
Curso
Introducción a la ingeniería de datos
4 h
127.6K
Si trabajas con almacenes de datos, sabes lo importante que es estructurar los datos de una manera eficiente y fácil de manejar. ¿Pero alguna vez has pensado en qué esquema de base de datos se adapta mejor a tus necesidades? Hay dos marcos principales que puedes utilizar para ello: el esquema en estrella y el esquema Snowflake.
El esquema en estrella es sencillo y rápido, ideal cuando necesitas extraer datos para analizarlos rápidamente. Por otro lado, el esquema de Snowflake es más detallado. Da prioridad a la eficiencia del almacenamiento y a la gestión de relaciones de datos complejas.
En este artículo, te explicaré las estructuras de estos esquemas, destacaré sus diferencias y desglosaré sus ventajas. Al final, sabrás dónde encaja cada esquema y cómo decidir cuál es el más adecuado para tus proyectos de datos.
Un esquema en estrella es una forma de organizar los datos en una base de datos, especialmenteen almacenes de datos, para facilitar y agilizar su análisis. En el centro, hay una tabla principal llamadatabla de hechos (fact table) de la base de datos de hechos ( ), que contiene datos medibles como ventas o ingresos. A tu alrededor haytablas de dimensiones , que añaden detalles como nombres de productos, información de clientes o fechas. Este diseño forma una estrella.
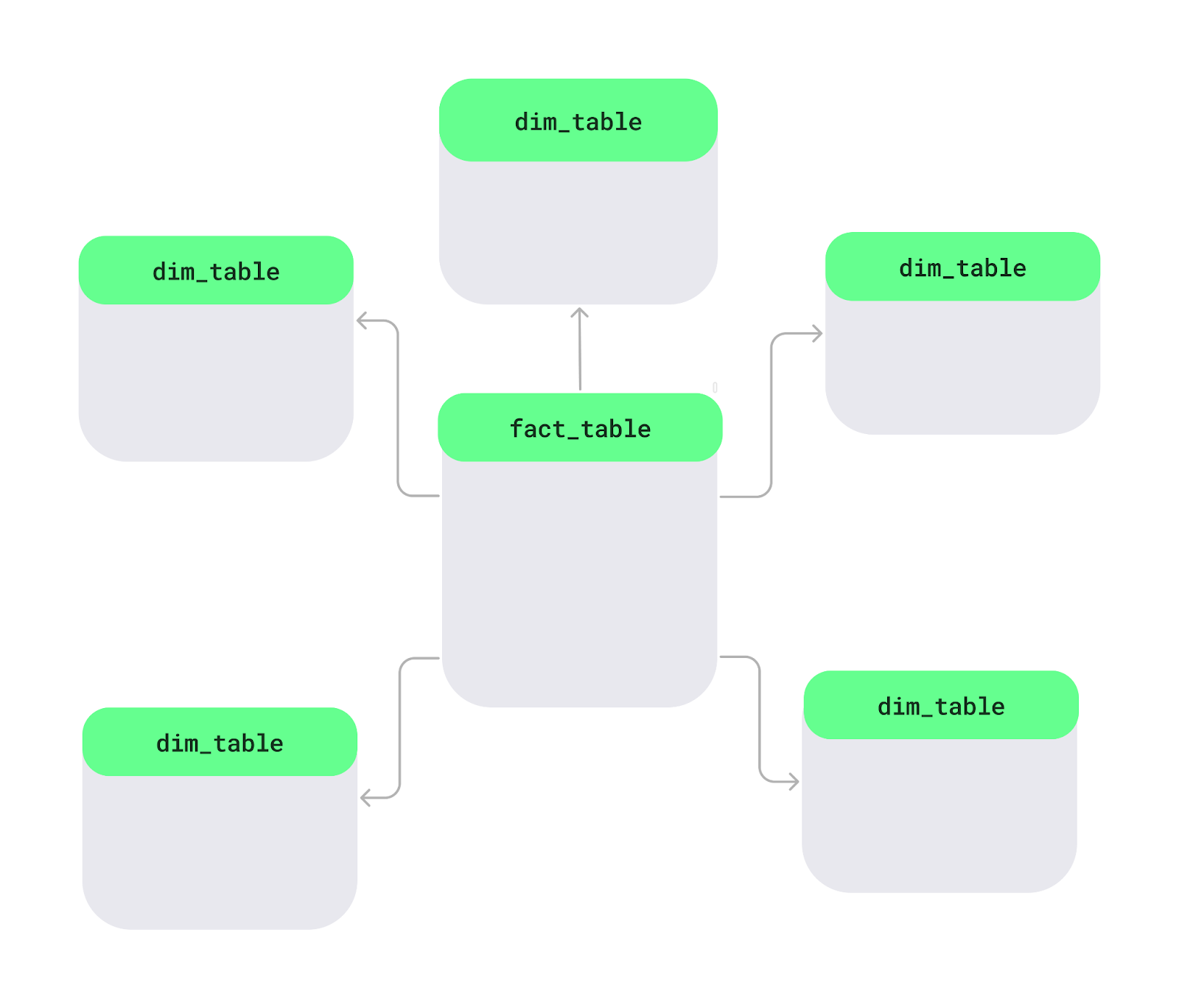
Diseño de esquema en estrella. Imagen del autor.
Veamos las características principales del esquema en estrella:
Entendamos esto con un sencillo diagrama de esquema en estrella. La tabla de hechos « » ( Sales ) se encuentra en el centro. Contiene los datos numéricos que deseas analizar, como las ventas o los beneficios. Conectadas a ella haytablas de dimensión es con detalles descriptivos, como nombres de productos, ubicación de los clientes o fechas:
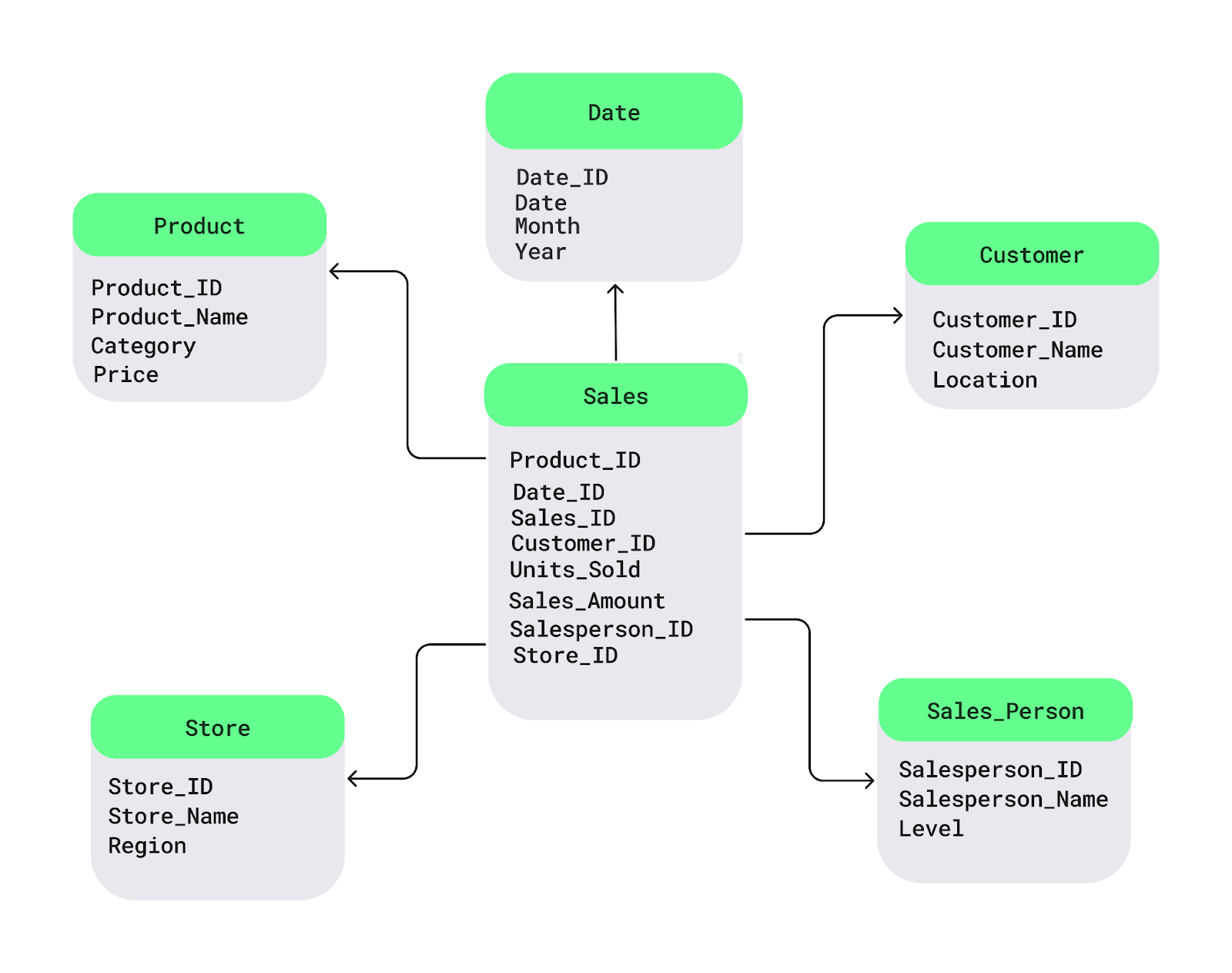
Ejemplo de esquema en estrella. Imagen del autor.
Aquí tienes un ejemplo sencillo de SQL para configurar un esquema en estrella con una Sales tabla de hechos y tablas de dimensiones para Product, Customery Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Este diseño acelera las consultas porque no hay uniones complejas. Por ejemplo, la siguiente consulta recupera las ventas totales agrupadas por ubicación del cliente, aprovechando las combinaciones simples del esquema en estrella:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Sin embargo, tendrías que aceptar cierta redundancia de datos, ya que las tablas de dimensiones pueden contener información repetida.
Ahora que ya sabes qué es el esquema en estrella, veamos por qué destaca:
A pesar de todas las ventajas, el esquema en estrella tiene un inconveniente. Como mencioné anteriormente, debido a la desnormalización, las tablas de dimensiones suelen contener información repetida, lo que aumenta el uso del almacenamiento. Por ejemplo, si varios productos pertenecen a la misma categoría, el nombre de cada producto podría repetirse, ocupando más espacio de almacenamiento.
Un esquemaen forma de Snowflake es otra forma de organizar los datos. En este esquema, las tablas de dimensiones se dividen en subdimensiones más pequeñas para mantener los datos más organizados y detallados, como copos de nieve en un gran lago.
