track
Utveckla AI-applikationer
21 timmar
n8n har vuxit fram som ett populärt och kraftfullt ramverk inom agentisk AI. Det låter oss bygga automatiserade arbetsflöden utan behov av komplex kodning.
I den här artikeln går jag steg för steg igenom hur du får ut mesta möjliga av den här robusta plattformen för att automatisera två olika processer:
Vi håller våra läsare uppdaterade om det senaste inom AI via The Median, vårt kostnadsfria fredagsnyhetsbrev som sammanfattar veckans viktigaste nyheter. Prenumerera och håll dig skarp på bara några minuter i veckan:
n8n är ett open source‑verktyg för automatisering som hjälper oss koppla ihop olika appar och tjänster för att skapa arbetsflöden, ungefär som ett digitalt löpande band. Användare kan visuellt designa dessa arbetsflöden med noder, där varje nod representerar ett steg i processen.
Med n8n kan vi automatisera uppgifter, hantera dataflöden och till och med integrera API:er, allt utan att behöva omfattande programmeringskunskaper. Här är ett exempel på en automatisering vi bygger i den här guiden:
Utan att gå in på detaljer är detta vad automatiseringen gör:
Vi har två sätt att använda n8n:
Båda alternativen låter dig följa den här guiden utan kostnad. Vi kör det lokalt, men om du föredrar webgränssnittet är stegen desamma.
Obs: n8n 2.0 släpptes i slutet av 2025 och introducerade ett utkast/publicera‑arbetsflödessystem, autospara (januari 2026), ett uppdaterat fokusfönster för att redigera noder utan att tappa kontext i canvas, samt Task Runners som isolerar arbetsflödeskörning för bättre säkerhet.
Arbetsflödena nedan körs på 2.x — om du använder 1.x, överväg att uppgradera innan du följer med.
n8n:s officiella repo förklarar hur du sätter upp n8n lokalt. Det enklaste sättet är att:
Ladda ner och installera Node.js från den officiella webbplatsen.
Öppna en terminal och kör kommandot npx n8n.
Klart! Efter att du kört kommandot bör du se detta i terminalen:
För att öppna gränssnittet, tryck antingen "o" på tangentbordet eller öppna localhost‑URL:en som visas i terminalen—i mitt fall http://localhost:5678.
Innan vi bygger vår första automatisering är det bra att förstå hur n8n fungerar. Ett n8n‑arbetsflöde består av en sekvens av noder. Det börjar med en trigger‑nod som anger villkoren för när arbetsflödet ska köras.
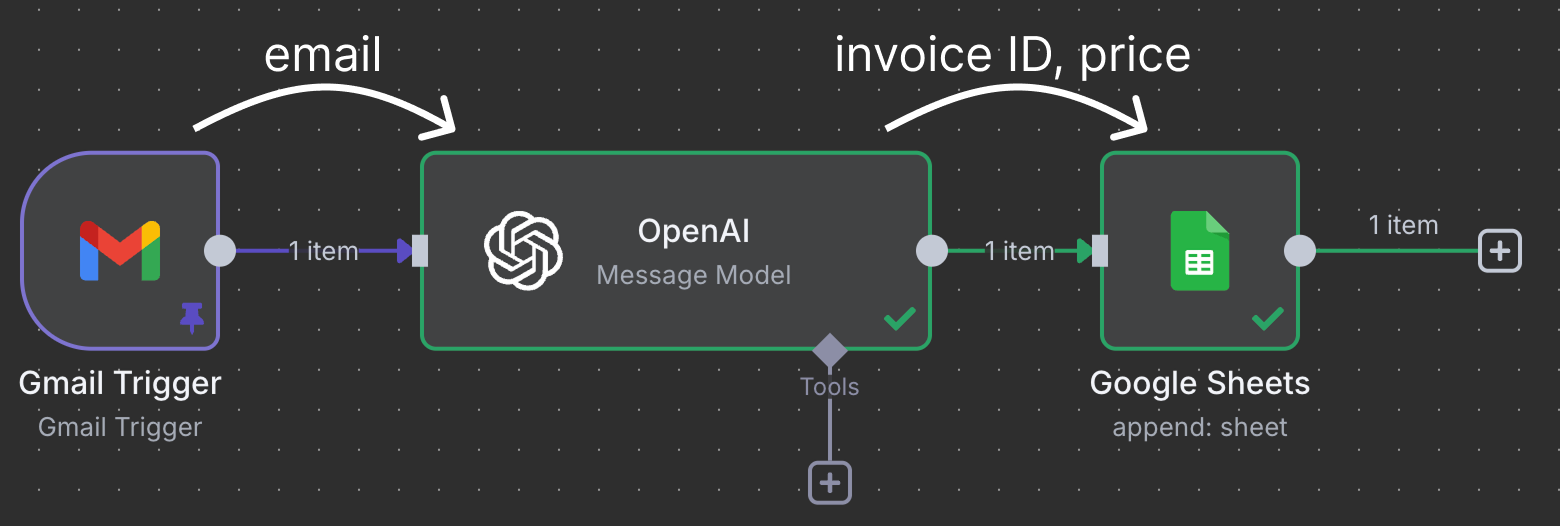
Noder kopplas ihop för att flytta och bearbeta data. I det här exemplet kopplas Gmail‑triggern till en OpenAI‑nod. Det betyder att mejlet lämnas till ChatGPT för bearbetning. Slutligen skickas ChatGPT:s utdata till en Google Sheets‑nod, som kopplas till ett kalkylark i vår Google Drive och skriver en ny rad i ett kalkylblad.
