
Tracks
Phát triển các ứng dụng trí tuệ nhân tạo
21 giờ
n8n đã trở thành một framework phổ biến và mạnh mẽ trong AI tác tử. Nó cho phép chúng ta xây dựng các quy trình tự động hóa mà không cần mã hóa phức tạp.
Trong bài viết này, tôi sẽ giải thích từng bước cách tận dụng tối đa nền tảng vững chắc này để tự động hóa hai quy trình khác nhau:
Chúng tôi luôn cập nhật cho độc giả những điều mới nhất trong AI thông qua The Median, bản tin miễn phí vào thứ Sáu hằng tuần tóm lược các câu chuyện quan trọng của tuần. Đăng ký để nắm bắt thông tin chỉ trong vài phút mỗi tuần:
n8n là một công cụ tự động hóa mã nguồn mở giúp chúng ta kết nối nhiều ứng dụng và dịch vụ để tạo quy trình làm việc, giống như một dây chuyền lắp ráp số. Nó cho phép người dùng thiết kế trực quan các quy trình này bằng các node, mỗi node đại diện cho một bước khác nhau trong quy trình.
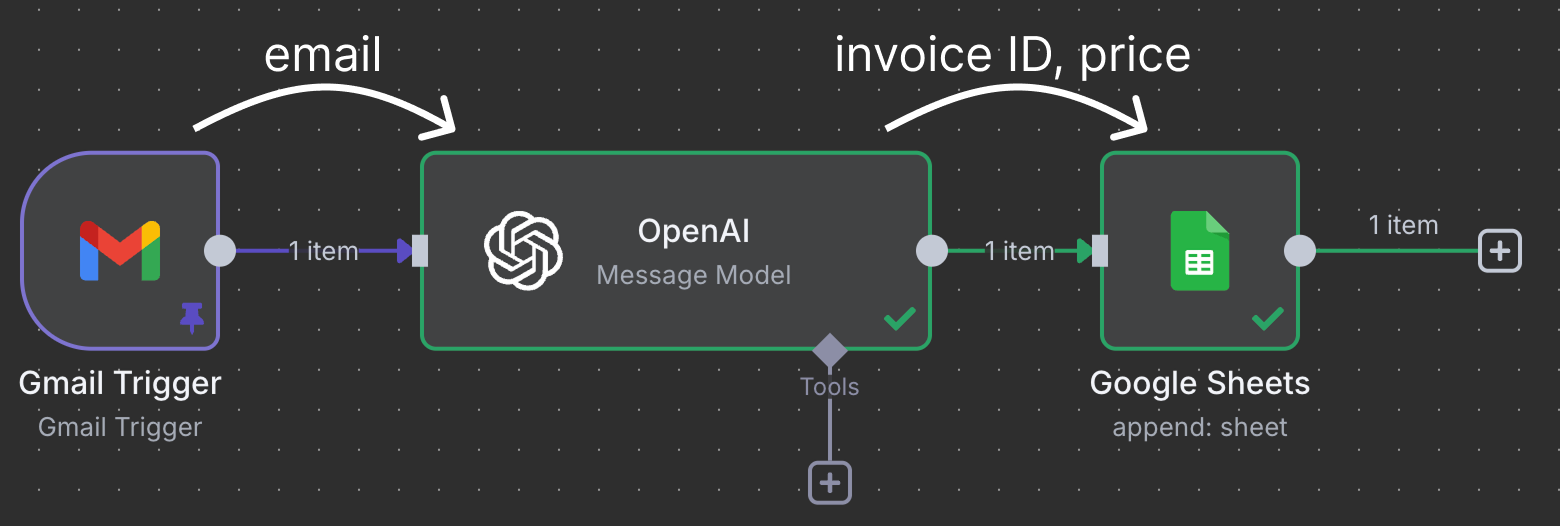
Với n8n, chúng ta có thể tự động hóa tác vụ, quản lý luồng dữ liệu, và thậm chí tích hợp API mà không cần kỹ năng lập trình chuyên sâu. Đây là một ví dụ về quy trình tự động hóa chúng ta sẽ xây dựng trong hướng dẫn này:
Không đi sâu vào chi tiết, đây là mô tả về những gì quy trình tự động này thực hiện:
Chúng ta có hai cách để sử dụng n8n:
Cả hai lựa chọn đều cho phép bạn theo dõi hướng dẫn này mà không tốn chi phí. Chúng tôi sẽ chạy cục bộ, nhưng nếu bạn thích dùng giao diện web, các bước đều giống nhau.
Lưu ý: n8n 2.0 phát hành vào cuối năm 2025 và giới thiệu hệ thống quy trình Nháp/Xuất bản, tự động lưu (tháng 1/2026), bảng tập trung cập nhật để chỉnh sửa node mà không mất ngữ cảnh canvas, và Task Runners cô lập việc thực thi quy trình để tăng bảo mật.
Các quy trình dưới đây chạy trên bản 2.x — nếu bạn đang dùng 1.x, hãy cân nhắc nâng cấp trước khi thực hiện.
Kho chính thức của n8n giải thích cách thiết lập n8n cục bộ. Cách đơn giản nhất là:
Tải và cài đặt Node.js từ trang chính thức.
Mở terminal và chạy lệnh npx n8n.
Xong! Sau khi chạy lệnh, bạn sẽ thấy thế này trong terminal:
Để mở giao diện, nhấn phím "o" trên bàn phím hoặc mở URL localhost hiển thị trong terminal — trong trường hợp của tôi là http://localhost:5678.
Trước khi xây dựng quy trình tự động đầu tiên, sẽ hữu ích nếu hiểu cách n8n hoạt động. Một workflow trong n8n gồm một chuỗi các node. Nó bắt đầu với một node kích hoạt (trigger) xác định điều kiện để workflow được thực thi.
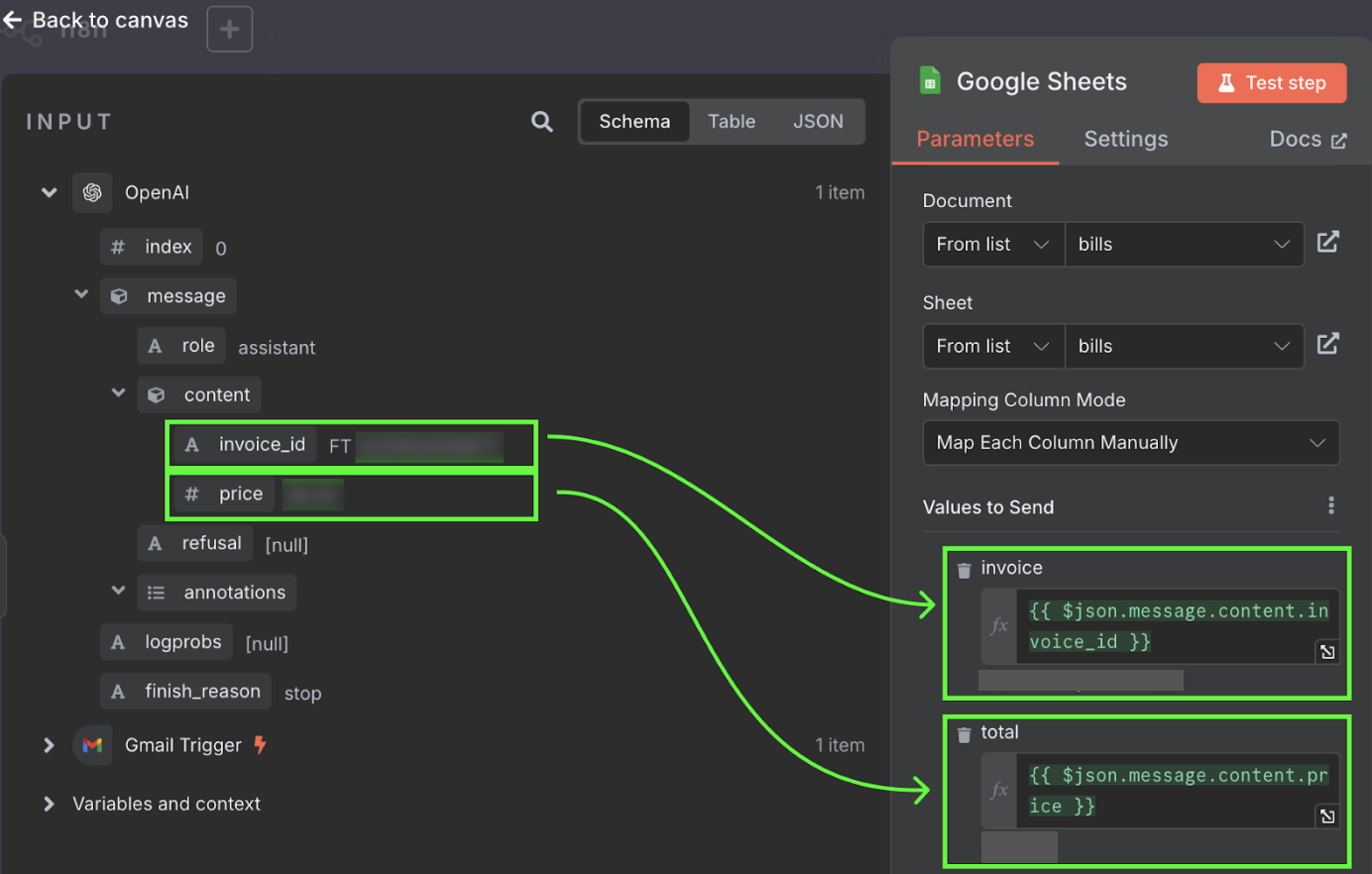
Các node kết nối để di chuyển và xử lý dữ liệu. Trong ví dụ này, node kích hoạt Gmail kết nối đến một node OpenAI. Điều đó có nghĩa email được chuyển cho ChatGPT xử lý. Cuối cùng, đầu ra từ ChatGPT được gửi đến một node Google Sheet, node này kết nối với một Google Sheet trong Google Drive của chúng ta và ghi một dòng mới vào bảng tính.
Quy trình cụ thể này dùng ChatGPT để xác định hóa đơn cần thanh toán và điền một dòng trong sheet với mã hóa đơn và số tiền.
