
Corso
Introduzione al Data Engineering
4 h
128.3K
Se lavori con i data warehouse, sai quanto sia importante strutturare i dati in modo efficiente e facile da gestire. Ma ti sei mai chiesto quale schema di database sia più adatto alle tue esigenze? Ci sono due framework principali che puoi usare per questo: lo schema a stella e lo schema a fiocco di neve.
Lo schema a stella è semplice e veloce — ideale quando devi estrarre rapidamente i dati per l’analisi. Lo schema a fiocco di neve, invece, è più dettagliato. Dà priorità all’efficienza di archiviazione e alla gestione di relazioni dati complesse.
In questo articolo ti guiderò attraverso le strutture di questi schemi, ne evidenzierò le differenze e ne analizzerò i vantaggi. Alla fine saprai dove è più adatto ciascuno schema e come decidere quale sia il migliore per i tuoi progetti dati.
Uno schema a stella è un modo di organizzare i dati in un database, specialmente nei data warehouse, per rendere l’analisi più semplice e veloce. Al centro c’è una tabella principale chiamata tabella dei fatti, che contiene dati misurabili come vendite o ricavi. Intorno ci sono le tabelle delle dimensioni, che aggiungono dettagli come nomi dei prodotti, informazioni sui clienti o date. Questo layout forma una struttura a stella.
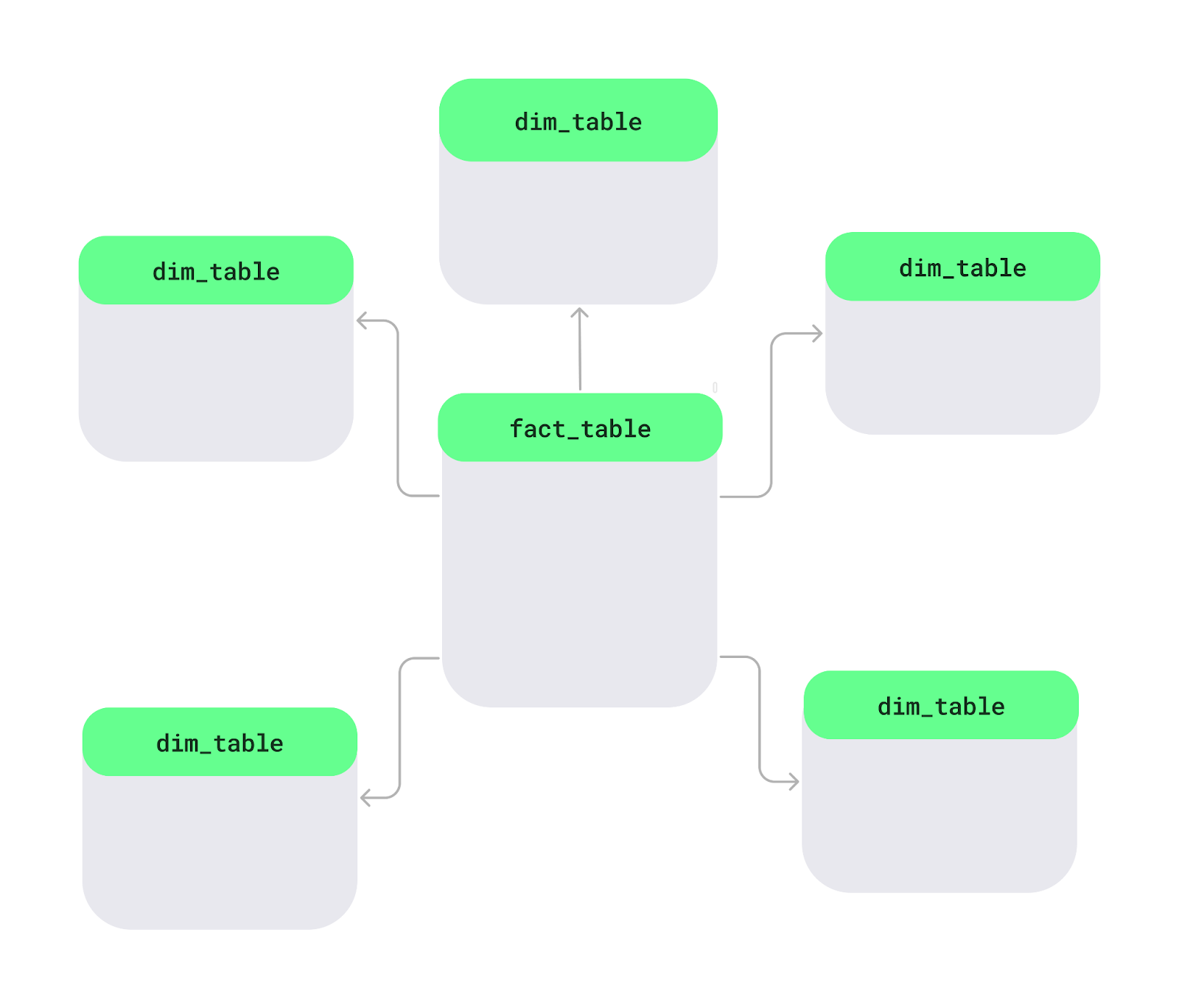
Schema a stella. Immagine dell’autore.
