
Track
AI Fundamentals
10 hr
The emergence of large language models has transformed industries, bringing the power of technologies like OpenAI's GPT-3.5 and GPT-4 to various applications. However, the high cost and data confidentiality concerns often deter potential adopters. This is where open-source models like Vicuna-13B come in, offering similar performance without the significant expense and risk to sensitive information.
To learn more about GPT-3.5 and GPT-4, our tutorial Using GPT-3.5 and GPT-4 via the OpenAI API in Python is a good starting point to understand how to work with the OpenAI Python package to programmatically have conversations with ChatGPT.
Vicuna-13B is an open-source conversational model trained from fine-tuning the LLaMa 13B model using user-shared conversations gathered from ShareGPT.
A preliminary evaluation using GPT-4 as a judge showed Vicuna-13B achieving more than 90% quality of chatGPT and Google Bard, then outperformed other models like LLaMa and Alpaca in more than 90% of cases. The overall fine-tuning and evaluation workflow is illustrated below:
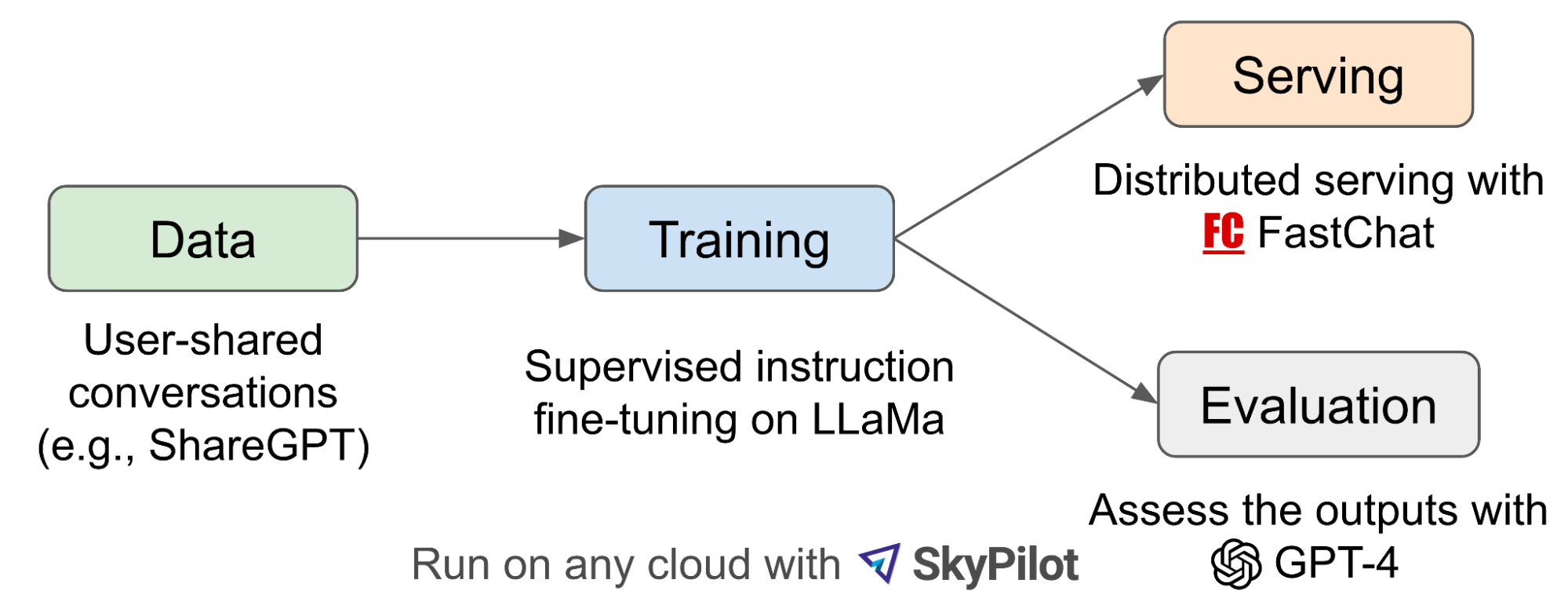
Vicuna-13B fine-tuning and evaluation workflow (source)
While this highlights the strength of Vicuna-13B, it has its own limitations and is not limited to tasks such as mathematics and reasoning.
