Kurs
Python’a Giriş
4 sa
6.9M
Bulanık dize eşleştirme algoritması, iki farklı dizenin birbirine ne kadar yakın olduğunu belirlemeye çalışır. Bu da “düzenleme mesafesi” olarak bilinen bir uzaklık metriği kullanılarak bulunur. Düzenleme mesafesi, bir dizenin diğerine dönüştürülmesi için gereken en az sayıda “düzenleme”yi bularak iki dizenin ne kadar yakın olduğunu belirler.
Eğer düzenleme mesafesi bize bir dizenin diğerinden kaç işlem uzakta olduğunu söylemek için düzenleme işlemlerinin sayısını sayıyorsa, bir düzenleme, bir dizenin başka bir dizeye dönüştürülmesi için o dize üzerinde gerçekleştirilen bir işlemdir.
Dört temel düzenleme türü vardır:
| Düzenleme İşlemi | Açıklama | Örnek |
|---|---|---|
| Ekle | Bir harf ekle | "Londn" -> "London" |
| Sil | Bir harf çıkar | "Londoon" -> "London" |
| Yer değiştir | Yanyana iki harfi takas et | "Lnodon" -> "London" |
| Değiştir | Bir harfi başka bir harfle değiştir | "Londin" -> "London" |
Bu dört düzenleme işlemi, herhangi bir dizenin değiştirilmesini mümkün kılar.
Düzenleme işlemlerini birleştirmek, N düzenleme uzakta olan olası dizelerin listesini keşfetmenizi sağlar; burada N, düzenleme işlemlerinin sayısıdır. Örneğin “London” ile “Londin” arasındaki düzenleme mesafesi birdir; çünkü “i”nin “o” ile değiştirilmesi tam eşleşmeye götürür.
Peki düzenleme mesafesi tam olarak nasıl hesaplanır?
Düzenleme mesafesini hesaplamanın farklı varyasyonları vardır. Örneğin Levenshtein mesafesi, Hamming mesafesi, Jaro mesafesi ve daha fazlası.
Bu eğitimde yalnızca Levenshtein mesafesi ile ilgileniyoruz.
Bu metrik, iki kelime dizisi arasındaki farkı ölçmek için 1965'te ilk olarak bunu ele alan Vladimir Levenshtein'in adını taşır. Tek bir kelime dizisini diğerine dönüştürmek için yapmanız gereken en az sayıda düzenlemeyi bulmak için kullanabiliriz.
Resmî hesaplama şöyledir:
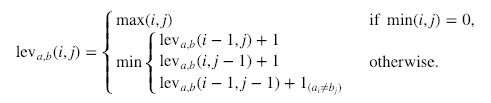
Burada 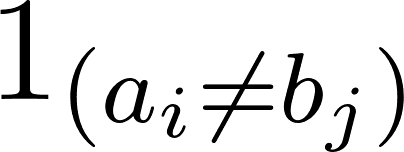 a=b iken 0'ı, aksi halde 1'i ifade eder.
a=b iken 0'ı, aksi halde 1'i ifade eder.
Yukarıdaki minimumdaki satırların sırasıyla silme, ekleme ve yerine koymaya (ikameye) karşılık geldiğini not etmek önemlidir.
Levenshtein mesafesine dayanarak Levenshtein benzerlik oranını hesaplamak da mümkündür. Bu, aşağıdaki formülle yapılabilir:
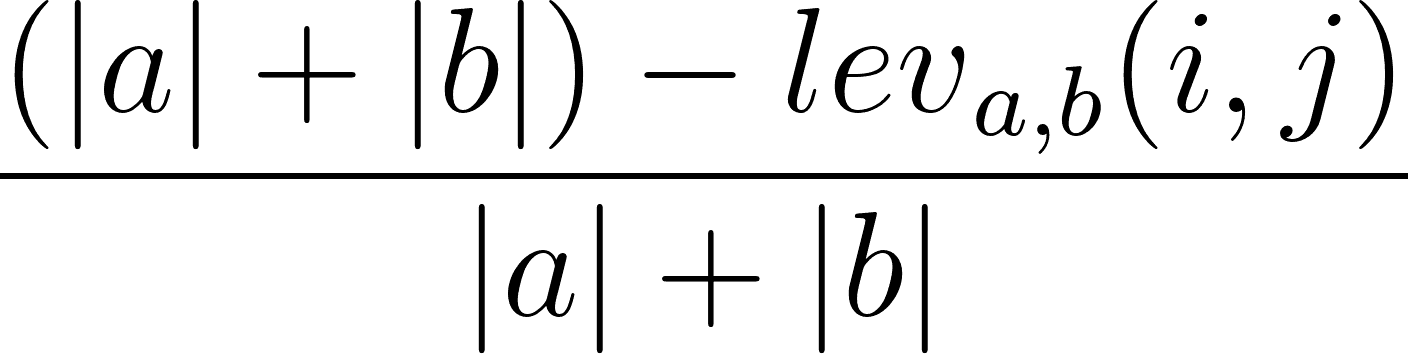
burada |a| ve |b| sırasıyla a ve b dizilerinin uzunluklarıdır.
Python'da bulanık dize eşleştirme için en popüler paketlerden biri tarihsel olarak FuzzyWuzzy idi. Ancak lisans sorunlarını çözmek ve kod tabanını güncellemek için proje 2021'de TheFuzz olarak yeniden adlandırıldı. Sadelik nedeniyle yeni başlayanlar için hâlâ başvurulan bir kütüphanedir ve bu eğitimde kullanacağımız kütüphanedir.
İlk olarak SeatGeek tarafından, benzer isimlere sahip iki bilet ilanının aynı etkinlik için olup olmadığını ayırt etmek amacıyla geliştirildi. Selekörü gibi TheFuzz, iki dize arasındaki yakınlığı hesaplamak için Levenshtein düzenleme mesafesini kullanır.
İpucu: Üretimde RapidFuzz kullanın. TheFuzz öğrenme ve küçük veri kümeleri için mükemmel olsa da, büyük ölçekli veri işleme için yavaş kalabilir. Sektör büyük ölçüde RapidFuzz adlı daha yeni bir kütüphaneye yönelmiştir.
fuzz.ratio), dolayısıyla daha sonra kolayca geçiş yapabilirsiniz.Bu rehberde, birçok ortamda önceden yüklü geldiği ve temel kavramları anlamak için ideal olduğu için TheFuzz ile devam edeceğiz.
Önce TheFuzz paketini kurmalıyız. Bunu aşağıdaki komutla pip kullanarak yapabilirsiniz:
!pip install thefuzzNot: Bu kütüphane DataLab çalışma kitabında önceden yüklüdür.
Şimdi, thefuzz ile neler yapabileceğimize bir göz atalım.
Bu DataLab çalışma kitabındaki kodla birlikte ilerleyin.
İki dize arasındaki basit oranı, fuzz nesnesi üzerindeki ratio() yöntemiyle belirleyebiliriz. Bu, her iki giriş dizisinin sıralamasına dayanarak düzenleme mesafesini hesaplar difflib.ratio() – daha fazla bilgi için difflib belgelerine bakın.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.ratio(name, full_name)}")
"""
Similarity Score: 86
"""Kodda, adımın iki varyasyonunu benzerlik puanını karşılaştırmak için kullandık ve sonuç 86 olarak verildi.
Bunu kısmi oranla karşılaştıralım.
Kısmi oranı kontrol etmek için yukarıdaki kodda yapmamız gereken tek şey ratio() yerine fuzz nesnemizde partial_ratio() çağırmaktır.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Similarity score: {fuzz.partial_ratio(name, full_name)}")
"""
Similarity Score: 67
"""Bir düşüş görüyoruz. Ne oluyor?
partial_ratio(), iki dizenin kısmen ne kadar benzer olduğunu bulmaya çalışır. İki dize, ortak bir sırada bazı kelimelere sahipse kısmen benzerdir.
partial_ratio(), daha kısa olan diziyi alarak (bu senaryoda name değişkeninde saklanmıştır) daha uzun dizide (full_name) aynı uzunluktaki alt dizelerle karşılaştırıp benzerliği hesaplar.
Kısmi oranda sıralama önemli olduğundan, bu örnekte puanımız düştü. Dolayısıyla %100 benzerlik eşleşmesi için, "K D" kısmını (ikinci adımı ifade ediyor) dizenin sonuna taşımanız gerekir. Örneğin:
# Order matters with partial ratio
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis Pykes K D"
print(f"Partial ratio similarity score: {fuzz.partial_ratio(name, full_name)}")
# But order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Partial ratio similarity score: 100
Simple ratio similarity score: 86
"""Peki bulanık dize eşleştiricimizin sıralamayı görmezden gelmesini istersek?
O zaman “token sort ratio”yu kullanmak isteyebilirsiniz.
Tamam, dizelerdeki kelimelerin sıralamasını yok saymak ama yine de ne kadar benzer olduklarını belirlemek istiyoruz – token sort tam olarak bunu yapmanıza yardımcı olur. Token sort, kelimelerin hangi sırayla geçtiğiyle ilgilenmez. Yukarıda açıklandığı gibi, sırada olmayan benzer dizeleri hesaba katar.
Dolayısıyla, en son örnekte token sort ratio kullanarak %100 puan almalıyız:
# Check the similarity score
full_name = "Kurtis K D Pykes"
full_name_reordered = "Kurtis Pykes K D"
# Order does not matter for token sort ratio
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(full_name_reordered, full_name)}")
# Order matters for partial ratio
print(f"Partial ratio similarity score: {fuzz.partial_ratio(full_name, full_name_reordered)}")
# Order will not effect simple ratio if strings do not match
print(f"Simple ratio similarity score: {fuzz.ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
Partial ratio similarity score: 75
Simple ratio similarity score: 86
"""… ve beklendiği gibi aldık.
Orijinal name ve full_name değişkenlerine geri dönelim. Şimdi token sort kullanırsak ne olacağını düşünüyorsunuz?
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_sort_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 86
"""Puan düşüyor.
Bunun nedeni token sort'un yalnızca sıralamayı görmezden gelmesidir. Dizelerde benzer olmayan kelimeler varsa, yukarıda gördüğümüz gibi bu durum benzerlik oranını olumsuz etkiler.
Ancak bir çözüm yolu var.
token_set_ratio() yöntemi token_sort_ratio()ya oldukça benzer, ancak benzerliği hesaplamadan önce ortak tokenları çıkarır: bu, dizelerin uzunlukları önemli ölçüde farklı olduğunda son derece yararlıdır.
Hem name hem de full_name değişkenleri “Kurtis Pykes”ı içerdiğinden, token set ratio benzerliğinin %100 olmasını bekleyebiliriz.
# Check the similarity score
name = "Kurtis Pykes"
full_name = "Kurtis K D Pykes"
print(f"Token sort ratio similarity score: {fuzz.token_set_ratio(name, full_name)}")
"""
Token sort ratio similarity score: 100
"""Process modülü, kullanıcıların bir koleksiyondan bulanık dize eşleştirme kullanarak metin çıkarmasını sağlar. Process modülünde extract() yöntemini çağırmak, benzerlik puanlarıyla birlikte dizeleri bir vektörde döndürür. Örneğin:
from thefuzz import process
collection = ["AFC Barcelona", "Barcelona AFC", "barcelona fc", "afc barcalona"]
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82), ('afc barcalona', 73)]
"""extract() yönteminin döndürdüğü vektörün uzunluğunu, limit parametresini istenen uzunluğa ayarlayarak kontrol edebiliriz.
print(process.extract("barcelona", collection, scorer=fuzz.ratio))
"""
[('barcelona fc', 86), ('AFC Barcelona', 82), ('Barcelona AFC', 82)]
"""Bu örnekte, extract() tanımladığımız skorlayıcıya göre en yakın üç eşleşen diziyi döndürür.
Aşağıdaki tabloda, TheFuzz içinde bulunan farklı tekniklerin hızlı bir karşılaştırmasını görebilirsiniz:
| Teknik | Açıklama | Kod Örneği |
|---|---|---|
| Basit Oran | Girdi dizelerinin sırasını dikkate alarak benzerliği hesaplar. | fuzz.ratio(name, full_name) |
| Kısmi Oran | Daha kısa diziyi alt dizelerle karşılaştırarak kısmi benzerliği bulur. | fuzz.partial_ratio(name, full_name) |
| Token Sort Oranı | Dizelerdeki kelimelerin sırasını yok sayar. | fuzz.token_sort_ratio(full_name_reordered, full_name) |
| Token Set Oranı | Benzerliği hesaplamadan önce ortak tokenları kaldırır. | fuzz.token_set_ratio(name, full_name) |
Bu bölümde, bir pandas veri çerçevesinde bulanık dize eşleştirme yapmayı göreceğiz.
Diyelim ki bir veriyi pandas veri çerçevesine aktardınız ve bunu elinizdeki mevcut verilerle birleştirmek istiyorsunuz.
import pandas as pd
# Creating a dataframe
dict_one = {
"country": ["England", "Scotland", "Wales", "United Kingdom", "Northern Ireland"],
"population_in_millions": [55.98, 5.45, 3.14, 67.33, 1.89]
}
dict_two = {
"country": ["Northern Iland", "Wles", "Scotlnd", "Englnd", "United K."],
"GDP_per_capita": [24900, 23882, 37460, 45101, 46510.28]
}
existing_data = pd.DataFrame(dict_one)
exported_data = pd.DataFrame(dict_two)
print(existing_data, exported_data, sep="\n\n")
"""
country population_in_millions
0 England 55.98
1 Scotland 5.45
2 Wales 3.14
3 United Kingdom 67.33
4 Northern Ireland 1.89
country GDP_per_capita
0 Northern Iland 24900.00
1 Wles 23882.00
2 Scotlnd 37460.00
3 Englnd 45101.00
4 United K. 46510.28
"""Önemli bir sorun var.