Vediamo le caratteristiche chiave dello schema a stella:
Capendo questo con un semplice diagramma a stella. La tabella dei fatti Sales è al centro. Contiene i dati numerici che vuoi analizzare, come vendite o profitti. A essa sono collegate le tabelle delle dimensioni con dettagli descrittivi, come nomi dei prodotti, posizione dei clienti o date:
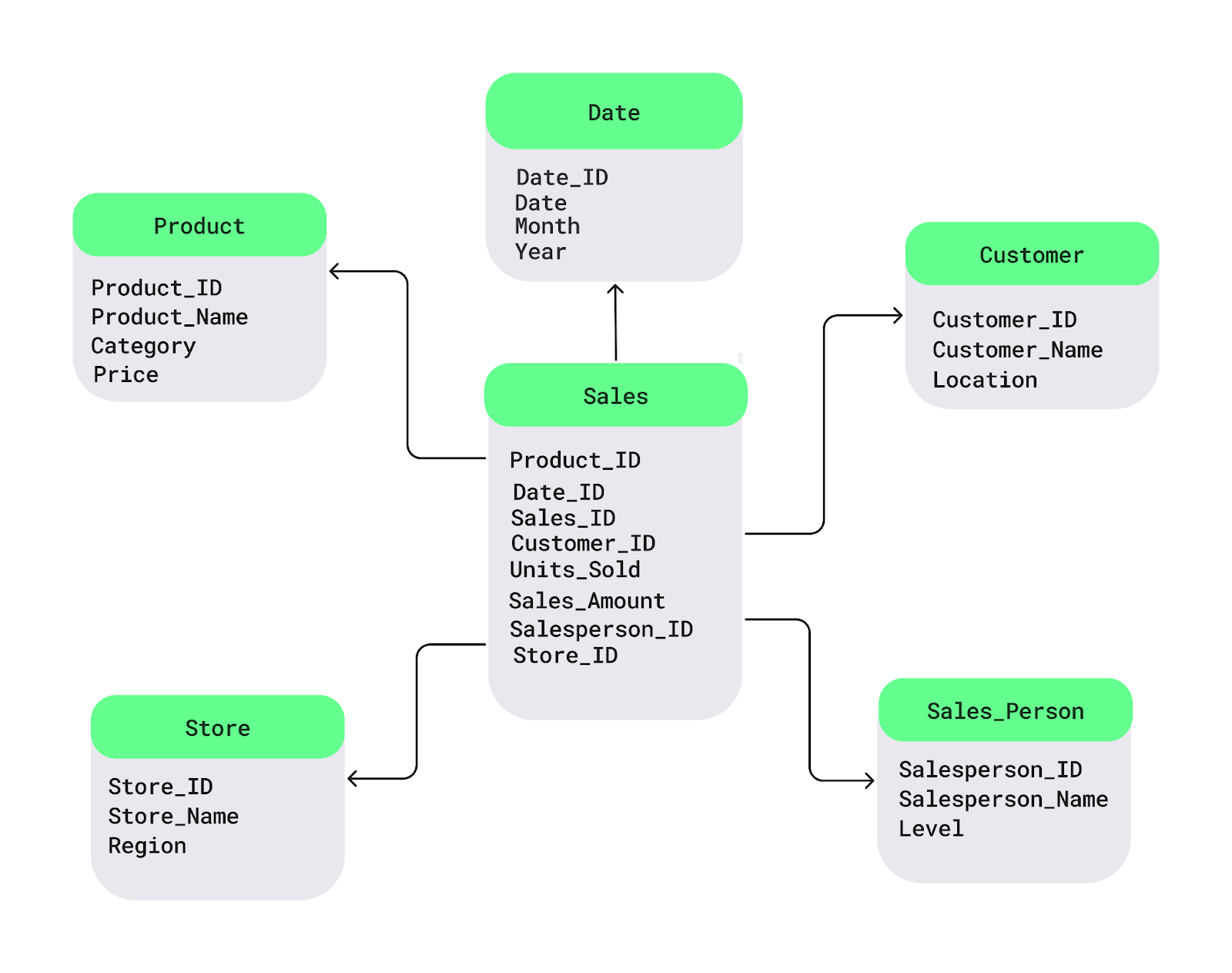
Esempio di schema a stella. Immagine dell’autore.
