
Courses
Introduction to Data Engineering
4 giờ
128.3K
Tiền xử lý dữ liệu gồm nhiều bước, mỗi bước giải quyết những thách thức cụ thể liên quan đến chất lượng, cấu trúc và mức độ liên quan của dữ liệu.
Hãy xem các bước chính này, thông thường diễn ra theo thứ tự sau:
Làm sạch dữ liệu là quá trình xác định và sửa lỗi hoặc sự không nhất quán trong dữ liệu để đảm bảo tính chính xác và đầy đủ. Mục tiêu là xử lý các vấn đề có thể làm sai lệch phân tích hoặc hiệu năng mô hình.
Ví dụ:
Ví dụ Python như sau:
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Kết quả của đoạn mã trên
Tích hợp dữ liệu là kết hợp dữ liệu từ nhiều nguồn để tạo thành một tập dữ liệu hợp nhất. Điều này thường cần thiết khi dữ liệu được thu thập từ các hệ thống nguồn khác nhau.
Một số kỹ thuật dùng trong tích hợp dữ liệu gồm:
Ví dụ, giả sử chúng ta có dữ liệu khách hàng từ nhiều cơ sở dữ liệu. Cách gộp lại thành một cái nhìn thống nhất như sau:
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Kết quả của đoạn mã trên
Biến đổi dữ liệu chuyển dữ liệu sang các định dạng phù hợp cho phân tích, machine learning hoặc khai phá dữ liệu.
Ví dụ:
Ví dụ bằng Python với scikit-learn:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)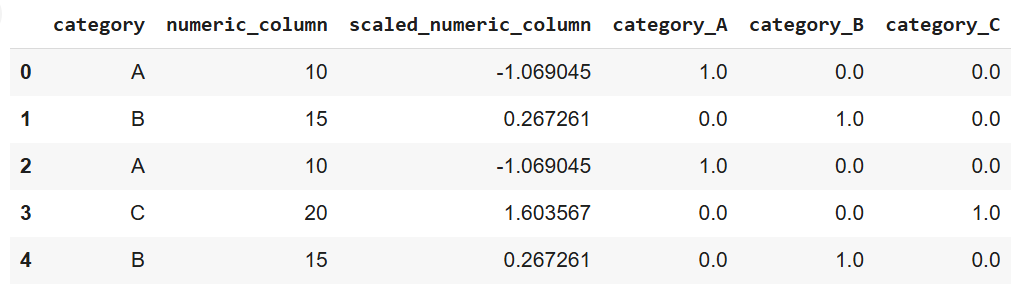
Kết quả của đoạn mã trên
Giảm dữ liệu đơn giản hóa tập dữ liệu bằng cách giảm số lượng đặc trưng hoặc bản ghi trong khi vẫn giữ thông tin cốt lõi. Điều này giúp tăng tốc phân tích và huấn luyện mô hình mà không làm giảm độ chính xác.
Các kỹ thuật giảm dữ liệu gồm:
Và đây là cách triển khai giảm chiều trong Python:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)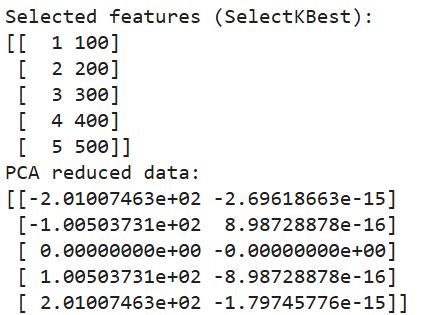
Kết quả của đoạn mã trên
Chúng ta đã xác định rằng tiền xử lý dữ liệu thô là thiết yếu để phù hợp cho phân tích hoặc mô hình machine learning. Ta cũng đã điểm qua các bước trong quy trình.
Trong phần này, chúng ta sẽ khám phá các kỹ thuật để xử lý những vấn đề thường gặp trong giai đoạn tiền xử lý. Bên cạnh đó, chúng ta sẽ tìm hiểu data augmentation, một kỹ thuật hữu ích để tạo dữ liệu tổng hợp trong các ngữ cảnh cụ thể như tập dữ liệu ảnh hoặc văn bản.
Dữ liệu thiếu có thể ảnh hưởng tiêu cực đến hiệu năng mô hình machine learning hoặc phân tích. Có một số chiến lược để xử lý hiệu quả giá trị khuyết:
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesNgoại lệ là các giá trị cực đoan lệch đáng kể so với phần còn lại của dữ liệu, tương tự như dữ liệu thiếu, có thể làm sai lệch phân tích và hiệu năng mô hình. Có nhiều kỹ thuật để phát hiện và xử lý ngoại lệ:
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Khi làm việc với dữ liệu phân loại, cần mã hóa để chuyển các hạng mục thành biểu diễn số mà các thuật toán machine learning có thể xử lý. Các kỹ thuật mã hóa phổ biến gồm:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])Chuẩn tỉ lệ và chuẩn hóa đảm bảo các đặc trưng số nằm trên thang đo tương tự, đặc biệt quan trọng với các thuật toán dựa trên khoảng cách (ví dụ, k-nearest neighbors, SVM).
