
Kurs
SQL ile Veri İşleme
4 sa
328.2K
SQL, ilişkisel veritabanlarında verileri yöneten ve işleyen herkes için önemli bir araçtır. Veritabanlarıyla etkileşime geçmemizi ve temel görevleri verimli şekilde gerçekleştirmemizi sağlar. Mevcut veri miktarı her geçen gün arttıkça, bu verileri almak için karmaşık sorgular yazma zorluğuyla karşılaşıyoruz.
Yavaş sorgular gerçek bir darboğaz olabilir; uygulama performansından kullanıcı deneyimine kadar her şeyi etkiler. SQL sorgularını optimize etmek performansı artırır, kaynak tüketimini azaltır ve ölçeklenebilirliği sağlar.
Bu yazıda SQL sorgularımızı optimize etmek için en etkili tekniklerden bazılarına bakacağız. Her tekniğin avantaj ve dezavantajlarına dalarak SQL sorgu performansı üzerindeki etkilerini anlayacağız. Haydi başlayalım!
Bir kütüphanede kataloğu olmadan kitap aradığımızı hayal edin. Bulana kadar her rafı ve her sırayı kontrol etmemiz gerekirdi. Veritabanındaki dizinler kataloglara benzer. Tüm tabloyu taramadan ihtiyaç duyduğumuz veriyi hızlıca bulmamıza yardımcı olurlar.
Dizinler, verinin getirilme hızını artıran veri yapılarıdır. Dizinlenen sütunların sıralı bir kopyasını oluşturarak çalışırlar; bu sayede veritabanı sorgumuzla eşleşen satırları hızla tespit eder ve bize çokça zaman kazandırır.
Veritabanlarında üç ana dizin türü vardır:
Peki, dizinleri SQL sorgularının performansını iyileştirmek için nasıl kullanabiliriz? Bazı en iyi uygulamalara bakalım:
customer_id veya item_id ile arıyorsak, bu sütunları dizinlemek hızı büyük ölçüde etkiler. Aşağıda bir dizin nasıl oluşturulur görebilirsiniz:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT sorgularını hızlandırmada çok faydalı olsa da INSERT, UPDATE ve DELETE işlemlerini biraz yavaşlatabilir. Bunun nedeni, veriyi her değiştirdiğinizde dizinin de güncellenmesi gerekmesidir. Bu nedenle çok fazla dizin, veri değişikliklerinde ek yükü artırarak işleri yavaşlatabilir. Bazen analizimizle ilgisi olmayanlar dahil tüm sütunları çekmek için SELECT * kullanmaya meylederiz. Bu pratik görünebilse de performansı yavaşlatan çok verimsiz sorgulara yol açar.
Veritabanı gereğinden fazla veriyi okumak ve aktarmak zorunda kalır; sunucunun ihtiyaçtan fazla bilgiyi işlemesi ve saklaması gerektiği için daha yüksek bellek kullanımı gerektirir.
Genel bir en iyi uygulama olarak, yalnızca ihtiyaç duyduğumuz belirli sütunları seçmeliyiz. Gereksiz veriyi en aza indirmek, kodumuzu temiz ve anlaşılır tutmanın yanı sıra performansın optimize edilmesine de yardımcı olur.
Dolayısıyla şunu yazmak yerine:
SELECT *
FROM products;Şunu yazmalıyız:
SELECT product_id, product_name, product_price
FROM products;Az önce yalnızca ilgili sütunları seçmenin SQL sorgularını optimize etmek için iyi bir uygulama olduğundan bahsettik. Ancak sadece sütunları değil, getirdiğimiz satır sayısını da sınırlamak önemlidir. Satır sayısı arttıkça sorgular genellikle yavaşlar.
Dönen satır sayısını azaltmak için LIMIT kullanabiliriz. Bu özellik, yalnızca birkaç satırla çalışmamız gerekirken istemeden binlerce satır veri çekmemizi engeller.
LIMIT fonksiyonu özellikle doğrulama sorguları veya üzerinde çalıştığımız bir dönüşümün çıktısını incelemek için faydalıdır. Deney yapmak ve kodumuzun nasıl davrandığını anlamak için idealdir. Ancak tüm veri kümesini döndürmemiz gereken otomatik veri modelleri için uygun olmayabilir.
İşte LIMIT kullanımına bir örnek:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;İlişkisel veritabanlarıyla çalışırken, veriler çoğu zaman fazlalığı önlemek ve verimliliği artırmak için ayrı tablolarda düzenlenir. Ancak bu, ihtiyacımız olan tüm ilgili bilgileri elde etmek için verileri farklı yerlerden alıp birleştirmemiz gerektiği anlamına gelir.
Join’ler, aralarında ilişkili bir sütuna dayanarak iki veya daha fazla tablodan satırları tek bir sorguda birleştirmemizi sağlar ve daha karmaşık analizler yapmayı mümkün kılar.
Farklı join türleri vardır ve bunları nasıl kullanacağımızı anlamamız gerekir. Yanlış join kullanımı veri kümemizde yinelenen satırlar oluşmasına ve yavaşlamaya neden olabilir.
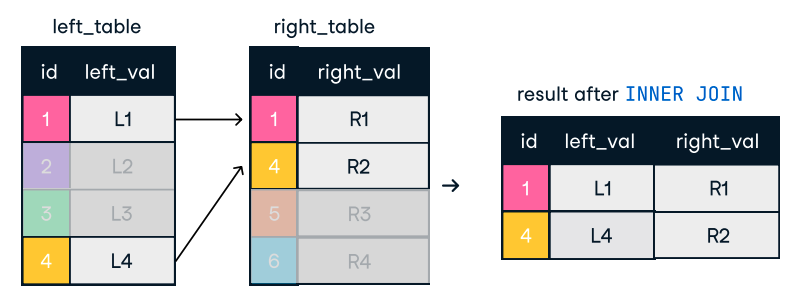
Şekil: Inner Join. Görsel kaynağı: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
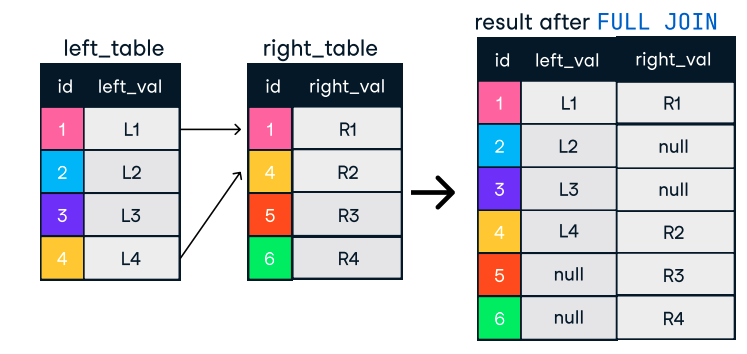
Şekil: Outer veya Full Join. Görsel kaynağı: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;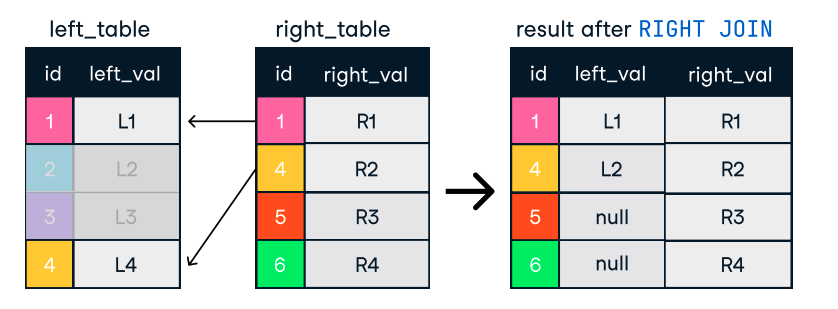
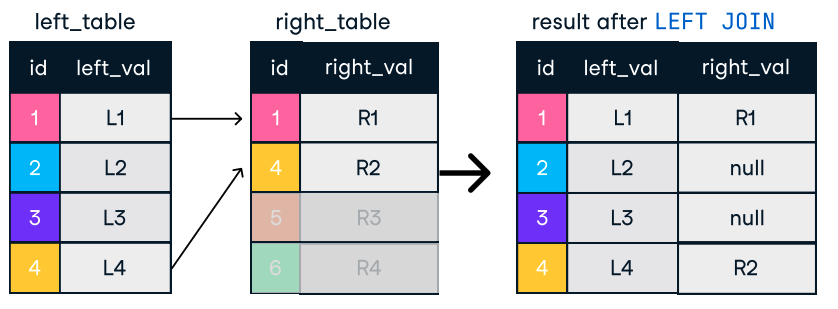
Şekil: Left ve Right Join. Görsel kaynağı: DataCamp SQL-Join cheat sheet.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Verimli join’ler için ipuçları:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;Çoğu zaman SQL sorgularını çalıştırır ve yalnızca elde edilen çıktının beklediğimiz gibi olup olmadığını kontrol ederiz. Ancak bir SQL sorgusunu yürüttüğümüzde arka planda neler olduğuna nadiren kafa yorarız.
Çoğu veritabanı bu süreci görselleştirmek için EXPLAIN veya EXPLAIN PLAN gibi işlevler sunar. Bu planlar, veritabanının verileri nasıl getireceğine dair adım adım bir döküm sağlar. Bu özelliği performans darboğazlarını belirlemek ve sorgularımızı optimize etme konusunda bilinçli kararlar almak için kullanabiliriz.
Darboğazları belirlemek için EXPLAIN nasıl kullanabiliriz, görelim. Aşağıdaki kodu çalıştıracağız:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id Ardından sonuçları inceleyebiliriz:
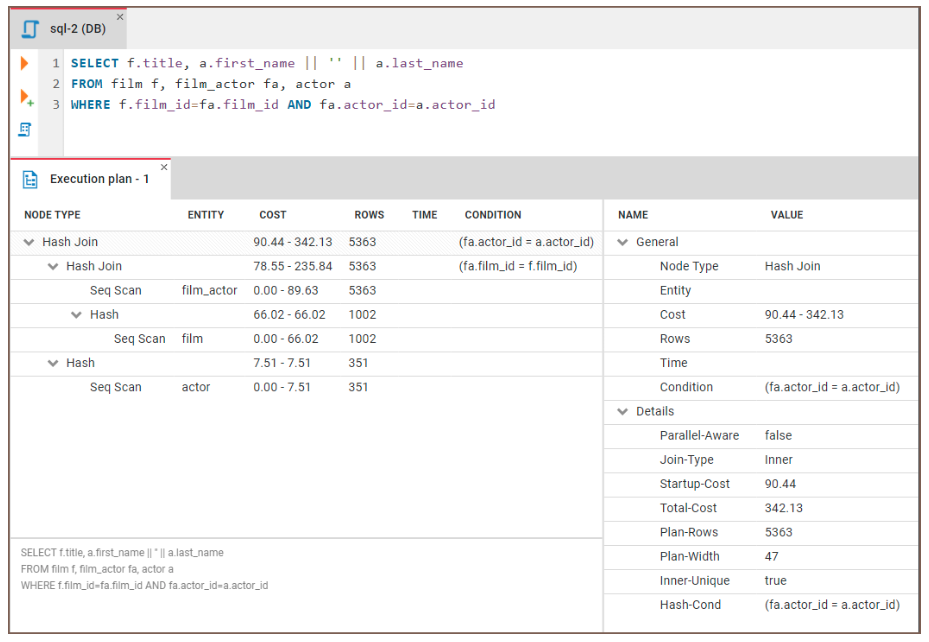
Şekil: Örnek bir sorgu yürütme planı. Görsel kaynağı: CloudDBeaver website.
Sonuçları yorumlamak için genel bir yol haritası:
WHERE koşuluna işaret eder.WHERE koşulu, belirli koşullara göre verileri filtrelememizi sağlayarak yalnızca ilgili kayıtların döndürülmesini mümkün kıldığı için SQL sorgularında esastır. İşlenen veri miktarını azaltarak sorgu verimliliğini artırır; bu da büyük veri kümeleriyle çalışırken çok önemlidir.
Dolayısıyla doğru bir WHERE koşulu, bir SQL sorgusunun performansını optimize ederken güçlü bir müttefik olabilir. Bu koşuldan nasıl yararlanabileceğimize dair bazı yollar görelim:
WHERE koşuluna sahip olmak iyidir ama yeterli değildir. Koşulu nereye yerleştirdiğimize dikkat etmeliyiz. WHERE içinde mümkün olduğunca erken aşamada fazla satırları elemek sorguyu optimize etmeye yardımcı olabilir.WHERE koşulundaki sütunlarda fonksiyon kullanmaktan kaçının. Bir sütuna fonksiyon uyguladığımızda, veritabanı sonuçları filtreleyebilmeden önce bu fonksiyonu tablodaki her satıra uygulamak zorunda kalır. Bu da veritabanının dizinleri etkin şekilde kullanmasını engeller.Örneğin, bunun yerine:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Şunu kullanmalıyız:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= genellikle LIKE’dan daha hızlıdır ve belirli tarih aralıkları kullanmak, MONTH(order_date) gibi fonksiyonları kullanmaktan daha hızlıdır.Dolayısıyla, şu sorguyu çalıştırmak yerine:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Aşağıdakini uygulayabiliriz:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';Bazı durumlarda bir sorgu yazarken dinamik olarak filtreleme, toplama veya join işlemleri yapmamız gerektiğini hissederiz. Birden fazla sorgu yapmak istemeyiz; bunun yerine tek bir sorguyla kalmak isteriz.
Bu durumlar için alt sorguları kullanabiliriz. SQL’de alt sorgular genellikle SELECT, INSERT, UPDATE veya DELETE ifadeleri içinde yuvalanmış sorgulardır.
Alt sorgular güçlü ve hızlı olabilir; ancak dikkatli kullanılmazlarsa performans sorunlarına yol açabilirler. Kural olarak, alt sorguların kullanımını en aza indirmeli ve bir dizi en iyi uygulamayı izlemeliyiz:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Alt sorgularla çalışırken, bir değerin sonuç kümesinde olup olmadığını sıkça kontrol etmemiz gerekir. Bunu IN veya EXISTS ile yapabiliriz; ancak özellikle büyük veri kümelerinde EXISTS genellikle daha etkilidir.
IN koşulu, alt sorgunun tüm sonuç kümesini karşılaştırmadan önce belleğe okur. Öte yandan EXISTS ilk eşleşmeyi bulur bulmaz alt sorgunun işlenmesini durdurur.
Bu koşulun nasıl kullanılacağına bir örnek:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Benzersiz şehirlerden müşterilere promosyon teklifi göndermek için bir analiz yaptığımızı hayal edin. Veritabanında aynı müşterilerden birden çok sipariş var. Aklımıza gelen ilk şey DISTINCT koşulunu kullanmaktır.
Bu işlev bazı durumlar için kullanışlıdır ancak özellikle büyük veri kümelerinde kaynak açısından yoğundur. DISTINCT için birkaç alternatif vardır:
DISTINCT yerine GROUP BY kullanın. GROUP BY özellikle toplu fonksiyonlarla birlikte kullanıldığında daha verimli olabilir. Dolayısıyla şunu çalıştırmak yerine:
SELECT DISTINCT city FROM customers;Şunu kullanabiliriz:
SELECT city FROM customers GROUP BY city;ROW_NUMBER gibi fonksiyonlar, DISTINCT kullanmadan kopyaları tanımlamamıza ve elememize yardımcı olabilir.Verilerle çalışırken onlarla bir Veritabanı Yönetim Sistemi (DBMS) aracılığıyla SQL kullanarak etkileşime gireriz. DBMS, SQL komutlarını işler, veritabanını yönetir ve veri bütünlüğü ile güvenliğini sağlar. Farklı veritabanı sistemleri, sorguları optimize etmeye yardımcı olabilecek benzersiz özellikler sunar.
Veritabanı ipuçları (hints), bir sorgunun daha verimli yürütülmesi için sorgularımıza ekleyebileceğimiz özel yönergelerdir. Faydalıdırlar, ancak dikkatli kullanılmalıdırlar.
Örneğin MySQL’de USE INDEX ipucu belirli bir dizinin kullanımını zorlayabilir:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;SQL Server’da OPTION (LOOP JOIN) ipucu join yöntemini belirtir:
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Bu ipuçları, belirli senaryolarda performansı iyileştirerek varsayılan sorgu optimizasyonunu geçersiz kılar.
Öte yandan, bölümleme (partitioning) ve sharding, bulutta veriyi dağıtmak için kullanılan iki tekniktir.
Sorgu iyileştiricisinin (optimizer) sorguları en verimli şekilde yürütmenin yollarına ilişkin bilinçli ve doğru kararlar alabilmesini sağlamak için veritabanı istatistiklerini güncel tutmak önemlidir.
İstatistikler bir tablodaki veri dağılımını (ör. satır sayısı, değerlerin sıklığı ve sütunlar arasındaki yayılım) açıklar ve iyileştirici, sorgu yürütme maliyetlerini tahmin etmek için bu bilgilere güvenir. İstatistikler güncel değilse, iyileştirici yanlış dizinleri kullanmak veya daha verimli bir dizin taraması yerine tam tablo taramasını tercih etmek gibi verimsiz yürütme planları seçebilir; bu da zayıf sorgu performansına yol açar.
Veritabanları, doğru istatistikleri korumak için genellikle otomatik güncellemeleri destekler. Örneğin SQL Server’da varsayılan yapılandırma, önemli miktarda veri değiştiğinde istatistikleri otomatik olarak günceller. Benzer şekilde PostgreSQL’de belirli bir veri değişiklik eşiğinden sonra istatistikleri güncelleyen auto-analyze özelliği vardır.
Ancak otomatik güncellemelerin yetersiz kaldığı veya manuel müdahalenin gerektiği durumlarda istatistikleri elle güncelleyebiliriz. SQL Server’da belirli bir tablo veya dizin için istatistikleri yenilemek üzere UPDATE STATISTICS komutunu; PostgreSQL’de ise bir veya daha fazla tablo için istatistikleri güncellemek üzere ANALYZE komutunu kullanabiliriz.
-- Geçerli veritabanındaki tüm tablolar için istatistikleri güncelle
ANALYZE;
-- Belirli bir tablo için istatistikleri güncelle
ANALYZE my_table;Saklı yordam, veritabanımıza kaydettiğimiz ve aynı SQL’i tekrar tekrar yazmamıza gerek bırakmayan bir SQL komutları kümesidir. Yeniden kullanılabilir bir betik olarak düşünebiliriz.
Kayıtları güncellemek veya değerleri hesaplamak gibi belirli bir görevi yerine getirmemiz gerektiğinde saklı yordamı çağırırız. Girdi alabilir, bazı işlemler (sorgulama veya veriyi değiştirme gibi) yapabilir ve hatta bir sonuç döndürebilir. Saklı yordamlar, SQL önceden derlendiği için işleri hızlandırır; kodunuzu daha temiz ve yönetimi kolay hale getirir.
PostgreSQL’de aşağıdaki gibi bir saklı yordam oluşturabiliriz:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');Veri uygulayıcıları olarak, içgörüleri daha kolay elde etmek için verimizin sıralı ve gruplu olmasını severiz. SQL sorgularımızda genellikle ORDER BY ve GROUP BY kullanırız.
Ancak her iki koşul da, özellikle büyük veri kümeleriyle uğraşırken hesaplama açısından pahalı olabilir. Veriyi sıralarken veya toplarken veritabanı motoru çoğu zaman verinin tamamını taramak ve ardından düzenlemek, grupları belirlemek ve/veya toplu fonksiyonları uygulamak zorunda kalır; bu da genellikle kaynak yoğun algoritmalar gerektirir.
Sorguları optimize etmek için şu ipuçlarını takip edebiliriz:
ORDER BY’ı yalnızca gerektiğinde kullanmalıyız. Sıralama zorunlu değilse bu koşulu çıkarmak işlem süresini önemli ölçüde azaltabilir. ORDER BY ve GROUP BY içinde yer alan sütunların dizinlendiğinden emin olmalıyız. GROUP BY içeren karmaşık sorgularda, veriyi daha erken bir aşamada veya bir maddileştirilmiş görünümde önceden toplayabiliriz; böylece veritabanının aynı toplamları tekrar tekrar hesaplamasına gerek kalmaz.Birden çok sorgunun sonuçlarını tek bir listede birleştirmek istediğimizde UNION ve UNION ALL koşullarını kullanabiliriz. Her ikisi de aynı sütun adlarına sahip iki veya daha fazla SELECT ifadesinin sonuçlarını birleştirir. Ancak aynı değillerdir ve aralarındaki fark, farklı kullanım senaryolarına uygun olmalarını sağlar.
UNION yinelenen satırları kaldırır; bu da daha fazla işlem süresi gerektirir.
Şekil: SQL’de Union. Görsel kaynağı: DataCamp SQL-Join cheat sheet.
Öte yandan UNION ALL sonuçları birleştirir ancak yinelenenler dahil tüm satırları korur. Dolayısıyla, kopyaları kaldırmamız gerekmiyorsa daha iyi performans için UNION ALL kullanmalıyız.
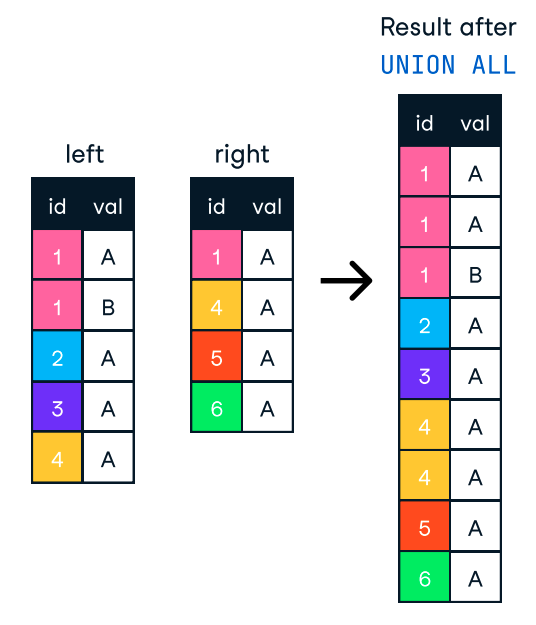
Şekil: SQL’de UNION ALL. Görsel kaynağı: DataCamp SQL-Join cheat sheet.
-- Potansiyel olarak daha yavaş
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potansiyel olarak daha hızlı
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Büyük veri kümeleriyle çalışmak, sıklıkla anlaşılması ve optimize edilmesi zor karmaşık sorgularla karşılaşacağımız anlamına gelir. Bu vakaları daha küçük ve basit sorgulara bölerek ele alabiliriz. Böylece performans darboğazlarını daha kolay belirleyebilir ve optimizasyon tekniklerini uygulayabiliriz.
Sorguları parçalara ayırmak için en sık kullanılan stratejilerden biri maddileştirilmiş görünümlerdir. Bu, her başvurulduğunda sorgunun yeniden hesaplanması yerine önceden hesaplanmış ve depolanmış sorgu sonuçlarıdır; bu sonuçlara hızlıca erişilebilir. Temel veriler değiştiğinde, maddileştirilmiş görünümün manuel veya otomatik olarak yenilenmesi gerekir.
İşte bir maddileştirilmiş görünümün nasıl oluşturulacağı ve sorgulanacağına dair bir örnek:
-- Maddileştirilmiş görünüm oluştur
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Maddileştirilmiş görünümü sorgula
SELECT * FROM daily_sales;Bu yazıda, dizinleme ve join’lerden alt sorgulara ve veritabanına özgü özelliklere kadar SQL sorgularını optimize etmeye yönelik çeşitli stratejileri ve en iyi uygulamaları inceledik. Bu teknikleri uygulayarak sorgularınızın performansını önemli ölçüde artırabilir ve veritabanlarımızın daha verimli çalışmasını sağlayabilirsiniz.
Unutmayın, SQL sorgularını optimize etmek sürekli bir süreçtir. Verileriniz büyüdükçe ve uygulamanız geliştikçe, sorgularınızın en iyi performansta çalıştığından emin olmak için onları sürekli izleyip optimize etmeniz gerekir.
SQL’i daha iyi anlamak için DataCamp’teki aşağıdaki kaynakları incelemenizi öneririz:
Bu kurslarla SQL hakkında daha fazlasını öğrenin!
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
