
Cours
Introduction au data engineering
4 h
127.6K
Le prétraitement des données comporte plusieurs étapes, chacune répondant à des défis spécifiques liés à la qualité, à la structure et à la pertinence des données.
Examinons ces étapes clés, qui se déroulent généralement dans l'ordre suivant :
Le nettoyage des données consiste à identifier et à corriger les erreurs ou les incohérences dans les données afin de s'assurer qu'elles sont exactes et complètes. L'objectif est de résoudre les problèmes qui peuvent fausser l'analyse ou les performances du modèle.
Par exemple :
Voici ce que cela donne en Python :
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Sortie du code ci-dessus
L'intégration des données consiste à combiner des données provenant de sources multiples pour créer un ensemble de données unifié. Cela est souvent nécessaire lorsque les données sont collectées à partir de différents systèmes sources.
Parmi les techniques utilisées pour l'intégration des données, on peut citer
Par exemple, supposons que nous ayons des données sur les clients provenant de plusieurs bases de données. Voici comment nous pourrions les fusionner en une seule vue :
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Sortie du code ci-dessus
La transformation des données permet de convertir les données dans des formats adaptés à l'analyse, à l'apprentissage automatique ou à l'exploitation minière.
Par exemple :
Voici ce que cela donne en Python, en utilisant scikit-learn :
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)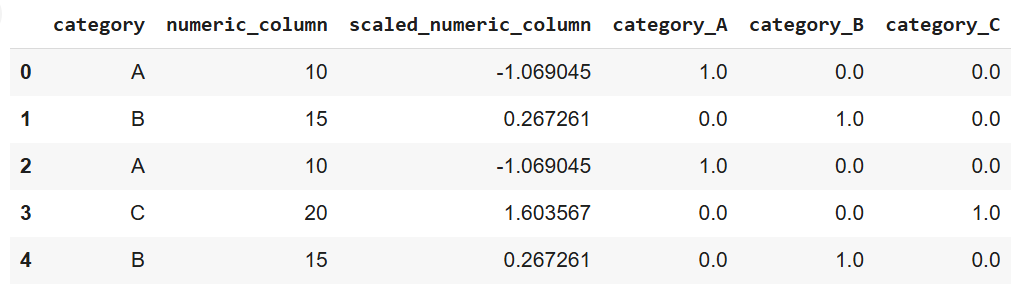
Sortie du code ci-dessus
La réduction des données permet de simplifier l'ensemble des données en réduisant le nombre de caractéristiques ou d'enregistrements tout en préservant les informations essentielles. Cela permet d'accélérer l'analyse et la formation des modèles sans sacrifier la précision.
Les techniques de réduction des données comprennent
Et voici comment nous mettons en œuvre la réduction de la dimensionnalité en Python :
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)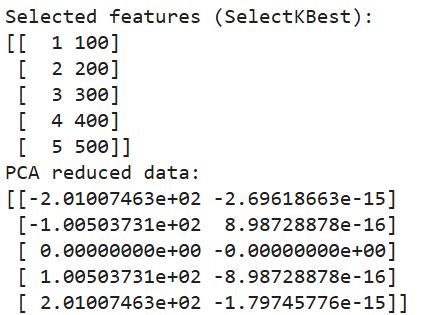
Sortie du code ci-dessus
Nous avons établi que le prétraitement des données brutes est essentiel pour s'assurer qu'elles sont bien adaptées à l'analyse ou aux modèles d'apprentissage automatique. Nous avons également abordé les étapes du processus.
Dans cette section, nous allons explorer différentes techniques pour traiter les problèmes courants lors de la phase de prétraitement. En outre, nous explorerons l'augmentation des données, une technique utile pour créer des données synthétiques dans des contextes spécifiques tels que des ensembles de données d'images ou de textes.
Les données manquantes peuvent avoir un impact négatif sur les performances d'un modèle ou d'une analyse d'apprentissage automatique. Il existe plusieurs stratégies pour traiter efficacement les valeurs manquantes :
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesLes valeurs aberrantes sont des valeurs extrêmes qui s'écartent de manière significative du reste des données et qui, comme les valeurs manquantes, peuvent fausser l'analyse et les performances du modèle. Différentes techniques peuvent être utilisées pour détecter et traiter les valeurs aberrantes :
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Lorsque l'on travaille avec des données catégorielles, l'encodage est nécessaire pour convertir les catégories en représentations numériques que les algorithmes d'apprentissage automatique peuvent traiter. Les techniques d'encodage les plus courantes sont les suivantes :
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])La mise à l'échelle et la normalisation garantissent que les caractéristiques numériques sont sur une échelle similaire, ce qui est particulièrement important pour les algorithmes qui reposent sur des mesures de distance (par exemple, k-voisins les plus proches, SVM).