Just det här arbetsflödet använder ChatGPT för att identifiera fakturor som behöver betalas och lägger till en rad i bladet med faktura‑ID och belopp.
n8n‑arbetsflöden kan vara mycket mer komplexa. n8n stöder över 400 officiella integrationer (kärnnoder), plus 600+ community‑byggda noder och anpassade kopplingar via HTTP Request‑noden — så vi kan inte täcka alla i en guide.
I stället fokuserar jag på att ge dig en övergripande bild av hur det fungerar och tillräcklig bakgrund för att utforska vidare på egen hand. Om det finns ett verktyg du ofta använder är chansen stor att n8n antingen stöder det eller att du kan integrera det manuellt.
I den här delen lär vi oss bygga arbetsflödet ovan.
Detta är ett verkligt användningsfall som jag använder för att hantera mina hyresfakturor. Jag har ett hus med några rum som jag hyr ut. Räkningarna delas lika mellan alla hyresgäster. Varje gång jag får en faktura behöver jag lägga till totalsumman i ett kalkylark som delas med hyresgästerna.
Jag har en specifik e‑postadress dit fakturor för husets räkningar vidarebefordras. På så sätt vet jag att alla mejl i den inkorgen motsvarar en faktura. Jag skickar innehållet i mejlet till ChatGPT för att identifiera faktura‑ID och totalsumma. Sedan läggs den informationen till som en ny rad i det delade kalkylarket.
För att starta ett nytt arbetsflöde klickar vi på knappen "Add first step...".

Eftersom det är den första noden måste det vara en trigger, så vi får upp en panel för att välja trigger‑nod. En trigger‑nod definierar villkoren för när arbetsflödet ska köras.
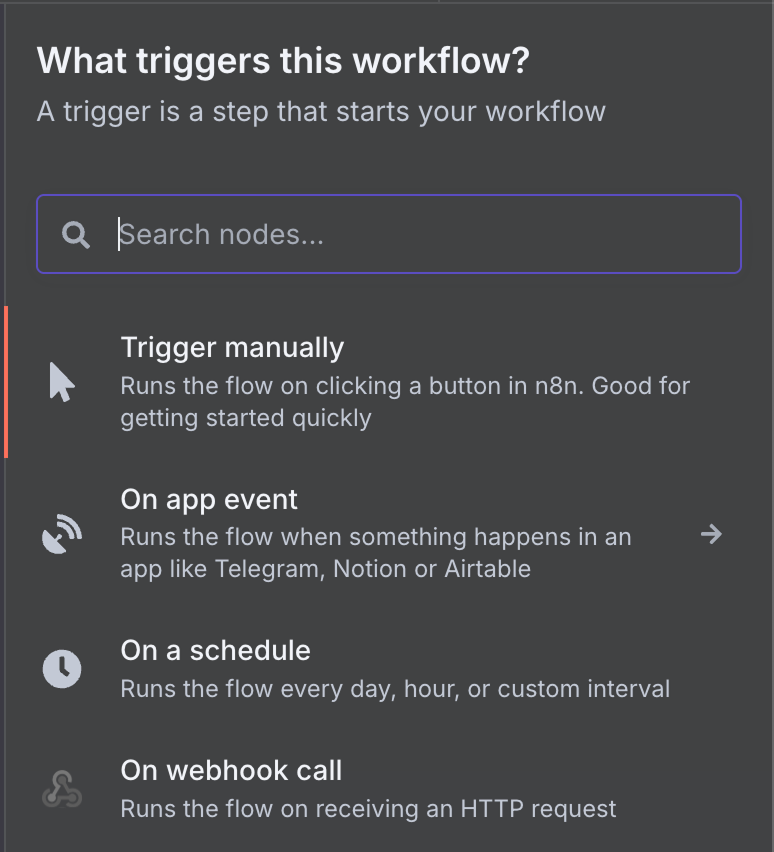
Det finns ett brett urval av möjliga trigger‑noder. Välj en Gmail‑trigger genom att skriva "gmail" i sökrutan och klicka på Gmail‑noden.
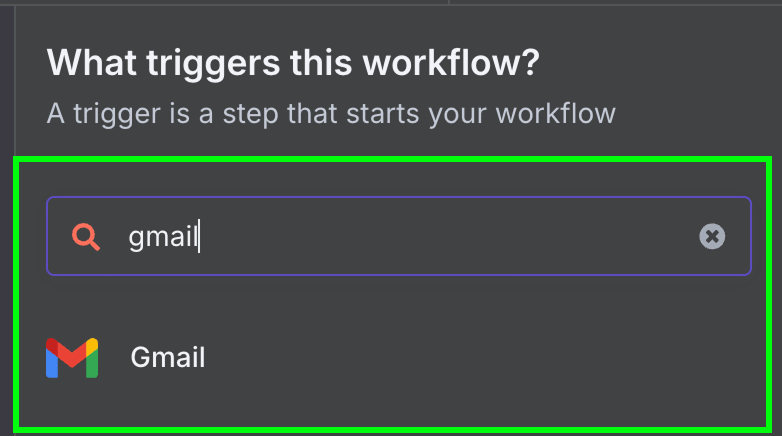
Därefter väljer vi den enda tillgängliga triggern för Gmail: "On message received".

