
Course
Introduction to Data Engineering
4 hr
127.6K
If you work with data warehouses, you know how important it is to structure data in a way that’s efficient and easy to handle. But have you ever thought about which database schema best suits your needs? There are two major frameworks that you can use for this: the star schema and the snowflake schema.
The star schema is simple and fast — ideal when you need to extract data for analysis quickly. On the other hand, the snowflake schema is more detailed. It prioritizes storage efficiency and managing complex data relationships.
In this article, I’ll walk you through the structures of these schemas, highlight their differences, and break down their advantages. By the end, you’ll know where each schema suits and how to decide which is best for your data projects.
A star schema is a way to organize data in a database, especially in data warehouses, to make it easier and faster to analyze. At the center, there's a main table called the fact table, which holds measurable data like sales or revenue. Around it are dimension tables, which add details like product names, customer info, or dates. This layout forms a star-like shape.
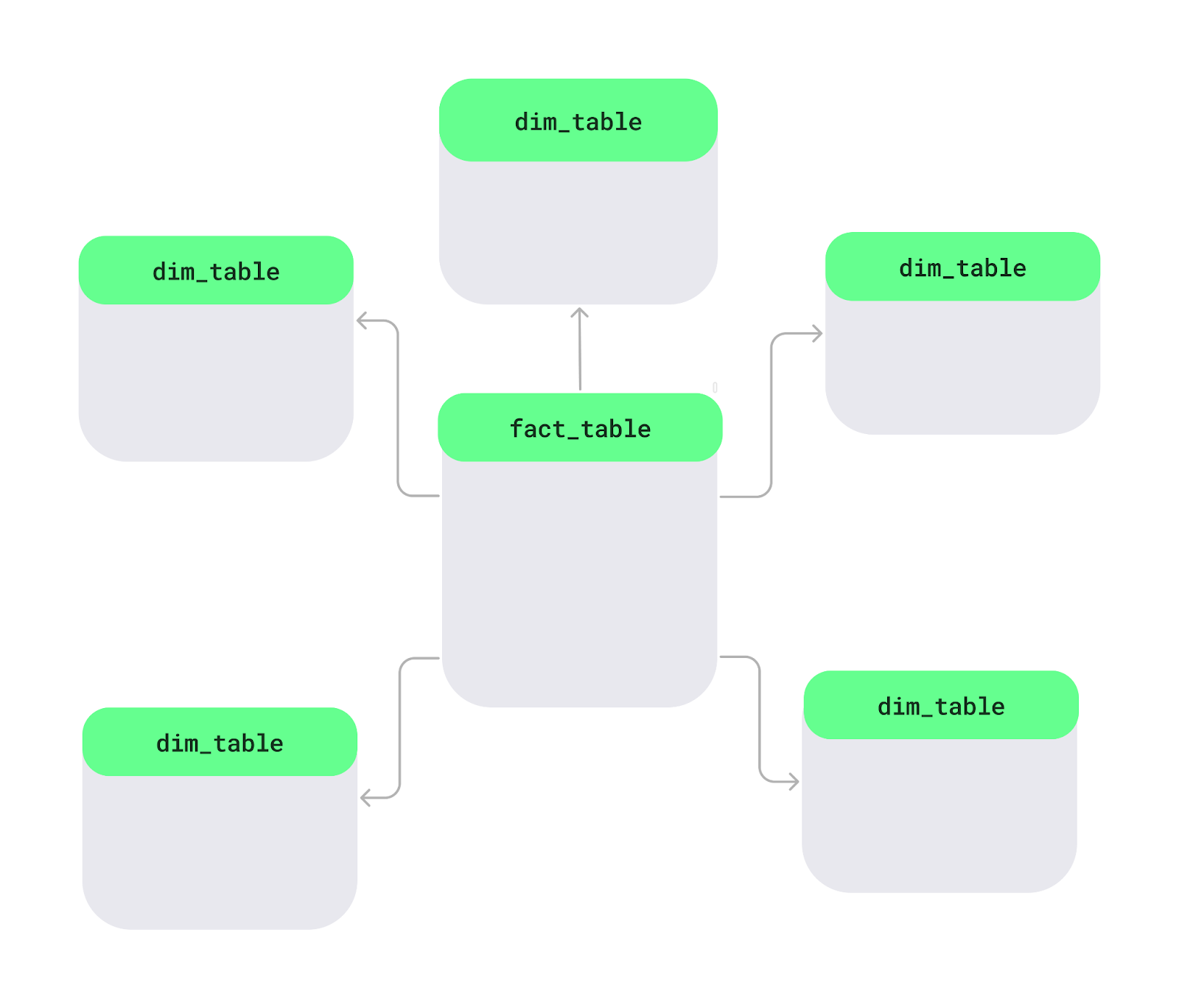
Star schema layout. Image by Author.
