
Kursus
Pengantar Data Engineering
4 Hr
128.3K
Prapemrosesan data mencakup beberapa langkah, masing-masing menangani tantangan spesifik terkait kualitas, struktur, dan relevansi data.
Mari kita lihat langkah-langkah kunci ini, yang umumnya berjalan dalam urutan berikut:
Pembersihan data adalah proses mengidentifikasi dan memperbaiki kesalahan atau ketidakkonsistenan dalam data untuk memastikan data akurat dan lengkap. Tujuannya adalah mengatasi masalah yang dapat mendistorsi analisis atau kinerja model.
Contohnya:
Berikut tampilannya di Python:
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Output kode di atas
Integrasi data melibatkan penggabungan data dari beberapa sumber untuk membuat satu set data terpadu. Ini sering diperlukan saat data dikumpulkan dari berbagai sistem sumber.
Beberapa teknik yang digunakan dalam integrasi data meliputi:
Misalnya, anggaplah kita memiliki data pelanggan dari beberapa basis data. Begini cara kita menggabungkannya menjadi satu tampilan:
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Output kode di atas
Transformasi data mengonversi data ke format yang sesuai untuk analisis, machine learning, atau penambangan data.
Contohnya:
Berikut tampilannya di Python, menggunakan scikit-learn:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)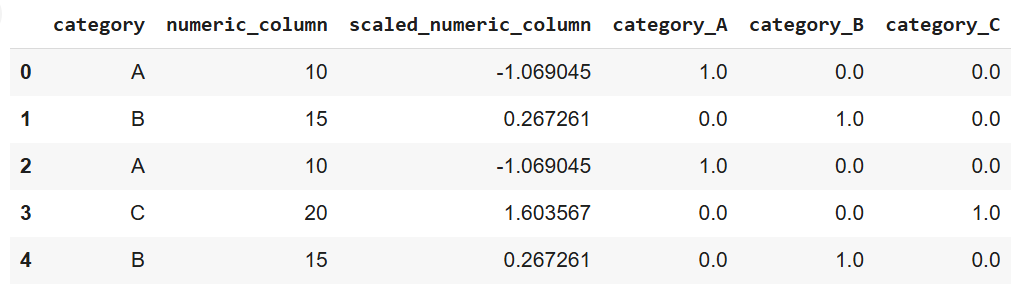
Output kode di atas
Reduksi data menyederhanakan set data dengan mengurangi jumlah fitur atau catatan sambil mempertahankan informasi esensial. Ini membantu mempercepat analisis dan pelatihan model tanpa mengorbankan akurasi.
Teknik reduksi data meliputi:
Dan berikut cara menerapkan reduksi dimensi di Python:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)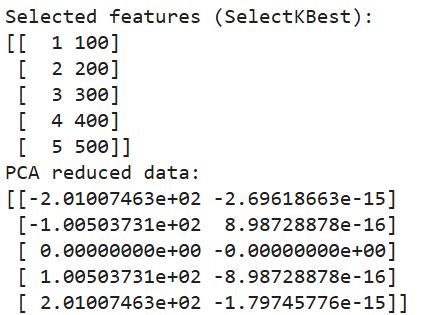
Output kode di atas
Kita telah menetapkan bahwa prapemrosesan data mentah sangat penting untuk memastikan data siap digunakan untuk analisis atau model machine learning. Kita juga telah membahas langkah-langkah yang terlibat dalam proses ini.
Pada bagian ini, kita akan mengeksplorasi berbagai teknik untuk menangani masalah umum selama fase prapemrosesan. Selain itu, kita akan membahas augmentasi data, teknik berguna untuk membuat data sintetis dalam konteks spesifik seperti set data gambar atau teks.
Data yang hilang dapat berdampak negatif pada kinerja model machine learning atau analisis. Ada beberapa strategi untuk menangani nilai yang hilang secara efektif:
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesOutlier adalah nilai ekstrem yang menyimpang secara signifikan dari sebagian besar data, yang seperti nilai hilang, dapat mendistorsi analisis dan kinerja model. Berbagai teknik dapat digunakan untuk mendeteksi dan menangani outlier:
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Saat bekerja dengan data kategorikal, pengodean diperlukan untuk mengonversi kategori ke representasi numerik yang dapat diproses oleh algoritma machine learning. Teknik pengodean yang umum meliputi:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])Skalasi dan normalisasi memastikan bahwa fitur numerik berada pada skala yang serupa, yang sangat penting untuk algoritma yang mengandalkan metrik jarak (misalnya, k-nearest neighbors, SVM).
