
Curso
Introdução à Engenharia de Dados
4 h
127.6K
Se você trabalha com warehouses de dados, sabe como é importante organizar os dados de um jeito eficiente e fácil de lidar. Mas você já pensou qual esquema de banco de dados é o mais adequado para suas necessidades? Tem duas estruturas principais que você pode usar pra isso: o esquema estrela e o esquema Snowflake.
O esquema em estrela é simples e rápido — ideal quando você precisa extrair dados para análise rapidamente. Por outro lado, o esquema Snowflake é mais detalhado. Ele prioriza a eficiência do armazenamento e o gerenciamento de relações complexas de dados.
Neste artigo, vou te mostrar como funcionam esses esquemas, falar sobre as diferenças entre eles e explicar suas vantagens. No final, você vai saber onde cada esquema se encaixa e como decidir qual é o melhor para seus projetos de dados.
Um esquema em estrela é uma forma de organizar dados em um banco de dados, especialmenteem warehouses, para facilitar e agilizar a análise. No centro, tem uma tabela principal chamadatabela de fatos ( ), que guarda dados mensuráveis, como vendas ou receita. Ao redor dela estãotabelas de dimensões , que adicionam detalhes como nomes de produtos, informações de clientes ou datas. Esse layout tem um formato parecido com uma estrela.
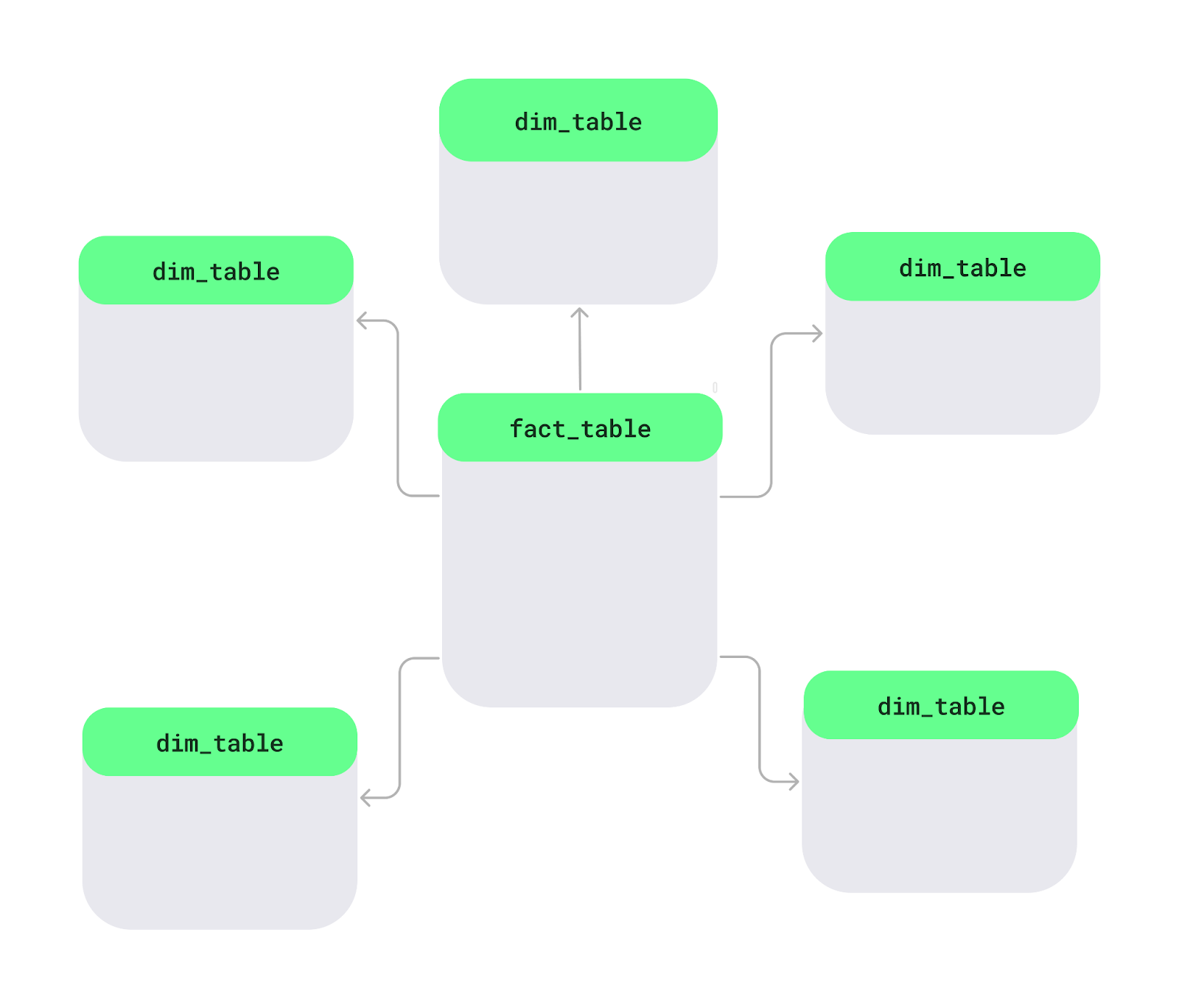
Layout do esquema em estrela. Imagem do autor.