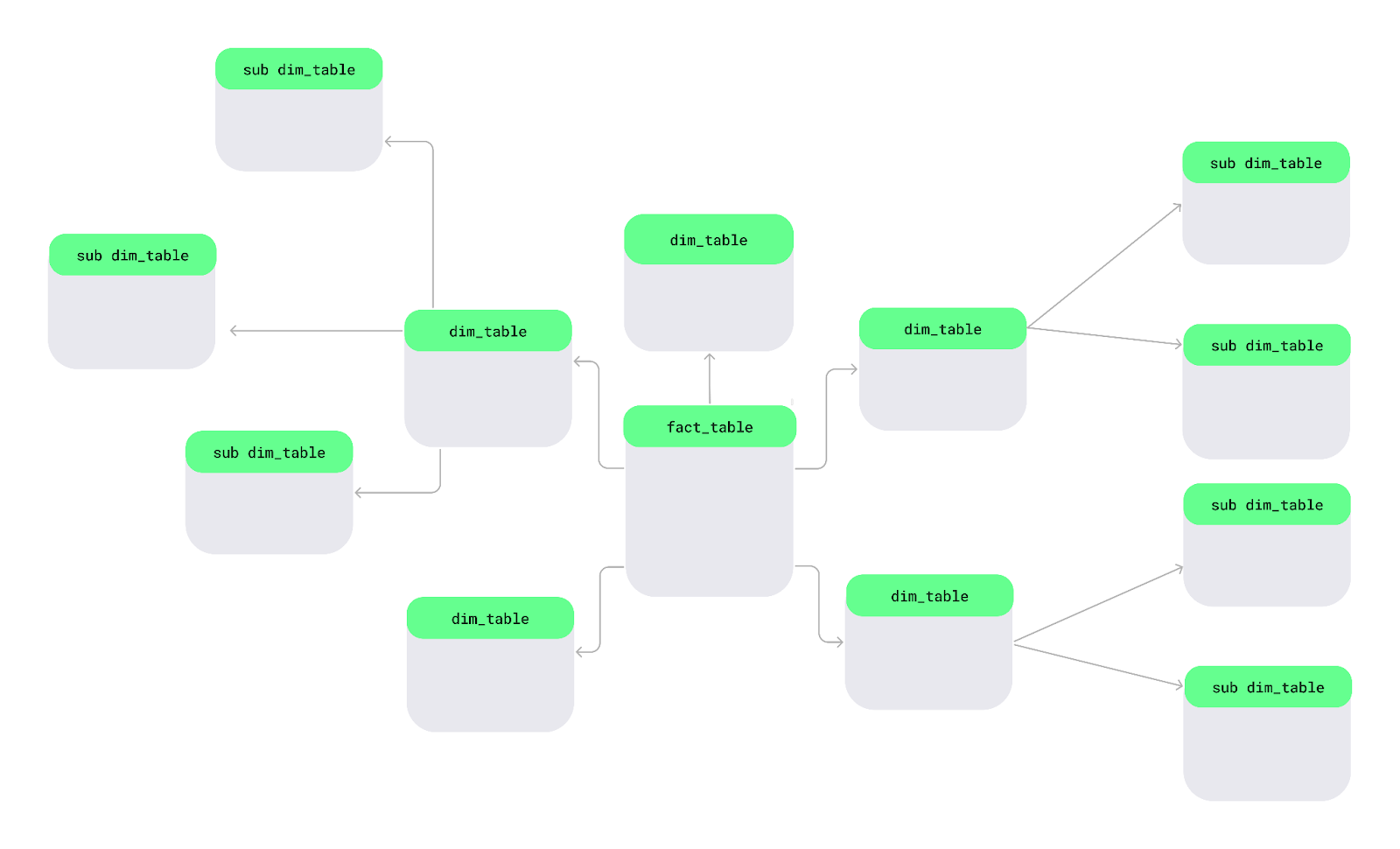
Diseño del esquema Snowflake. Imagen del autor.
Veamos las características clave del esquema Snowflake que lo diferencian de otros esquemas:
Electronics para cada producto, puedo almacenar la categoría en una tabla separada y vincularla a productos individuales.Entendamos esto con un sencillo diagrama esquemático de un Snowflake. En el centro se encuentra la tabla de hechos, que contiene datos medibles. Se conecta a tablas de dimensiones que describen los hechos, y estas tablas de dimensiones se ramifican a su vez en tablas de subdimensiones, formando una estructura similar a un Snowflake.
