
Corso
Manipolazione dei dati in SQL
4 h
328.2K
SQL è uno strumento fondamentale per chiunque gestisca e manipoli dati all'interno di database relazionali. Ci permette di interagire con i database ed eseguire attività essenziali in modo efficiente. Con la quantità di dati disponibili in crescita ogni giorno, ci troviamo ad affrontare la sfida di scrivere query complesse per recuperarli.
Le query lente possono essere un vero collo di bottiglia, con impatti che vanno dalle prestazioni dell’applicazione all’esperienza utente. Ottimizzare le query SQL migliora le prestazioni, riduce il consumo di risorse e garantisce scalabilità.
In questo articolo vedremo alcune delle tecniche più efficaci per ottimizzare le nostre query SQL. Approfondiremo vantaggi e svantaggi di ciascuna tecnica per capirne l’impatto sulle prestazioni delle query. Iniziamo!
Immagina di cercare un libro in una biblioteca senza catalogo. Dovresti controllare ogni scaffale e ogni ripiano finché non lo trovi. Gli indici in un database sono simili ai cataloghi. Ci aiutano a trovare rapidamente i dati di cui abbiamo bisogno senza scansionare l’intera tabella.
Gli indici sono strutture dati che migliorano la velocità di recupero dei dati. Creano una copia ordinata delle colonne indicizzate, consentendo al database di individuare rapidamente le righe che corrispondono alla nostra query, facendoci risparmiare molto tempo.
Esistono tre tipi principali di indici nei database:
Come possiamo usare gli indici per migliorare le prestazioni delle query SQL? Vediamo alcune best practice:
customer_id o item_id, indicizzare queste colonne avrà un grande impatto sulla velocità. Di seguito come creare un indice:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT, possono rallentare leggermente le operazioni INSERT, UPDATE e DELETE. Questo perché l’indice va aggiornato ogni volta che modifichi i dati. Troppi indici possono quindi rallentare le cose aumentando l’overhead sulle modifiche ai dati. A volte siamo tentati di usare SELECT * per prendere tutte le colonne, anche quelle che non sono rilevanti per la nostra analisi. Anche se può sembrare comodo, porta a query molto inefficienti che possono rallentare le prestazioni.
Il database deve leggere e trasferire più dati del necessario, richiedendo più memoria poiché il server deve elaborare e memorizzare più informazioni del dovuto.
Come regola generale, dovremmo selezionare solo le colonne specifiche di cui abbiamo bisogno. Ridurre i dati superflui non solo mantiene il codice pulito e facile da capire, ma aiuta anche a ottimizzare le prestazioni.
Quindi, invece di scrivere:
SELECT *
FROM products;Dovremmo scrivere:
SELECT product_id, product_name, product_price
FROM products;Abbiamo appena detto che selezionare solo le colonne rilevanti è una best practice per ottimizzare le query SQL. Tuttavia, è anche importante limitare il numero di righe che stiamo recuperando, non solo le colonne. Le query di solito rallentano quando aumenta il numero di righe.
Possiamo usare LIMIT per ridurre il numero di righe restituite. Questa funzionalità impedisce di recuperare involontariamente migliaia di righe quando ci serve lavorare solo con poche.
La funzione LIMIT è particolarmente utile per query di validazione o per ispezionare l’output di una trasformazione su cui stiamo lavorando. È ideale per sperimentare e capire come si comporta il nostro codice. Tuttavia, potrebbe non essere adatta a modelli di dati automatizzati, dove dobbiamo restituire l’intero dataset.
Ecco un esempio di come funziona LIMIT:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;Quando lavoriamo con database relazionali, i dati sono spesso organizzati in tabelle separate per evitare ridondanze e migliorare l’efficienza. Questo significa però che dobbiamo recuperare dati da punti diversi e unirli per ottenere tutte le informazioni rilevanti di cui abbiamo bisogno.
I join ci permettono di combinare, in un’unica query, righe provenienti da due o più tabelle in base a una colonna correlata tra di esse, rendendo possibili analisi più complesse.
Esistono diversi tipi di join e dobbiamo sapere come usarli. Usare il join sbagliato può creare duplicati nel dataset e rallentarlo.
