
Kursus
Manipulasi Data di SQL
4 Hr
328.2K
SQL adalah alat penting bagi siapa pun yang mengelola dan memanipulasi data dalam database relasional. SQL memungkinkan kita berinteraksi dengan database dan melakukan tugas-tugas penting secara efisien. Dengan pertumbuhan data yang tersedia setiap hari, kita menghadapi tantangan untuk menulis query kompleks guna mengambil data tersebut.
Query yang lambat bisa menjadi penghambat utama, memengaruhi kinerja aplikasi hingga pengalaman pengguna. Mengoptimalkan query SQL meningkatkan performa, mengurangi konsumsi sumber daya, dan memastikan skalabilitas.
Dalam artikel ini, kita akan meninjau beberapa teknik paling efektif untuk mengoptimalkan query SQL. Kita akan membahas manfaat dan kelemahan masing-masing teknik untuk memahami dampaknya terhadap performa query SQL. Mari mulai!
Bayangkan kita mencari sebuah buku di perpustakaan tanpa katalog. Kita harus memeriksa setiap rak dan setiap baris sampai akhirnya menemukannya. Indeks dalam database mirip dengan katalog. Indeks membantu kita dengan cepat menemukan data yang dibutuhkan tanpa memindai seluruh tabel.
Indeks adalah struktur data yang meningkatkan kecepatan pengambilan data. Indeks bekerja dengan membuat salinan terurut dari kolom yang diindeks, sehingga database dapat dengan cepat menemukan baris yang cocok dengan query kita, menghemat banyak waktu.
Ada tiga jenis indeks utama dalam database:
Lalu, bagaimana kita bisa menggunakan indeks untuk meningkatkan performa query SQL? Berikut beberapa praktik terbaik:
customer_id atau item_id, melakukan indeks pada kolom-kolom tersebut akan sangat berdampak pada kecepatan. Lihat di bawah cara membuat indeks:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT, indeks dapat sedikit memperlambat operasi INSERT, UPDATE, dan DELETE. Ini karena indeks perlu diperbarui setiap kali Anda memodifikasi data. Jadi, terlalu banyak indeks dapat memperlambat proses dengan meningkatkan overhead untuk modifikasi data. Terkadang, kita tergoda menggunakan SELECT * untuk mengambil semua kolom, termasuk yang tidak relevan dengan analisis. Meskipun tampak praktis, ini menghasilkan query yang sangat tidak efisien dan dapat memperlambat performa.
Database harus membaca dan mentransfer lebih banyak data daripada yang diperlukan, sehingga membutuhkan penggunaan memori yang lebih tinggi karena server harus memproses dan menyimpan informasi lebih banyak dari yang dibutuhkan.
Sebagai praktik terbaik, kita hanya perlu memilih kolom spesifik yang dibutuhkan. Meminimalkan data yang tidak perlu tidak hanya menjaga kode tetap ringkas dan mudah dipahami, tetapi juga membantu mengoptimalkan performa.
Jadi, alih-alih menulis:
SELECT *
FROM products;Kita sebaiknya menulis:
SELECT product_id, product_name, product_price
FROM products;Kita baru saja membahas bahwa memilih hanya kolom yang relevan merupakan praktik terbaik untuk mengoptimalkan query SQL. Namun, penting juga untuk membatasi jumlah baris yang diambil, bukan hanya kolom. Query biasanya melambat ketika jumlah baris meningkat.
Kita dapat menggunakan LIMIT untuk mengurangi jumlah baris yang dikembalikan. Fitur ini mencegah kita tanpa sengaja mengambil ribuan baris data ketika kita hanya perlu bekerja dengan beberapa saja.
Fungsi LIMIT sangat membantu untuk query validasi atau memeriksa output dari transformasi yang sedang kita kerjakan. Ini ideal untuk eksperimen dan memahami bagaimana kode kita berperilaku. Namun, mungkin tidak cocok untuk model data otomatis, di mana kita perlu mengembalikan seluruh dataset.
Berikut contoh cara kerja LIMIT:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;Saat bekerja dengan database relasional, data sering diorganisasi ke dalam tabel terpisah untuk menghindari redundansi dan meningkatkan efisiensi. Namun, ini berarti kita perlu mengambil data dari lokasi berbeda dan menggabungkannya untuk mendapatkan semua informasi relevan yang kita perlukan.
Join memungkinkan kita menggabungkan baris dari dua atau lebih tabel berdasarkan kolom terkait di antara tabel-tabel tersebut dalam satu query, sehingga memungkinkan analisis yang lebih kompleks.
