
Cours
Introduction au data engineering
4 h
127.6K
Si vous travaillez avec des entrepôts de données, vous comprenez l'importance de structurer les données de manière efficace et facile à gérer. Avez-vous déjà réfléchi au schéma de base de données qui correspond le mieux à vos besoins ? Il existe deux principaux cadres que vous pouvez utiliser à cette fin : le schéma en étoile et le schéma Snowflake.
Le schéma en étoile est simple et rapide, ce qui le rend idéal lorsque vous avez besoin d'extraire rapidement des données à des fins d'analyse. D'autre part, le schéma Snowflake est plus détaillé. Il privilégie l'efficacité du stockage et la gestion des relations complexes entre les données.
Dans cet article, je vais vous présenter la structure de ces schémas, souligner leurs différences et détailler leurs avantages. À la fin, vous saurez où chaque schéma convient et comment déterminer lequel est le plus adapté à vos projets de données.
Un schéma en étoile est une méthode d'organisation des données dans une base de données, en particulierdans les entrepôts de données, afin de faciliter et d'accélérer leur analyse. Au centre se trouve une table principale appelée «table de faits »( ), qui contient des données mesurables telles que les ventes ou les revenus. Il est entouré detableaux de dimensions , qui ajoutent des détails tels que les noms de produits, les informations sur les clients ou les dates. Cette disposition forme une configuration en étoile.
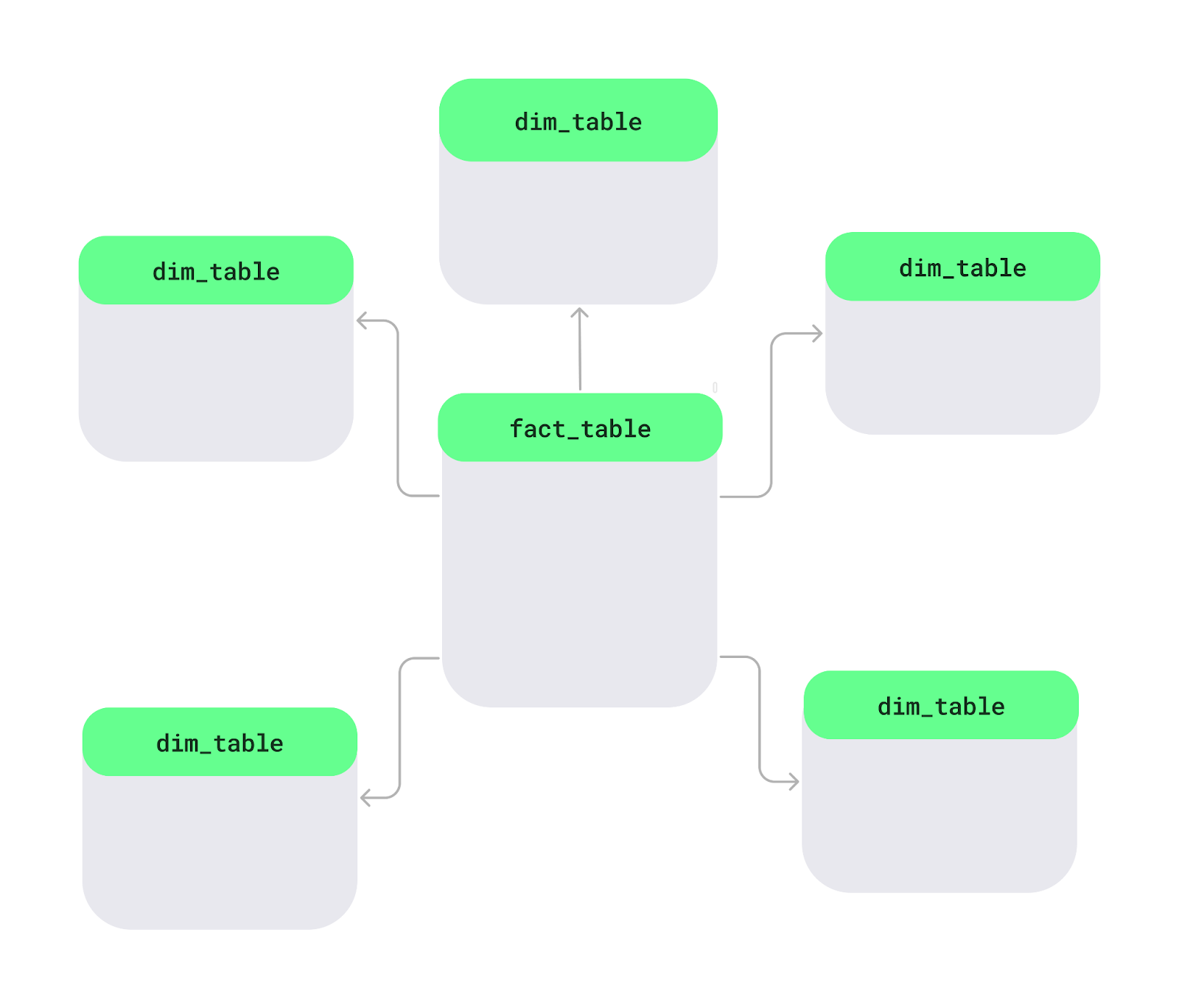
Disposition en étoile. Image fournie par l'auteur.
Examinons les principales caractéristiques du schéma en étoile :
Comprenons cela à l'aide d'un diagramme simple représentant un schéma en étoile. La table de faits Sales se trouve au centre. Il contient les données numériques que vous souhaitez analyser, telles que les ventes ou les bénéfices. s tables de dimensions y sont associées, contenant des détails descriptifs tels que les noms des produits, la localisation des clients ou les dates :
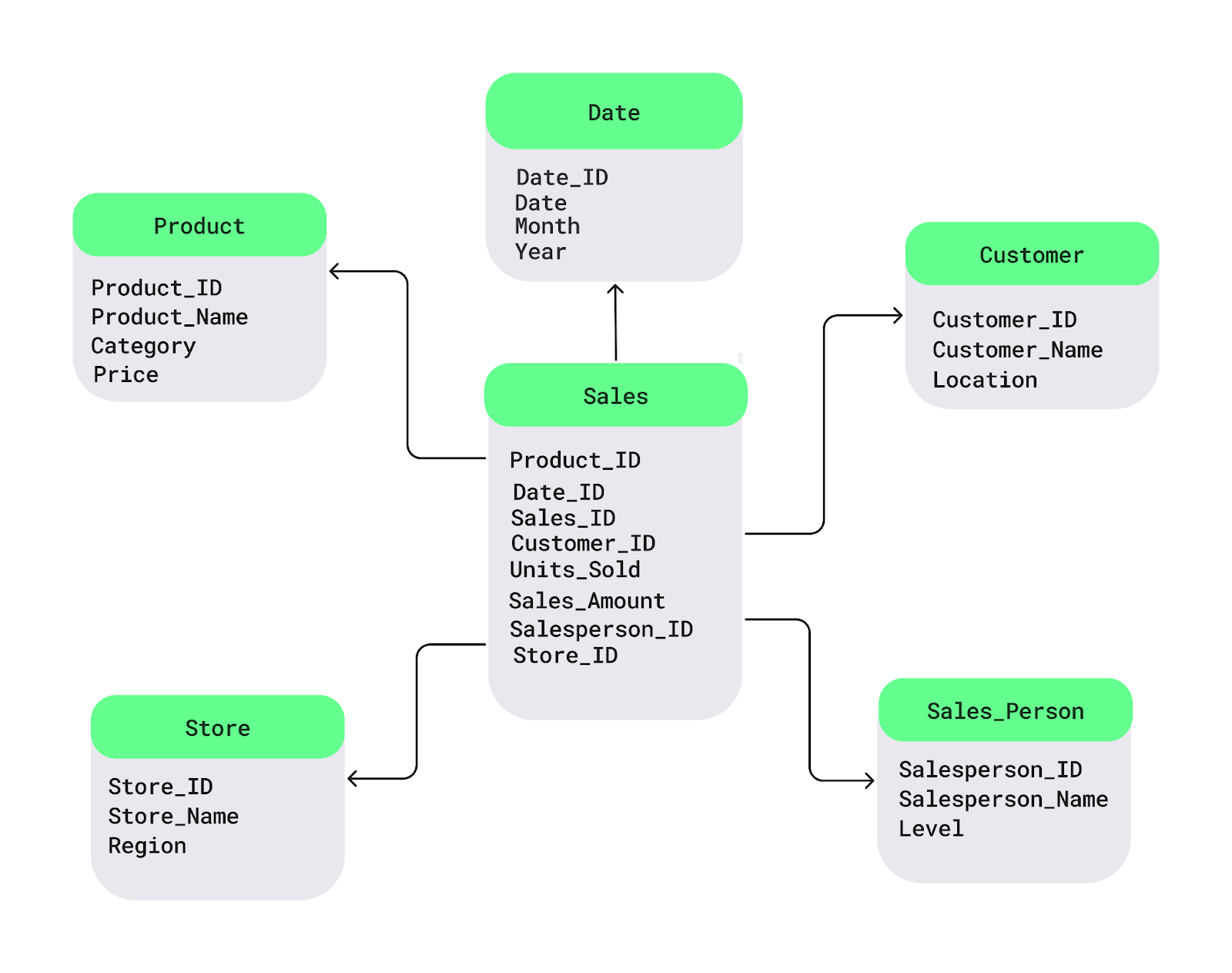
Exemple de schéma en étoile. Image fournie par l'auteur.
Voici un exemple SQL simple pour configurer un schéma en étoile avec une Sales tableaux de faits et des tableaux de dimensions pour Product, Customeret Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Cette structure accélère les requêtes, car elle ne comporte pas de jointures complexes. Par exemple, la requête suivante récupère le total des ventes regroupées par emplacement client, en utilisant les jointures simples du schéma en étoile :
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Cependant, il serait nécessaire d'accepter une certaine redondance des données, car les tables de dimensions peuvent contenir des informations répétées.
Maintenant que vous comprenez ce qu'est un schéma en étoile, examinons pourquoi il se distingue :
Malgré tous ses avantages, le schéma en étoile présente un inconvénient. Comme je l'ai déjà mentionné, en raison de la dénormalisation, les tables de dimensions contiennent souvent des informations répétées, ce quiaugmente l'utilisation de l'espace de stockage . Par exemple, si plusieurs produits appartiennent à la même catégorie, le nom de chaque produit pourrait être répété, occupant ainsi davantage d'espace de stockage.
Le schéma Snowflake est une autre méthode d'organisation des données. Dans ce schéma, les tables de dimensions sont divisées en sous-dimensions plus petites afin de mieux organiser et détailler les données, à l'instar des flocons de neige dans un grand lac.