Ecco un semplice esempio SQL per impostare uno schema a stella con una tabella dei fatti Sales e tabelle delle dimensioni per Product, Customer e Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Questo layout accelera le query perché non ci sono join complessi. Ad esempio, la query seguente recupera le vendite totali raggruppate per località del cliente, sfruttando i join semplici dello schema a stella:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Tuttavia, devi accettare una certa ridondanza dei dati poiché le tabelle delle dimensioni possono contenere informazioni ripetute.
Ora che sai cos’è lo schema a stella, vediamo perché si distingue:
Nonostante tutti i vantaggi, lo schema a stella ha un lato negativo. Come detto prima, a causa della denormalizzazione, le tabelle delle dimensioni spesso contengono informazioni ripetute, il che aumenta l’uso di spazio. Ad esempio, se più prodotti appartengono alla stessa categoria, il nome di ciascun prodotto potrebbe ripetersi, occupando più spazio di archiviazione.
Uno schema a fiocco di neve è un altro modo di organizzare i dati. In questo schema, le tabelle delle dimensioni sono suddivise in sotto-dimensioni più piccole per mantenere i dati più ordinati e dettagliati — proprio come i fiocchi di neve in un grande lago.
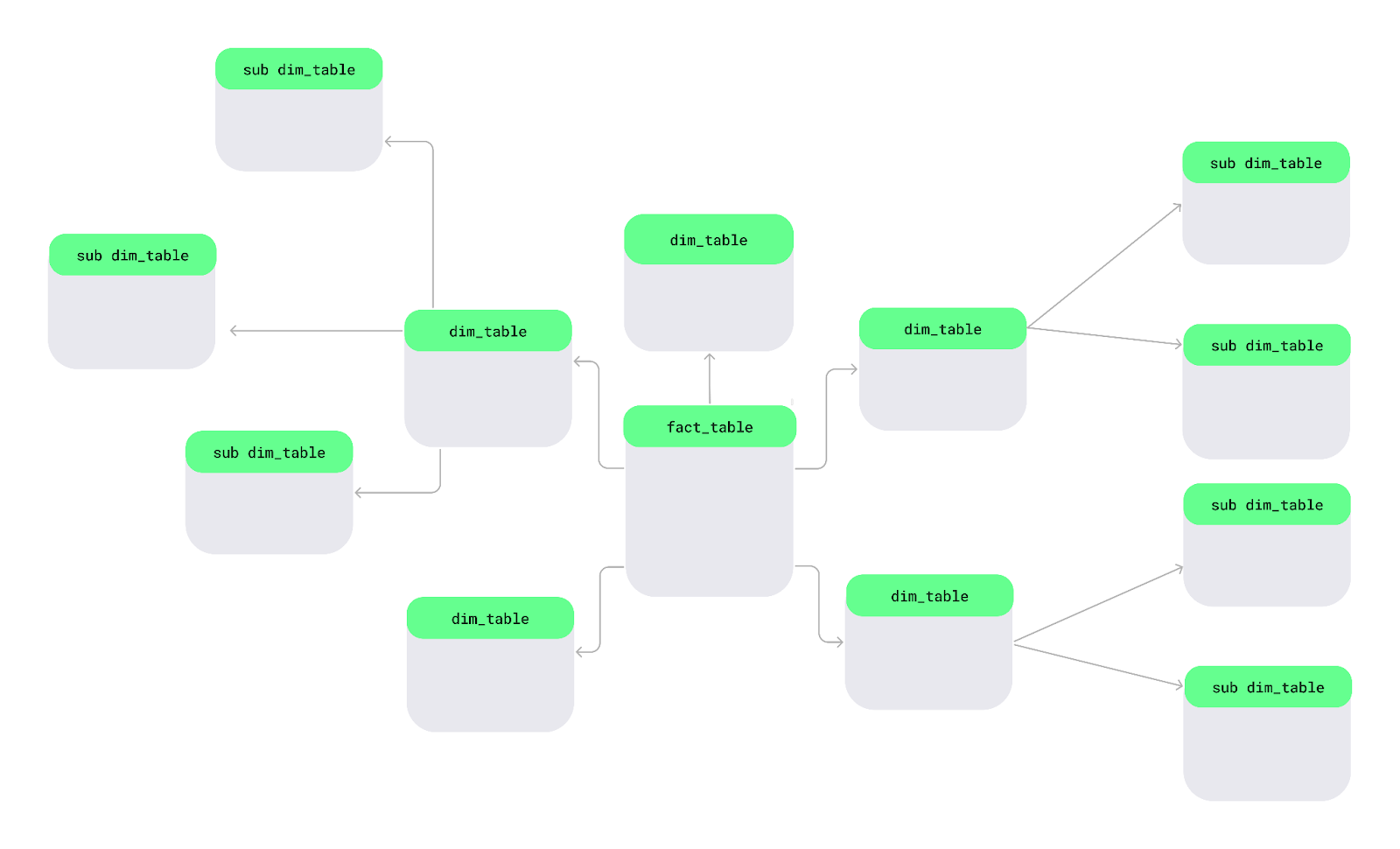
Schema a fiocco di neve. Immagine dell’autore.
Vediamo le caratteristiche chiave dello schema a fiocco di neve che lo differenziano dagli altri schemi:
Electronics per ogni prodotto, posso archiviare la categoria in una tabella separata e collegarla ai singoli prodotti.Comprendiamolo con un semplice diagramma a fiocco di neve. Al centro c’è la tabella dei fatti, che contiene dati misurabili. Si collega a tabelle delle dimensioni che descrivono i fatti, e queste tabelle si diramano ulteriormente in sotto-dimensioni, formando una struttura simile a un fiocco di neve.
Per esempio, qui ho suddiviso la tabella Product in Manufacturer e Category e la tabella Customer in Transaction e Location :
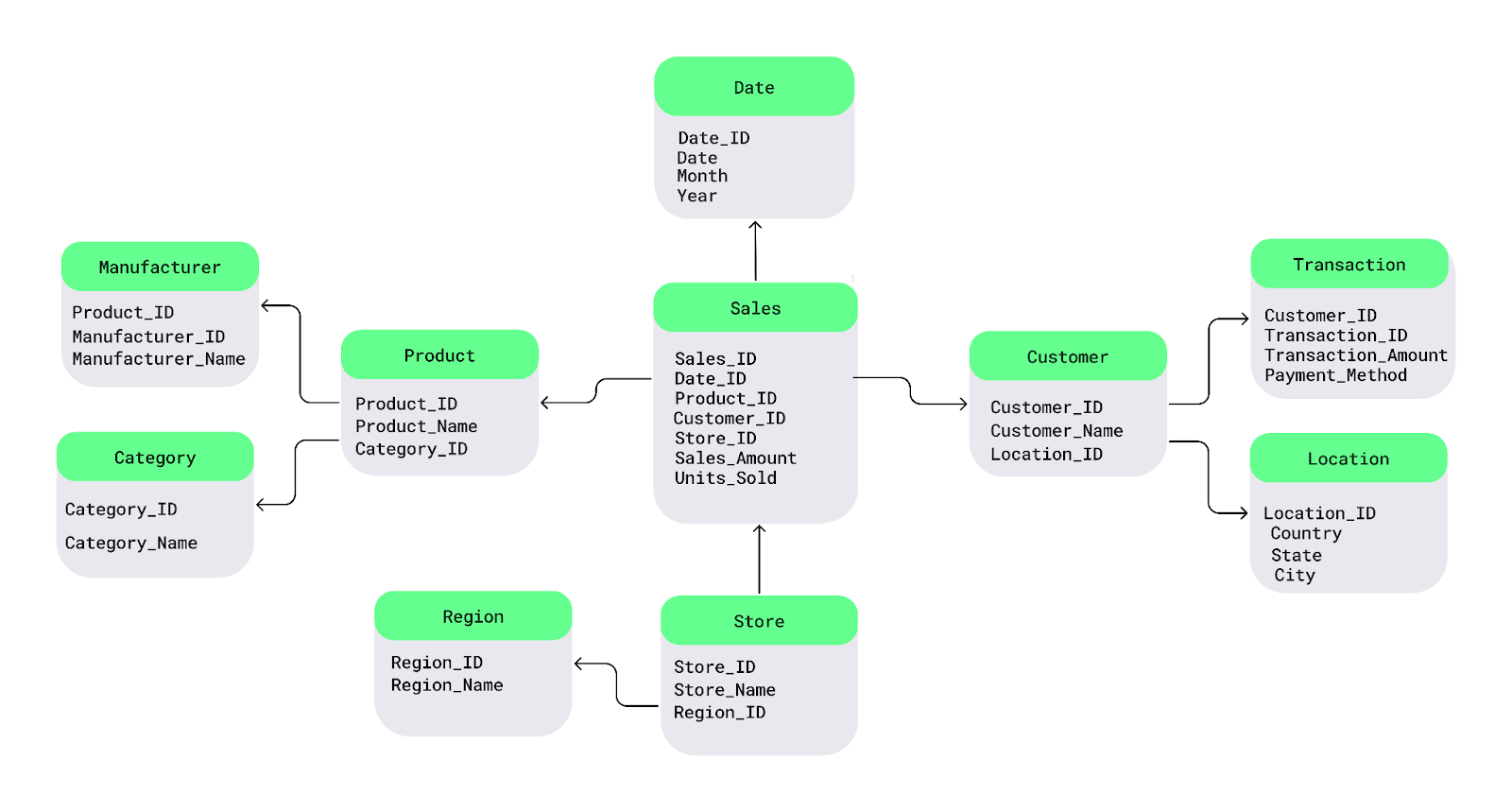
Esempio di schema a fiocco di neve. Immagine dell’autore.
Ecco un esempio SQL che illustra uno schema a fiocco di neve in cui la tabella Product è ulteriormente normalizzata nelle tabelle Category e Manufacturer:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);La query seguente calcola le vendite totali per categoria di prodotto. Anche se comporta più join rispetto allo schema a stella, è più efficiente in termini di spazio:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Come lo schema a stella, anche lo schema a fiocco di neve ha i suoi vantaggi. Vediamo quali sono:
Tuttavia, nonostante i suoi vantaggi, ci sono anche alcuni limiti. Per esempio, le query possono essere più lente perché ci sono più join tra tabelle. Oltre a questo, la struttura multilivello è più impegnativa da progettare e mantenere rispetto a schemi più semplici come quello a stella. Quindi, scegliilo solo se hai un team di DBA esperto.
Ti consiglio di dare un’occhiata al corso Database Design se vuoi approfondire come strutturare i dati in modo efficiente per l’analisi.
Nei progetti reali è comune usare entrambi i pattern in livelli diversi per combinare i punti di forza di entrambi gli approcci:
Questo consente ai team di bilanciare integrità e governance dei dati con un consumo analitico rapido e semplice.
Sia gli schemi a stella che quelli a fiocco di neve sono ampiamente usati nel data warehousing, ma le loro caratteristiche uniche li rendono adatti a esigenze diverse. Vediamo come differiscono per struttura, prestazioni, requisiti di archiviazione e casi d’uso.
In uno schema a stella, tutte le tabelle delle dimensioni si collegano direttamente a un’unica tabella dei fatti centrale. Ciò significa che tutti i tuoi dati di riferimento sono a un solo passo dai dati principali, rendendo il tutto facile da comprendere e usare.
In confronto, uno schema a fiocco di neve suddivide le tabelle delle dimensioni in sotto-dimensioni più piccole e specifiche. Per esempio, puoi avere tabelle separate per Paesi, Stati/Regioni e Città invece di un’unica tabella delle località. Anche se questo crea una struttura più ordinata e dettagliata, implica anche più collegamenti (o join) per accedere ai dati — uno dei motivi principali per cui lo schema a fiocco di neve è più complesso di quello a stella.
In termini di velocità, gli schemi a stella sono spesso migliori. Poiché tutte le tabelle delle dimensioni si collegano direttamente alla tabella dei fatti, le query richiedono di solito meno join, con prestazioni più rapide. Supponiamo che tu voglia analizzare le vendite per regione — in questo caso, puoi usare lo schema a stella per recuperare i dati con elaborazione minima.
Al contrario, gli schemi a fiocco di neve sono spesso più lenti perché devi passare attraverso più tabelle per recuperare i dati. Ogni join aggiunge tempo di elaborazione, rendendo gli schemi a fiocco di neve meno efficienti per attività che richiedono risultati rapidi.