Ada berbagai jenis join, dan kita perlu memahami cara menggunakannya. Menggunakan join yang salah dapat membuat duplikasi dalam dataset dan memperlambat proses.
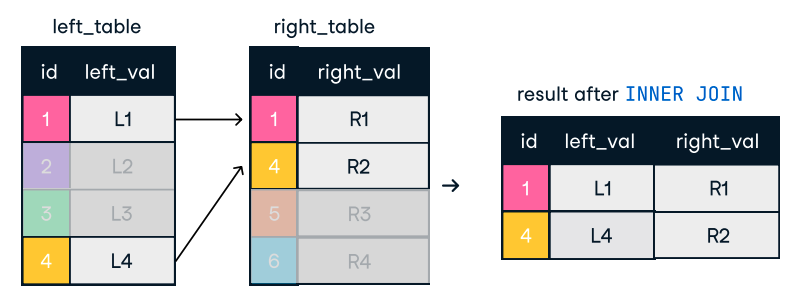
Gambar: Inner Join. Sumber gambar: Lembar contekan SQL-Join DataCamp.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
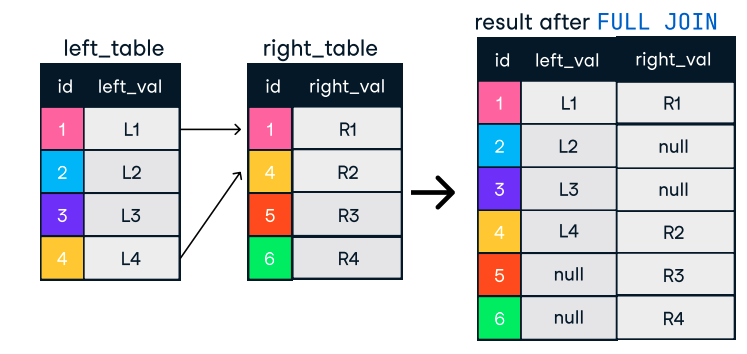
Gambar: Outer atau Full Join. Sumber gambar: Lembar contekan SQL-Join DataCamp.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;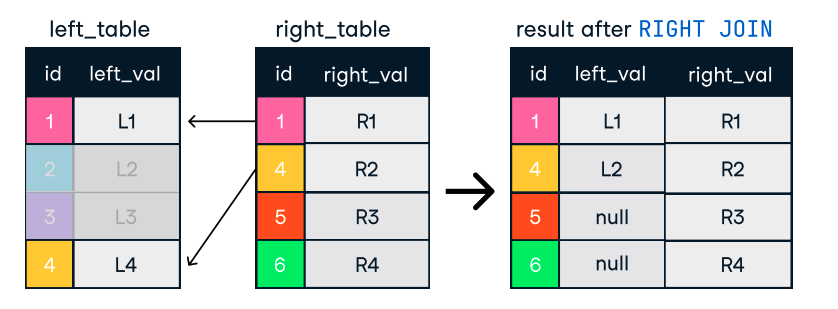
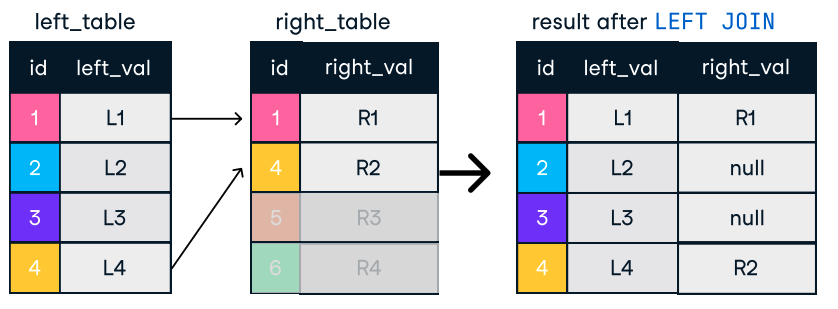
Gambar: Left dan Right Join. Sumber gambar: Lembar contekan SQL-Join DataCamp.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Tips untuk join yang efisien:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;Sering kali, kita menjalankan query SQL dan hanya memeriksa apakah output atau hasil yang diambil sesuai harapan. Namun, jarang kita memikirkan apa yang terjadi di balik layar saat menjalankan query SQL.
Sebagian besar database menyediakan fungsi seperti EXPLAIN atau EXPLAIN PLAN untuk memvisualisasikan proses ini. Rencana ini memberikan rincian langkah demi langkah tentang bagaimana database akan mengambil data. Kita dapat menggunakan fitur ini untuk mengidentifikasi di mana letak bottleneck performa dan membuat keputusan yang tepat untuk mengoptimalkan query.
