
Kurs
Einführung in das Data Engineering
4 Std.
127.6K
Wenn du mit Data Warehouses arbeitest, weißt du, wie wichtig es ist, Daten so zu strukturieren, dass sie effizient und einfach zu handhaben sind. Hast du dir schon mal überlegt, welches Datenbankschema am besten zu deinen Bedürfnissen passt? Dafür gibt's zwei wichtige Frameworks, die du nutzen kannst: das Sternschema und das Snowflake-Schema.
Das Sternschema ist einfach und schnell – perfekt, wenn du Daten schnell für Analysen extrahieren musst. Andererseits ist das Snowflake-Schema detaillierter. Es legt Wert auf Speichereffizienz und das Verwalten von komplizierten Datenbeziehungen.
In diesem Artikel zeig ich dir die Strukturen dieser Schemata, zeig dir ihre Unterschiede und erkläre dir ihre Vorteile. Am Ende wirst du wissen, wo jedes Schema passt und wie du entscheiden kannst, welches für deine Datenprojekte am besten ist.
Ein Sternschema ist eine Methode, um Daten in einer Datenbank, vor allemin Data Warehouses, so zu organisieren, dass sie einfacher und schneller analysiert werden können. In der Mitte gibt's eine Haupttabelle namens„ -Faktentabelle“ (), die messbare Daten wie Verkäufe oder Einnahmen enthält. Drum herum gibt'sdie Dimensionstabellen „ “ und „ “, die Details wie Produktnamen, Kundeninfos oder Daten hinzufügen. Dieses Layout sieht aus wie ein Stern.
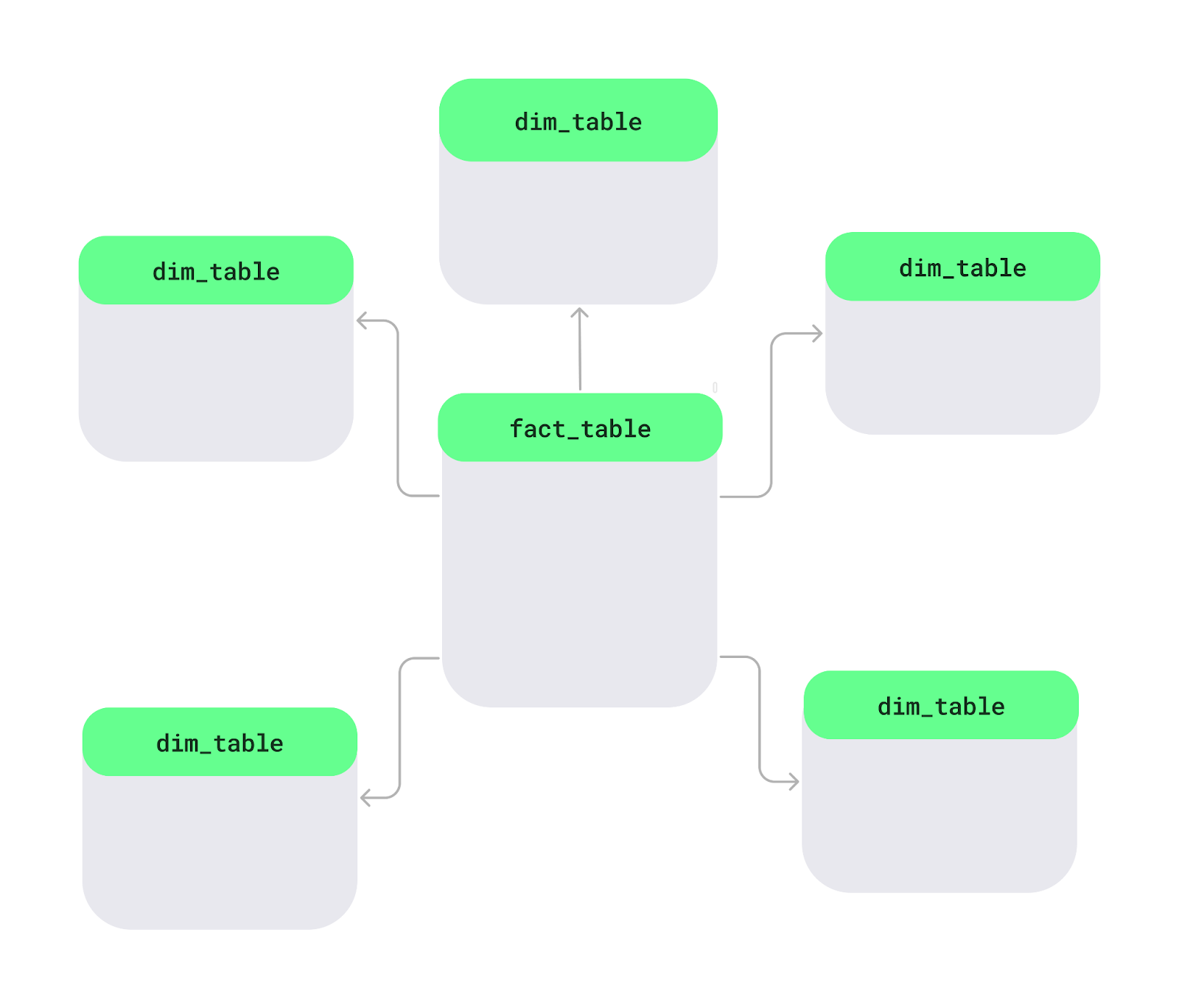
Sternschema-Layout. Bild vom Autor.
Schauen wir uns mal die wichtigsten Features des Sternschemas an:
Schauen wir uns das mal mit einem einfachen Sternschema-Diagramm an. DieFaktentabelle „ “ ( Sales ) ist in der Mitte. Es enthält die Zahlen, die du analysieren willst, wie zum Beispiel Umsätze oder Gewinne. Damit verbunden sinddie Dimensionstabellen „ “ mit beschreibenden Details wie Produktnamen, Kundenstandort oder Daten:
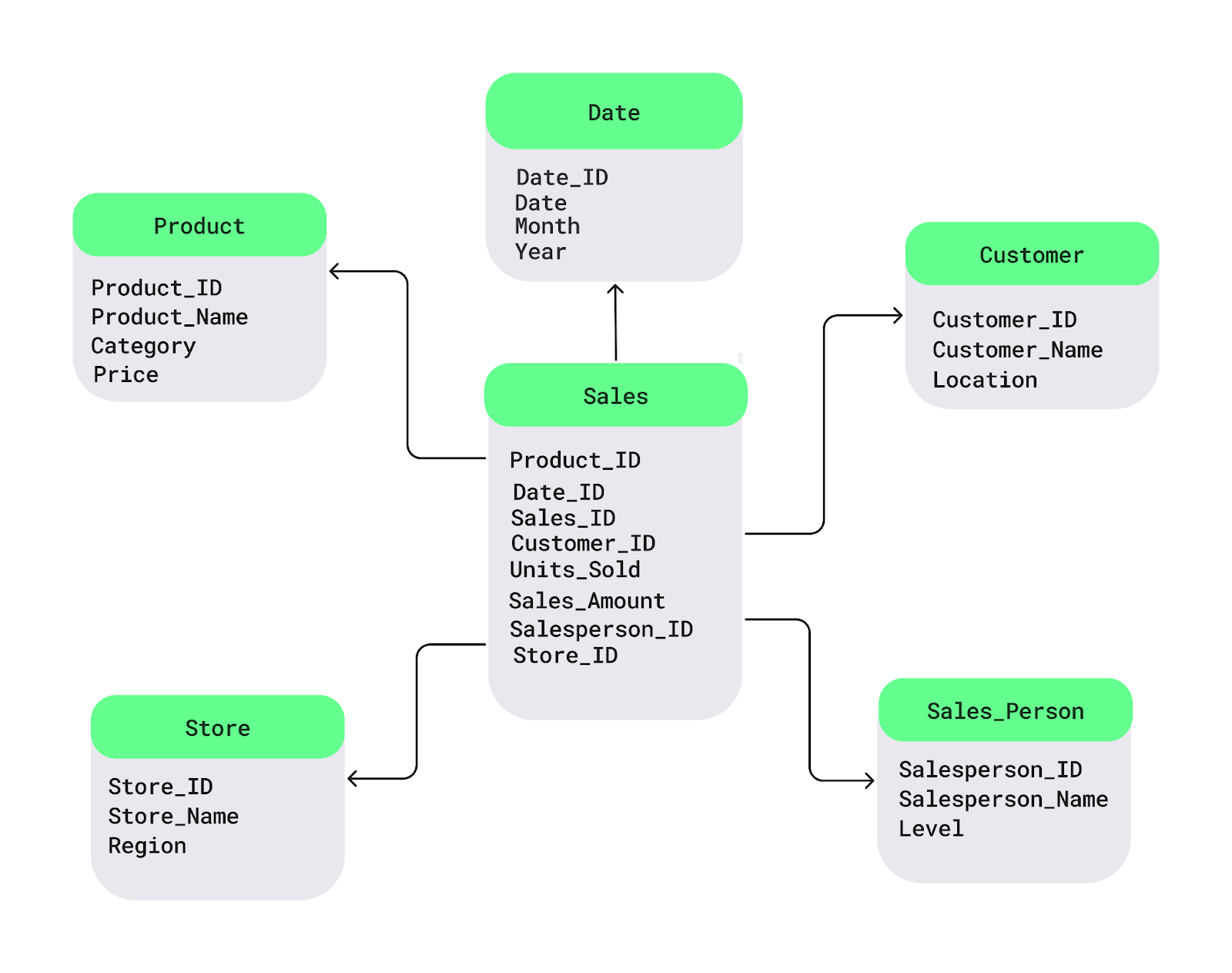
Beispiel für ein Sternschema. Bild vom Autor.
Hier ist ein einfaches SQL-Beispiel für die Einrichtung eines Sternschemas mit einer Sales Faktentabellen und Dimensionstabellen für Product, Customerund Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Dieses Layout macht Abfragen schneller, weil es keine komplizierten Verknüpfungen gibt. Die folgende Abfrage zeigt zum Beispiel den Gesamtumsatz nach Kundenstandort gruppiert an, indem sie die einfachen Verknüpfungen des Sternschemas nutzt:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Allerdings müsstest du mit einer gewissen Datenredundanz rechnen, da die Dimensionstabellen möglicherweise wiederholte Informationen enthalten.
Jetzt, wo du weißt, was ein Sternschema ist, schauen wir mal, warum es so besonders ist:
Trotz all der Vorteile hat das Sternschema auch einen Nachteil. Wie ich schon gesagt habe, haben Dimensionstabellen wegen der Denormalisierung oft doppelte Infos, was den Speicherplatzbedarf erhöht. Wenn zum Beispiel mehrere Produkte zur selben Kategorie gehören, kann es sein, dass sich die Namen der einzelnen Produkte wiederholen und dadurch mehr Speicherplatz verbrauchen.
Ein Snowflake-Schema ist eine andere Art, Daten zu organisieren. In diesem Schema werden Dimensionstabellen in kleinere Unterdimensionen aufgeteilt, um die Daten übersichtlicher und detaillierter zu halten – wie Snowflakes in einem großen See.