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])Augmentasi data adalah teknik untuk secara artifisial meningkatkan ukuran set data dengan membuat contoh baru yang sintetis. Ini sangat berguna untuk set data gambar atau teks dalam model deep learning, di mana sejumlah besar data diperlukan untuk kinerja model yang andal.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Meskipun Anda dapat menerapkan pemrosesan data menggunakan kode Python murni, berbagai alat yang kuat telah dikembangkan untuk menangani beragam tugas dan membuat proses keseluruhan lebih efisien. Berikut beberapa contohnya:
Ada cukup banyak library khusus untuk prapemrosesan data di Python. Berikut 3 yang paling populer:
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)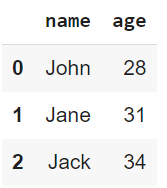
Output kode di atas
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Output kode di atas
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Output kode di atas
Sistem on-premise mungkin tidak dapat menangani set data besar secara efektif. Dalam situasi seperti ini, platform cloud menawarkan solusi yang skalabel dan efisien yang memungkinkan Anda memproses data dalam jumlah besar di sistem terdistribusi.
Beberapa alat platform cloud yang dapat dipertimbangkan meliputi:
Mengotomatiskan langkah-langkah berulang dalam prapemrosesan data dapat menghemat waktu dan mengurangi kesalahan – terutama saat menangani model machine learning dan set data besar. Berikut beberapa alat yang menawarkan pipeline prapemrosesan bawaan:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)Penting untuk mengikuti praktik terbaik guna memaksimalkan efektivitas upaya prapemrosesan Anda. Karena itu, berikut beberapa praktik yang saya sarankan untuk dipertimbangkan:
Sebelum Anda terjun ke prapemrosesan, penting untuk memahami set data secara menyeluruh. Lakukan analisis data eksploratori untuk mengidentifikasi struktur data yang ada. Yang ingin Anda pahami secara spesifik adalah:
Tanpa terlebih dahulu memahami karakteristik set data, kemungkinan besar Anda dapat menerapkan metode prapemrosesan yang salah, yang akan mendistorsi data.
Prapemrosesan sering melibatkan tugas yang berulang. Mengotomatiskan tugas-tugas ini dengan membangun pipeline memastikan konsistensi dan efisiensi serta mengurangi kemungkinan kesalahan manual. Untuk menyederhanakan alur kerja, manfaatkan pipeline di alat seperti scikit-learn atau platform berbasis cloud.
Dokumentasi yang jelas membantu mencapai dua tujuan:
Setiap keputusan, transformasi, atau langkah penyaringan harus dicatat, termasuk alasannya. Ini akan sangat meningkatkan kolaborasi di antara anggota tim dan membantu Anda melanjutkan proyek dari titik terakhir.
Prapemrosesan data bukan tugas satu kali – ini harus menjadi proses iteratif. Seiring model berkembang dan memberikan umpan balik atas kinerjanya, gunakan informasi ini untuk meninjau kembali dan menyempurnakan langkah prapemrosesan, karena hal itu dapat menghasilkan hasil yang lebih baik. Misalnya, rekayasa fitur dapat mengungkap fitur baru yang berguna, atau penyetelan penanganan outlier dapat meningkatkan akurasi model – gunakan umpan balik ini untuk memperbarui langkah prapemrosesan Anda.
Prapemrosesan data memainkan peran krusial dalam keberhasilan proyek data apa pun. Prapemrosesan yang tepat memastikan data mentah diubah menjadi format yang bersih dan terstruktur, yang membantu model dan analisis menghasilkan wawasan yang lebih akurat dan bermakna.
Dalam artikel ini, saya telah membagikan berbagai teknik untuk membantu menerapkan prapemrosesan data. Namun, hal terpenting untuk dicatat adalah bahwa proses ini bukan upaya satu kali, melainkan proses iteratif! Penyempurnaan berkelanjutan mengarah pada peningkatan kinerja model dan pengambilan keputusan yang lebih baik. Set data yang dipersiapkan dengan baik menjadi fondasi bagi setiap inisiatif AI data yang sukses.
Untuk melanjutkan pembelajaran Anda, saya merekomendasikan sumber daya unggulan berikut:
Pelajari lebih lanjut tentang data engineering dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