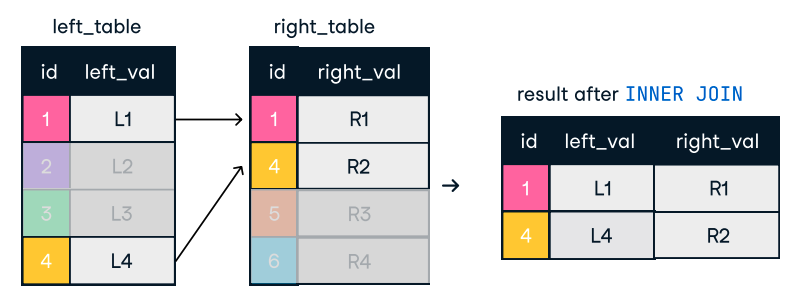
Figura: Inner Join. Fonte immagine: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
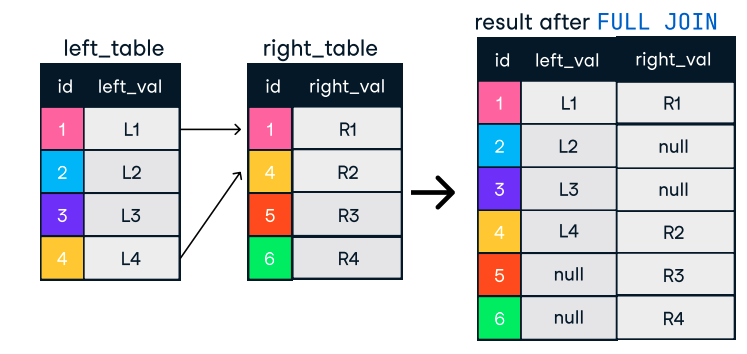
Figura: Outer o Full Join. Fonte immagine: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;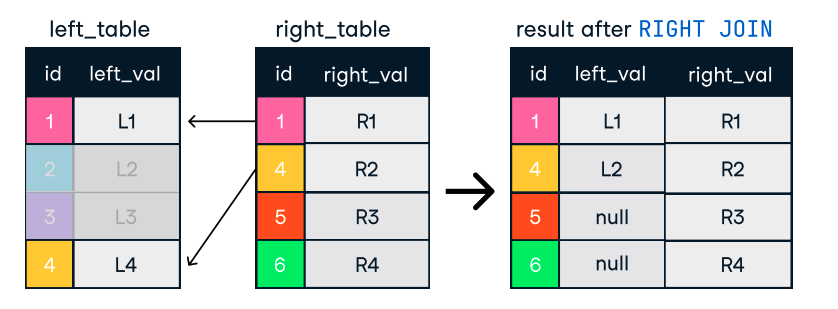
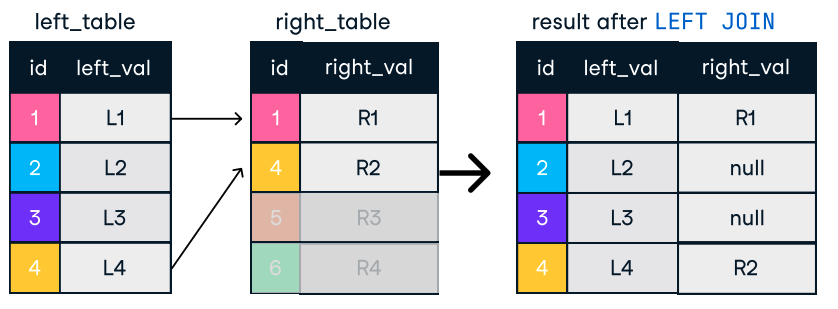
Figura: Left e Right Join. Fonte immagine: DataCamp SQL-Join cheat sheet.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Consigli per join efficienti:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;Molto spesso eseguiamo query SQL e controlliamo solo che l’output o il risultato recuperato sia quello atteso. Raramente però ci chiediamo cosa succede dietro le quinte quando eseguiamo una query SQL.
La maggior parte dei database fornisce funzioni come EXPLAIN o EXPLAIN PLAN per visualizzare questo processo. Questi piani offrono una scomposizione passo passo di come il database recupererà i dati. Possiamo usare questa funzione per identificare i colli di bottiglia delle prestazioni e prendere decisioni informate su come ottimizzare le query.
Vediamo come usare EXPLAIN per individuare i colli di bottiglia. Eseguiremo il seguente codice:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id Possiamo quindi esaminare i risultati:
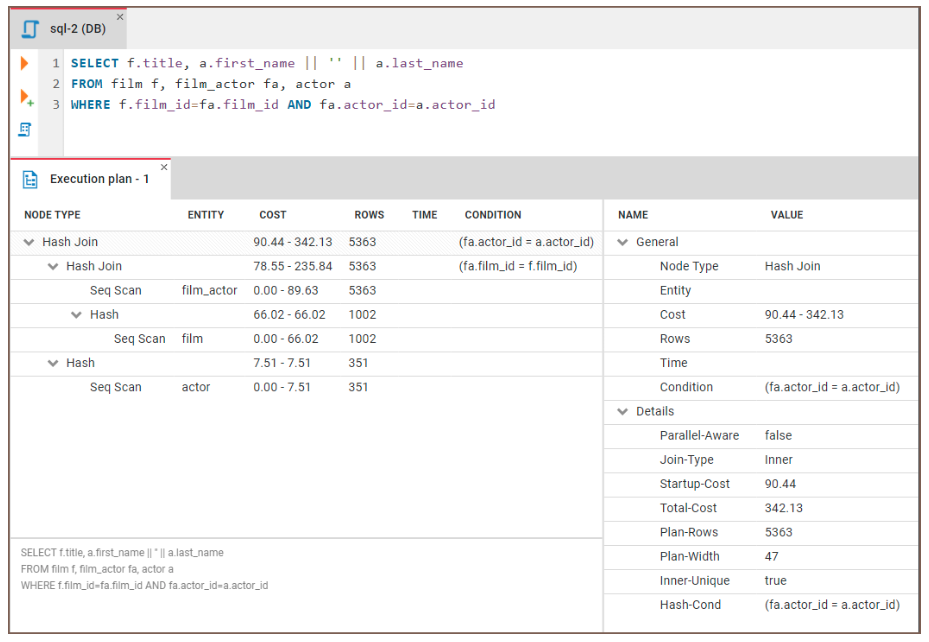
Figura: Un esempio di piano di esecuzione di una query. Fonte immagine: sito CloudDBeaver.
Ecco alcune linee guida generali per interpretare i risultati:
WHERE inefficiente.La clausola WHERE è fondamentale nelle query SQL perché ci permette di filtrare i dati in base a condizioni specifiche, assicurando che vengano restituite solo le righe rilevanti. Migliora l’efficienza delle query riducendo la quantità di dati elaborati, aspetto molto importante quando si lavora con dataset di grandi dimensioni.
Una WHERE ben scritta può quindi essere un’alleata potente quando ottimizziamo le prestazioni di una query SQL. Vediamo alcuni modi per sfruttarla al meglio:
WHERE è utile ma non basta. Bisogna fare attenzione a dove viene posizionata. Filtrare il maggior numero possibile di righe all’inizio della WHERE può aiutare a ottimizzare la query.WHERE. Quando applichiamo una funzione a una colonna, il database deve applicarla a ogni riga della tabella prima di poter filtrare i risultati. Questo impedisce l’uso efficace degli indici.Per esempio, invece di:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Dovremmo usare:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= è generalmente più veloce di LIKE e usare intervalli di date specifici è più veloce che usare funzioni come MONTH(order_date).Quindi, ad esempio, invece di eseguire questa query:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Possiamo eseguire la seguente:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';In alcuni casi, mentre scriviamo una query, sentiamo il bisogno di applicare dinamicamente filtri, aggregazioni o join sui dati. Non vogliamo fare più query; preferiamo mantenerne una sola.
Per questi casi possiamo usare le sottoquery. Le sottoquery in SQL sono query annidate all’interno di un’altra query, in genere nelle istruzioni SELECT, INSERT, UPDATE o DELETE.
Le sottoquery possono essere potenti e veloci, ma possono anche causare problemi di prestazioni se non usate con attenzione. In generale, dovremmo minimizzare l’uso delle sottoquery e seguire alcune best practice:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Quando lavoriamo con sottoquery, spesso dobbiamo verificare se un valore esiste in un insieme di risultati. Possiamo farlo con IN o EXISTS, ma EXISTS è in genere più efficiente, soprattutto su dataset di grandi dimensioni.
La clausola IN legge l’intero risultato della sottoquery in memoria prima del confronto. Al contrario, EXISTS interrompe l’elaborazione della sottoquery non appena trova una corrispondenza.
Ecco un esempio di come usare questa clausola:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Immagina di lavorare a un’analisi per inviare un’offerta promozionale a clienti di città uniche. Il database contiene più ordini degli stessi clienti. La prima cosa che ci viene in mente è usare la clausola DISTINCT.
Questa funzione è utile in certi casi ma può essere dispendiosa in termini di risorse, soprattutto su dataset grandi. Esistono alcune alternative a DISTINCT:
GROUP BY al posto di DISTINCT quando possibile. GROUP BY può essere più efficiente, soprattutto se combinato con funzioni di aggregazione. Quindi, invece di eseguire:
SELECT DISTINCT city FROM customers;Possiamo usare:
SELECT city FROM customers GROUP BY city;ROW_NUMBER possono aiutarci a identificare i duplicati e filtrarli senza usare DISTINCT.Quando lavoriamo con i dati, interagiamo tramite SQL attraverso un sistema di gestione del database (DBMS). Il DBMS elabora i comandi SQL, gestisce il database e garantisce integrità e sicurezza dei dati. I diversi sistemi di database offrono funzionalità uniche che possono aiutare a ottimizzare le query.
Gli hint del database sono istruzioni speciali che possiamo aggiungere alle query per eseguirle in modo più efficiente. Sono uno strumento utile, ma vanno usati con cautela.
Ad esempio, in MySQL, l’hint USE INDEX può forzare l’uso di un indice specifico:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;In SQL Server, l’hint OPTION (LOOP JOIN) specifica il metodo di join:
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Questi hint sovrascrivono l’ottimizzazione predefinita delle query, migliorando le prestazioni in scenari specifici.
D’altra parte, partizionamento e sharding sono due tecniche per distribuire i dati nel cloud.
Mantenere aggiornate le statistiche del database è importante per fare in modo che l’ottimizzatore di query possa prendere decisioni informate e accurate sul modo più efficiente di eseguire le query.
Le statistiche descrivono la distribuzione dei dati in una tabella (ad esempio, il numero di righe, la frequenza dei valori e la loro distribuzione tra le colonne) e l’ottimizzatore si basa su queste informazioni per stimare i costi di esecuzione. Se le statistiche non sono aggiornate, l’ottimizzatore può scegliere piani di esecuzione inefficienti, come usare gli indici sbagliati o optare per una scansione completa invece di una più efficiente scansione tramite indice, con conseguenti scarse prestazioni delle query.
I database spesso supportano aggiornamenti automatici per mantenere statistiche accurate. Ad esempio, in SQL Server, la configurazione predefinita aggiorna automaticamente le statistiche quando cambia una quantità significativa di dati. Allo stesso modo, PostgreSQL ha una funzionalità di auto-analyze, che aggiorna le statistiche dopo una soglia specificata di modifiche ai dati.
Tuttavia, possiamo aggiornare manualmente le statistiche nei casi in cui gli aggiornamenti automatici non bastano o se è necessario un intervento manuale. In SQL Server, possiamo usare il comando UPDATE STATISTICS per aggiornare le statistiche di una specifica tabella o indice, mentre in PostgreSQL si può eseguire il comando ANALYZE per aggiornare le statistiche di una o più tabelle.
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;Una stored procedure è un insieme di comandi SQL che salviamo nel database, così non dobbiamo riscrivere ogni volta lo stesso SQL. Possiamo pensarla come a uno script riutilizzabile.
Quando dobbiamo eseguire un certo compito, come aggiornare record o calcolare valori, richiamiamo la stored procedure. Può accettare input, eseguire operazioni come interrogare o modificare dati e persino restituire un risultato. Le stored procedure accelerano le operazioni poiché l’SQL è precompilato, rendendo il codice più pulito e facile da gestire.
Possiamo creare una stored procedure in PostgreSQL come segue:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');Come professionisti dei dati, ci piace avere i dati ordinati e raggruppati per ricavarne insight più facilmente. In SQL usiamo spesso ORDER BY e GROUP BY.