Mevcut verilerde ülkelerin doğru yazımları varken, dışa aktarılan verilerde yok. İki veri çerçevesini country sütununda birleştirmeye çalışırsak, pandas yanlış yazılmış kelimeleri doğru yazılmış kelimelerle eşit olarak tanımaz. Dolayısıyla merge işlevinden dönen sonuç beklendiği gibi olmayacaktır.
Deneseydik ne olacağı aşağıda:
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 NaN
1 Scotland 5.45 NaN
2 Wales 3.14 NaN
3 United Kingdom 67.33 NaN
4 Northern Ireland 1.89 NaN
"""Bu, bu veri çerçevelerini birleştirme girişiminin tüm amacını boşa çıkarır.
Ancak, bu sorunu bulanık dize eşleştirme ile aşabiliriz.
Kodda nasıl göründüğüne bakalım:
# Rename the misspelled columns
exported_data["country"] = exported_data["country"].apply(
lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]
)
# Attempt to join the two dataframe
data = pd.merge(existing_data, exported_data, on="country", how="left")
print(data.head())
"""
country population_in_millions GDP_per_capita
0 England 55.98 45101.00
1 Scotland 5.45 37460.00
2 Wales 3.14 23882.00
3 United Kingdom 67.33 46510.28
4 Northern Ireland 1.89 24900.00
"""Bu kodda, dışa aktarılan verilerin country sütunundaki yanlış yazılmış değerleri, process.extractOne() yöntemiyle birlikte kullandığımız şık bir lambda işleviyle yeniden adlandırdık. Dikkat edin, yalnızca benzer dizeyi döndürmek için extractOne() sonucunda 0 indeksini kullandık; böylece dize ve benzerlik değerini içeren bir liste yerine doğrudan dizeyi aldık.
Ardından, veri çerçevelerini country sütununda sol birleştirme ile birleştirdik. Sonuç, doğru yazılmış ülkeleri (Birleşik Krallık'ın siyasi birliği dahil) içeren tek bir veri çerçevesidir.
Yukarıdaki çözüm bu eğitim ve küçük veri kümeleri için mükemmel olsa da, bunu "Büyük Veri"ye uygularken dikkatli olun.
Bulanık eşleştirme ile .apply() kullandığınızda, bilgisayar A veri çerçevesindeki her bir satırı B veri çerçevesindeki her bir satırla karşılaştırmak zorundadır (Kartezyen Çarpım).
Birkaç bin satırı aşan veri kümeleri için, hız için C++ kullanan RapidFuzzu veya karşılaştırmaları azaltmak için "bloklama" kullanan Splinki düşünün.
Yukarıda bahsedilen tekniklere hızlı bir özet gerekiyorsa, bunları aşağıdaki tabloda bulabilirsiniz:
| Adım | Açıklama | Kod Parçası |
|---|---|---|
| DataFrame Oluşturun | Yanlış yazımlar içerebilecek verileri tanımlayın. | existing_data = pd.DataFrame(dict_one), exported_data = pd.DataFrame(dict_two) |
| Hatalı Birleştirmeyi Deneyin | İlk birleştirme, eşleşmeyen dizeler nedeniyle başarısız olur. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
| Yanlış Yazımları Düzeltin | Bulanık eşleştirme kullanarak yanlış yazılmış ülke adlarını düzeltin. | exported_data["country"] = exported_data["country"].apply(lambda x: process.extractOne(x, existing_data["country"], scorer=fuzz.partial_ratio)[0]) |
| Başarılı Birleştirme | Bulanık dize eşleştirme ile yanlış yazımları düzelttikten sonra veri çerçevelerini birleştirin. | data = pd.merge(existing_data, exported_data, on="country", how="left") |
Bu eğitimde şunları öğrendiniz:
Buradaki örnekler basit olabilir, ancak bir bilgisayarın eşleşmiyor olarak düşündüğü çeşitli dize durumlarının nasıl ele alınacağını göstermek için yeterlidir. Yazım denetimi ve biyoinformatik gibi alanlarda, DNA dizilerini eşleştirmek için bulanık mantığın kullanıldığı birçok bulanık eşleştirme uygulaması vardır.
Python kursları
Kurs
Kurs
Kurs
blog
Dario Radečić
15 dk.
blog
Abid Ali Awan
14 dk.
Eğitim
Adel Nehme
Eğitim
Kurtis Pykes
