
Kurs
Data Engineering'e Giriş
4 sa
128.3K
Veri ambarlarıyla çalışıyorsanız, verileri verimli ve kolay yönetilebilir şekilde yapılandırmanın ne kadar önemli olduğunu bilirsiniz. Peki hiç veritabanı şemasının hangisinin ihtiyaçlarınıza en uygun olduğunu düşündünüz mü? Bunun için kullanabileceğiniz iki ana çerçeve vardır: yıldız şeması ve kar tanesi şeması.
Yıldız şeması basit ve hızlıdır — analiz için veriyi çabucak çıkarmak istediğinizde idealdir. Öte yandan kar tanesi şeması daha detaylıdır. Depolama verimliliğine ve karmaşık veri ilişkilerinin yönetimine öncelik verir.
Bu yazıda, bu şemaların yapılarını inceleyecek, farklarını vurgulayacak ve avantajlarını açıklayacağım. Sonunda, her bir şemanın nerede uygun olduğunu ve veri projeleriniz için hangisini seçmeniz gerektiğini bileceksiniz.
Yıldız şeması, özellikle veri ambarlarında verileri daha kolay ve hızlı analiz edilebilir hale getirmek için verileri bir veritabanında düzenleme yöntemidir. Merkezde, olgu tablosu adı verilen ana bir tablo bulunur; satış veya gelir gibi ölçülebilir verileri tutar. Etrafında ise ürün adları, müşteri bilgileri veya tarihler gibi detayları ekleyen boyut tabloları yer alır. Bu yerleşim yıldız benzeri bir şekil oluşturur.
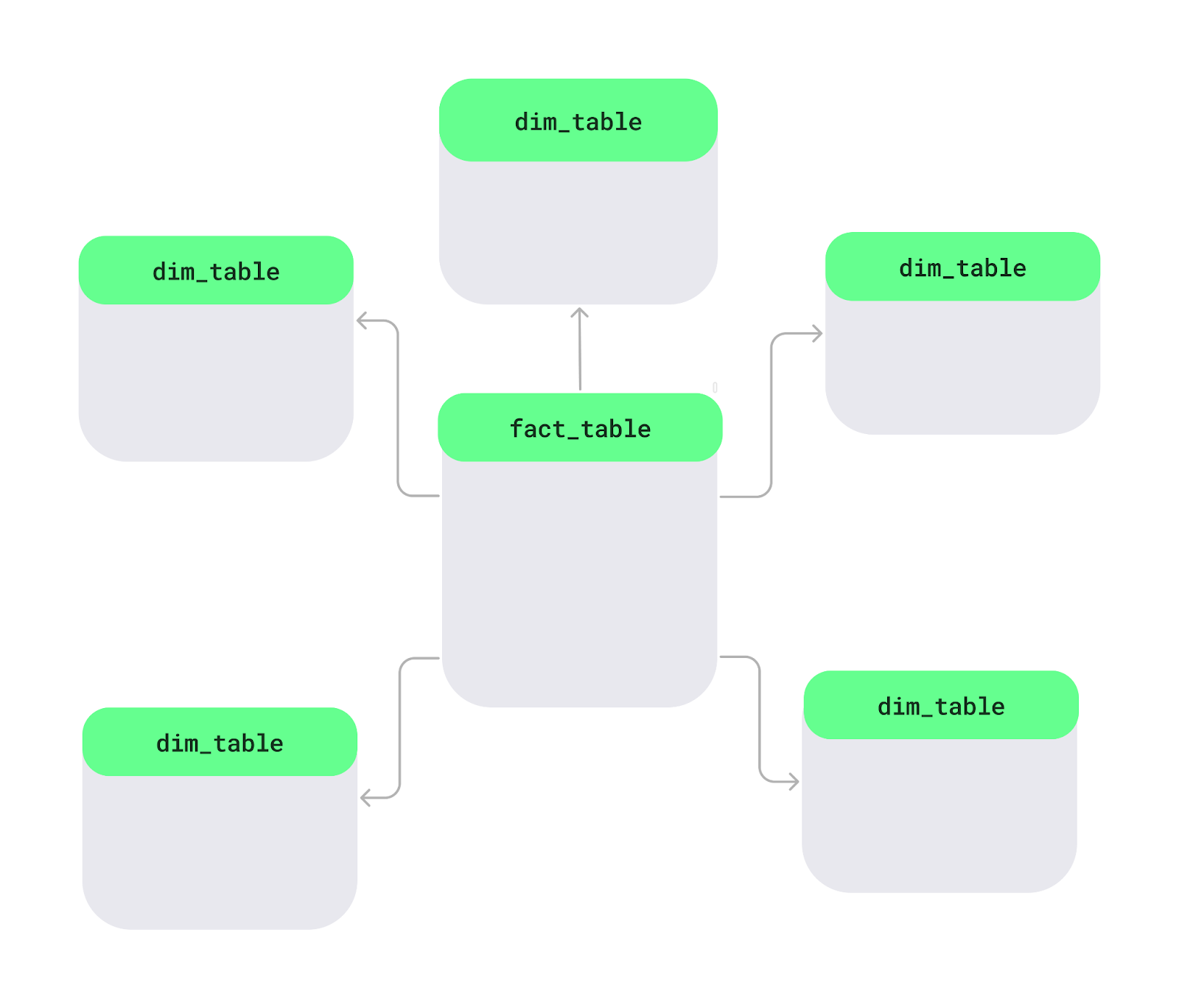
Yıldız şeması yerleşimi. Görsel: Yazar.
Yıldız şemasının temel özelliklerine bakalım:
Bunu basit bir yıldız şeması diyagramıyla anlayalım. Merkezde olgu tablosu Sales bulunur. Satış veya kâr gibi analiz etmek istediğiniz sayısal verileri tutar. Buna bağlı olarak, ürün adları, müşteri konumu veya tarihler gibi açıklayıcı ayrıntılar içeren boyut tabloları yer alır:
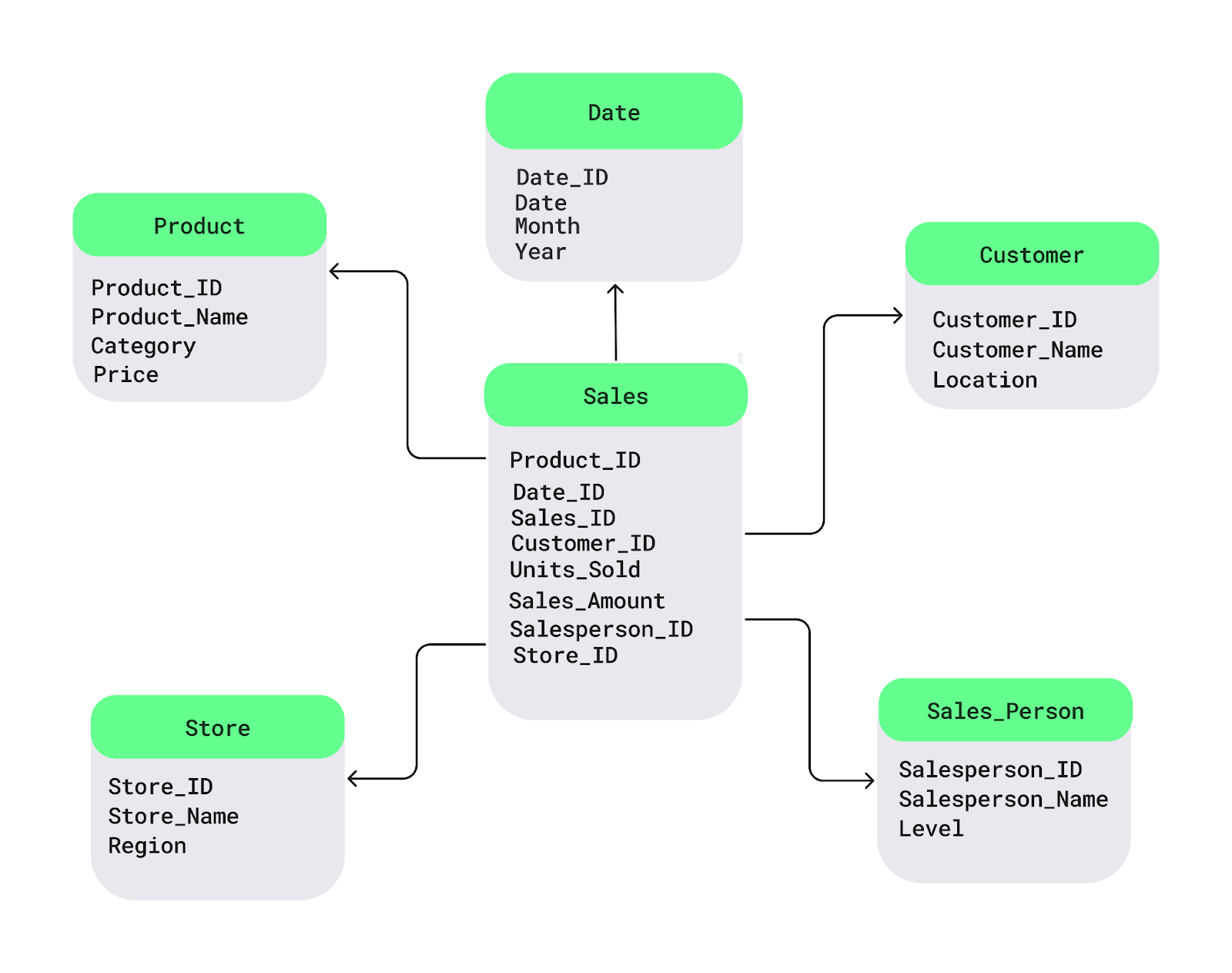
Örnek yıldız şeması. Görsel: Yazar.
Aşağıda, bir Sales olgu tablosu ile Product, Customer ve Date boyut tablolarını içeren bir yıldız şemasını kurmak için basit bir SQL örneği yer alıyor:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Bu yerleşim, karmaşık birleştirmeler olmadığı için sorguları hızlandırır. Örneğin aşağıdaki sorgu, yıldız şemasının basit birleştirmelerinden yararlanarak müşteri konumuna göre gruplanmış toplam satışları getirir:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Ancak, boyut tabloları tekrarlanan bilgiler içerebileceğinden bir miktar veri fazlalığını kabullenmeniz gerekir.
Artık yıldız şemasının ne olduğunu bildiğinize göre, neden öne çıktığına bakalım:
Tüm bu faydalara rağmen yıldız şemasının bir dezavantajı vardır. Daha önce belirttiğim gibi, denormalizasyon nedeniyle boyut tabloları sıklıkla tekrarlanan bilgiler içerir; bu da depolama kullanımını artırır. Örneğin, birden fazla ürün aynı kategoriye aitse, her ürünün adı tekrarlanabilir ve daha fazla depolama alanı kaplar.
Bir kar tanesi şeması başka bir veri düzenleme yöntemidir. Bu şemada, boyut tabloları daha düzenli ve ayrıntılı tutmak için daha küçük alt boyutlara bölünür — tıpkı büyük bir göldeki kar taneleri gibi.
