
Courses
Xử lý dữ liệu trong SQL
4 giờ
328.2K
SQL là công cụ quan trọng với bất kỳ ai quản lý và thao tác dữ liệu trong các cơ sở dữ liệu quan hệ. Nó cho phép chúng ta tương tác với cơ sở dữ liệu và thực hiện các tác vụ thiết yếu một cách hiệu quả. Khi lượng dữ liệu sẵn có tăng lên mỗi ngày, chúng ta đối mặt với thách thức viết những truy vấn phức tạp để truy xuất dữ liệu đó.
Các truy vấn chậm có thể trở thành nút thắt cổ chai thực sự, ảnh hưởng từ hiệu năng ứng dụng đến trải nghiệm người dùng. Tối ưu hóa truy vấn SQL giúp cải thiện hiệu năng, giảm tiêu thụ tài nguyên và đảm bảo khả năng mở rộng.
Trong bài viết này, chúng ta sẽ xem xét một số kỹ thuật hiệu quả nhất để tối ưu hóa truy vấn SQL. Chúng ta sẽ đi sâu vào lợi ích và hạn chế của từng kỹ thuật để hiểu tác động của chúng đến hiệu năng truy vấn SQL. Hãy bắt đầu!
Hãy tưởng tượng chúng ta tìm một cuốn sách trong thư viện mà không có mục lục. Ta sẽ phải kiểm tra từng kệ, từng hàng cho đến khi tìm thấy. Chỉ mục trong cơ sở dữ liệu tương tự như mục lục. Chúng giúp nhanh chóng định vị dữ liệu cần thiết mà không phải quét toàn bộ bảng.
Chỉ mục là các cấu trúc dữ liệu giúp cải thiện tốc độ truy xuất dữ liệu. Chúng hoạt động bằng cách tạo một bản sao đã được sắp xếp của các cột được lập chỉ mục, cho phép cơ sở dữ liệu nhanh chóng xác định các hàng khớp với truy vấn của chúng ta, tiết kiệm rất nhiều thời gian.
Có ba loại chỉ mục chính trong cơ sở dữ liệu:
Vậy chúng ta có thể dùng chỉ mục để cải thiện hiệu năng truy vấn SQL như thế nào? Dưới đây là một số thực hành tốt:
customer_id hoặc item_id, việc lập chỉ mục cho các cột đó sẽ tác động lớn đến tốc độ. Xem bên dưới cách tạo một chỉ mục:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT, chúng có thể làm chậm nhẹ các thao tác INSERT, UPDATE và DELETE. Lý do là chỉ mục phải được cập nhật mỗi khi bạn sửa đổi dữ liệu. Vì vậy, quá nhiều chỉ mục có thể làm chậm hệ thống do tăng chi phí xử lý cho các lần sửa đổi dữ liệu. Đôi khi, chúng ta có xu hướng dùng SELECT * để lấy tất cả các cột, kể cả những cột không liên quan đến phân tích. Mặc dù có vẻ tiện, nhưng điều này dẫn đến các truy vấn rất kém hiệu quả có thể làm chậm hiệu năng.
Cơ sở dữ liệu phải đọc và truyền nhiều dữ liệu hơn mức cần thiết, đòi hỏi sử dụng bộ nhớ cao hơn vì máy chủ phải xử lý và lưu trữ nhiều thông tin thừa.
Theo thực hành tốt chung, chúng ta chỉ nên chọn các cột cụ thể cần dùng. Giảm thiểu dữ liệu không cần thiết không chỉ giúp mã nguồn gọn gàng, dễ hiểu mà còn tối ưu hiệu năng.
Vì vậy, thay vì viết:
SELECT *
FROM products;Chúng ta nên viết:
SELECT product_id, product_name, product_price
FROM products;Chúng ta vừa thảo luận rằng chỉ chọn các cột liên quan là thực hành tốt để tối ưu truy vấn SQL. Tuy nhiên, việc giới hạn số lượng hàng truy xuất cũng quan trọng không kém, không chỉ là cột. Truy vấn thường chậm lại khi số lượng hàng tăng.
Chúng ta có thể dùng LIMIT để giảm số hàng trả về. Tính năng này giúp tránh việc vô tình lấy hàng nghìn hàng dữ liệu khi ta chỉ cần làm việc với vài hàng.
Hàm LIMIT đặc biệt hữu ích cho các truy vấn kiểm tra/đối chiếu hoặc xem thử đầu ra của một bước chuyển đổi đang thực hiện. Nó lý tưởng cho việc thử nghiệm và hiểu cách mã của chúng ta hoạt động. Tuy nhiên, có thể không phù hợp cho các mô hình dữ liệu tự động, nơi cần trả về toàn bộ tập dữ liệu.
Dưới đây là ví dụ về cách LIMIT hoạt động:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;Khi làm việc với cơ sở dữ liệu quan hệ, dữ liệu thường được tổ chức thành các bảng riêng biệt để tránh dư thừa và tăng hiệu quả. Điều này có nghĩa là chúng ta cần truy xuất dữ liệu từ nhiều nơi và ghép chúng lại để có đầy đủ thông tin cần thiết.
Join cho phép kết hợp các hàng từ hai hoặc nhiều bảng dựa trên một cột liên quan giữa chúng trong một truy vấn, giúp thực hiện các phân tích phức tạp hơn.
Có các loại join khác nhau và chúng ta cần hiểu cách sử dụng. Dùng sai loại join có thể tạo bản ghi trùng lặp trong tập dữ liệu và làm chậm hiệu năng.
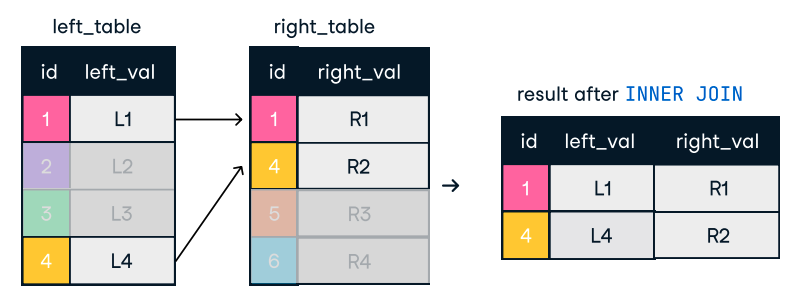
Hình: Inner Join. Nguồn ảnh: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
