
Cursus
Gegevens manipuleren in SQL
4 Hr
328.2K
SQL is een belangrijk hulpmiddel voor iedereen die data beheert en bewerkt in relationele databases. Het stelt ons in staat met databases te werken en essentiële taken efficiënt uit te voeren. Nu de hoeveelheid beschikbare data dagelijks groeit, staan we voor de uitdaging om complexe queries te schrijven om die data op te halen.
Trage queries kunnen een flinke bottleneck zijn en alles beïnvloeden: van applicatieprestaties tot gebruikerservaring. Het optimaliseren van SQL-queries verbetert de prestaties, vermindert het verbruik van resources en zorgt voor schaalbaarheid.
In dit artikel bekijken we enkele van de meest effectieve technieken om onze SQL-queries te optimaliseren. We duiken in de voor- en nadelen van elke techniek om hun impact op de performance van SQL-queries te begrijpen. Laten we beginnen!
Stel je voor dat we in een bibliotheek een boek zoeken zonder catalogus. We zouden elke plank en elke rij moeten nalopen tot we het eindelijk vinden. Indexen in een database zijn vergelijkbaar met catalogi. Ze helpen ons de data die we nodig hebben snel te vinden zonder de hele tabel te scannen.
Indexen zijn datastructuren die de snelheid van het ophalen van data verbeteren. Ze doen dit door een gesorteerde kopie van de geïndexeerde kolommen te maken, waardoor de database snel de rijen kan vinden die aan onze query voldoen. Dat scheelt veel tijd.
Er zijn drie hoofdtypen indexen in databases:
Hoe kunnen we indexen gebruiken om de prestaties van SQL-queries te verbeteren? Hier zijn enkele best practices:
customer_id of item_id, dan zal het indexeren van die kolommen de snelheid sterk beïnvloeden. Zie hieronder hoe je een index maakt:CREATE INDEX index_customer_id ON customers (customer_id);
SELECT-queries te versnellen, kunnen ze INSERT-, UPDATE- en DELETE-bewerkingen iets vertragen. Dat komt omdat de index elke keer moet worden bijgewerkt wanneer je data wijzigt. Te veel indexen kunnen zaken dus vertragen door extra overhead bij datamodificaties. Soms zijn we geneigd SELECT * te gebruiken om alle kolommen op te halen, ook die niet relevant zijn voor onze analyse. Hoewel dat handig lijkt, leidt het tot zeer inefficiënte queries die de prestaties kunnen vertragen.
De database moet meer data lezen en overdragen dan nodig is, wat meer geheugen vereist omdat de server meer informatie moet verwerken en opslaan dan nodig.
Als algemene best practice selecteren we alleen de specifieke kolommen die we nodig hebben. Het minimaliseren van onnodige data houdt onze code niet alleen schoon en begrijpelijk, maar helpt ook de prestaties te optimaliseren.
Dus in plaats van te schrijven:
SELECT *
FROM products;Schrijven we beter:
SELECT product_id, product_name, product_price
FROM products;We hebben net besproken dat het selecteren van alleen relevante kolommen een best practice is om SQL-queries te optimaliseren. Het is echter ook belangrijk het aantal rijen dat we ophalen te beperken, niet alleen kolommen. Queries vertragen meestal wanneer het aantal rijen toeneemt.
We kunnen LIMIT gebruiken om het aantal geretourneerde rijen te verminderen. Deze functie voorkomt dat we onbedoeld duizenden rijen ophalen terwijl we er maar een paar nodig hebben.
De functie LIMIT is vooral handig voor validatiequeries of het inspecteren van de output van een transformatie waar we aan werken. Ideaal voor experimenteren en begrijpen hoe onze code zich gedraagt. Het is echter mogelijk ongeschikt voor geautomatiseerde datamodellen, waarbij we de volledige dataset moeten retourneren.
Hier is een voorbeeld van hoe LIMIT werkt:
SELECT name
FROM customers
ORDER BY customer_group DESC
LIMIT 100;Bij het werken met relationele databases is data vaak verdeeld over aparte tabellen om redundantie te voorkomen en efficiëntie te verbeteren. Dat betekent echter dat we data uit verschillende plaatsen moeten ophalen en samenvoegen om alle benodigde informatie te krijgen.
Joins stellen ons in staat om rijen uit twee of meer tabellen te combineren op basis van een gerelateerde kolom binnen één query, zodat we complexere analyses kunnen uitvoeren.
Er zijn verschillende typen joins, en we moeten begrijpen hoe we ze gebruiken. De verkeerde join kan duplicaten in onze dataset creëren en die vertragen.
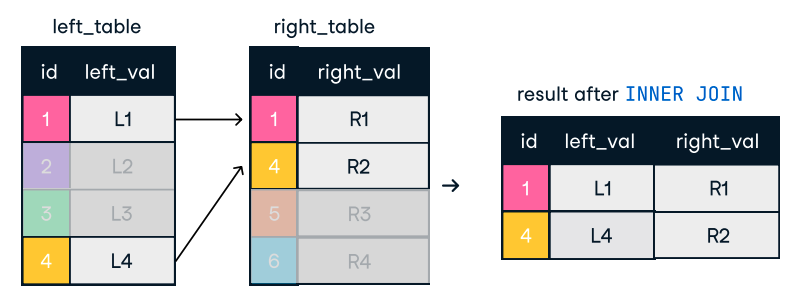
Figuur: Inner join. Afbeeldingsbron: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
INNER JOIN customers c ON o.customer_id = c.customer_id;
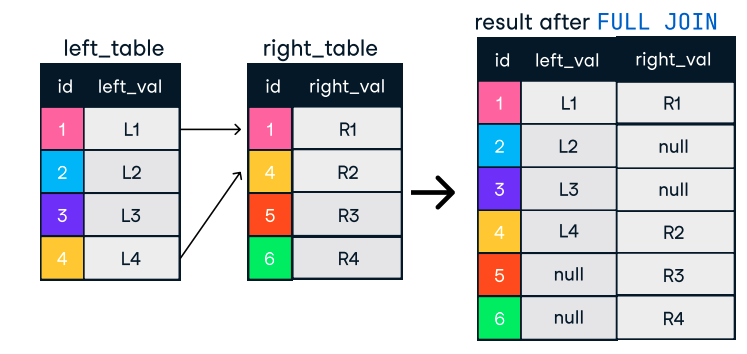
Figuur: Outer of full join. Afbeeldingsbron: DataCamp SQL-Join cheat sheet.
SELECT o.order_id, c.name
FROM orders o
FULL OUTER JOIN customers c ON o.customer_id = c.customer_id;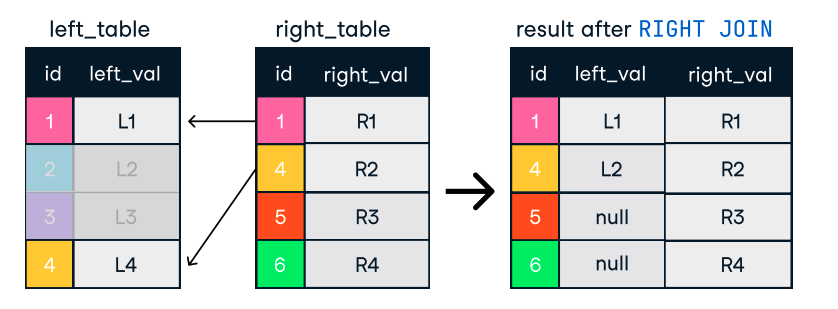
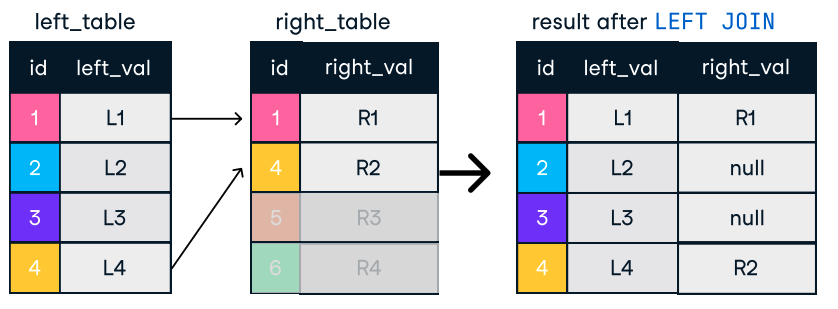
Figuur: Left en right join. Afbeeldingsbron: DataCamp SQL-Join cheat sheet.
SELECT c.name, o.order_id
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id;Tips voor efficiënte joins:
WITH RecentOrders AS (
SELECT customer_id, order_id
FROM orders
WHERE order_date >= DATE('now', '-30 days')
)
SELECT c.customer_name, ro.order_id
FROM customers c
INNER JOIN RecentOrders ro ON c.customer_id = ro.customer_id;Meestal voeren we SQL-queries uit en controleren we alleen of de output is wat we verwachtten. We vragen ons echter zelden af wat er achter de schermen gebeurt wanneer we een SQL-query uitvoeren.
De meeste databases bieden functies zoals EXPLAIN of EXPLAIN PLAN om dit proces te visualiseren. Deze plannen geven stap voor stap weer hoe de database de data zal ophalen. We kunnen deze functie gebruiken om te identificeren waar de bottlenecks zitten en weloverwogen beslissingen te nemen over het optimaliseren van onze queries.
Laten we zien hoe we EXPLAIN kunnen gebruiken om bottlenecks te identificeren. We voeren de volgende code uit:
EXPLAIN SELECT f.title, a.actor_name
FROM film f, film_actor fa, actor a
WHERE f.film_id = fa.film_id and fa.actor_id = a.id Vervolgens kunnen we de resultaten onderzoeken:
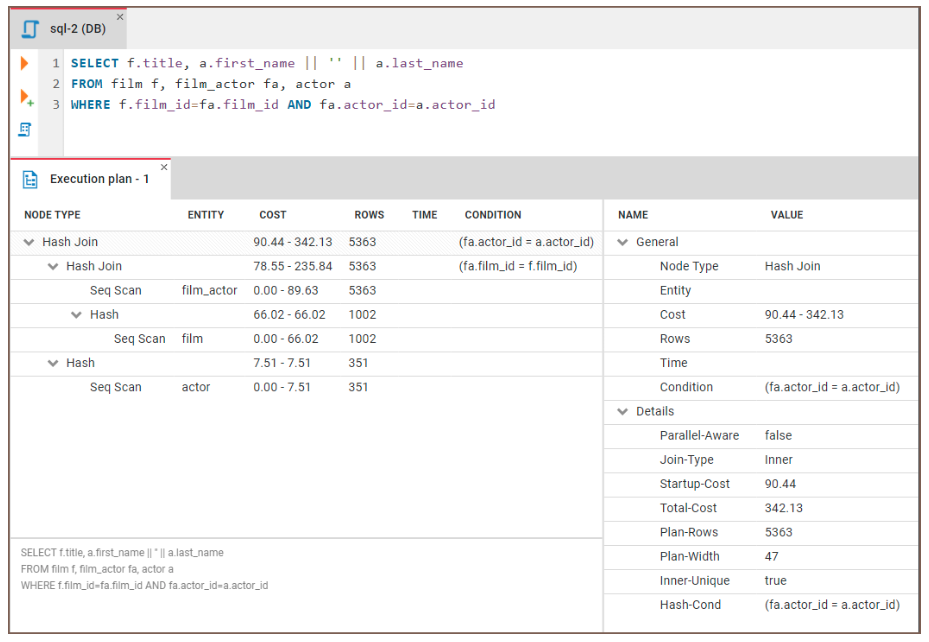
Figuur: Een voorbeeld van een query-uitvoeringsplan. Afbeeldingsbron: CloudDBeaver-website.
Hier is algemene richtlijn over hoe je de resultaten interpreteert:
WHERE-clausule.De WHERE-clausule is essentieel in SQL-queries omdat we hiermee data kunnen filteren op basis van specifieke voorwaarden, zodat alleen relevante records worden geretourneerd. Dit verbetert de efficiëntie doordat minder data wordt verwerkt, wat erg belangrijk is bij grote datasets.
Een juiste WHERE-clausule kan dus een krachtig hulpmiddel zijn bij het optimaliseren van de performance van een SQL-query. Enkele manieren waarop we hiervan kunnen profiteren:
WHERE-clausule goed maar niet genoeg. We moeten opletten waar we de clausule plaatsen. Zo veel mogelijk rijen vroeg in de WHERE-clausule wegfilteren kan helpen de query te optimaliseren.WHERE-clausule. Als we een functie op een kolom toepassen, moet de database die functie op elke rij in de tabel toepassen voordat hij kan filteren. Dit verhindert effectief indexgebruik.Bijvoorbeeld, in plaats van:
SELECT *
FROM employees WHERE
YEAR(hire_date) = 2020;Gebruiken we beter:
SELECT *
FROM employees
WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01';= doorgaans sneller dan LIKE, en specifieke datumbereiken zijn sneller dan functies zoals MONTH(order_date).Dus, in plaats van deze query uit te voeren:
SELECT *
FROM orders
WHERE MONTH(order_date) = 12 AND YEAR(order_date) = 2023;Kunnen we het volgende doen:
SELECT *
FROM orders
WHERE order_date >= '2023-12-01' AND order_date < '2024-01-01';In sommige gevallen schrijven we een query en voelen we dat we dynamisch moeten filteren, aggregeren of data joinen. We willen geen meerdere queries doen; we willen het bij één query houden.
Voor die gevallen kunnen we subquery’s gebruiken. Subquery’s in SQL zijn queries die genest zijn in een andere query, meestal in de SELECT-, INSERT-, UPDATE- of DELETE-statements.
Subquery’s kunnen krachtig en snel zijn, maar ook performanceproblemen veroorzaken als ze niet zorgvuldig worden gebruikt. In het algemeen minimaliseren we het gebruik van subquery’s en volgen we een aantal best practices:
WITH SalesCTE AS (
SELECT salesperson_id, SUM(sales_amount) AS total_sales
FROM sales GROUP BY salesperson_id )
SELECT salesperson_id, total_sales
FROM SalesCTE WHERE total_sales > 5000;Bij het werken met subquery’s moeten we vaak controleren of een waarde in een set resultaten voorkomt. Dat kan met IN of EXISTS, maar EXISTS is over het algemeen efficiënter, vooral bij grotere datasets.
De IN-clausule leest de volledige set subqueryresultaten in het geheugen voordat hij vergelijkt. De EXISTS-clausule stopt daarentegen met verwerken zodra er een match is gevonden.
Hier is een voorbeeld van hoe je deze clausule gebruikt:
SELECT *
FROM orders o
WHERE EXISTS (SELECT 1 FROM customers c WHERE c.customer_id = o.customer_id AND c.country = 'USA');Stel dat we werken aan een analyse om een promotionele aanbieding te sturen naar klanten uit unieke steden. De database bevat meerdere bestellingen van dezelfde klanten. Het eerste waar we aan denken is de DISTINCT-clausule.
Deze functie is handig in bepaalde gevallen, maar kan veel resources vergen, vooral bij grote datasets. Er zijn een paar alternatieven voor DISTINCT:
GROUP BY in plaats van DISTINCT waar mogelijk. GROUP BY kan efficiënter zijn, vooral in combinatie met aggregatiefuncties. Dus in plaats van:
SELECT DISTINCT city FROM customers;Kunnen we gebruiken:
SELECT city FROM customers GROUP BY city;ROW_NUMBER kunnen ons helpen duplicaten te identificeren en te filteren zonder DISTINCT te gebruiken.Wanneer we met data werken, doen we dat met SQL via een Database Management System (DBMS). Het DBMS verwerkt de SQL-commando’s, beheert de database en zorgt voor dataintegriteit en -beveiliging. Verschillende databasesystemen bieden unieke features die kunnen helpen bij het optimaliseren van queries.
Databasehints zijn speciale instructies die we aan onze queries kunnen toevoegen om een query efficiënter uit te voeren. Ze zijn nuttig, maar moeten met voorzichtigheid gebruikt worden.
In MySQL kan de hint USE INDEX het gebruik van een specifieke index afdwingen:
SELECT * FROM employees USE INDEX (idx_salary) WHERE salary > 50000;In SQL Server specificeert de hint OPTION (LOOP JOIN) de joinmethode:
SELECT *
FROM orders
INNER JOIN customers ON orders.customer_id = customers.id OPTION (LOOP JOIN); Deze hints overschrijven de standaard query-optimalisatie en kunnen de prestaties in specifieke scenario’s verbeteren.
Aan de andere kant zijn partitioneren en sharding twee technieken om data in de cloud te verdelen.
Het up-to-date houden van databasestatistieken is belangrijk om ervoor te zorgen dat de query-optimizer weloverwogen, nauwkeurige beslissingen kan nemen over de meest efficiënte manier om queries uit te voeren.
Statistieken beschrijven de dataverdeling in een tabel (bijv. het aantal rijen, de frequentie van waarden en de spreiding van waarden over kolommen), en de optimizer vertrouwt op deze informatie om de uitvoeringskosten van queries te schatten. Als statistieken verouderd zijn, kan de optimizer inefficiënte uitvoeringsplannen kiezen, zoals het gebruiken van de verkeerde indexen of kiezen voor een volledige tabelscan in plaats van een efficiëntere indexscan, wat leidt tot slechte queryprestaties.
Databases ondersteunen vaak automatische updates om statistieken accuraat te houden. Zo werkt in SQL Server de standaardconfiguratie statistieken automatisch bij wanneer een significant deel van de data verandert. Evenzo heeft PostgreSQL een auto-analyze-functie, die statistieken bijwerkt na een drempel aan datamodificatie.
We kunnen statistieken echter handmatig bijwerken in gevallen waar automatische updates onvoldoende zijn of wanneer handmatige tussenkomst nodig is. In SQL Server kunnen we het commando UPDATE STATISTICS gebruiken om statistieken voor een specifieke tabel of index te verversen, terwijl in PostgreSQL het commando ANALYZE kan worden uitgevoerd om statistieken voor één of meer tabellen bij te werken.
-- Update statistics for all tables in the current database
ANALYZE;
-- Update statistics for a specific table
ANALYZE my_table;Een stored procedure is een set SQL-commando’s die we in onze database opslaan zodat we niet steeds dezelfde SQL hoeven te schrijven. Je kunt het zien als een herbruikbaar script.
Wanneer we een bepaalde taak moeten uitvoeren, zoals records bijwerken of waarden berekenen, roepen we simpelweg de stored procedure aan. Die kan invoer ontvangen, werk uitvoeren zoals data opvragen of wijzigen, en zelfs een resultaat teruggeven. Stored procedures helpen de boel te versnellen omdat de SQL vooraf gecompileerd is, waardoor je code schoner en makkelijker te beheren is.
We kunnen in PostgreSQL als volgt een stored procedure maken:
CREATE OR REPLACE PROCEDURE insert_employee(
emp_id INT,
emp_first_name VARCHAR,
emp_last_name VARCHAR
)
LANGUAGE plpgsql
AS $
BEGIN
-- Insert a new employee into the employees table
INSERT INTO employees (employee_id, first_name, last_name)
VALUES (emp_id, emp_first_name, emp_last_name);
END;
$;
-- call the procedure
CALL insert_employee(101, 'John', 'Doe');Als dataprofessionals houden we ervan onze data te sorteren en te groeperen zodat we gemakkelijker inzichten kunnen krijgen. We gebruiken hiervoor vaak ORDER BY en GROUP BY in onze SQL-queries.
Beide clausules kunnen echter rekenintensief zijn, vooral bij grote datasets. Bij het sorteren of aggregeren van data moet de database-engine vaak een volledige scan uitvoeren en de data vervolgens ordenen, de groepen bepalen en/of aggregatiefuncties toepassen, meestal met algoritmen die veel resources vragen.
Om de queries te optimaliseren, kunnen we enkele van deze tips volgen:
ORDER BY alleen wanneer het nodig is. Als sorteren niet essentieel is, kan het weglaten van deze clausule de verwerkingstijd sterk verkorten. ORDER BY en GROUP BY zijn geïndexeerd. GROUP BY kunnen we de data in een eerder stadium of in een gematerialiseerde view vooraggregeren, zodat de database niet telkens dezelfde aggregaties hoeft te berekenen.Wanneer we resultaten uit meerdere queries in één lijst willen combineren, kunnen we de clausules UNION en UNION ALL gebruiken. Beide combineren de resultaten van twee of meer SELECT -statements wanneer ze dezelfde kolomnamen hebben. Ze zijn echter niet hetzelfde, en dat verschil maakt ze geschikt voor verschillende use-cases.
De clausule UNION verwijdert dubbele rijen, wat meer verwerkingstijd kost.
Figuur: Union in SQL. Afbeeldingsbron: DataCamp SQL-Join cheat sheet.
Daarentegen combineert UNION ALL de resultaten maar houdt alle rijen, inclusief duplicaten, intact. Als we geen duplicaten hoeven te verwijderen, gebruiken we dus UNION ALL voor betere performance.
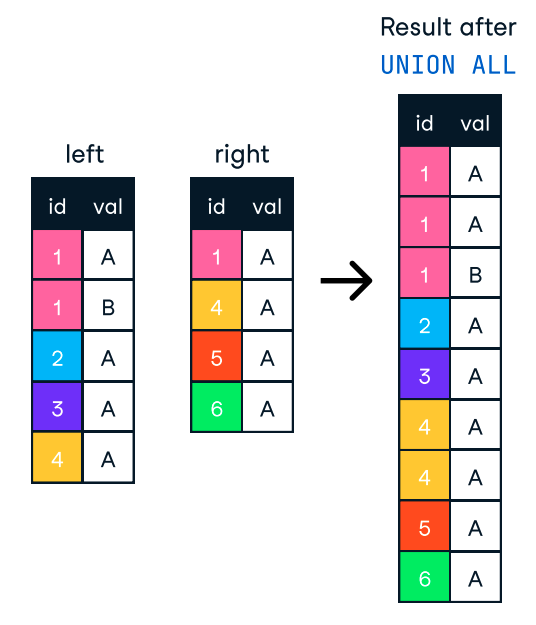
Figuur: UNION ALL in SQL. Afbeeldingsbron: DataCamp SQL-Join cheat sheet.
-- Potentially slower
SELECT product_id FROM products WHERE category = 'Electronics'
UNION
SELECT product_id FROM products WHERE category = 'Books';
-- Potentially faster
SELECT product_id FROM products WHERE category = 'Electronics'
UNION ALL
SELECT product_id FROM products WHERE category = 'Books';Werken met grote datasets betekent dat we vaak complexe queries tegenkomen die lastig te begrijpen en te optimaliseren zijn. We kunnen dit aanpakken door ze op te delen in kleinere, eenvoudigere queries. Zo kunnen we prestatieknelpunten makkelijker identificeren en optimalisatietechnieken toepassen.
Een van de meest gebruikte strategieën om queries op te delen, is gematerialiseerde views. Dit zijn voorbewerkte en opgeslagen queryresultaten die snel toegankelijk zijn, in plaats van de query telkens opnieuw te berekenen. Wanneer de onderliggende data verandert, moet de gematerialiseerde view handmatig of automatisch worden ververst.
Hier is een voorbeeld van hoe je een gematerialiseerde view maakt en bevraagt:
-- Create a materialized view
CREATE MATERIALIZED VIEW daily_sales AS
SELECT product_id, SUM(quantity) AS total_quantity
FROM order_items
GROUP BY product_id;
-- Query the materialized view
SELECT * FROM daily_sales;In dit artikel hebben we diverse strategieën en best practices voor het optimaliseren van SQL-queries verkend, van indexering en joins tot subquery’s en databasespecifieke features. Door deze technieken toe te passen, kun je de prestaties van je queries aanzienlijk verbeteren en onze databases efficiënter laten draaien.
Onthoud: SQL-queries optimaliseren is een continu proces. Naarmate je data groeit en je applicatie evolueert, moet je je queries blijven monitoren en optimaliseren om ze optimaal te laten presteren.
Om je begrip van SQL verder te verdiepen, raden we je aan de volgende bronnen op DataCamp te verkennen:
Leer meer over SQL met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
