
Kursus
Pengantar Data Engineering
4 Hr
128.3K
Jika Anda bekerja dengan gudang data, Anda tahu betapa pentingnya menata data agar efisien dan mudah dikelola. Namun, pernahkah Anda berpikir skema basis data mana yang paling sesuai dengan kebutuhan Anda? Ada dua kerangka utama yang bisa Anda gunakan untuk ini: skema star dan skema snowflake.
Skema star itu sederhana dan cepat — ideal ketika Anda perlu mengekstrak data untuk analisis dengan cepat. Di sisi lain, skema snowflake lebih terperinci. Skema ini memprioritaskan efisiensi penyimpanan dan pengelolaan relasi data yang kompleks.
Dalam artikel ini, saya akan mengulas struktur kedua skema ini, menyoroti perbedaannya, dan menjabarkan keunggulannya. Pada akhirnya, Anda akan tahu di mana masing-masing skema cocok dan bagaimana memutuskan mana yang terbaik untuk proyek data Anda.
Skema star adalah cara mengorganisasi data dalam basis data, terutama di gudang data, untuk memudahkan dan mempercepat analisis. Di tengah, ada tabel utama yang disebut tabel fakta, yang menyimpan data terukur seperti penjualan atau pendapatan. Di sekelilingnya terdapat tabel dimensi, yang menambahkan detail seperti nama produk, informasi pelanggan, atau tanggal. Tata letak ini membentuk bentuk menyerupai bintang.
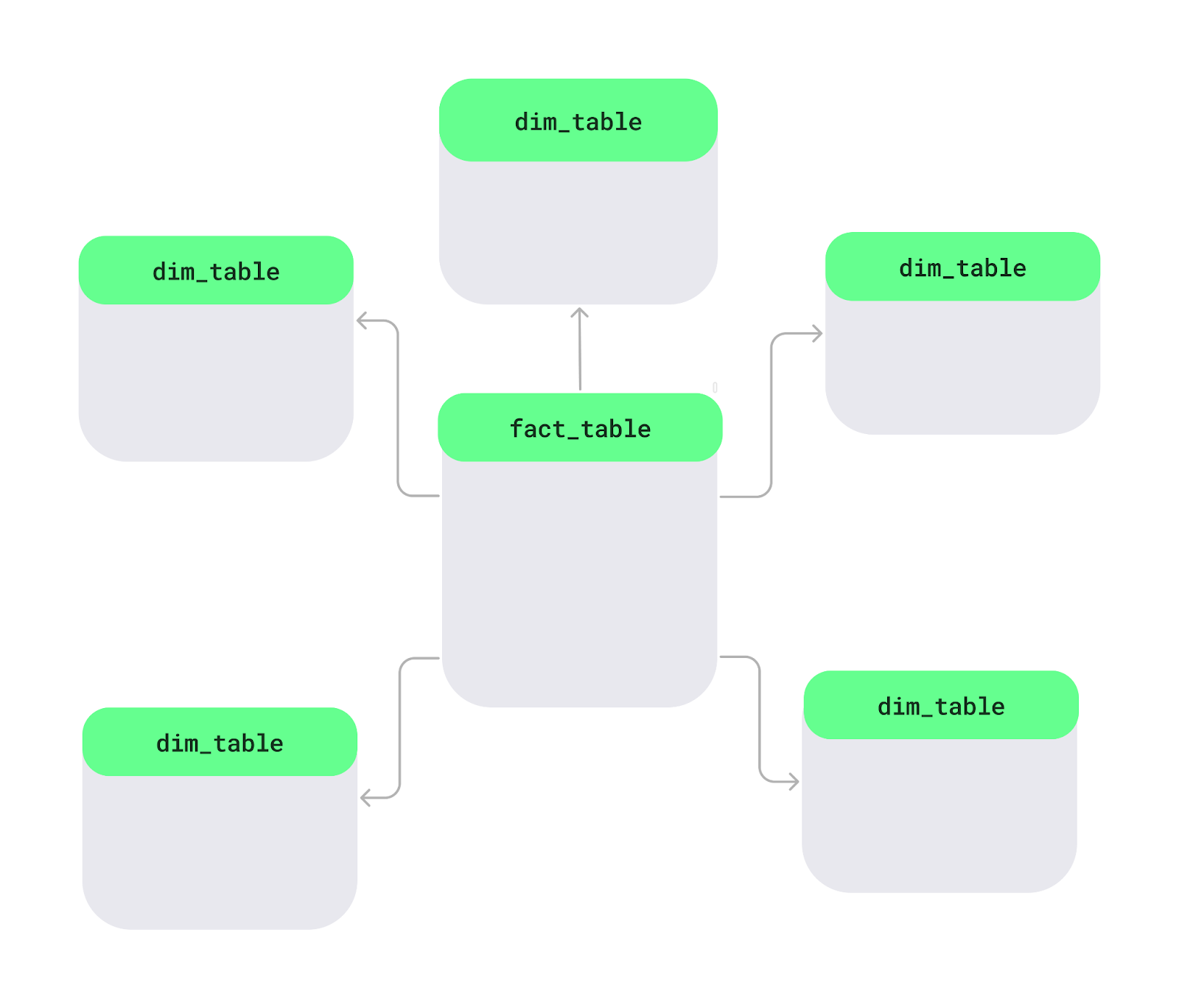
Tata letak skema star. Gambar oleh Penulis.
