
Cursus
Introductie tot Data Engineering
4 Hr
128.3K
Als je met datawarehouses werkt, weet je hoe belangrijk het is om data zo te structureren dat die efficiënt en gemakkelijk te verwerken is. Maar heb je je ooit afgevraagd welk databaseschema het beste bij jouw behoeften past? Er zijn twee grote raamwerken die je hiervoor kunt gebruiken: het starschema en het snowflakeschema.
Het starschema is eenvoudig en snel — ideaal wanneer je snel data wilt ophalen voor analyse. Het snowflakeschema is daarentegen gedetailleerder. Het geeft prioriteit aan opslagefficiëntie en het beheren van complexe datarelaties.
In dit artikel neem ik je mee door de structuren van deze schema’s, licht ik hun verschillen uit en zet ik hun voordelen op een rij. Aan het eind weet je waar elk schema past en hoe je beslist welk schema het beste is voor jouw dataprojecten.
Een starschema is een manier om data in een database te organiseren, vooral in datawarehouses, om het analyseren makkelijker en sneller te maken. In het midden staat een hoofdtafel, de feittabel, die meetbare data bevat zoals verkoop of omzet. Daaromheen staan dimensietabellen, die details toevoegen zoals productnamen, klantinformatie of datums. Deze opzet vormt een stervormige structuur.
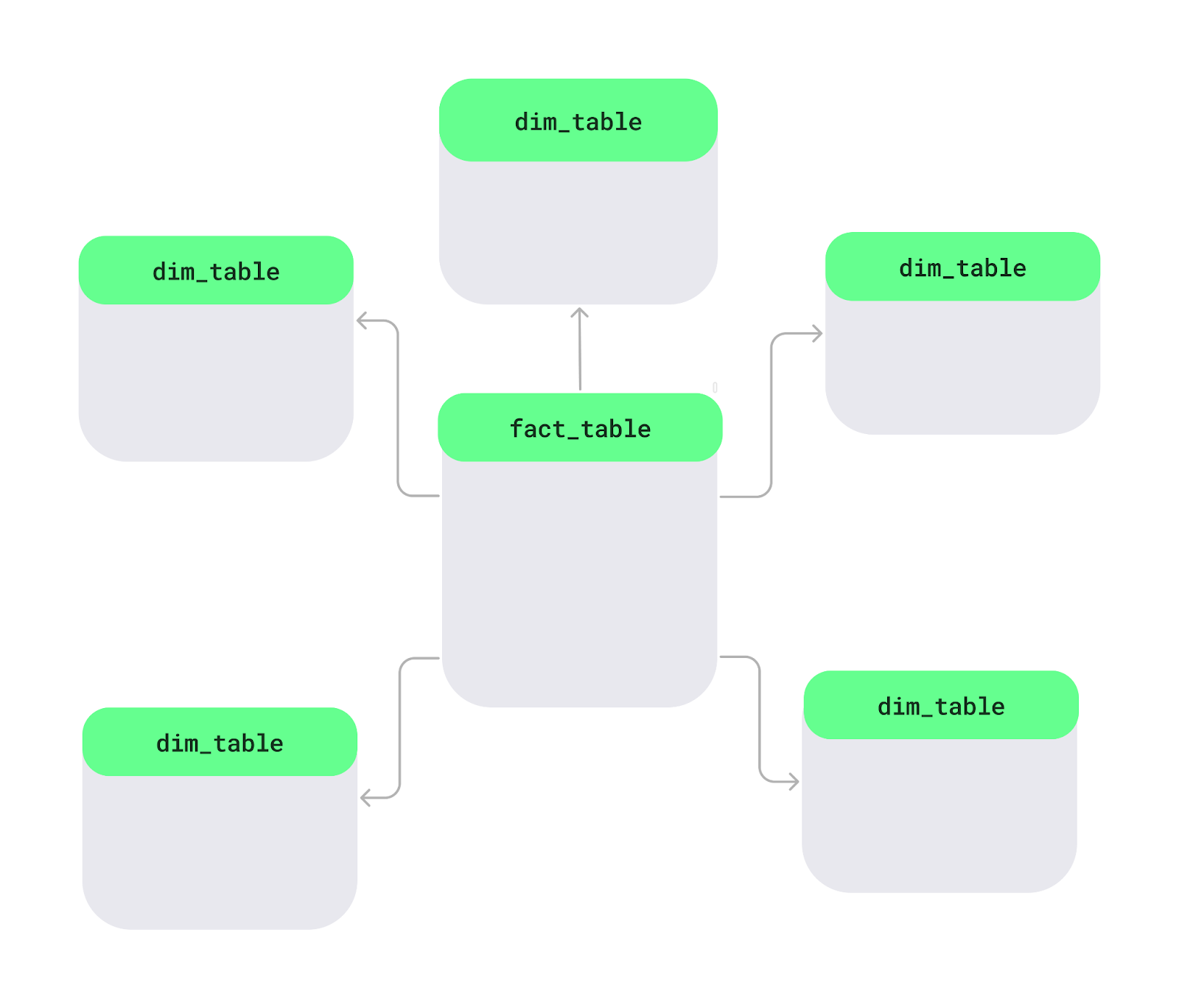
Indeling van een starschema. Afbeelding door de auteur.
Dit zijn de belangrijkste kenmerken van het starschema:
Laten we dit begrijpen met een eenvoudig diagram van een starschema. De feittabel Sales staat in het midden. Deze bevat de numerieke data die je wilt analyseren, zoals verkopen of winst. Daaraan gekoppeld zijn dimensietabellen met beschrijvende details, zoals productnamen, klantlocaties of datums:
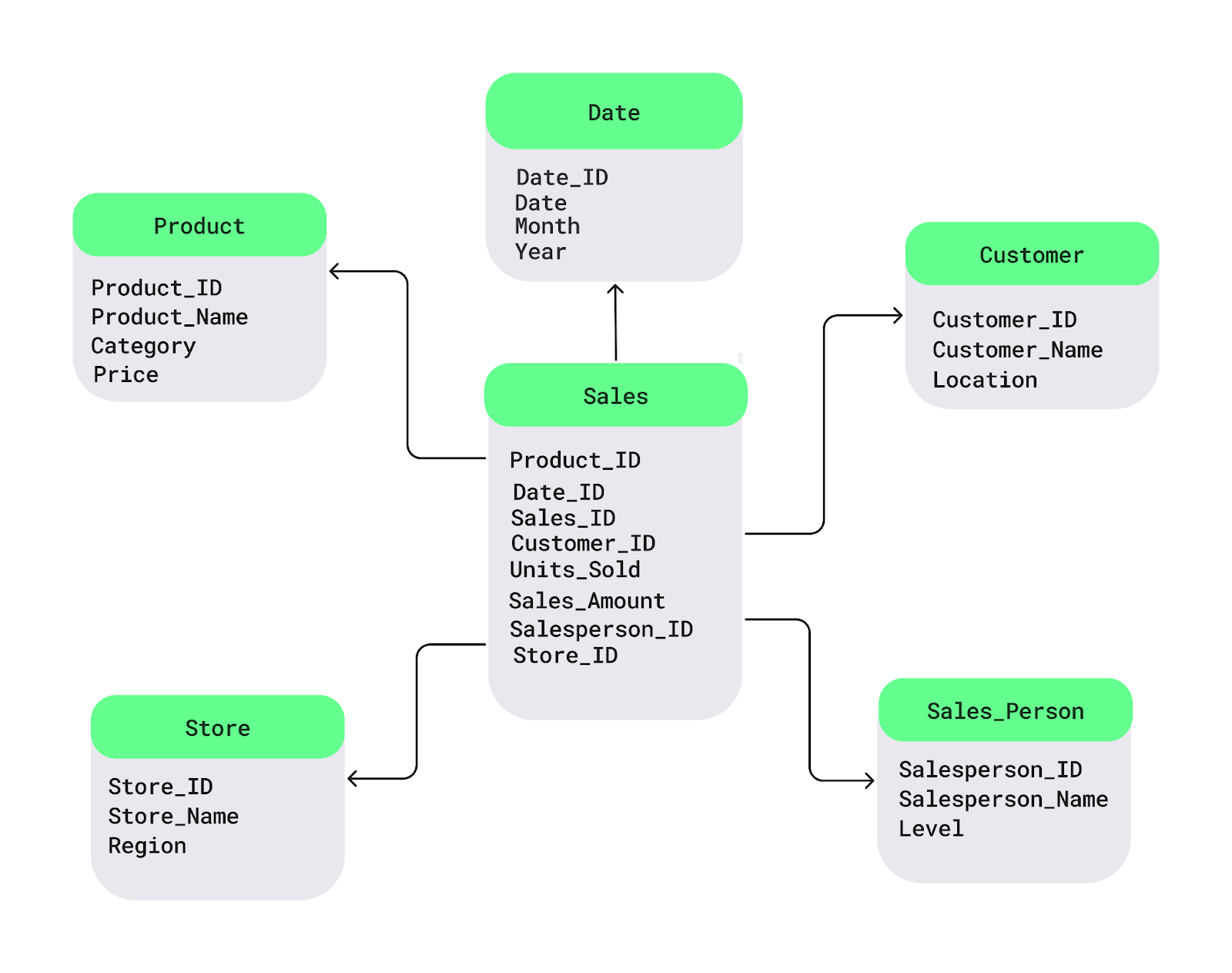
Voorbeeld van een starschema. Afbeelding door de auteur.
Hier is een eenvoudig SQL-voorbeeld voor het opzetten van een starschema met een Sales-feittabel en dimensietabellen voor Product, Customer en Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Deze indeling versnelt queries omdat er geen complexe joins zijn. De volgende query haalt bijvoorbeeld de totale verkoop op, gegroepeerd per klantlocatie, waarbij de eenvoudige joins van het starschema worden benut:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Je moet echter wel enige dataduplicatie accepteren, omdat de dimensietabellen herhaalde informatie kunnen bevatten.
Nu je weet wat een starschema is, bekijken we waarom het eruit springt:
Ondanks alle voordelen heeft het starschema ook een nadeel. Zoals ik eerder noemde, bevatten dimensietabellen door de gedenormaliseerde opzet vaak herhaalde informatie, wat het opslaggebruik verhoogt. Als meerdere producten bijvoorbeeld tot dezelfde categorie behoren, kan de categorienaam bij elk product terugkomen, wat extra opslagruimte kost.
Een snowflakeschema is een andere manier om data te organiseren. In dit schema worden dimensietabellen opgesplitst in kleinere subdimensies om data geordender en gedetailleerder te houden — net als sneeuwvlokken in een groot meer.
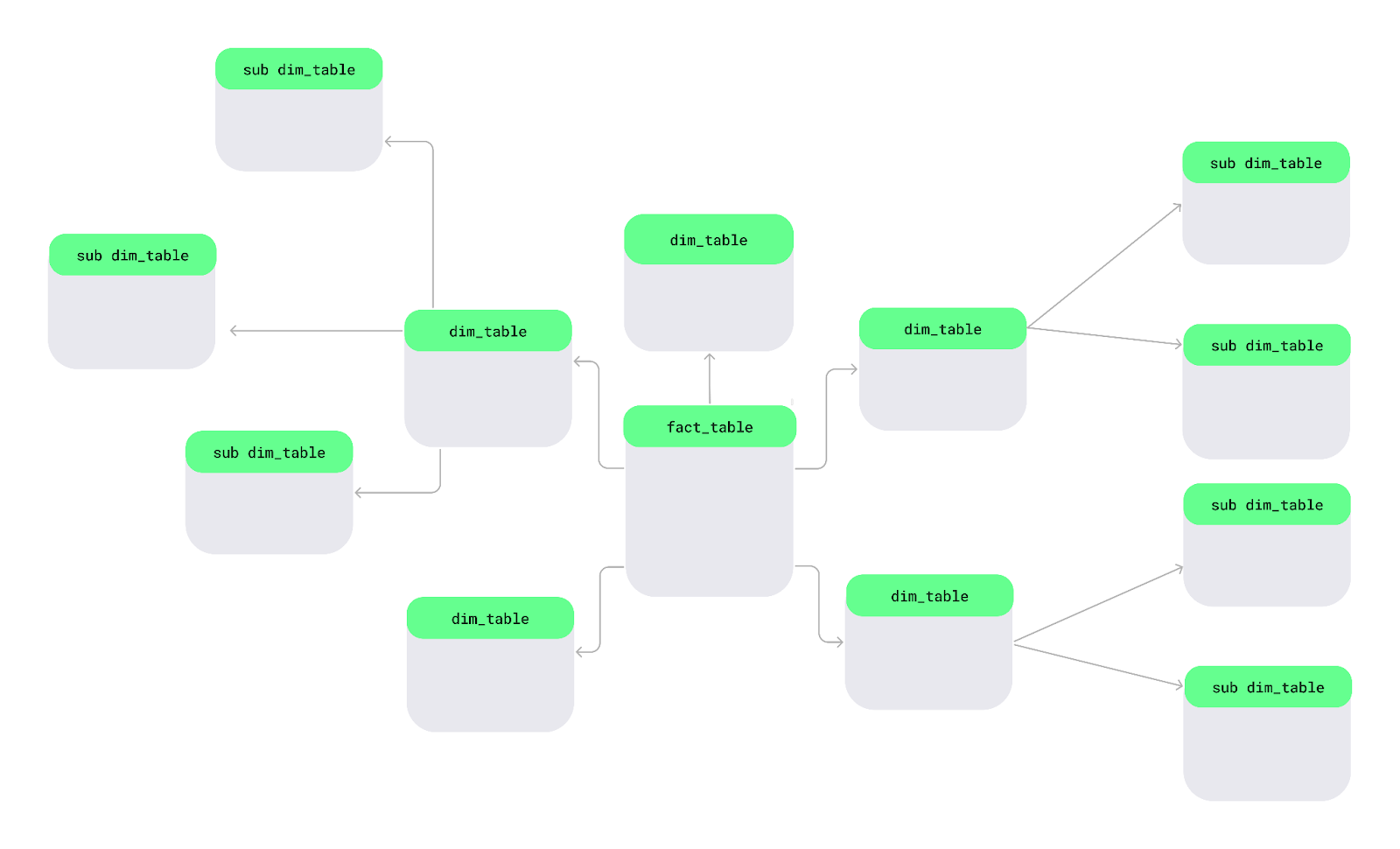
Indeling van een snowflakeschema. Afbeelding door de auteur.
Dit zijn de belangrijkste kenmerken van het snowflakeschema die het onderscheiden van andere schema’s:
Electronics voor elk product te herhalen, kan ik de categorie in een aparte tabel opslaan en die koppelen aan afzonderlijke producten.Laten we dit begrijpen met een eenvoudig diagram van een snowflakeschema. In het midden staat de feittabel met meetbare data. Deze is verbonden met dimensietabellen die de feiten beschrijven, en die dimensietabellen vertakken verder in subdimensietabellen, wat samen een sneeuwvlokachtige structuur vormt.
Zo heb ik hier de tabel Product opgesplitst in tabellen Manufacturer en Category en de tabel Customer in tabellen Transaction en Location opgesplitst:
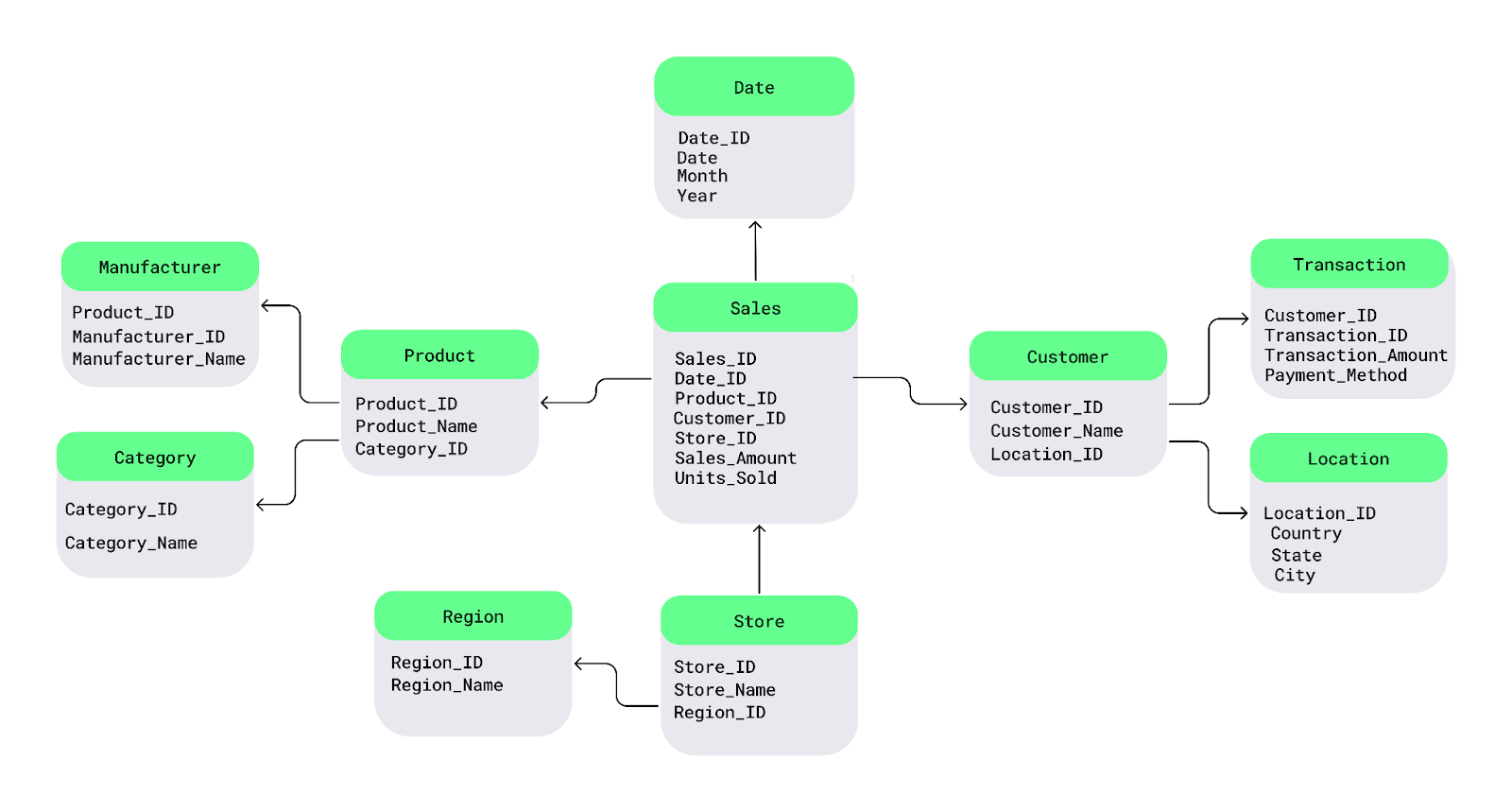
Voorbeeld van een snowflakeschema. Afbeelding door de auteur.
Hier is een SQL-voorbeeld van een snowflakeschema waarin de tabel Product verder is genormaliseerd naar de tabellen Category en Manufacturer:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);De volgende query berekent de totale verkoop per productcategorie. Hoewel deze meer joins bevat dan het starschema, is het opslagzuiniger:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Net als het starschema heeft het snowflakeschema zijn eigen voordelen. Dit zijn ze:
Toch zijn er, ondanks de voordelen, ook enkele beperkingen. Zo kunnen queries langzamer zijn omdat er meer joins tussen tabellen nodig zijn. Daarnaast is de meerlagige structuur lastiger te ontwerpen en te onderhouden dan eenvoudigere schema’s zoals het starschema. Kies hiervoor dus alleen als je een ervaren DBA-team hebt.
Ik raad je aan om de Database Design-cursus te bekijken als je meer wilt leren over het efficiënt structureren van data voor analyse.
In echte projecten is het gebruikelijk om beide patronen op verschillende lagen te combineren om de sterke punten van beide benaderingen te benutten:
Zo kunnen teams dataintegriteit en governance in balans brengen met snelle, eenvoudige analytics-consumptie.
Zowel star- als snowflakeschema’s worden veel gebruikt in datawarehousing, maar hun unieke eigenschappen maken ze geschikt voor verschillende behoeften. Laten we kijken hoe deze schema’s verschillen qua structuur, performance, opslagvereisten en use cases.
In een starschema zijn alle dimensietabellen direct verbonden met één centrale feittabel. Dit betekent dat al je referentiedata één stap verwijderd is van je hoofddata, wat het begrijpen en werken ermee eenvoudig maakt.
Ter vergelijking: een snowflakeschema splitst dimensietabellen op in kleinere, specifiekere subdimensietabellen. Je kunt bijvoorbeeld aparte tabellen hebben voor landen, staten/provincies en steden in plaats van één locatietabel. Hoewel dit een geordendere en gedetailleerdere structuur oplevert, zijn er ook meer verbindingen (of joins) nodig om je data te benaderen — een belangrijke reden waarom het snowflakeschema complexer is dan het starschema.
Als het om snelheid gaat, zijn starschema’s vaak beter. Omdat alle dimensietabellen direct met de feittabel zijn verbonden, vereisen queries meestal minder joins, wat zorgt voor snellere prestaties. Stel dat je verkoop per regio wilt analyseren — dan kun je met het starschema de data met minimale verwerking ophalen.
Snowflakeschema’s zijn daarentegen vaak langzamer, omdat je door meerdere tabellen heen moet koppelen om de data op te halen. Elke join voegt verwerkingstijd toe, waardoor snowflakeschema’s minder efficiënt zijn voor taken die snelle queryresultaten vereisen.
De cursus Joining Data in SQL is een uitstekende inleiding om te leren hoe je tabellen samenvoegt, relationele verzamelingenleer toepast en met subqueries werkt.
Starschema’s nemen meer opslagruimte in beslag omdat ze redundante informatie in dimensietabellen opslaan. Als meerdere producten bijvoorbeeld tot dezelfde categorie behoren, wordt de categorienaam voor elk product herhaald, wat de opslagbehoefte vergroot.
Snowflakeschema’s normaliseren data zodat alle informatie slechts één keer wordt opgeslagen. In plaats van categorienamen te herhalen, worden die in een aparte tabel opgeslagen en met de producttabel verbonden via foreign keys. Dit ontwerp bespaart opslagruimte en is ideaal voor grote datasets.
Starschema’s zijn ideaal voor online analytical processing (OLAP)-systemen, rapportage en business intelligence-taken. Hun eenvoud maakt ze perfect voor scenario’s waar snelheid en gebruiksgemak belangrijk zijn, zoals het genereren van snelle dashboards of verkooprapporten.
Snowflakeschema’s worden vaak gebruikt voor financiële analyse of customer relationship management (CRM)-systemen. Het organiseren van gedetailleerde hiërarchieën en het besparen van opslagruimte is in zulke gevallen belangrijker dan querysnelheid.
Hier is een snelle vergelijking van het star- en snowflakeschema om je te helpen bepalen welk schema het beste bij jouw databehoeften past. Ik heb de belangrijkste verschillen in deze tabel uitgelicht, met focus op structuur, performance, opslag en use cases:
|
Kenmerk |
Starschema |
Snowflakeschema |
Hybride aanpak |
|
Structuur |
Centrale feittabel gekoppeld aan gedenormaliseerde dimensies |
Centrale feittabel gekoppeld aan genormaliseerde dimensies |
Genormaliseerd kernmodel, plus starvormige marts of gedenormaliseerde views voor consumptie |
|
Complexiteit |
Eenvoudig, met minder joins |
Complex, met meer joins |
Gemiddeld, met meer bewegende delen, maar elke laag blijft eenvoudiger voor zijn doel |
|
Dataduplicatie |
Meer duplicatie door gedenormaliseerde dimensies |
Minder duplicatie door genormaliseerde dimensies |
Gemiddelde duplicatie door selectieve denormalisatie |
|
Queryprestaties |
Snellere queries dankzij eenvoudigere structuur |
Langzamere queries door extra joins |
Snel voor BI omdat de consumptielaag gedenormaliseerd is |
|
Opslag |
Meer opslag nodig door duplicatie |
Minder opslag nodig door normalisatie |
Gemiddelde opslag, omdat marts/views enige duplicatie kunnen toevoegen |
|
Onderhoudsgemak |
Makkelijker te ontwerpen en te onderhouden |
Complexer te ontwerpen en te onderhouden |
Makkelijk te onderhouden, omdat marts opnieuw kunnen worden opgebouwd vanuit de gecontroleerde kern |
|
Het meest geschikt voor |
Kleine tot middelgrote datasets |
Grote en complexe datasets |
Moderne dataplatformen met zowel governance- als BI-prestatiebehoeften |
Als je je data vooral eenvoudig en snel wilt organiseren, is het starschema perfect. Dit zijn momenten waarop je het kunt gebruiken:
Het snowflakeschema is geschikter voor het weergeven van hiërarchieën en gedeelde referentiedata, vooral wanneer meerdere dimensiekenmerken zich over veel rijen herhalen. Dit zijn momenten waarop je het kunt gebruiken:
In veel moderne clouddatawarehouses is opslag relatief goedkoop vergeleken met compute. Dat betekent dat de “extra opslag” door gedenormaliseerde dimensies vaak minder belangrijk is dan de compute-kosten van het scannen en joinen van data.
Kies je tussen star en snowflake, houd dan rekening met het prijsmodel van je platform (compute vs. storage), je queryconcurrentie en of je caching/materiële views kunt gebruiken om querykosten laag te houden.
In deze blog heb ik de verschillen tussen star- en snowflakeschema’s behandeld, hun sterke punten en wanneer je elk gebruikt. Hopelijk heb je nu een helder beeld en praktische tips voor je werk! Wil je meer leren, bekijk dan deze resources op DataCamp:
Cursussen Data Engineering
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
