
Corso
Introduzione al Data Engineering
4 h
128.3K
Il preprocessing dei dati comprende diverse fasi, ognuna delle quali affronta sfide specifiche legate a qualità, struttura e rilevanza dei dati.
Vediamo questi passaggi chiave, che in genere seguono il seguente ordine:
La pulizia dei dati è il processo di identificazione e correzione di errori o incoerenze nei dati per garantirne accuratezza e completezza. L’obiettivo è affrontare problemi che possono alterare l’analisi o le prestazioni del modello.
Per esempio:
Ecco come appare in Python:
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Output del codice sopra
L’integrazione dei dati comporta la combinazione di dati provenienti da più fonti per creare un dataset unificato. Questo è spesso necessario quando i dati sono raccolti da diversi sistemi sorgente.
Alcune tecniche utilizzate nell’integrazione dei dati includono:
Per esempio, supponiamo di avere dati sui clienti da più database. Ecco come li uniremmo in una singola vista:
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Output del codice sopra
La trasformazione dei dati converte i dati in formati adatti all’analisi, al machine learning o al data mining.
Per esempio:
Ecco come si presenta in Python, usando scikit-learn:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)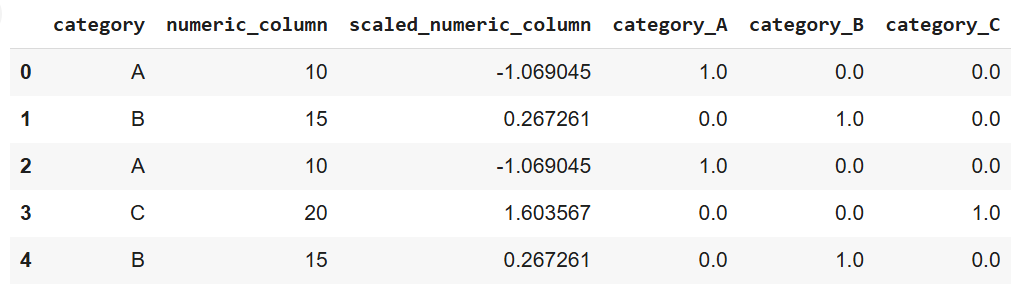
Output del codice sopra
La riduzione dei dati semplifica il dataset riducendo il numero di feature o di record, preservando al contempo le informazioni essenziali. Questo aiuta ad accelerare analisi e training dei modelli senza sacrificare l’accuratezza.
Le tecniche di riduzione dei dati includono:
Ed ecco come implementare la riduzione della dimensionalità in Python:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)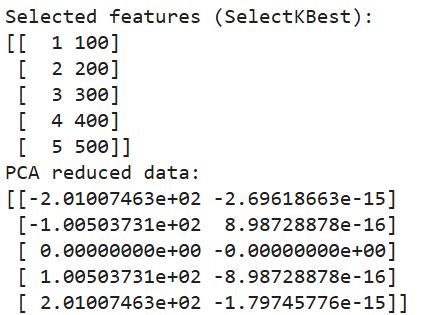
Output del codice sopra
Abbiamo stabilito che il preprocessing dei dati grezzi è essenziale per garantire che siano adatti all’analisi o ai modelli di machine learning. Abbiamo anche visto le fasi coinvolte nel processo.
In questa sezione, esploreremo varie tecniche per gestire problemi comuni durante la fase di preprocessing. Inoltre, vedremo la data augmentation, una tecnica utile per creare dati sintetici in contesti specifici come dataset di immagini o di testo.
I dati mancanti possono influire negativamente sulle prestazioni di un modello di machine learning o di un’analisi. Esistono diverse strategie per gestire in modo efficace i valori mancanti:
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesGli outlier sono valori estremi che si discostano significativamente dal resto dei dati e, come i valori mancanti, possono alterare analisi e prestazioni dei modelli. Esistono diverse tecniche per individuare e gestire gli outlier:
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Quando si lavora con dati categorici, è necessario codificarli per convertirli in rappresentazioni numeriche che gli algoritmi di machine learning possano elaborare. Tra le tecniche comuni di codifica ci sono:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])Scaling e normalizzazione assicurano che le feature numeriche siano su una scala simile, particolarmente importante per algoritmi che si basano su metriche di distanza (ad es. k-nearest neighbors, SVM).
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])La data augmentation è una tecnica per aumentare artificialmente la dimensione di un dataset creando nuovi esempi sintetici. È particolarmente utile per dataset di immagini o di testo nei modelli di deep learning, dove sono necessarie grandi quantità di dati per prestazioni robuste.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Sebbene tu possa implementare l’elaborazione dei dati con puro codice Python, sono stati sviluppati potenti strumenti per gestire varie attività e rendere l’intero processo più efficiente. Eccone alcuni esempi:
Esistono parecchie librerie specializzate per il preprocessing in Python. Ecco tre delle più popolari:
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)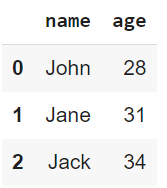
Output del codice sopra
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Output del codice sopra
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Output del codice sopra
I sistemi on-premise potrebbero non essere in grado di gestire efficacemente grandi dataset. In tali situazioni, le piattaforme cloud offrono soluzioni scalabili ed efficienti che ti permettono di elaborare enormi quantità di dati su sistemi distribuiti.
Alcuni strumenti di piattaforme cloud da considerare includono:
Automatizzare i passaggi ripetitivi del preprocessing può far risparmiare tempo e ridurre gli errori, soprattutto quando si lavora con modelli di machine learning e grandi dataset. Ecco alcuni strumenti che offrono pipeline di preprocessing integrate:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)È essenziale seguire le best practice per massimizzare l’efficacia delle attività di preprocessing. Detto ciò, ecco alcune pratiche che ti invito a considerare:
Prima di iniziare il preprocessing, è importante comprendere a fondo il dataset. Conduci un’analisi esplorativa dei dati per identificare la struttura dei dati a disposizione. In particolare, quello che vuoi capire è:
Senza comprendere prima le caratteristiche del dataset, è abbastanza probabile che tu applichi metodi di preprocessing errati, alterando i dati.
Il preprocessing spesso include attività ripetitive. Automatizzare questi compiti costruendo pipeline garantisce coerenza ed efficienza e riduce la probabilità di errori manuali. Per snellire i workflow, sfrutta le pipeline in strumenti come scikit-learn o piattaforme cloud.
Una documentazione chiara aiuta a raggiungere due obiettivi:
Ogni decisione, trasformazione o passaggio di filtro dovrebbe essere registrato, inclusa la motivazione. Questo migliorerà notevolmente la collaborazione tra i membri del team e ti aiuterà a riprendere i progetti da dove li avevi lasciati.
Il preprocessing dei dati non è un’attività una tantum: dovrebbe essere un processo iterativo. Man mano che i modelli evolvono e forniscono feedback sulle prestazioni, usa queste informazioni per rivedere e perfezionare i passaggi di preprocessing, poiché può portare a risultati migliori. Per esempio, il feature engineering può far emergere nuove feature utili, oppure una migliore taratura della gestione degli outlier può migliorare l’accuratezza del modello: usa questo feedback per aggiornare i passaggi di preprocessing.
Il preprocessing dei dati svolge un ruolo cruciale nel successo di qualsiasi progetto data-driven. Un preprocessing corretto trasforma i dati grezzi in un formato pulito e strutturato, aiutando modelli e analisi a produrre insight più accurati e significativi.
In questo articolo ho condiviso varie tecniche per aiutarti a implementare il preprocessing dei dati. Tuttavia, la cosa più importante da ricordare è che non si tratta di uno sforzo una tantum, ma di un processo iterativo! Un perfezionamento continuo porta a prestazioni migliori del modello e a decisioni più informate. Un dataset ben preparato è la base di qualsiasi iniziativa di AI di successo.
Per continuare a imparare, ti consiglio di dare un’occhiata a queste risorse eccellenti:
Approfondisci il data engineering con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

