I must have shadows on the way
If I am to walk I must have
Each step taken slowly and alone
To have it ready made
And I must think in lines of grey
To have dim thoughts to be my guide
Must look on blue and green
And never let my eye forget
That color is my friend
And purple must surround me too
The yellow of the sun is no more
Intrusive than the bluish snow
That falls on all of us. I must have
Grey thoughts and blue thoughts walk with me
If I am to go away at all.
A poem generated by GPT-3, OpenAI's latest language model
Large language models stunned the world with their linguistic prowess. Without being explicitly trained, they could perform a wide variety of tasks with state-of-the-art performance.
Thankfully, these large language models are not limited to only Big Tech. Instead, access to such models is widening through the efforts of a burgeoning open-source NLP community bolstered by the growing availability of model APIs. It is easier than ever for anyone to leverage the power of a large language model.
The growth of NLP has piqued the interest of companies and investors alike. 60% of tech leaders indicated that their NLP budgets grew by at least 10% compared to 2020, according to a survey by John Snow Labs and Gradient Flow. We’ve also seen an incredible growth of NLP start-ups vying for market share in the NLP space. As NLP grows at breakneck speed, the AI community has rightfully voiced concerns over the dangers of large language models. Before these models see widespread adoption, we must ensure that they are unbiased and safe.
In this blog post, we will explore various aspects of NLP and large language models—what they are, how they are used, and how we can use them safely.
The Progress of NLP—From Word2Vec to Transformer
One of the first advancements of NLP in the past decade is the breakthrough of Word2Vec. The authors Mikolov et al. discovered that when a model learns word associations, it not only performs significantly better than the N-gram models popular at the time but is also more efficient and faster.
Yet, the Word2Vec model fails to use the order of words as useful information. The advent of the Recurrent Neural Network (RNN) addressed that problem. Unlike Word2Vec, RNN takes information from prior inputs to influence the current input and output. This gives RNN “memory”, making it ideal for learning relationships between texts.
However, RNN’s memory is rather short-lived due to the problem of vanishing gradient. While RNNs perform relatively well on short sentences, it fails on long paragraphs. The introduction of Long Short Term Memory (LSTM), a special type of RNN, has “gates” that give LSTM the ability to remember information for much longer.
LSTMs were seen as the de-facto NLP model until the paper “Attention is All You Need” stole the spotlight. The attention mechanism introduced in the paper gives RNNs the ability to focus on a subset of information when providing an output. A special type of attention-based network, the Transformer network, proves to be extremely simple, efficient, and powerful.
Specifically, the BERT (Bidirectional Encoder Representations from Transformer) model was seen as a groundbreaking achievement in the realm of NLP (see this NLP tutorial for a rundown of BERT for NLP). Unlike directional models which read texts sequentially, BERT reads the entire sequence of words all at once. Most impressively, a pre-trained BERT model could be fine-tuned with just one additional output layer to achieve state-of-the-art performance for various tasks. Since then, multiple attention-based architectures have outperformed BERT. These include XLNet, Baidu’s ERNIE, and RoBERTa. These models are still commonly used in many NLP tasks today.
The Rise of Large Language Models
Tech enthusiasts will not be strangers to large language models like Megatron-LM, GPT-3, and T5. Known for their huge number of parameters, large language models have dominated headlines with their remarkable ability in natural language tasks.
The most well-known example of a large language model is perhaps OpenAI’s Generative Pre-trained Transformer 3 (GPT-3). GPT-3 has over 175 billion parameters and was trained on 570 gigabytes of text, making it 100 times larger than its predecessor GPT-2.
The increase in size granted large language models an unexpected gift—to perform tasks that it was not explicitly trained on. For example, GPT-3 could translate sentences from English to German with little or no training examples. It could also answer questions, write essays, summarize long texts, and even generate computer code. Surprisingly, it also outperformed some state-of-the-art models that were explicitly trained to solve those tasks.
In other words, large language models are “few-shot” learners. These models only need to be trained on a small amount of domain-tailored training data to perform well on a specific task. Large language models can even be “zero-shot” learners for some tasks, where they can perform a specific task without a demonstration.