Detta öppnar nodens konfigurationspanel, där vi behöver ställa in våra Gmail‑uppgifter för att ge n8n‑arbetsflödet åtkomst till vårt Gmail‑konto. Klicka på "New credential". Då öppnas följande fönster:
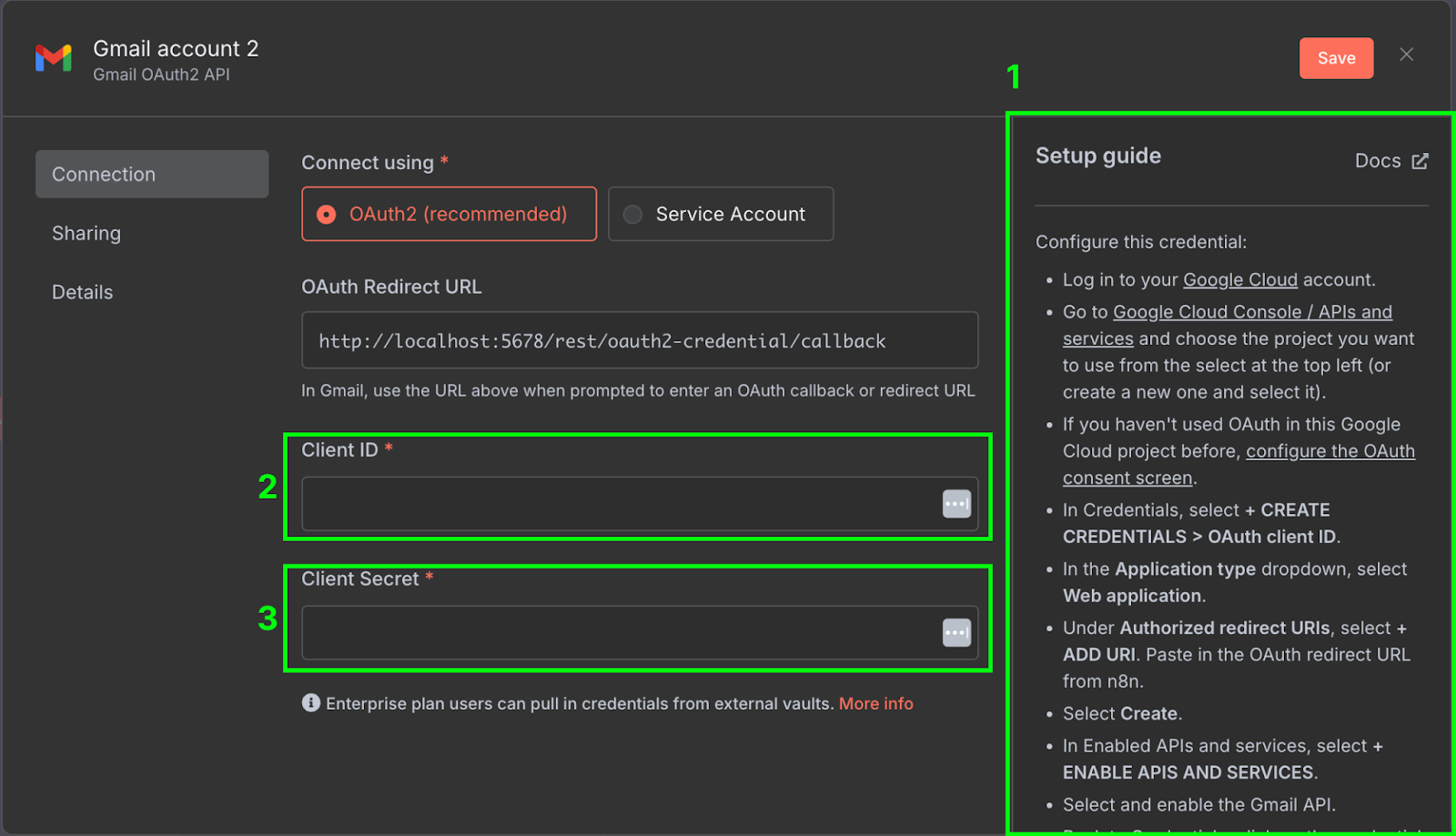
Till höger (1) finns en installationsguide som förklarar stegen för att konfigurera uppgifterna i Google Cloud. Guiderna från n8n är mycket heltäckande, så vi upprepar inte stegen här. Se till att även aktivera Gmail API i Google Cloud Console.
När allt är konfigurerat kopierar vi klient‑ID (2) och klienthemlighet (3) från Google Cloud till autentiseringsuppgifterna i n8n.
För att säkerställa att allt är korrekt konfigurerat kan vi testa noden genom att klicka på "Fetch Test Event".

Efter testet bör vi se det senaste mejlet i inkorgen i utdataavsnittet. Innehållet i mejlet finns i fältet snippet.
