Course
Intermediate Python
4 hr
1.4M
In deep learning, it is common to see a lot of discussion around tensors as the cornerstone data structure. Tensor even appears in the name of Google’s flagship machine learning library: “TensorFlow”. Tensors are a type of data structure used in linear algebra, and like vectors and matrices, you can calculate arithmetic operations with tensors.
On the other hand, PyTorch is a python package built by Facebook that provides two high-level features: 1) Tensor computation (like Numpy) with strong GPU acceleration and 2) Deep Neural Networks built on a tape-based automatic differentiation system.
In this tutorial, you will discover what tensors are and how to manipulate them in Python with PyTorch.
So, without further ado let's get started with the introduction to Tensors.
A tensor is a generalization of vectors and matrices and is easily understood as a multidimensional array. According to the popular deep learning book called "Deep Learning" (Goodfellow et al.) -
"In the general case, an array of numbers arranged on a regular grid with a variable number of axes is known as a tensor."
A scalar is zero-order tensor or rank zero tensor. A vector is a one-dimensional or first order tensor, and a matrix is a two-dimensional or second order tensor.
The following info-graphic describes tensors in a very convenient way:
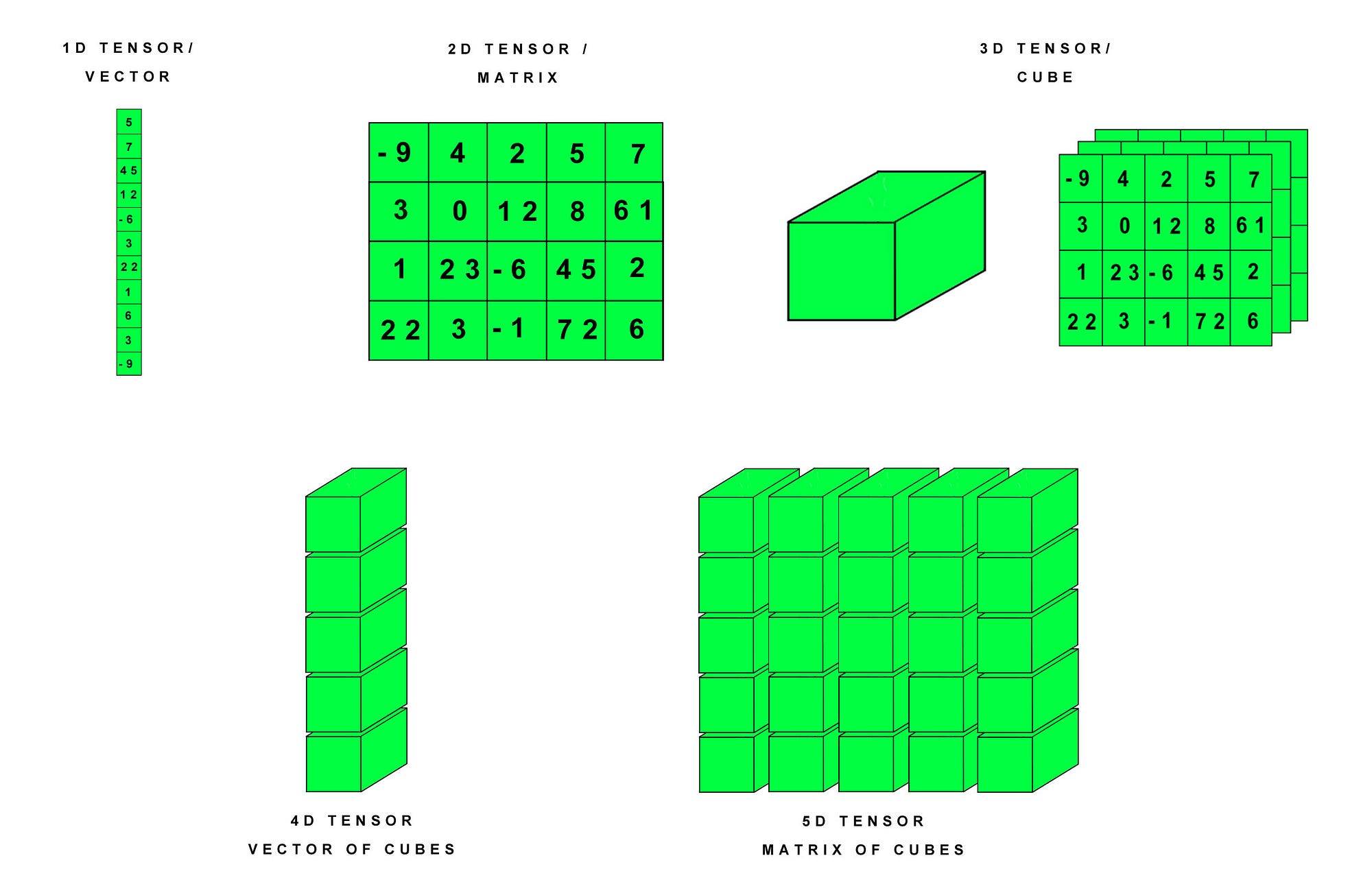
Let's build the intuition behind tensors in a more lucid way now.
A tensor is the basic building block of modern machine learning. At its core, it's a data container. Mostly it contains numbers. Sometimes it even includes strings, but that is rare. So think of it as a bucket of numbers.
But often, people confuse tensors with multi-dimensional arrays. As per StackExchange:
Tensors and multidimensional arrays are different types of object. The first is a type of function The second is a data structure suitable for representing a tensor in a coordinate system.
Mathematically, tensors are defined as a multi-linear function. A multi-linear function consists of various vector variables. A tensor field is a tensor-valued function. For a rigorous mathematical explanation, you can read here.
So, tensors are functions or containers which you need to define. The actual calculation happens when there is data fed. What you see as arrays or multi-dimensional (1D, 2D, …, ND) can be considered as generic tensors.
Now, let's talk a bit about Tensor notation.
Tensor notation is much like matrix notation with a capital letter representing a tensor and lowercase letters with subscript integers representing scalar values within the tensor.

Many of the operations that can be performed with scalars, vectors, and matrices can be reformulated to be performed with tensors.
As a tool, tensors and tensor algebra is widely used in the fields of physics and engineering. It is a term, and set of techniques known in machine learning in the training and operation of deep learning models can be described regarding tensors.
PyTorch is a Python-based scientific computing package targeted for:
Let's quickly summarize the unique features of PyTorch -
PyTorch provides a wide variety of tensor routines to accelerate and fit your scientific computation needs such as slicing, indexing, math operations, linear algebra, reductions. And they are fast.
PyTorch has a unique way of building neural networks: using and replaying a tape recorder.
Most frameworks such as TensorFlow, Theano, Caffe and CNTK have a static view of the world. One has to build a neural network and reuse the same structure again and again. Changing the way the network behaves means that one has to start from scratch.
PyTorch uses a technique called Reverse-mode auto-differentiation, which allows you to change the way your network behaves arbitrarily with zero lag or overhead. Our inspiration comes from several research papers on this topic, as well as current and past work such as autograd, autograd, Chainer, etc.
(While this technique is not unique to PyTorch, it’s one of the fastest implementations of it to date. You get the best of speed and flexibility for your crazy research.)
(Hence, PyTorch is quite fast – whether you run small or large neural networks.)
This blog makes the comparison between PyTorch and Tensorflow very well.
P.S.: This DataCamp blog is an excellent starter for getting started with Tensorflow.
Installation of PyTorch is pretty straightforward. As PyTorch supports efficient GPU computation, it efficiently communicates with your Cuda drivers and performs things faster.
You will be needing torch and torchvision for using PyTorch. Let's install them for a Windows environment. Later, you will see the steps for Linux and Mac as well.