Các workflow của n8n có thể phức tạp hơn nhiều. n8n hỗ trợ hơn 400 tích hợp chính thức (node lõi), cùng hơn 600 node do cộng đồng xây dựng và kết nối tùy chỉnh qua node HTTP Request — nên chúng ta không thể bao quát hết trong một hướng dẫn.
Thay vào đó, tôi sẽ tập trung giúp bạn có cái nhìn tổng quan về cách hoạt động và nền tảng cần thiết để tự khám phá. Nếu có công cụ bạn hay dùng, rất có thể n8n đã hỗ trợ hoặc bạn có thể tích hợp thủ công.
Trong phần này, chúng ta học cách xây dựng workflow ở trên.
Đây là một trường hợp sử dụng thực tế mà tôi dùng để quản lý hóa đơn cho thuê. Tôi có một căn nhà với vài phòng cho thuê. Hóa đơn được chia đều cho tất cả người thuê. Mỗi khi nhận hóa đơn, tôi cần thêm tổng tiền vào một bảng tính được chia sẻ với người thuê.
Tôi có một địa chỉ email riêng để chuyển tiếp các hóa đơn liên quan đến chi phí nhà. Bằng cách này, tôi biết mọi email trong hộp thư đó đều tương ứng với một hóa đơn. Tôi gửi nội dung email đến ChatGPT để xác định mã hóa đơn và tổng số tiền cần trả. Sau đó thông tin này được thêm vào một hàng mới trong bảng tính dùng chung.
Để bắt đầu một workflow mới, chúng ta cần nhấp nút "Add first step...".

Vì đây là node đầu tiên nên nó phải là trigger, vì vậy một bảng chọn node trigger sẽ hiện ra. Node trigger định nghĩa điều kiện để workflow chạy.
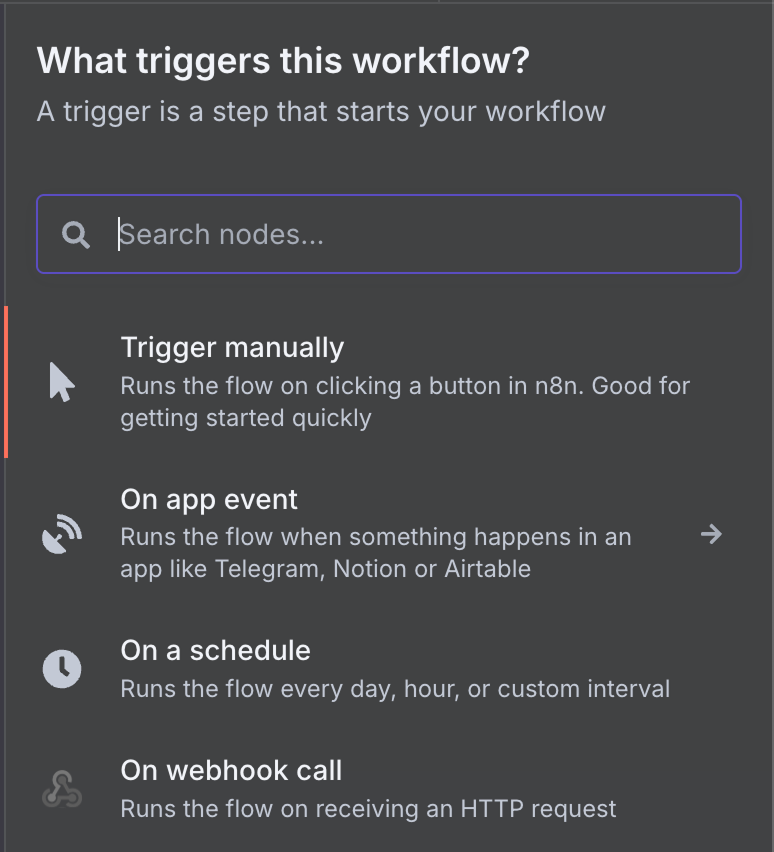
Có rất nhiều node trigger khác nhau. Hãy chọn node trigger Gmail bằng cách gõ "gmail" vào ô tìm kiếm và nhấp vào node Gmail.
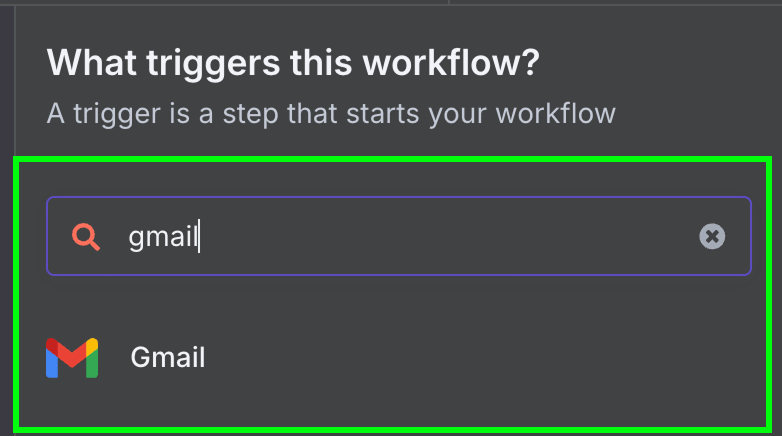
Sau đó, chọn trigger duy nhất có cho Gmail: "On message received".

Thao tác này sẽ mở bảng cấu hình node, nơi chúng ta cần cấu hình thông tin xác thực Gmail để workflow n8n có thể truy cập tài khoản Gmail của mình. Để làm vậy, nhấp "New credential". Cửa sổ sau sẽ mở ra:
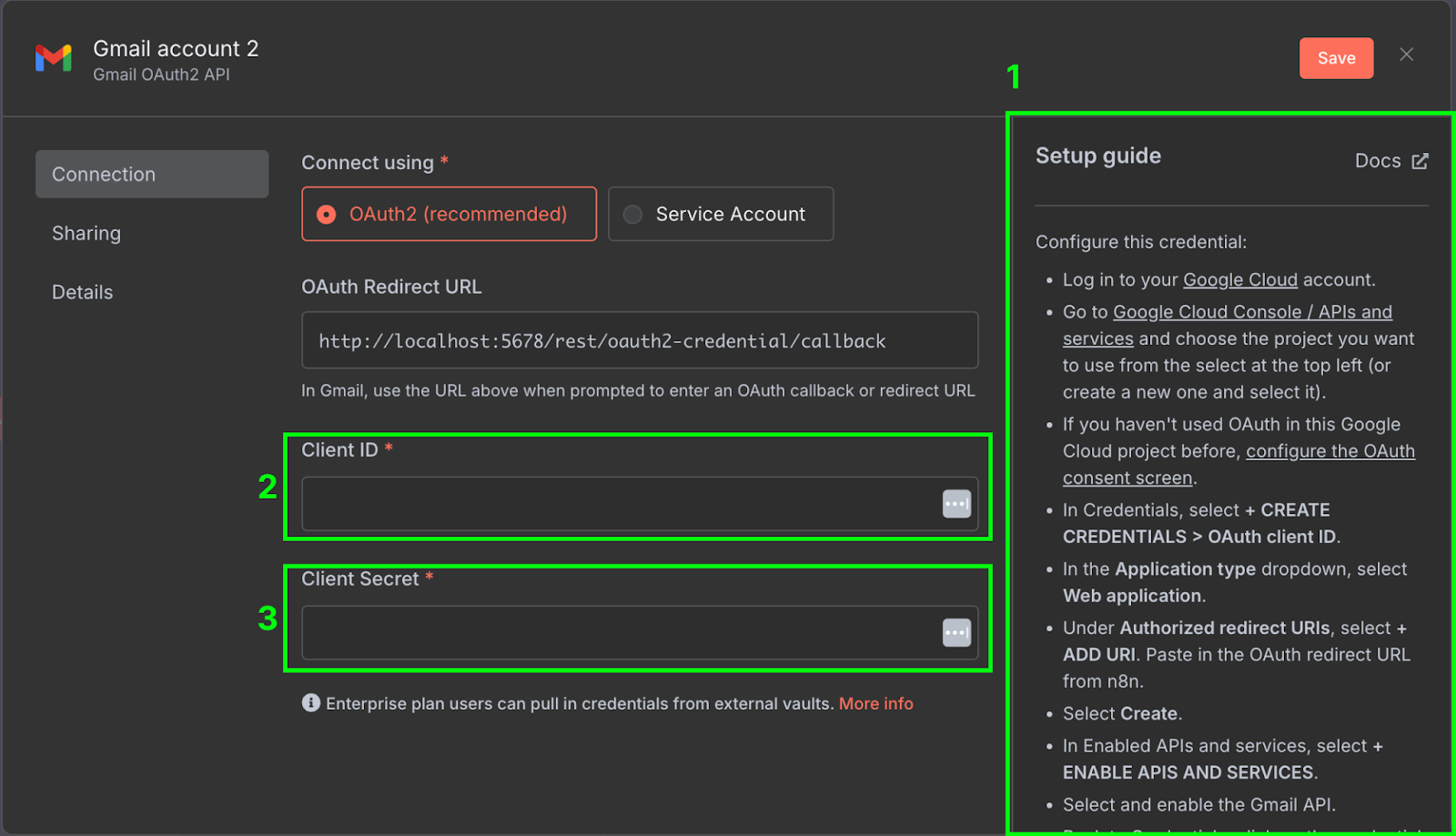
Ở phía bên phải (1), có hướng dẫn thiết lập mô tả các bước cần để cấu hình thông tin xác thực trên Google Cloud. Các hướng dẫn do n8n cung cấp khá đầy đủ, nên chúng tôi sẽ không lặp lại ở đây. Hãy nhớ bật cả Gmail API trong Google Cloud Console.
Khi cấu hình xong, chúng ta cần sao chép client ID (2) và client secret (3) từ Google Cloud vào cấu hình thông tin xác thực của n8n.
Để đảm bảo mọi thứ đã đúng, chúng ta có thể kiểm tra node bằng cách nhấp "Fetch Test Event".

Sau khi kiểm thử, chúng ta sẽ thấy email mới nhất trong hộp thư đến ở phần đầu ra. Nội dung email nằm trong trường snippet.