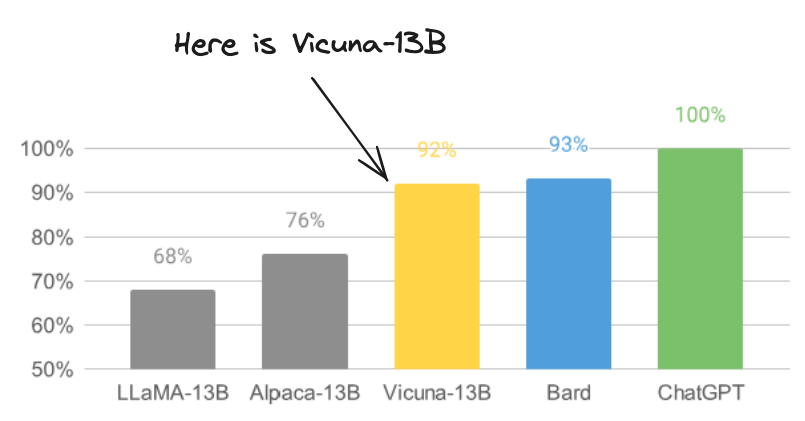
Image from LMSYSORG modified by author
As an intelligent chatbot, the applications of Vicuna-13B are countless, and some of them are illustrated below in different industries, such as customer service, healthcare, education, finance, and travel/hospitality.

Five different applications of Vicuna-13 in real-life
The above list is not exhaustive, and our article How NLP is changing the future of Data Science discusses how NLP is driving the future of data science and machine learning, its future applications, risks, and how to mitigate them.
Based on these real-life applications, there is no doubt that there is a tremendous demand for AI-powered conversational agents like Vicuna-13B across major industries.
Hence, mastering how to implement and integrate such technology into an industry workflow is becoming an increasing skill as more companies use these technologies to empower their customer engagements, generate more leads, and overall increase their return on investments.
The good news is that the whole purpose of this tutorial is to help you develop the required skills to run the Vicuna-13B model and be able to integrate it into any business information system workflow.
Before diving into the running process of the Vicuna-13B model, it is important to properly set up the prerequisites, which includes:
Once these requirements are met, we will have a better understanding of the input and output formats and be able to successfully run the model.
Having a better understanding of the input and output format of the Vicuna-13B can provide the developer with a minimum knowledge of the factors that could affect the model decision-making.
This section explains the main required parameters in the input along with the expected output format of the Vicuna-13B model.