Vamos dar uma olhada nas principais características do esquema em estrela:
Vamos entender isso com um diagrama simples do esquema em estrela. Atabela de fatos Sales está no centro. Ele guarda os dados numéricos que você quer analisar, tipo vendas ou lucros. Conectadas a ela estãotabelas de dimensões com detalhes descritivos, como nomes de produtos, localização do cliente ou datas:
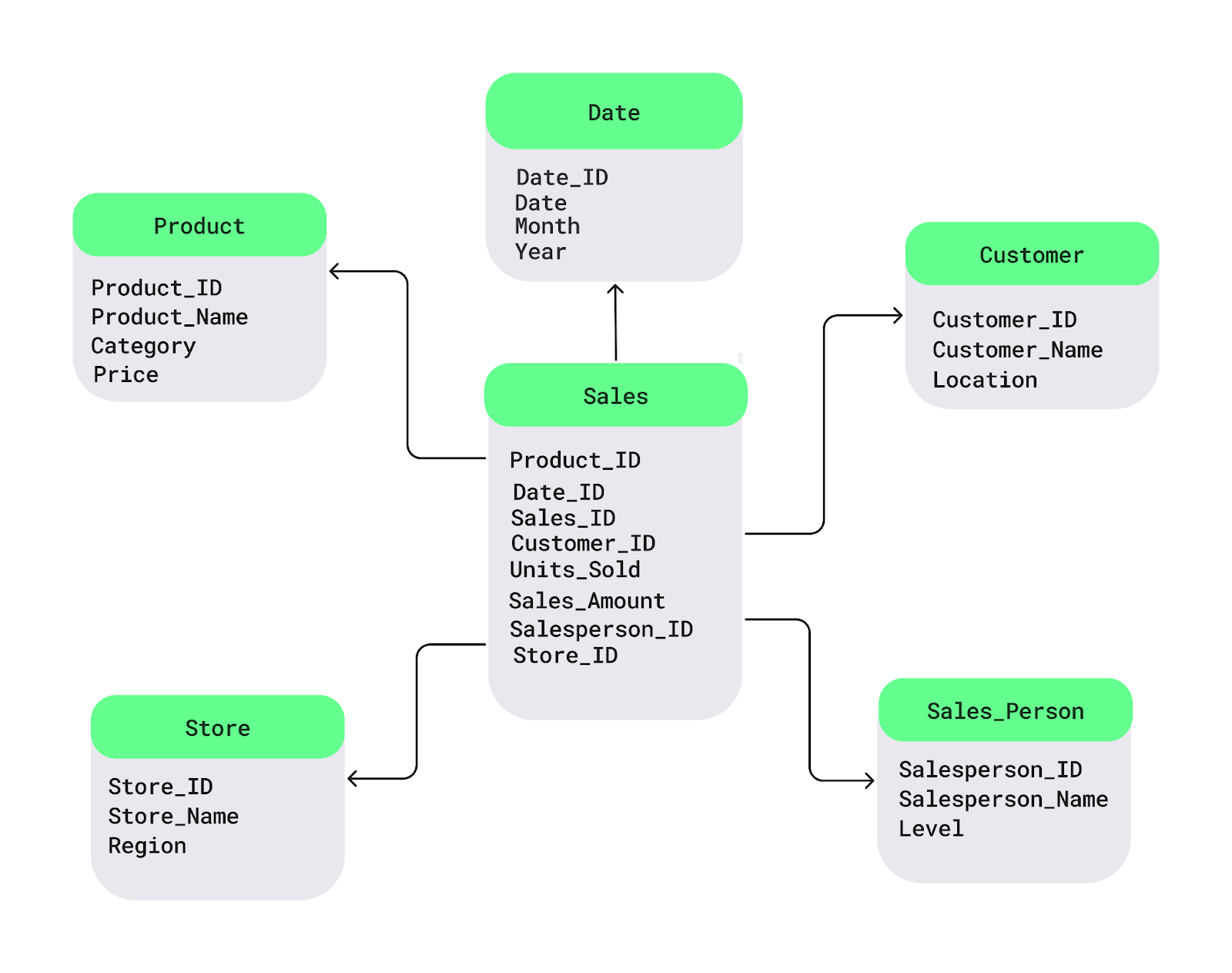
Exemplo de esquema em estrela. Imagem do autor.
Aqui está um exemplo simples de SQL para configurar um esquema em estrela com uma Sales tabela de fatos e tabelas de dimensões para Product, Customere Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Esse layout agiliza as consultas porque não tem junções complicadas. Por exemplo, a consulta a seguir recupera as vendas totais agrupadas por localização do cliente, usando as junções simples do esquema em estrela:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Mas, você vai ter que aceitar um pouco de redundância de dados, já que as tabelas de dimensões podem ter informações repetidas.
Agora que você já sabe o que é o esquema em estrela, vamos ver por que ele se destaca:
Apesar de todas as vantagens, o esquema em estrela tem uma desvantagem. Como eu falei antes, por causa da desnormalização, as tabelas de dimensões geralmente têm informações repetidas, o que aumenta o uso de armazenamento. Por exemplo, se vários produtos pertencem à mesma categoria, o nome de cada produto pode se repetir, ocupando mais espaço de armazenamento.
Um esquema de Snowflake é outra maneira de organizar dados. Nesse esquema, as tabelas de dimensões são divididas em subdimensões menores para manter os dados mais organizados e detalhados — assim como flocos de neve em um grande lago.
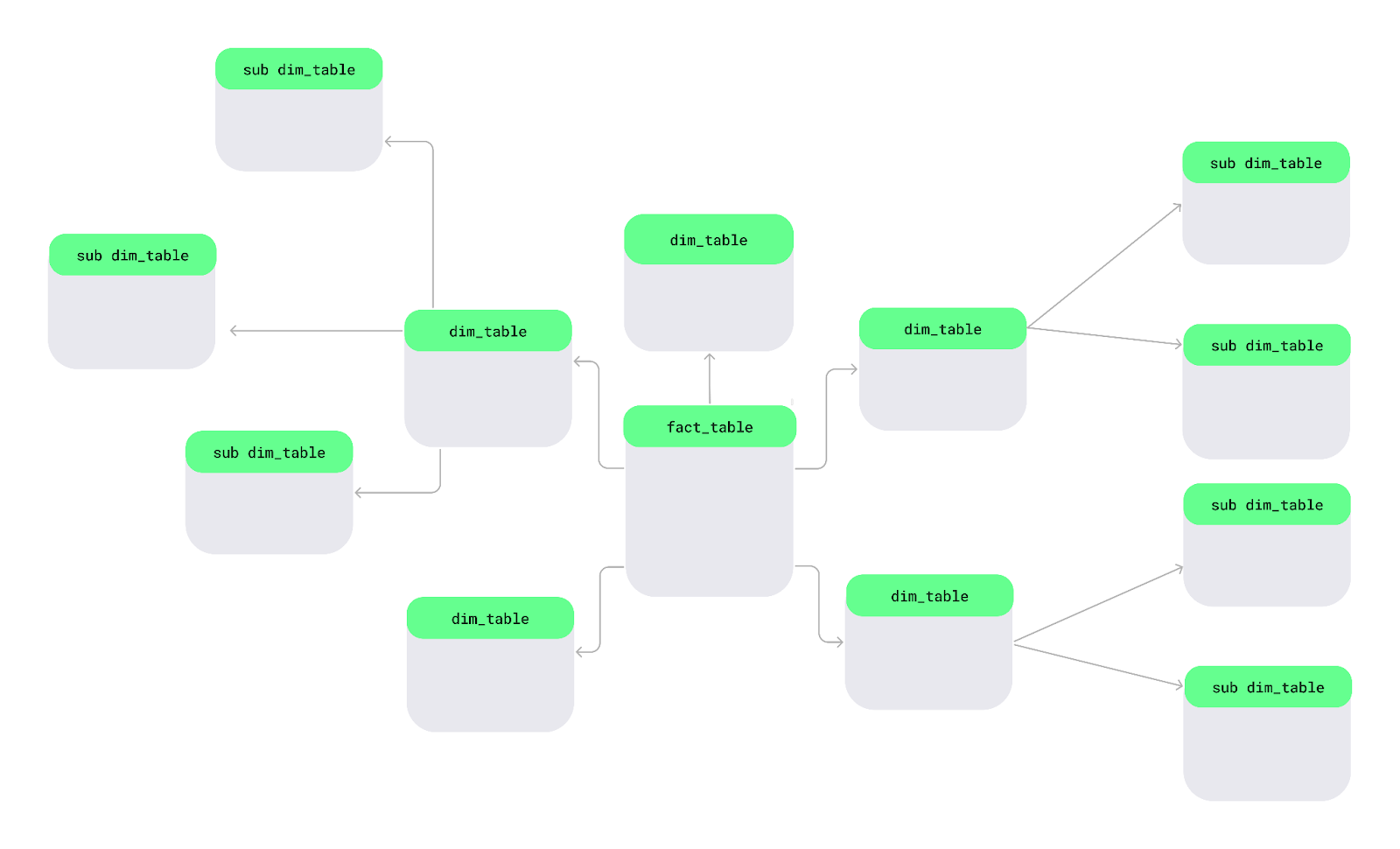
Esquema de Snowflake. Imagem do autor.