I have Python 3.5 with Anaconda setup. Also, I don't have CUDA. Run the following commands to install torch and torchvision:
(Please keep in mind that PyTorch does not support Python 2.7. So it is must have a Python version => 3.5.)
If you have CUDA enabled on your machine feel free and run the following (this is for CUDA 9.0):
Now, let's see the installation steps for a Linux environment with Python 3.5 and no CUDA support:
Yes, you guessed it right! It is the same as the Windows' one.
Now, if you have CUDA support (9.0) then the step would be:
For a Mac environment with Python 3.5 and no CUDA support the steps would be:
And, with CUDA support (9.0):
(MacOS Binaries don't support CUDA, install from source if CUDA is needed)
Hope, you are done with the installation of PyTorch by now!
Now, let's straight dive to some Tensor arithmetic with PyTorch.
First, let's import all the required libraries.
from __future__ import print_function
import torch
If the PyTorch installation was successful, then running the above lines of code won't give you any errors.
Now, let's construct a 5x3 matrix, uninitialized:
x = torch.rand(5, 3)
print(x)
tensor([[ 0.5991, 0.9365, 0.6120],
[ 0.3622, 0.1408, 0.8811],
[ 0.6248, 0.4808, 0.0322],
[ 0.2267, 0.3715, 0.8430],
[ 0.0145, 0.0900, 0.3418]])
Construct a matrix filled zeros and of data type long:
x = torch.zeros(5, 3, dtype=torch.long)
print(x)
tensor([[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0],
[ 0, 0, 0]])
Construct a tensor directly from data:
x = torch.tensor([5.5, 3])
print(x)
tensor([ 5.5000, 3.0000])
If you understood Tensors correctly, tell me what kind of Tensor x is in the comments section!
You can create a tensor based on an existing tensor. These methods will reuse properties of the input tensor, e.g. dtype (data type), unless new values are provided by user:
x = x.new_ones(5, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
print(x)
tensor([[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.],
[ 1., 1., 1.]], dtype=torch.float64)
tensor([[-1.2174, 1.1807, 1.4249],
[-1.1114, -0.8098, 0.4003],
[ 0.0780, -0.5011, -1.0985],
[ 1.8160, -0.3778, -0.8610],
[-0.7109, -2.0509, -1.2079]])
Get its size:
print(x.size())
torch.Size([5, 3])
Note that torch.Size is in fact a tuple, so it supports all tuple operations.
Now, let's do an addition operation on Tensors.
The element-wise addition of two tensors with the same dimensions results in a new tensor with the same dimensions where each scalar value is the element-wise addition of the scalars in the parent tensors.

# Syntax 1 for Tensor addition in PyTorch
y = torch.rand(5, 3)
print(x)
print(y)
print(x + y)
tensor([[-1.2174, 1.1807, 1.4249],
[-1.1114, -0.8098, 0.4003],
[ 0.0780, -0.5011, -1.0985],
[ 1.8160, -0.3778, -0.8610],
[-0.7109, -2.0509, -1.2079]])
tensor([[ 0.8285, 0.7619, 0.1147],
[ 0.1624, 0.8994, 0.6119],
[ 0.2802, 0.2950, 0.7098],
[ 0.8132, 0.3382, 0.4383],
[ 0.6738, 0.2022, 0.3264]])
tensor([[-0.3889, 1.9426, 1.5396],
[-0.9490, 0.0897, 1.0122],
[ 0.3583, -0.2061, -0.3887],
[ 2.6292, -0.0396, -0.4227],
[-0.0371, -1.8487, -0.8815]])
# Syntax 2 for Tensor addition in PyTorch
print(torch.add(x, y))
tensor([[-0.3889, 1.9426, 1.5396],
[-0.9490, 0.0897, 1.0122],
[ 0.3583, -0.2061, -0.3887],
[ 2.6292, -0.0396, -0.4227],
[-0.0371, -1.8487, -0.8815]])
Let's do Tensor subtraction now.
The element-wise subtraction of one tensor from another tensor with the same dimensions results in a new tensor with the same dimensions where each scalar value is the element-wise subtraction of the scalars in the parent tensors4.

Now let's take a look at Tensor Product:
Performs a matrix multiplication of the matrices mat1 and mat2.
If mat1 is a (n×m) tensor, mat2 is a (m×p) tensor, out will be a (n×p) tensor.
You do Tensor products in PyTorch like the following:
mat1 = torch.randn(2, 3)
mat2 = torch.randn(3, 3)
print(mat1)
print(mat2)
print(torch.mm(mat1, mat2))
tensor([[ 1.9490, -0.6503, -1.9448],
[-0.7126, 1.0519, -0.4250]])
tensor([[ 0.0846, 0.4410, -0.0625],
[-1.3264, -0.5265, 0.2575],
[-1.3324, 0.6644, 0.3528]])
tensor([[ 3.6185, -0.0901, -0.9753],
[-0.8892, -1.1504, 0.1654]])
Note that torch.mm() does not broadcast. Let's discuss a bit about broadcasting.
The term broadcasting describes how arrays are treated with different shapes during arithmetic operations. Subject to certain constraints, the smaller array is “broadcast” across, the broader array so that they have compatible shapes. Broadcasting provides a means of vectorizing array operations so that looping occurs in C instead of Python. It does this without making needless copies of data and usually leads to efficient algorithm implementations. There are, however, cases where broadcasting is a bad idea because it leads to inefficient use of memory that slows computation.
Two tensors are “broadcastable” if the following rules hold:
Let's understand this with PyTorch using the following code snippet:
x=torch.empty(5,7,3)
y=torch.empty(5,7,3)
# same shapes are always broadcastable (i.e. the above rules always hold)
x=torch.empty((0,))
y=torch.empty(2,2)
# x and y are not broadcastable, because x does not have at least 1 dimension
# can line up trailing dimensions
x=torch.empty(5,3,4,1)
y=torch.empty( 3,1,1)
# x and y are broadcastable.
# 1st trailing dimension: both have size 1
# 2nd trailing dimension: y has size 1
# 3rd trailing dimension: x size == y size
# 4th trailing dimension: y dimension doesn't exist
# but:
>>> x=torch.empty(5,2,4,1)
>>> y=torch.empty( 3,1,1)
# x and y are not broadcastable, because in the 3rd trailing dimension 2 != 3
Now that you have got a fair idea of broadcasting let's see if two tensors are "broadcastable" then what would be their resulting tensor.
If two tensors x, y are “broadcastable”, the resulting tensor size is calculated as follows:
If the number of dimensions of x and y are not equal, prepend 1 to the dimensions of the tensor with fewer dimensions to make them equal length. Then, for each dimension size, the resulting dimension size is the max of the sizes of x and y along that dimension. For Example:
# can line up trailing dimensions to make reading easier
x=torch.empty(5,1,4,1)
y=torch.empty( 3,1,1)
(x+y).size()
torch.Size([5, 3, 4, 1])
torch.Size([5, 3, 4, 1])
# but not necessary:
x=torch.empty(1)
y=torch.empty(3,1,7)
(x+y).size()
torch.Size([3, 1, 7])
torch.Size([3, 1, 7])
x=torch.empty(5,2,4,1)
y=torch.empty(3,1,1)
(x+y).size()
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-17-72fb34250db7> in <module>()
1 x=torch.empty(5,2,4,1)
2 y=torch.empty(3,1,1)
----> 3 (x+y).size()
RuntimeError: The size of tensor a (2) must match the size of tensor b (3) at non-singleton dimension 1
You get the concept now!
The tensor product is the most common form of tensor multiplication that you may encounter, but many other types of tensor multiplications exist, such as the tensor dot product and the tensor contraction.
Converting a Torch Tensor to a NumPy array and vice versa is a breeze. The concept is called Numpy Bridge. Let's take a look at that.
The Torch Tensor and NumPy array will share their underlying memory locations, and changing one will change the other.
Converting a Torch Tensor to a NumPy Array.
# A 1D tensor of 5 ones
a = torch.ones(5)
print(a)
tensor([ 1., 1., 1., 1., 1.])
# Convert the Torch tensor to a NumPy array
b = a.numpy()
print(b)
[1. 1. 1. 1. 1.]
See how the NumPy array changed in value.
So, in the above sections, you did some basic Tensor arithmetic like addition, subtraction, and tensor products. Now in the following section, you will implement a basic neural network in PyTorch.
If you need a refresher on neural nets, then this DataCamp article is the best to look for. You might want to check the following links as well:
Before the implementing, let's discuss a bit about a concept called Automatic Differentiation which is central to all neural networks in PyTorch. This is particularly useful for calculating gradients in the course of doing backpropagation.
The autograd package provides automatic differentiation for all operations on Tensors. It is a define-by-run framework, which means that your backpropagation is defined by how your code is run and that every single iteration can be different.
Let's see Automatic Differentiation in action with a straightforward code example.
# Create a Rank-2 tensor of all ones
x = torch.ones(2, 2, requires_grad=True)
print(x)
tensor([[ 1., 1.],
[ 1., 1.]])
Do an addition operation.
y = x + 2
print(y)
tensor([[ 3., 3.],
[ 3., 3.]])
Do some more operations on y.
z = y * y * 3
out = z.mean()
print(z, out)
tensor([[ 27., 27.],
[ 27., 27.]]) tensor(27.)
Let’s backprop now because out contains a single scalar, out.backward() is equivalent to out.backward(torch.tensor(1)).
out.backward()
# print gradients d(out)/dx
print(x.grad)
tensor([[ 4.5000, 4.5000],
[ 4.5000, 4.5000]])

Now you know about Automatic Differentiation and how PyTorch handles it. You will now code a simple neural network using PyTorch.
You’ll create a simple neural network with one hidden layer and a single output unit. You will use the ReLU activation in the hidden layer and the sigmoid activation in the output layer.
First, you need to import the PyTorch library. Neural networks can be constructed using the torch.nn package.
import torch
import torch.nn as nn
Then you e define the sizes of all the layers and the batch size:
n_in, n_h, n_out, batch_size = 10, 5, 1, 10
And now, you will create some dummy input data x and some dummy target data y. You will use PyTorch Tensors to store this data. PyTorch Tensors can be used and manipulated just like NumPy arrays but with the added benefit that PyTorch tensors can be run on the GPUs. But you will simply run them on the CPU for this tutorial. Although, it is quite simple to transfer them to a GPU.
x = torch.randn(batch_size, n_in)
y = torch.tensor([[1.0], [0.0], [0.0], [1.0], [1.0], [1.0], [0.0], [0.0], [1.0], [1.0]])
And now, you will define our model in one line of code.
model = nn.Sequential(nn.Linear(n_in, n_h),
nn.ReLU(),
nn.Linear(n_h, n_out),
nn.Sigmoid())
This creates a model that looks like input -> linear -> relu -> linear -> sigmoid. There is another way to define your models which is used to define more complicated and custom models. It is done by defining our model in a class. You can read about it here.
Now, it is time to construct your loss function. You will use the Mean Squared Error Loss.
criterion = torch.nn.MSELoss()
Also, don’t forget to define your optimizer. You will use the mighty Stochastic Gradient Descent in this one and a learning rate of 0.01. model.parameters() returns an iterator over your model’s parameters (weights and biases).
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
Now, you will run Gradient Descent for 50 epochs. This does the forward propagation, loss computation, backward propagation and parameter updates in that sequence.
for epoch in range(50):
# Forward Propagation
y_pred = model(x)
# Compute and print loss
loss = criterion(y_pred, y)
print('epoch: ', epoch,' loss: ', loss.item())
# Zero the gradients
optimizer.zero_grad()
# perform a backward pass (backpropagation)
loss.backward()
# Update the parameters
optimizer.step()
epoch: 0 loss: 0.2399429827928543
epoch: 1 loss: 0.23988191783428192
epoch: 2 loss: 0.23982088267803192
epoch: 3 loss: 0.2397598922252655
epoch: 4 loss: 0.23969893157482147
epoch: 5 loss: 0.23963800072669983
epoch: 6 loss: 0.23957709968090057
epoch: 7 loss: 0.23951618373394012
epoch: 8 loss: 0.23945537209510803
epoch: 9 loss: 0.23939454555511475
epoch: 10 loss: 0.23933371901512146
epoch: 11 loss: 0.23927298188209534
epoch: 12 loss: 0.23921218514442444
epoch: 13 loss: 0.23915143311023712
epoch: 14 loss: 0.2390907108783722
epoch: 15 loss: 0.23903003334999084
epoch: 16 loss: 0.23896940052509308
epoch: 17 loss: 0.23890872299671173
epoch: 18 loss: 0.23884813487529755
epoch: 19 loss: 0.23878750205039978
epoch: 20 loss: 0.23872694373130798
epoch: 21 loss: 0.2386663407087326
epoch: 22 loss: 0.2386058121919632
epoch: 23 loss: 0.23854532837867737
epoch: 24 loss: 0.23848481476306915
epoch: 25 loss: 0.23842433094978333
epoch: 26 loss: 0.2383638620376587
epoch: 27 loss: 0.23830339312553406
epoch: 28 loss: 0.2382429838180542
epoch: 29 loss: 0.23818258941173553
epoch: 30 loss: 0.2381247729063034
epoch: 31 loss: 0.2380656749010086
epoch: 32 loss: 0.23800739645957947
epoch: 33 loss: 0.2379491776227951
epoch: 34 loss: 0.2378900945186615
epoch: 35 loss: 0.23783239722251892
epoch: 36 loss: 0.23777374625205994
epoch: 37 loss: 0.23771481215953827
epoch: 38 loss: 0.23765745759010315
epoch: 39 loss: 0.23759838938713074
epoch: 40 loss: 0.23753997683525085
epoch: 41 loss: 0.2374821901321411
epoch: 42 loss: 0.23742322623729706
epoch: 43 loss: 0.23736533522605896
epoch: 44 loss: 0.23730707168579102
epoch: 45 loss: 0.23724813759326935
epoch: 46 loss: 0.23719079792499542
epoch: 47 loss: 0.23713204264640808
epoch: 48 loss: 0.23707345128059387
epoch: 49 loss: 0.2370160073041916
y_pred gets the predicted values from a forward pass of our model. You pass this, along with target values y to the criterion which calculates the loss.
Then, optimizer.zero_grad() zeroes out all the gradients. You need to do this so that previous gradients don’t keep on accumulating.
Then, loss.backward() is the main PyTorch magic that uses PyTorch’s Autograd feature. Autograd computes all the gradients w.r.t. all the parameters automatically based on the computation graph that it creates dynamically. Basically, this does the backward pass (backpropagation) of gradient descent.
Finally, you call optimizer.step() which does a single update of all the parameters using the new gradients.
So, you have made till the end. In this post, you covered a whole bunch of things starting from Tensors to Automatic Differentiation and what not! You also implemented a simple neural net using PyTorch and its tensor system.
If you want to learn more about PyTorch and want to dive deeper into it, take a look at PyTorch’s official documentation and tutorials. They are really well-written. You can find them here.
Following are some references which helped me in writing this tutorial:
Let me know if you have something to ask or discuss in the comments section!
If you are interested in learning more about Python, take DataCamp's Statistical Thinking in Python (Part 1).
Learn more about Python and PyTorch
Course
Course
cheat-sheet
Richie Cotton
Tutorial
Karlijn Willems
Tutorial
Kurtis Pykes
Tutorial
Arjun Sarkar
Tutorial
Zoumana Keita
Tutorial
Karlijn Willems