Mari lihat bagaimana kita dapat menggunakan EXPLAIN untuk mengidentifikasi bottleneck. Kita akan menjalankan kode berikut:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id Kita kemudian dapat menelaah hasilnya:
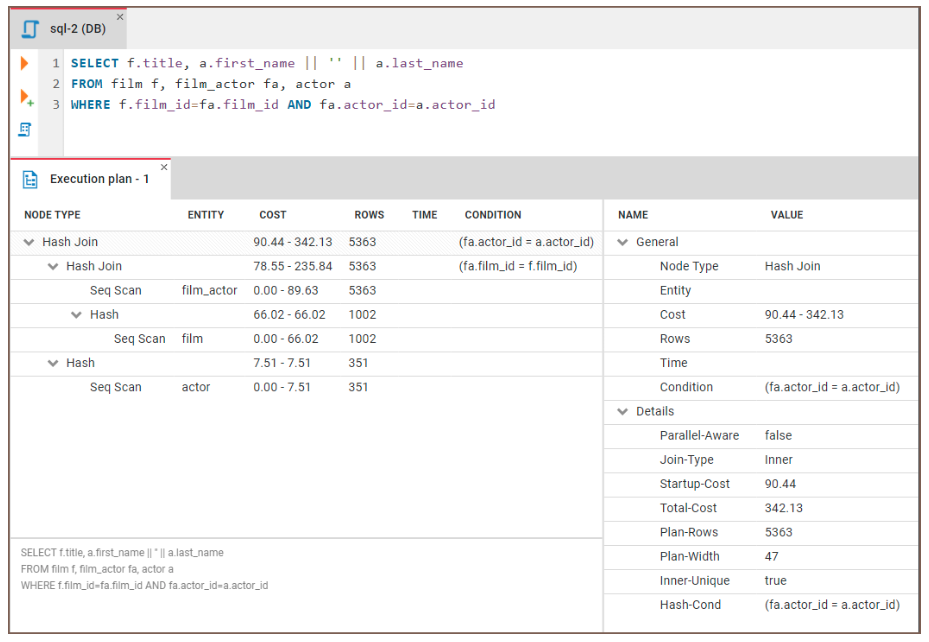
Gambar: Contoh rencana eksekusi query. Sumber gambar: Situs CloudDBeaver.
Berikut panduan umum untuk menafsirkan hasilnya:
WHERE yang tidak efisien.Klausa WHERE sangat penting dalam query SQL karena memungkinkan kita memfilter data berdasarkan kondisi tertentu, memastikan hanya record yang relevan yang dikembalikan. Ini meningkatkan efisiensi query dengan mengurangi jumlah data yang diproses, yang sangat penting saat bekerja dengan dataset besar.
Jadi, klausa WHERE yang tepat bisa menjadi andalan saat kita mengoptimalkan performa query SQL. Berikut beberapa cara untuk memanfaatkannya:
WHERE saja belum cukup. Kita harus berhati-hati di mana kita menempatkannya. Menyaring sebanyak mungkin baris sedini mungkin dalam klausa WHERE dapat membantu mengoptimalkan query.WHERE. Saat kita menerapkan fungsi pada sebuah kolom, database harus menerapkan fungsi tersebut pada setiap baris di tabel sebelum dapat memfilter hasil. Hal ini mencegah database menggunakan indeks secara efektif.Sebagai contoh, alih-alih:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Kita sebaiknya menggunakan:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= umumnya lebih cepat daripada LIKE, dan menggunakan rentang tanggal spesifik lebih cepat daripada menggunakan fungsi seperti MONTH(order_date).Jadi, misalnya, alih-alih menjalankan query berikut:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Kita dapat menjalankan yang berikut:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';Dalam beberapa kasus, saat menulis query kita merasa perlu melakukan pemfilteran, agregasi, atau join data secara dinamis. Kita tidak ingin membuat beberapa query; kita ingin tetap satu query saja.
Untuk kasus tersebut, kita dapat menggunakan subquery. Subquery dalam SQL adalah query yang disarang di dalam query lain, biasanya pada pernyataan SELECT, INSERT, UPDATE, atau DELETE.
Subquery bisa kuat dan cepat, tetapi juga dapat menyebabkan masalah performa jika tidak digunakan dengan hati-hati. Sebagai aturan, kita perlu meminimalkan penggunaan subquery dan mengikuti serangkaian praktik terbaik:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Saat bekerja dengan subquery, kita sering perlu memeriksa apakah suatu nilai ada dalam sekumpulan hasil. Kita dapat melakukannya dengan IN atau EXISTS, tetapi EXISTS umumnya lebih efisien, terutama untuk dataset yang lebih besar.
Klausa IN membaca seluruh hasil subquery ke dalam memori sebelum membandingkan. Di sisi lain, klausa EXISTS menghentikan pemrosesan subquery segera setelah menemukan kecocokan.
Berikut contoh cara menggunakan klausa ini:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Bayangkan kita mengerjakan analisis untuk mengirim penawaran promosi kepada pelanggan dari kota yang unik. Database memiliki banyak pesanan dari pelanggan yang sama. Hal pertama yang terlintas di benak kita adalah menggunakan klausa DISTINCT.
Fungsi ini berguna untuk kasus tertentu tetapi bisa menguras sumber daya, terutama pada dataset besar. Ada beberapa alternatif untuk DISTINCT:
GROUP BY alih-alih DISTINCT bila memungkinkan. GROUP BY bisa lebih efisien, terutama jika digabungkan dengan fungsi agregat. Jadi, alih-alih menjalankan:
SELECT DISTINCT city FROM customers;Kita dapat menggunakan:
SELECT city FROM customers GROUP BY city;ROW_NUMBER dapat membantu kita mengidentifikasi duplikasi dan menyaringnya tanpa menggunakan DISTINCT.Saat bekerja dengan data, kita berinteraksi menggunakan SQL melalui Database Management System (DBMS). DBMS memproses perintah SQL, mengelola database, dan memastikan integritas serta keamanan data. Sistem database yang berbeda menawarkan fitur unik yang dapat membantu mengoptimalkan query.
Database hint adalah instruksi khusus yang dapat kita tambahkan ke query agar dieksekusi lebih efisien. Hint berguna, tetapi harus digunakan dengan hati-hati.
Contohnya, di MySQL, hint USE INDEX dapat memaksa penggunaan indeks tertentu:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;Di SQL Server, hint OPTION (LOOP JOIN) menentukan metode join:
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Hint ini menimpa optimasi query bawaan, meningkatkan performa dalam skenario tertentu.
Di sisi lain, partitioning dan sharding adalah dua teknik untuk mendistribusikan data di cloud.
Menjaga statistik database tetap mutakhir penting agar query optimizer dapat membuat keputusan yang tepat dan akurat terkait cara paling efisien mengeksekusi query.
Statistik menjelaskan distribusi data dalam sebuah tabel (misalnya, jumlah baris, frekuensi nilai, dan sebaran nilai di berbagai kolom), dan optimizer bergantung pada informasi ini untuk memperkirakan biaya eksekusi query. Jika statistik usang, optimizer dapat memilih rencana eksekusi yang tidak efisien, seperti menggunakan indeks yang salah atau memilih full table scan alih-alih index scan yang lebih efisien, yang mengarah pada performa query yang buruk.
Database sering mendukung pembaruan otomatis untuk mempertahankan statistik yang akurat. Misalnya, di SQL Server, konfigurasi default secara otomatis memperbarui statistik saat sejumlah besar data berubah. Demikian pula, PostgreSQL memiliki fitur auto-analyze, yang memperbarui statistik setelah ambang batas modifikasi data tertentu tercapai.
Namun, kita dapat memperbarui statistik secara manual jika pembaruan otomatis tidak memadai atau jika diperlukan intervensi manual. Di SQL Server, kita dapat menggunakan perintah UPDATE STATISTICS untuk menyegarkan statistik untuk tabel atau indeks tertentu, sementara di PostgreSQL, perintah ANALYZE dapat dijalankan untuk memperbarui statistik untuk satu atau lebih tabel.
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;Stored procedure adalah sekumpulan perintah SQL yang kita simpan di database sehingga kita tidak perlu menulis SQL yang sama berulang kali. Anggap saja sebagai skrip yang dapat digunakan kembali.
Saat kita perlu melakukan tugas tertentu, seperti memperbarui record atau menghitung nilai, kita cukup memanggil stored procedure. Stored procedure dapat menerima input, melakukan pekerjaan seperti melakukan query atau memodifikasi data, dan bahkan mengembalikan hasil. Stored procedure membantu mempercepat proses karena SQL sudah dikompilasi sebelumnya, sehingga kode Anda lebih bersih dan lebih mudah dikelola.
Kita dapat membuat stored procedure di PostgreSQL sebagai berikut:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');Sebagai praktisi data, kita senang data kita diurutkan dan dikelompokkan agar lebih mudah mendapatkan insight. Kita biasanya menggunakan ORDER BY dan GROUP BY dalam query SQL.
Namun, kedua klausa ini dapat mahal secara komputasi, terutama saat menangani dataset besar. Saat mengurutkan atau mengagregasikan data, mesin database sering kali harus melakukan pemindaian penuh terhadap data lalu mengaturnya, mengidentifikasi grup, dan/atau menerapkan fungsi agregat, biasanya menggunakan algoritme yang intensif sumber daya.
Untuk mengoptimalkan query, kita dapat mengikuti beberapa tips berikut:
ORDER BY saat diperlukan. Jika pengurutan tidak esensial, menghilangkan klausa ini dapat sangat mengurangi waktu pemrosesan. ORDER BY dan GROUP BY terindeks. GROUP BY, kita dapat melakukan pra-agregasi data pada tahap lebih awal atau dalam sebuah materialized view, sehingga database tidak perlu menghitung agregat yang sama berulang kali.Saat kita ingin menggabungkan hasil dari beberapa query menjadi satu daftar, kita dapat menggunakan klausa UNION dan UNION ALL. Keduanya menggabungkan hasil dari dua atau lebih pernyataan SELECT ketika memiliki nama kolom yang sama. Namun, keduanya tidak sama, dan perbedaannya membuatnya cocok untuk kasus penggunaan yang berbeda.
Klausa UNION menghapus baris duplikat, yang memerlukan waktu pemrosesan lebih lama.
Gambar: Union dalam SQL. Sumber gambar: Lembar contekan SQL-Join DataCamp.
Di sisi lain, UNION ALL menggabungkan hasil tetapi mempertahankan semua baris, termasuk duplikasi. Jadi, jika kita tidak perlu menghapus duplikasi, sebaiknya gunakan UNION ALL untuk performa yang lebih baik.
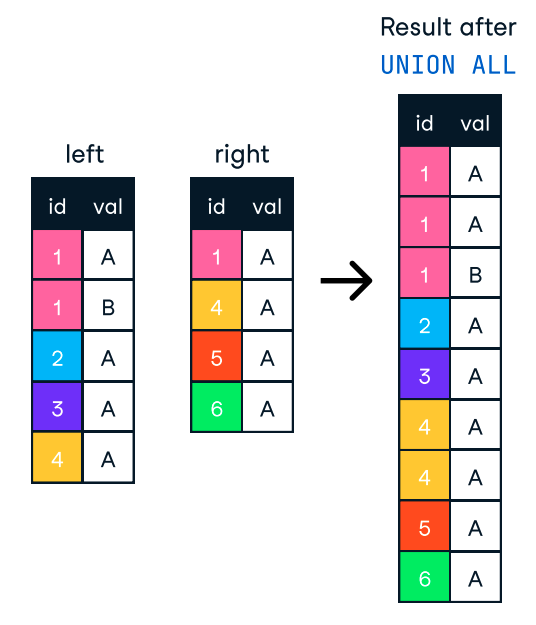
Gambar: UNION ALL dalam SQL. Sumber: Lembar contekan SQL-Join DataCamp.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Bekerja dengan dataset besar berarti kita sering menemui query kompleks yang sulit dipahami dan dioptimalkan. Kita dapat mencoba mengatasinya dengan memecahnya menjadi query yang lebih kecil dan sederhana. Dengan cara ini, kita lebih mudah mengidentifikasi bottleneck performa dan menerapkan teknik optimasi.
Salah satu strategi yang paling sering digunakan untuk memecah query adalah materialized view. Ini adalah hasil query yang dihitung dan disimpan sebelumnya sehingga dapat diakses dengan cepat alih-alih menghitung ulang setiap kali direferensikan. Saat data dasar berubah, materialized view harus disegarkan secara manual atau otomatis.
Berikut contoh cara membuat dan melakukan query pada materialized view:
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;Dalam artikel ini, kita telah mengeksplorasi berbagai strategi dan praktik terbaik untuk mengoptimalkan query SQL, mulai dari pengindeksan dan join hingga subquery dan fitur spesifik database. Dengan menerapkan teknik-teknik ini, Anda dapat secara signifikan meningkatkan performa query dan membuat database kita berjalan lebih efisien.
Ingat, mengoptimalkan query SQL adalah proses yang berkelanjutan. Seiring pertumbuhan data Anda dan evolusi aplikasi Anda, Anda perlu terus memantau dan mengoptimalkan query agar berjalan pada performa terbaik.
Untuk semakin meningkatkan pemahaman Anda tentang SQL, kami mendorong Anda menjelajahi sumber daya berikut di DataCamp:
Pelajari lebih lanjut tentang SQL dengan kursus-kursus ini!
Kursus
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