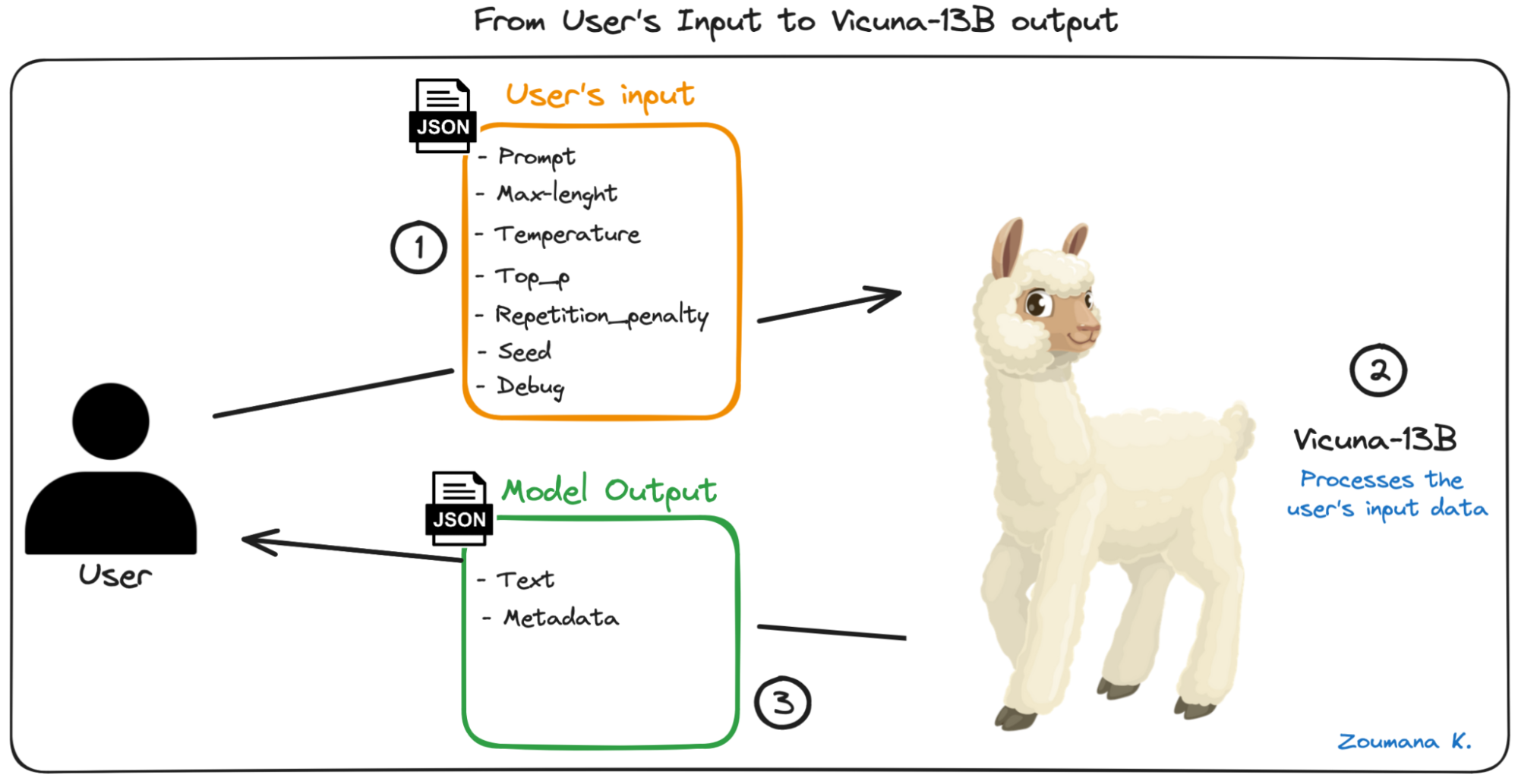
Minimalist workflow of the end-to-end workflow
Let’s understand the above workflow. First, the user submits the desired input, which includes the prompt, which is the main textual request the user might want a response for.
The prompt is provided along with the following additional parameters:
After submitting the prompt with the above parameters, the Vicuna-13B model performs the relevant processing under the hood to generate the required output, which corresponds to the following schema:
Now that we have a better understanding of the input and output, we can proceed with the identification of the main libraries to successfully run the vicuna model.
All the commands in this section are run from a terminal. Using the conda create statement, we create a virtual environment called vicuna-env.
conda create --name vicuna-envAfter successful creating the virtual environment, we activate the above virtual environment using the conda activate statement, as follows from :
conda activate vicuna-envThe above statement should display the name of the environment variable between brackets at the beginning of the terminal as follows:

Name of the virtual environment after activation
The above libraries can be installed in two ways. The first one is by manually running the pip install for each library, and this can be time-consuming when dealing with a significant amount of libraries and is not optimal when working at an industry level.
The second one is the best option and uses a requirements.txt file containing each one of the required libraries. Below is the content of the requirements.txt file, along with the installation using a single pip install command.
