
Curso
Introducción a la ingeniería de datos
4 h
127.6K
El preprocesamiento de datos implica varios pasos, cada uno de los cuales aborda retos específicos relacionados con la calidad, la estructura y la relevancia de los datos.
Echemos un vistazo a estos pasos clave, que generalmente van en el siguiente orden:
La limpieza de datos es el proceso de identificar y corregir errores o incoherencias en los datos para garantizar que sean exactos y completos. El objetivo es abordar los problemas que pueden distorsionar el análisis o el rendimiento del modelo.
Por ejemplo:
Así es como se ve en Python:
# Creating a manual dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack', 'John', None],
'age': [28, 34, None, 28, 22],
'purchase_amount': [100.5, None, 85.3, 100.5, 50.0],
'date_of_purchase': ['2023/12/01', '2023/12/02', '2023/12/01', '2023/12/01', '2023/12/03']
})
# Handling missing values using mean imputation for 'age' and 'purchase_amount'
imputer = SimpleImputer(strategy='mean')
data[['age', 'purchase_amount']] = imputer.fit_transform(data[['age', 'purchase_amount']])
# Removing duplicate rows
data = data.drop_duplicates()
# Correcting inconsistent date formats
data['date_of_purchase'] = pd.to_datetime(data['date_of_purchase'], errors='coerce')
print(data)
Salida del código anterior
La integración de datos implica combinar datos de múltiples fuentes para crear un conjunto de datos unificado. Esto suele ser necesario cuando los datos se recogen de distintos sistemas fuente.
Algunas técnicas utilizadas en la integración de datos son
Por ejemplo, supongamos que tenemos datos de clientes procedentes de varias bases de datos. Así es como lo fusionaríamos en una sola vista:
# Creating two manual datasets
data1 = pd.DataFrame({
'customer_id': [1, 2, 3],
'name': ['John', 'Jane', 'Jack'],
'age': [28, 34, 29]
})
data2 = pd.DataFrame({
'customer_id': [1, 3, 4],
'purchase_amount': [100.5, 85.3, 45.0],
'purchase_date': ['2023-12-01', '2023-12-02', '2023-12-03']
})
# Merging datasets on a common key 'customer_id'
merged_data = pd.merge(data1, data2, on='customer_id', how='inner')
print(merged_data)
Salida del código anterior
La transformación de datos los convierte en formatos adecuados para el análisis, el aprendizaje automático o la minería.
Por ejemplo:
Así es como se ve en Python, utilizando scikit-learn:
from sklearn.preprocessing import StandardScaler, OneHotEncoder
# Creating a manual dataset
data = pd.DataFrame({
'category': ['A', 'B', 'A', 'C', 'B'],
'numeric_column': [10, 15, 10, 20, 15]
})
# Scaling numeric data
scaler = StandardScaler()
data['scaled_numeric_column'] = scaler.fit_transform(data[['numeric_column']])
# Encoding categorical variables using one-hot encoding
encoder = OneHotEncoder(sparse_output=False)
encoded_data = pd.DataFrame(encoder.fit_transform(data[['category']]),
columns=encoder.get_feature_names_out(['category']))
# Concatenating the encoded data with the original dataset
data = pd.concat([data, encoded_data], axis=1)
print(data)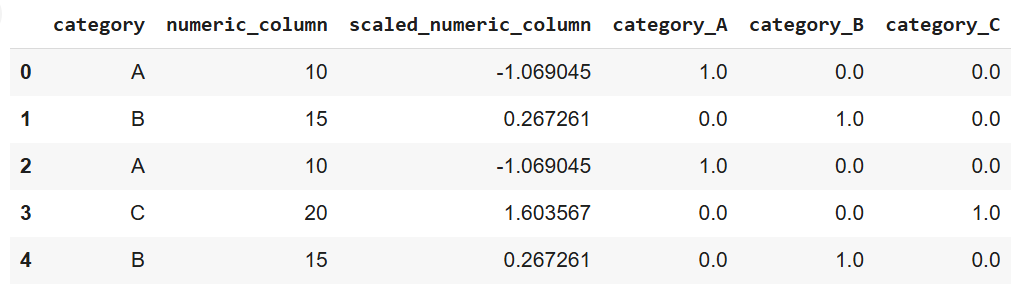
Salida del código anterior
La reducción de datos simplifica el conjunto de datos reduciendo el número de características o registros, pero conservando la información esencial. Esto ayuda a acelerar el análisis y el entrenamiento del modelo sin sacrificar la precisión.
Las técnicas de reducción de datos incluyen
Y así es como aplicamos la reducción de la dimensionalidad en Python:
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, chi2
# Creating a manual dataset
data = pd.DataFrame({
'feature1': [10, 20, 30, 40, 50],
'feature2': [1, 2, 3, 4, 5],
'feature3': [100, 200, 300, 400, 500],
'target': [0, 1, 0, 1, 0]
})
# Feature selection using SelectKBest
selector = SelectKBest(chi2, k=2)
selected_features = selector.fit_transform(data[['feature1', 'feature2', 'feature3']], data['target'])
# Printing selected features
print("Selected features (SelectKBest):")
print(selected_features)
# Dimensionality reduction using PCA
pca = PCA(n_components=2)
pca_data = pca.fit_transform(data[['feature1', 'feature2', 'feature3']])
# Printing PCA results
print("PCA reduced data:")
print(pca_data)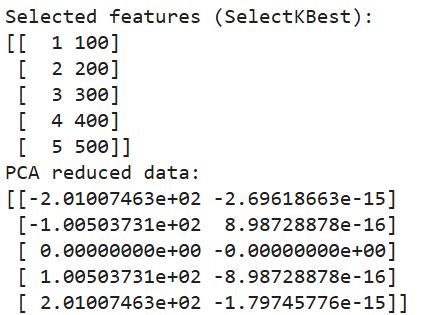
Salida del código anterior
Hemos establecido que el preprocesamiento de los datos brutos es esencial para garantizar que son adecuados para el análisis o los modelos de aprendizaje automático. También hemos cubierto los pasos del proceso.
En esta sección, exploraremos varias técnicas para tratar problemas comunes durante la fase de preprocesamiento. Además, exploraremos el aumento de datos, una técnica útil para crear datos sintéticos en contextos específicos, como conjuntos de datos de imágenes o texto.
Los datos que faltan pueden afectar negativamente al rendimiento de un modelo o análisis de aprendizaje automático. Hay varias estrategias para tratar eficazmente los valores perdidos:
# Note: This is dummy code and not expected to run on its own
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy='mean') # Replace 'mean' with 'median' or 'most_frequent' if needed
data['column_with_missing'] = imputer.fit_transform(data[['column_with_missing']])data.dropna(inplace=True) # Removes rows with any missing valuesLos valores atípicos son valores extremos que se desvían significativamente del resto de los datos y que, al igual que los valores perdidos, pueden distorsionar el análisis y el rendimiento del modelo. Se pueden utilizar varias técnicas para detectar y tratar los valores atípicos:
# Note: this is dummy code.
# It won’t work unless a data with a column named “column” is imported
from scipy import stats
z_scores = stats.zscore(data['column']) outliers = abs(z_scores) > 3 # Identifying outliersQ1 = data['column'].quantile(0.25)
Q3 = data['column'].quantile(0.75)
IQR = Q3 - Q1
outliers = (data['column'] < (Q1 - 1.5 * IQR)) | (data['column'] > (Q3 + 1.5 * IQR))Cuando se trabaja con datos categóricos, la codificación es necesaria para convertir las categorías en representaciones numéricas que los algoritmos de aprendizaje automático puedan procesar. Entre las técnicas habituales de codificación se incluyen:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded_data = encoder.fit_transform(data[['categorical_column']])from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
data['encoded_column'] = le.fit_transform(data['categorical_column'])from sklearn.preprocessing import OrdinalEncoder
oe = OrdinalEncoder(categories=[['low', 'medium', 'high']])
data['ordinal_column'] = oe.fit_transform(data[['ordinal_column']])El escalado y la normalización garantizan que las características numéricas estén en una escala similar, lo que es especialmente importante para los algoritmos que se basan en métricas de distancia (por ejemplo, k-vecinos más próximos, SVM).
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data[['scaled_column']] = scaler.fit_transform(data[['numeric_column']])from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['standardized_column']] = scaler.fit_transform(data[['numeric_column']])El aumento de datos es una técnica para aumentar artificialmente el tamaño de un conjunto de datos creando nuevos ejemplos sintéticos. Esto es especialmente útil para conjuntos de datos de imágenes o texto en modelos de aprendizaje profundo, donde se requieren grandes cantidades de datos para un rendimiento sólido del modelo.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
augmented_images = datagen.flow_from_directory('image_directory', target_size=(150, 150))import nlpaug.augmenter.word as naw
# install nlpaug here: https://github.com/makcedward/nlpaug
aug = naw.SynonymAug(aug_src='wordnet')
augmented_text = aug.augment("This is a sample text for augmentation.")Aunque puedes implementar el procesamiento de datos utilizando código Python puro, se han desarrollado potentes herramientas para gestionar diversas tareas y hacer que el proceso global sea más eficiente. He aquí algunos ejemplos:
Existen bastantes bibliotecas especializadas para el preprocesamiento de datos en Python. Aquí tienes 3 de los más populares:
import pandas as pd
# Load a sample dataset
data = pd.DataFrame({
'name': ['John', 'Jane', 'Jack'],
'age': [28, 31, 34]
})
print(data)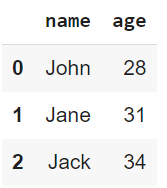
Salida del código anterior
import numpy as np
# Create an array and perform element-wise operations
array = np.array([1, 2, 3, 4])
squared_array = np.square(array)
print(squared_array)![]()
Salida del código anterior
from sklearn.preprocessing import StandardScaler
# Standardize data
data = [[10, 2], [15, 5], [20, 3]]
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
print(scaled_data)
Salida del código anterior
Los sistemas locales pueden no ser capaces de manejar grandes conjuntos de datos con eficacia. En tales situaciones, las plataformas en la nube ofrecen soluciones escalables y eficientes que te permiten procesar grandes cantidades de datos en sistemas distribuidos.
Algunas herramientas de plataforma en la nube a tener en cuenta son
Automatizar los pasos repetitivos del preprocesamiento de datos puede ahorrar tiempo y reducir los errores, especialmente cuando se trata de modelos de aprendizaje automático y grandes conjuntos de datos. He aquí algunas herramientas que ofrecen canalizaciones de preprocesamiento integradas:
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
# Example Pipeline combining different preprocessing tasks
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OneHotEncoder())
])
preprocessor = ColumnTransformer(transformers=[
('num', numeric_transformer, ['age']),
('cat', categorical_transformer, ['category'])
])
preprocessed_data = preprocessor.fit_transform(data)Es esencial seguir las mejores prácticas para maximizar la eficacia de tus esfuerzos de preprocesamiento. Dicho esto, a continuación te propongo algunas prácticas que te animo a considerar:
Antes de sumergirte en el preprocesamiento, es importante comprender a fondo el conjunto de datos. Realiza un análisis exploratorio de los datos para identificar la estructura de los datos en cuestión. Lo que quieres entender específicamente son
Sin conocer primero las características del conjunto de datos, es muy probable que apliques métodos de preprocesamiento incorrectos, que distorsionarán los datos.
El preprocesamiento suele implicar tareas repetitivas. Automatizar estas tareas mediante la creación de pipelines garantiza la coherencia y la eficacia, y reduce las probabilidades de errores manuales. Para agilizar los flujos de trabajo, aprovecha los pipelines de herramientas como scikit-learn o las plataformas basadas en la nube.
Una documentación clara ayuda a conseguir dos objetivos:
Cada decisión, transformación o paso de filtrado debe registrarse, incluido su razonamiento. Esto mejorará significativamente la colaboración entre los miembros del equipo y te ayudará a retomar los proyectos donde los dejaste.
El preprocesamiento de datos no es una tarea de una sola vez, sino que debe ser un proceso iterativo. A medida que los modelos evolucionan y proporcionan información sobre su rendimiento, utiliza esta información para revisar y perfeccionar los pasos del preprocesamiento, ya que puede conducir a mejores resultados. Por ejemplo, la ingeniería de rasgos puede revelar nuevos rasgos útiles, o el ajuste de la gestión de valores atípicos puede mejorar la precisión del modelo: utiliza esta información para actualizar tus pasos de preprocesamiento.
El preprocesamiento de datos desempeña un papel fundamental en el éxito de cualquier proyecto de datos. Un preprocesamiento adecuado garantiza que los datos brutos se transformen en un formato limpio y estructurado, lo que ayuda a que los modelos y análisis produzcan perspectivas más precisas y significativas.
En este artículo, he compartido varias técnicas para ayudar a implementar el preprocesamiento de datos. Aun así, lo más importante que hay que tener en cuenta es que este proceso no es un esfuerzo de una sola vez, ¡sino un proceso iterativo! El perfeccionamiento continuo conduce a un mejor rendimiento del modelo y a una mejor toma de decisiones. Un conjunto de datos bien preparado sienta las bases del éxito de cualquier iniciativa de IA de datos.
Para seguir aprendiendo, te recomiendo que consultes los siguientes recursos excelentes:
¡Aprende más sobre ingeniería de datos con estos cursos!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Kurtis Pykes
Tutorial
Moez Ali
Tutorial
Vidhi Chugh
Tutorial
Abid Ali Awan
Tutorial
Abid Ali Awan