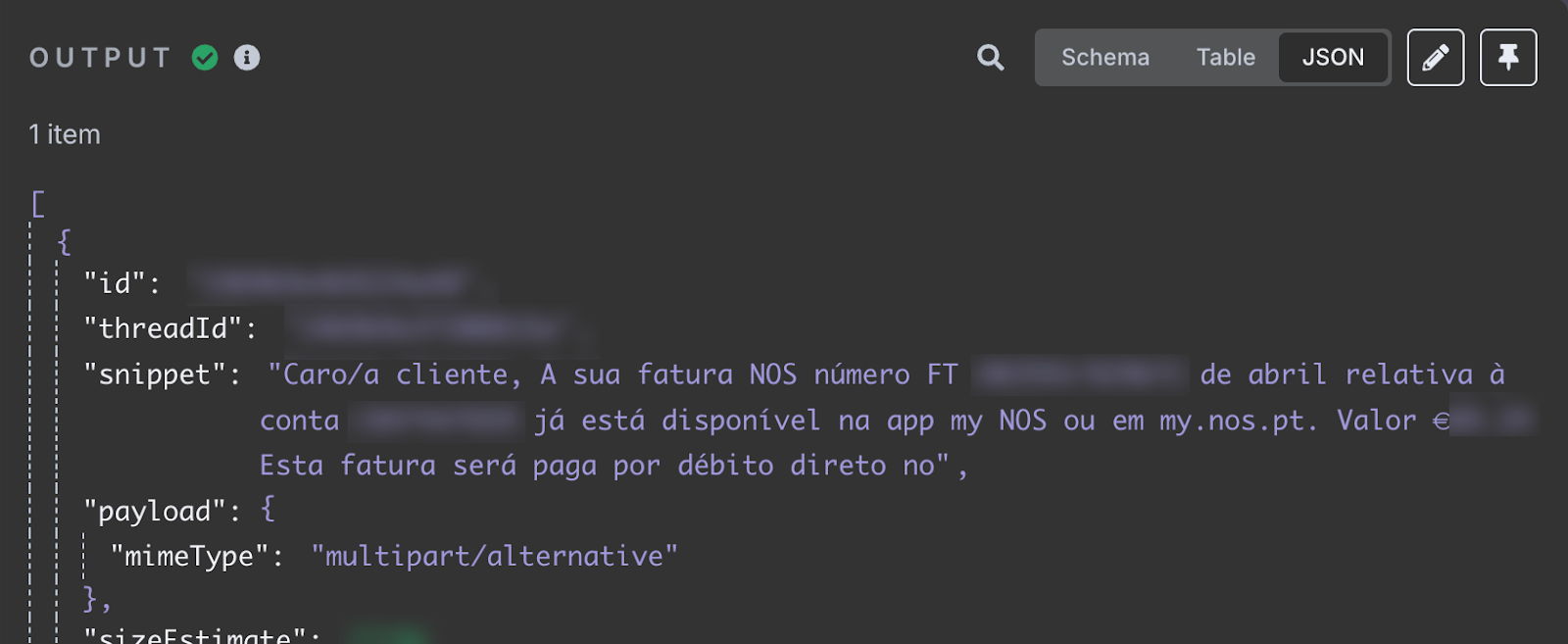
Fältet snippet lagrar mejlinnehållet. Det står att min internetfaktura för april finns tillgänglig. Det innehåller faktura‑ID och totalbelopp att betala. Det är den informationen vi vill lägga till i kalkylarket.
För teständamål rekommenderar jag att fästa utdatat genom att klicka på knappnålen uppe till höger:
Detta låser resultatet till triggern, vilket innebär att varje gång vi kör arbetsflödet används samma utdata. Det gör det enklare att testa, eftersom resultatet inte påverkas av nya mejl som kan komma in. Vi avfäster det när arbetsflödet är korrekt uppsatt.
I det här skedet bör vårt arbetsflöde ha en enda trigger‑nod (vi ser att det är en trigger‑nod tack vare den lilla blixtsymbolen till vänster).

Observera att eftersom du sannolikt inte har en faktura i din inkorg kommer ChatGPT senare troligen att ge ett svar som inte är vettigt. Om du vill testa just det här arbetsflödet kan du skicka ett testmejl till dig själv med följande innehåll (eller något liknande):
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.Efter att du skickat detta måste du avfästa resultatet, köra Gmail‑noden igen och fästa det nya resultatet.
Nästa steg är att konfigurera OpenAI‑noden. Börja med att klicka på "+"‑knappen till höger om Gmail‑triggernoden:

Skriv "OpenAI" och välj motsvarande alternativ i listan.
Välj sedan under "Text Actions" noden "Message a model". Denna nod används för att skicka meddelanden till en LLM.

Precis som tidigare behöver vi skapa autentiseringsuppgifter för att komma åt OpenAI. När en uppsättning uppgifter väl är skapad kan den återanvändas i alla arbetsflöden. Vi behöver inte ställa in den varje gång.
För OpenAI‑uppgifterna behöver vi bara en API‑nyckel. Om du inte har en kan du skapa en här. Om du stöter på problem har n8n även en guide för detta.
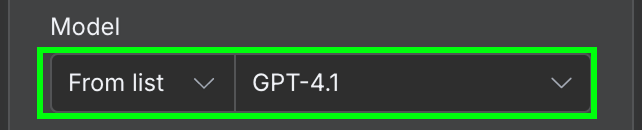
I konfigurationen behöver vi välja AI‑modellen vi vill använda och meddelandet vi skickar till modellen.
För modellen använder vi GPT‑4.1. OpenAI har sedan släppt GPT‑5‑familjen (5.4, 5.4‑mini, 5.5) och fasat ut 4.1 från ChatGPT, men den finns fortfarande tillgänglig via API:t och räcker gott för enkel extraktion som detta.
I meddelandefältet behöver vi ange prompten. I detta exempel ger vi modellen innehållet i mejlet och ber den identifiera faktura‑ID och totalbelopp att betala. Här är prompten jag använde:
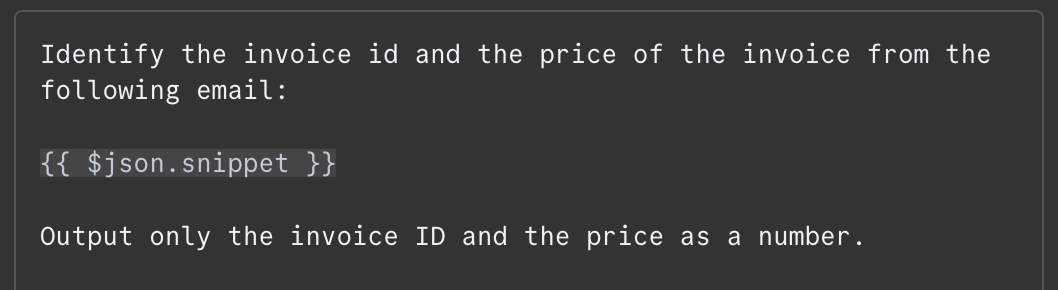
Innehållet i mejlet tillhandahålls som {{ $json.snippet }}. I n8n kan prompten innehålla variabler som fylls med utdata från tidigare noder, i vårt fall mejlet. Listan över tillgängliga fält visas till vänster. Vi kan skriva in fältet manuellt eller dra och släppa det i prompten.
