
Kurs
Data Engineering'e Giriş
4 sa
128.3K
Veri ön işleme; veri kalitesi, yapı ve alaka düzeyiyle ilgili belirli zorlukları ele alan birkaç adımdan oluşur.
Genellikle şu sırada ilerleyen bu temel adımlara bakalım:
Veri temizleme, verideki hataları veya tutarsızlıkları tespit edip düzeltme sürecidir; amaç verinin doğru ve eksiksiz olmasını sağlamaktır. Hedef, analizi veya model performansını çarpıtabilecek sorunları gidermektir.
Örneğin:
Python'da nasıl göründüğüne bir örnek:
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Yukarıdaki kodun çıktısı
Veri bütünleştirme, birleştirilmiş bir veri kümesi oluşturmak için verileri birden fazla kaynaktan bir araya getirmeyi içerir. Bu, veriler farklı kaynak sistemlerden toplandığında sıklıkla gereklidir.
Veri bütünleştirmede kullanılan bazı teknikler şunlardır:
Örneğin birden fazla veritabanından müşteri verimiz olduğunu varsayalım. Bunu tek bir görünümde şöyle birleştiririz:
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Yukarıdaki kodun çıktısı
Veri dönüştürme, veriyi analiz, makine öğrenimi veya madencilik için uygun biçimlere çevirir.
Örneğin:
scikit-learn kullanarak Python'da nasıl göründüğü:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)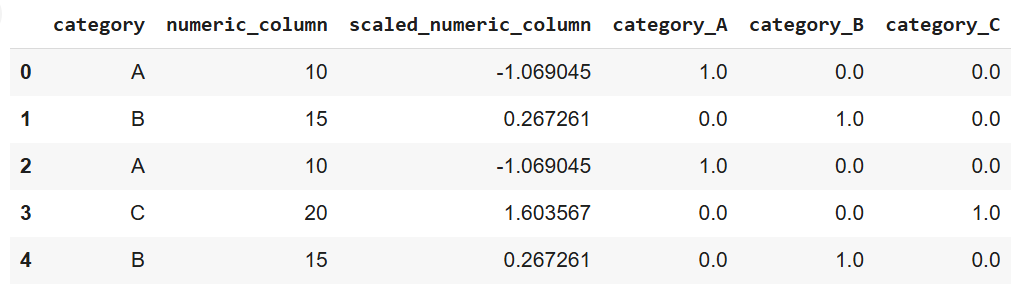
Yukarıdaki kodun çıktısı
Veri indirgeme, temel bilgiyi korurken özellik veya kayıt sayısını azaltarak veri kümesini sadeleştirir. Bu, doğruluktan ödün vermeden analizi ve model eğitimini hızlandırır.
Veri indirgeme teknikleri şunları içerir:
Python'da boyut indirgemeyi böyle uygularız:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)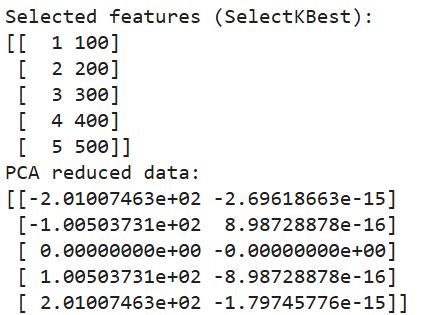
Yukarıdaki kodun çıktısı
Ham veriyi ön işlemek, analiz veya makine öğrenimi modellerine uygun hale getirmek için gereklidir. Süreçteki adımları da ele aldık.
Bu bölümde, ön işleme aşamasında karşılaşılan yaygın sorunları ele almak için çeşitli teknikleri inceleyeceğiz. Ayrıca, görsel veya metin veri kümeleri gibi belirli bağlamlarda sentetik veri oluşturmada yararlı bir yöntem olan veri artırmayı da keşfedeceğiz.
Eksik veriler, bir makine öğrenimi modelinin veya analizin performansını olumsuz etkileyebilir. Eksik değerlerle etkili biçimde başa çıkmak için çeşitli stratejiler vardır:
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesAykırı değerler, verinin geri kalanından önemli ölçüde sapan uç değerlerdir ve tıpkı eksik değerler gibi analizi ve model performansını çarpıtabilir. Aykırı değerleri tespit edip ele almak için çeşitli teknikler kullanılabilir:
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Kategorik verilerle çalışırken, kategorileri makine öğrenimi algoritmalarının işleyebileceği sayısal temsillere dönüştürmek için kodlama gereklidir. Yaygın kodlama teknikleri şunlardır:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])Ölçekleme ve normalleştirme, sayısal özelliklerin benzer bir ölçekte olmasını sağlar; bu, özellikle uzaklık ölçütlerine dayanan algoritmalar (ör. en yakın komşular, SVM) için önemlidir.
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])Veri artırma, yeni sentetik örnekler oluşturarak bir veri kümesinin boyutunu yapay olarak artırma tekniğidir. Bu, özellikle derin öğrenim modellerinde büyük miktarda verinin gerektiği görsel veya metin veri kümeleri için faydalıdır.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Veri işlemesini saf Python koduyla uygulayabilseniz de, çeşitli görevleri ele almak ve genel süreci daha verimli kılmak için güçlü araçlar geliştirilmiştir. İşte birkaç örnek:
Python'da veri ön işlemesi için epeyce uzmanlaşmış kütüphane vardır. En popüler 3 tanesi:
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)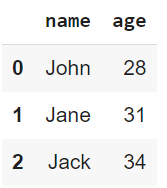
Yukarıdaki kodun çıktısı
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Yukarıdaki kodun çıktısı
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Yukarıdaki kodun çıktısı
Şirket içi sistemler büyük veri kümelerini etkili biçimde işleyemeyebilir. Böyle durumlarda, bulut platformları dağıtık sistemler genelinde çok büyük miktarda veriyi işlemenizi sağlayan ölçeklenebilir ve verimli çözümler sunar.
Dikkate alabileceğiniz bazı bulut platformu araçları şunlardır:
Veri ön işlemenin tekrarlayan adımlarını otomatikleştirmek zaman kazandırır ve hataları azaltır – özellikle makine öğrenimi modelleri ve büyük veri kümeleriyle çalışırken. Yerleşik ön işleme hatları (pipeline) sunan bazı araçlar şunlardır:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)Ön işleme çalışmalarınızın etkinliğini en üst düzeye çıkarmak için en iyi uygulamaları izlemek önemlidir. Bu bağlamda, dikkate almanızı önereceğim bazı uygulamalar şunlardır:
Ön işlemeye başlamadan önce veri kümesini etraflıca anlamak önemlidir. Elde bulunan verinin yapısını belirlemek için keşifçi veri analizi yapın. Özellikle anlamak istediğiniz noktalar şunlardır:
Veri kümesinin özelliklerini önce anlamadan yanlış ön işleme yöntemleri uygulamanız ve veriyi çarpıtmanız kuvvetle muhtemeldir.
Ön işleme sıklıkla tekrarlayan görevleri içerir. Hatlar (pipeline) oluşturarak bu görevleri otomatikleştirmek, tutarlılık ve verimlilik sağlar ve manuel hataların olasılığını azaltır. İş akışlarını sadeleştirmek için scikit-learn gibi araçlardaki ya da bulut tabanlı platformlardaki hatalardan yararlanın.
Açık belgelendirme iki hedefe hizmet eder:
Her karar, dönüştürme veya filtreleme adımı, gerekçesiyle birlikte kaydedilmelidir. Bu, ekip üyeleri arasında iş birliğini önemli ölçüde güçlendirir ve projelere bıraktığınız yerden devam etmenize yardımcı olur.
Veri ön işleme tek seferlik bir görev değildir – yinelemeli bir süreç olmalıdır. Modeller geliştikçe ve performanslarına dair geri bildirim sağladıkça, daha iyi sonuçlar elde etmek için bu bilgiyi kullanarak ön işleme adımlarını gözden geçirip iyileştirin. Örneğin, özellik mühendisliği yeni faydalı özellikler ortaya çıkarabilir veya aykırı değer işleme ayarları model doğruluğunu artırabilir – bu geri bildirimi ön işleme adımlarınızı güncellemek için kullanın.
Veri ön işleme, herhangi bir veri projesinin başarısında kritik bir rol oynar. Doğru ön işleme, ham verinin temiz ve yapılandırılmış bir formata dönüştürülmesini sağlar; bu da model ve analizlerin daha doğru, anlamlı içgörüler üretmesine yardımcı olur.
Bu yazıda, veri ön işlemesini uygulamanıza yardımcı olacak çeşitli teknikleri paylaştım. Yine de en önemli nokta, bu sürecin tek seferlik değil yinelemeli bir süreç olduğudur! Sürekli iyileştirme, model performansını artırır ve daha iyi kararlar almanızı sağlar. İyi hazırlanmış bir veri kümesi, başarılı her veri ve yapay zeka girişiminin temelini atar.
Öğrenmeye devam etmek için aşağıdaki mükemmel kaynaklara göz atmanızı öneririm:
Bu kurslarla veri mühendisliğini daha yakından keşfedin!
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