# Content of the requirements.txt file
llama-cpp-python==0.1.48
fastapi
uvicorn[standard]All three libraries can be installed as follows:
pip install -r requirements.txtFrom the Hugging Face platform, we can download the Vicuna model weights as shown below:
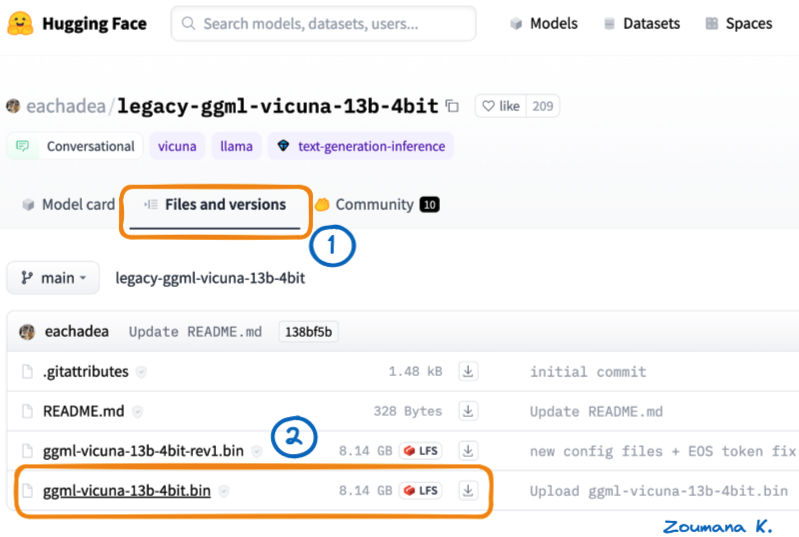
Two main steps to download Vicuna-13B weight from Hugging face
For a better organization of the code, we can move the downloaded model’s weight to a new model folder.
While all the prerequisites have been met to run the model via the command line, deploying an API that interfaces with the model is a more practical approach. This will make the model easily accessible to a wider range of users.
To achieve that level, we need the following steps:
The overall structure of the source code is given below, and the complete code is available on GitHub.
------ model
|------- ggml-vicuna-13b-4bit.bin
------ requirements.txt
------ vicuna_app.pyggml-vicuna-13b-4bit.bin is the downloaded model weight in the model folderrequirements.txt contains the dependencies to run the modelvicuna_app.py contains the Python code to create the API, which is the main focus of this section.In our case, the following two main routes are required. Before that, we need to import the relevant libraries, load the model, and create an instance of the FastAPI module.
# Import the libraries
from fastapi import FastAPI, HTTPException
from llama_cpp import Llama
# Load the model
vicuna_model_path = "./model/ggml-vicuna-13b-4bit.bin"
vicuna_model = Llama(model_path=vicuna_model_path)
app = FastAPI()"/” returns the following JSON format “Message”: “Welcome to the Vicuna Demo FastAPI” through the home() function which does not take a parameter.# Define the default route
@app.get("/")
def home():
return {"Message": "Welcome to the Vicuna Demo FastAPI"}/vicuna_says” responsible for triggering the answer_prompt() function, which takes as a parameter the user’s prompt, and returns a JSON response containing the the Vicuna model’s result and some additional metadata.@app.post("/vicuna_says")
def answer_prompt(user_prompt):
if (not (user_prompt)):
raise HTTPException(status_code=400,
detail="Please Provide a valid text message")
response = vicuna_model(user_prompt)
return {"Answer": response}We can finally run the API with the following instruction from the command line, from the location of the vicuna_app.py file.
uvicorn vicuna_app:app --reloaduvicorn starts the unicorn server.vicuna_app: corresponds to the python vicuna_app.py. It is the one on the left of the “:” sign.app: corresponds to the object created inside the vicuna_app.py file with the instruction app = FastAPI(). If the name of the file was main.py the instruction would be uvicorn main:app --reload--reload: an option used to restart the server after any code changes. Keep in mind that this is to be used only when we are in the development stage, not during the deployment stage.Here is the result we get from running the previous command, and we can see that the server is running on the localhost on port 8000 (http://127.0.0.1:8000)

Url of the API running on localhost
Accessing the default route is straightforward. Just type the following URL on any browser.

Response from the default route
Here is an interesting part. The URL http://127.0.0.1:8000/docs provides a complete dashboard for interacting with the API, and below is the result.
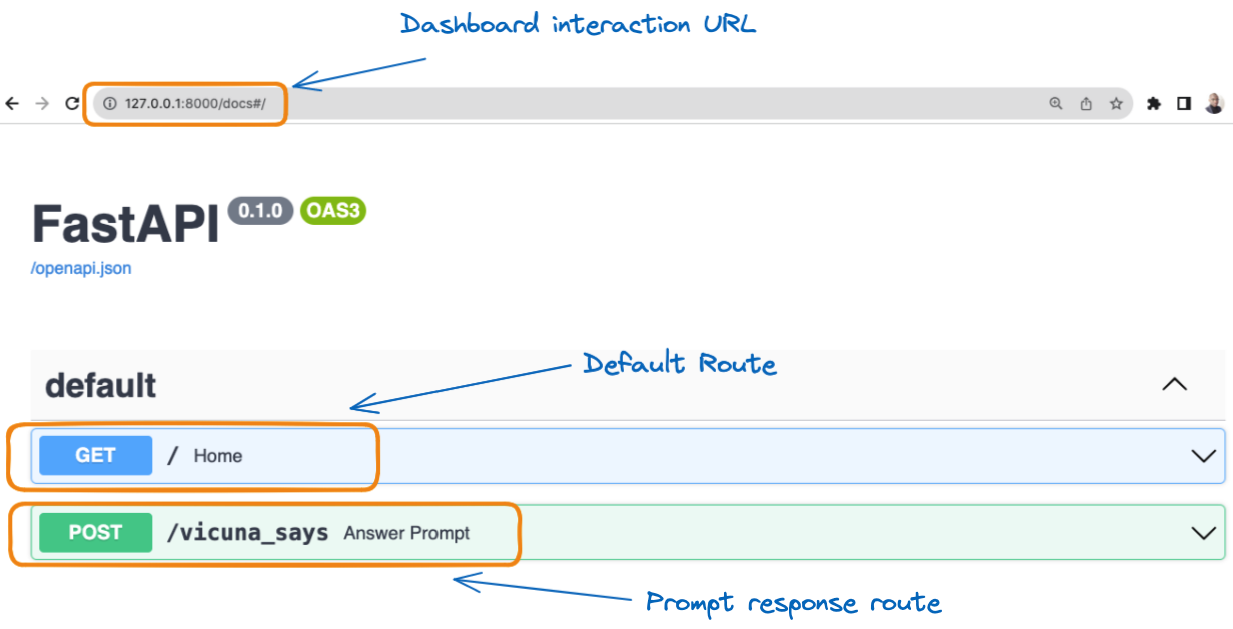
Graphical visualization of the two routes
From the previous Image, when we select the /vicuna_says in the green box, we get the complete guide to interact with our API, as shown below.
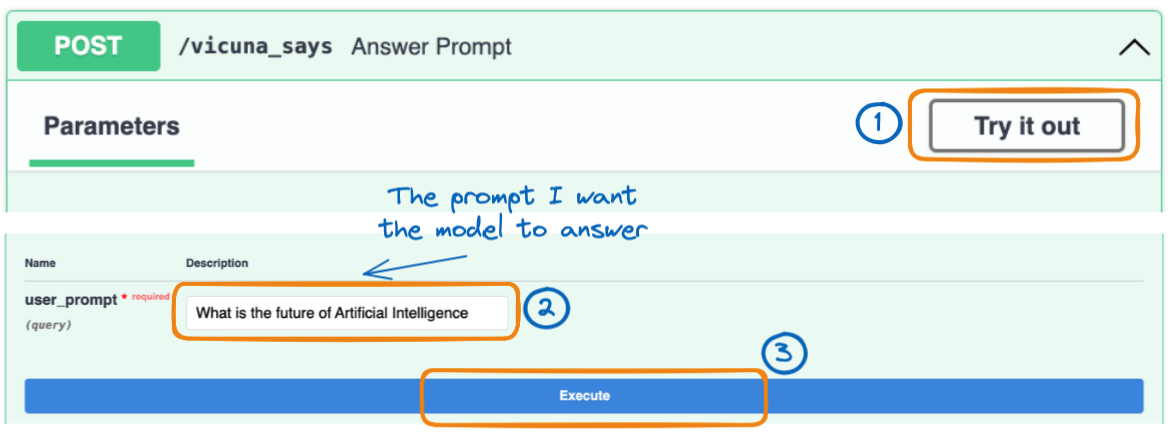
The three main steps to execute the user’s prompt
Just select the Try it out tab and provide the message you want the prediction for in the text_message zone.
We finally get the following result after selecting the Execute button.
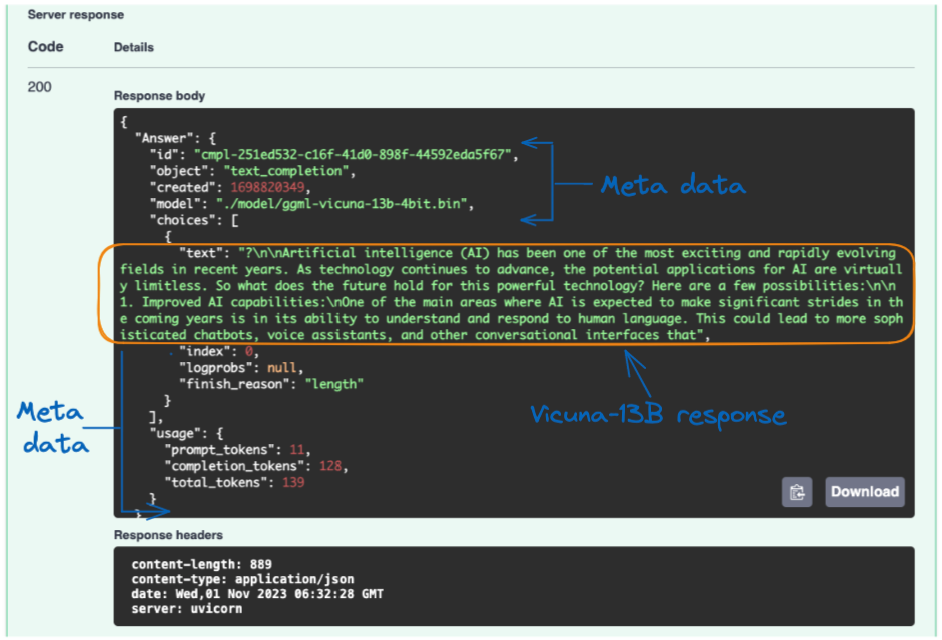
Server response from the Vicuna model to the user’s query
The Vicuna model response is provided in the “text” field, and the result looks pretty impressive.
Additional metadata is provided, such as the model being used, the response creation date, the number of tokens in the prompt, and the number of tokens in the response, just to mention a few.
Deploying such a powerful the model enhances user experience and operational efficiency in several notable ways, and not limited to the ones below:
Overall, deployment facilitates a more accessible, reliable, and versatile use of the vicuna-13B model, broadening its applicability for various users and applications.
When working with the Vicuna-13B model, a few best practices and tips can help developers optimize their experience, results and troubleshoot common issues.
By following these best practices and tips, they can ensure a smoother experience and better results when working with the Vicuna-13B model.
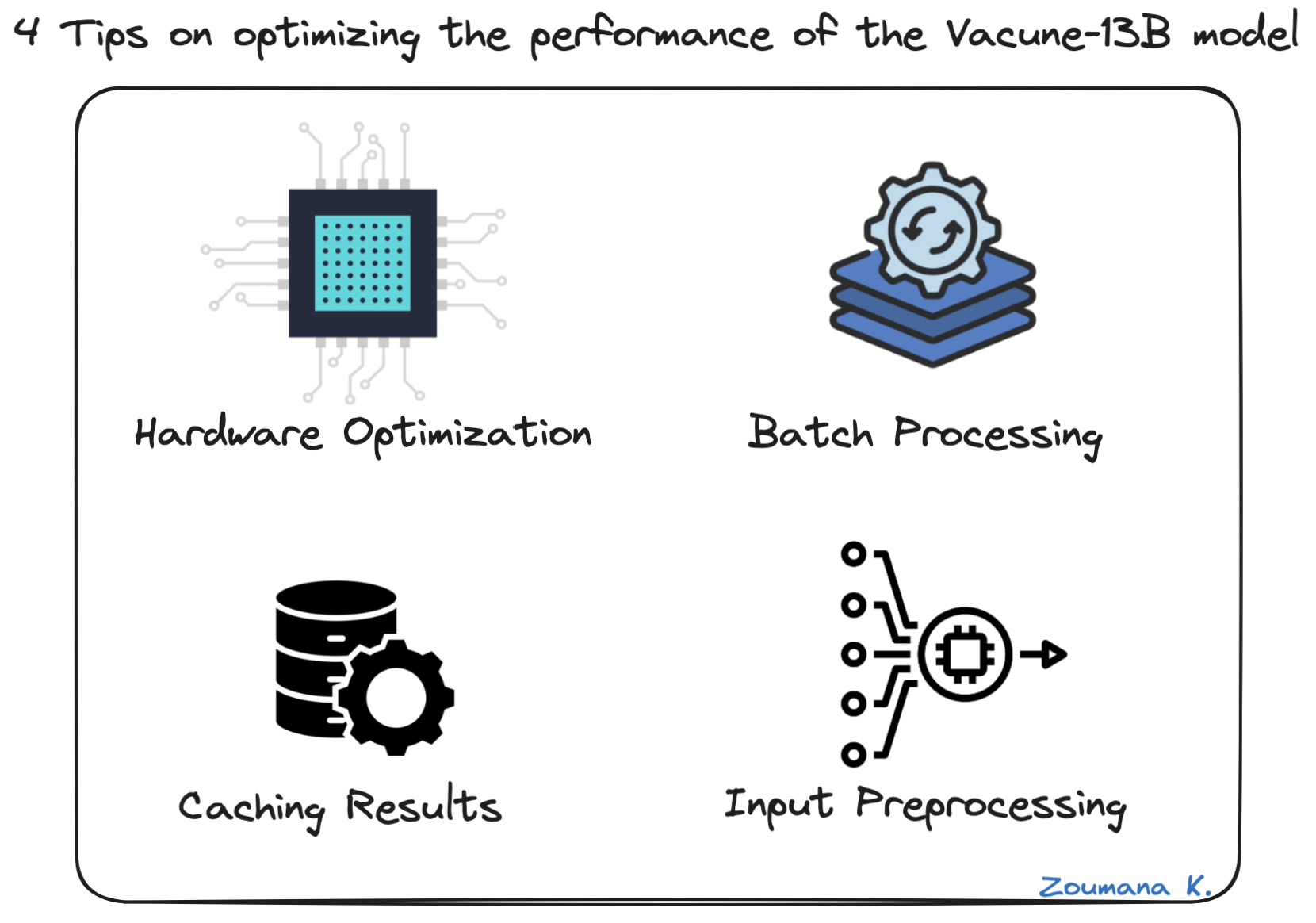
4 tips to optimize the performance of the Vicuna-13B model
Transitioning from performance optimization, it is also important to be adept at troubleshooting common issues that might arise during the use of Vicuna-13B, and below are four examples:
Some common troubleshooting issues
In summary, this article has provided a comprehensive overview on setting up and utilizing the Vicuna-13B model. We covered the necessary prerequisites, including hardware, software, and obtaining the LLaMa weights essential for running the model successfully.
Detailed instructions were provided for setting up the working environment, installing the required software, and setting up Vicuna-13B's weights, emphasizing the significance of weights in language models.
Furthermore, we delved into the packaging and deployment of Vicuna-13B, highlighting how deployment facilitates its usage as a web interface and API.
Finally, Practical insights on interacting with Vicuna-13B, examples of its capabilities, and best practices for optimizing its performance and troubleshooting common issues were also shared.
Ready to dive deeper into the world of AI and machine learning? Enhance your skills with the powerful deep learning framework used by AI professionals. Join the Deep Learning with PyTorch course today.
Start Your AI Journey Today!
Track
Course
Course
Tutorial
Kurtis Pykes
Tutorial
Bex Tuychiev
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita