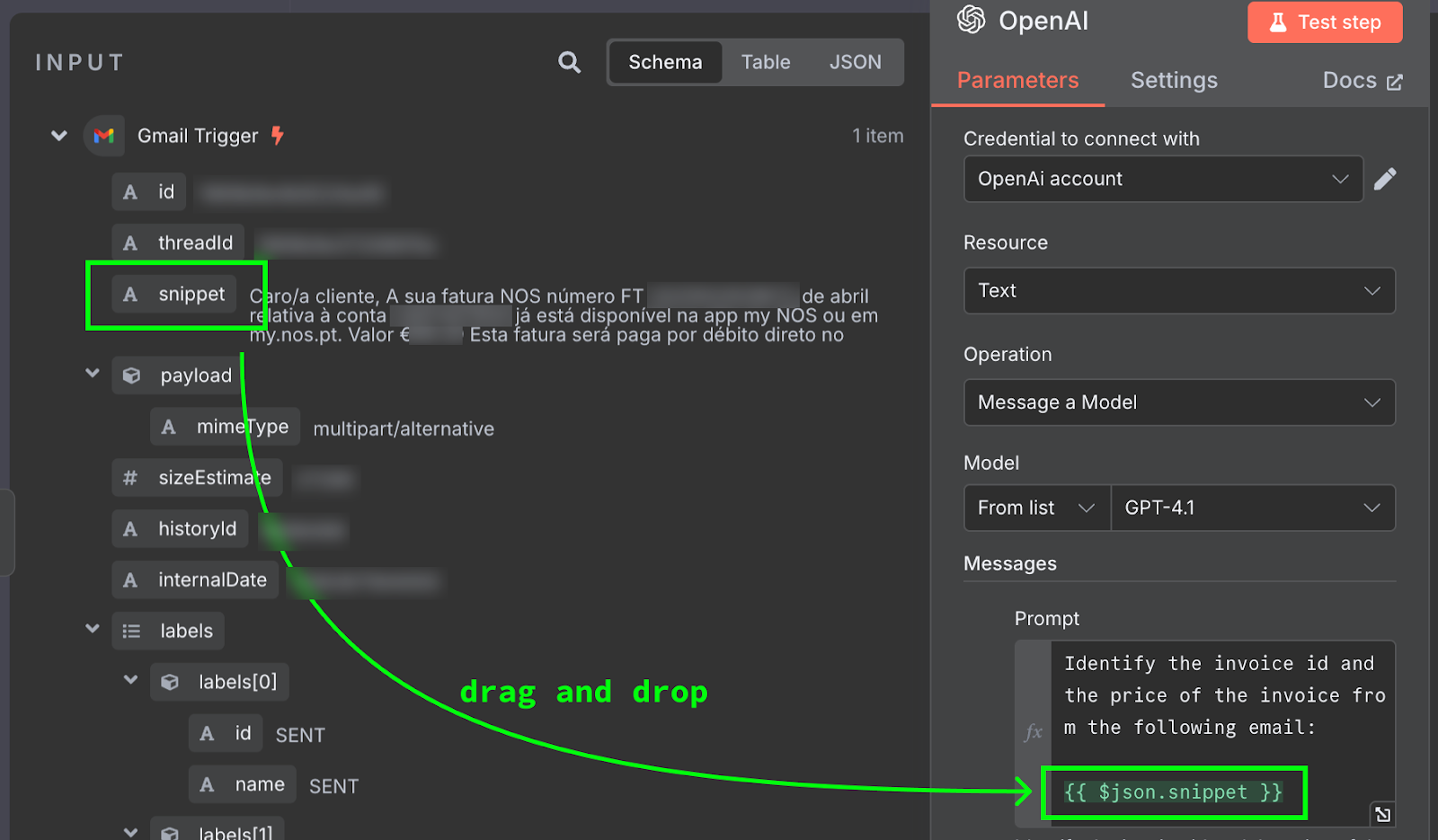
För att testa detta klickar vi på knappen "Test Step" högst upp i konfigurationspanelen. Resultatet visas till höger:
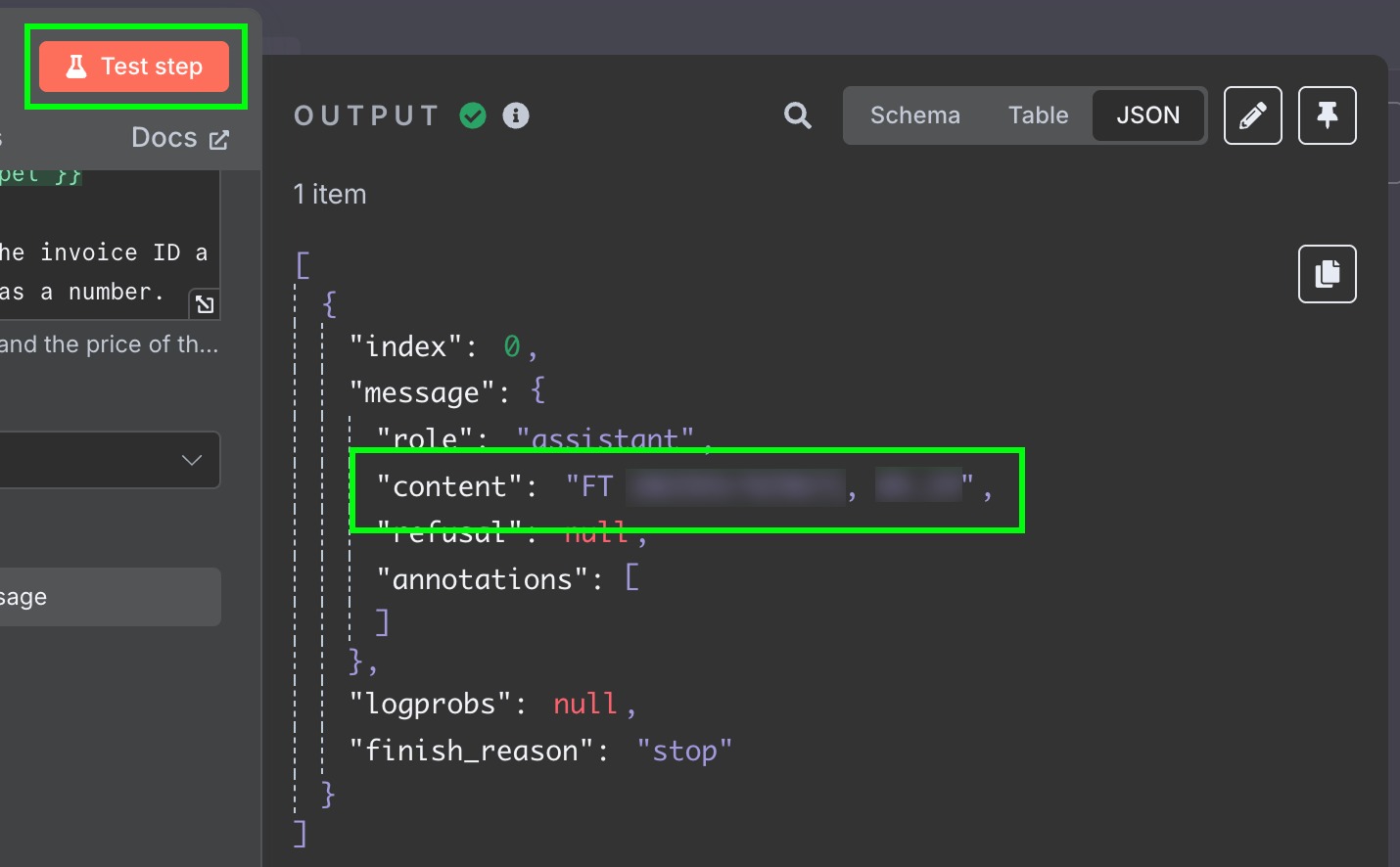
Resultatet är en sträng med modellens svar. Vi vill gärna ha de två fälten separat, så att vi slipper efterbehandla meddelandet. Det kan vi åstadkomma genom att ändra LLM:ens utdata till JSON:

Testar vi detta steg igen får vi de två fälten som JSON‑data:
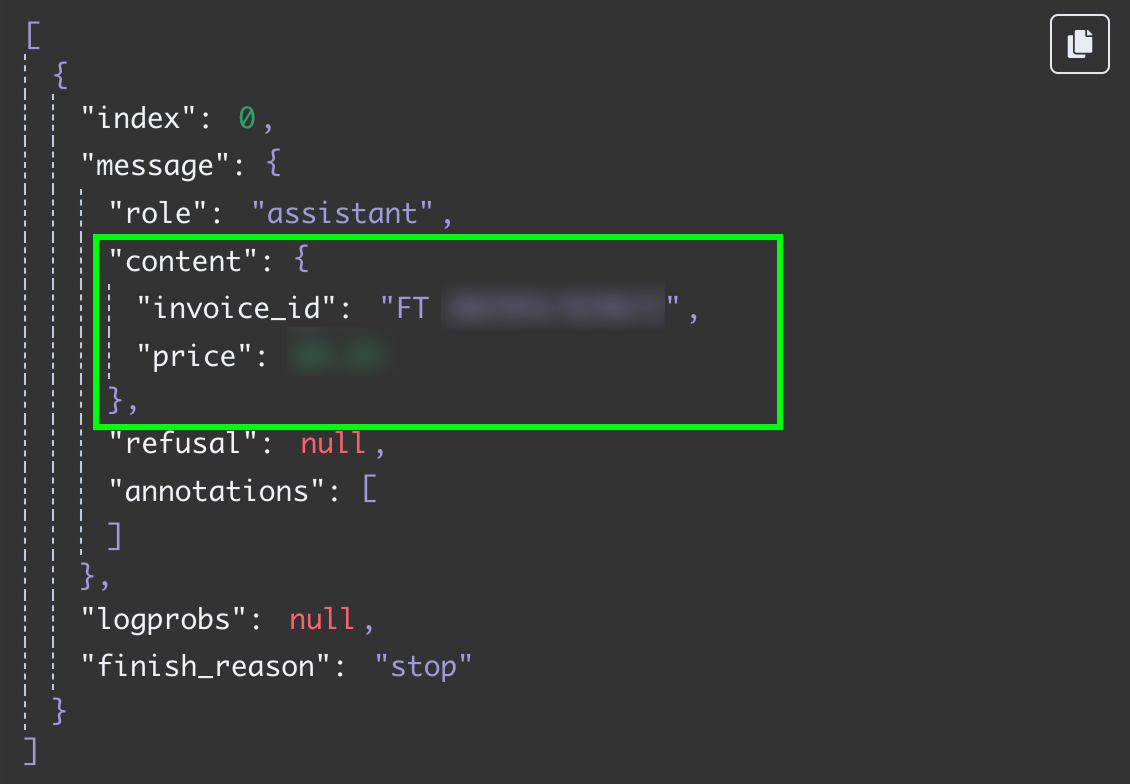
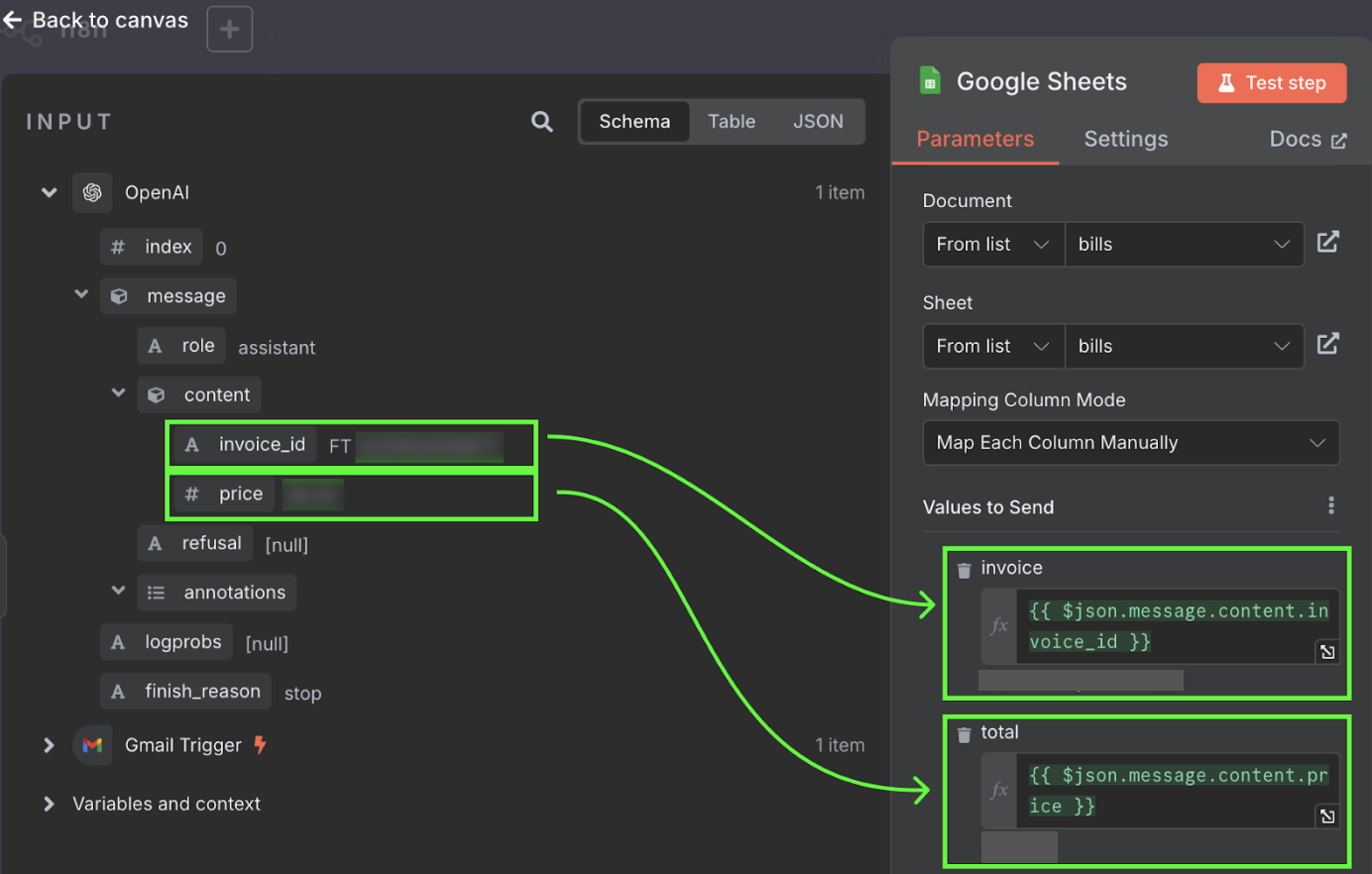
Det sista steget i detta arbetsflöde är att skicka faktura‑ID och belopp till en ny rad i ett Google‑kalkylark. Nu behöver vi koppla utdata från OpenAI‑noden till Google Sheets. Det gör vi som tidigare genom att klicka på "+"‑knappen till vänster om noden:
Här vill vi skriva Google Sheets och välja noden "Append row in sheet":
Vi kan använda samma uppgifter som vi använde för Gmail‑åtkomst. Men vi måste aktivera följande API:er i Google Cloud Console:
För att konfigurera Google Sheets‑noden behöver vi välja bladet och välja vilka värden som ska fylla fälten. Bladet ska skapas manuellt med två kolumner, en för faktura‑ID och en för fakturabelopp.