Por ejemplo, aquí he dividido la tabla Product enlas tablas Manufacturer y Category , y latabla Customer enlas tablas Transaction y Location :
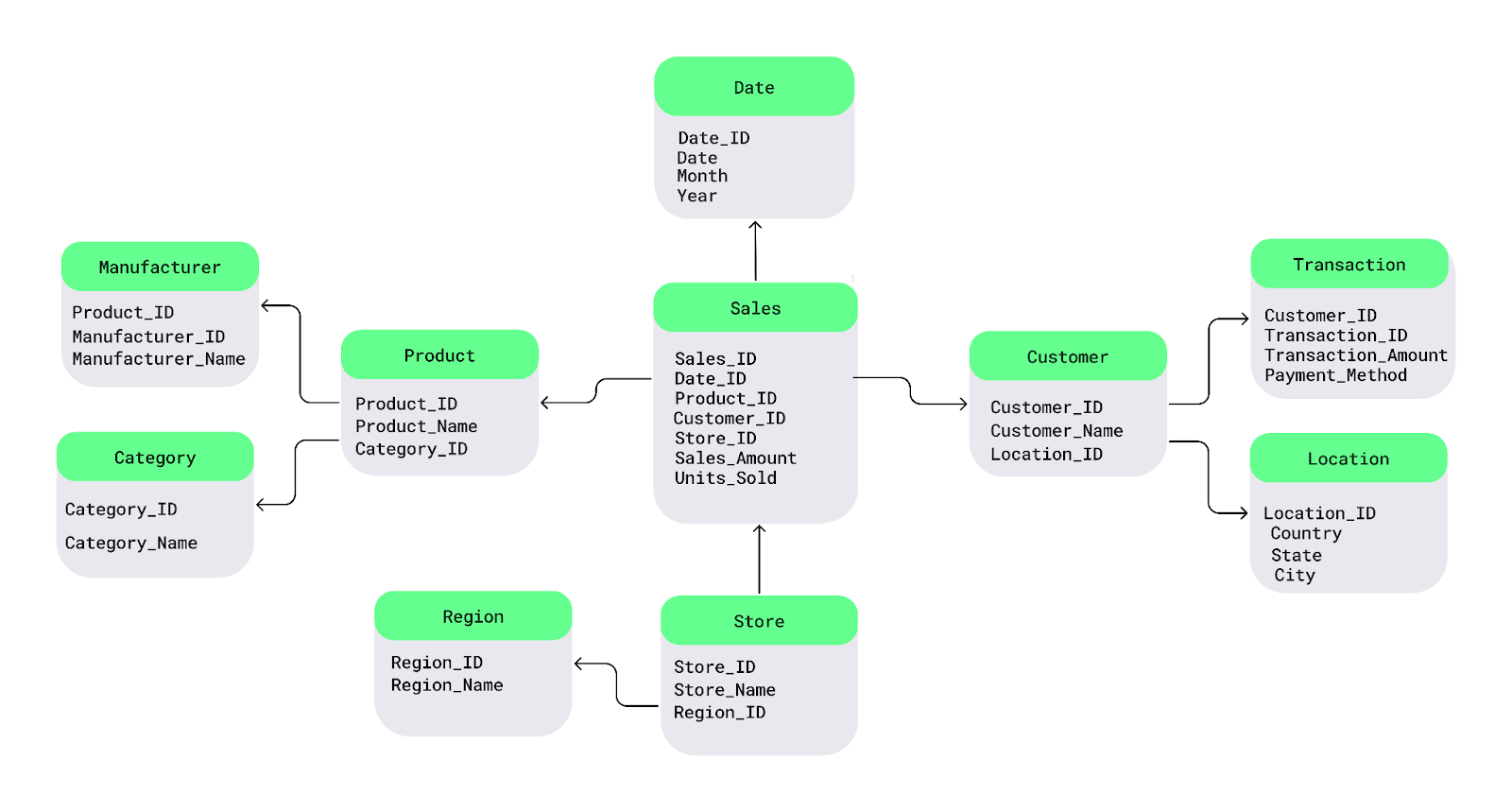
Ejemplo de esquema Snowflake. Imagen del autor.
