
Cursus
Introductie tot Data Engineering
4 Hr
128.3K
Datapreprocessing omvat verschillende stappen, die elk specifieke uitdagingen rond datakwaliteit, -structuur en -relevantie aanpakken.
Laten we deze kerntappen bekijken, die doorgaans in de volgende volgorde verlopen:
Data opschonen is het identificeren en corrigeren van fouten of inconsistenties in de data om te zorgen dat deze accuraat en compleet is. Het doel is om problemen aan te pakken die analyse of modelprestaties kunnen vertekenen.
Bijvoorbeeld:
Zo ziet dat eruit in Python:
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Output van bovenstaande code
Dataintegratie houdt in dat data uit meerdere bronnen wordt gecombineerd tot één uniforme dataset. Dit is vaak nodig wanneer data uit verschillende bronsystemen komt.
Enkele technieken die worden gebruikt bij dataintegratie zijn:
Stel dat we klantdata uit meerdere databases hebben. Zo voegen we die samen tot één geheel:
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Output van bovenstaande code
Datatransformatie zet data om in formaten die geschikt zijn voor analyse, machine learning of mining.
Bijvoorbeeld:
Zo ziet dat eruit in Python, met scikit-learn:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)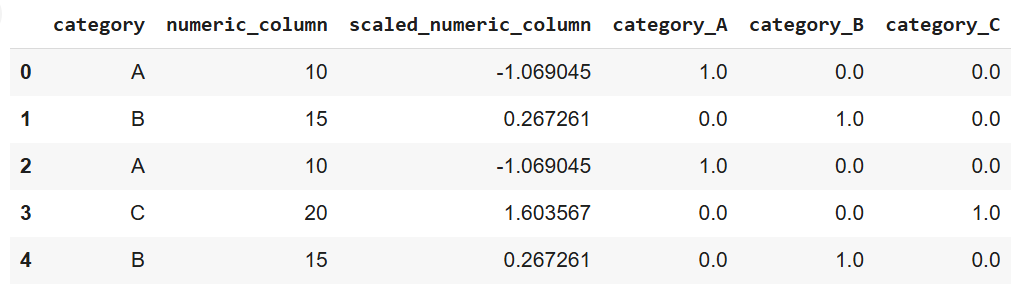
Output van bovenstaande code
Datareductie vereenvoudigt de dataset door het aantal features of records te verminderen, terwijl de essentie behouden blijft. Dit versnelt analyse en modeltraining zonder aan nauwkeurigheid in te boeten.
Technieken voor datareductie zijn onder meer:
En zo implementeren we dimensiereductie in Python:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)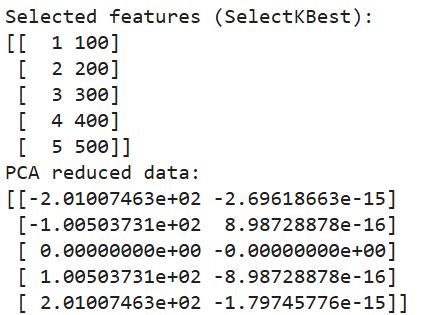
Output van bovenstaande code
We hebben vastgesteld dat het preppen van ruwe data essentieel is om deze geschikt te maken voor analyses of machinelearningmodellen. We hebben ook de stappen in het proces besproken.
In deze sectie verkennen we verschillende technieken om veelvoorkomende problemen tijdens de preprocessingfase aan te pakken. Daarnaast bekijken we data-augmentatie, een handige techniek om synthetische data te creëren in specifieke contexten, zoals beeld- of tekstdatasets.
Ontbrekende data kan de prestatie van een machinelearningmodel of analyse negatief beïnvloeden. Er zijn verschillende strategieën om ontbrekende waarden effectief te behandelen:
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesOutliers zijn extreme waarden die sterk afwijken van de rest van de data en, net als ontbrekende waarden, analyse en modelprestaties kunnen vertekenen. Er zijn verschillende technieken om outliers te detecteren en te behandelen:
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Bij werken met categorische data is encodering nodig om categorieën om te zetten in numerieke representaties die machinelearningalgoritmes kunnen verwerken. Veelgebruikte encodetechnieken zijn:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])Schalen en normaliseren zorgen ervoor dat numerieke features op een vergelijkbare schaal liggen, wat vooral belangrijk is voor algoritmes die op afstandsmaatstaven steunen (bijv. k-nearest neighbors, SVM's).