Vamos dar uma olhada nas principais características do esquema Snowflake que o diferenciam de outros esquemas:
Electronics para cada produto, posso guardar a categoria numa tabela separada e ligá-la a produtos individuais.Vamos entender isso com um diagrama simples do esquema do Snowflake. No centro está a tabela de fatos, que contém dados mensuráveis. Ele se conecta a tabelas de dimensões que descrevem os fatos, e essas tabelas de dimensões se ramificam em tabelas de subdimensões, formando uma estrutura semelhante a um Snowflake.
Por exemplo, aqui eu dividi atabela Product em Manufacturer e Category e atabela Customer em Transaction e Location :
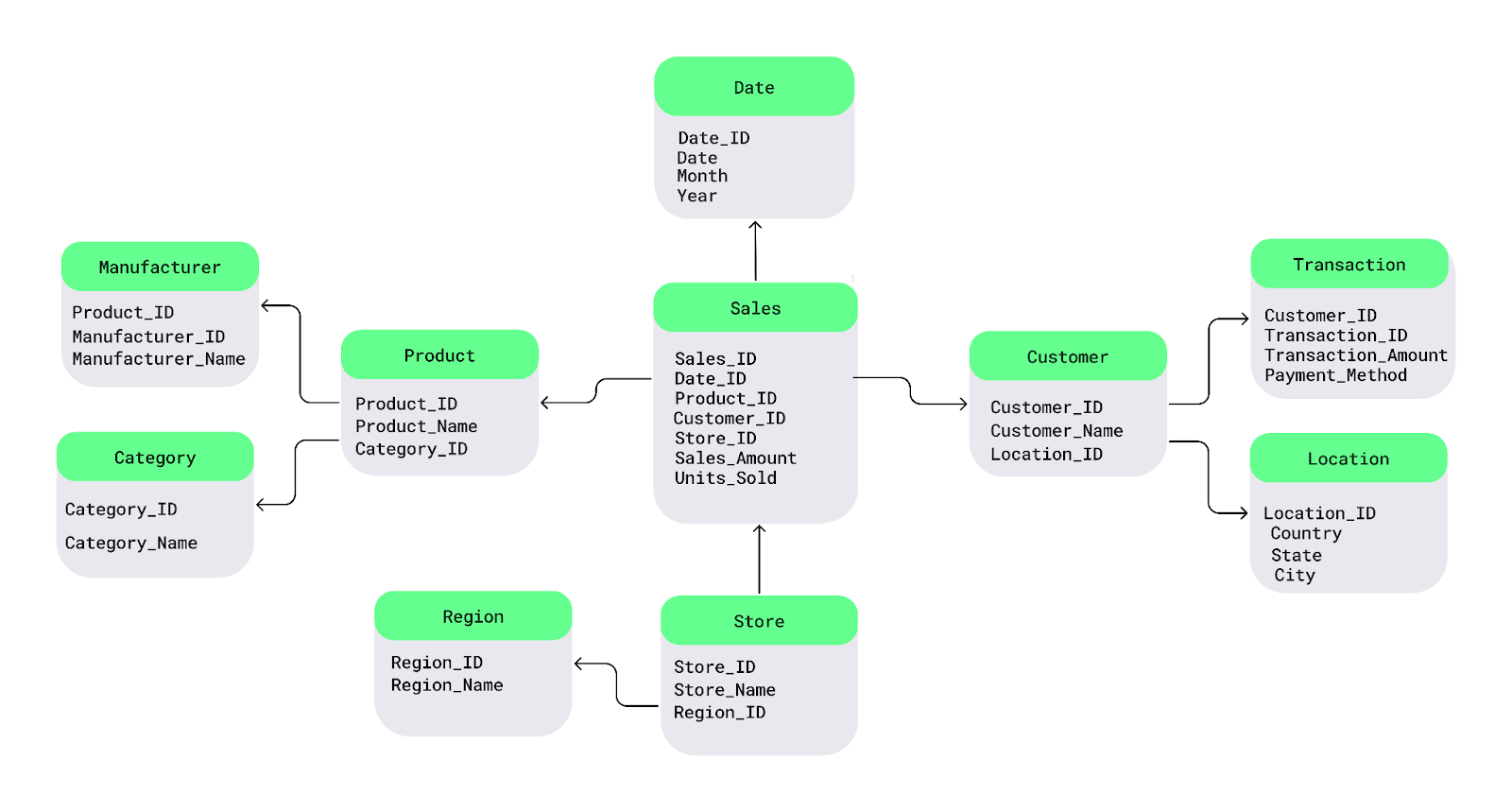
Exemplo de esquema Snowflake. Imagem do autor.
Aqui está um exemplo de SQL que mostra um esquema Snowflake, onde a Product tabela é ainda mais normalizada em Category e Manufacturer tabelas:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);A consulta a seguir calcula o total de vendas por categoria de produto. Embora envolva mais junções do que o esquema em estrela, é mais eficiente em termos de armazenamento:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Assim como o esquema em estrela, o esquema Snowflake também tem suas próprias vantagens. Vamos ver quais são:
Mas, mesmo com todas essas vantagens, também tem algumas limitações. Por exemplo,consultas podem ser mais lentas do que porque há mais junções entre as tabelas. Além disso, a estrutura multinível é maisdifícil de projetar e manter do que esquemas mais simples, como o esquema em estrela. Então, só faça isso se você tiver uma equipe experiente de administradores de banco de dados.
Recomendo conferir o curso de Design de Banco de Dados se você quiser saber mais sobre como organizar dados de forma eficiente para análise.
Em projetos reais, é comum usar os dois padrões em camadas diferentes para juntar os pontos fortes das duas abordagens:
Isso permite que as equipes equilibrem a integridade e a governança dos dados com o uso rápido e simples de análises.
Os esquemas em estrela e em Snowflake são bem usados em warehouse de dados, mas suas características únicas fazem com que sejam mais adequados para diferentes necessidades. Vamos ver como esses esquemas diferem em estrutura, desempenho, requisitos de armazenamento e casos de uso.
Todas as tabelas de dimensões se conectam diretamente a uma tabela de fatos central em um esquema em estrela. Isso quer dizer que todos os seus dados de referência estão a um passo dos seus dados principais, facilitando a compreensão e o trabalho.
Comparando, um esquema de Snowflake divide as tabelas de dimensões em tabelas de subdimensões menores e mais específicas. Por exemplo, você pode ter tabelas separadas para países, estados e cidades, em vez de uma tabela única de localização. Embora isso crie uma estrutura mais organizada e detalhada, também significa que são necessárias mais conexões (ou junções) para acessar seus dados — uma das principais razões pelas quais o esquema Snowflake é mais complexo do que o esquema Star.
Quando se trata de velocidade, os esquemas em estrela costumam ser melhores. Como todas as tabelas de dimensões se conectam diretamente à tabela de fatos, as consultas geralmente precisam de menos junções, o que significa um desempenho mais rápido. Digamos que você queira analisar as vendas por região — nesse caso, você pode usar o esquema em estrela para pegar os dados com o mínimo de processamento.
Por outro lado, os esquemas Snowflake costumam ser mais lentos porque você precisa se conectar por meio de várias tabelas para recuperar os dados. Cada junção aumenta o tempo de processamento, tornando os esquemas Snowflake menos eficientes para tarefas que exigem resultados rápidos de consulta.
O curso Joining Data in SQL é uma excelente introdução para aprender como unir tabelas, aplicar a teoria dos conjuntos relacionais e trabalhar com subconsultas.
Os esquemas em estrela ocupam mais espaço de armazenamento porque guardam informações redundantes nas tabelas de dimensões. Por exemplo, se vários produtos pertencem à mesma categoria, o nome da categoria vai se repetir para cada produto, aumentando as necessidades de armazenamento.
Mas os esquemas de Snowflake normalizam os dados pra guardar todas as informações só uma vez. Por exemplo, em vez de repetir os nomes das categorias, eles são guardados numa tabela separada e ligados à tabela de produtos usando chaves estrangeiras. Esse design economiza espaço de armazenamento, sendo ideal para grandes conjuntos de dados.
Os esquemas em estrela são perfeitos para sistemas de processamento analítico online (OLAP), relatórios e tarefas de inteligência empresarial. A simplicidade deles faz com que sejam perfeitos pra situações em que a rapidez e a facilidade de uso são importantes, tipo criar painéis ou relatórios de vendas rapidinho.
Os esquemas Snowflake são frequentemente usados para análise financeira ou sistemas de gestão de relacionamento com o cliente (CRM). Organizar hierarquias detalhadas e economizar espaço de armazenamento são mais importantes do que a velocidade de consulta nesses casos.
Aqui vai uma comparação rápida entre os esquemas estrela e Snowflake pra te ajudar a decidir qual deles é mais adequado pras suas necessidades de dados. Destaquei as principais diferenças nesta tabela, focando na estrutura, desempenho, armazenamento e casos de uso:
|
Recurso |
Esquema em estrela |
Esquema Snowflake |
Abordagem híbrida |
|
Estrutura |
Tabela de fatos central ligada a dimensões desnormalizadas |
Tabela de fatos central ligada a dimensões normalizadas |
Modelo central normalizado, mais marts em forma de estrela ou visualizações desnormalizadas para consumo |
|
Complexidade |
Simples, com menos junções |
Complexo, com mais junções |
Médio, com mais partes móveis, mas cada camada continua mais simples para o seu propósito. |
|
Redundância de dados |
Maior redundância por causa das dimensões desnormalizadas |
Menos redundância por causa das dimensões normalizadas |
Redundância média por causa da desnormalização seletiva |
|
Desempenho da consulta |
Consultas mais rápidas por causa da estrutura mais simples |
Consultas mais lentas por causa de junções adicionais |
Rápido para BI porque a camada de consumo é desnormalizada |
|
Armazenamento |
Precisa de mais espaço de armazenamento por causa da redundância |
Precisa de menos espaço de armazenamento por causa da normalização |
Precisa de um armazenamento moderado porque os marts/visualizações podem adicionar alguma duplicação. |
|
Facilidade de manutenção |
Mais fácil de projetar e manter |
Mais complicado de projetar e manter |
Fácil de manter, já que os marts podem ser reconstruídos a partir do núcleo controlado |
|
Ideal para |
Conjuntos de dados de pequeno a médio porte |
Conjuntos de dados grandes e complexos |
Plataformas de dados modernas com necessidades de governança e desempenho de BI |
Se você quer principalmente organizar seus dados de forma simples e rápida, o esquema em estrela seria perfeito. Veja quando você pode usar:
O esquema Snowflake é mais legal para representar hierarquias e dados de referência compartilhados, principalmente quando vários atributos de dimensão se repetem em várias linhas. Veja quando você pode usar:
Em muitos armazéns de dados em nuvem modernos, o armazenamento é relativamente barato em comparação com a computação. Isso quer dizer que o “armazenamento extra” das dimensões desnormalizadas geralmente é menos importante do que o custo de computação da varredura e da junção de dados.
Ao escolher entre estrela e Snowflake, pense no modelo de preços da sua plataforma (computação x armazenamento), na simultaneidade das consultas e se você pode usar cache/visualizações materializadas para manter os custos das consultas baixos.
Neste blog, falei sobre as diferenças entre os esquemas estrela e Snowflake, seus pontos fortes e quando usar cada um deles. Espero que você tenha entendido tudo direitinho e tenha dicas práticas para o seu trabalho! Se você quiser saber mais, dá uma olhada nesses recursos no DataCamp:
Cursos de Engenharia de Dados
Curso
Curso
Curso
blog
Matt Crabtree
11 min
blog
Mona Khalil
5 min
blog
Kurtis Pykes
11 min
blog
Nisha Arya Ahmed
15 min
blog
Austin Chia
8 min
Tutorial
Zoumana Keita
