Tracks
开发 AI 应用程序
21小时
n8n 已成为代理式 AI 领域广受欢迎且功能强大的框架。它使我们无需复杂编码即可构建自动化工作流。
在本文中,我将一步步讲解如何充分利用这一强大的平台来自动化两个不同的流程:
我们通过每周五免费通讯 The Median,梳理解读一周要闻,及时为读者带来最新 AI 动态。订阅即可每周用几分钟保持敏锐:
n8n 是一款开源自动化工具,帮助我们连接各类应用与服务以创建工作流,就像一条数字装配线。它允许用户通过可视化的节点来设计工作流,每个节点代表流程中的一个步骤。
借助 n8n,我们可以自动化任务、管理数据流,甚至集成 API,而无需深厚的编程技能。以下是本教程中我们将搭建的一条自动化示例:
不展开细节,下面是这条自动化的功能描述:
我们有两种方式使用 n8n:
两种方式都能零成本完成本教程。我们将以本地运行为例,如果您更喜欢网页版,步骤相同。
注:n8n 2.0 于 2025 年底发布,引入了草稿/发布工作流系统、自动保存(2026 年 1 月)、用于在不丢失画布上下文的情况下编辑节点的更新聚焦面板,以及用于隔离工作流执行、提升安全性的任务运行器(Task Runners)。
下文的工作流运行于 2.x——如果您仍在 1.x,建议在开始前升级。
n8n 官方仓库说明了如何在本地设置 n8n。最简方式如下:
从 官方网站 下载并安装 Node.js。
打开终端并运行命令 npx n8n。
就这么简单!运行该命令后,您应在终端中看到类似输出:
要打开界面,可直接按键盘上的 "o",或打开终端中显示的本地地址——我这里是 http://localhost:5678。
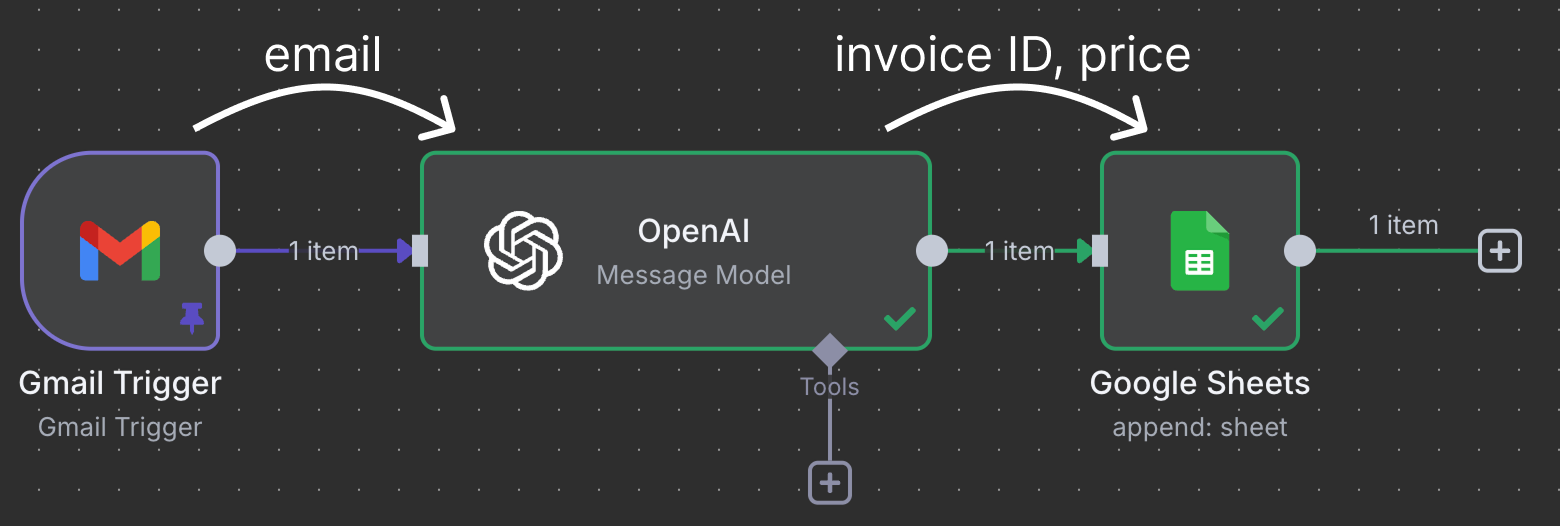
在构建首个自动化之前,先了解 n8n 的工作原理会更好。一个 n8n 工作流由一系列节点组成。它以一个触发器节点开始,该节点定义了执行工作流的条件。
