
Kurs
Einführung in das Data Engineering
4 Std.
127.6K
Die Datenvorverarbeitung umfasst mehrere Schritte, die jeweils spezifische Herausforderungen in Bezug auf Datenqualität, -struktur und -relevanz angehen.
Werfen wir einen Blick auf diese wichtigen Schritte, die in der Regel in der folgenden Reihenfolge ablaufen:
Bei der Datenbereinigung geht es darum, Fehler oder Unstimmigkeiten in den Daten zu identifizieren und zu korrigieren, um sicherzustellen, dass sie korrekt und vollständig sind. Das Ziel ist es, Probleme zu lösen, die die Analyse oder die Modellleistung verzerren können.
Zum Beispiel:
So sieht es in Python aus:
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Ausgabe des obigen Codes
Bei der Datenintegration werden Daten aus verschiedenen Quellen kombiniert, um einen einheitlichen Datensatz zu erstellen. Das ist oft notwendig, wenn Daten aus verschiedenen Quellsystemen gesammelt werden.
Einige Techniken, die bei der Datenintegration eingesetzt werden, sind:
Nehmen wir zum Beispiel an, wir haben Kundendaten aus mehreren Datenbanken. So würden wir sie in einer einzigen Ansicht zusammenführen:
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Ausgabe des obigen Codes
Bei der Datenumwandlung werden Daten in Formate umgewandelt, die für Analysen, maschinelles Lernen oder Mining geeignet sind.
Zum Beispiel:
So sieht es in Python aus, wenn du Scikit-Learn verwendest:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)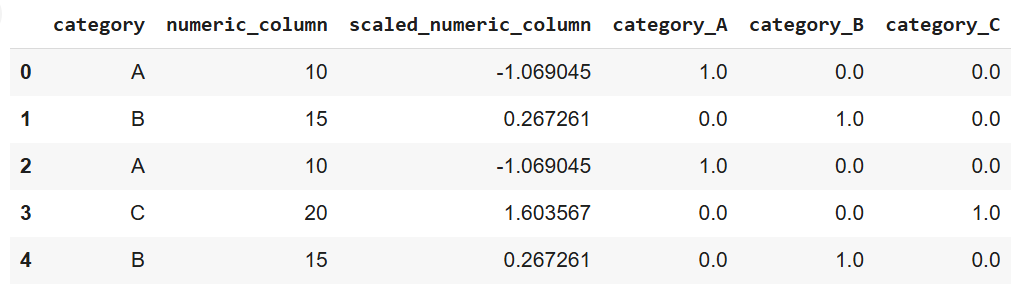
Ausgabe des obigen Codes
Bei der Datenreduzierung wird der Datensatz vereinfacht, indem die Anzahl der Merkmale oder Datensätze reduziert wird, während die wesentlichen Informationen erhalten bleiben. Das hilft, die Analyse und das Modelltraining zu beschleunigen, ohne die Genauigkeit zu beeinträchtigen.
Zu den Techniken zur Datenreduzierung gehören:
Und hier ist, wie wir die Dimensionalitätsreduktion in Python umsetzen:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)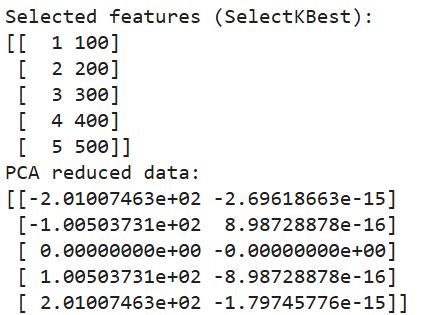
Ausgabe des obigen Codes
Wir haben festgestellt, dass die Vorverarbeitung von Rohdaten wichtig ist, um sicherzustellen, dass sie für die Analyse oder für maschinelle Lernmodelle gut geeignet sind. Wir haben auch die einzelnen Schritte des Prozesses beschrieben.
In diesem Abschnitt werden wir uns mit verschiedenen Techniken befassen, um häufige Probleme in der Vorverarbeitungsphase zu lösen. Außerdem werden wir uns mit der Datenerweiterung befassen, einer nützlichen Technik zur Erstellung synthetischer Daten in bestimmten Kontexten wie Bild- oder Textdatensätzen.
Fehlende Daten können sich negativ auf die Leistung eines maschinellen Lernmodells oder einer Analyse auswirken. Es gibt verschiedene Strategien, um fehlende Werte effektiv zu behandeln:
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesAusreißer sind Extremwerte, die erheblich vom Rest der Daten abweichen und die, ebenso wie fehlende Werte, die Analyse und die Modellleistung verzerren können. Um Ausreißer zu erkennen und zu behandeln, können verschiedene Techniken eingesetzt werden:
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Bei der Arbeit mit kategorialen Daten ist eine Kodierung notwendig, um die Kategorien in numerische Darstellungen umzuwandeln, die maschinelle Lernalgorithmen verarbeiten können. Zu den gängigen Kodierungstechniken gehören:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])Skalierung und Normalisierung stellen sicher, dass die numerischen Merkmale auf einer ähnlichen Skala liegen. Das ist besonders wichtig für Algorithmen, die auf Abstandsmetriken beruhen (z. B. k-nearest neighbors, SVMs).
