
Courses
Introduction to Data Engineering
4 giờ
128.3K
Nếu bạn làm việc với kho dữ liệu, bạn sẽ biết việc tổ chức dữ liệu sao cho hiệu quả và dễ xử lý quan trọng thế nào. Nhưng bạn đã bao giờ nghĩ về việc schema cơ sở dữ liệu nào phù hợp nhất với nhu cầu của mình chưa? Có hai khung chính bạn có thể dùng cho mục đích này: star schema và snowflake schema.
Star schema đơn giản và nhanh — lý tưởng khi bạn cần trích xuất dữ liệu để phân tích một cách nhanh chóng. Ngược lại, snowflake schema chi tiết hơn. Nó ưu tiên hiệu quả lưu trữ và quản lý các mối quan hệ dữ liệu phức tạp.
Trong bài viết này, tôi sẽ giới thiệu cấu trúc của các schema này, làm nổi bật sự khác biệt của chúng và phân tích ưu điểm. Đến cuối bài, bạn sẽ biết mỗi schema phù hợp ở đâu và cách quyết định cái nào tốt nhất cho dự án dữ liệu của bạn.
Star schema là cách tổ chức dữ liệu trong cơ sở dữ liệu, đặc biệt là trong kho dữ liệu, nhằng giúp phân tích dễ dàng và nhanh hơn. Ở trung tâm là bảng chính gọi là bảng fact, chứa dữ liệu đo lường như doanh số hoặc doanh thu. Bao quanh là các bảng dimension, bổ sung chi tiết như tên sản phẩm, thông tin khách hàng hoặc ngày tháng. Bố cục này tạo thành hình ngôi sao.
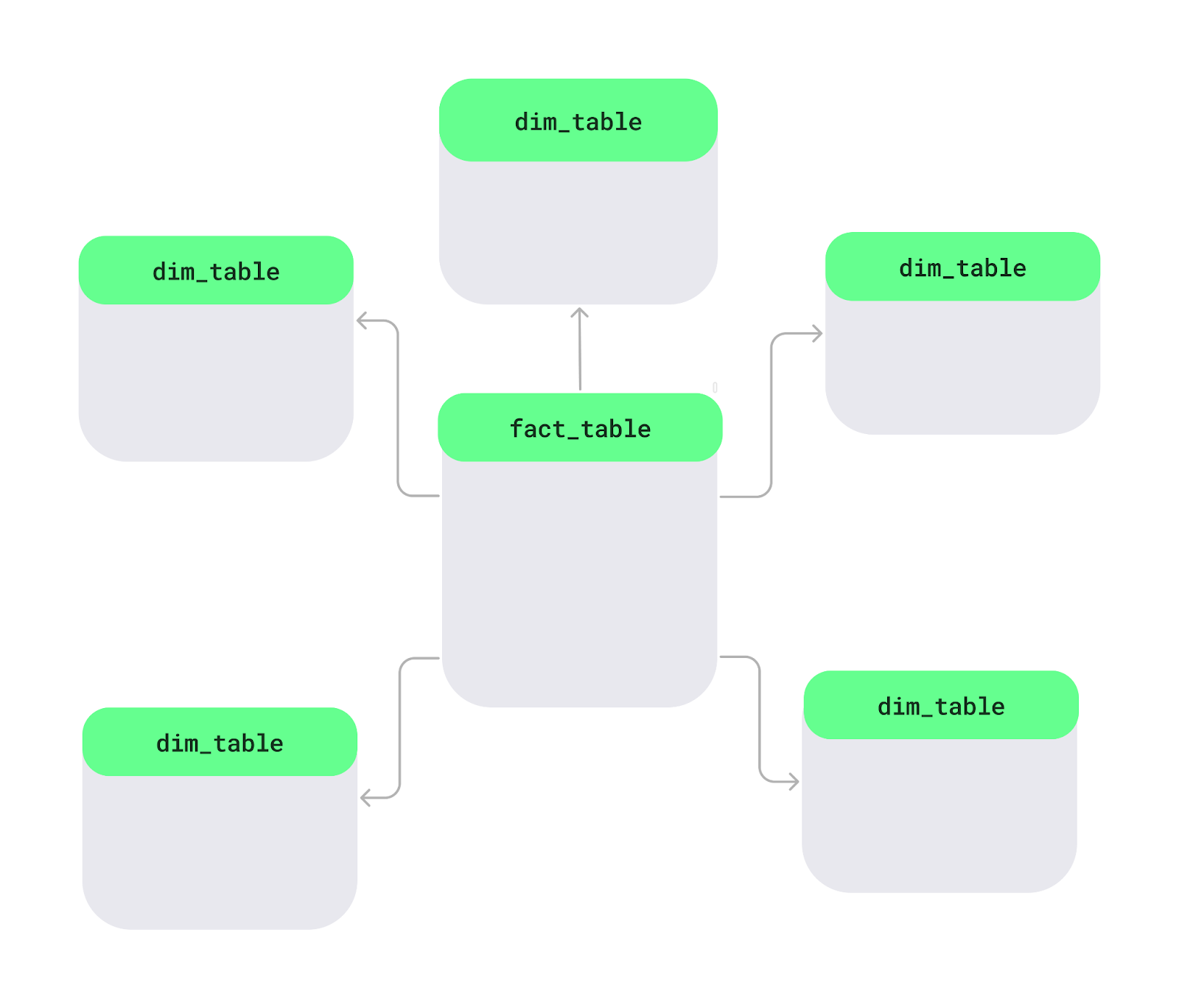
Bố cục star schema. Ảnh: Tác giả.
Hãy cùng xem các đặc điểm chính của star schema:
Hãy hiểu rõ hơn qua một sơ đồ star schema đơn giản. Bảng fact Sales nằm ở trung tâm. Nó chứa dữ liệu số bạn muốn phân tích, như doanh số hoặc lợi nhuận. Kết nối với nó là các bảng dimension với thông tin mô tả, như tên sản phẩm, vị trí khách hàng hoặc ngày tháng:
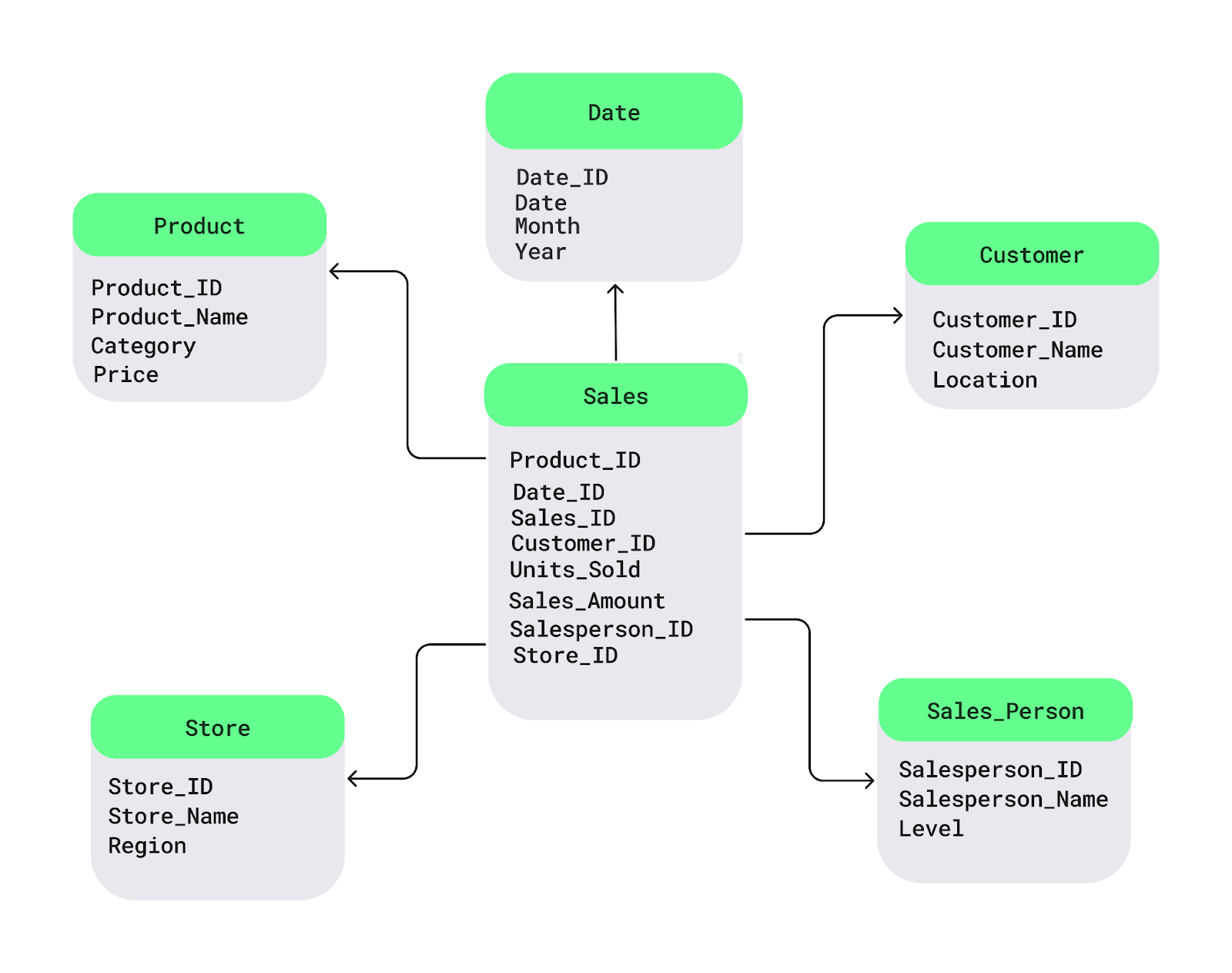
Ví dụ star schema. Ảnh: Tác giả.
Dưới đây là ví dụ SQL đơn giản để thiết lập star schema với bảng fact Sales và các bảng dimension Product, Customer và Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Bố cục này tăng tốc truy vấn vì không có các phép nối phức tạp. Ví dụ, truy vấn sau đây truy xuất tổng doanh số theo vị trí khách hàng, tận dụng các phép nối đơn giản của star schema:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Tuy nhiên, bạn sẽ phải chấp nhận một số dư thừa dữ liệu vì các bảng dimension có thể chứa thông tin lặp lại.
Giờ bạn đã biết star schema là gì, hãy xem vì sao nó nổi bật:
Dù có nhiều lợi ích, star schema vẫn có một nhược điểm. Như tôi đã đề cập, do phi chuẩn hoá, các bảng dimension thường chứa thông tin lặp lại, điều này làm tăng mức sử dụng lưu trữ. Ví dụ, nếu nhiều sản phẩm thuộc cùng một danh mục, tên danh mục có thể lặp lại cho mỗi sản phẩm, chiếm thêm dung lượng.
Snowflake schema là một cách khác để tổ chức dữ liệu. Trong schema này, các bảng dimension được tách thành các bảng phân dimension nhỏ hơn để dữ liệu được tổ chức và chi tiết hơn — giống như những bông tuyết trong một hồ lớn.
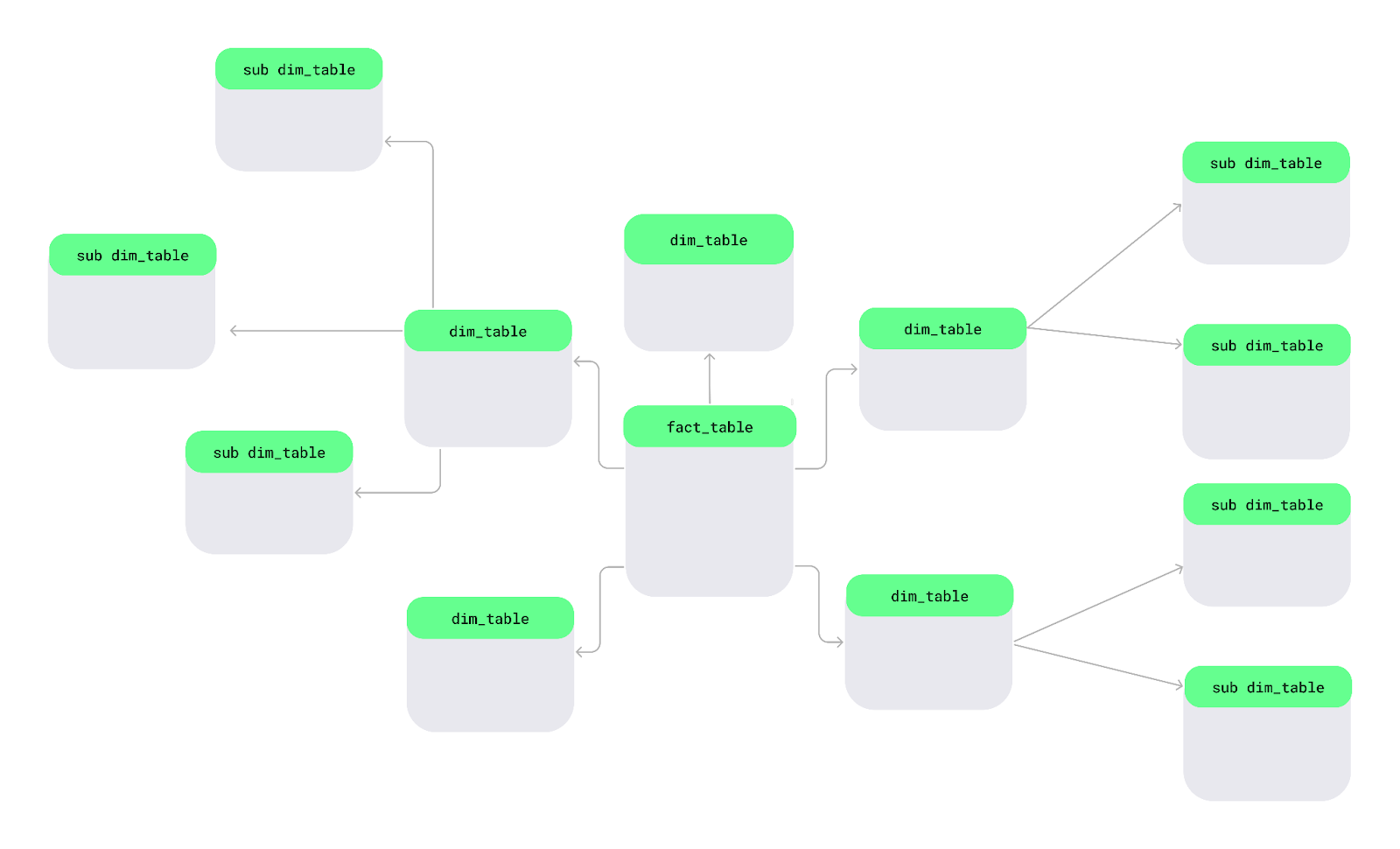
Bố cục snowflake schema. Ảnh: Tác giả.
Hãy xem các đặc điểm chính của snowflake schema khiến nó khác biệt với những schema khác:
Electronics cho mọi sản phẩm, tôi có thể lưu danh mục ở một bảng riêng và liên kết với từng sản phẩm.Hãy hiểu qua một sơ đồ snowflake schema đơn giản. Ở trung tâm là bảng fact, chứa dữ liệu đo lường. Nó kết nối tới các bảng dimension mô tả các fact, và các bảng dimension này tiếp tục phân nhánh thành các bảng phân dimension, tạo thành cấu trúc như bông tuyết.
Ví dụ, ở đây tôi tách Product thành các bảng Manufacturer và Category và tách bảng Customer thành các bảng Transaction và Location :
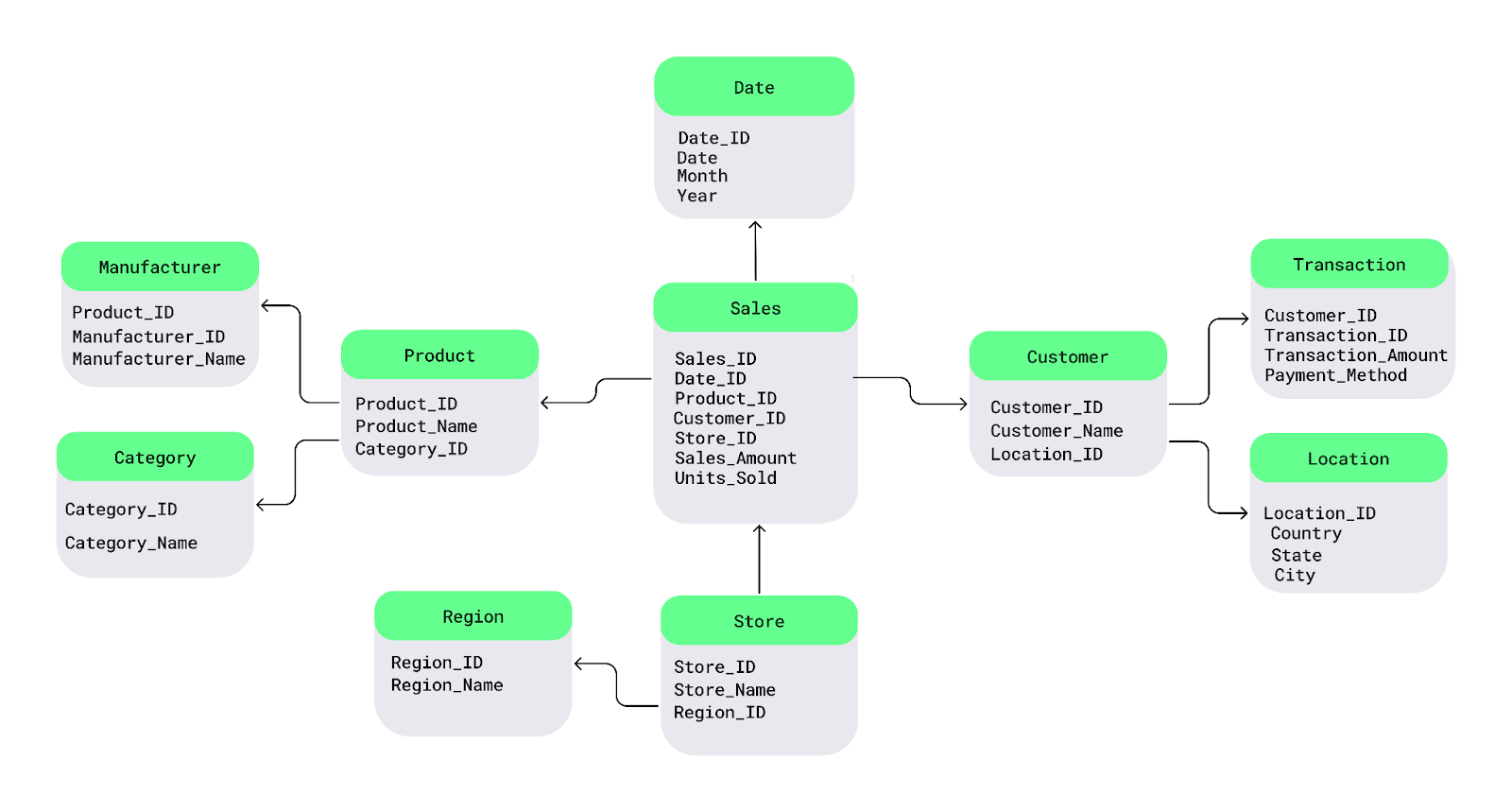
Ví dụ snowflake schema. Ảnh: Tác giả.
Dưới đây là ví dụ SQL minh hoạ snowflake schema, trong đó bảng Product được chuẩn hoá thêm thành các bảng Category và Manufacturer:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);Truy vấn sau đây tính tổng doanh số theo danh mục sản phẩm. Dù có nhiều phép nối hơn so với star schema, nó tiết kiệm lưu trữ hơn:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Giống như star schema, snowflake schema cũng có những ưu điểm riêng. Hãy xem đó là gì:
Tuy nhiên, bên cạnh các ưu điểm, cũng có vài hạn chế. Ví dụ, truy vấn có thể chậm hơn vì có nhiều phép nối giữa các bảng. Ngoài ra, cấu trúc nhiều cấp khó thiết kế và bảo trì hơn so với các schema đơn giản như star schema. Vì vậy, chỉ nên dùng nếu bạn có đội ngũ DBA giàu kinh nghiệm.
Tôi khuyến nghị xem khóa học Database Design nếu bạn muốn tìm hiểu thêm về cách cấu trúc dữ liệu hiệu quả cho phân tích.
Trong các dự án thực tế, thường sử dụng cả hai mẫu ở những lớp khác nhau để kết hợp điểm mạnh của mỗi cách tiếp cận:
Cách này giúp đội ngũ cân bằng giữa tính toàn vẹn và quản trị dữ liệu với khả năng tiêu thụ phân tích nhanh, đơn giản.
Cả star và snowflake schema đều được dùng rộng rãi trong kho dữ liệu, nhưng đặc điểm riêng khiến chúng phù hợp với các nhu cầu khác nhau. Hãy xem chúng khác nhau ra sao về cấu trúc, hiệu năng, yêu cầu lưu trữ và trường hợp sử dụng.
Trong star schema, tất cả các bảng dimension kết nối trực tiếp với một bảng fact trung tâm. Điều này có nghĩa toàn bộ dữ liệu tham chiếu của bạn chỉ cách dữ liệu chính một bước, giúp dễ hiểu và làm việc.
Ngược lại, snowflake schema chia các bảng dimension thành các bảng phân dimension nhỏ, cụ thể hơn. Ví dụ, bạn có thể có các bảng riêng cho quốc gia, bang/tỉnh và thành phố thay vì một bảng vị trí. Mặc dù tạo ra cấu trúc có tổ chức và chi tiết hơn, nó cũng đòi hỏi nhiều kết nối (join) hơn để truy cập dữ liệu — là lý do chính khiến snowflake schema phức tạp hơn star schema.
Về tốc độ, star schema thường tốt hơn. Vì tất cả bảng dimension kết nối trực tiếp với bảng fact, truy vấn thường cần ít phép nối hơn, nghĩa là hiệu năng nhanh hơn. Giả sử bạn muốn phân tích doanh số theo khu vực — trong trường hợp này, bạn có thể dùng star schema để truy xuất dữ liệu với xử lý tối thiểu.
Ngược lại, snowflake schema thường chậm hơn vì bạn phải nối qua nhiều bảng để truy xuất dữ liệu. Mỗi phép nối thêm thời gian xử lý, khiến snowflake kém hiệu quả hơn cho các tác vụ cần kết quả truy vấn nhanh.
Khóa học Joining Data in SQL là phần mở đầu tuyệt vời để học cách nối bảng, áp dụng lý thuyết tập quan hệ và làm việc với truy vấn lồng.
Star schema tốn nhiều không gian lưu trữ hơn vì lưu thông tin dư thừa trong các bảng dimension. Ví dụ, nếu nhiều sản phẩm thuộc cùng một danh mục, tên danh mục sẽ lặp lại cho mỗi sản phẩm, làm tăng nhu cầu lưu trữ.
Tuy nhiên, snowflake schema chuẩn hoá dữ liệu để mọi thông tin chỉ được lưu một lần. Ví dụ, thay vì lặp lại tên danh mục, chúng được lưu trong bảng riêng và liên kết với bảng sản phẩm bằng khoá ngoại. Thiết kế này tiết kiệm không gian, phù hợp với tập dữ liệu lớn.
Star schema lý tưởng cho hệ thống xử lý phân tích trực tuyến (OLAP), báo cáo và tác vụ business intelligence. Sự đơn giản khiến chúng hoàn hảo cho các tình huống cần tốc độ và dễ sử dụng, như tạo dashboard nhanh hoặc báo cáo doanh số.
Snowflake schema thường được dùng cho phân tích tài chính hoặc hệ thống quản lý quan hệ khách hàng (CRM). Việc tổ chức phân cấp chi tiết và tiết kiệm lưu trữ quan trọng hơn tốc độ truy vấn trong các trường hợp này.
Dưới đây là so sánh nhanh giữa star và snowflake schema để giúp bạn quyết định cái nào phù hợp nhất với nhu cầu dữ liệu. Tôi đã làm nổi bật các khác biệt chính trong bảng này, tập trung vào cấu trúc, hiệu năng, lưu trữ và trường hợp sử dụng:
|
Tính năng |
Star schema |
Snowflake schema |
Cách tiếp cận lai |
|
Cấu trúc |
Bảng fact trung tâm liên kết tới các dimension phi chuẩn hoá |
Bảng fact trung tâm liên kết tới các dimension chuẩn hoá |
Mô hình lõi chuẩn hoá, cộng thêm các data mart dạng ngôi sao hoặc view phi chuẩn hoá cho lớp tiêu thụ |
|
Độ phức tạp |
Đơn giản, ít phép nối hơn |
Phức tạp, nhiều phép nối hơn |
Trung bình, có nhiều phần chuyển động, nhưng mỗi lớp đơn giản hơn cho mục đích của nó |
|
Dư thừa dữ liệu |
Dư thừa cao do dimension phi chuẩn hoá |
Dư thừa thấp do dimension chuẩn hoá |
Dư thừa ở mức trung bình do phi chuẩn hoá có chọn lọc |
|
Hiệu năng truy vấn |
Truy vấn nhanh hơn nhờ cấu trúc đơn giản |
Truy vấn chậm hơn vì có thêm phép nối |
Nhanh cho BI vì lớp tiêu thụ được phi chuẩn hoá |
|
Lưu trữ |
Cần nhiều lưu trữ hơn do dư thừa |
Cần ít lưu trữ hơn nhờ chuẩn hoá |
Cần lưu trữ ở mức vừa phải vì các mart/view có thể thêm một số trùng lặp |
|
Dễ bảo trì |
Dễ thiết kế và bảo trì |
Khó thiết kế và bảo trì hơn |
Dễ bảo trì, vì các mart có thể dựng lại từ lõi được kiểm soát |
|
Phù hợp nhất cho |
Tập dữ liệu nhỏ đến trung bình |
Tập dữ liệu lớn và phức tạp |
Nền tảng dữ liệu hiện đại vừa cần quản trị vừa cần hiệu năng BI |
Nếu mục tiêu chính của bạn là tổ chức dữ liệu đơn giản và nhanh chóng, star schema sẽ rất phù hợp. Dùng trong các trường hợp sau:
Snowflake schema phù hợp hơn để biểu diễn phân cấp và dữ liệu tham chiếu dùng chung, đặc biệt khi nhiều thuộc tính dimension lặp lại trên nhiều hàng. Dùng trong các trường hợp sau:
Trong nhiều kho dữ liệu đám mây hiện đại, lưu trữ tương đối rẻ so với tính toán. Điều đó có nghĩa “thêm lưu trữ” từ các dimension phi chuẩn hoá thường kém quan trọng hơn chi phí tính toán để quét và nối dữ liệu.
Khi chọn giữa star và snowflake, hãy cân nhắc mô hình giá của nền tảng (tính toán so với lưu trữ), mức độ đồng thời truy vấn, và liệu bạn có thể dùng cache/view vật hoá để giảm chi phí truy vấn hay không.
Trong bài viết này, tôi đã trình bày sự khác biệt giữa star và snowflake schema, điểm mạnh và thời điểm dùng mỗi loại. Hy vọng bạn đã có hiểu biết rõ ràng và mẹo thực tiễn cho công việc! Nếu muốn học thêm, hãy xem các tài nguyên trên DataCamp:
Khóa học Data Engineering
Courses
Courses
Courses