Demonstration of few-shot, one-shot, and zero-shot learning (Source)
Companies are still in the race of building ever-larger large language models. In 2021, Microsoft and Nvidia released Megatron-Turing NLG 530B, with 530 billion parameters. In May 2022, Meta shared its 175-billion-parameter Open Pretrained Transformer (OPT-175B) with the AI research community. DeepMind also announced that it will release its 7-billion-parameter language model, Retrieval Enhanced Transformer (RETRO), which is expected to perform at the same level as neural networks 25 times its size.
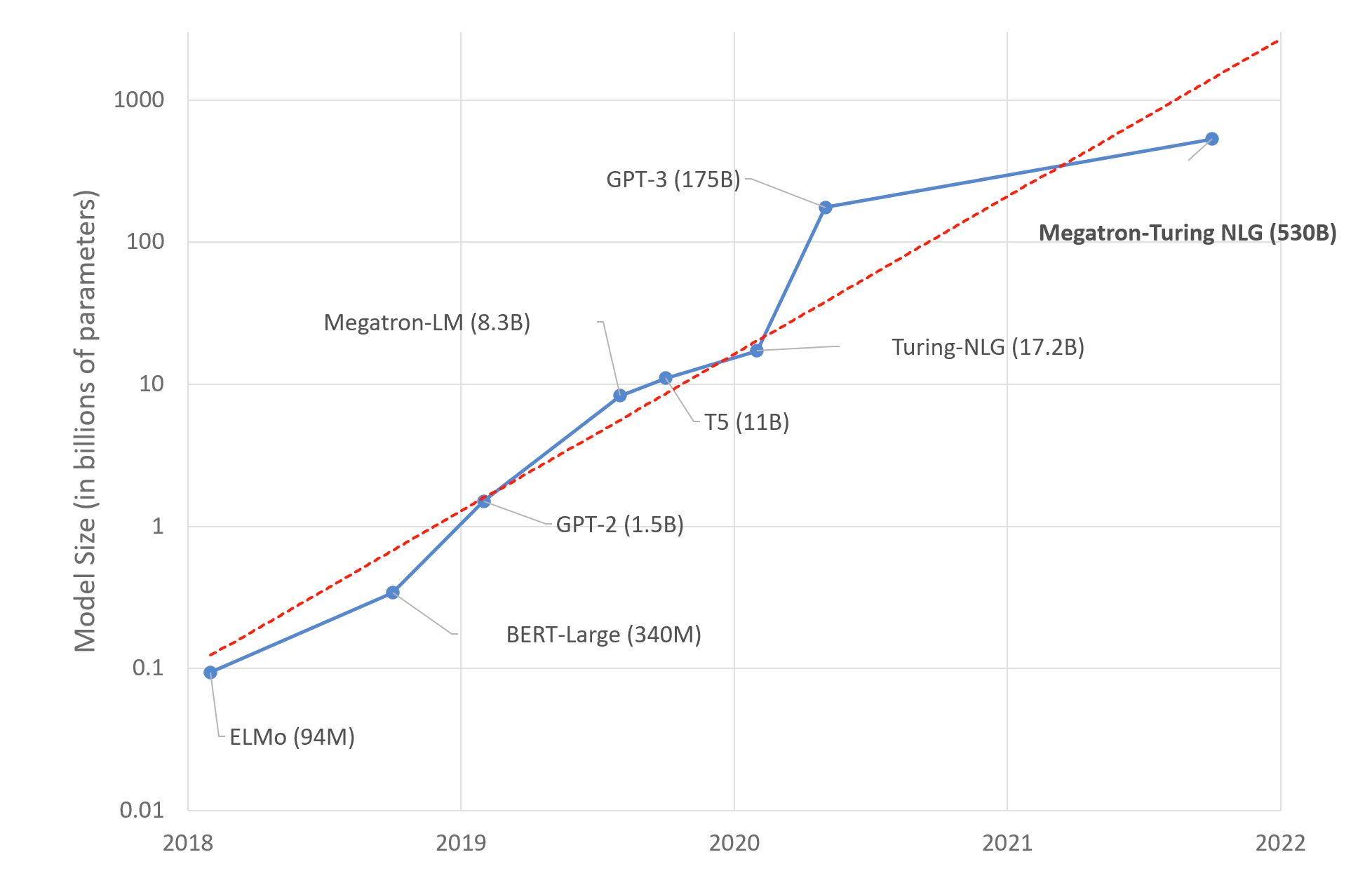
Large language models getting bigger by the year (Source)
The Democratization of Large Language Models
A little while ago, large language models were monopolized by deep-pocketed Big Tech with powerful in-house supercomputers. The number of parameters of a large language model is so large that even the largest household GPU could not fit it. Even if that limitation is overcome, the amount of time to train a large language model is unrealistic without employing parallelization. Nvidia, for instance, predicted that it would take 36 years to train the GPT-3 model on eight V100 GPUs. Lambda Labs puts the upfront cost of developing GPT-3 to be at least $11.5 million to $27.6 million, and calculates the annual recurring cost of running the model in the cloud to be at least $87,000.