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])Data augmentation là kỹ thuật tăng kích thước tập dữ liệu một cách nhân tạo bằng cách tạo các ví dụ tổng hợp mới. Điều này đặc biệt hữu ích với tập dữ liệu ảnh hoặc văn bản trong các mô hình học sâu, nơi cần lượng dữ liệu lớn cho hiệu năng vững vàng.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Dù bạn có thể triển khai xử lý dữ liệu bằng mã Python thuần, nhiều công cụ mạnh đã được phát triển để xử lý đa dạng tác vụ và làm cho toàn bộ quy trình hiệu quả hơn. Dưới đây là một vài ví dụ:
Có khá nhiều thư viện chuyên dụng cho tiền xử lý dữ liệu trong Python. Dưới đây là 3 thư viện phổ biến nhất:
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)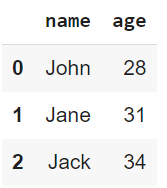
Kết quả của đoạn mã trên
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Kết quả của đoạn mã trên
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Kết quả của đoạn mã trên
Các hệ thống on-premise có thể không xử lý hiệu quả tập dữ liệu lớn. Trong những trường hợp như vậy, nền tảng đám mây cung cấp giải pháp linh hoạt, hiệu quả cho phép bạn xử lý lượng dữ liệu khổng lồ trên các hệ thống phân tán.
Một số công cụ trên nền tảng đám mây nên cân nhắc gồm:
Tự động hóa các bước lặp lại trong tiền xử lý dữ liệu có thể tiết kiệm thời gian và giảm lỗi – đặc biệt khi làm việc với mô hình machine learning và tập dữ liệu lớn. Dưới đây là một số công cụ cung cấp pipeline tiền xử lý dựng sẵn:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)Điều quan trọng là tuân thủ các thực hành tốt nhất để tối đa hóa hiệu quả của nỗ lực tiền xử lý. Dưới đây là một số khuyến nghị tôi muốn bạn cân nhắc:
Trước khi bắt đầu tiền xử lý, cần hiểu rõ tập dữ liệu. Thực hiện phân tích khám phá dữ liệu để xác định cấu trúc dữ liệu. Cụ thể, bạn cần nắm:
Nếu không hiểu đặc điểm của tập dữ liệu trước, bạn rất có thể áp dụng sai phương pháp tiền xử lý, làm sai lệch dữ liệu.
Tiền xử lý thường gồm các tác vụ lặp lại. Tự động hóa bằng cách xây dựng pipeline giúp đảm bảo tính nhất quán và hiệu quả, đồng thời giảm khả năng lỗi thủ công. Để tối ưu quy trình, hãy tận dụng pipeline trong các công cụ như scikit-learn hoặc nền tảng đám mây.
Ghi chép rõ ràng giúp đạt hai mục tiêu:
Mọi quyết định, phép biến đổi hay bước lọc đều nên được ghi lại cùng với lý do. Điều này sẽ tăng cường hợp tác trong nhóm và giúp bạn tiếp tục dự án thuận lợi khi quay lại sau.
Tiền xử lý dữ liệu không phải nhiệm vụ làm một lần – đó là quá trình lặp. Khi mô hình phát triển và phản hồi về hiệu năng, hãy dùng thông tin này để xem xét và tinh chỉnh các bước tiền xử lý, vì điều đó có thể mang lại kết quả tốt hơn. Ví dụ, kỹ thuật đặc trưng có thể hé lộ các đặc trưng hữu ích mới, hoặc tinh chỉnh cách xử lý ngoại lệ có thể cải thiện độ chính xác – hãy tận dụng phản hồi này để cập nhật quy trình tiền xử lý.
Tiền xử lý dữ liệu đóng vai trò then chốt trong thành công của mọi dự án dữ liệu. Tiền xử lý đúng cách đảm bảo dữ liệu thô được chuyển thành định dạng sạch, có cấu trúc, giúp mô hình và phân tích đưa ra insight chính xác, có ý nghĩa hơn.
Trong bài viết này, tôi đã chia sẻ nhiều kỹ thuật để triển khai tiền xử lý dữ liệu. Tuy nhiên, điều quan trọng nhất cần lưu ý là quá trình này không phải thực hiện một lần, mà là quá trình lặp! Việc tinh chỉnh liên tục dẫn đến hiệu năng mô hình được cải thiện và ra quyết định tốt hơn. Một tập dữ liệu được chuẩn bị tốt là nền tảng cho mọi sáng kiến dữ liệu và AI thành công.
Để tiếp tục học, tôi khuyến nghị bạn tham khảo các tài nguyên xuất sắc sau:
Tìm hiểu thêm về kỹ thuật dữ liệu với các khóa học này!
Courses
Courses
Courses