节点通过连接来传递并处理数据。在此示例中,Gmail 触发器节点连接到 OpenAI 节点,这意味着邮件会交由 ChatGPT 处理。最后,ChatGPT 的输出被发送到 Google Sheet 节点,后者连接到我们 Google Drive 中的某个表格,并向电子表格写入一行新记录。
该工作流利用 ChatGPT 识别需支付的发票,并在表中新增一行,记录发票 ID 和金额。
n8n 的工作流可以复杂得多。 n8n 支持 400 多个官方集成(核心节点),外加 600+ 社区构建节点,以及通过 HTTP Request 节点进行自定义连接——因此在一篇教程中不可能全部覆盖。
因此,我将重点帮助您建立整体认知,以及具备自行探索所需的背景。若您常用的某个工具未被提及,很可能 n8n 已支持它,或者您可以手动集成。
本节中,我们学习如何构建上述工作流。
这是我用于管理房屋租赁发票的真实用例。我有一套房子,分租了几个房间,账单在所有租客之间平均分摊。每次收到发票,我都需要将总金额添加到与租客共享的电子表格中。
我设置了一个专用邮箱,所有与房屋账单相关的发票都会转发到该地址。这样我就知道该邮箱中的所有邮件都对应一张发票。我将邮件内容发送给 ChatGPT,识别发票 ID 和应付总额,然后把这些信息以新行的形式添加到共享表格。
要开始一个新工作流,我们需要点击 "Add first step..." 按钮。

由于这是第一个节点,它必须是触发器,因此会弹出一个面板让我们选择触发器节点。触发器节点用于定义执行工作流的条件。
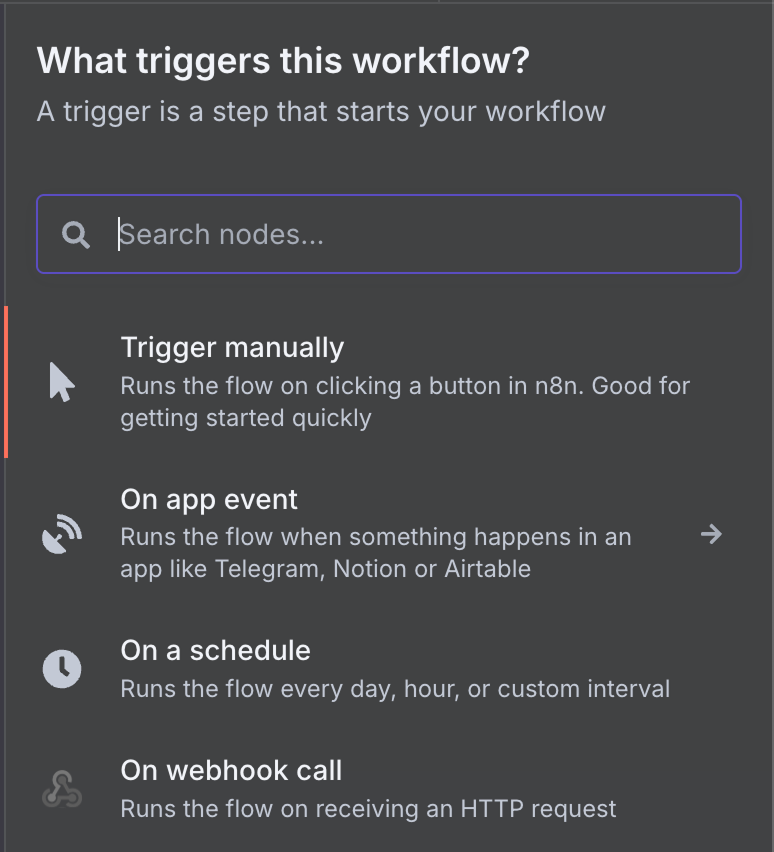
可选的触发器节点非常多。我们在搜索框中输入 "gmail" 并点击 Gmail 节点,选择 Gmail 触发器。
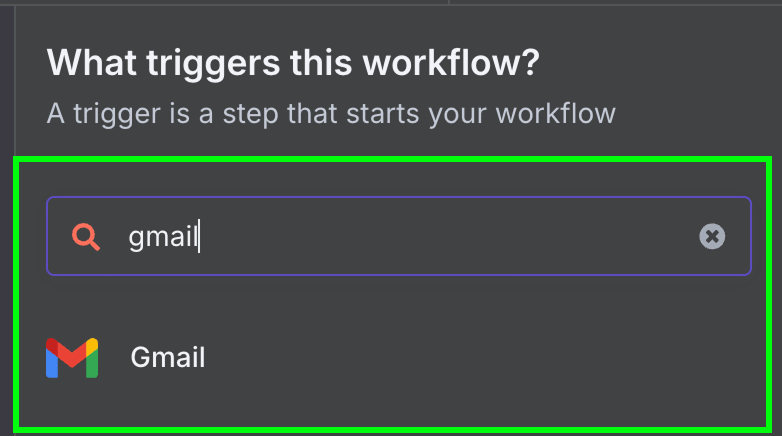
随后,选择 Gmail 唯一可用的触发器:“On message received”。