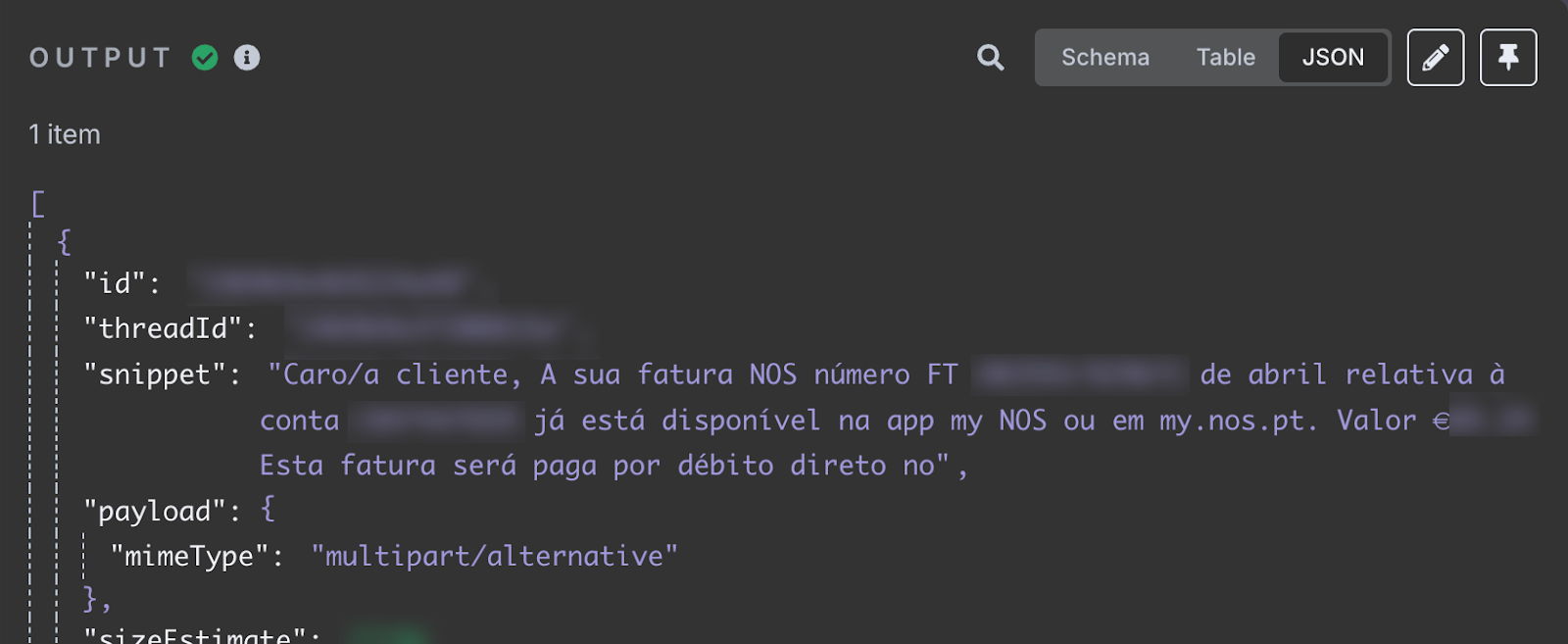
Trường snippet lưu nội dung email. Nó cho biết hóa đơn internet tháng 4 của tôi đã có. Email cung cấp mã hóa đơn và tổng số tiền cần trả. Đây là thông tin chúng ta muốn thêm vào bảng tính.
Để thuận tiện khi thử nghiệm, tôi khuyên nên ghim (pin) đầu ra bằng cách nhấp nút ghim ở góc trên cùng bên phải:
Thao tác này sẽ khóa kết quả cho trigger, nghĩa là mỗi khi chạy workflow, cùng một đầu ra này sẽ được dùng, giúp thử nghiệm dễ hơn vì kết quả không bị ảnh hưởng bởi email mới. Chúng ta sẽ bỏ ghim khi thiết lập xong workflow.
Ở giai đoạn này, workflow của chúng ta sẽ chỉ có một node trigger (ta có thể nhận biết vì có biểu tượng tia sét nhỏ ở bên trái).

Lưu ý rằng do nhiều khả năng bạn sẽ không có email hóa đơn trong hộp thư, sau này ChatGPT có thể đưa ra câu trả lời không hợp lý. Nếu bạn muốn thử đúng workflow này, bạn có thể tự gửi một email kiểm thử với nội dung sau (hoặc tương tự):
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.Sau khi gửi email này, bạn phải bỏ ghim kết quả, chạy lại node Gmail và ghim kết quả mới.
Bước tiếp theo là cấu hình node OpenAI. Bắt đầu bằng cách nhấp nút "+" ở bên phải node trigger Gmail:

Gõ "OpenAI" và chọn mục tương ứng từ danh sách.
Sau đó, dưới "Text Actions", chọn node "Message a model". Node này dùng để nhắn tin với một LLM.

Như trước, chúng ta cần tạo thông tin xác thực để truy cập OpenAI. Lưu ý rằng sau khi tạo, thông tin xác thực có thể dùng lại trong mọi workflow. Không cần thiết lập lại mỗi lần.
Với thông tin xác thực OpenAI, chúng ta chỉ cần API key. Nếu bạn chưa có, có thể tạo tại đây. Nếu gặp khó khăn, n8n cũng có hướng dẫn cho việc này.
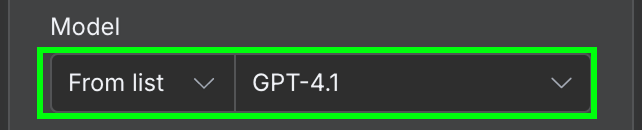
Về cấu hình, chúng ta cần chọn mô hình AI muốn dùng và thông điệp gửi tới mô hình.
Với mô hình, chúng ta sẽ dùng GPT-4.1. OpenAI đã phát hành gia đình GPT-5 (5.4, 5.4-mini, 5.5) và ngừng 4.1 trên ChatGPT, nhưng 4.1 vẫn có qua API và là quá đủ cho bài toán trích xuất đơn giản như thế này.
Trong trường thông điệp, chúng ta cần cung cấp prompt. Ở ví dụ này, ta đưa cho mô hình nội dung email và yêu cầu xác định mã hóa đơn và tổng số tiền cần thanh toán. Đây là prompt tôi dùng:
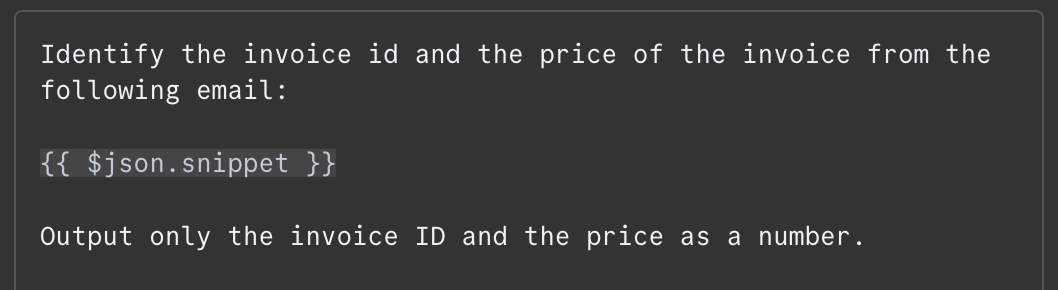
Nội dung email được cung cấp dưới dạng {{ $json.snippet }}. Trong n8n, prompt có thể chứa biến được lấy từ đầu ra của các node trước đó, ở đây là email. Danh sách các trường có sẵn hiển thị bên trái. Ta có thể gõ thủ công hoặc kéo thả trường vào prompt.