Let’s look at the key features of the star schema:
Let’s understand this with a simple star schema diagram. The fact table Sales is in the center. It holds the numeric data you want to analyze, like sales or profits. Connected to it are dimension tables with descriptive details, such as product names, customer location, or dates:
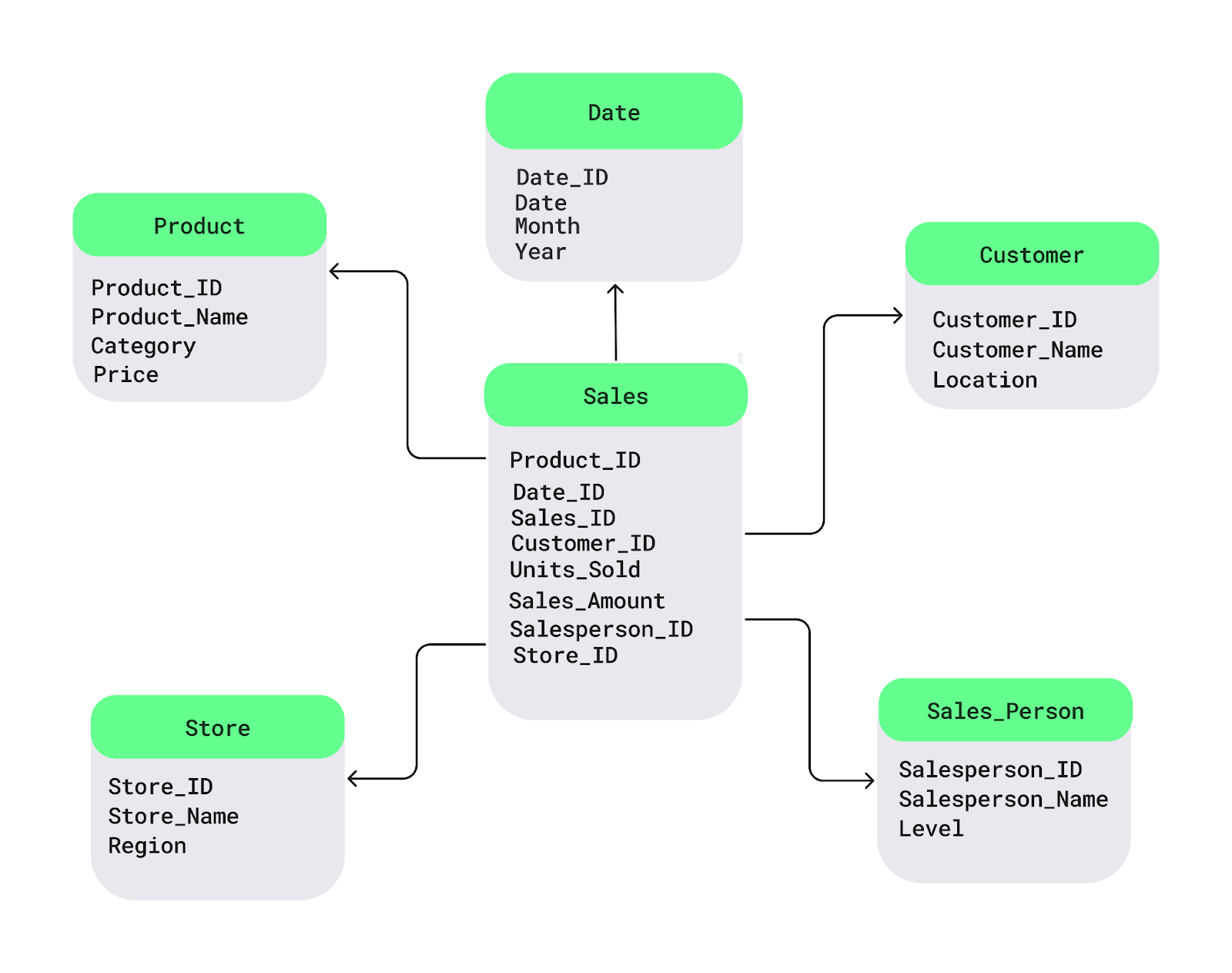
Sample star schema. Image by Author.
Here’s a simple SQL example for setting up a star schema with a Sales fact table and dimension tables for Product, Customer, and Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);This layout speeds up queries because there are no complex joins. For example, the following query retrieves total sales grouped by customer location, leveraging the simple joins of the star schema:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;However, you would have to accept some data redundancy since the dimension tables may contain repeated information.
Now that you know what star schema is, let’s look at why it stands out:
Despite all the benefits, star schema does have a drawback. As I mentioned before, due to denormalization, dimension tables often contain repeated information, which increases storage use. For example, if several products belong to the same category, each product's name might repeat, taking up more storage space.
A snowflake schema is another way of organizing data. In this schema, dimension tables are split into smaller sub-dimensions to keep data more organized and detailed — just like snowflakes in a large lake.
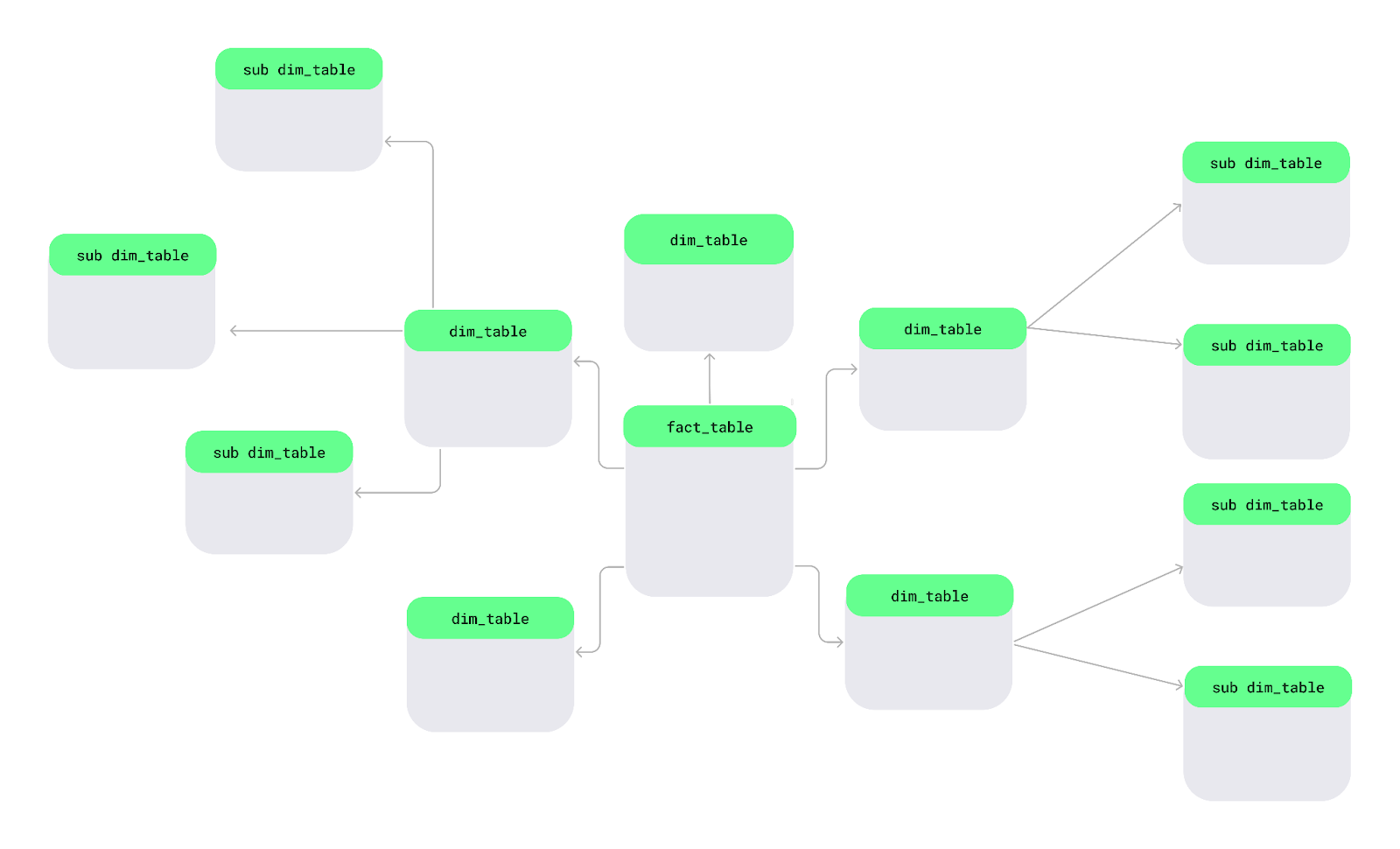
Snowflake schema layout. Image by Author.
Let’s look at the key features of the snowflake schema that make it different from other schemas:
Electronics for every product, I can store the category in a separate table and link it to individual products.Let’s understand this with a simple snowflake schema diagram. At the center is the fact table, which contains measurable data. It connects to dimension tables that describe the facts, and these dimension tables further branch out into sub-dimension tables, forming a snowflake-like structure.
For example, here I split the Product into Manufacturer and Category tables and the Customer table into Transaction and Location tables:
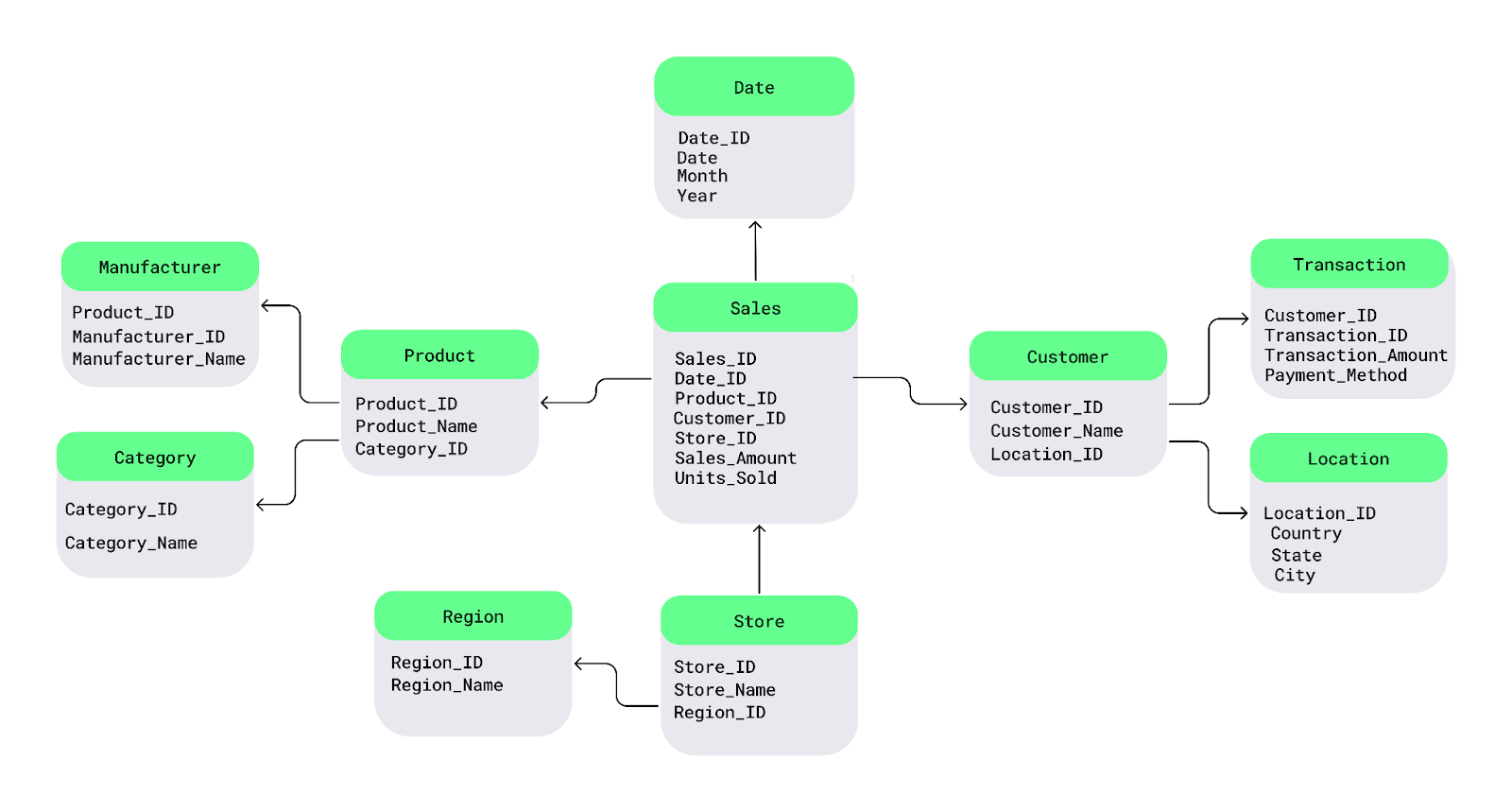
Snowflake schema example. Image by Author.
Here’s a SQL example illustrating a snowflake schema where the Product table is further normalized into Category and Manufacturer tables:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);The following query calculates total sales by product category. Although it involves more joins than the star schema, it is more storage-efficient:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Like star schema, snowflake schema also has its own advantages. Let’s see what they are:
However, despite its advantages, there are a few limitations too. For example, queries can be slower because there are more joins between tables. Apart from this, the multi-level structure is more challenging to design and maintain than simpler schemas like star schema. So, go for it only if you have an experienced DBA team.
I recommend checking out the Database Design course if you want to learn more about efficiently structuring data for analysis.
In real projects, it’s common to use both patterns at different layers to combine the strengths of both approaches:
This lets teams balance data integrity and governance with fast, simple analytics consumption.
Both star and snowflake schemas are widely used in data warehousing, but their unique characteristics make them suitable for different needs. Let’s see how these schemas differ in structure, performance, storage requirements, and use cases.
All dimension tables connect directly to one central fact table in a star schema. This means all your reference data is one step away from your main data, making it easy to understand and work with.
In comparison, a snowflake schema breaks dimension tables into smaller, more specific sub-dimension tables. For example, you can have separate tables for countries, states, and cities instead of one location table. While this creates a more organized and detailed structure, it also means more connections (or joins) are required to access your data — a primary reason why snowflake schema is more complex than star schema.
When it comes to speed, star schemas are often better. Since all dimension tables connect directly to the fact table, queries usually require fewer joins, which means faster performance. Let’s say you want to analyze sales by region — in this case, you can use the star schema to retrieve the data with minimal processing.
Conversely, Snowflake schemas are often slower because you have to connect through multiple tables to retrieve the data. Each join adds processing time, making snowflake schemas less efficient for tasks that require quick query results.
The course Joining Data in SQL is an excellent primer for learning how to join tables together, apply relational set theory, and work with subqueries.
Star schemas take up more storage space because they store redundant information in dimension tables. For example, if multiple products belong to the same category, the category name will repeat for each product, increasing storage needs.
However, snowflake schemas normalize data to store all information only once. For example, instead of repeating category names, they are stored in a separate table and linked to the product table using foreign keys. This design saves storage space, making it ideal for large datasets.
Star schemas are ideal for online analytical processing (OLAP) systems, reporting, and business intelligence tasks. Their simplicity makes them perfect for scenarios where speed and ease of use are important, such as generating quick dashboards or sales reports.
Snowflake schemas are often used for financial analysis or customer relationship management (CRM) systems. Organizing detailed hierarchies and saving storage space are more important than query speed in such cases.
Here's a quick comparison of the star and snowflake schemas to help you decide which best suits your data needs. I’ve highlighted the key differences in this table, focusing on their structure, performance, storage, and use cases:
|
Feature |
Star schema |
Snowflake schema |
Hybrid approach |
|
Structure |
Central fact table linked to denormalized dimensions |
Central fact table linked to normalized dimensions |
Normalized core model, plus star-shaped marts or denormalized views for consumption |
|
Complexity |
Simple, with fewer joins |
Complex, with more joins |
Medium, with more moving parts, but each layer stays simpler for its purpose |
|
Data redundancy |
Higher redundancy due to denormalized dimensions |
Lower redundancy due to normalized dimensions |
Medium redundancy due to selective denormalization |
|
Query performance |
Faster queries due to simpler structure |
Slower queries because of additional joins |
Fast for BI because the consumption layer is denormalized |
|
Storage |
Requires more storage because of redundancy |
Requires less storage due to normalization |
Requires moderate storage because marts/views may add some duplication |
|
Ease of maintenance |
Easier to design and maintain |
More complex to design and maintain |
Easy to maintain, as marts can be rebuilt from the controlled core |
|
Best suited for |
Small to medium-sized datasets |
Large and complex datasets |
Modern data platforms with both governance needs and BI performance needs |
If you primarily want to organize your data simply and quickly, the star schema would be perfect. Here’s when you can use it:
Snowflake schema is more suitable for representing hierarchies and shared reference data, especially when multiple dimension attributes repeat across many rows. Here’s when you can use it:
In many modern cloud data warehouses, storage is relatively inexpensive compared to compute. That means the “extra storage” from denormalized dimensions is often less important than the compute cost of scanning and joining data.
When choosing between star and snowflake, consider your platform’s pricing model (compute vs. storage), your query concurrency, and whether you can use caching/materialized views to keep query costs down.
In this blog, I’ve covered the differences between the star and snowflake schemas, their strengths, and when to use each one. I hope you have a clear understanding and practical tips for your work! If you want to learn more, check out these resources on DataCamp:
Data Engineering Courses
Course
Course
Course
blog
Austin Chia
10 min
blog
Bex Tuychiev
12 min
blog
Tim Lu
12 min
Tutorial
Laiba Siddiqui
Tutorial
Gus Frazer
Tutorial
Bex Tuychiev