这将打开节点配置面板,我们需要在此配置 Gmail 凭据,以允许 n8n 工作流访问我们的 Gmail 帐号。点击 "New credential" 新建凭据,会出现如下窗口:
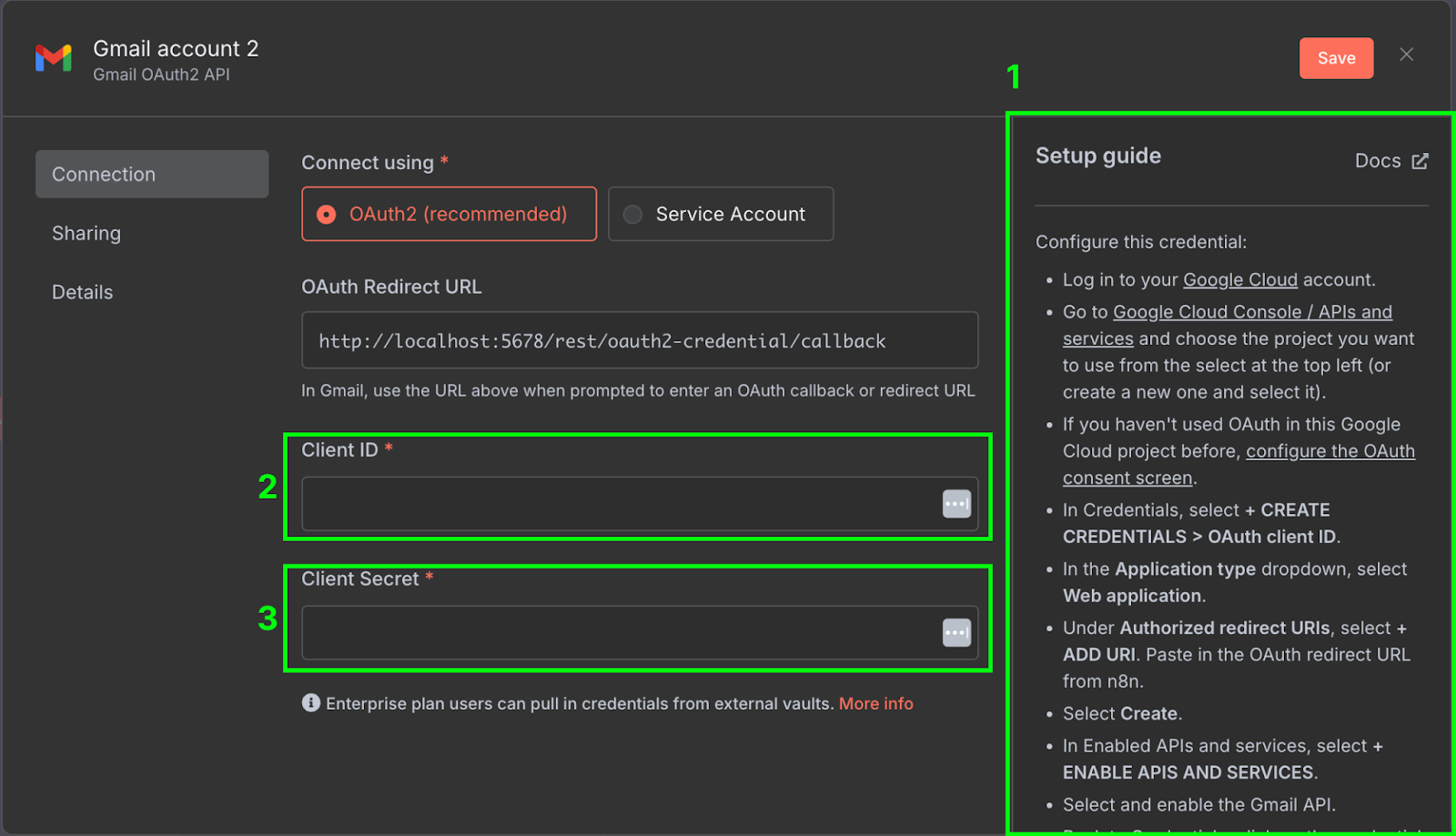
右侧(1)提供了在 Google Cloud 上配置凭据的步骤指南。n8n 提供的指南相当全面,这里不再赘述。请确保在 Google Cloud Console 中启用 Gmail API。
配置完成后,我们需要将 Google Cloud 上的客户端 ID(2)和客户端密钥(3)复制到 n8n 的凭据配置中。
为确保配置无误,可以点击 "Fetch Test Event" 来测试该节点。

测试后,我们应当在输出部分看到收件箱中最新邮件。邮件内容在 snippet 字段中。
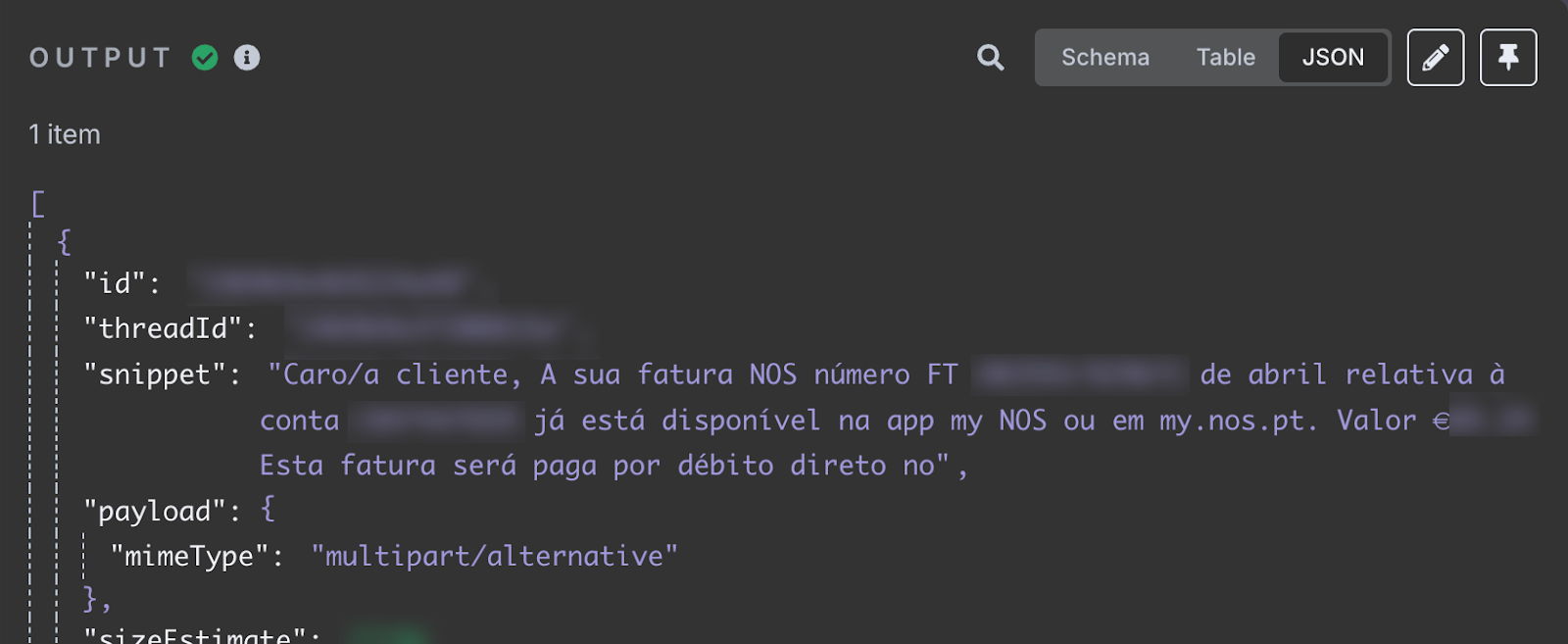
snippet 字段存储邮件内容。这里写道我的四月网络发票已可获取,提供了发票 ID 和应付总额。这正是我们要添加到表格的信息。
为了便于测试,建议点击右上角的图钉按钮固定输出:
这会将结果锁定到该触发器,意味着每次运行工作流都会使用同一输出,便于测试,不会受到新收邮件的影响。等工作流正确设置好后我们再取消固定。
此时,我们的工作流应只有一个触发器节点(左侧有小闪电标记即可识别为触发器节点)。

请注意,由于您邮箱中很可能没有发票邮件,后续 ChatGPT 的回答可能不符合预期。如果您想测试完全相同的工作流,可以给自己发送一封测试邮件,内容如下(或类似):
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.发送完成后,您需要取消固定结果,重新运行 Gmail 节点,并固定新的结果。
下一步是配置 OpenAI 节点。先点击 Gmail 触发器节点右侧的 "+" 按钮:

输入 "OpenAI" 并从列表中选择对应选项。
随后在 "Text Actions" 下选择 "Message a model" 节点。该节点用于向一个大语言模型发送消息。

与之前一样,我们需要创建访问 OpenAI 的凭据。注意,一旦创建好凭据,它可在任何工作流中复用,无需每次重新设置。
对于 OpenAI 凭据,我们只需一个 API key。若您还没有,可在 此处 创建。如果遇到问题,n8n 也提供了相关指南。
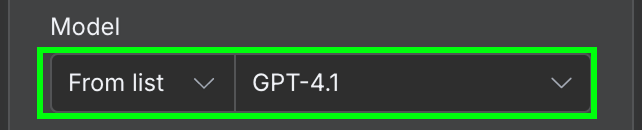
在配置方面,我们需要选择要使用的 AI 模型,以及发送给模型的消息。
模型方面,我们将使用 GPT-4.1。尽管 OpenAI 随后发布了 GPT-5 系列(5.4、5.4-mini、5.5)并在 ChatGPT 中下线了 4.1,但它仍可通过 API 使用,对这种简单抽取任务来说已绰绰有余。
在消息字段中,我们需要提供提示词。本例中,我们将邮件内容提供给模型,并让其识别发票 ID 和应付总额。以下是我使用的提示词:
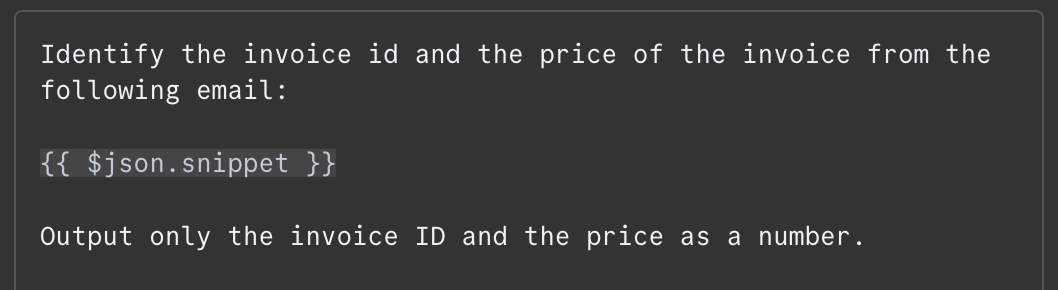
邮件内容通过 {{ $json.snippet }} 提供。在 n8n 中,提示词可以包含变量,这些变量来自上游节点的输出,此处即为邮件。可用字段列表在左侧。我们可以手动输入字段,或拖拽到提示词中。
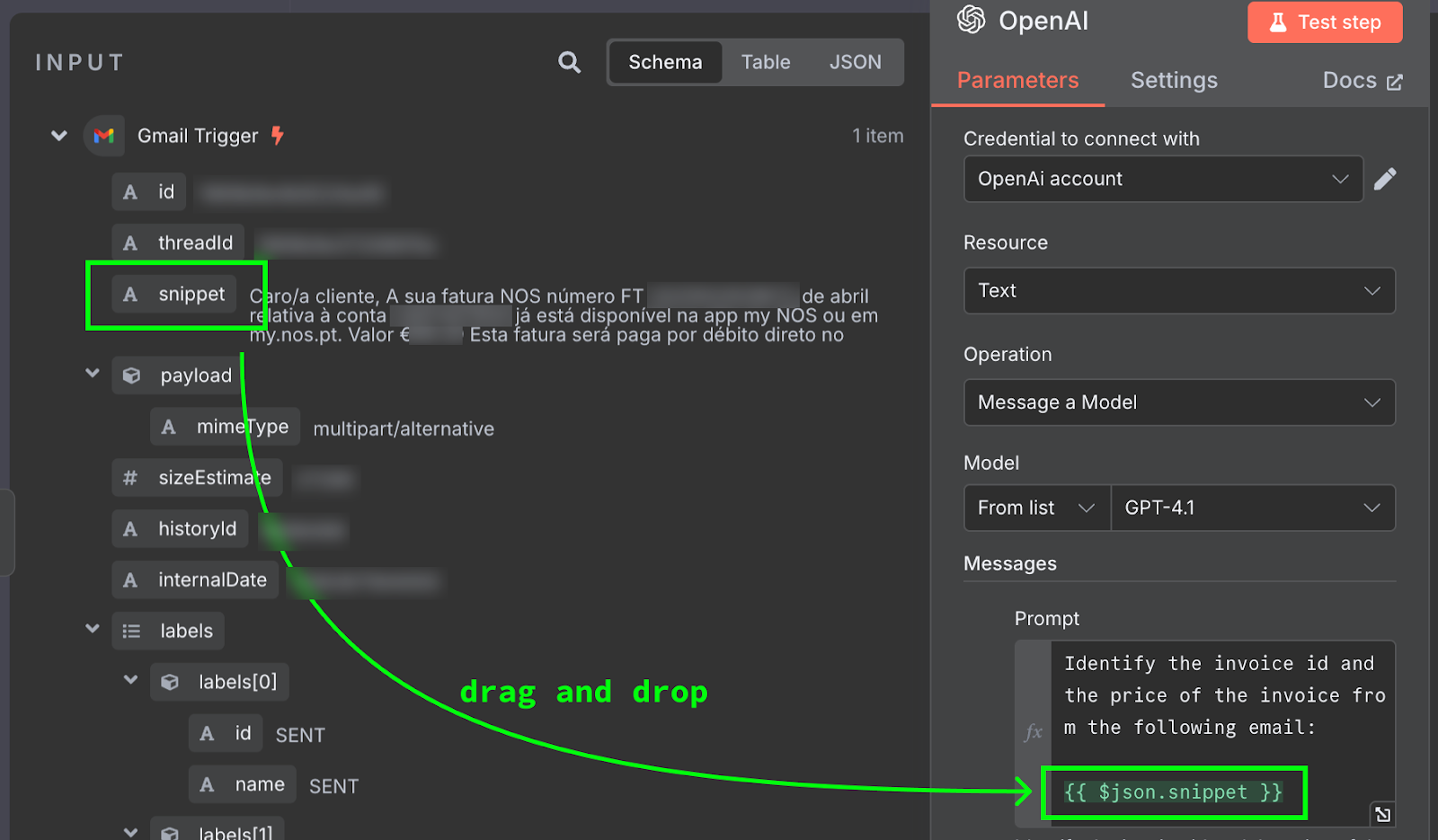
要测试,点击配置面板顶部的 "Test Step" 按钮。结果会显示在右侧:
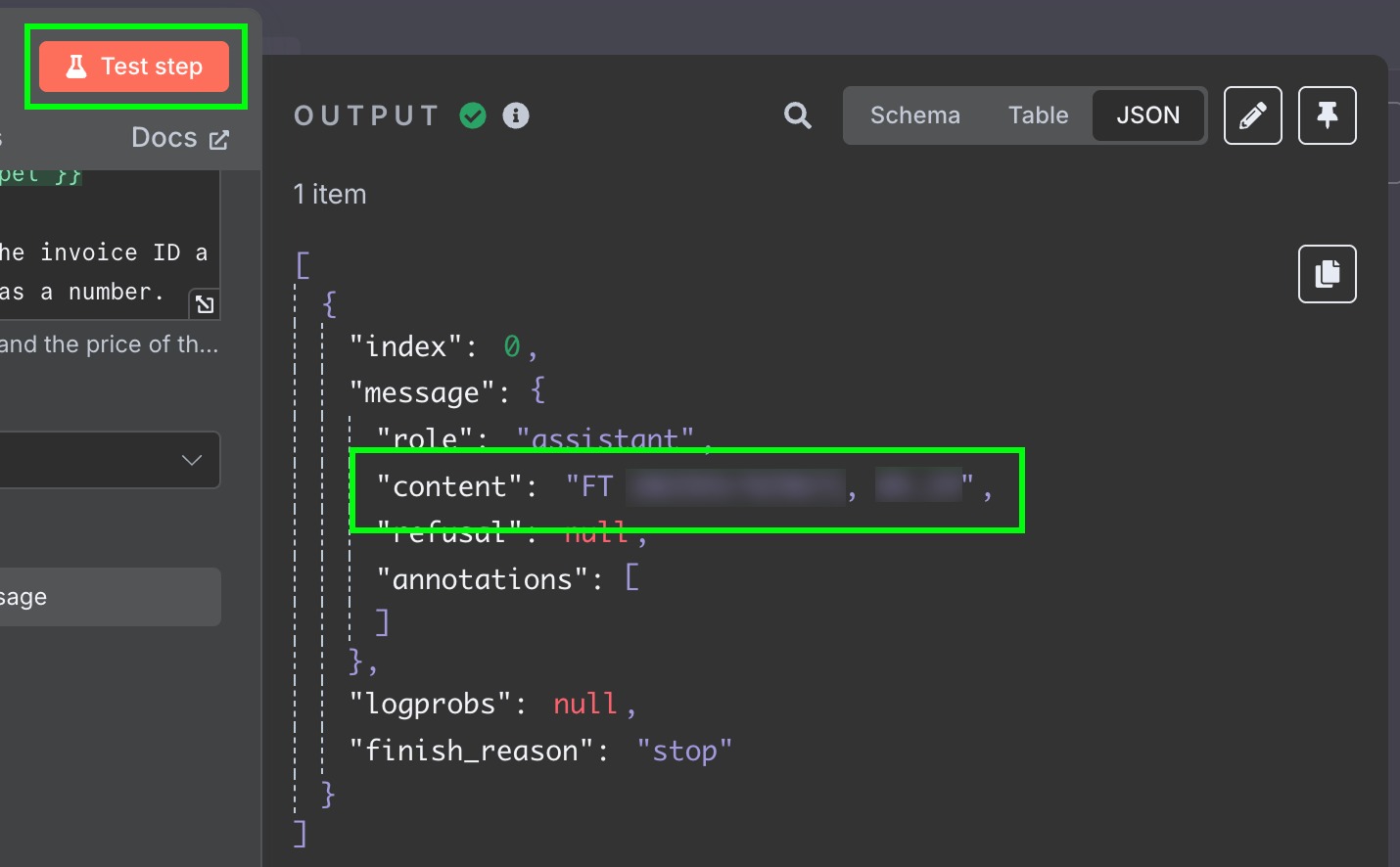
结果是模型返回的一段字符串。我们更希望将两个字段分别拿到,这样无需再处理消息。可以通过将 LLM 输出改为 JSON 来实现:

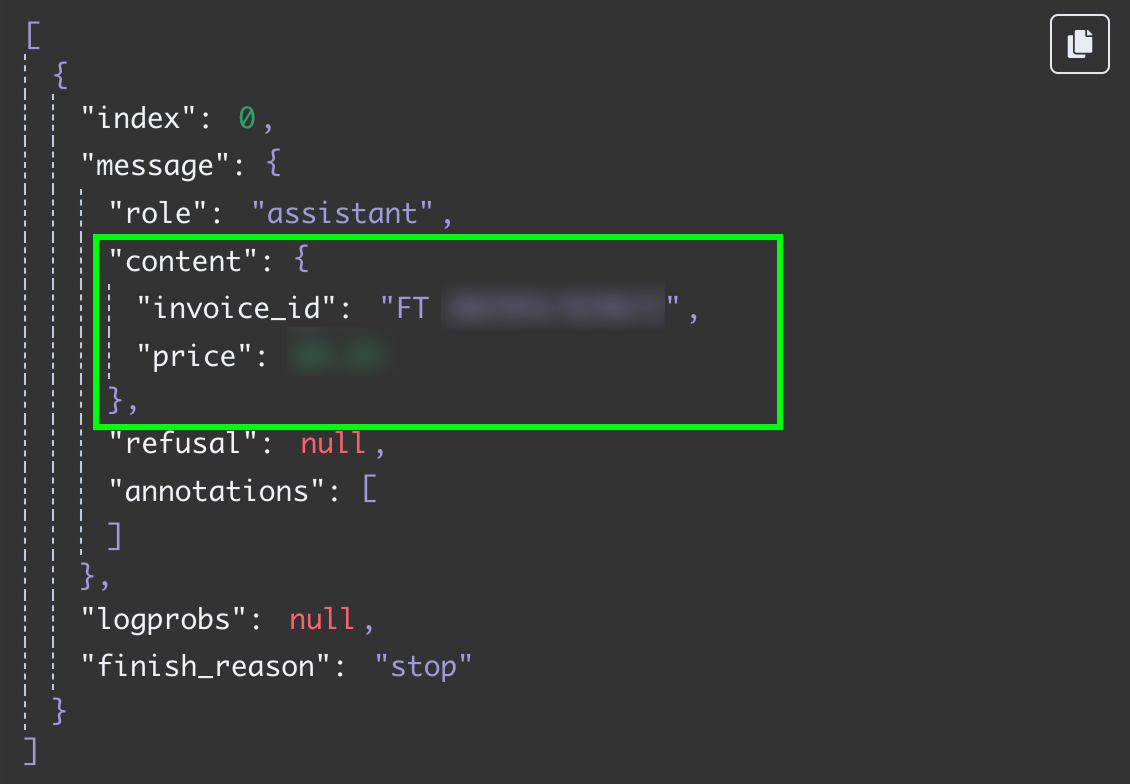
再次测试该步骤,我们即可获得包含两个字段的 JSON 数据:
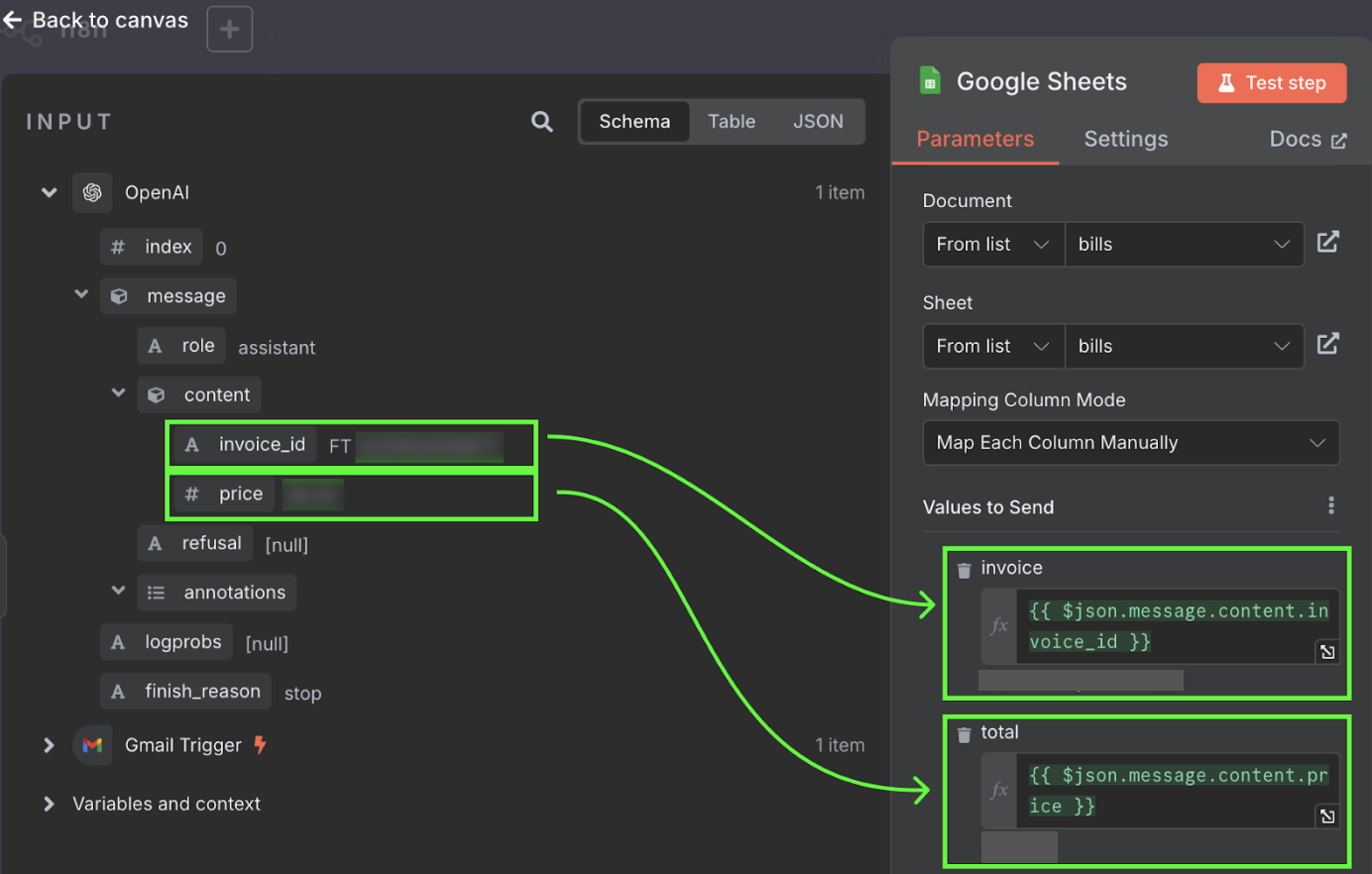
该工作流的最后一步,是将发票 ID 和价格追加到 Google 表格的新行。此时我们需要把 OpenAI 节点的输出连接至 Google Sheets。与之前一样,点击节点左侧的 "+" 按钮:
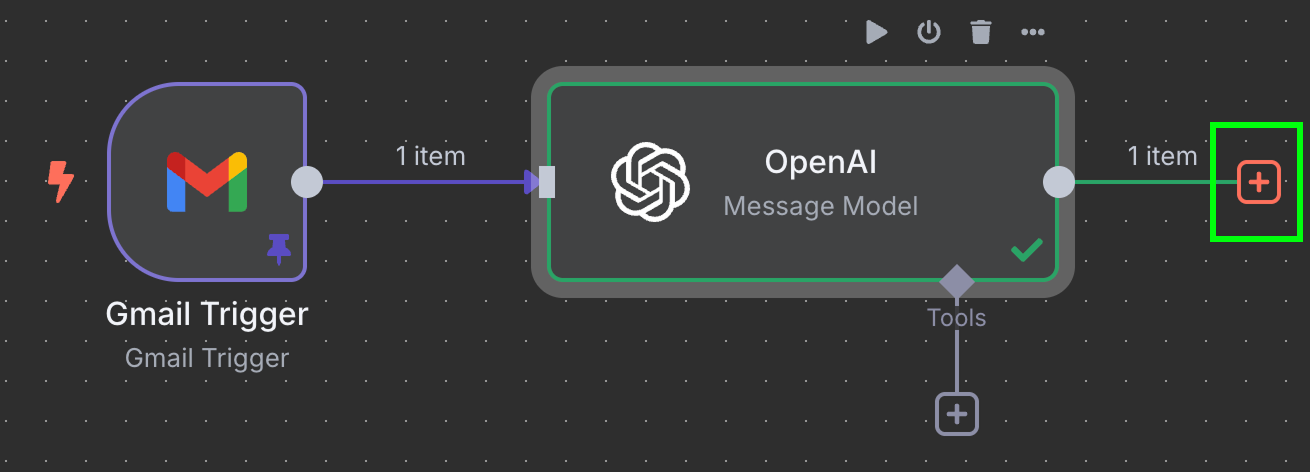
这里我们输入 Google Sheets 并选择 "Append row in sheet" 节点:
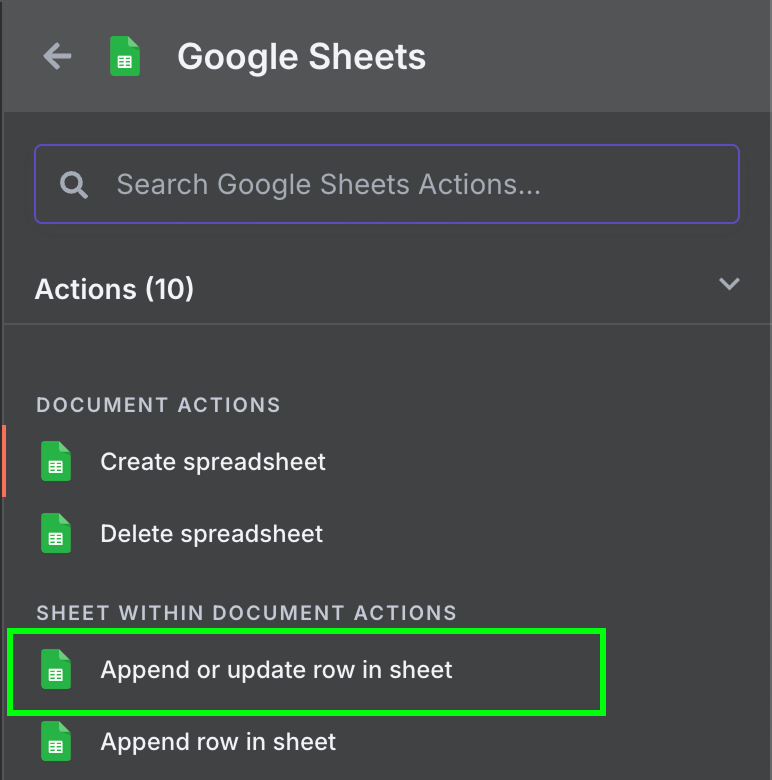
我们可以复用用于 Gmail 访问的同一凭据。但需要在 Google Cloud Console 中启用以下 API:
配置 Google Sheets 节点时,我们需要选择表格,并选择填充字段的取值。该表格应手动创建两列,一列存放发票 ID,另一列存放发票总额。
这些值来自 OpenAI 节点的输出。我们可以将其拖拽到相应列中。
完成!我们已经拥有一条能将发票自动处理到 Google 表格的工作流。可点击底部的 "Test workflow" 进行测试:
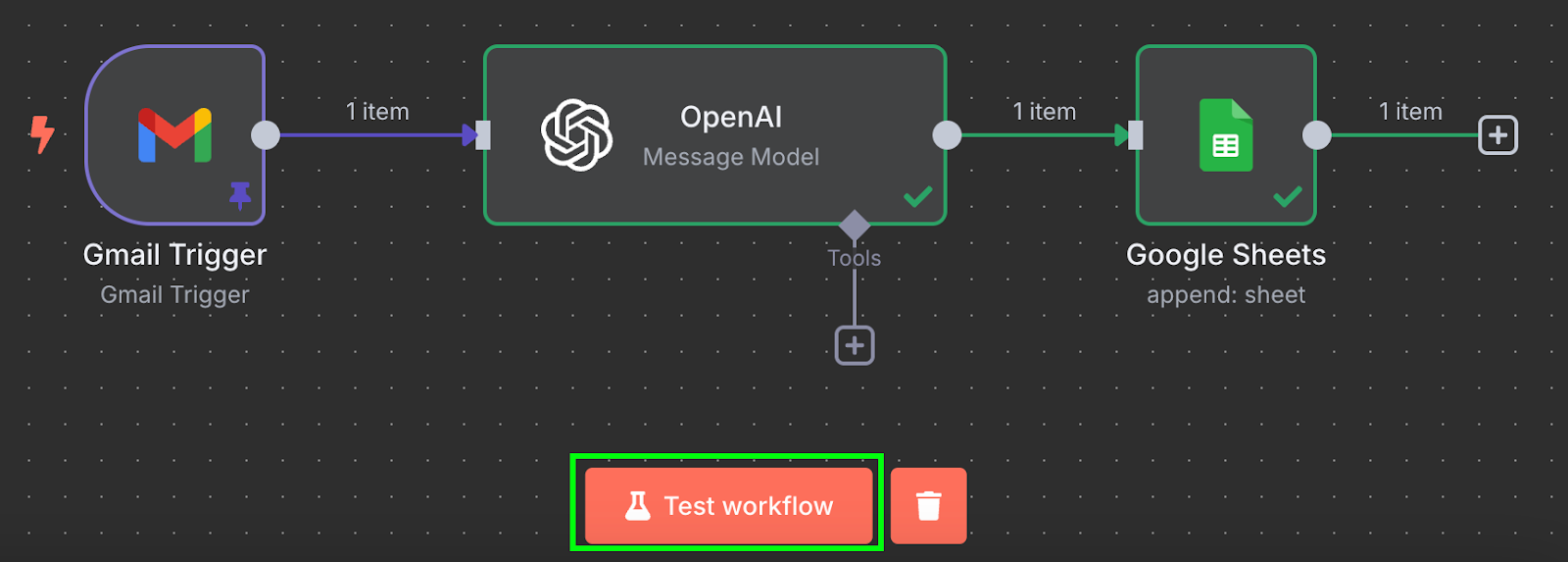
运行后,打开我们的 Google 表格,即可看到新增的一行数据:
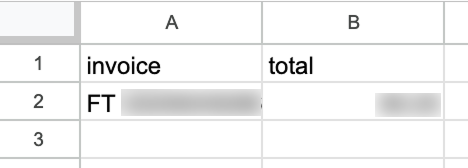
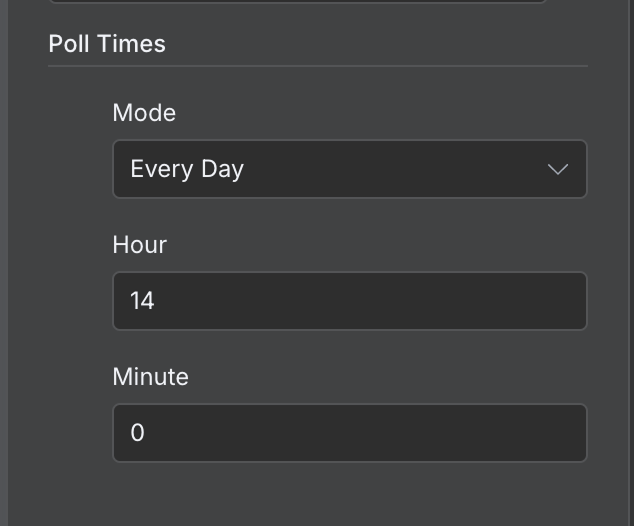
默认情况下,工作流每分钟运行一次。应根据具体工作流合理设置运行频率。本示例中,每分钟执行显然过于频繁,改为每天一次更为合适。
我们可以通过双击触发器节点,在 "Poll Times" 字段中设置不同的取值:
本节我们将构建一个更复杂的 RAG 代理工作流。 RAG 是检索增强生成(retrieval-augmented generation)的缩写,该技术结合了从数据库或文档中检索相关信息,以及使用语言模型基于检索结果生成回答。