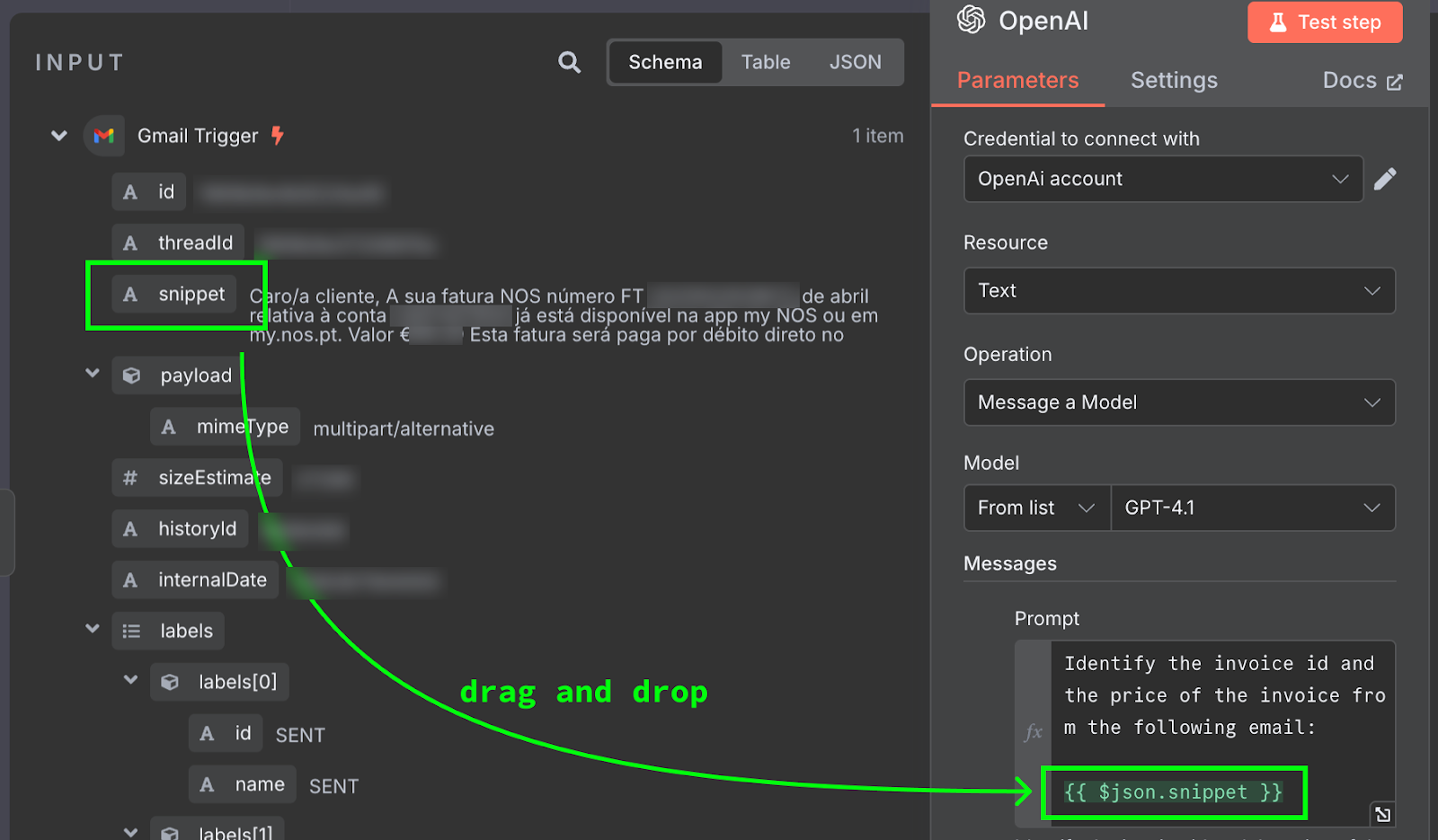
Để thử nghiệm, ta nhấp nút "Test Step" ở trên cùng bảng cấu hình. Kết quả hiển thị ở bên phải:
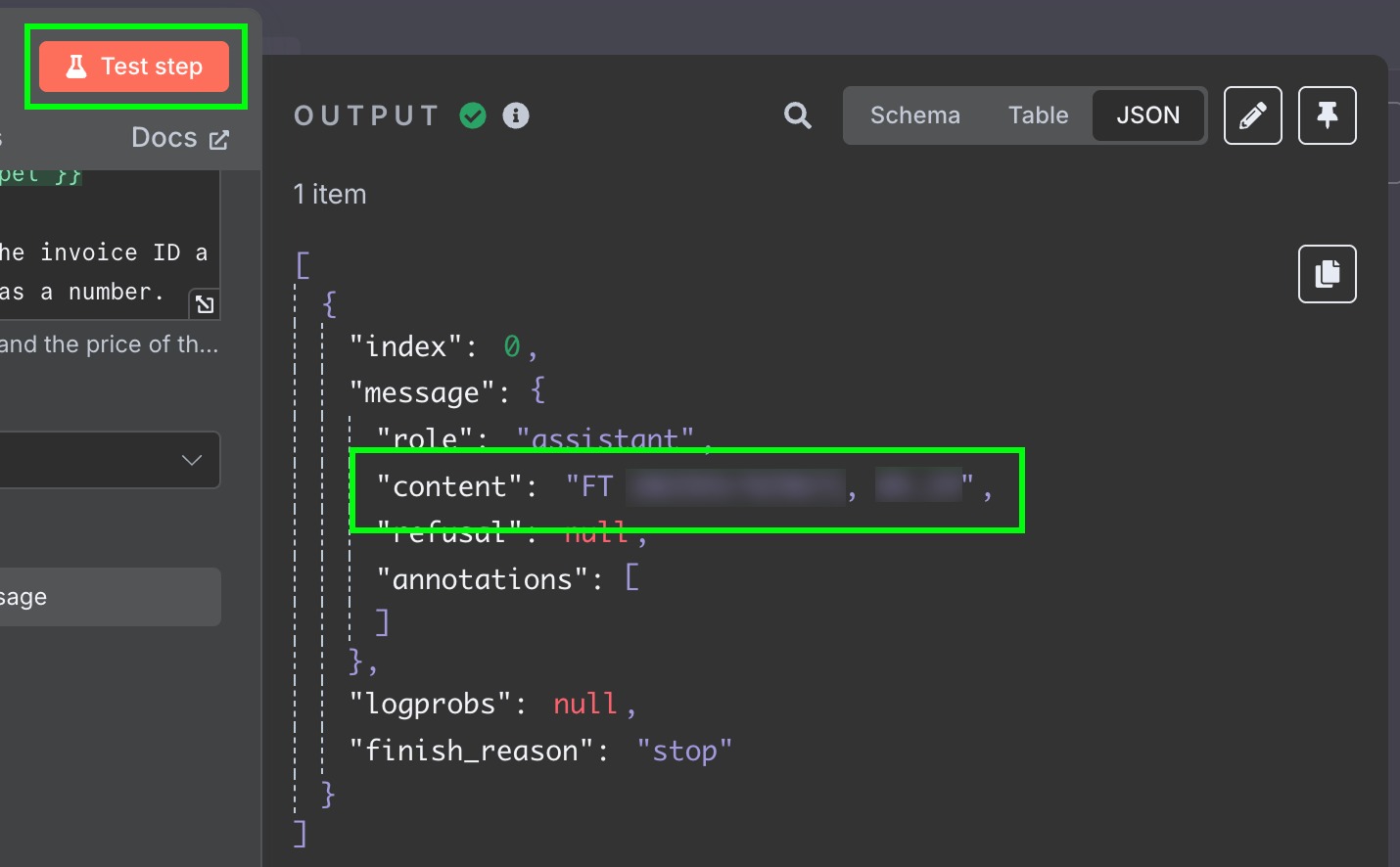
Kết quả là một chuỗi phản hồi từ mô hình. Chúng ta muốn có hai trường tách biệt để khỏi phải xử lý thêm. Có thể đạt được bằng cách đổi đầu ra của LLM sang JSON:

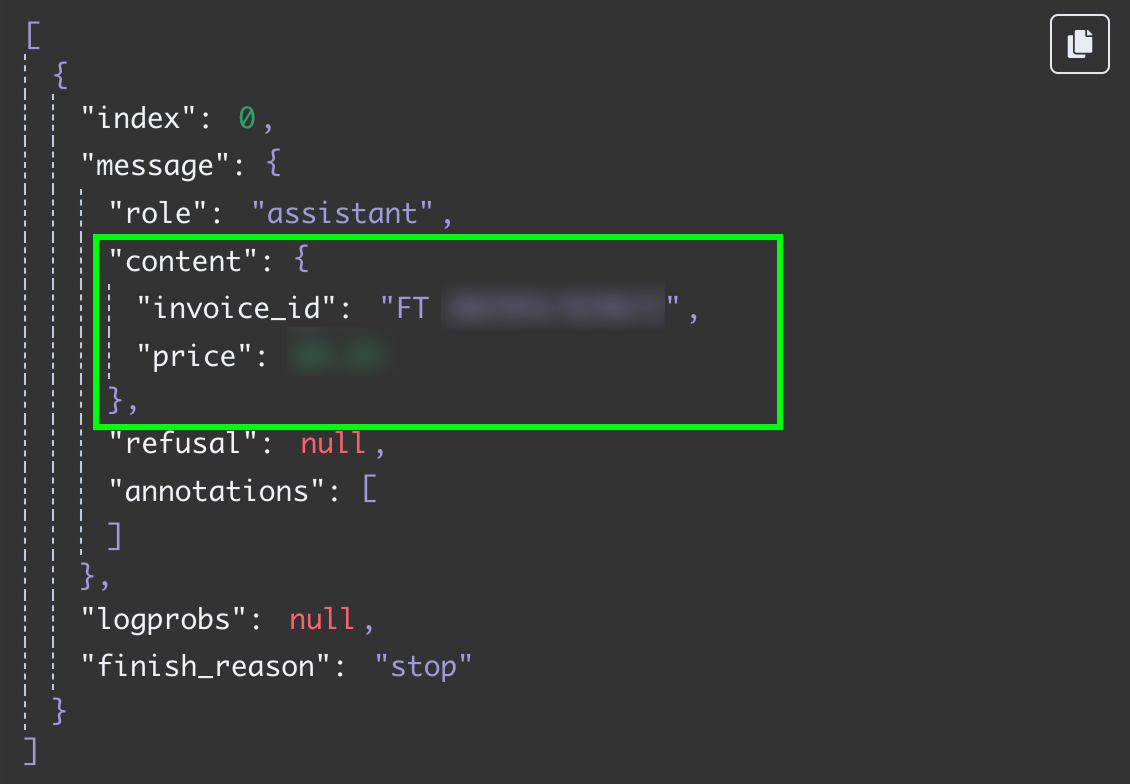
Thử lại bước này, chúng ta nhận hai trường dưới dạng dữ liệu JSON:
Bước cuối của workflow này là gửi mã hóa đơn và số tiền sang một hàng mới trong Google Sheet. Lúc này, ta cần kết nối đầu ra của node OpenAI tới Google Sheets. Thực hiện như trước bằng cách nhấp nút "+" ở bên trái node:
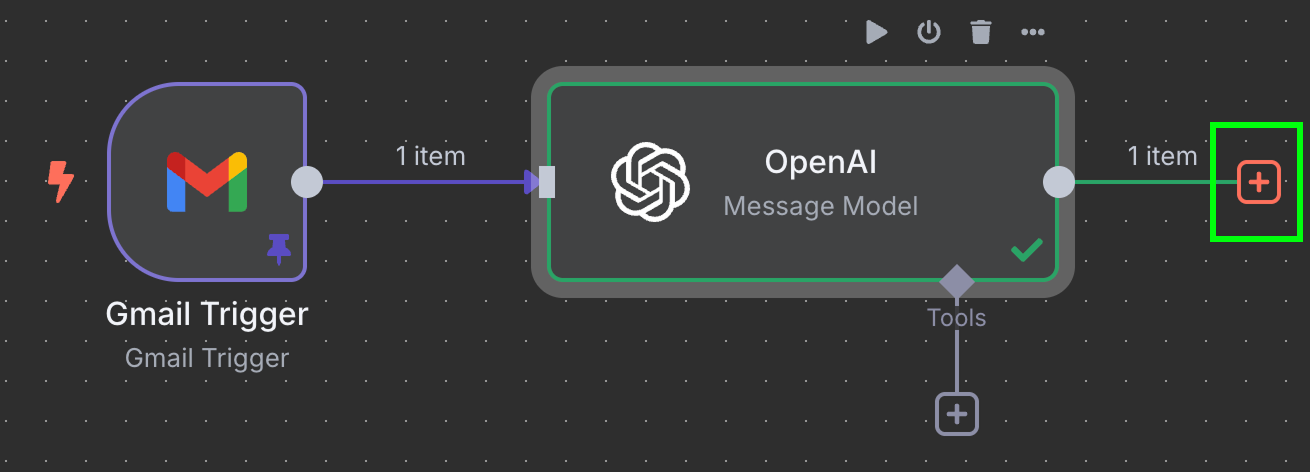
Ở đây chúng ta gõ Google Sheets và chọn node "Append row in sheet":
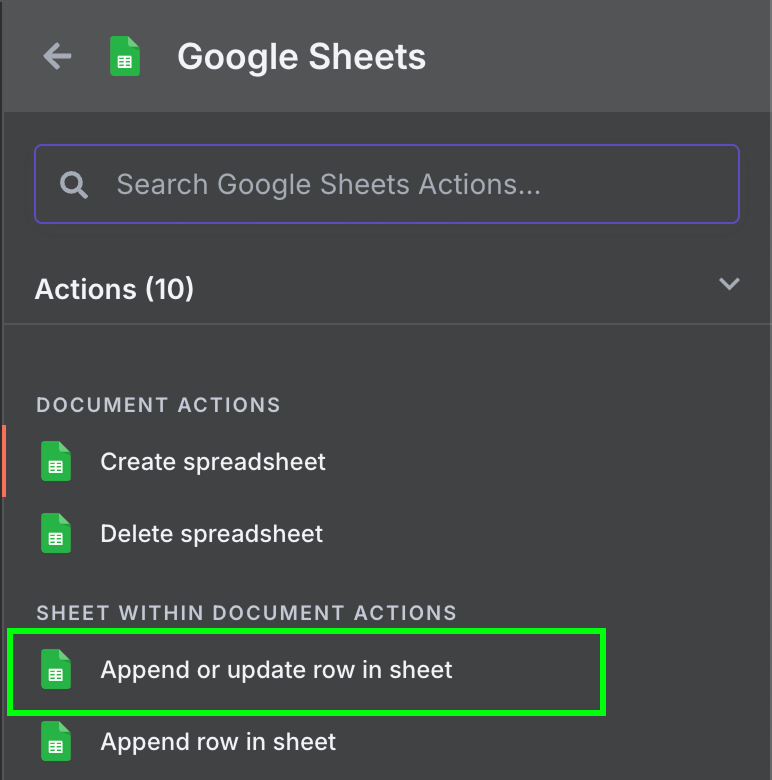
Chúng ta có thể dùng lại thông tin xác thực đã dùng để truy cập Gmail. Nhưng cần bật các API sau trong Google Cloud Console:
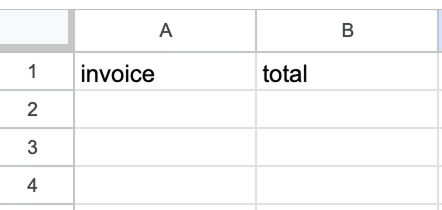
Để cấu hình node Google Sheets, chúng ta cần chọn sheet và chọn các giá trị để điền vào trường. Sheet nên được tạo thủ công với hai cột, một để lưu mã hóa đơn và một cho tổng tiền hóa đơn.
Những giá trị đó được lấy từ đầu ra của node OpenAI. Chúng ta có thể kéo thả chúng vào các cột.
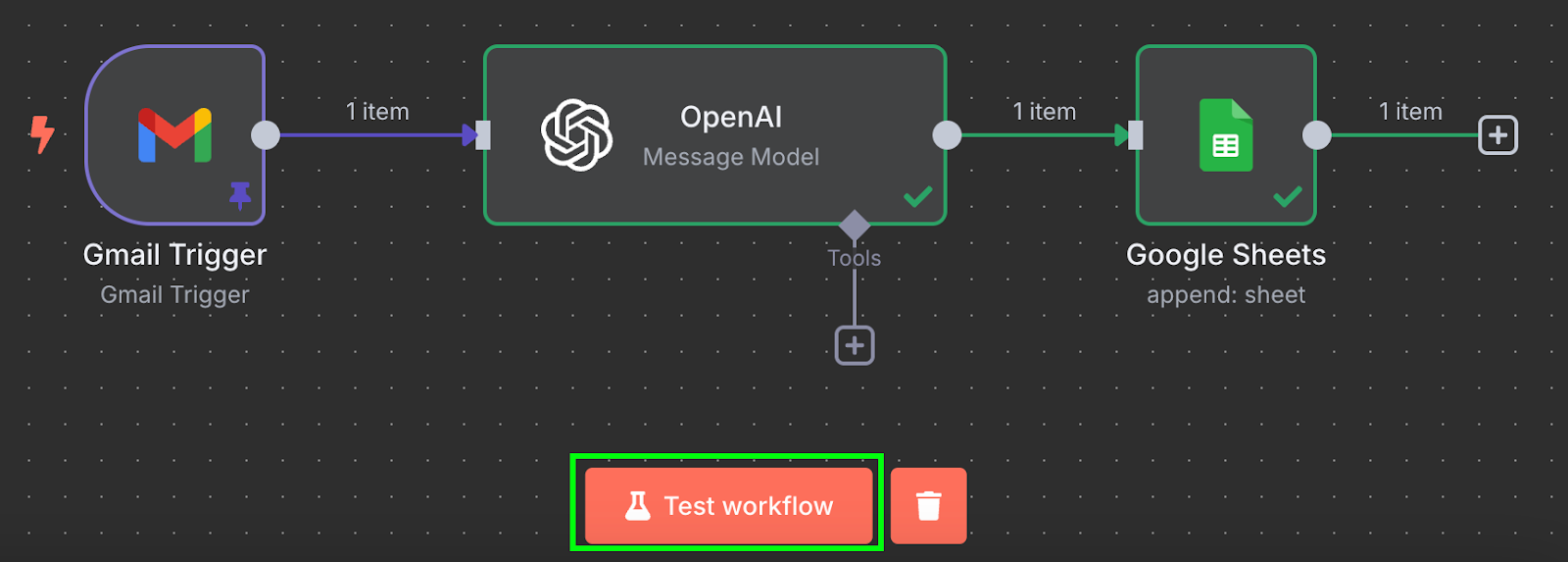
Xong rồi! Chúng ta đã có một workflow sẽ tự động xử lý hóa đơn vào Google Sheet. Có thể kiểm thử bằng cách nhấp "Test workflow" ở dưới cùng:
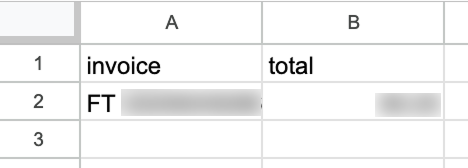
Sau khi chạy, nếu vào Google Sheet chúng ta sẽ thấy một hàng mới với dữ liệu:
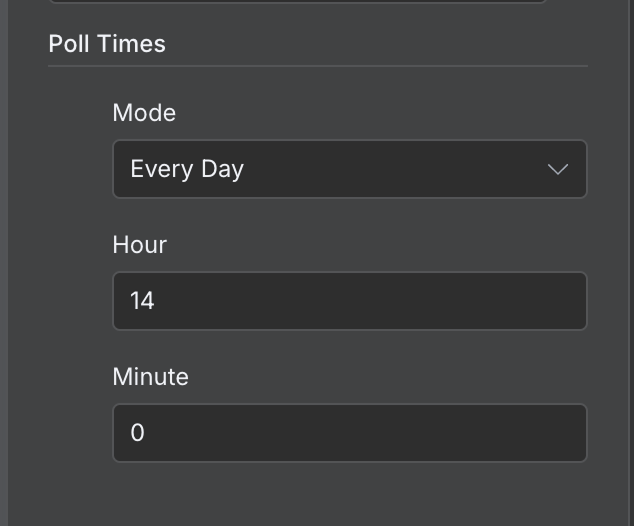
Theo mặc định, một workflow sẽ chạy mỗi phút. Tùy vào workflow, chúng ta nên cấu hình tần suất phù hợp. Trong ví dụ này, mỗi phút là quá thường xuyên. Mỗi ngày một lần sẽ hợp lý hơn.
Chúng ta có thể cấu hình bằng cách nhấp đúp vào node trigger và đặt giá trị khác trong trường "Poll Times":
Trong phần này, chúng ta xây dựng một workflow tác tử RAG phức tạp hơn. RAG là viết tắt của retrieval-augmented generation, một kỹ thuật kết hợp việc truy xuất thông tin liên quan từ cơ sở dữ liệu hoặc tài liệu với việc dùng mô hình ngôn ngữ để tạo phản hồi dựa trên thông tin đã truy xuất.
Điều này rất hữu ích khi chúng ta có một kho tri thức cụ thể, như một tài liệu dài, và muốn xây dựng tác tử AI có thể trả lời câu hỏi về tài liệu đó.
Tôi thích chơi board game, nhưng bạn bè và tôi thường tranh luận về luật chơi rồi mất thời gian tra cứu thay vì chơi, khá khó chịu. Xây dựng một tác tử RAG dựa trên luật của trò chơi là giải pháp tốt cho vấn đề này, vì lần sau có câu hỏi, chúng tôi chỉ cần hỏi tác tử.
Để xây dựng tác tử này, chúng ta sẽ thực hiện hai workflow:
Pinecone là một loại cơ sở dữ liệu quản lý dữ liệu dưới dạng vector. Cơ sở dữ liệu vector như Pinecone rất phù hợp cho tác tử RAG của chúng ta vì nó giúp tác tử tra cứu và hiểu thông tin liên quan nhanh chóng, nâng cao hiệu quả cung cấp câu trả lời chính xác.
Vì workflow này chỉ cần chạy một lần, ta có thể dùng node trigger thủ công. Đây là node trigger dùng để chạy workflow bằng tay.
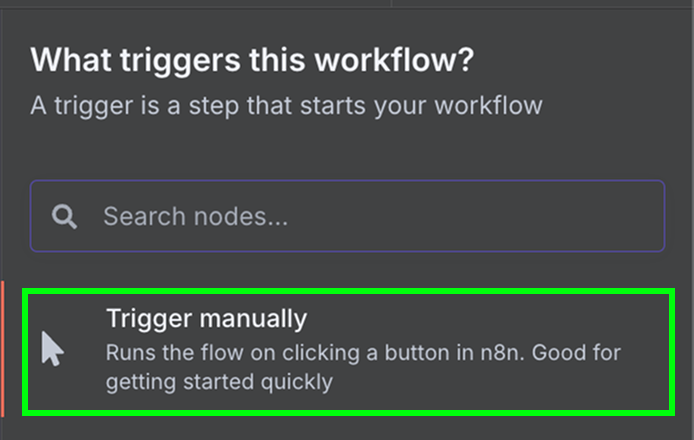
Kết nối node trigger thủ công với node “Google Drive” để tải dữ liệu từ Google Drive.