Aquí tienes un ejemplo SQL que ilustra un esquema Snowflake en el que la Product tabla se normaliza aún más en Category y Manufacturer tablas:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);La siguiente consulta calcula las ventas totales por categoría de producto. Aunque implica más uniones que el esquema en estrella, es más eficiente en cuanto al almacenamiento:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Al igual que el esquema en estrella, el esquema Snowflake también tiene sus propias ventajas. Veamos cuáles son:
Sin embargo, a pesar de sus ventajas, también existen algunas limitaciones. Por ejemplo,las consultas pueden ser más lentas que porque hay más uniones entre tablas. Aparte de esto, la estructura multinivel es más difícil de diseñar y mantener que esquemas más simples como el esquema en estrella. Por lo tanto, hazlo solo si cuentas con un equipo de administradores de bases de datos con experiencia.
Te recomiendo que eches un vistazo al curso Diseño de bases de datos si deseas aprender más sobre cómo estructurar datos de forma eficiente para su análisis.
En proyectos reales, es habitual utilizar ambos patrones en diferentes capas para combinar las ventajas de ambos enfoques:
Esto permite a los equipos equilibrar la integridad y la gestión de los datos con un consumo rápido y sencillo de los análisis.
Tanto los esquemas en estrella como los esquemas Snowflake se utilizan ampliamente en el almacenamiento de datos, pero sus características únicas los hacen adecuados para diferentes necesidades. Veamos en qué se diferencian estos esquemas en cuanto a estructura, rendimiento, requisitos de almacenamiento y casos de uso.
Todas las tablas de dimensiones se conectan directamente a una tabla de hechos central en un esquema en estrella. Esto significa que todos tus datos de referencia están a un paso de tus datos principales, lo que facilita su comprensión y manejo.
En comparación, un esquema de Snowflake divide las tablas de dimensiones en tablas de subdimensiones más pequeñas y específicas. Por ejemplo, puedes tener tablas separadas para países, estados y ciudades en lugar de una sola tabla de ubicaciones. Si bien esto crea una estructura más organizada y detallada, también significa que se necesitan más conexiones (o uniones) para acceder a tus datos, lo que constituye una de las principales razones por las que el esquema Snowflake es más complejo que el esquema Star.
En lo que respecta a la velocidad, los esquemas en estrella suelen ser mejores. Dado que todas las tablas de dimensiones se conectan directamente a la tabla de hechos, las consultas suelen requerir menos uniones, lo que se traduce en un rendimiento más rápido. Supongamos que deseas analizar las ventas por región; en este caso, puedes utilizar el esquema en estrella para recuperar los datos con un procesamiento mínimo.
Por el contrario, los esquemas de Snowflake suelen ser más lentos porque hay que conectarse a través de varias tablas para recuperar los datos. Cada unión añade tiempo de procesamiento, lo que hace que los esquemas Snowflake sean menos eficientes para tareas que requieren resultados de consulta rápidos.
El curso «Unión de datos en SQL» es una excelente introducción para aprender a unir tablas, aplicar la teoría de conjuntos relacionales y trabajar con subconsultas.
Los esquemas en estrella ocupan más espacio de almacenamiento porque almacenan información redundante en tablas de dimensiones. Por ejemplo, si varios productos pertenecen a la misma categoría, el nombre de la categoría se repetirá para cada producto, lo que aumentará las necesidades de almacenamiento.
Sin embargo, los esquemas de Snowflake normalizan los datos para almacenar toda la información una sola vez. Por ejemplo, en lugar de repetir los nombres de las categorías, estos se almacenan en una tabla separada y se vinculan a la tabla de productos mediante claves externas. Este diseño ahorra espacio de almacenamiento, lo que lo hace ideal para conjuntos de datos de gran tamaño.