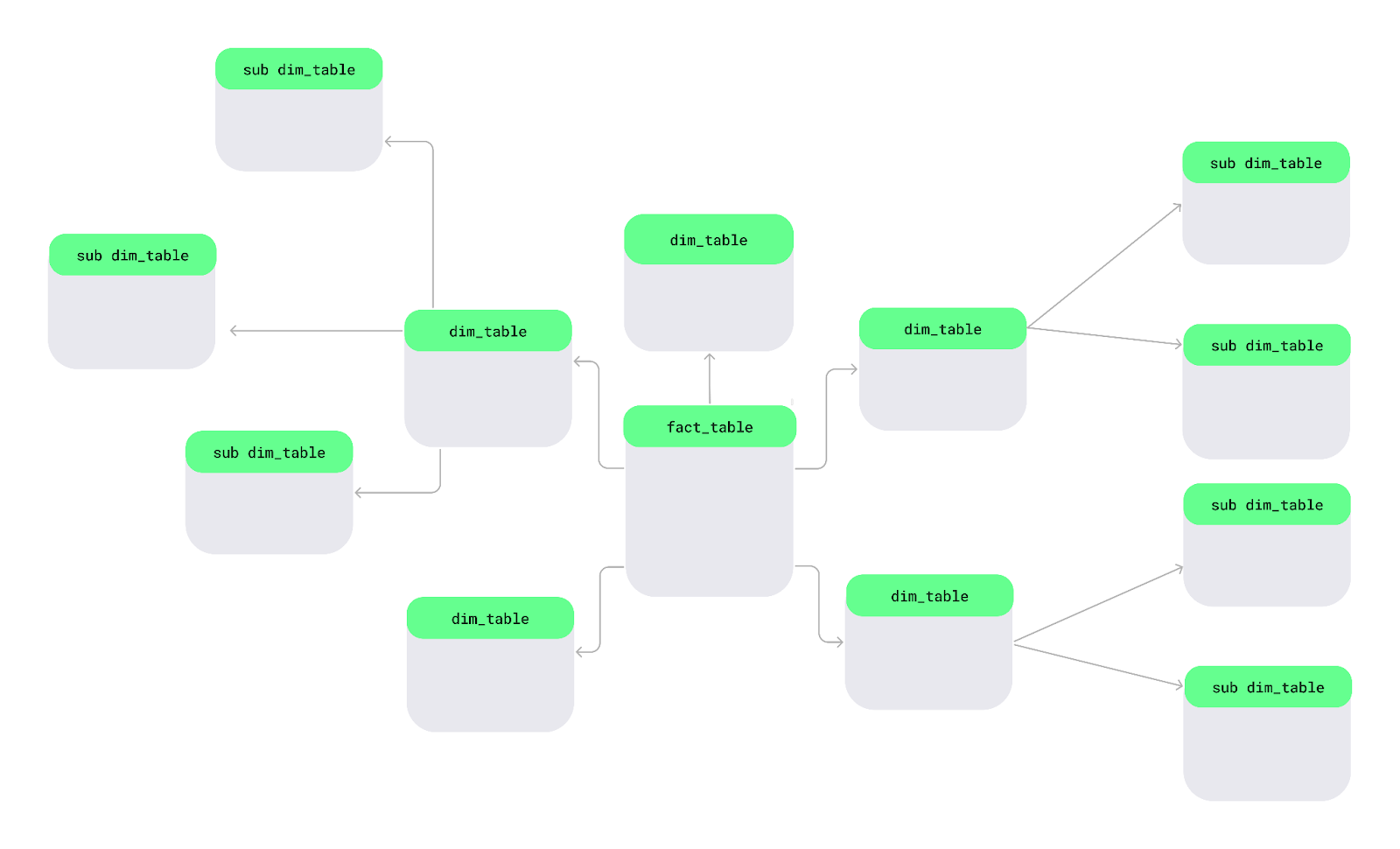
Kar tanesi şeması yerleşimi. Görsel: Yazar.
Kar tanesi şemasını diğer şemalardan farklı kılan temel özelliklere bakalım:
Electronics gibi bir ürün kategorisini tekrarlamak yerine kategoriyi ayrı bir tabloda tutup tekil ürünlerle ilişkilendirebilirim.Bunu basit bir kar tanesi şeması diyagramıyla anlayalım. Merkezde ölçülebilir verileri içeren olgu tablosu vardır. Bu tablo, olguları açıklayan boyut tablolarına bağlanır ve bu boyut tabloları da alt boyutlara dallanarak kar tanesi benzeri bir yapı oluşturur.
Örneğin burada Product tablosunu Manufacturer ve Category tablolarına, Customer tablosunu ise Transaction ve Location tablolarına böldüm:
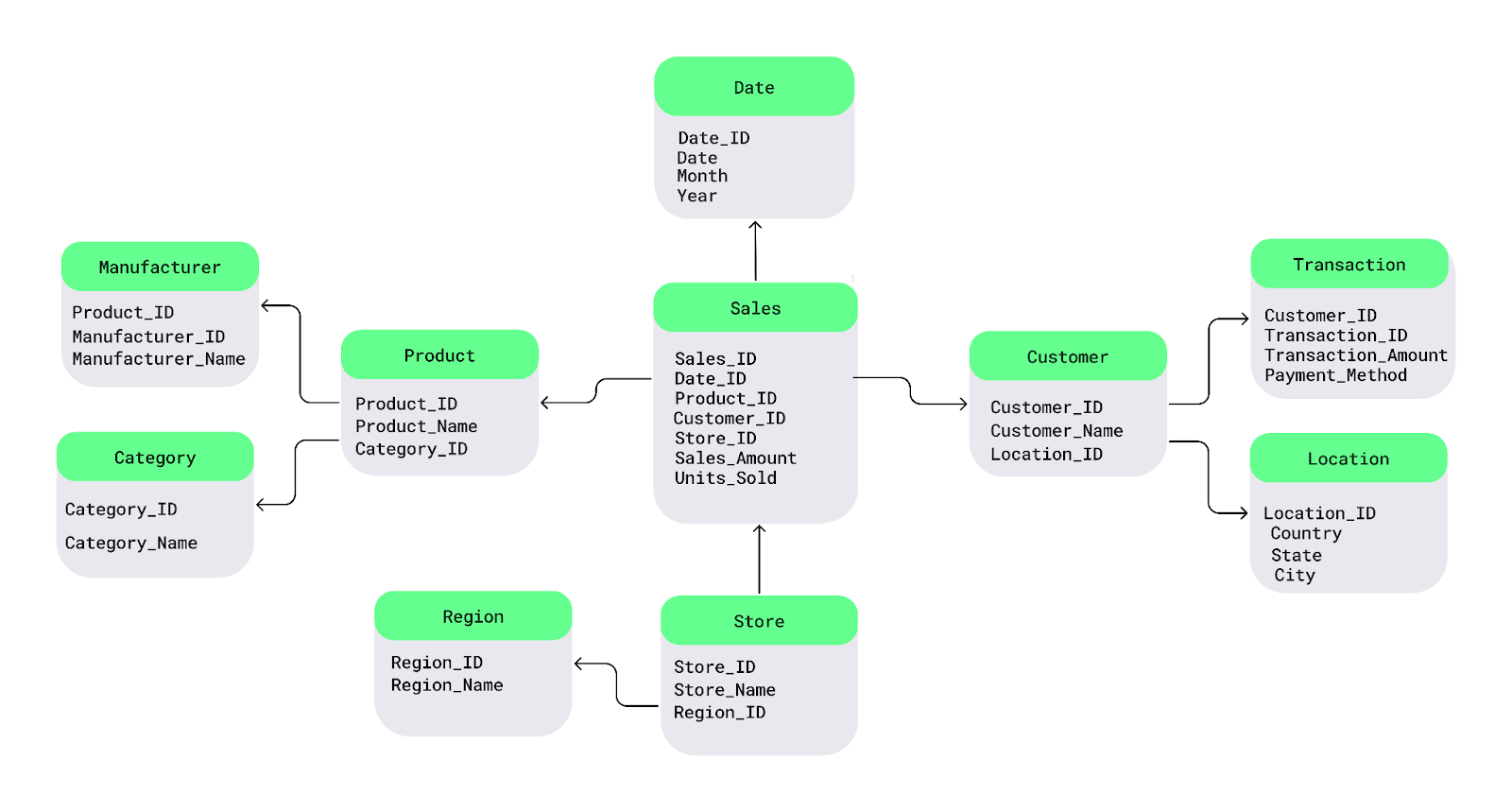
Kar tanesi şeması örneği. Görsel: Yazar.
Aşağıda, Product tablosunun Category ve Manufacturer tablolara daha fazla normalize edildiği bir kar tanesi şemasını gösteren bir SQL örneği yer alıyor:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);Aşağıdaki sorgu, ürün kategorisine göre toplam satışları hesaplar. Yıldız şemasından daha fazla birleştirme içerse de depolama açısından daha verimlidir:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Yıldız şeması gibi, kar tanesi şemasının da kendine özgü avantajları vardır. Neler olduklarına bakalım:
Bununla birlikte, avantajlarına rağmen bazı sınırlamaları da vardır. Örneğin, sorgular daha yavaş olabilir çünkü tablolar arasında daha fazla birleştirme vardır. Bunun dışında, çok katmanlı yapı, yıldız şeması gibi daha basit şemalara kıyasla tasarlaması ve bakımını yapması daha zordur. Bu nedenle, yalnızca deneyimli bir DBA ekibiniz varsa tercih edin.
Analiz için verileri verimli şekilde yapılandırmayı daha fazla öğrenmek isterseniz Database Design kursuna göz atmanızı öneririm.
Gerçek projelerde, her iki yaklaşımın da güçlü yanlarını birleştirmek için farklı katmanlarda her iki deseni birden kullanmak yaygındır:
Bu sayede ekipler, veri bütünlüğü ve yönetişimini hızlı ve basit analiz tüketimiyle dengeleyebilir.
Hem yıldız hem de kar tanesi şemaları veri ambarlarında yaygın olarak kullanılır; ancak benzersiz özellikleri onları farklı ihtiyaçlara uygun kılar. Bu şemaların yapı, performans, depolama gereksinimleri ve kullanım alanları açısından nasıl farklılaştığını görelim.
Yıldız şemasında tüm boyut tabloları doğrudan merkezi bir olgu tablosuna bağlanır. Bu, tüm referans verinizin ana verinizden bir adım uzakta olduğu anlamına gelir; anlaşılması ve üzerinde çalışılması kolaydır.
Buna kıyasla, kar tanesi şeması boyut tablolarını daha küçük ve daha spesifik alt boyut tablolarına böler. Örneğin tek bir konum tablosu yerine ülkeler, eyalet/bölgeler ve şehirler için ayrı tablolarınız olabilir. Bu daha düzenli ve ayrıntılı bir yapı oluştursa da verilerinize erişmek için daha fazla bağlantı (veya join) gerektiği anlamına gelir — kar tanesi şemasının yıldız şemasına göre daha karmaşık olmasının başlıca nedeni budur.
Hız söz konusu olduğunda yıldız şemaları genellikle daha iyidir. Tüm boyut tabloları doğrudan olgu tablosuna bağlandığı için sorgular genellikle daha az birleştirme gerektirir; bu da daha hızlı performans demektir. Diyelim ki bölgelere göre satışları analiz etmek istiyorsunuz — bu durumda yıldız şemasını kullanarak minimum işlemle veriyi getirebilirsiniz.
Buna karşılık, kar tanesi şemaları genellikle daha yavaştır çünkü veriyi getirmek için birden çok tablo üzerinden bağlanmanız gerekir. Her birleştirme işlem süresi ekler; bu da hızlı sorgu sonuçları gerektiren görevler için kar tanesi şemalarını daha az verimli kılar.
Joining Data in SQL kursu, tabloları birleştirmeyi öğrenmek, ilişkisel küme teorisini uygulamak ve alt sorgularla çalışmak için mükemmel bir başlangıçtır.
Yıldız şemaları, boyut tablolarında tekrarlı bilgi tuttukları için daha fazla depolama alanı kaplar. Örneğin, birden fazla ürün aynı kategoriye aitse, kategori adı her ürün için tekrar eder ve depolama ihtiyacını artırır.
Buna karşın kar tanesi şemaları, tüm bilgiyi yalnızca bir kez saklamak için verileri normalize eder. Örneğin, kategori adlarını tekrar etmek yerine ayrı bir tabloda tutar ve ürün tablosuna yabancı anahtarlarla bağlar. Bu tasarım depolama alanından tasarruf sağlar ve büyük veri kümeleri için idealdir.
Yıldız şemaları, çevrimiçi analitik işlem (OLAP) sistemleri, raporlama ve iş zekâsı görevleri için idealdir. Basitlikleri, hızlı pano veya satış raporları üretmek gibi hız ve kullanım kolaylığının önemli olduğu senaryolar için onları mükemmel kılar.
Kar tanesi şemaları sıklıkla finansal analiz veya müşteri ilişkileri yönetimi (CRM) sistemlerinde kullanılır. Bu tür durumlarda, sorgu hızından ziyade ayrıntılı hiyerarşilerin düzenlenmesi ve depolama alanından tasarruf edilmesi daha önemlidir.
Veri ihtiyaçlarınıza en uygun olanı seçmenize yardımcı olmak için yıldız ve kar tanesi şemalarının hızlı bir karşılaştırması burada. Aşağıdaki tabloda yapı, performans, depolama ve kullanım alanlarına odaklanarak temel farkları vurguladım:
|
Özellik |
Yıldız şeması |
Kar tanesi şeması |
Hibrit yaklaşım |
|
Yapı |
Merkezi olgu tablosu denormalize boyutlara bağlı |
Merkezi olgu tablosu normalize boyutlara bağlı |
Tüketim için normalize çekirdek model artı yıldız biçimli martlar veya denormalize görünümler |
|
Karmaşıklık |
Basit, daha az birleştirme |
Karmaşık, daha fazla birleştirme |
Orta; daha fazla hareketli parça var ama her katman kendi amacı için daha basit kalır |
|
Veri fazlalığı |
Denormalize boyutlar nedeniyle daha yüksek fazlalık |
Normalize boyutlar sayesinde daha düşük fazlalık |
Seçici denormalizasyon nedeniyle orta düzeyde fazlalık |
|
Sorgu performansı |
Daha basit yapı sayesinde hızlı sorgular |
Ek birleştirmeler nedeniyle daha yavaş sorgular |
BI için hızlı çünkü tüketim katmanı denormalizedir |
|
Depolama |
Fazlalık nedeniyle daha fazla depolama gerektirir |
Normalizasyon sayesinde daha az depolama gerektirir |
Orta düzeyde depolama; çünkü martlar/görünümler bir miktar kopya ekleyebilir |
|
Bakım kolaylığı |
Tasarımı ve bakımı daha kolay |
Tasarımı ve bakımı daha karmaşık |
Bakımı kolay; çünkü martlar kontrollü çekirdekten yeniden inşa edilebilir |
|
En uygun olduğu durumlar |
Küçük ve orta ölçekli veri kümeleri |
Büyük ve karmaşık veri kümeleri |
Hem yönetişim hem de BI performans gereksinimleri olan modern veri platformları |
Verinizi öncelikle basit ve hızlı bir şekilde düzenlemek istiyorsanız, yıldız şeması uygundur. Şu durumlarda kullanabilirsiniz:
Kar tanesi şeması, özellikle birden çok boyut özniteliğinin birçok satırda tekrarlandığı durumlarda hiyerarşileri ve paylaşılan referans verisini temsil etmek için daha uygundur. Şu durumlarda kullanabilirsiniz:
Birçok modern bulut veri ambarında, depolama hesaplamaya kıyasla nispeten ucuzdur. Bu da denormalize boyutlardan kaynaklanan “ek depolama”nın, veriyi tarama ve birleştirme hesaplama maliyetinden genellikle daha az önemli olduğu anlamına gelir.
Yıldız ve kar tanesi arasında seçim yaparken platformunuzun fiyatlandırma modelini (hesaplama vs. depolama), sorgu eşzamanlılığını ve sorgu maliyetlerini düşürmek için önbellekleme/materyalize görünümleri kullanıp kullanamayacağınızı değerlendirin.
Bu blogda yıldız ve kar tanesi şemaları arasındaki farkları, güçlü yanlarını ve her birini ne zaman kullanmanız gerektiğini ele aldım. Umarım artık daha net bir anlayışa ve işiniz için pratik ipuçlarına sahipsinizdir! Daha fazla öğrenmek isterseniz DataCamp’teki şu kaynaklara göz atın:
Veri Mühendisliği Kursları
Kurs
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