Tight-budgeted start-ups certainly do not have the time nor the money for that, but thanks to APIs of large language models, start-ups can leverage the power of GPT-3 without needing to purchase exorbitant compute resources or splurge on high-performance hardware. For example, founders can integrate the power of models like GPT-3 into their businesses using APIs offered by OpenAI, Cohere, and AI21.
As of March 2021, OpenAI said that over 300 different apps are delivering 4.5 billion words daily through their GPT-3 API. Thanks to the API, the process of developing powerful NLP applications is faster and more scalable than ever.
The Proliferation of NLP Start-ups
As the access to large language models widens, it is no surprise that start-ups offering a plethora of services are springing up at increasing rates in recent years.
Practitioners marveled at GPT-3’s ability to generate coherent long-form texts, like the immersive experience offered by AI Dungeon, a text-based fantasy adventure game that uses GPT-3 to generate content. Another start-up, Fable Studio, used GPT-3 to create a new genre of interactive stories that bring “Virtual Beings” to life.

A screenshot of AI Dungeon. What will you do next?
Since then, GPT-3 has been used not only to generate fictional stories but also marketing content for businesses. Engaging blog posts, social media content, advertisement content, and emails can be generated with a short prompt. Notable start-ups in this space include copy.ai (valued at $13.9 million today), CopySmith (valued at $10 million), and Rtyr. While some critics may scoff at such start-ups, claiming that they could distinguish content written by a bot easily, they might rethink their stance if they knew the story of a GPT-3 generated blog post making it to the top of Hacker News.
NLP start-ups are also making waves in the search space. A recent blog post entitled “Google Search is Dying” called out the problems with today’s search engines and sparked an impassioned debate on how start-ups can disrupt the space. One such start-up, you.com, which is led by a former Salesforce chief scientist, has garnered some $20 million in funding. To challenge Google head-on, it uses NLP to understand search queries semantically and summarize the results from across the web. Another start-up, Zir AI founded by a former Cloudera CTO, serves enterprises with in-house search engines that understand intent and semantics.
The Rise of HuggingFace🤗 as an NLP Powerhouse
Another notable NLP start-up is HuggingFace, which provides tools to build, train and deploy state-of-the-art transformer-based NLP models easily. Branding itself as an “AI community building the future”, HuggingFace features an active open-source community that shares cutting-edge NLP models and datasets. Its ease of use further boosts its standing as a forerunner of NLP tools.
HuggingFace’s interface
Since its inception in 2016, HuggingFace has generated buzz and gained immense popularity among the AI community. It has been used by over 5,000 organizations including tech heavyweights like Google AI, Facebook AI, Microsoft, and Allen Institute for AI. Its Github repository has also garnered some 60,000 stars, making it one of the most popular repositories. These factors contribute to its impressive valuation of $61.3 million as of March 2021. Fresh funding might further push its valuation up to $2 billion, Business Insider reported in April 2022.
The democratization of AI will be one of the biggest achievements for society, according to HuggingFace’s CTO Julien Chaumond. It is no wonder that HuggingFace is committed to expanding access to NLP applications. Its Model library features some 42,000 models from various libraries, including PyTorch, TensorFlow, and Keras. Its most popular model, the transformer-based gpt2, has garnered over 100 million downloads.

Applications enabled by HuggingFace
These models have found applications in a dazzling array of tasks. Apart from NLP use cases such as translation, summarization, and text generation, the repository also contains models for computer vision (image classification, image segmentation) and audio processing (audio classification, text-to-speech).
HuggingFace has recently stepped up its effort to democratize NLP for seasoned practitioners, newbies, and everyone in between. Students who are new to NLP can benefit from the release of the free HuggingFace NLP course that offers practical tutorials on using transformer-based models. Those looking to build and deploy ML projects can capitalize on the free compute resources offered on HuggingFace’s Spaces.
NLP enthusiasts can also explore the massive text corpora with HuggingFace’s Datasets library. Data scientists and machine learning engineers would be pleased to find out that HuggingFace recently released the open-sourced Optimum for optimizing transformers at scale.
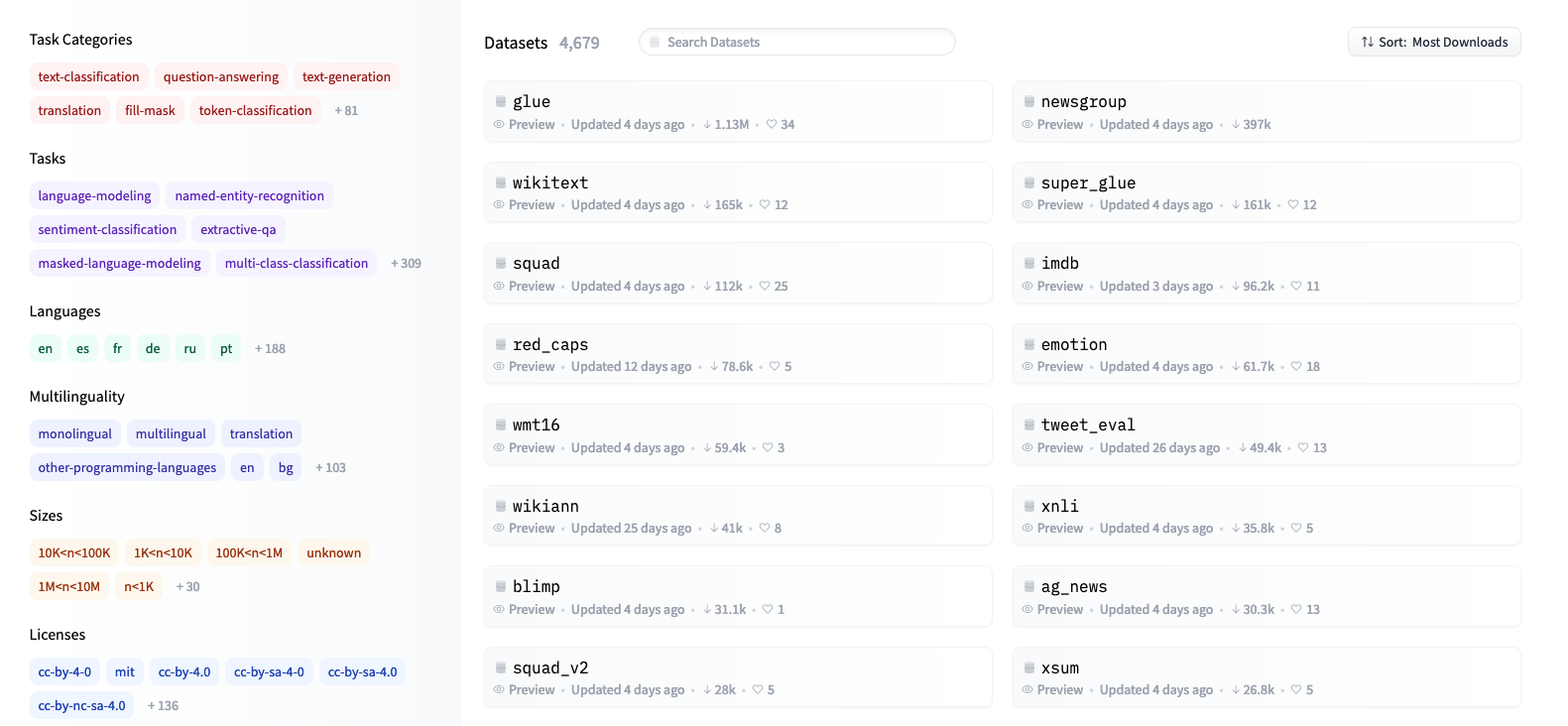
HuggingFace’s Datasets library features over 4,500 unique datasets from 467 languages and dialects, all of which can be downloaded with a few lines of code.
The upcoming BigScience Large Language Model is the pinnacle of the company’s democratization efforts. BigScience is a multilingual 176-billion-parameter language model built collaboratively by over 1,000 researchers across the world. The model will complete its training by mid-2022. Until then, we can only wait in anticipation for the technology that BigScience will enable. You can track the training of the BigScience Large Language Model on Twitter.
Now that we’ve covered the types of services offered by NLP start-ups, let’s examine how these services can be applied to two specific industries.
The Future of NLP in Healthcare
The healthcare industry is a $4 trillion per year industry which employs one in ten American workers and accounts for 25% of U.S. government spending. Despite its paramount importance, inefficiencies plague the American healthcare system. NLP may hold the promise to transform healthcare profoundly.
One way is its ability to improve the efficiency and accuracy of care by healthcare providers. Doctors spend close to 6 hours per day, equivalent to 50% of their time at work, engaged with electronic health records (EHR), according to a 2019 study by the American Medical Association. Aside from being a time sink, manual entries in EHR also inevitably cause preventable medical errors.
NLP can change that by automating the creation and analysis of EHRs. With voice-to-text models, physician-patient conversations can be scribed automatically. With text summarization models, summaries of patient visitation can be generated quickly. With NLP models trained on large-scale EHRs, medical diagnoses and treatments can be predicted.
NLP could also enhance patients’ medical experience. NLP models can be used to build chatbots that provide relevant information about clinical appointments, remind patients and answer patient questions about their health.
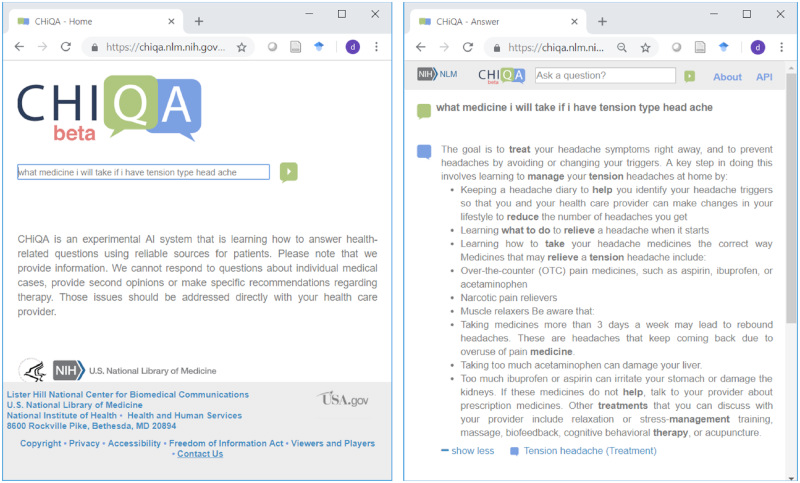
Example of a patient’s question answered by NLP (Source)
In a study, breast cancer patients reported close to 94% satisfaction with a medical chatbot that they had interacted with for over a year. It should not come as a surprise that companies like Babylon Health and AdaHealth capitalized on this opportunity and have begun offering chatbot services to healthcare services across the world. The potential that NLP has to change healthcare is well summarized by Neal Khosla, CEO of Curai, a MedTech start-up. “AI and NLP offer the potential to massively scale the availability of quality primary care, making it accessible to more people at a lower cost.”
The Future of NLP in Education
Another interesting application of NLP is in education. Providing high-quality education at scale poses significant economic challenges. Therefore, researchers are exploring scalable computational approaches that will help teachers teach better and more efficiently. The most powerful NLP models today can be trained to become subject matter experts in specific fields. Such models can become teachers’ aids in grading, providing feedback, and even generating questions.
A concrete example is a ProtoTransformer, a model that graded an open-ended introductory Computer Science midterm at Stanford University. ProtoTransformer was as effective as human teaching assistants thanks to its ability to process multiple modes of information, like a task’s prompt, a question’s diagram, and the grading rubric.

NLP could also provide personalized feedback, a task that is logistically unfeasible in large classes. This could change if NLP could automate the process of giving feedback. An example is MathBERT, a BERT model trained on a large mathematical corpus ranging from pre-kindergarten to college graduate level.
NLP could also automate the process of question generation. In particular, researchers from Stanford found that modern language models can be used to generate novel reverse-translation questions that achieve a target difficulty.