Los esquemas en estrella son ideales para sistemas de procesamiento analítico en línea (OLAP), generación de informes y tareas de inteligencia empresarial. Su simplicidad los hace perfectos para situaciones en las que la velocidad y la facilidad de uso son importantes, como la generación rápida de paneles de control o informes de ventas.
Los esquemas Snowflake se utilizan a menudo para análisis financieros o sistemas de gestión de relaciones con los clientes (CRM). En estos casos, organizar jerarquías detalladas y ahorrar espacio de almacenamiento es más importante que la velocidad de las consultas.
A continuación, se muestra una comparación rápida entre los esquemas de estrella y Snowflake para ayudarte a decidir cuál se adapta mejor a tus necesidades de datos. He resaltado las diferencias clave en esta tabla, centrándome en su estructura, rendimiento, almacenamiento y casos de uso:
|
Característica |
Esquema en estrella |
Esquema Snowflake |
Enfoque híbrido |
|
Estructura |
Tabla de hechos central vinculada a dimensiones desnormalizadas |
Tabla de hechos central vinculada a dimensiones normalizadas |
Modelo central normalizado, más mercados en forma de estrella o vistas desnormalizadas para consumo |
|
Complejidad |
Simple, con menos uniones |
Complejo, con más uniones. |
Medio, con más piezas móviles, pero cada capa sigue siendo más sencilla para su finalidad. |
|
Redundancia de datos |
Mayor redundancia debido a dimensiones desnormalizadas. |
Menor redundancia gracias a las dimensiones normalizadas. |
Redundancia media debido a la desnormalización selectiva |
|
Rendimiento de las consultas |
Consultas más rápidas gracias a una estructura más sencilla. |
Consultas más lentas debido a uniones adicionales |
Rápido para BI porque la capa de consumo está desnormalizada. |
|
Almacenamiento |
Requiere más almacenamiento debido a la redundancia. |
Requiere menos almacenamiento gracias a la normalización. |
Requiere un almacenamiento moderado, ya que los marts/vistas pueden añadir cierta duplicación. |
|
Facilidad de mantenimiento |
Más fácil de diseñar y mantener |
Más complejo de diseñar y mantener. |
Fácil de mantener, ya que los marts se pueden reconstruir a partir del núcleo controlado. |
|
Ideal para |
Conjuntos de datos pequeños y medianos |
Conjuntos de datos grandes y complejos |
Plataformas de datos modernas con necesidades tanto de gobernanza como de rendimiento de BI. |
Si lo que quieres principalmente es organizar tus datos de forma sencilla y rápida, el esquema en estrella sería perfecto. Aquí tienes cuándo puedes utilizarlo:
El esquema Snowflake es más adecuado para representar jerarquías y datos de referencia compartidos, especialmente cuando varios atributos dimensionales se repiten en muchas filas. Aquí tienes cuándo puedes utilizarlo:
En muchos almacenes de datos en la nube modernos, el almacenamiento es relativamente barato en comparación con la computación. Esto significa que el «almacenamiento adicional» de las dimensiones desnormalizadas suele ser menos importante que el coste computacional que supone escanear y unir datos.
A la hora de elegir entre estrella y Snowflake, ten en cuenta el modelo de precios de tu plataforma (computación frente a almacenamiento), la concurrencia de tus consultas y si puedes utilizar el almacenamiento en caché o las vistas materializadas para reducir los costes de las consultas.
En este blog, he abordado las diferencias entre los esquemas estrella y Snowflake, sus puntos fuertes y cuándo utilizar cada uno de ellos. ¡Espero que hayas comprendido bien y hayas obtenido consejos prácticos para tu trabajo! Si deseas obtener más información, consulta estos recursos en DataCamp:
Cursos de ingeniería de datos
Curso
Curso
Curso
blog
Gus Frazer
14 min
blog
Tim Lu
11 min
blog
Mona Khalil
5 min
blog
Arun Nanda
15 min
Tutorial
Amberle McKee
Tutorial
Allan Ouko