Sử dụng cấu hình sau:
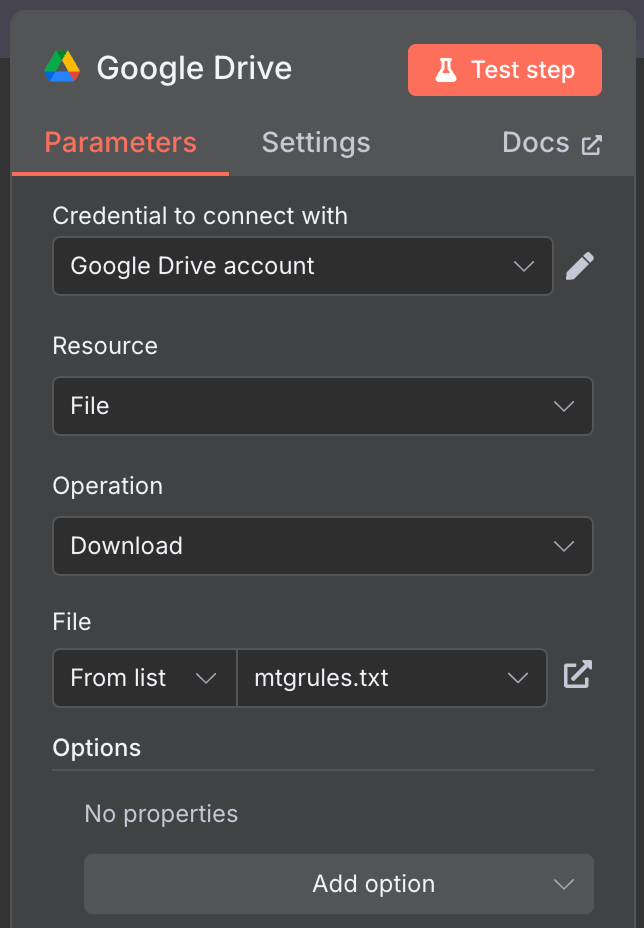
Tôi dùng tệp mtgrules.txt công khai chứa luật của trò chơi thẻ bài Magic: The Gathering. Bạn có thể dùng bất kỳ tệp nào bạn muốn đặt câu hỏi; workflow là như nhau.
Để cấu hình Pinecone, đăng nhập vào Pinecone, sao chép API key và tạo một index bằng cách nhấp nút "Create index". Tôi đặt tên index là rules và chọn mô hình text-embedding-3-small.

Quay lại n8n, kết nối đầu ra của node Google Drive đến node Pinecone Vector Store với hành động "Add documents to vector store":
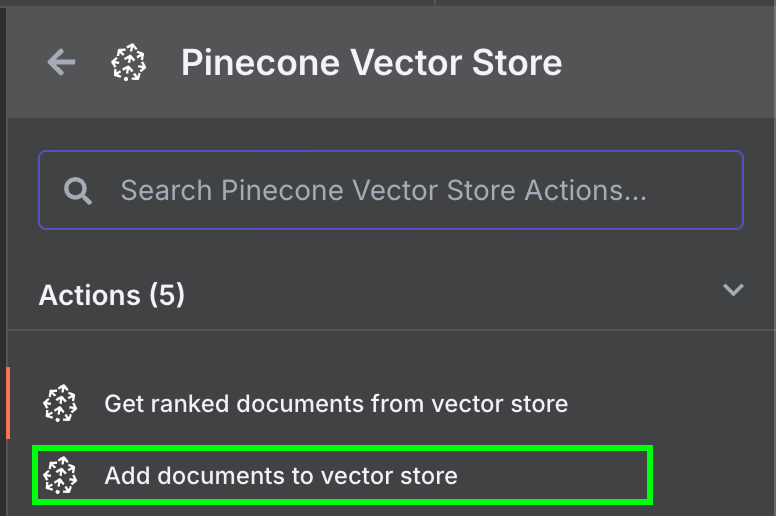
Để cấu hình node, chúng ta cần tạo thông tin xác thực bằng cách dán API key và chọn Pinecone Index vừa tạo. Bên dưới node Pinecone Vector Store, chúng ta thấy hai thứ cần cấu hình: một mô hình embedding và một data loader.
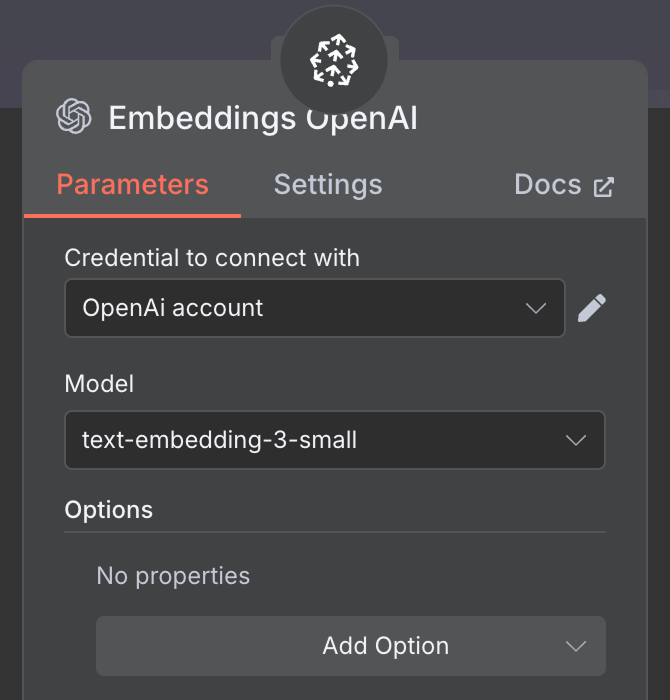
Với embedding, tạo node OpenAI Embedding với mô hình text-embedding-3-small:
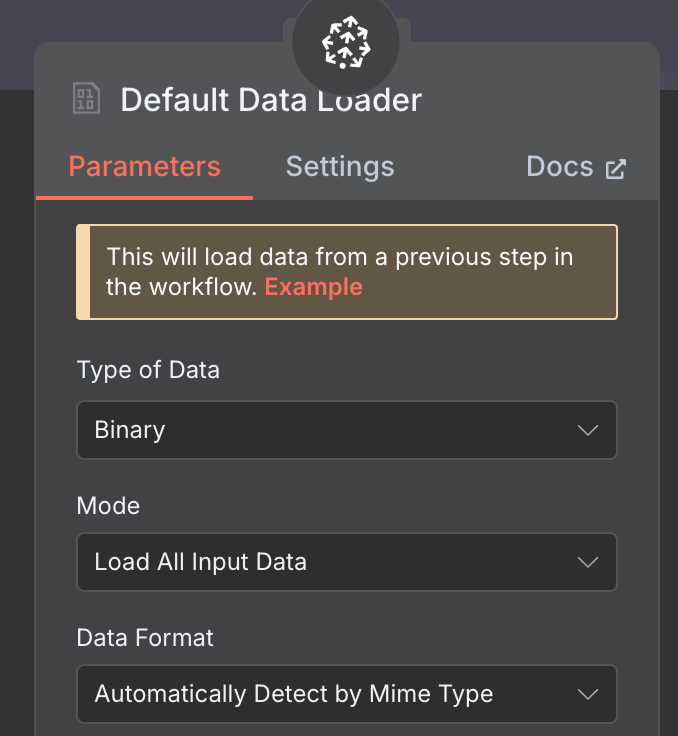
Với data loader, tạo node Default Data Loader với kiểu dữ liệu nhị phân (binary):
Cuối cùng, data loader cần một Text Splitter node, chỉ định cách tách dữ liệu từ tệp khi tạo vector store. Chúng ta dùng node Recursive Character Text Splitter, là node được khuyến nghị cho hầu hết ứng dụng.
Chúng ta cấu hình kích thước đoạn (chunk size) là 1.000 và chồng lấn đoạn (chunk overlap) là 200:
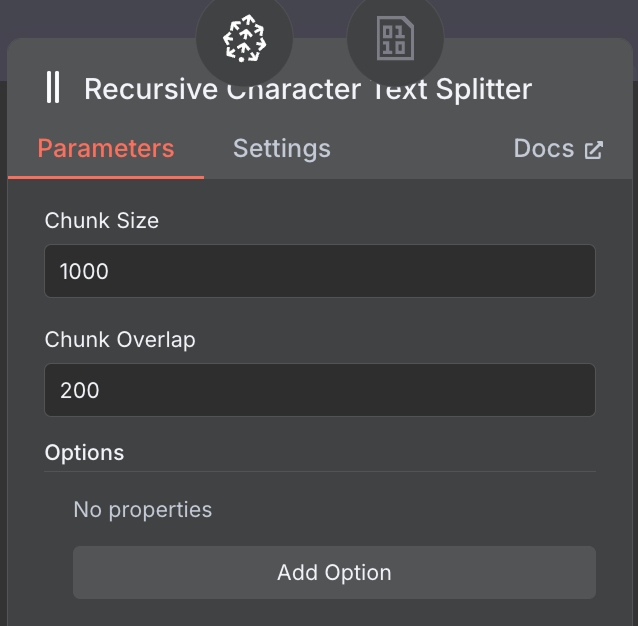
Khi chọn kích thước và chồng lấn đoạn, hãy cân nhắc dùng đoạn lớn hơn cho tài liệu dài để nắm bắt đủ nội dung và chồng lấn nhỏ hơn để giữ ngữ cảnh giữa các phần mà không trùng lặp.
Đây là workflow cuối cùng:
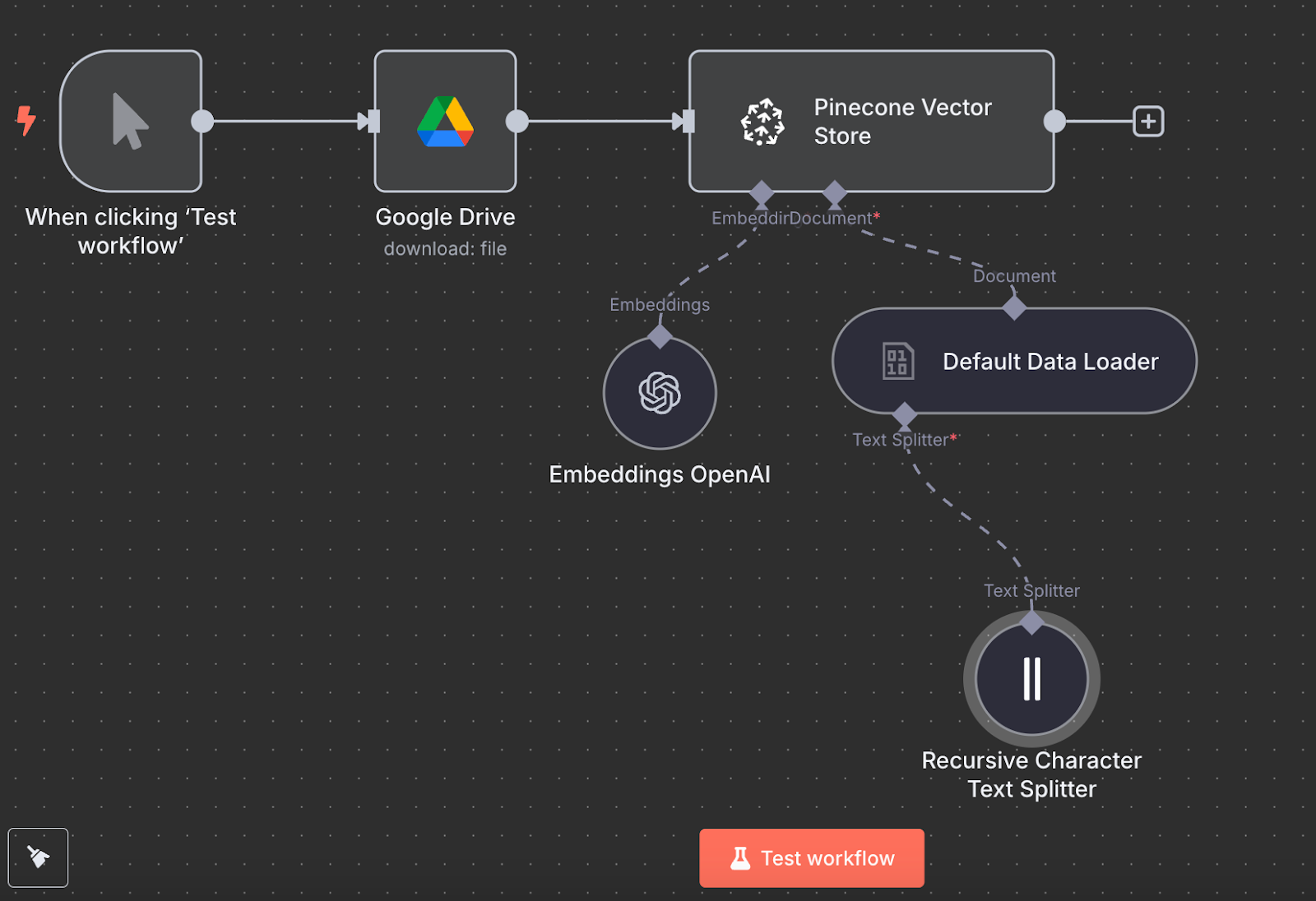
Chúng ta có thể chạy bằng cách nhấp “Test workflow”, và khi hoàn tất, có thể kiểm tra trong Pinecone rằng dữ liệu đã được nạp.
Đây là sơ đồ cuối cùng cho tác tử RAG:
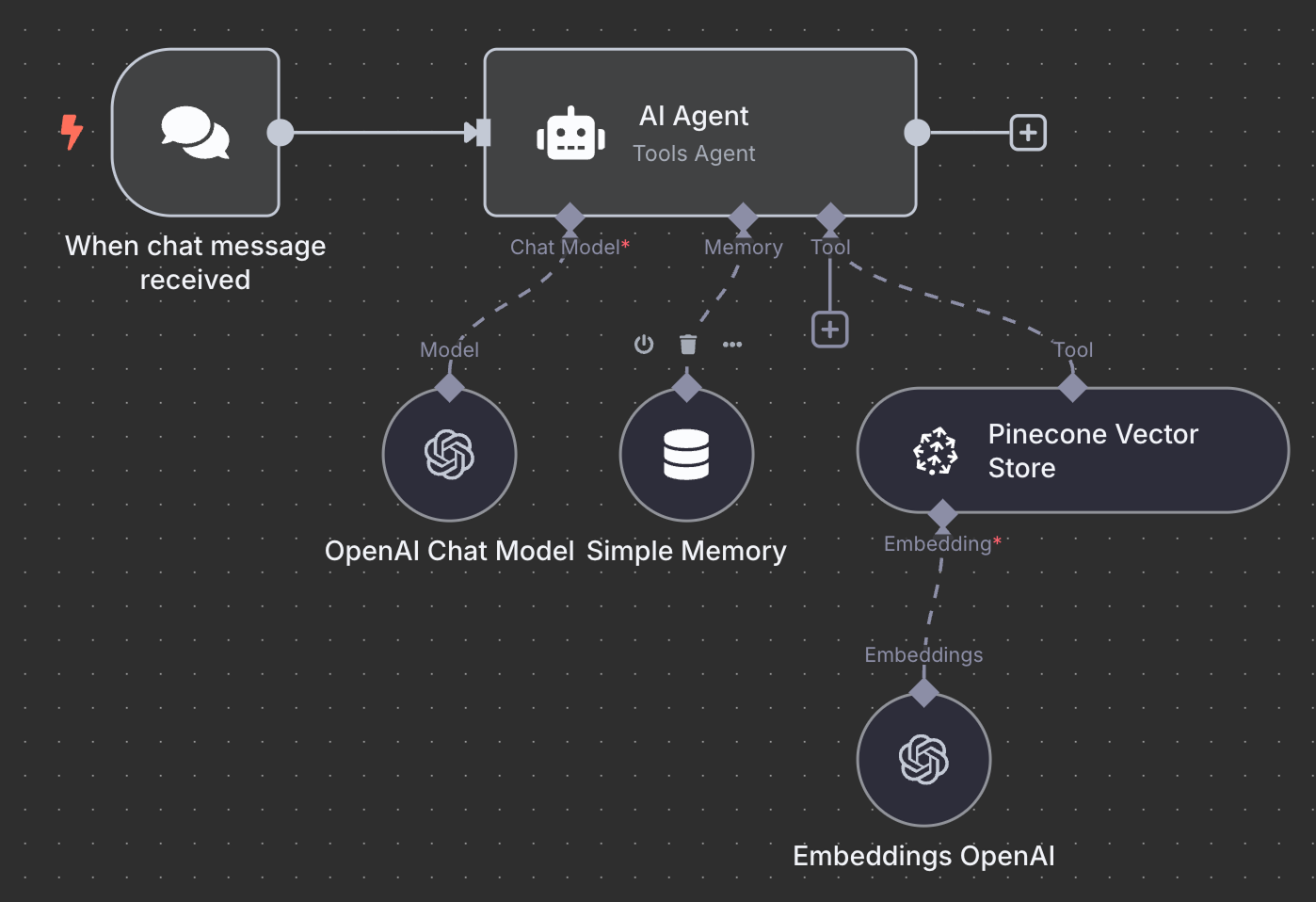
Như một bài tập, tôi khuyến khích bạn cố gắng hiểu và thậm chí tự dựng lại cục bộ trước khi đọc tiếp.
Chúng ta bắt đầu với node trigger "On chat message". Node này dùng để tạo workflow trò chuyện.
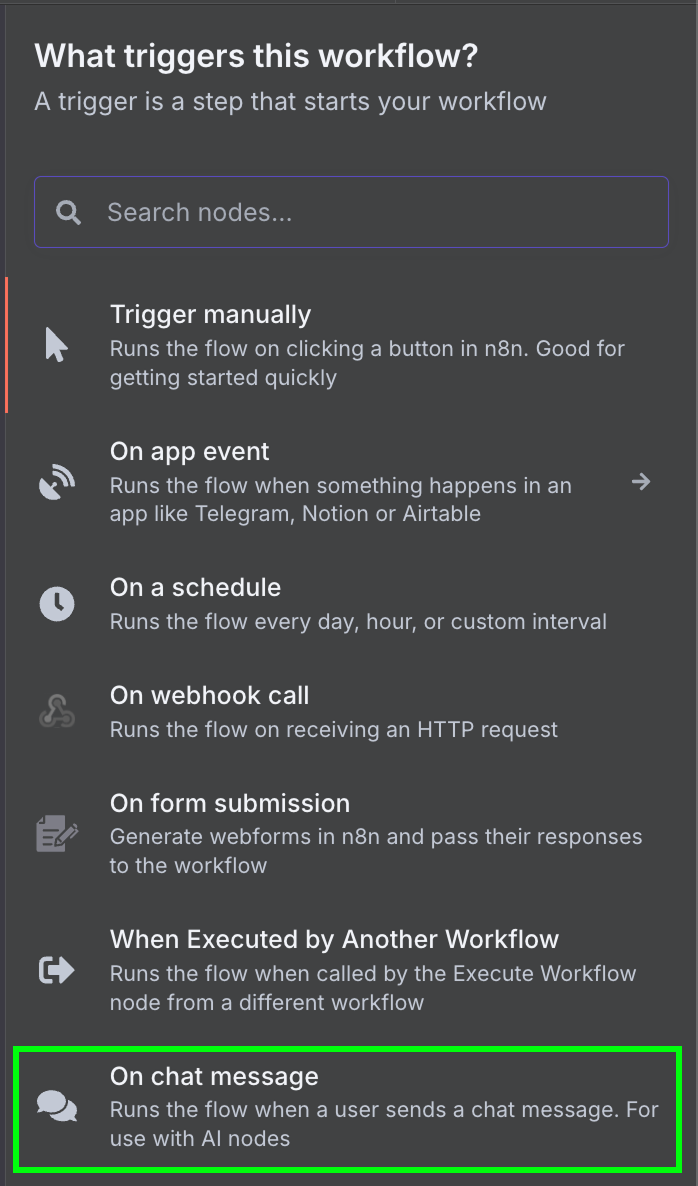
Tiếp theo, chúng ta kết nối trigger chat với node "AI Agent" với các tùy chọn mặc định.
Bên dưới AI Agent, chúng ta có thể cấu hình ba thành phần:
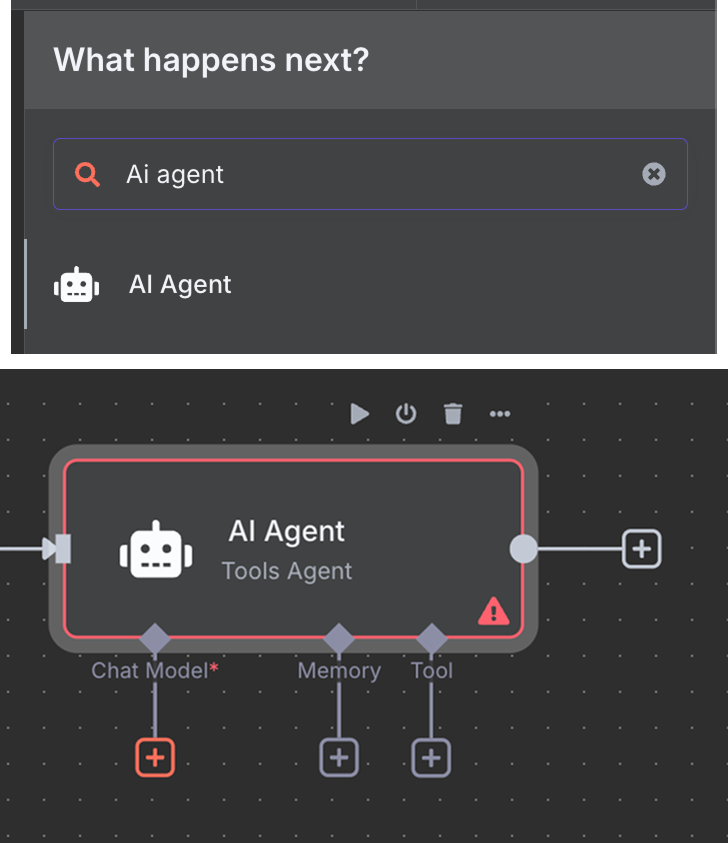
Với mô hình AI, chúng ta chọn node "OpenAI Chat Model" và dùng GPT-4.1 như trước. Gia đình GPT-5 là dòng mô hình hiện tại của OpenAI, nhưng 4.1 có cửa sổ ngữ cảnh 1M token và rất phù hợp với RAG.
Với bộ nhớ, chúng ta dùng node "Simple Memory" với cửa sổ ngữ cảnh dài 5. Điều này có nghĩa tác tử sẽ ghi nhớ và cân nhắc 5 tương tác trước đó khi trả lời.
Cuối cùng, ở công cụ (tool), chúng ta thêm node "Pinecone Vector Store" với cấu hình sau:
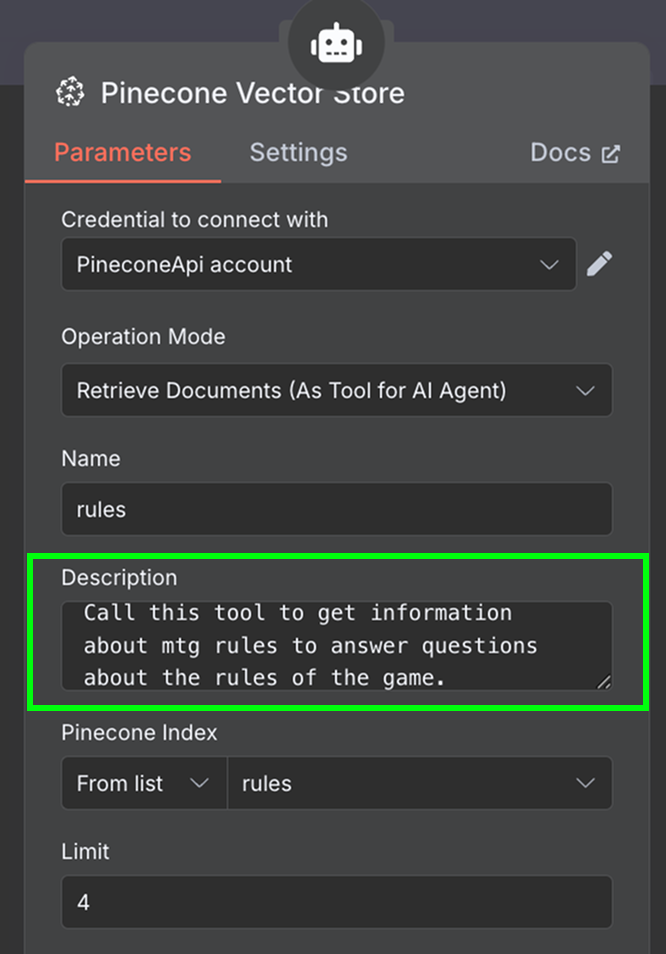
Trong trường mô tả, điều quan trọng là chỉ rõ khi nào công cụ nên được sử dụng. Đây là cơ sở để tác tử quyết định có gọi công cụ hay không.
Điều cuối cùng cần làm là cấu hình embedding dùng bởi vector store. Như trước, chúng ta dùng node OpenAI Embedding với mô hình text-embedding-3-small:
Workflow đã hoàn tất và chúng ta có thể trò chuyện với tác tử. Đây là một ví dụ:
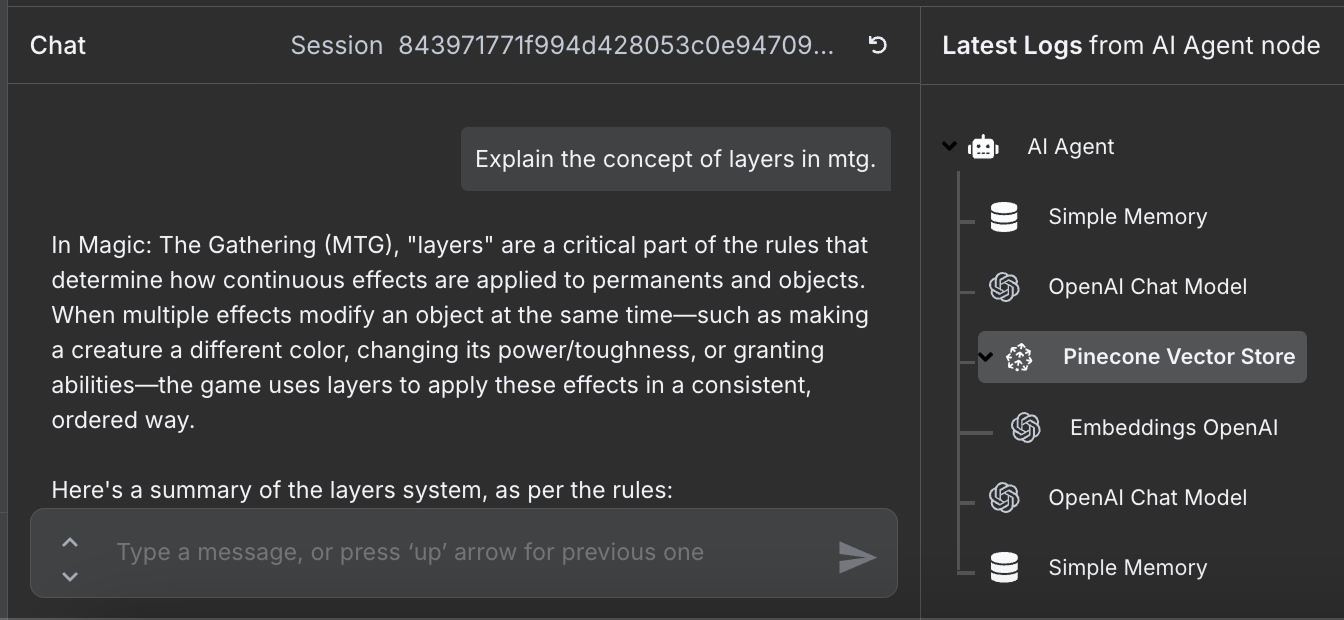
Ở bên phải, chúng ta có thể thấy các bước tác tử đã thực hiện để trả lời câu hỏi. Đặc biệt, nó đã truy cập cơ sở dữ liệu Pinecone để lấy thông tin luật liên quan.
n8n cung cấp một tính năng hữu ích có thể tăng tốc đáng kể quá trình tạo workflow: thư viện mẫu n8n.
Thư viện này là tập hợp các workflow dựng sẵn, do cộng đồng và chuyên gia n8n xây dựng. Dù chúng ta đang cố tự động hóa tác vụ đơn giản hay quy trình phức tạp, rất có khả năng đã có ai đó xây dựng workflow phù hợp với nhu cầu của chúng ta.
Nhập một workflow vào thiết lập n8n của chúng ta đồng nghĩa không phải lúc nào cũng phải bắt đầu từ đầu. Thay vào đó, ta có thể tận dụng các giải pháp sáng tạo do người dùng khác phát triển. Sau khi nhập, việc cần làm chỉ là cấu hình thông tin xác thực và tinh chỉnh để phù hợp yêu cầu cụ thể.
Với bất kỳ tác vụ nào muốn tự động hóa, từ xử lý email đến quản lý mạng xã hội, rất có thể đã có mẫu trong thư viện.
n8n cung cấp hệ sinh thái tích hợp phong phú, cho phép chúng ta kết nối hơn một nghìn dịch vụ và công cụ để tạo tác tử AI. Trong hướng dẫn này, chúng ta mới chỉ chạm đến bề nổi những gì n8n có thể làm. Bằng cách khám phá cách dùng n8n để xây dựng tác tử AI tự động hóa các tác vụ thường ngày, chúng ta chỉ mới bắt đầu khai mở tiềm năng của nó.
Học AI với các khóa học này!
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút