
Curso
Introdução à Engenharia de Dados
4 h
127.6K
O pré-processamento de dados envolve várias etapas, cada uma abordando desafios específicos relacionados à qualidade, à estrutura e à relevância dos dados.
Vamos dar uma olhada nessas etapas principais, que geralmente seguem a seguinte ordem:
A limpeza de dados é o processo de identificação e correção de erros ou inconsistências nos dados para garantir que eles sejam precisos e completos. O objetivo é abordar problemas que podem distorcer a análise ou o desempenho do modelo.
Por exemplo:
Veja como fica em Python:
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Saída do código acima
A integração de dados envolve a combinação de dados de várias fontes para criar um conjunto de dados unificado. Isso geralmente é necessário quando os dados são coletados de diferentes sistemas de origem.
Algumas técnicas usadas na integração de dados incluem:
Por exemplo, digamos que você tenha dados de clientes de vários bancos de dados. Veja como você poderia mesclá-los em uma única exibição:
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Saída do código acima
A transformação de dados converte os dados em formatos adequados para análise, aprendizado de máquina ou mineração.
Por exemplo:
Veja como fica em Python, usando o scikit-learn:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)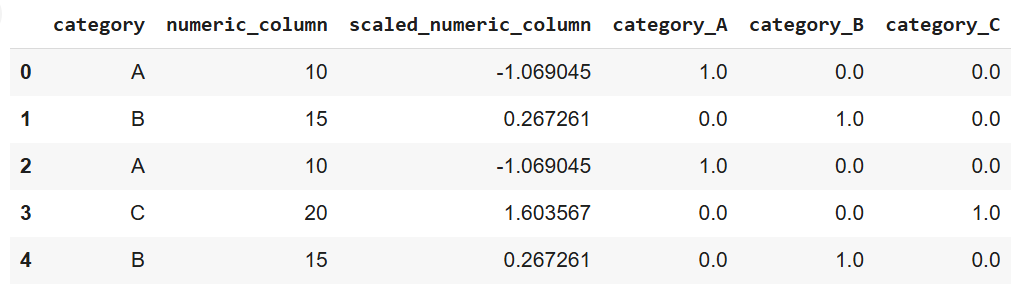
Saída do código acima
A redução de dados simplifica o conjunto de dados, reduzindo o número de recursos ou registros e preservando as informações essenciais. Isso ajuda a acelerar a análise e o treinamento de modelos sem sacrificar a precisão.
As técnicas de redução de dados incluem:
E aqui está como implementamos a redução de dimensionalidade em Python:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)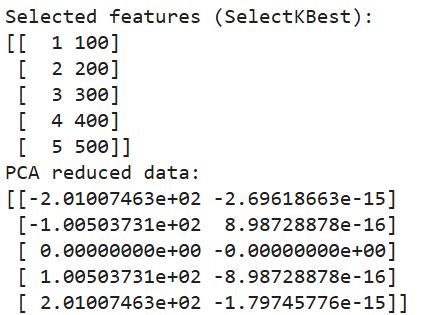
Saída do código acima
Já estabelecemos que o pré-processamento de dados brutos é essencial para garantir que eles sejam adequados para análise ou modelos de aprendizado de máquina. Também abordamos as etapas envolvidas no processo.
Nesta seção, exploraremos várias técnicas para lidar com problemas comuns durante a fase de pré-processamento. Além disso, exploraremos o aumento de dados, uma técnica útil para criar dados sintéticos em contextos específicos, como conjuntos de dados de imagem ou texto.
A falta de dados pode afetar negativamente o desempenho de um modelo ou análise de aprendizado de máquina. Há várias estratégias para lidar com valores ausentes de forma eficaz:
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesOs outliers são valores extremos que se desviam significativamente do restante dos dados e que, assim como os valores ausentes, podem distorcer a análise e o desempenho do modelo. Várias técnicas podem ser usadas para detectar e lidar com outliers:
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Ao trabalhar com dados categóricos, a codificação é necessária para converter categorias em representações numéricas que os algoritmos de aprendizado de máquina possam processar. As técnicas comuns de codificação incluem:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])O escalonamento e a normalização garantem que os recursos numéricos estejam em uma escala semelhante, o que é particularmente importante para algoritmos que dependem de métricas de distância (por exemplo, k-nearest neighbors, SVMs).
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])O aumento de dados é uma técnica para aumentar artificialmente o tamanho de um conjunto de dados por meio da criação de novos exemplos sintéticos. Isso é especialmente útil para conjuntos de dados de imagem ou texto em modelos de aprendizagem profunda, em que grandes quantidades de dados são necessárias para um desempenho robusto do modelo.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Embora você possa implementar o processamento de dados usando código Python puro, foram desenvolvidas ferramentas poderosas para lidar com várias tarefas e tornar o processo geral mais eficiente. Aqui estão alguns exemplos:
Existem várias bibliotecas especializadas para pré-processamento de dados em Python. Aqui estão três dos mais populares:
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)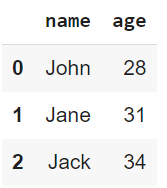
Saída do código acima
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Saída do código acima
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Saída do código acima
Os sistemas locais podem não ser capazes de lidar com grandes conjuntos de dados de forma eficaz. Nessas situações, as plataformas de nuvem oferecem soluções dimensionáveis e eficientes que permitem que você processe grandes quantidades de dados em sistemas distribuídos.
Algumas ferramentas da plataforma de nuvem que você deve considerar incluem:
Automatizar as etapas repetitivas do pré-processamento de dados pode economizar tempo e reduzir erros, especialmente quando você lida com modelos de aprendizado de máquina e grandes conjuntos de dados. Aqui estão algumas ferramentas que oferecem pipelines de pré-processamento integrados:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)É essencial seguir as práticas recomendadas para maximizar a eficácia de seus esforços de pré-processamento. Dito isso, abaixo estão algumas práticas que eu incentivaria você a considerar:
Antes de você se aprofundar no pré-processamento, é importante entender completamente o conjunto de dados. Realizar análise exploratória de dados para identificar a estrutura dos dados em questão. O que você deseja entender especificamente é:
Sem antes entender as características do conjunto de dados, é bem provável que você aplique métodos de pré-processamento incorretos, o que distorcerá os dados.
O pré-processamento geralmente envolve tarefas repetitivas. A automação dessas tarefas por meio da criação de pipelines garante consistência e eficiência e reduz as chances de erros manuais. Para otimizar os fluxos de trabalho, aproveite os pipelines em ferramentas como o scikit-learn ou plataformas baseadas em nuvem.
A documentação clara ajuda a atingir dois objetivos:
Cada decisão, transformação ou etapa de filtragem deve ser registrada, incluindo o raciocínio. Isso aumentará significativamente a colaboração entre os membros da equipe e o ajudará a retomar os projetos de onde você parou.
O pré-processamento de dados não é uma tarefa única - deve ser um processo iterativo. À medida que os modelos evoluem e fornecem feedback sobre seu desempenho, use essas informações para revisitar e refinar as etapas de pré-processamento, pois isso pode levar a melhores resultados. Por exemplo, a engenharia de recursos pode revelar novos recursos úteis ou o ajuste do tratamento de outliers pode melhorar a precisão do modelo - use esse feedback para atualizar as etapas de pré-processamento.
O pré-processamento de dados desempenha um papel fundamental no sucesso de qualquer projeto de dados. O pré-processamento adequado garante que os dados brutos sejam transformados em um formato limpo e estruturado, o que ajuda os modelos e as análises a produzir percepções mais precisas e significativas.
Neste artigo, compartilhei várias técnicas para ajudar a implementar o pré-processamento de dados. Ainda assim, o mais importante a ser observado é que esse processo não é um esforço único, mas um processo iterativo! O refinamento contínuo leva a um melhor desempenho do modelo e a uma melhor tomada de decisões. Um conjunto de dados bem preparado estabelece a base para qualquer iniciativa de IA de dados bem-sucedida.
Para continuar seu aprendizado, recomendo que você consulte os excelentes recursos a seguir:
Saiba mais sobre engenharia de dados com estes cursos!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Vidhi Chugh
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Moez Ali