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])Data-augmentatie is een techniek om de omvang van een dataset kunstmatig te vergroten door nieuwe, synthetische voorbeelden te maken. Dit is vooral handig voor beeld- of tekstdatasets in deep learning-modellen, waar grote hoeveelheden data nodig zijn voor robuuste modelprestaties.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Hoewel je datapreprocessing met pure Python kunt implementeren, zijn er krachtige tools ontwikkeld om verschillende taken af te handelen en het hele proces efficiënter te maken. Hier zijn enkele voorbeelden:
Er zijn heel wat gespecialiseerde bibliotheken voor datapreprocessing in Python. Hier zijn 3 van de populairste:
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)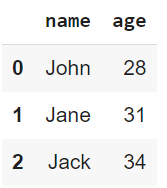
Output van bovenstaande code
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Output van bovenstaande code
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Output van bovenstaande code
On-premisesystemen kunnen mogelijk niet effectief met grote datasets omgaan. In zulke situaties bieden cloudplatforms schaalbare, efficiënte oplossingen die je in staat stellen enorme hoeveelheden data te verwerken over gedistribueerde systemen.
Enkele cloudplatformtools om te overwegen zijn:
Het automatiseren van de repetitieve stappen van preprocessing kan tijd besparen en fouten verminderen – vooral bij machinelearningmodellen en grote datasets. Hier zijn enkele tools met ingebouwde preprocessingpijplijnen:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)Het is essentieel om best practices te volgen om het effect van je preprocessing te maximaliseren. Hieronder enkele praktijken die ik je zou aanraden:
Voordat je met preprocessing begint, is het belangrijk om de dataset grondig te begrijpen. Voer exploratieve data-analyse uit om de structuur van de data in kaart te brengen. Wat je specifiek wilt begrijpen zijn:
Zonder eerst de kenmerken van de dataset te begrijpen, is de kans groot dat je onjuiste preprocessingmethoden toepast, wat de data kan vertekenen.
Preprocessing bevat vaak repetitieve taken. Door pipelines te bouwen automatiseer je deze taken, wat zorgt voor consistentie en efficiëntie en de kans op handmatige fouten verkleint. Gebruik pipelines in tools zoals scikit-learn of cloudplatforms om workflows te stroomlijnen.
Duidelijke documentatie dient twee doelen:
Elke beslissing, transformatie of filterstap moet worden vastgelegd, inclusief de onderbouwing. Dit verbetert de samenwerking binnen teams aanzienlijk en helpt je projecten weer op te pakken waar je gebleven was.
Datapreprocessing is geen eenmalige taak – het is een iteratief proces. Naarmate modellen evolueren en feedback geven over hun prestaties, gebruik je die informatie om preprocessingstappen te herzien en te verfijnen, wat kan leiden tot betere resultaten. Zo kan feature engineering nieuwe nuttige features opleveren, of het bijstellen van outlierbehandeling de modelnauwkeurigheid verbeteren – gebruik die feedback om je preprocessing bij te werken.
Datapreprocessing speelt een cruciale rol in het succes van elk dataproject. Juiste preprocessing zorgt ervoor dat ruwe data wordt omgezet in een schoon, gestructureerd formaat, waardoor modellen en analyses meer accurate, betekenisvolle inzichten opleveren.
In dit artikel heb ik verschillende technieken gedeeld om datapreprocessing te implementeren. Het belangrijkste om te onthouden is echter dat dit geen eenmalige inspanning is, maar een iteratief proces! Continue verfijning leidt tot betere modelprestaties en slimmere beslissingen. Een goed voorbereide dataset vormt de basis voor elke succesvolle data- en AI-initiatie.
Wil je verder leren? Bekijk dan deze uitstekende resources:
Leer meer over data engineering met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