Tuttavia, entrambe le clausole possono essere costose dal punto di vista computazionale, soprattutto con dataset grandi. Quando ordina o aggrega i dati, il motore del database spesso deve eseguire una scansione completa e poi organizzarli, identificare i gruppi e/o applicare funzioni di aggregazione, tipicamente usando algoritmi ad alta intensità di risorse.
Per ottimizzare le query, possiamo seguire alcuni suggerimenti:
ORDER BY solo quando necessario. Se l’ordinamento non è essenziale, omettere questa clausola può ridurre drasticamente i tempi di elaborazione. ORDER BY e GROUP BY siano indicizzate. GROUP BY, possiamo pre-aggregare i dati in una fase precedente o in una vista materializzata, in modo che il database non debba ricalcolare ogni volta le stesse aggregazioni.Quando vogliamo combinare i risultati di più query in un unico elenco, possiamo usare le clausole UNION e UNION ALL. Entrambe combinano i risultati di due o più istruzioni SELECT con gli stessi nomi di colonna. Tuttavia, non sono identiche e la loro differenza le rende adatte a casi d’uso diversi.
La clausola UNION rimuove le righe duplicate, cosa che richiede più tempo di elaborazione.
Figura: Union in SQL. Source immagine: DataCamp SQL-Join cheat sheet.
D’altra parte, UNION ALL combina i risultati ma mantiene tutte le righe, inclusi i duplicati. Quindi, se non serve rimuovere duplicati, è meglio usare UNION ALL per prestazioni migliori.
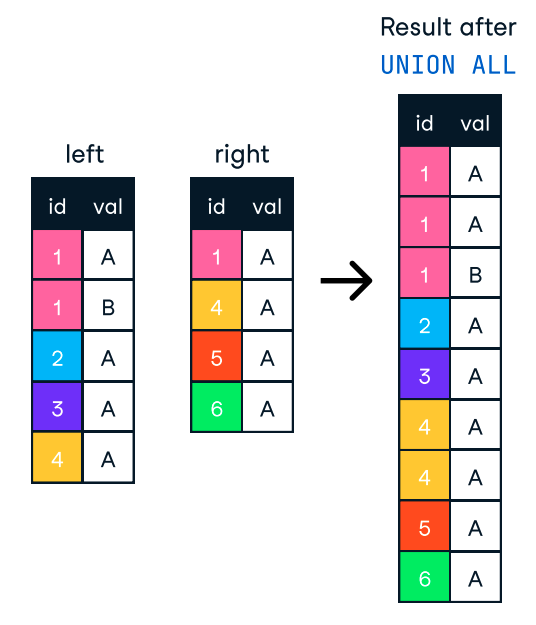
Figura: UNION ALL in SQL. Source immagine: DataCamp SQL-Join cheat sheet.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Lavorare con dataset di grandi dimensioni implica che spesso incontreremo query complesse difficili da comprendere e ottimizzare. Possiamo affrontare questi casi scomponendole in query più piccole e semplici. In questo modo è più facile individuare i colli di bottiglia e applicare tecniche di ottimizzazione.
Una delle strategie più usate per scomporre le query è ricorrere alle viste materializzate. Si tratta di risultati di query precomputati e memorizzati, accessibili rapidamente senza ricalcolare la query ogni volta che viene richiamata. Quando i dati sottostanti cambiano, la vista materializzata deve essere aggiornata manualmente o automaticamente.
Ecco un esempio di come creare e interrogare una vista materializzata:
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;In questo articolo abbiamo esplorato diverse strategie e best practice per ottimizzare le query SQL, dall’indicizzazione ai join, fino a sottoquery e funzionalità specifiche dei database. Applicando queste tecniche, puoi migliorare sensibilmente le prestazioni delle tue query e far funzionare i database in modo più efficiente.
Ricorda che ottimizzare le query SQL è un processo continuo. Man mano che i tuoi dati crescono e l’applicazione evolve, dovrai monitorare e ottimizzare costantemente le query per garantire prestazioni ottimali.
Per approfondire la tua conoscenza di SQL, ti invitiamo a esplorare le seguenti risorse su DataCamp:
Approfondisci SQL con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