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])Die Datenerweiterung ist eine Technik zur künstlichen Vergrößerung eines Datensatzes durch die Erstellung neuer, synthetischer Beispiele. Dies ist besonders nützlich für Bild- oder Textdatensätze in Deep Learning-Modellen, wo große Datenmengen für eine robuste Modellleistung erforderlich sind.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Du kannst die Datenverarbeitung zwar mit reinem Python-Code implementieren, aber es wurden auch leistungsstarke Tools entwickelt, um verschiedene Aufgaben zu erledigen und den gesamten Prozess effizienter zu gestalten. Hier sind ein paar Beispiele:
Es gibt eine ganze Reihe spezialisierter Bibliotheken für die Datenvorverarbeitung in Python. Hier sind 3 der beliebtesten:
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)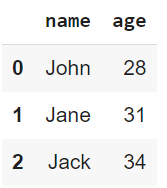
Ausgabe des obigen Codes
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Ausgabe des obigen Codes
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Ausgabe des obigen Codes
Vor Ort installierte Systeme können große Datenmengen möglicherweise nicht effektiv verarbeiten. In solchen Situationen bieten Cloud-Plattformen skalierbare, effiziente Lösungen, mit denen du große Datenmengen über verteilte Systeme hinweg verarbeiten kannst.
Einige Cloud-Plattform-Tools, die du in Betracht ziehen solltest, sind:
Die Automatisierung der sich wiederholenden Schritte der Datenvorverarbeitung kann Zeit sparen und Fehler reduzieren - vor allem, wenn du mit Machine-Learning-Modellen und großen Datensätzen arbeitest. Hier sind einige Tools, die integrierte Preprocessing-Pipelines anbieten:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)Es ist wichtig, dass du die besten Praktiken befolgst, um die Effektivität deiner Vorverarbeitung zu maximieren. Im Folgenden findest du einige Praktiken, die ich dir ans Herz legen möchte:
Bevor du mit der Vorverarbeitung beginnst, ist es wichtig, dass du den Datensatz genau verstehst. Führe eine explorative Datenanalyse durch, um die Struktur der vorliegenden Daten zu ermitteln. Was du genau verstehen willst, sind:
Wenn du die Eigenschaften des Datensatzes nicht kennst, ist es sehr wahrscheinlich, dass du falsche Vorverarbeitungsmethoden anwendest und die Daten dadurch verzerrt werden.
Die Vorverarbeitung umfasst oft sich wiederholende Aufgaben. Die Automatisierung dieser Aufgaben durch den Aufbau von Pipelines sorgt für Konsistenz und Effizienz und verringert die Wahrscheinlichkeit von manuellen Fehlern. Um Arbeitsabläufe zu rationalisieren, kannst du Pipelines in Tools wie Scikit-Learn oder cloudbasierte Plattformen nutzen.
Eine klare Dokumentation hilft, zwei Ziele zu erreichen:
Jede Entscheidung, Umwandlung oder Filterung sollte aufgezeichnet werden, einschließlich der Gründe dafür. Dadurch wird die Zusammenarbeit zwischen den Teammitgliedern deutlich verbessert und du kannst Projekte dort fortsetzen, wo du aufgehört hast.
Die Datenvorverarbeitung ist keine einmalige Aufgabe - sie sollte ein iterativer Prozess sein. Wenn sich die Modelle weiterentwickeln und Rückmeldungen zu ihrer Leistung liefern, kannst du diese Informationen nutzen, um die Vorverarbeitungsschritte zu überarbeiten und zu verfeinern, da dies zu besseren Ergebnissen führen kann. So kann zum Beispiel das Feature-Engineering neue nützliche Merkmale zutage fördern oder die Behandlung von Ausreißern die Modellgenauigkeit verbessern - nutze dieses Feedback, um deine Vorverarbeitungsschritte zu aktualisieren.
Die Datenvorverarbeitung spielt eine entscheidende Rolle für den Erfolg eines jeden Datenprojekts. Die richtige Vorverarbeitung sorgt dafür, dass die Rohdaten in ein sauberes, strukturiertes Format umgewandelt werden, damit die Modelle und Analysen genauere und aussagekräftigere Erkenntnisse liefern.
In diesem Artikel habe ich verschiedene Techniken vorgestellt, die bei der Datenvorverarbeitung helfen. Das Wichtigste ist jedoch, dass dieser Prozess keine einmalige Anstrengung ist, sondern ein iterativer Prozess! Die kontinuierliche Verfeinerung führt zu einer verbesserten Modellleistung und einer besseren Entscheidungsfindung. Ein gut aufbereiteter Datensatz ist die Grundlage für jede erfolgreiche Daten-KI-Initiative.
Um dich weiterzubilden, empfehle ich dir, die folgenden ausgezeichneten Ressourcen zu lesen:
Lerne mehr über Data Engineering mit diesen Kursen!
Kurs
Kurs
Kurs
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Allan Ouko
Tutorial
Moez Ali
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