Mari lihat fitur utama skema star:
Mari pahami ini dengan diagram skema star sederhana. Tabel fakta Sales berada di tengah. Tabel ini menyimpan data numerik yang ingin Anda analisis, seperti penjualan atau laba. Terhubung dengannya ada tabel dimensi dengan detail deskriptif, seperti nama produk, lokasi pelanggan, atau tanggal:
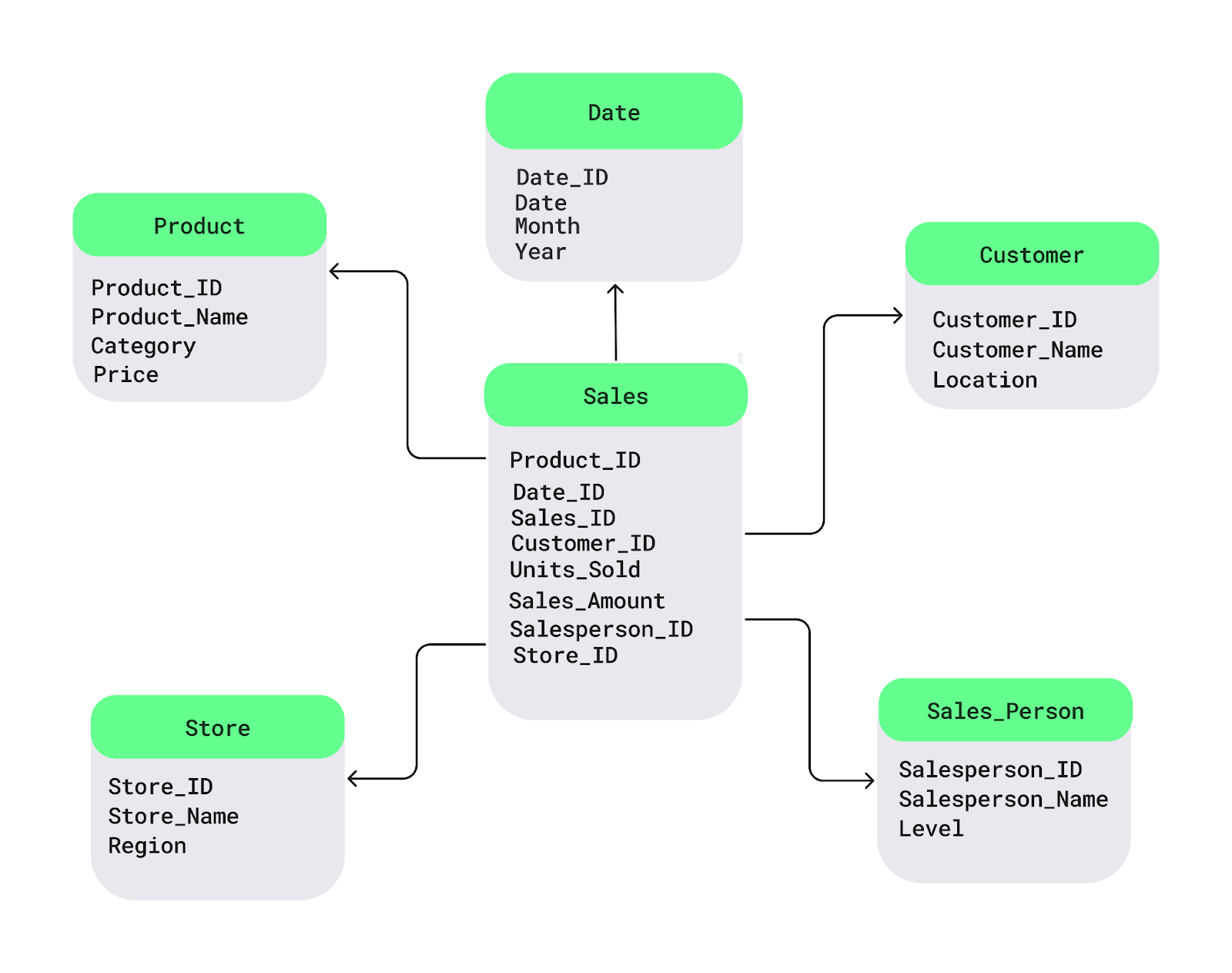
Contoh skema star. Gambar oleh Penulis.
Berikut contoh SQL sederhana untuk menyiapkan skema star dengan tabel fakta Sales dan tabel dimensi untuk Product, Customer, dan Date:
-- Fact table
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Product(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customer(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Date(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category VARCHAR(50)
);
-- Dimension table: Customer
CREATE TABLE Customer (
Customer_ID INT PRIMARY KEY,
Customer_Name VARCHAR(100),
Location VARCHAR(50)
);
-- Dimension table: Date
CREATE TABLE Date (
Date_ID INT PRIMARY KEY,
Date DATE,
Year INT,
Month VARCHAR(20)
);Tata letak ini mempercepat kueri karena tidak ada join yang kompleks. Misalnya, kueri berikut mengambil total penjualan yang dikelompokkan menurut lokasi pelanggan, memanfaatkan join sederhana dari skema star:
SELECT c.Location, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Customer c ON s.Customer_ID = c.Customer_ID
GROUP BY c.Location;Namun, Anda harus menerima adanya redundansi data karena tabel dimensi dapat berisi informasi yang berulang.
Sekarang setelah Anda tahu apa itu skema star, mari lihat mengapa skema ini menonjol:
Meski banyak manfaatnya, skema star memiliki kekurangan. Seperti saya sebutkan sebelumnya, karena denormalisasi, tabel dimensi sering berisi informasi yang berulang, yang meningkatkan penggunaan penyimpanan. Misalnya, jika beberapa produk termasuk dalam kategori yang sama, nama kategori tersebut mungkin berulang di tiap produk, sehingga memakan ruang penyimpanan lebih besar.
Skema snowflake adalah cara lain untuk mengorganisasi data. Dalam skema ini, tabel dimensi dipecah menjadi sub-dimensi yang lebih kecil agar data lebih tertata dan terperinci — layaknya kepingan salju di danau yang luas.