当我们拥有特定知识库(如一份长文档)并希望构建一个能就其内容答疑的 AI 代理时,这种方法非常有用。
我喜欢玩桌游,但我和朋友经常为规则争论,最后不得不花时间查规则而不是玩游戏,挺让人沮丧。基于游戏规则构建一个 RAG 代理是个不错的解决方案,下次有疑问时,我们直接问代理即可。
为构建该代理,我们将创建两条工作流:
Pinecone 是一种以向量形式管理数据的数据库。像 Pinecone 这样的向量数据库非常适合我们的 RAG 代理,因为它能帮助代理快速检索并理解相关信息,从而更高效地给出准确回答。
由于这条工作流只需运行一次,我们可以使用手动触发器节点。该触发器用于手动运行工作流。
将手动触发器节点连接到 “Google Drive” 节点,从 Google Drive 下载数据。

使用以下配置:
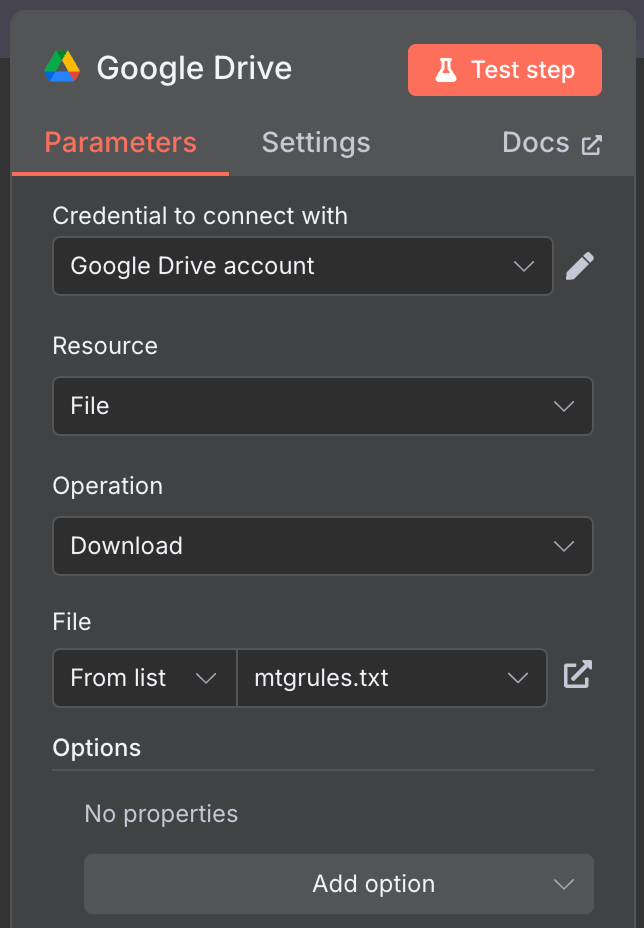
我使用的是公开可用的 mtgrules.txt 文件,其中包含集换式卡牌游戏《万智牌》的规则。您可以使用任意希望就其提问的文件;工作流相同。
要配置 Pinecone,登录 Pinecone,复制 API key,并点击 "Create index" 创建索引。我将索引命名为 rules,并选择 text-embedding-3-small 模型。

回到 n8n,将 Google Drive 节点的输出连接到 Pinecone Vector Store 节点,选择操作 "Add documents to vector store":
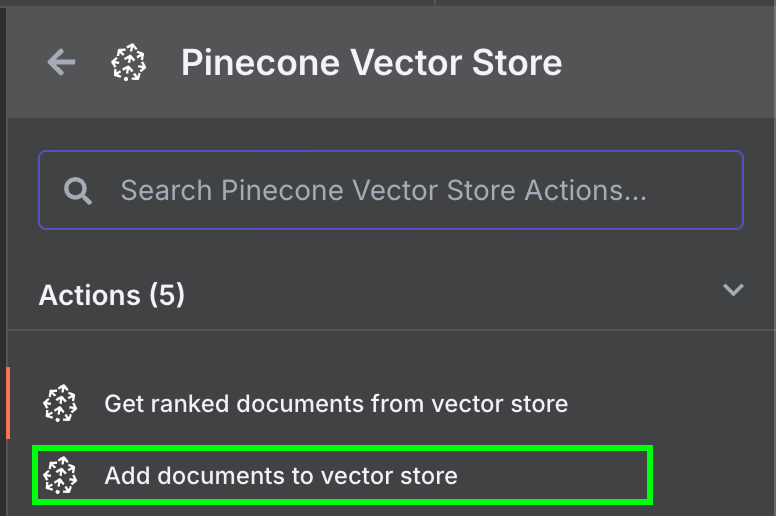
要配置该节点,我们需要新建凭据,粘贴 API key,并选择刚创建的 Pinecone 索引。在 Pinecone Vector Store 节点下方,我们会看到需要配置两项:嵌入模型与数据加载器。
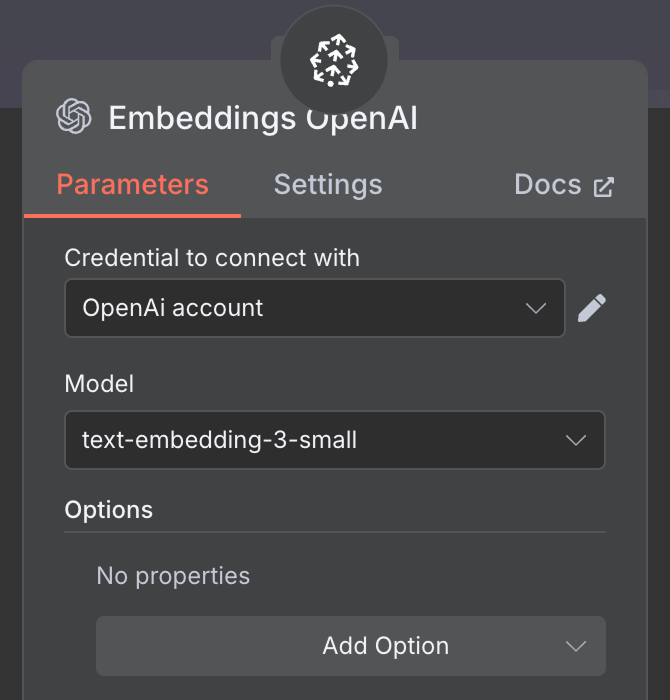
嵌入方面,创建一个 OpenAI Embedding 节点,模型为 text-embedding-3-small:
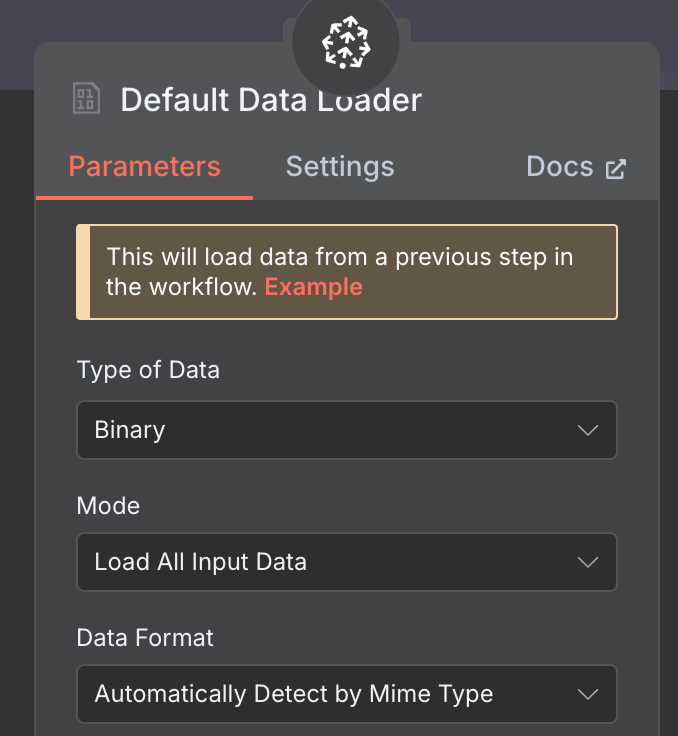
数据加载器方面,创建一个 Default Data Loader 节点,数据类型选择二进制(binary):
最后,数据加载器需要一个文本切分器(Text Splitter)节点,用于指定创建向量存储时如何切分文件数据。我们使用递归字符文本切分器(Recursive Character Text Splitter)节点,这是大多数应用的推荐选择。
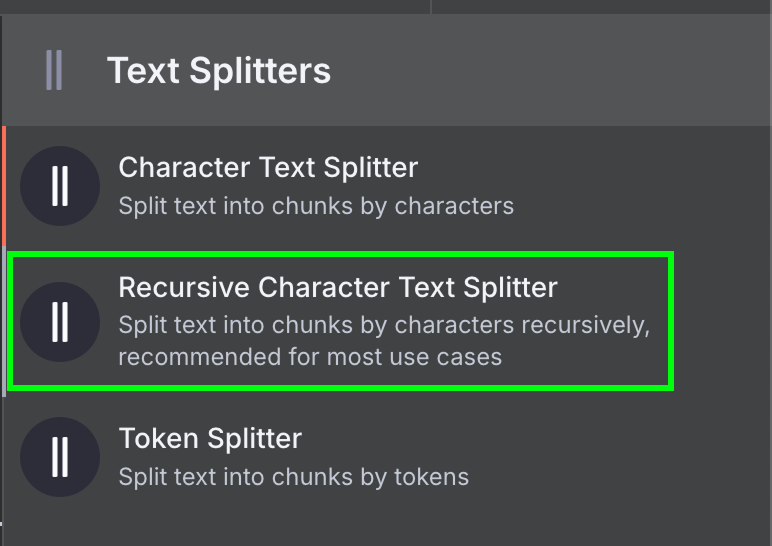
将其配置为块大小 1,000、块重叠 200:
选择块大小与重叠时,长文档宜使用更大的块以覆盖足够内容,重叠可适当减小,以在分段间保留上下文同时避免冗余。
最终工作流如下所示:
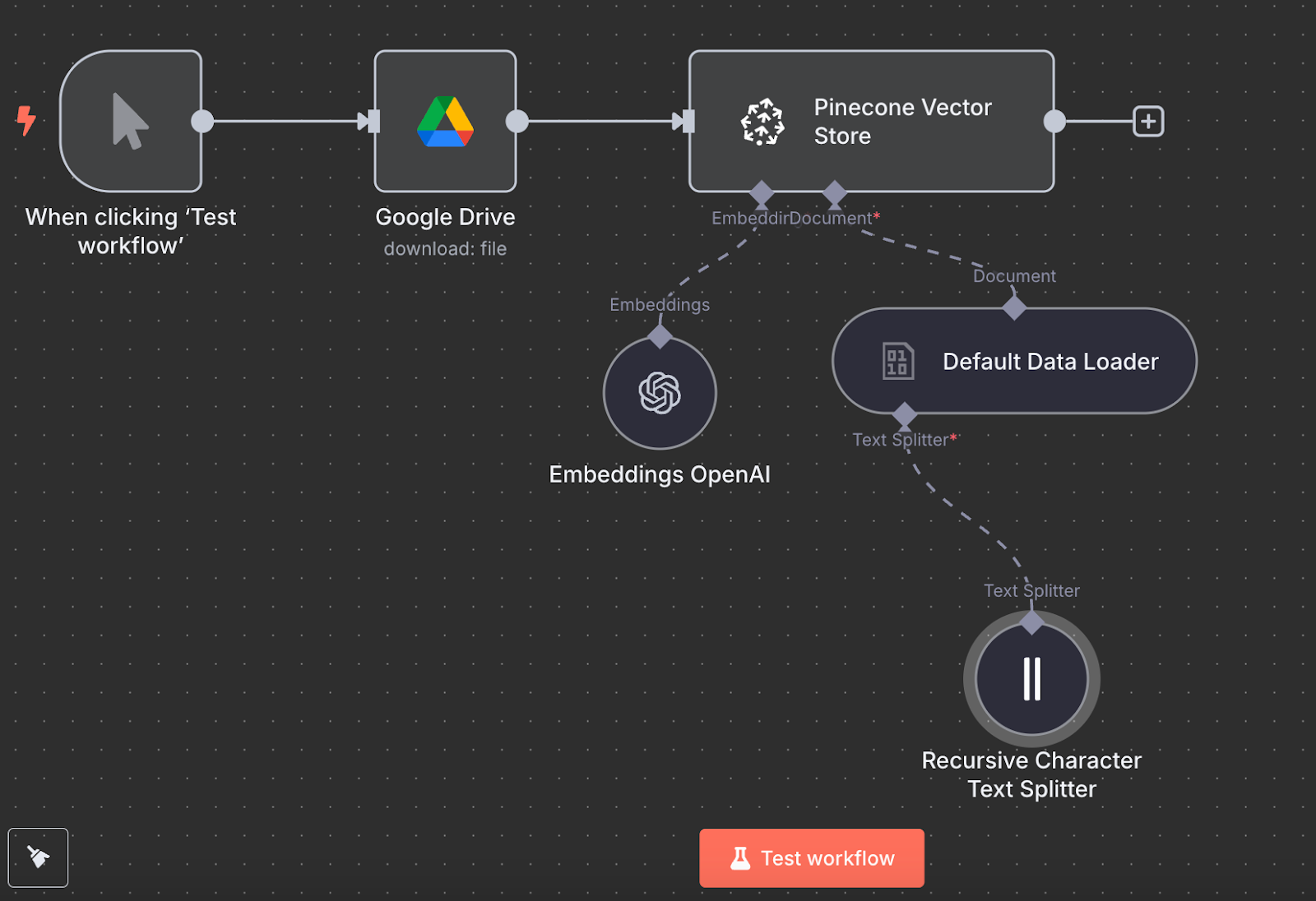
点击 “Test workflow” 即可运行,完成后我们可在 Pinecone 中验证数据是否已加载。
以下是 RAG 代理的最终结构:
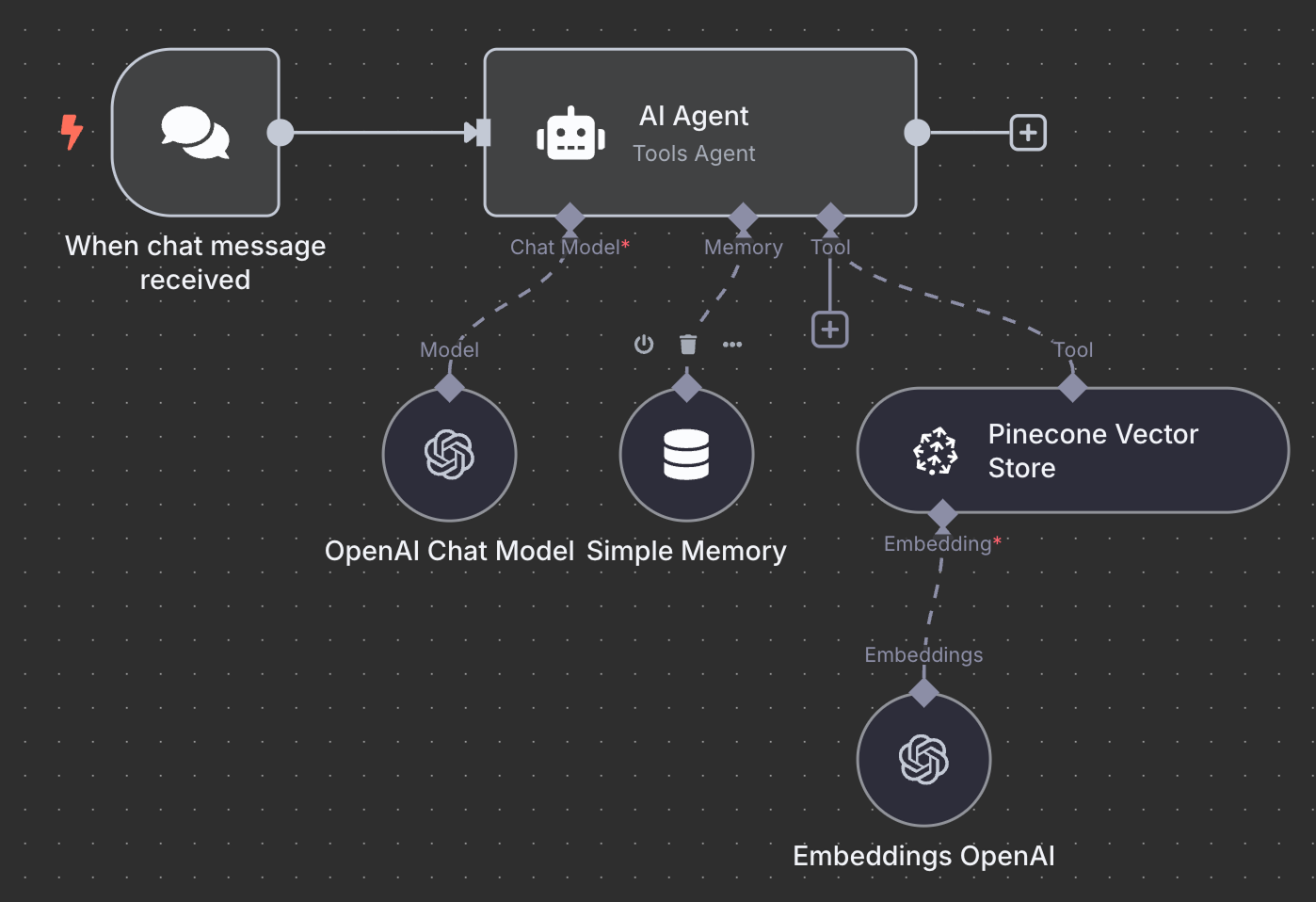
作为练习,建议您先尝试理解并在本地复现,再继续往下阅读。
我们从 "On chat message" 触发器节点开始。该节点用于创建聊天型工作流。
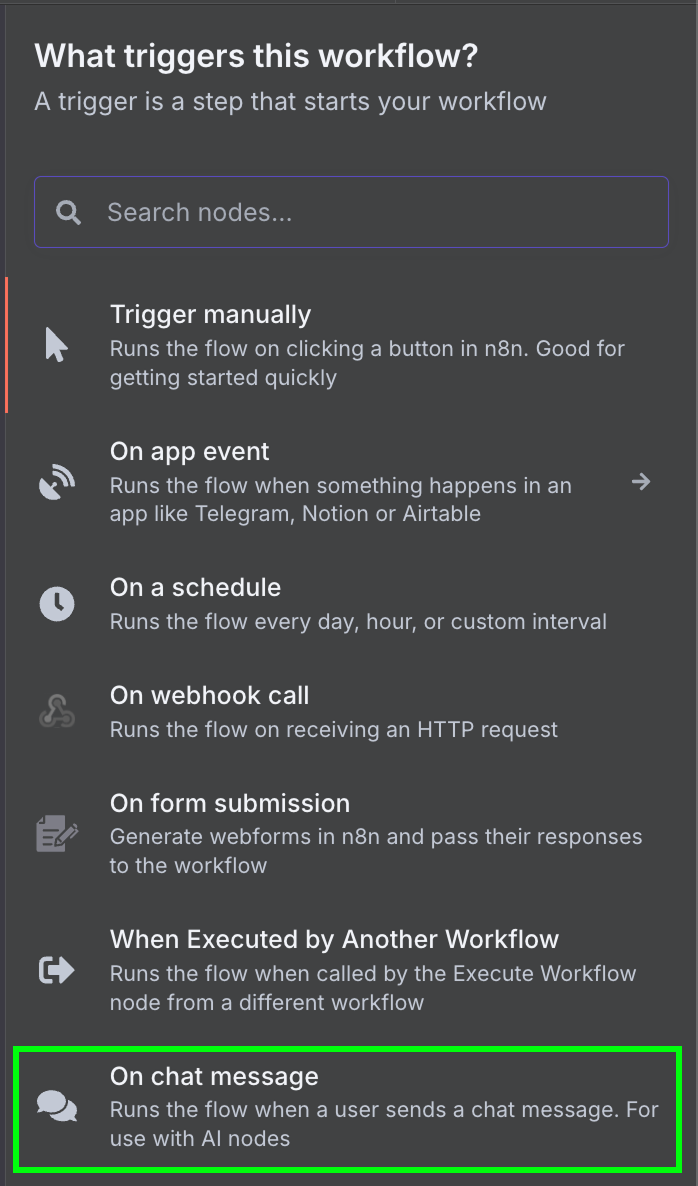
接着,我们将聊天触发器连接到一个 "AI Agent" 节点,使用默认选项。
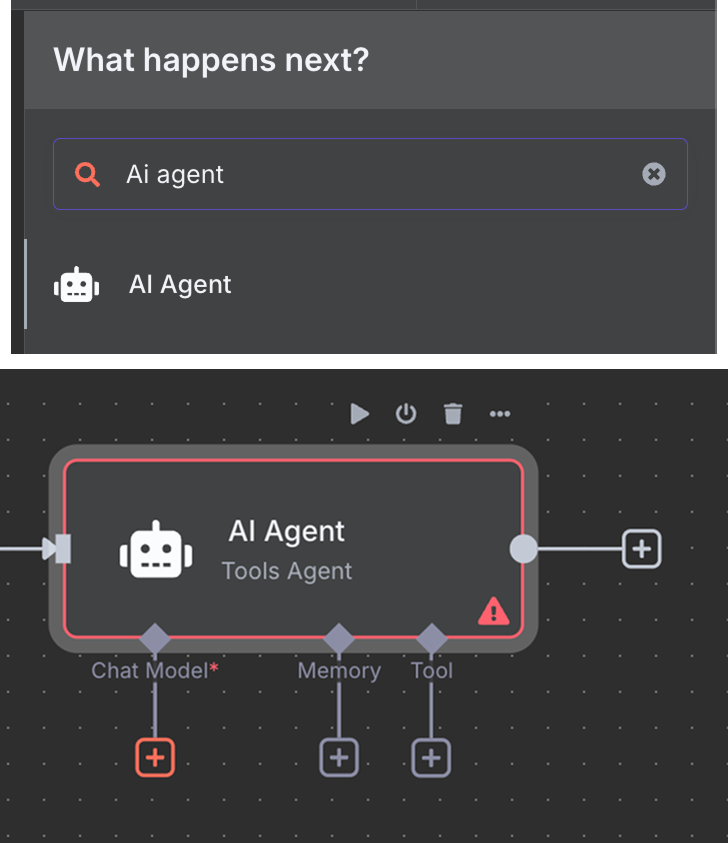
在 AI Agent 下方,我们可以配置三项内容:
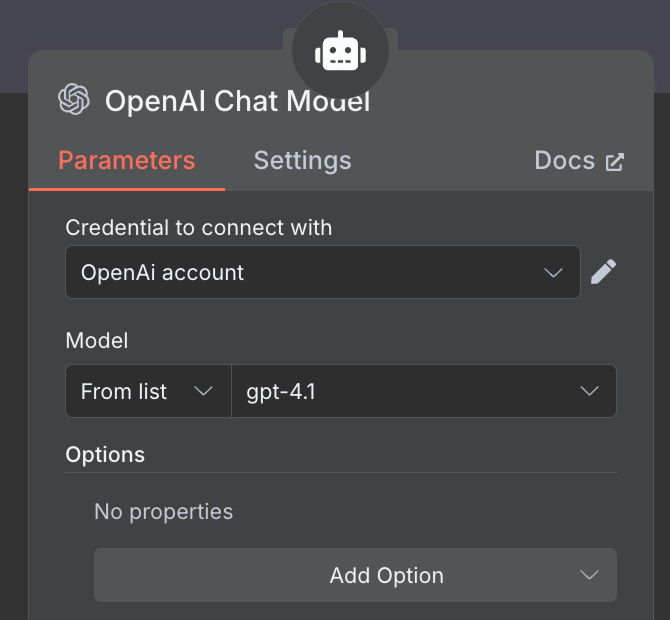
AI 模型方面,我们选择一个 "OpenAI Chat Model" 节点,并像之前一样使用 GPT-4.1。GPT-5 是 OpenAI 当前的模型家族,但 4.1 具备 100 万 token 的上下文窗口,很适合 RAG。
记忆方面,我们使用 "Simple Memory" 节点,设置上下文窗口长度为 5。这意味着代理在回答时会记住并考虑前 5 次交互。
最后,在工具中添加一个 "Pinecone Vector Store" 节点,配置如下:
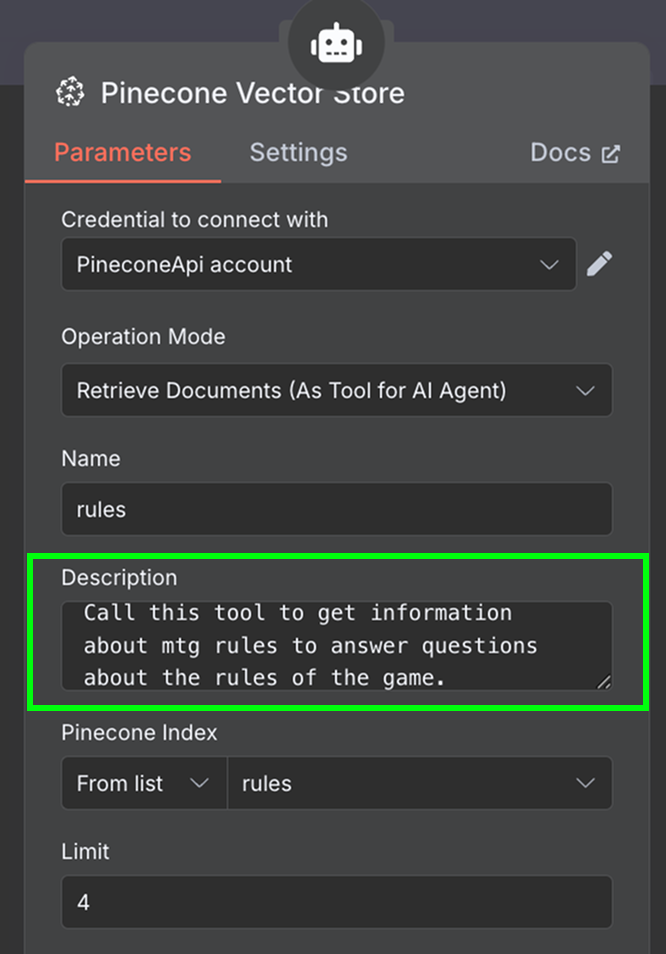
在描述字段中,明确工具应在何时使用非常重要。代理将据此判断是否调用该工具。
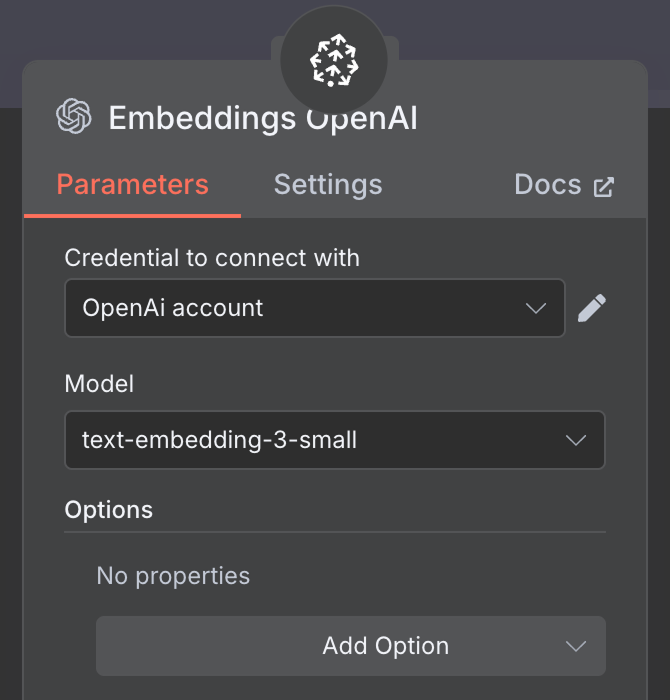
最后需要配置的是向量存储所用的嵌入。与之前一样,使用 OpenAI Embedding 节点,模型为 text-embedding-3-small:
工作流现已完成,我们可以与代理对话。示例如下:
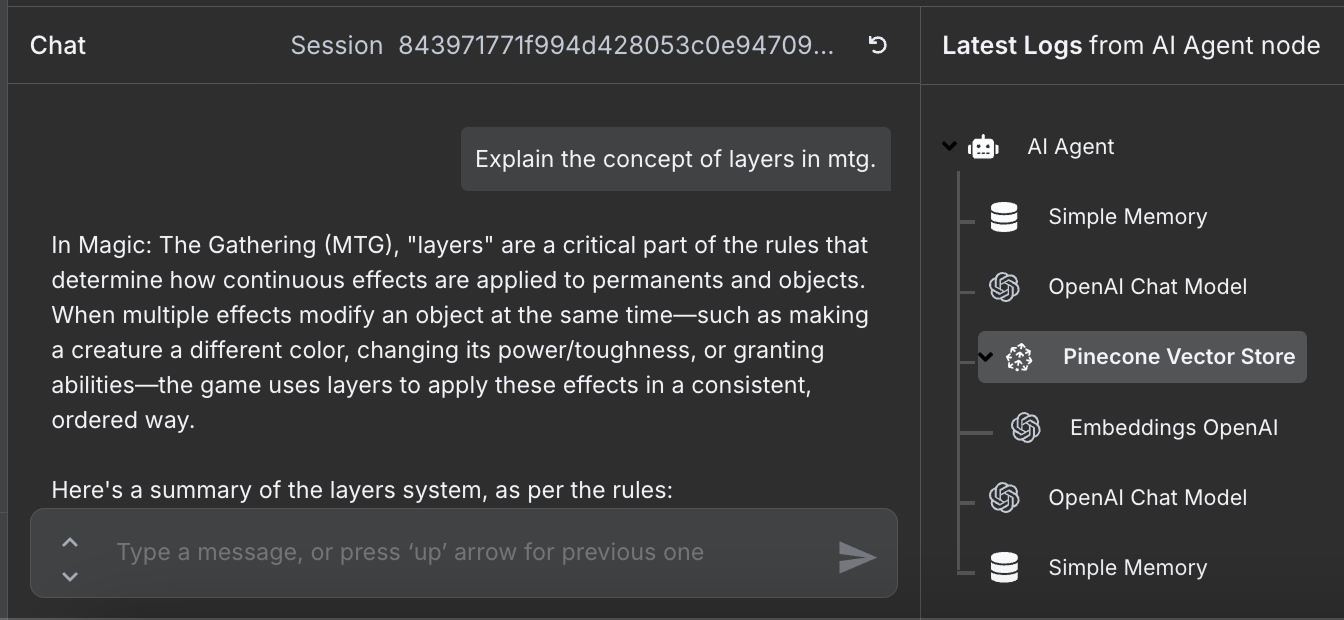
我们可以在右侧看到代理为回答问题所采取的步骤,尤其是它访问了 Pinecone 数据库以获取相关规则信息。
n8n 提供了一项能显著加速我们创建工作流的实用功能: n8n 模板库。
该库收录了由社区与 n8n 专家打造的预构建工作流。无论我们要自动化简单任务还是复杂流程,很可能已经有人为我们的需求构建了相应工作流。
将工作流导入我们的 n8n 环境后,我们并不总是需要从零开始。我们可以直接借鉴他人的巧妙方案。导入后,只需用我们的凭据进行配置,并根据实际需求做少量调整。
无论是邮件处理还是社媒管理,我们想要自动化的任务,很可能都能在库中找到模板。
n8n 提供了庞大的集成生态,使我们能够连接上千项服务与工具来创建 AI 代理。本教程只是浅尝辄止。通过探索如何使用 n8n 构建 AI 代理以自动化日常任务,我们才刚刚开始挖掘其潜力。
用这些课程学习 AI!
Tracks
Courses
Courses