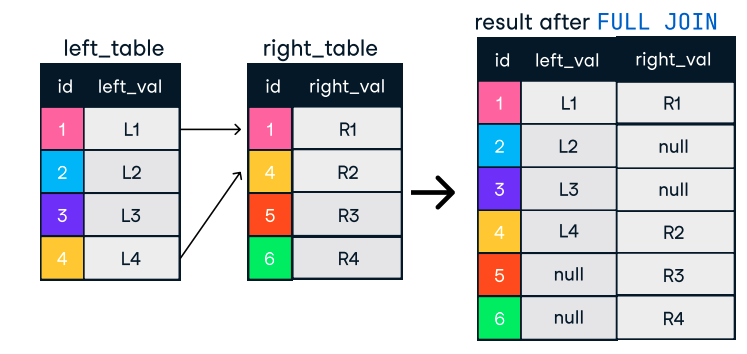
Hình: Outer hoặc Full Join. Nguồn ảnh: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;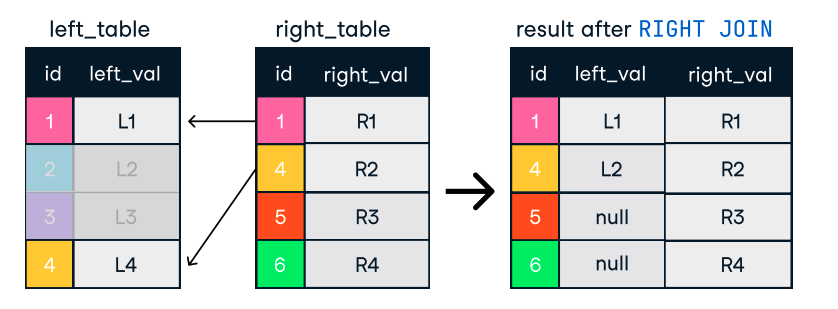
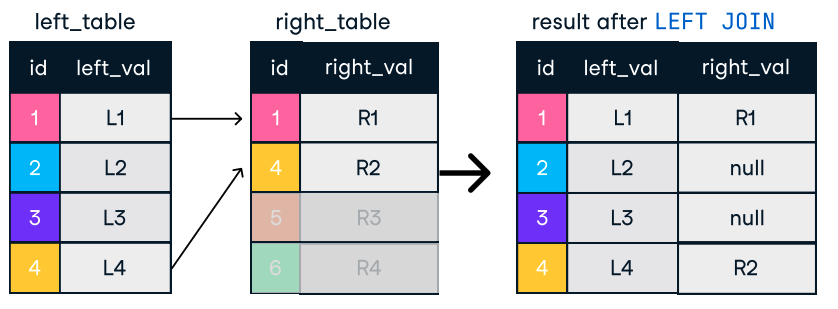
Hình: Left và Right Join. Nguồn ảnh: DataCamp SQL-Join cheat sheet.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Mẹo cho join hiệu quả:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;Phần lớn thời gian, chúng ta chạy truy vấn SQL và chỉ kiểm tra xem đầu ra hoặc kết quả nhận được có đúng như kỳ vọng không. Tuy nhiên, hiếm khi ta tự hỏi điều gì diễn ra phía sau khi thực thi một truy vấn SQL.
Hầu hết cơ sở dữ liệu cung cấp các chức năng như EXPLAIN hoặc EXPLAIN PLAN để trực quan hóa quy trình này. Các kế hoạch này cung cấp phần phân tích chi tiết từng bước về cách cơ sở dữ liệu sẽ truy xuất dữ liệu. Chúng ta có thể dùng tính năng này để xác định nơi có nút thắt hiệu năng và đưa ra quyết định tối ưu truy vấn một cách có cơ sở.
Hãy xem cách dùng EXPLAIN để xác định nút thắt. Chúng ta sẽ chạy đoạn mã sau:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id Sau đó, chúng ta có thể xem xét kết quả:
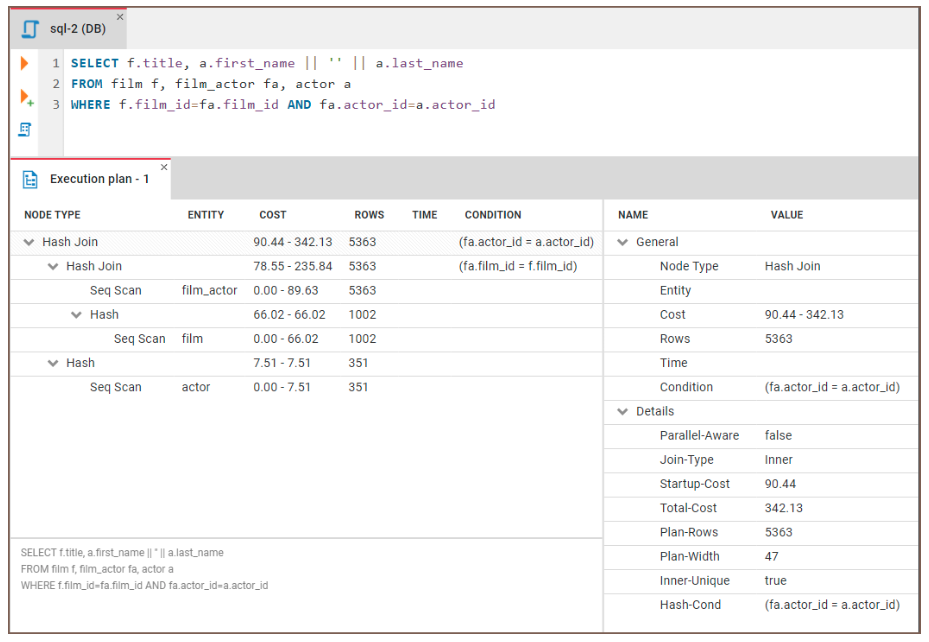
Hình: Ví dụ kế hoạch thực thi truy vấn. Nguồn ảnh: Trang CloudDBeaver.
Một số hướng dẫn chung để diễn giải kết quả:
WHERE kém hiệu quả.Mệnh đề WHERE rất quan trọng trong truy vấn SQL vì cho phép lọc dữ liệu theo điều kiện cụ thể, đảm bảo chỉ trả về các bản ghi liên quan. Nó cải thiện hiệu quả truy vấn bằng cách giảm lượng dữ liệu được xử lý, điều này rất quan trọng khi làm việc với tập dữ liệu lớn.
Vì vậy, một mệnh đề WHERE đúng đắn có thể là đồng minh mạnh mẽ khi tối ưu hiệu năng truy vấn SQL. Dưới đây là một số cách tận dụng mệnh đề này:
WHERE là tốt nhưng chưa đủ. Cần lưu ý vị trí đặt mệnh đề. Loại bỏ càng nhiều hàng càng sớm trong mệnh đề WHERE có thể giúp tối ưu truy vấn.WHERE. Khi áp dụng hàm lên một cột, cơ sở dữ liệu phải áp dụng hàm đó cho mọi hàng trước khi có thể lọc kết quả. Điều này ngăn cản việc sử dụng chỉ mục hiệu quả.Ví dụ, thay vì:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Chúng ta nên dùng:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= thường nhanh hơn LIKE, và sử dụng khoảng ngày cụ thể nhanh hơn dùng các hàm như MONTH(order_date).Vì vậy, ví dụ, thay vì thực hiện truy vấn này:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Chúng ta có thể thực hiện như sau:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';Trong một số trường hợp, khi viết truy vấn, chúng ta muốn linh hoạt lọc, tổng hợp hoặc join dữ liệu ngay trong cùng một truy vấn thay vì chạy nhiều truy vấn riêng lẻ.
Trong những trường hợp đó, chúng ta có thể dùng subquery. Subquery trong SQL là các truy vấn lồng bên trong một truy vấn khác, thường nằm trong các câu lệnh SELECT, INSERT, UPDATE hoặc DELETE.
Subquery có thể mạnh và nhanh, nhưng cũng có thể gây vấn đề hiệu năng nếu không dùng cẩn thận. Nguyên tắc là nên giảm thiểu việc dùng subquery và tuân theo một số thực hành tốt:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Khi làm việc với subquery, chúng ta thường cần kiểm tra một giá trị có tồn tại trong một tập kết quả không. Ta có thể làm điều này bằng IN hoặc EXISTS, nhưng EXISTS thường hiệu quả hơn, đặc biệt với tập dữ liệu lớn.
Mệnh đề IN sẽ đọc toàn bộ kết quả của subquery vào bộ nhớ trước khi so sánh. Ngược lại, EXISTS dừng xử lý subquery ngay khi tìm thấy một khớp.
Ví dụ cách sử dụng mệnh đề này:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Hãy tưởng tượng chúng ta đang làm một phân tích để gửi ưu đãi khuyến mãi tới khách hàng từ các thành phố duy nhất. Cơ sở dữ liệu có nhiều đơn hàng từ cùng khách hàng. Điều đầu tiên nảy ra trong đầu là dùng mệnh đề DISTINCT.
Hàm này hữu ích trong một số trường hợp nhưng có thể tốn tài nguyên, đặc biệt với tập dữ liệu lớn. Có vài lựa chọn thay thế cho DISTINCT:
GROUP BY thay cho DISTINCT khi có thể. GROUP BY có thể hiệu quả hơn, đặc biệt khi kết hợp với các hàm tổng hợp. Vì vậy, thay vì thực hiện:
SELECT DISTINCT city FROM customers;Chúng ta có thể dùng:
SELECT city FROM customers GROUP BY city;ROW_NUMBER có thể giúp xác định và loại bỏ trùng lặp mà không cần dùng DISTINCT.Khi làm việc với dữ liệu, chúng ta tương tác bằng SQL thông qua Hệ quản trị cơ sở dữ liệu (DBMS). DBMS xử lý các lệnh SQL, quản lý cơ sở dữ liệu và đảm bảo tính toàn vẹn, bảo mật dữ liệu. Các hệ thống cơ sở dữ liệu khác nhau cung cấp những tính năng độc đáo có thể giúp tối ưu truy vấn.
Database hint là các hướng dẫn đặc biệt chúng ta có thể thêm vào truy vấn để thực thi hiệu quả hơn. Chúng hữu ích nhưng cần sử dụng thận trọng.
Ví dụ, trong MySQL, hint USE INDEX có thể buộc sử dụng một chỉ mục cụ thể:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;Trong SQL Server, hint OPTION (LOOP JOIN) chỉ định phương thức join:
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Các hint này ghi đè tối ưu hóa truy vấn mặc định, cải thiện hiệu năng trong các kịch bản cụ thể.
Mặt khác, partitioning và sharding là hai kỹ thuật để phân phối dữ liệu trên đám mây.
Giữ cho thống kê của cơ sở dữ liệu luôn cập nhật là quan trọng để bộ tối ưu truy vấn có thể đưa ra quyết định chính xác, sáng suốt về cách thực thi truy vấn hiệu quả nhất.
Thống kê mô tả phân bố dữ liệu trong một bảng (ví dụ: số lượng hàng, tần suất các giá trị và độ phân tán của giá trị qua các cột), và bộ tối ưu dựa vào thông tin này để ước lượng chi phí thực thi truy vấn. Nếu thống kê lỗi thời, bộ tối ưu có thể chọn kế hoạch thực thi kém hiệu quả, như dùng sai chỉ mục hoặc chọn quét toàn bảng thay vì quét theo chỉ mục hiệu quả hơn, dẫn đến hiệu năng truy vấn kém.
Nhiều cơ sở dữ liệu hỗ trợ cập nhật tự động để duy trì thống kê chính xác. Chẳng hạn, trong SQL Server, cấu hình mặc định sẽ tự động cập nhật thống kê khi có lượng dữ liệu thay đổi đáng kể. Tương tự, PostgreSQL có tính năng auto-analyze, cập nhật thống kê sau khi vượt một ngưỡng thay đổi dữ liệu nhất định.
Tuy nhiên, chúng ta có thể cập nhật thủ công trong trường hợp cập nhật tự động chưa đủ hoặc cần can thiệp thủ công. Trong SQL Server, có thể dùng lệnh UPDATE STATISTICS để làm mới thống kê cho một bảng hoặc chỉ mục cụ thể, trong khi ở PostgreSQL, có thể chạy lệnh ANALYZE để cập nhật thống kê cho một hoặc nhiều bảng.
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;Stored procedure là tập lệnh SQL được lưu trong cơ sở dữ liệu để chúng ta không phải viết đi viết lại cùng một SQL. Có thể hình dung nó như một kịch bản tái sử dụng.
Khi cần thực hiện một tác vụ nhất định, như cập nhật bản ghi hoặc tính toán giá trị, chúng ta chỉ cần gọi stored procedure. Nó có thể nhận đầu vào, thực hiện công việc như truy vấn hoặc sửa đổi dữ liệu và thậm chí trả về kết quả. Stored procedure giúp tăng tốc vì SQL được biên dịch sẵn, khiến mã của bạn gọn gàng và dễ quản lý hơn.
Chúng ta có thể tạo stored procedure trong PostgreSQL như sau:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');Là người làm dữ liệu, chúng ta thích dữ liệu được sắp xếp và nhóm để rút ra thông tin dễ dàng hơn. Ta thường dùng ORDER BY và GROUP BY trong các truy vấn SQL.
Tuy nhiên, cả hai mệnh đề này đều tốn tài nguyên tính toán, đặc biệt khi xử lý tập dữ liệu lớn. Khi sắp xếp hoặc tổng hợp dữ liệu, bộ máy cơ sở dữ liệu thường phải quét toàn bộ dữ liệu rồi sắp xếp, xác định nhóm và/hoặc áp dụng các hàm tổng hợp, thường dùng các thuật toán tiêu tốn tài nguyên.
Để tối ưu truy vấn, chúng ta có thể làm theo một số gợi ý:
ORDER BY khi cần thiết. Nếu việc sắp xếp không quan trọng, loại bỏ mệnh đề này có thể giúp giảm đáng kể thời gian xử lý. ORDER BY và GROUP BY được lập chỉ mục. GROUP BY, chúng ta có thể tổng hợp dữ liệu từ sớm hoặc trong materialized view, để cơ sở dữ liệu không phải tính đi tính lại cùng các phép tổng hợp.Khi muốn kết hợp kết quả từ nhiều truy vấn thành một danh sách, chúng ta có thể dùng các mệnh đề UNION và UNION ALL. Cả hai đều kết hợp kết quả của hai hoặc nhiều câu lệnh SELECT khi chúng có cùng tên cột. Tuy nhiên, chúng không giống nhau và sự khác biệt khiến chúng phù hợp cho các trường hợp sử dụng khác nhau.
Mệnh đề UNION loại bỏ các hàng trùng lặp, điều này đòi hỏi thời gian xử lý nhiều hơn.
Hình: Union trong SQL. Nguồn ảnh: DataCamp SQL-Join cheat sheet.
Ngược lại, UNION ALL kết hợp kết quả nhưng giữ tất cả các hàng, bao gồm cả trùng lặp. Vì vậy, nếu không cần loại bỏ trùng lặp, chúng ta nên dùng UNION ALL để có hiệu năng tốt hơn.
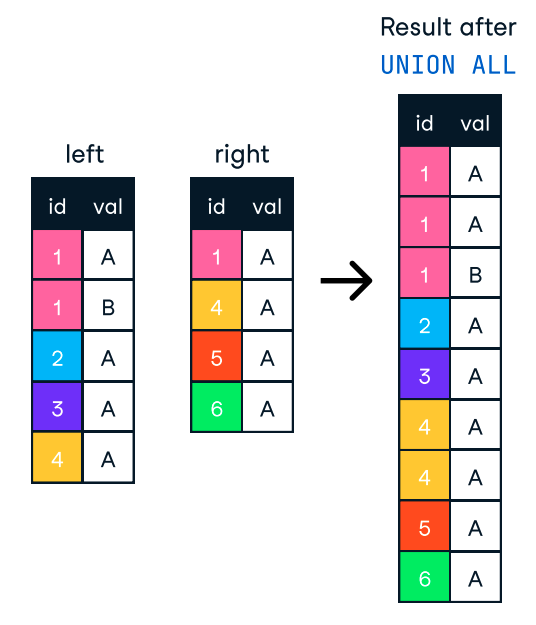
Hình: UNION ALL trong SQL. Nguồn ảnh: DataCamp SQL-Join cheat sheet.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Làm việc với các tập dữ liệu lớn đồng nghĩa với việc chúng ta sẽ thường xuyên gặp các truy vấn phức tạp khó hiểu và khó tối ưu. Chúng ta có thể xử lý chúng bằng cách chia nhỏ thành các truy vấn nhỏ, đơn giản hơn. Bằng cách này, ta dễ dàng xác định các nút thắt hiệu năng và áp dụng kỹ thuật tối ưu.
Một trong những chiến lược được dùng thường xuyên để chia nhỏ truy vấn là materialized view. Đây là kết quả truy vấn được tính sẵn và lưu trữ, có thể truy cập nhanh thay vì phải tính lại mỗi lần tham chiếu. Khi dữ liệu nền thay đổi, materialized view phải được làm mới thủ công hoặc tự động.
Ví dụ cách tạo và truy vấn một materialized view:
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;Trong bài viết này, chúng ta đã khám phá các chiến lược và thực hành tốt để tối ưu truy vấn SQL, từ lập chỉ mục và join đến subquery và các tính năng đặc thù của hệ quản trị. Áp dụng những kỹ thuật này, bạn có thể cải thiện đáng kể hiệu năng truy vấn và giúp cơ sở dữ liệu vận hành hiệu quả hơn.
Hãy nhớ rằng tối ưu truy vấn SQL là một quá trình liên tục. Khi dữ liệu tăng và ứng dụng phát triển, bạn sẽ cần liên tục giám sát và tối ưu các truy vấn để đảm bảo chúng chạy ở hiệu năng tối ưu.
Để nâng cao hiểu biết về SQL, chúng tôi khuyến khích bạn khám phá các tài nguyên sau trên DataCamp:
Tìm hiểu thêm về SQL với các khóa học này!
Courses
Courses
Courses