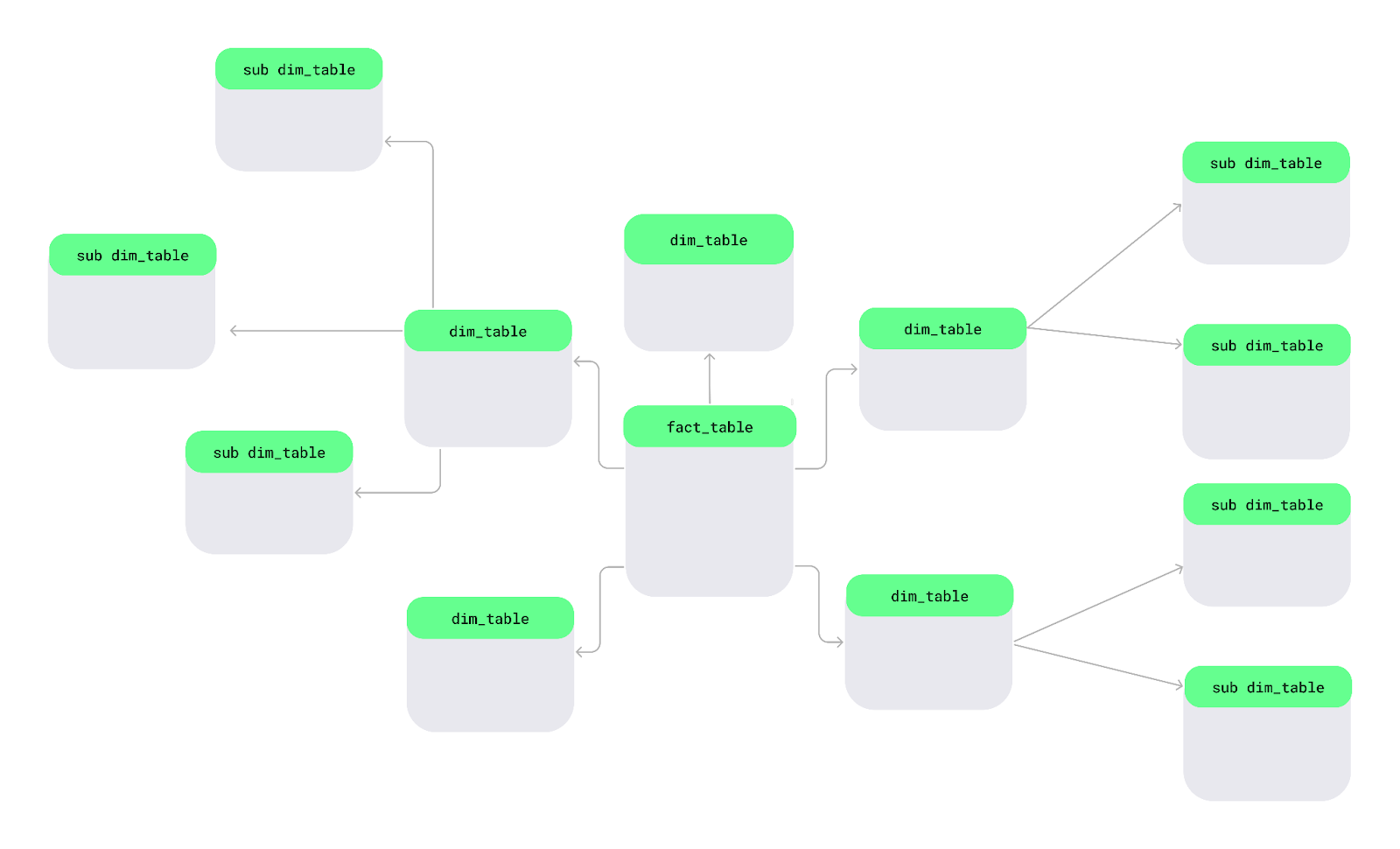
Structure du schéma Snowflake. Image fournie par l'auteur.
Examinons les principales caractéristiques du schéma Snowflake qui le distinguent des autres schémas :
Electronics pour chaque produit, je peux stocker la catégorie dans un tableau séparé et la lier à des produits individuels.Comprenons cela à l'aide d'un schéma simple représentant un Snowflake. Au centre se trouve la table des faits, qui contient des données mesurables. Il se connecte à des tables de dimensions qui décrivent les faits, et ces tables de dimensions se ramifient à leur tour en sous-tables de dimensions, formant ainsi une structure en forme de Snowflake.
Par exemple, j'ai divisé latable Product en Manufacturer et Category , et latable Customer en Transaction et Location :
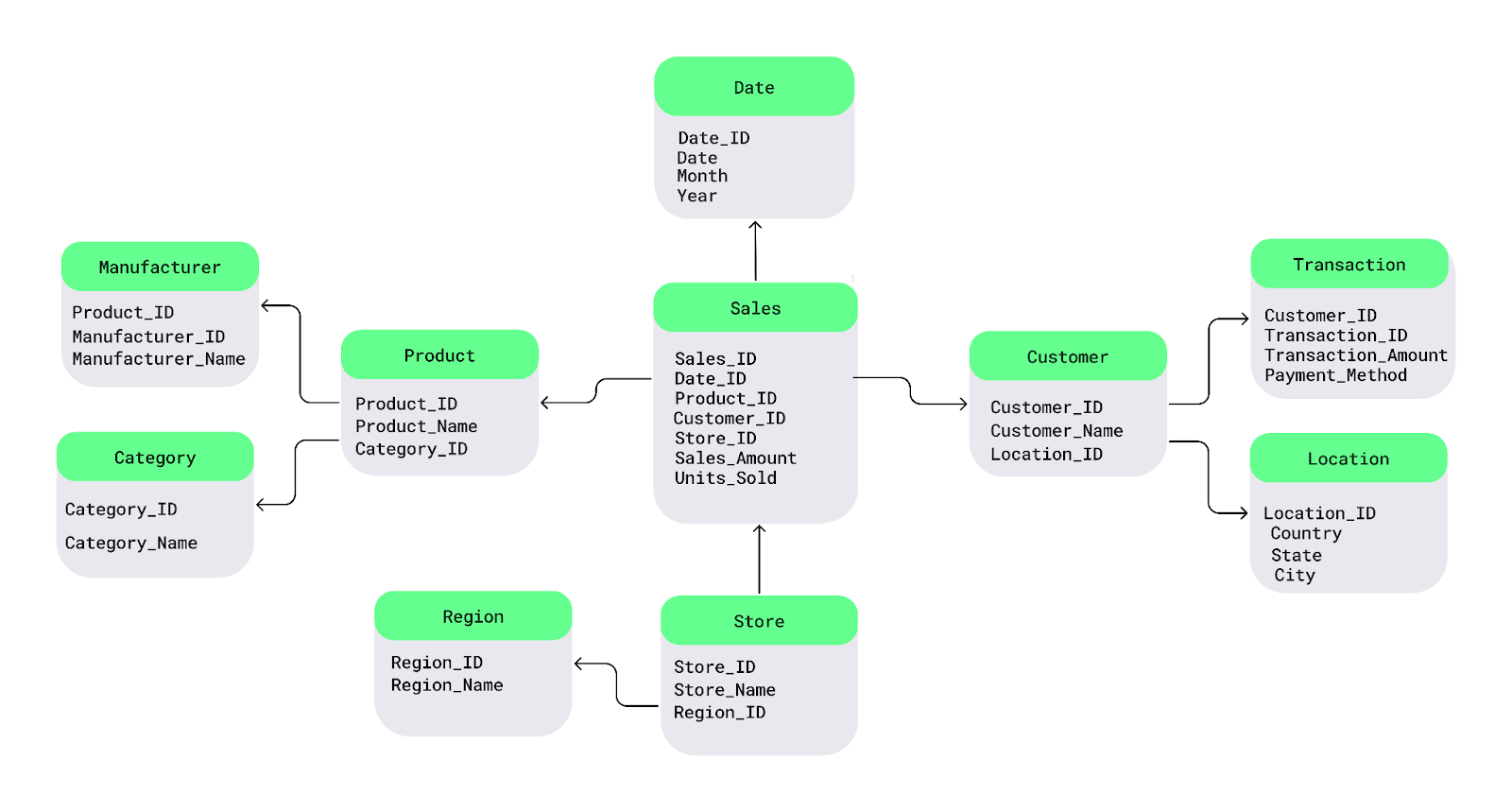
Exemple de schéma Snowflake. Image fournie par l'auteur.
Voici un exemple SQL illustrant un schéma Snowflake où la Product table est normalisée davantage en Category et Manufacturer tableaux:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);La requête suivante calcule le total des ventes par catégorie de produits. Bien qu'il implique davantage de jointures que le schéma en étoile, il est plus efficace en termes de stockage :
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Tout comme le schéma en étoile, le schéma Snowflake présente également ses propres avantages. Voyons ce qu'ils sont :
Cependant, malgré ses avantages, il existe également quelques limites. Par exemple,les requêtes peuvent être plus lentes que, car il y a davantage de jointures entre les tables. En outre, la structure à plusieurs niveaux est pluscomplexe à concevoir et à maintenir que des schémas plus simples tels que le schéma en étoile. Par conséquent, nous vous recommandons de procéder uniquement si vous disposez d'une équipe d'administrateurs de bases de données expérimentée.
Je vous recommande de consulter le cours sur la conception de bases de données si vous souhaitez en savoir plus sur la manière de structurer efficacement les données à des fins d'analyse.
Dans les projets réels, il est courant d'utiliser les deux modèles à différents niveaux afin de combiner les atouts des deux approches :
Cela permet aux équipes de trouver un équilibre entre l'intégrité et la gouvernance des données d'une part, et une utilisation rapide et simple des analyses d'autre part.
Les schémas en étoile et Snowflake sont largement utilisés dans le stockage de données, mais leurs caractéristiques uniques les rendent adaptés à des besoins différents. Examinons en détail les différences entre ces schémas en termes de structure, de performances, d'exigences de stockage et de cas d'utilisation.
Tous les tableaux de dimensions sont directement reliés à une table de faits centrale dans un schéma en étoile. Cela signifie que toutes vos données de référence sont à portée de main de vos données principales, ce qui facilite leur compréhension et leur utilisation.
En comparaison, un schéma en Snowflake divise les tables de dimensions en tables de sous-dimensions plus petites et plus spécifiques. Par exemple, vous pouvez disposer de tables distinctes pour les pays, les États et les villes au lieu d'une seule table de localisation. Bien que cela permette d'obtenir une structure plus organisée et plus détaillée, cela implique également davantage de connexions (ou jointures) pour accéder à vos données, ce qui constitue l'une des principales raisons pour lesquelles le schéma en Snowflake est plus complexe que le schéma en étoile.
En matière de vitesse, les schémas en étoile sont souvent plus performants. Étant donné que tous les tableaux de dimensions sont directement reliés à la table de faits, les requêtes nécessitent généralement moins de jointures, ce qui se traduit par des performances accrues. Supposons que vous souhaitiez analyser les ventes par région. Dans ce cas, vous pouvez utiliser le schéma en étoile pour récupérer les données avec un traitement minimal.
À l'inverse, les schémas Snowflake sont souvent plus lents, car il est nécessaire de se connecter à plusieurs tables pour récupérer les données. Chaque jointure ajoute du temps de traitement, ce qui rend les schémas Snowflake moins efficaces pour les tâches qui nécessitent des résultats de requête rapides.
Le cours « Joindre des données dans SQL » constitue une excellente introduction pour apprendre à joindre des tables, à appliquer la théorie des ensembles relationnels et à utiliser les sous-requêtes.
Les schémas en étoile occupent davantage d'espace de stockage, car ils stockent des informations redondantes dans les tables de dimensions. Par exemple, si plusieurs produits appartiennent à la même catégorie, le nom de la catégorie sera répété pour chaque produit, ce qui augmentera les besoins en stockage.
Cependant, les schémas Snowflake normalisent les données afin de ne stocker chaque information qu'une seule fois. Par exemple, au lieu de répéter les noms de catégories, ceux-ci sont stockés dans une table distincte et liés à la table des produits à l'aide de clés étrangères. Cette conception permet de gagner de l'espace de stockage, ce qui la rend idéale pour les grands ensembles de données.
Les schémas en étoile sont particulièrement adaptés aux systèmes OLAP ( Online Analytical Processing ), au reporting et aux tâches de veille économique. Leur simplicité les rend particulièrement adaptés aux situations où la rapidité et la facilité d'utilisation sont essentielles, comme la création rapide de tableaux de bord ou de rapports de ventes.
Les schémas Snowflake sont fréquemment utilisés pour l'analyse financière ou les systèmes de gestion de la relation client (CRM). Dans de tels cas, l'organisation de hiérarchies détaillées et l'économie d'espace de stockage sont plus importantes que la vitesse de requête.
Voici une comparaison rapide des schémas en étoile et en Snowflake afin de vous aider à déterminer lequel correspond le mieux à vos besoins en matière de données. J'ai mis en évidence les principales différences dans ce tableau, en mettant l'accent sur leur structure, leurs performances, leur stockage et leurs cas d'utilisation :
|
Caractéristique |
Schéma en étoile |
Schéma Snowflake |
Approche hybride |
|
Structure |
Table centrale des faits liée à des dimensions dénormalisées |
Table centrale des faits reliée aux dimensions normalisées |
Modèle central normalisé, complété par des mart en étoile ou vues dénormalisées destinées à la consommation |
|
Complexité |
Simple, avec moins de jointures |
Complexe, avec davantage de jonctions |
Moyen, avec davantage de composants mobiles, mais chaque couche reste plus simple pour remplir sa fonction. |
|
Redondance des données |
Redondance accrue due aux dimensions dénormalisées |
Réduction de la redondance grâce à la normalisation des dimensions |
Redondance moyenne due à une dénormalisation sélective |
|
Performance des requêtes |
Recherches plus rapides grâce à une structure simplifiée |
Ralentissement des requêtes en raison de jointures supplémentaires |
Rapide pour la BI car la couche de consommation est dénormalisée |
|
Stockage |
Nécessite davantage d'espace de stockage en raison de la redondance. |
Nécessite moins d'espace de stockage grâce à la normalisation. |
Nécessite un stockage modéré car les marts/vues peuvent entraîner une certaine duplication. |
|
Facilité d'entretien |
Plus facile à concevoir et à entretenir |
Plus complexe à concevoir et à entretenir |
Facile à entretenir, car les marchés peuvent être reconstruits à partir du noyau contrôlé. |
|
Idéal pour |
Ensembles de données de petite à moyenne taille |
Ensembles de données volumineux et complexes |
Plateformes de données modernes répondant à la fois aux exigences de gouvernance et aux besoins de performance en matière de BI |
Si votre objectif principal est d'organiser vos données de manière simple et rapide, le schéma en étoile serait idéal. Voici quand vous pouvez l'utiliser :
Le schéma Snowflake est plus adapté à la représentation des hiérarchies et des données de référence partagées, en particulier lorsque plusieurs attributs dimensionnels se répètent sur de nombreuses lignes. Voici quand vous pouvez l'utiliser :
Dans de nombreux entrepôts de données cloud modernes, le stockage est relativement peu coûteux par rapport au calcul. Cela signifie que le « stockage supplémentaire » provenant des dimensions dénormalisées est souvent moins important que le coût de calcul lié à l'analyse et à la jointure des données.
Lorsque vous choisissez entre l'étoile et Snowflake, veuillez prendre en considération le modèle de tarification de votre plateforme (calcul ou stockage), la concurrence des requêtes et la possibilité d'utiliser la mise en cache ou les vues matérialisées pour réduire les coûts liés aux requêtes.
Dans cet article, j'ai abordé les différences entre les schémas en étoile et en Snowflake, leurs points forts et les cas dans lesquels il convient d'utiliser l'un ou l'autre. J'espère que vous avez acquis une compréhension claire et des conseils pratiques pour votre travail. Si vous souhaitez en savoir plus, veuillez consulter ces ressources sur DataCamp :
Cours d'ingénierie des données
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
Tutoriel
Samuel Shaibu
Tutoriel
Matt Crabtree
Tutoriel
Tutoriel
Sejal Jaiswal