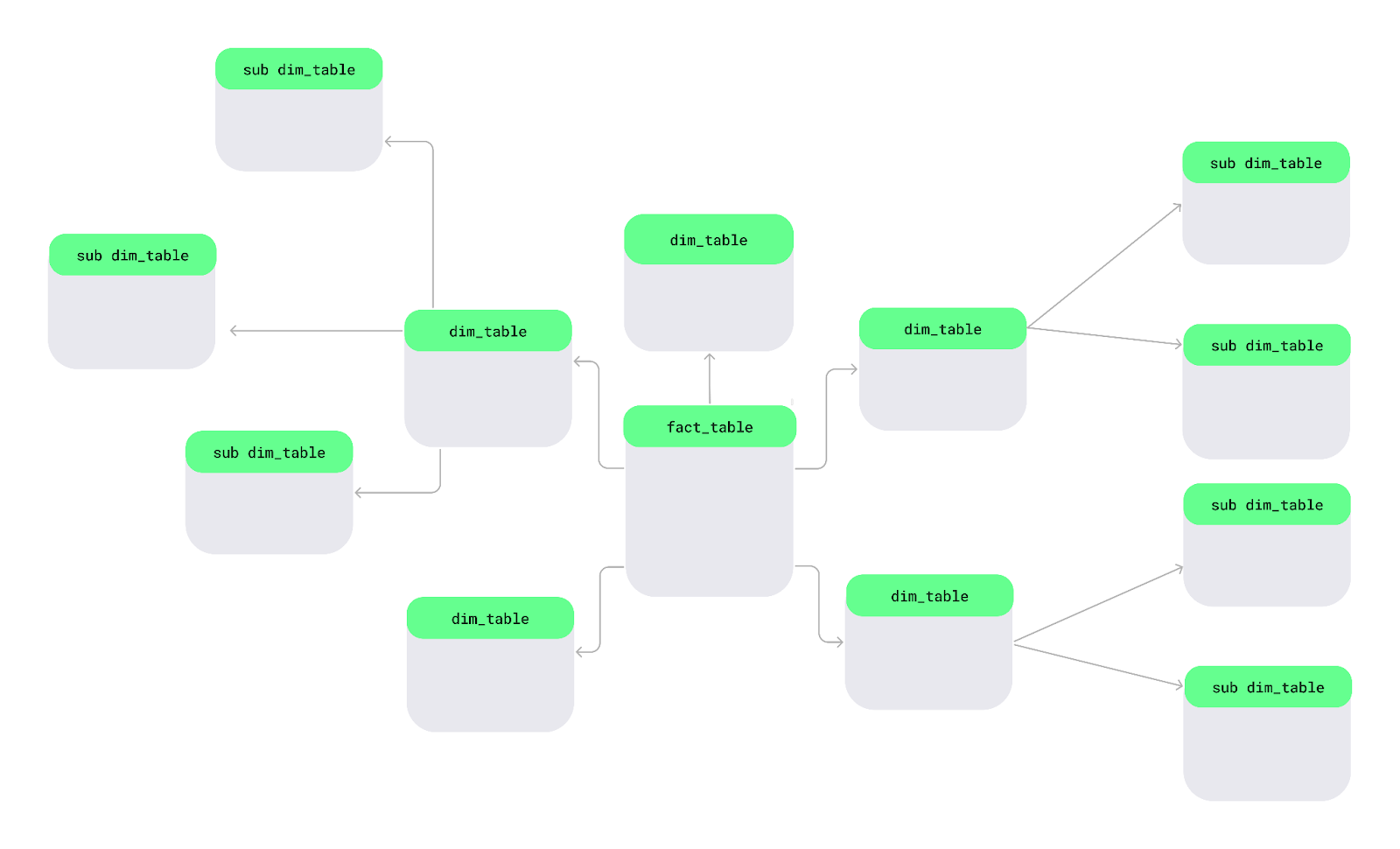
Layout des Snowflake-Schemas. Bild vom Autor.
Schauen wir uns mal die wichtigsten Features des Snowflake-Schemas an, die es von anderen Schemata unterscheiden:
Electronics “ zu wiederholen, kann ich die Kategorie in einer separaten Tabelle speichern und mit den einzelnen Produkten verknüpfen.Schauen wir uns das mal mit einem einfachen Snowflake-Schema an. Im Mittelpunkt steht die Faktentabelle, die messbare Daten enthält. Es verbindet sich mit Dimensionstabellen, die die Fakten beschreiben, und diese Dimensionstabellen verzweigen sich weiter in Unterdimensionstabellen, wodurch eine Snowflake-artige Struktur entsteht.
Zum Beispiel habe ich hier die Tabelle „ Product ” indie Tabellen „ Manufacturer” ( )und „ ” ( ) sowie „ Category” ( )und „ ” ( ) aufgeteiltunddie Tabelle „ Customer” ( ) indie Tabellen „ Transaction” ( ) und „ ” ( ) sowie„ Location” ( ) und„ ” ( ) aufgeteilt:
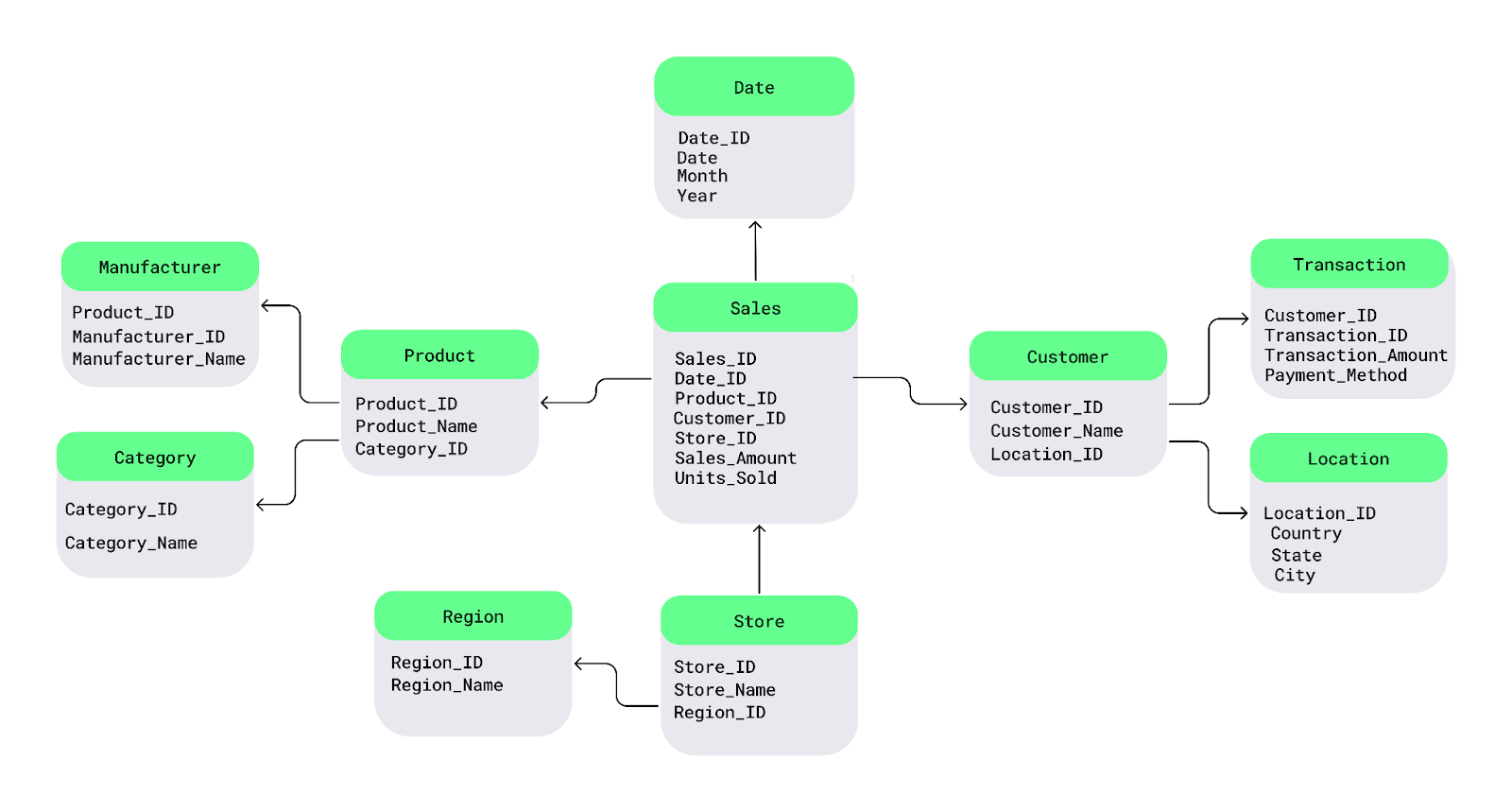
Beispiel für ein Snowflake-Schema. Bild vom Autor.
Hier ist ein SQL-Beispiel, das ein Snowflake-Schema zeigt, bei dem die Product Tabelle weiter in Category und Manufacturer Tabellen:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);Die folgende Abfrage zeigt den Gesamtumsatz nach Produktkategorie an. Obwohl es mehr Verknüpfungen als das Sternschema hat, ist es speichereffizienter:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Genau wie das Sternschema hat auch das Snowflake-Schema seine eigenen Vorteile. Mal sehen, was das ist:
Trotz der Vorteile gibt es aber auch ein paar Einschränkungen. Zum Beispielkönnen Abfragen mit „ “ langsamer sein als „ “, weil es mehr Verknüpfungen zwischen den Tabellen gibt. Außerdem ist die mehrstufige Strukturschwieriger zu entwerfen und zu pflegen als einfachere Schemata wie das Sternschema. Also, mach das nur, wenn du ein erfahrenes DBA-Team hast.
Ich empfehle dir, den Kurs „Datenbankdesign“ zu besuchen, wenn du mehr über die effiziente Strukturierung von Daten für Analysezwecke lernen möchtest.
In echten Projekten ist es üblich, beide Muster auf verschiedenen Ebenen zu nutzen, um die Vorteile beider Ansätze zu kombinieren:
So können Teams die Datenintegrität und -verwaltung mit einer schnellen und einfachen Nutzung von Analysen in Einklang bringen.
Sowohl Stern- als auch Snowflake-Schemata sind in der Datenlagerung weit verbreitet, aber aufgrund ihrer einzigartigen Eigenschaften eignen sie sich für unterschiedliche Anforderungen. Schauen wir mal, wie sich diese Schemata in Sachen Struktur, Leistung, Speicherbedarf und Anwendungsfälle unterscheiden.
Alle Dimensionstabellen sind direkt mit einer zentralen Faktentabelle in einem Sternschema verbunden. Das heißt, alle deine Referenzdaten sind nur einen Schritt von deinen Hauptdaten entfernt, was sie leicht verständlich und benutzerfreundlich macht.
Im Vergleich dazu teilt ein Snowflake-Schema Dimensionstabellen in kleinere, spezifischere Unterdimensionstabellen auf. Du kannst zum Beispiel separate Tabellen für Länder, Bundesstaaten und Städte haben, anstatt nur eine Standorttabelle. Das sorgt zwar für eine übersichtlichere und detailliertere Struktur, aber es heißt auch, dass mehr Verbindungen (oder Verknüpfungen) nötig sind, um auf deine Daten zuzugreifen – ein Hauptgrund, warum das Snowflake-Schema komplexer ist als das Sternschema.
Wenn es um Geschwindigkeit geht, sind Sternschemata oft besser. Weil alle Dimensionstabellen direkt mit der Faktentabelle verbunden sind, brauchen Abfragen normalerweise weniger Verknüpfungen, was eine schnellere Leistung bedeutet. Angenommen, du möchtest die Umsätze nach Regionen analysieren – in diesem Fall kannst du das Sternschema verwenden, um die Daten mit minimalem Verarbeitungsaufwand abzurufen.
Andererseits sind Snowflake-Schemas oft langsamer, weil man über mehrere Tabellen verbinden muss, um die Daten abzurufen. Jede Verknüpfung kostet mehr Zeit, was Snowflake-Schemas für Aufgaben, die schnelle Abfrageergebnisse brauchen, weniger effizient macht.
Der Kurs „Joining Data in SQL” ist super, um zu lernen, wie man Tabellen zusammenführt, relationale Mengenlehre anwendet und mit Unterabfragen arbeitet.
Sternschemata brauchen mehr Speicherplatz, weil sie doppelte Infos in Dimensionstabellen speichern. Wenn zum Beispiel mehrere Produkte zur selben Kategorie gehören, wird der Name der Kategorie für jedes Produkt wiederholt, was den Speicherbedarf erhöht.
Bei Snowflake-Schemas werden die Daten aber so normalisiert, dass alle Infos nur einmal gespeichert werden. Anstatt zum Beispiel Kategorienamen zu wiederholen, werden sie in einer separaten Tabelle gespeichert und über Fremdschlüssel mit der Produkttabelle verknüpft. Dieses Design spart Speicherplatz und ist deshalb super für große Datensätze.
Sternschemata sind super für OLAP-Systeme ( Online Analytical Processing ), Berichte und Business-Intelligence-Aufgaben. Ihre Einfachheit macht sie perfekt für Situationen, in denen es auf Schnelligkeit und Benutzerfreundlichkeit ankommt, wie zum Beispiel beim Erstellen von schnellen Dashboards oder Verkaufsberichten.
Snowflake-Schemata werden oft für Finanzanalysen oder CRM-Systeme (Customer Relationship Management) benutzt. In solchen Fällen ist es wichtiger, detaillierte Hierarchien zu organisieren und Speicherplatz zu sparen, als die Abfragegeschwindigkeit zu erhöhen.
Hier ist ein kurzer Vergleich zwischen dem Stern- und dem Snowflake-Schema, damit du besser entscheiden kannst, welches am besten zu deinen Datenanforderungen passt. Ich habe die wichtigsten Unterschiede in dieser Tabelle hervorgehoben und mich dabei auf ihre Struktur, Leistung, Speicherkapazität und Anwendungsfälle konzentriert:
|
Feature |
Sternschema |
Snowflake-Schema |
Hybridansatz |
|
Struktur |
Zentrale Faktentabelle, die mit denormalisierten Dimensionen verbunden ist |
Zentrale Faktentabelle, die mit normalisierten Dimensionen verbunden ist |
Normalisiertes Kernmodell plus sternförmige Märkte oder nicht normalisierte Ansichten für die Nutzung |
|
Komplexität |
Einfach, mit weniger Verbindungen |
Komplex, mit mehr Verbindungen |
Mittlere Größe, mit mehr beweglichen Teilen, aber jede Schicht bleibt für ihren Zweck einfacher. |
|
Datenredundanz |
Mehr Redundanz wegen denormalisierter Dimensionen |
Weniger Redundanz durch einheitliche Maße |
Mittlere Redundanz durch selektive Denormalisierung |
|
Abfrage-Performance |
Schnellere Abfragen dank einer einfacheren Struktur |
Langsameres Abfragen wegen extra Verknüpfungen |
Schnell für BI, weil die Verbrauchsebene denormalisiert ist |
|
Lagerung |
Braucht mehr Speicherplatz wegen der Redundanz |
Braucht weniger Speicherplatz wegen der Normalisierung |
Benötigt mäßigen Speicherplatz, weil Märkte/Ansichten zu Duplikaten führen können. |
|
Einfache Wartung |
Einfacher zu entwerfen und zu warten |
Komplexer in der Gestaltung und Wartung |
Einfach zu warten, weil Märkte aus dem kontrollierten Kern wieder aufgebaut werden können. |
|
Am besten geeignet für |
Kleine bis mittelgroße Datensätze |
Große und komplizierte Datensätze |
Moderne Datenplattformen, die sowohl Governance-Anforderungen als auch BI-Leistungsanforderungen erfüllen |
Wenn du deine Daten vor allem einfach und schnell organisieren willst, ist das Sternschema genau das Richtige für dich. Hier kannst du es verwenden:
Das Snowflake-Schema eignet sich besser, um Hierarchien und gemeinsame Referenzdaten darzustellen, vor allem wenn sich mehrere Dimensionsattribute über viele Zeilen wiederholen. Hier kannst du es verwenden:
In vielen modernen Cloud-Data-Warehouses ist der Speicherplatz im Vergleich zur Rechenleistung ziemlich günstig. Das heißt, der „zusätzliche Speicherplatz“ von denormalisierten Dimensionen ist oft weniger wichtig als die Rechenkosten für das Scannen und Zusammenführen von Daten.
Wenn du zwischen Stern und Snowflake wählst, denk an das Preismodell deiner Plattform (Rechenleistung vs. Speicherplatz), die Anzahl der gleichzeitigen Abfragen und ob du Caching/materialisierte Ansichten nutzen kannst, um die Abfragekosten niedrig zu halten.
In diesem Blog habe ich die Unterschiede zwischen dem Stern- und dem Snowflake-Schema, ihre Stärken und wann man welches Schema verwenden sollte, erklärt. Ich hoffe, du hast jetzt ein klares Verständnis und praktische Tipps für deine Arbeit! Wenn du mehr erfahren möchtest, schau dir diese Ressourcen auf DataCamp an:
Kurse im Bereich Datenverarbeitung
Kurs
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Tutorial
Matt Crabtree
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
Tutorial
Allan Ouko