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])L'augmentation des données est une technique permettant d'accroître artificiellement la taille d'un ensemble de données en créant de nouveaux exemples synthétiques. Ceci est particulièrement utile pour les ensembles de données d'images ou de textes dans les modèles d'apprentissage profond, où de grandes quantités de données sont nécessaires pour une performance robuste du modèle.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Bien que vous puissiez mettre en œuvre le traitement des données à l'aide d'un code Python pur, des outils puissants ont été développés pour gérer diverses tâches et rendre le processus global plus efficace. Voici quelques exemples :
Il existe pas mal de bibliothèques spécialisées dans le prétraitement des données en Python. Voici trois des plus populaires :
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)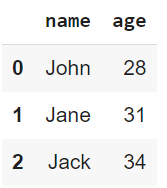
Sortie du code ci-dessus
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Sortie du code ci-dessus
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Sortie du code ci-dessus
Les systèmes sur site peuvent ne pas être en mesure de traiter efficacement des ensembles de données volumineux. Dans de telles situations, les plateformes cloud offrent des solutions évolutives et efficaces qui vous permettent de traiter de grandes quantités de données à travers des systèmes distribués.
Voici quelques outils de plateforme cloud à prendre en compte :
L'automatisation des étapes répétitives du prétraitement des données permet de gagner du temps et de réduire les erreurs, en particulier lorsqu'il s'agit de modèles d'apprentissage automatique et de grands ensembles de données. Voici quelques outils qui proposent des pipelines de prétraitement intégrés :
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)Il est essentiel de suivre les meilleures pratiques pour maximiser l'efficacité de vos efforts de prétraitement. Cela dit, voici quelques pratiques que je vous encourage à envisager :
Avant de vous lancer dans le prétraitement, il est important de bien comprendre l'ensemble de données. Effectuez une analyse exploratoire des données afin d'identifier la structure des données en question. Ce que vous voulez comprendre en particulier, c'est ce qui suit :
Si vous ne comprenez pas d'abord les caractéristiques de l'ensemble de données, il est fort probable que vous appliquiez des méthodes de prétraitement incorrectes, ce qui faussera les données.
Le prétraitement implique souvent des tâches répétitives. L'automatisation de ces tâches par la création de pipelines garantit la cohérence et l'efficacité et réduit les risques d'erreurs manuelles. Pour rationaliser les flux de travail, tirez parti des pipelines dans des outils comme scikit-learn ou des plateformes basées sur le cloud.
Une documentation claire permet d'atteindre deux objectifs :
Chaque décision, transformation ou étape de filtrage doit être enregistrée, y compris son raisonnement. Cela améliorera considérablement la collaboration entre les membres de l'équipe et vous aidera à reprendre les projets là où vous les avez laissés.
Le prétraitement des données n'est pas une tâche ponctuelle - il doit s'agir d'un processus itératif. Au fur et à mesure que les modèles évoluent et fournissent un retour d'information sur leurs performances, utilisez ces informations pour revoir et affiner les étapes de prétraitement, car elles peuvent conduire à de meilleurs résultats. Par exemple, l'ingénierie des caractéristiques peut révéler de nouvelles caractéristiques utiles, ou le traitement des valeurs aberrantes peut améliorer la précision du modèle - utilisez ce retour d'information pour mettre à jour vos étapes de prétraitement.
Le prétraitement des données joue un rôle essentiel dans la réussite de tout projet de données. Un prétraitement adéquat garantit que les données brutes sont transformées en un format propre et structuré, ce qui permet aux modèles et aux analyses de produire des informations plus précises et plus significatives.
Dans cet article, j'ai présenté plusieurs techniques permettant de mettre en œuvre le prétraitement des données. Cependant, la chose la plus importante à noter est que ce processus n'est pas un effort ponctuel mais un processus itératif ! L'affinement continu permet d'améliorer les performances du modèle et de prendre de meilleures décisions. Un ensemble de données bien préparé constitue la base de toute initiative réussie en matière d'IA des données.
Pour poursuivre votre apprentissage, je vous recommande de consulter les excellentes ressources suivantes :
Apprenez-en plus sur l'ingénierie des données avec ces cours !
Cours
Cours
Cours
Tutoriel
Moez Ali
Tutoriel
Sejal Jaiswal
Tutoriel
DataCamp Team
Tutoriel
Derrick Mwiti
Tutoriel
Mark Pedigo