Il corso Joining Data in SQL è un’ottima introduzione per imparare a unire le tabelle, applicare la teoria degli insiemi relazionali e lavorare con le subquery.
Gli schemi a stella occupano più spazio di archiviazione perché memorizzano informazioni ridondanti nelle tabelle delle dimensioni. Ad esempio, se più prodotti appartengono alla stessa categoria, il nome della categoria si ripeterà per ogni prodotto, aumentando le esigenze di spazio.
Gli schemi a fiocco di neve, invece, normalizzano i dati per archiviare ogni informazione una sola volta. Per esempio, invece di ripetere i nomi delle categorie, questi sono archiviati in una tabella separata e collegati alla tabella dei prodotti tramite chiavi esterne. Questo design risparmia spazio, rendendolo ideale per dataset di grandi dimensioni.
Gli schemi a stella sono ideali per i sistemi di online analytical processing (OLAP), la reportistica e le attività di business intelligence. La loro semplicità li rende perfetti per scenari in cui contano velocità e facilità d’uso, come la creazione di dashboard rapidi o report di vendita.
Gli schemi a fiocco di neve sono spesso usati per l’analisi finanziaria o i sistemi di customer relationship management (CRM). In questi casi sono più importanti l’organizzazione di gerarchie dettagliate e il risparmio di spazio che la velocità delle query.
Ecco un rapido confronto tra schema a stella e schema a fiocco di neve per aiutarti a decidere quale si adatta meglio alle tue esigenze. Ho evidenziato le differenze principali in questa tabella, concentrandomi su struttura, prestazioni, archiviazione e casi d’uso:
|
Caratteristica |
Schema a stella |
Schema a fiocco di neve |
Approccio ibrido |
|
Struttura |
Tabella dei fatti centrale collegata a dimensioni denormalizzate |
Tabella dei fatti centrale collegata a dimensioni normalizzate |
Modello core normalizzato, più data mart a stella o viste denormalizzate per il consumo |
|
Complessità |
Semplice, con meno join |
Complesso, con più join |
Media, con più componenti, ma ogni livello resta più semplice per il suo scopo |
|
Ridondanza dei dati |
Maggiore ridondanza a causa delle dimensioni denormalizzate |
Minore ridondanza grazie alle dimensioni normalizzate |
Ridondanza media grazie alla denormalizzazione selettiva |
|
Prestazioni delle query |
Query più rapide grazie alla struttura più semplice |
Query più lente a causa dei join aggiuntivi |
Veloci per la BI perché il livello di consumo è denormalizzato |
|
Archiviazione |
Richiede più spazio a causa della ridondanza |
Richiede meno spazio grazie alla normalizzazione |
Richiede spazio moderato perché i mart/viste possono aggiungere un po’ di duplicazione |
|
Facilità di manutenzione |
Più facile da progettare e mantenere |
Più complesso da progettare e mantenere |
Facile da mantenere, poiché i mart possono essere ricostruiti dal core controllato |
|
Più adatto per |
Dataset piccoli o medi |
Dataset grandi e complessi |
Piattaforme dati moderne con esigenze sia di governance sia di prestazioni BI |
Se il tuo obiettivo principale è organizzare i dati in modo semplice e rapido, lo schema a stella è perfetto. Ecco quando usarlo:
Lo schema a fiocco di neve è più adatto a rappresentare gerarchie e dati di riferimento condivisi, soprattutto quando molti attributi di dimensione si ripetono su molte righe. Ecco quando puoi usarlo:
In molti moderni data warehouse cloud, lo storage è relativamente economico rispetto al compute. Ciò significa che il “maggiore spazio” dovuto alle dimensioni denormalizzate è spesso meno importante del costo di calcolo per scansione e join dei dati.
Quando scegli tra stella e fiocco di neve, considera il modello di pricing della tua piattaforma (compute vs storage), la concorrenza delle query e se puoi usare caching/vista materializzate per mantenere bassi i costi delle query.
In questo blog ho trattato le differenze tra schema a stella e schema a fiocco di neve, i loro punti di forza e quando usare ciascuno. Spero che ora tu abbia un’idea chiara e suggerimenti pratici per il tuo lavoro! Se vuoi saperne di più, dai un’occhiata a queste risorse su DataCamp:
Corsi di Data Engineering
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