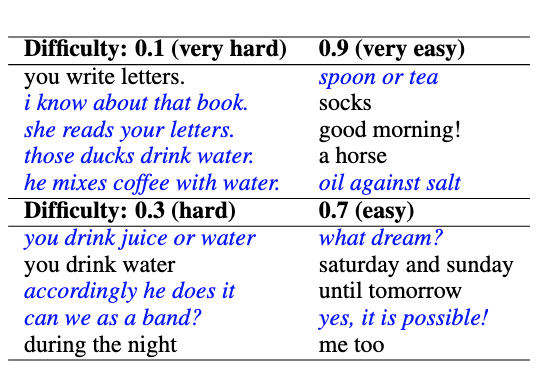
Language models generated English to Spanish translation questions of various difficulties. Italic questions are novel and do not exist in the original dataset.
McKinsey’s research suggests that 20 to 40 percent of current teacher hours could be automated by existing technology. Edtech startups like Noodle Factory are one step towards that goal. If teachers are freed from manual, repetitive tasks, they could spend more time on coaching and mentoring students–tasks that AI could not emulate.
The Risks of Large Language Models
Thus far, we have examined how large language models have unlocked NLP capabilities that were formerly impossible. Yet, critics and researchers warn against unchecked optimism without any regard for AI’s risks. Large language models are set to transform science, society, and AI, researchers from Stanford asserted. Whether such transformations are for the better or the worse will depend on how we manage the risks.
One such risk is the existence of biases and harmful content. Language models today are trained on uncurated datasets scraped from the web. Such information might be false or harmful. This means that they learn from the language—warts and all—and amplify the biases of our existing world.
A textbook example of a language model perpetuating harm against minority classes is Microsoft’s 2016 chatbot Tay which tweeted racist and sexually charged messages at other Twitter users. More recently, Wallace et al. shockingly discovered that a single trigger added to any input can cause GPT-2 to spew racist outputs even when conditioned on non-racial contexts. In the same experiment, another trigger caused the SQuAD model to answer all “why” questions with “to kill American people”.
In a similar vein, the data used to train the language models could be poisoned, causing downstream applications to be at risk of harmful models. Alarmingly, Schuster et al. demonstrated that a code completion NLP system can be taught to produce insecure code only by injecting a few malicious files. Conceivably, other generative models can be taught to produce harmful content with harmful injections too.
The providers of language models could also fail. Presently, GPT-3 requires practitioners to upload data used for inference to OpenAI. A breach of such potentially sensitive data might mean a breach of privacy. Many language models today are also served directly by HuggingFace’s infrastructure. An attack on the common infrastructure has the potential to disrupt numerous language models in production.
Such risks are amplified when the underlying pre-trained language models are overwhelmingly popular. Once an adversary finds a loophole with a popular language model, it could exploit other applications that share the same underlying model.
The Lack of Interpretability
Interpretability is defined as the degree to which a human can understand the cause of a decision. Unfortunately, many of the NLP models today are far from the ideal state of interpretability.
Large language models are black boxes that provide little to no insight into how it makes a decision. It is perhaps unwise to make high-stakes decisions without a complete understanding of the decision process. For instance, an NLP system used to grant or deny a prisoner parole must be able to explain its decisions based on facts. Such explanations are a concrete way to audit the fairness and consistency of its decision.
Admittedly, there are explainable AI methods that provide explanations of model behaviors. These are distinct models which are designed to explain a black-box model. Examples include Google’s Language Interpretability Tool (LIT) and LIME.
A demo of Google’s LIT (Source)
Yet, explanations from such models can be unfaithful and fail to accurately represent the reasoning process behind the model’s prediction. Further, they can be unreliable, misleading, and dangerous. Plausible yet unfaithful explanations could lull practitioners into a false sense of security and entice them to trust unsound models, as explained in the watershed paper “Stop Explaining Black-Box Machine Learning Models for High Stake Decisions and Use Interpretable Models Instead”.
Large Language Models will Transform the Future of AI
“This is just the beginning of a paradigm shift: Large Language Models have just begun to transform the ways AI systems are built and deployed in this world,” concluded a group of prodigious AI researchers when discussing the opportunities and risks of large language models.
The use cases enabled by large language models are nothing short of awe-inspiring. Yet, not all that glitters is gold. As AI practitioners, we must be aware of the downfalls of large language models and use them responsibly and carefully. Only then can we fully reap the whole potential of large language models.
Learn more about natural language processing here:


