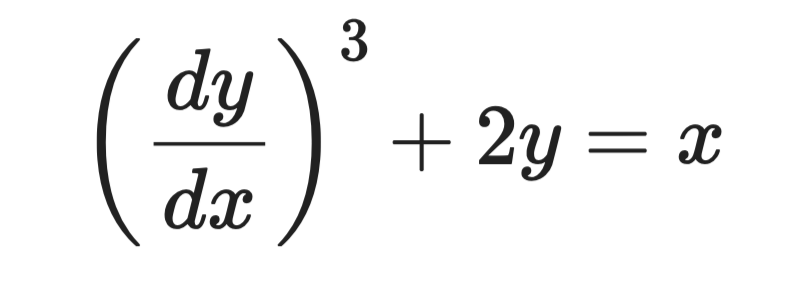
Exempel på differentialekvation
Den högsta derivatan är dy/dx, och den är upphöjd till 3. Så ordningen är 1 och graden är 3.
Ta nu den här:
Exempel på differentialekvation (2)
Den högsta ordningens derivata är d²y/dx², upphöjd till 1. Graden är 1, även om en derivata av lägre ordning förekommer med högre exponent.
Graden följer alltid den högsta ordningens derivata, inte den högsta exponenten i ekvationen.
Ett gränsfall är om en ekvation innehåller termer som sin(dy/dx) eller e^(d²y/dx²). Då är graden odefinierad – de formerna kan inte uttryckas som polynom i derivatorna.
Metoder för att lösa differentialekvationer
Det finns ingen enda metod som fungerar för varje differentialekvation. Rätt angreppssätt beror på ekvationens typ, ordning och om en exakt lösning ens existerar.
Övergripande har du två kategorier: analytiska metoder och numeriska metoder.
Analytiska metoder
Analytiska metoder ger en exakt, slutet-form-lösning – en formel du kan utvärdera vid varje punkt. De föredras när de är tillämpliga eftersom resultatet är precist och säger något om lösningens struktur.
Men de fungerar bara för specifika ekvationsformer. När ekvationen blir för komplex tar analytiska metoder stopp.
Variabelseparation
Variabelseparation fungerar på ekvationer där du kan isolera alla termer som involverar y på ena sidan och alla termer som involverar x (eller t) på den andra.
Ta denna första ordningens ODE:
Enkel differentialekvation
Steg 1 – separera variablerna:
Analytisk lösning (steg 1)
Steg 2 – integrera båda sidorna:
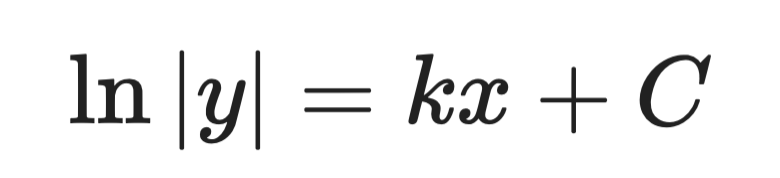
Analytisk lösning (steg 2)
Steg 3 – lös ut y:
Analytisk lösning (steg 3)
Där A är en konstant som bestäms av begynnelsevillkor. Det är den allmänna lösningen.
Detta är samma form som bakterietillväxtekvationen. Den säger att populationer – och allt annat med en tillväxthastighet proportionell mot sin storlek – växer exponentiellt.
Integrerande faktor
Integrerande faktorer hanterar linjära ODE av första ordningen av denna form:
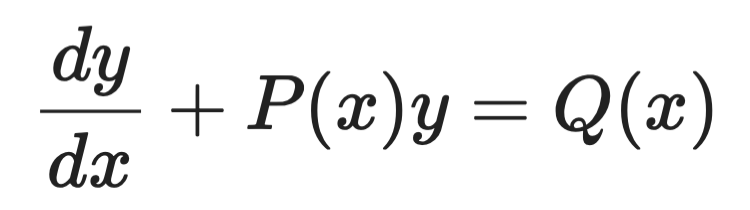
Exempel på integrerande faktor (1)
Idén är att multiplicera båda sidor med en noggrant vald funktion – den integrerande faktorn μ(x) – som gör vänsterledet till en perfekt derivata som du kan integrera direkt.
Den integrerande faktorn är alltid:
Exempel på integrerande faktor (2)
Efter att ha multiplicerat igenom blir ekvationen:
Exempel på integrerande faktor (3)
Integrera sedan båda sidorna och lös ut y. Vänsterledet kollapsar alltid snyggt tack vare hur μ(x) valdes – det är hela poängen med metoden.
Numeriska metoder
De flesta verkliga differentialekvationer har inga snygga analytiska lösningar. Numeriska metoder approximerar lösningen steg för steg och beräknar värden i diskreta punkter.
De byter exakthet mot generalitet. Och i praktiken är det ofta precis vad du behöver.
Eulers metod
Eulers metod är det enklaste numeriska angreppssättet. Idén är att starta i en känd punkt, använda derivatan för att uppskatta lutningen, ta ett litet steg i den riktningen och upprepa.
Givet en första ordningens ODE dy/dx = f(x, y) med begynnelsevillkor y(x₀) = y₀ ser varje steg ut så här:
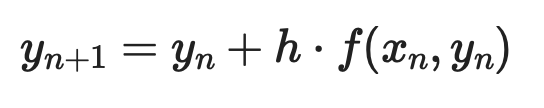
Exempel på Eulers metod (1)
Där h är steglängden. Mindre steg ger bättre noggrannhet – men mer beräkning.
Här är en Python-implementation som löser dy/dx = y med y(0) = 1 (den exakta lösningen är y = eˣ):
import numpy as np
import matplotlib.pyplot as plt
def euler_method(f, x0, y0, h, n_steps):
x = np.zeros(n_steps + 1)
y = np.zeros(n_steps + 1)
x[0], y[0] = x0, y0
for i in range(n_steps):
y[i+1] = y[i] + h * f(x[i], y[i])
x[i+1] = x[i] + h
return x, y
f = lambda x, y: y # dy/dx = y
x_euler, y_euler = euler_method(f, x0=0, y0=1, h=0.2, n_steps=20)
x_exact = np.linspace(0, 4, 200)
y_exact = np.exp(x_exact)
Eulers metod jämfört med den exakta lösningen
Gapet mellan de två linjerna är approximationsfelet. Med h=0.2 är felet litet till en början men byggs på över stegen – det är Eulers metods främsta svaghet.
Runge–Kutta-metoder
Runge–Kutta-metoder åtgärdar problemet med ackumulerande fel genom att sampla lutningen vid flera punkter inom varje steg och ta ett viktat medelvärde. Den vanligaste versionen är RK4 – Runge–Kutta av fjärde ordningen.
Istället för en lutningsuppskattning per steg som i Euler beräknar RK4 fyra:
Exempel på Runge–Kutta-metod (1)
Och kombinerar dem sedan:
Exempel på Runge–Kutta-metod (2)
I praktiken implementerar du inte RK4 för hand. SciPys solve_ivp sköter det åt dig:
from scipy.integrate import solve_ivp
import numpy as np
import matplotlib.pyplot as plt
f = lambda x, y: y # dy/dx = y
sol = solve_ivp(f, t_span=[0, 4], y0=[1], max_step=0.2)
RK45 jämfört med den exakta lösningen
RK45-kurvan ligger nästan perfekt ovanpå den exakta lösningen. Samma steglängd som i Euler-exemplet, men mycket bättre noggrannhet – det är skillnaden som viktad lutningssampling gör.
För de flesta praktiska uppgifter i Python är solve_ivp med standardlösaren RK45 ditt förstahandsval. Eulers metod är användbar för att förstå hur numeriska lösare fungerar, men du skulle inte använda den i produktion.
Tillämpningar av differentialekvationer i data science och maskininlärning
Ingenjörer använder differentialekvationer för att modellera elektriska kretsar och mekaniska system. Biologer använder dem för att följa populationsdynamik och sjukdomsspridning. Fysiker använder dem för att beskriva allt från värmetransport till kvantmekanik.
Men du är här för data science, så låt oss gå dit.
Maskininlärning och optimering
Den mest direkta kopplingen mellan differentialekvationer och ML är gradientnedstigning – algoritmen bakom träningen av nästan varje modell du bygger.
När du tränar en modell minimerar du en förlustfunktion L. För att göra det behöver du veta hur L förändras när du justerar varje parameter. Den förändringstakten är en derivata. När din modell har flera parametrar beräknar du en partiell derivata för var och en – tillsammans bildar de gradienten.
Gradientnedstigning använder dessa derivator för att uppdatera parametrar steg för steg:
Gradientnedstigning
Där θ är parametern, η är inlärningshastigheten och ∂L/∂θ är den partiella derivatan av förlusten med avseende på den parametern.
Här är ett enkelt Python-exempel som anpassar en linje till data med gradientnedstigning:
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
X = np.linspace(0, 10, 100)
y = 2.5 * X + np.random.randn(100) * 2
# Initialize parameters
theta = 0.0
bias = 0.0
eta = 0.001
n = len(X)
losses = []
for _ in range(500):
y_pred = theta * X + bias
loss = np.mean((y_pred - y) ** 2)
losses.append(loss)
# Partial derivatives
d_theta = (2/n) * np.sum((y_pred - y) * X)
d_bias = (2/n) * np.sum(y_pred - y)
theta -= eta * d_theta
bias -= eta * d_bias
Gradientnedstigning som anpassar en linje till data, och förlustkurvan över iterationer
Varje iteration flyttar parametrarna i den riktning som minskar förlusten. De partiella derivatorna talar om vilken riktning det är. Utan dem fungerar inte gradientnedstigning – och inte heller backpropagation i neurala nätverk, som bara är kedjeregeln applicerad upprepade gånger genom lagren.
Tidsserieanalys
Många tidsseriesystem är dynamiska – det aktuella värdet beror på tidigare värden och hur snabbt saker förändras. Differentialekvationer låter dig beskriva det.
Kalmanfiltret, som används brett för spårning och prognostisering, bygger på ett system av differentialekvationer som modellerar hur ett dolt tillstånd utvecklas över tid och hur brusiga observationer relaterar till det tillståndet. Det används i GPS-system, finans och väderprognoser.
ARIMA-modeller används för tidsserieprognoser och kopplar till differentialekvationer genom begreppet differensbildning. Att ta första eller andra differenser av en tidsserie är en diskret approximation av första och andra derivator. När du differensierar en serie för att göra den stationär frågar du: hur förändras den här serien över tid?
Statistisk modellering och regression
Här är en som ofta överraskar: att lösa ett system av differentialekvationer är ett sätt att härleda koefficienter i linjär regression.
När du anpassar en linjär regressionsmodell minimerar du summan av kvadrerade residualer. Ta den partiella derivatan av den förlusten med avseende på varje koefficient, sätt dem till noll och lös. Det ger dig Normalekvationen:
Normalekvationen
Varje regressionskoefficient du någonsin har beräknat kom från att sätta en derivata till noll och lösa. Det är analys – och det är samma princip bakom varje parametrisk modell du anpassar.
För logistisk regression är förlustfunktionen inte kvadratisk, så det finns ingen slutet-form-lösning. Du måste använda iterativa metoder som gradientnedstigning, som återigen bygger på partiella derivator i varje steg.
Kopplingen går längre. QR-faktorisering, en av de standardiserade numeriska metoderna för att lösa Normalekvationen, vilar på linjär algebra som direkt tangerar hur ekvationssystem – inklusive differentiala – löses i praktiken.
Simulering av dynamiska system
När du behöver modellera hur ett system utvecklas över tid – och en analytisk lösning inte finns – simulerar du det numeriskt.
Detta är vanligt i affärs- och verksamhetssammanhang. Kundbortfall, lagernivåer och försörjningskedjedynamik involverar alla storheter som förändras baserat på det aktuella tillståndet. Du kan skriva dessa samband som differentialekvationer och simulera dem med solve_ivp.
Här är ett exempel som simulerar ett enkelt utbuds–efterfrågesystem där lager I minskar i takt med efterfrågan D, och efterfrågan skiftar över tid:
import numpy as np
from scipy.integrate import solve_ivp
import matplotlib.pyplot as plt
def supply_chain(t, y):
I, D = y
dD_dt = 0.1 * np.sin(0.5 * t) # demand fluctuates over time
dI_dt = -D # inventory depletes at the demand rate
return [dI_dt, dD_dt]
sol = solve_ivp(
supply_chain,
t_span=[0, 20],
y0=[100, 5], # initial inventory=100, demand=5
max_step=0.1
)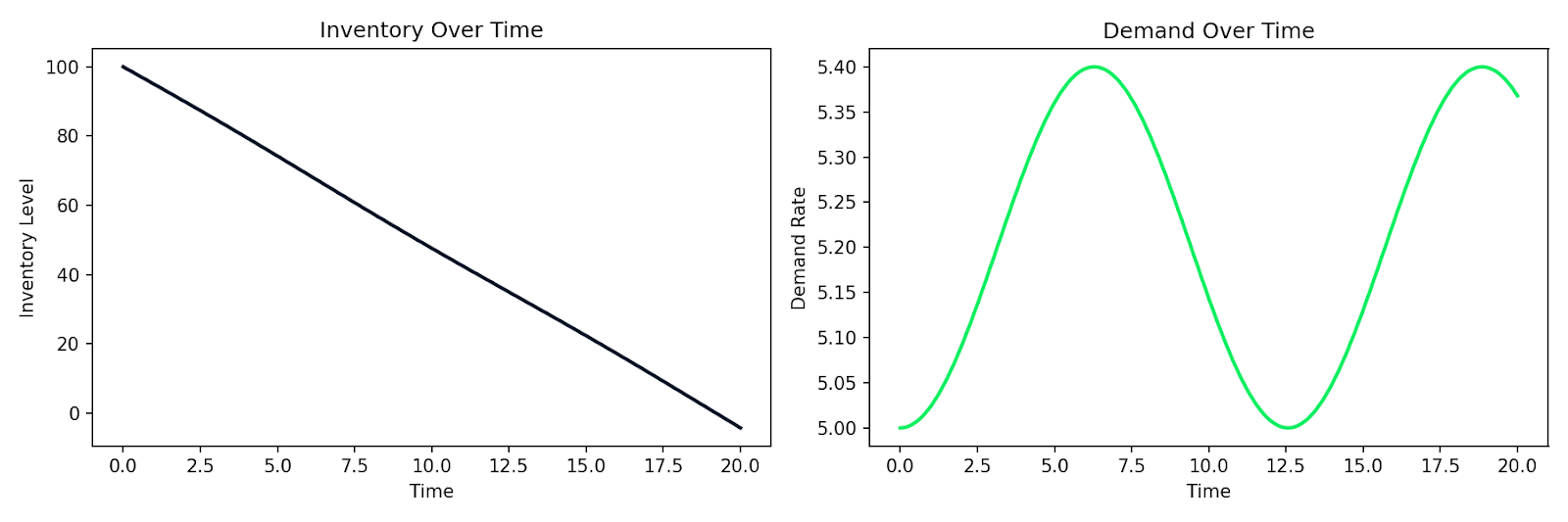
Simulerad lagerförbrukning tillsammans med fluktuerande efterfrågan över tid
Samma mönster gäller för modellering av kundbeteende, smittspridning i en användarbas eller vilket system som helst där förändringstakten beror på det aktuella tillståndet. Du skriver ner sambanden, ger dem till en numerisk lösare och får en simulering tillbaka.
Och det är den praktiska styrkan i differentialekvationer inom data science. Det är ett direkt verktyg för att modellera system som förändras.
Slutsats
Bakom gradientnedstigning finns partiella derivator. Bakom tidsserieprognoser finns dynamiska system. Bakom koefficienterna i linjär regression finns derivator satta till noll. Du behöver bara veta var du ska titta.
I den här artikeln förklarade jag vad differentialekvationer är, skillnaden mellan ODE och PDE, hur ordning och grad klassificerar dem och de viktigaste metoderna för att lösa dem – både analytiska och numeriska. Sedan tittade vi på var de faktiskt dyker upp i data science och maskininlärning i vardagen.
Det här är bara grunden. Om du vill utforska fler matematikämnen är kursen Linjär algebra för data science i R ett bra nästa steg. För praktisk träning i att tillämpa dessa koncept på riktiga dataproblem, kolla in vår kurs Kvantitativ analytiker i R.