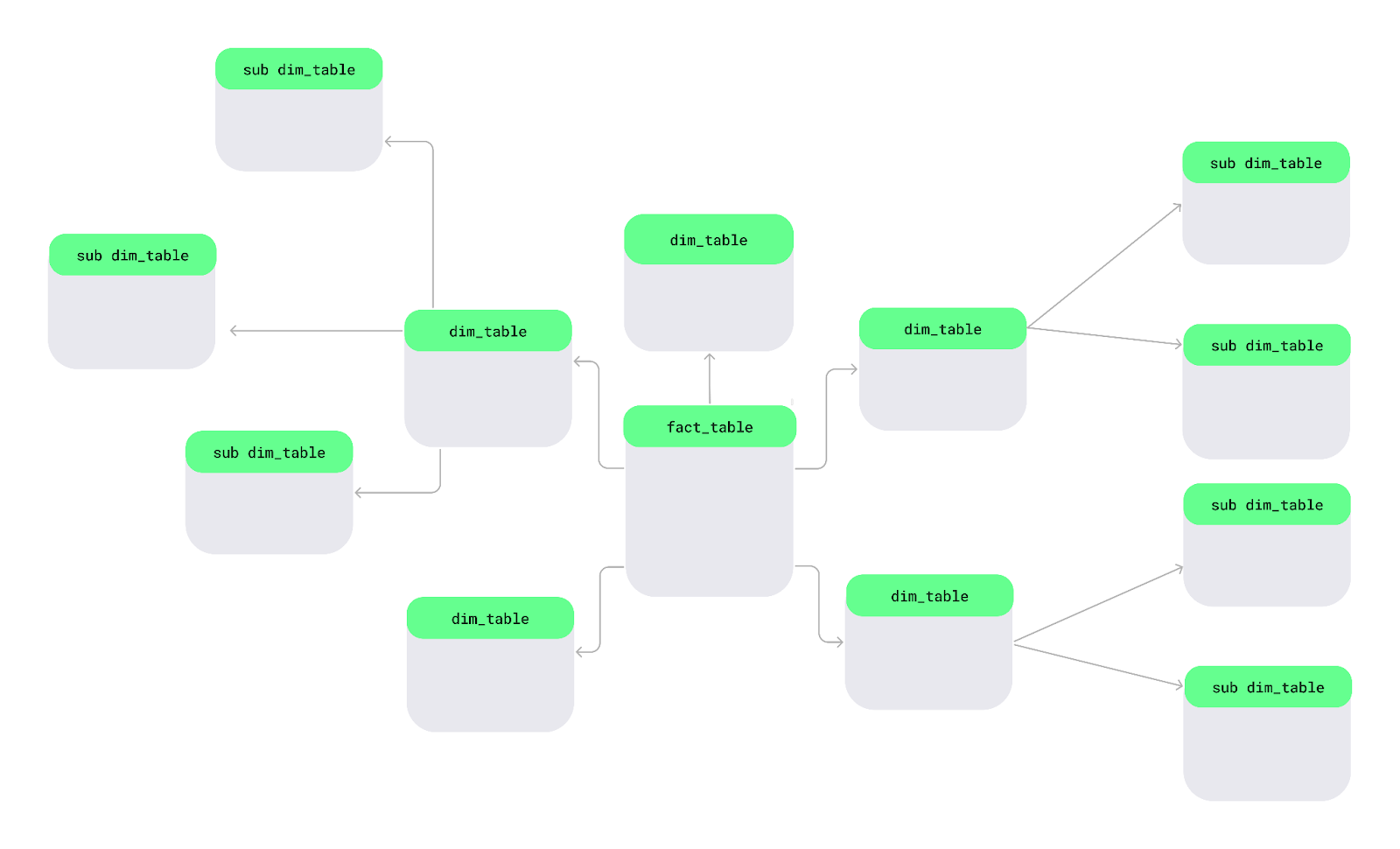
Tata letak skema snowflake. Gambar oleh Penulis.
Mari lihat fitur utama skema snowflake yang membedakannya dari skema lain:
Electronics untuk setiap produk, saya bisa menyimpan kategori di tabel terpisah dan menautkannya ke tiap produk.Mari pahami ini dengan diagram skema snowflake sederhana. Di tengah ada tabel fakta, yang berisi data terukur. Tabel ini terhubung ke tabel dimensi yang mendeskripsikan fakta, dan tabel dimensi tersebut bercabang lagi ke tabel sub-dimensi, membentuk struktur seperti kepingan salju.
Sebagai contoh, di sini saya memecah Product menjadi tabel Manufacturer dan Category serta tabel Customer menjadi tabel Transaction dan Location :
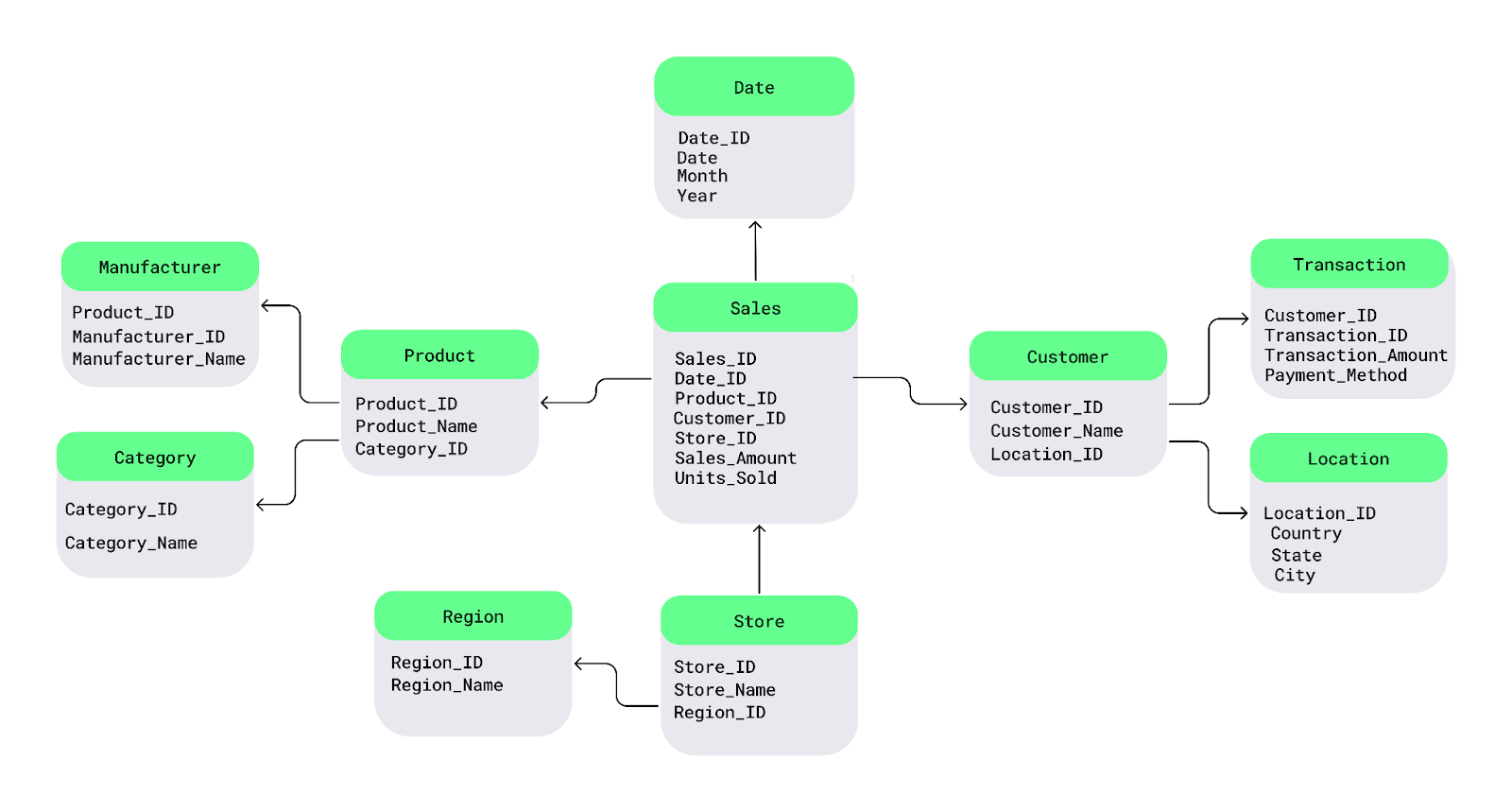
Contoh skema snowflake. Gambar oleh Penulis.
Berikut contoh SQL yang menggambarkan skema snowflake di mana tabel Product dinormalisasi lebih lanjut menjadi tabel Category dan Manufacturer:
-- Fact table remains the same
CREATE TABLE Sales (
Sales_ID INT PRIMARY KEY,
Product_ID INT,
Customer_ID INT,
Date_ID INT,
Sales_Amount DECIMAL(10, 2),
FOREIGN KEY (Product_ID) REFERENCES Products(Product_ID),
FOREIGN KEY (Customer_ID) REFERENCES Customers(Customer_ID),
FOREIGN KEY (Date_ID) REFERENCES Dates(Date_ID)
);
-- Dimension table: Product
CREATE TABLE Product (
Product_ID INT PRIMARY KEY,
Product_Name VARCHAR(100),
Category_ID INT,
Manufacturer_ID INT,
FOREIGN KEY (Category_ID) REFERENCES Category(Category_ID),
FOREIGN KEY (Manufacturer_ID) REFERENCES Manufacturer(Manufacturer_ID)
);
-- Sub-dimension table: Category
CREATE TABLE Category (
Category_ID INT PRIMARY KEY,
Category_Name VARCHAR(50)
);
-- Sub-dimension table: Manufacturer
CREATE TABLE Manufacturer (
Manufacturer_ID INT PRIMARY KEY,
Manufacturer_Name VARCHAR(100)
);Kueri berikut menghitung total penjualan berdasarkan kategori produk. Meskipun melibatkan lebih banyak join dibandingkan skema star, desain ini lebih efisien dalam penyimpanan:
SELECT cat.Category_Name, SUM(s.Sales_Amount) AS TotalSales
FROM Sales s
JOIN Product p ON s.Product_ID = p.Product_ID
JOIN Category cat ON p.Category_ID = cat.Category_ID
GROUP BY cat.Category_Name;Seperti skema star, skema snowflake juga memiliki keunggulannya sendiri. Mari lihat apa saja:
Namun, meski memiliki keunggulan, ada beberapa keterbatasan juga. Misalnya, kueri bisa lebih lambat karena ada lebih banyak join antar tabel. Selain itu, struktur multi-tingkat lebih menantang untuk dirancang dan dipelihara dibandingkan skema yang lebih sederhana seperti skema star. Jadi, gunakan ini hanya jika Anda memiliki tim DBA yang berpengalaman.
Saya menyarankan mengikuti kursus Database Design jika Anda ingin mempelajari lebih lanjut tentang menata data secara efisien untuk analisis.
Dalam proyek nyata, umum untuk menggunakan kedua pola pada lapisan yang berbeda guna menggabungkan kekuatan dari kedua pendekatan:
Ini memungkinkan tim menyeimbangkan integritas dan tata kelola data dengan konsumsi analitik yang cepat dan sederhana.
Baik skema star maupun snowflake banyak digunakan dalam gudang data, namun karakteristik uniknya membuat keduanya cocok untuk kebutuhan yang berbeda. Mari lihat bagaimana skema ini berbeda dalam struktur, performa, kebutuhan penyimpanan, dan kasus penggunaan.
Dalam skema star, semua tabel dimensi terhubung langsung ke satu tabel fakta pusat. Ini berarti semua data referensi Anda hanya selangkah dari data utama Anda, sehingga mudah dipahami dan digunakan.
Sebaliknya, skema snowflake memecah tabel dimensi menjadi tabel sub-dimensi yang lebih kecil dan lebih spesifik. Misalnya, Anda dapat memiliki tabel terpisah untuk negara, provinsi, dan kota alih-alih satu tabel lokasi. Walaupun ini menciptakan struktur yang lebih tertata dan terperinci, hal ini juga berarti dibutuhkan lebih banyak koneksi (atau join) untuk mengakses data — alasan utama mengapa skema snowflake lebih kompleks dibandingkan skema star.
Dalam hal kecepatan, skema star sering lebih unggul. Karena semua tabel dimensi terhubung langsung ke tabel fakta, kueri biasanya membutuhkan lebih sedikit join, yang berarti kinerja lebih cepat. Misalnya Anda ingin menganalisis penjualan berdasarkan wilayah — dalam kasus ini, Anda dapat menggunakan skema star untuk mengambil data dengan pemrosesan minimal.
Sebaliknya, skema Snowflake sering lebih lambat karena Anda harus terhubung melalui beberapa tabel untuk mengambil data. Setiap join menambah waktu pemrosesan, membuat skema snowflake kurang efisien untuk tugas yang memerlukan hasil kueri cepat.
Kursus Joining Data in SQL adalah pengantar yang sangat baik untuk mempelajari cara menggabungkan tabel, menerapkan teori himpunan relasional, dan bekerja dengan subkueri.
Skema star memerlukan lebih banyak ruang penyimpanan karena menyimpan informasi yang berulang dalam tabel dimensi. Misalnya, jika beberapa produk termasuk dalam kategori yang sama, nama kategori akan berulang di setiap produk, sehingga meningkatkan kebutuhan penyimpanan.
Namun, skema snowflake menormalisasi data agar semua informasi hanya disimpan sekali. Misalnya, alih-alih mengulang nama kategori, nama tersebut disimpan dalam tabel terpisah dan ditautkan ke tabel produk menggunakan foreign key. Desain ini menghemat ruang penyimpanan, sehingga ideal untuk dataset besar.
Skema star ideal untuk sistem online analytical processing (OLAP), pelaporan, dan tugas business intelligence. Kesederhanaannya membuatnya sempurna untuk skenario di mana kecepatan dan kemudahan penggunaan penting, seperti membuat dasbor cepat atau laporan penjualan.
Skema snowflake sering digunakan untuk analisis keuangan atau sistem manajemen hubungan pelanggan (CRM). Dalam kasus seperti ini, menata hierarki terperinci dan menghemat ruang penyimpanan lebih penting daripada kecepatan kueri.
Berikut perbandingan cepat antara skema star dan snowflake untuk membantu Anda memutuskan mana yang paling sesuai dengan kebutuhan data Anda. Saya menyoroti perbedaan utama pada tabel ini, berfokus pada struktur, performa, penyimpanan, dan kasus penggunaan:
|
Fitur |
Skema star |
Skema snowflake |
Pendekatan hibrida |
|
Struktur |
Tabel fakta pusat ditautkan ke dimensi terdenormalisasi |
Tabel fakta pusat ditautkan ke dimensi ternormalisasi |
Model inti ternormalisasi, plus mart berbentuk star atau view terdenormalisasi untuk konsumsi |
|
Kompleksitas |
Sederhana, dengan lebih sedikit join |
Kompleks, dengan lebih banyak join |
Sedang, dengan lebih banyak komponen, namun setiap lapisan tetap sederhana sesuai tujuannya |
|
Redundansi data |
Redundansi lebih tinggi karena dimensi terdenormalisasi |
Redundansi lebih rendah karena dimensi ternormalisasi |
Redundansi sedang karena denormalisasi selektif |
|
Performa kueri |
Kueri lebih cepat karena struktur yang lebih sederhana |
Kueri lebih lambat karena join tambahan |
Cepat untuk BI karena lapisan konsumsi terdenormalisasi |
|
Penyimpanan |
Memerlukan lebih banyak penyimpanan karena redundansi |
Memerlukan lebih sedikit penyimpanan karena normalisasi |
Memerlukan penyimpanan moderat karena mart/view dapat menambah sebagian duplikasi |
|
Kemudahan pemeliharaan |
Lebih mudah dirancang dan dipelihara |
Lebih kompleks untuk dirancang dan dipelihara |
Mudah dipelihara, karena mart dapat dibangun ulang dari inti yang terkontrol |
|
Paling cocok untuk |
Dataset kecil hingga menengah |
Dataset besar dan kompleks |
Platform data modern dengan kebutuhan tata kelola dan performa BI sekaligus |
Jika Anda terutama ingin menata data secara sederhana dan cepat, skema star akan sangat cocok. Berikut kapan Anda dapat menggunakannya:
Skema snowflake lebih cocok untuk merepresentasikan hierarki dan data referensi bersama, terutama ketika banyak atribut dimensi berulang di banyak baris. Berikut kapan Anda dapat menggunakannya:
Di banyak gudang data cloud modern, biaya penyimpanan relatif murah dibandingkan komputasi. Artinya, “penyimpanan ekstra” dari dimensi terdenormalisasi sering kurang penting dibandingkan biaya komputasi untuk memindai dan menggabungkan data.
Saat memilih antara star dan snowflake, pertimbangkan model harga platform Anda (komputasi vs penyimpanan), konkurensi kueri, serta apakah Anda dapat menggunakan caching/materialized view untuk menekan biaya kueri.
Dalam blog ini, saya telah membahas perbedaan antara skema star dan snowflake, kekuatannya, serta kapan menggunakan masing-masing. Saya harap Anda mendapatkan pemahaman yang jelas dan kiat praktis untuk pekerjaan Anda! Jika ingin belajar lebih lanjut, lihat sumber berikut di DataCamp:
Kursus Data Engineering
Kursus
Kursus
Kursus
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