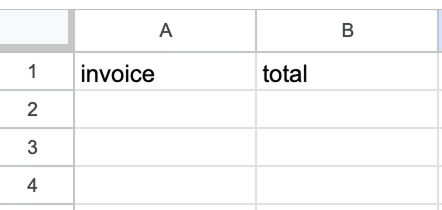
Dessa värden hämtas från utdata från OpenAI‑noden. Vi kan dra och släppa dem i kolumnerna.
Klart! Vi har ett arbetsflöde som automatiskt kommer att föra in våra fakturor i ett Google‑kalkylark. Vi kan testa det genom att klicka på "Test workflow" längst ned:
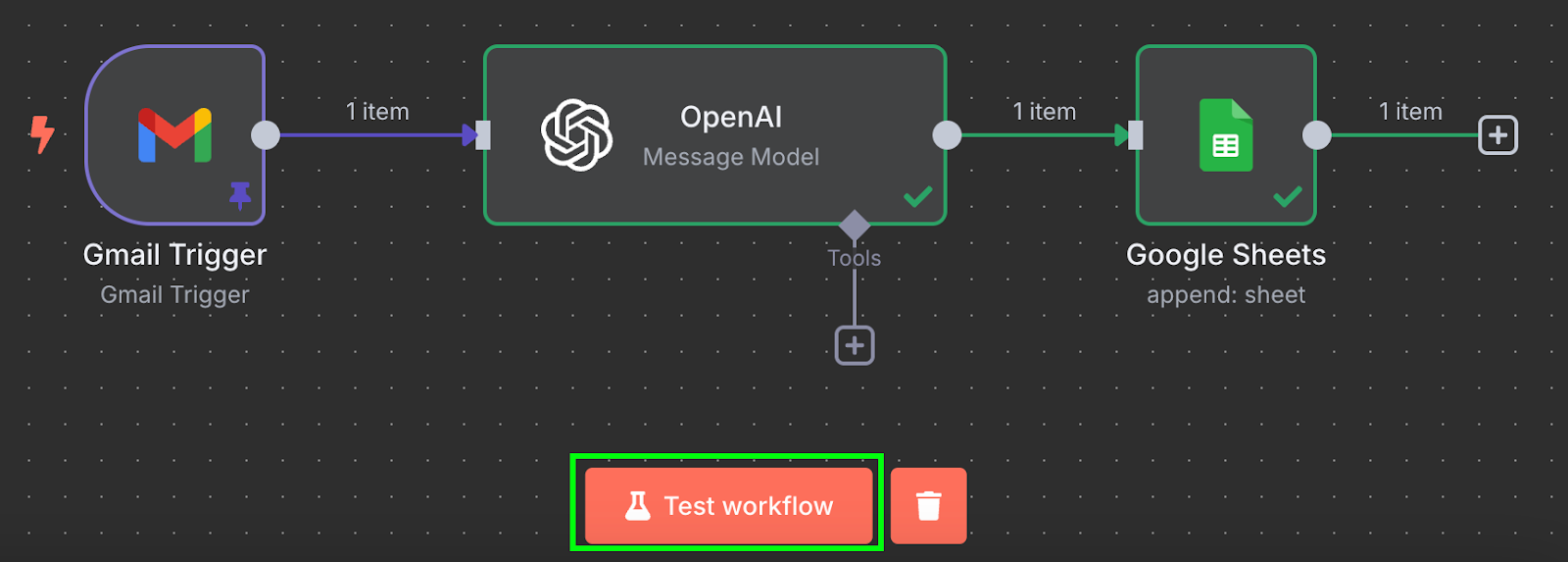
Efter körning, om vi går till vårt kalkylark i Google Sheets, ser vi en ny rad med data:
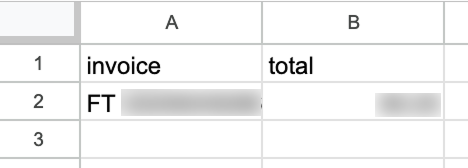
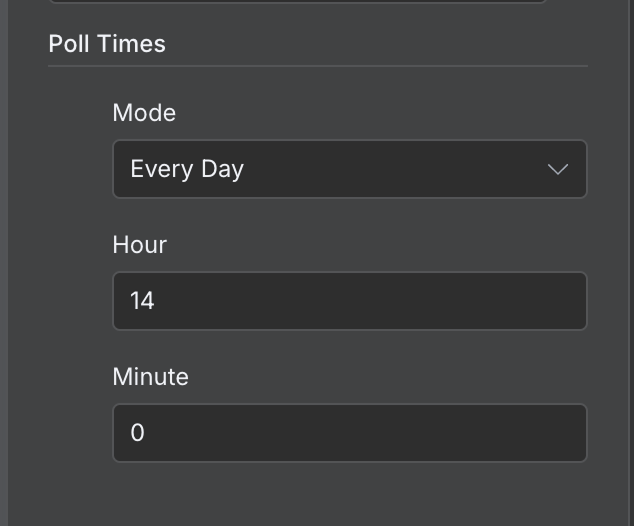
Som standard körs ett arbetsflöde varje minut. Beroende på arbetsflöde bör vi ställa in en lämplig körfrekvens. I just detta exempel är en gång per minut alldeles för ofta. En gång per dag är mer rimligt.
Det ställer vi in genom att dubbelklicka på trigger‑noden och sätta ett annat värde i fältet "Poll Times":
I denna del bygger vi ett mer komplext RAG‑agentarbetsflöde. RAG står för retrieval‑augmented generation, en teknik som kombinerar hämtning av relevant information från en databas eller ett dokument med att sedan använda en språkmodell för att generera svar baserat på den hämtade informationen.
Detta är mycket användbart när vi har en specifik kunskapsbas, till exempel ett långt textdokument, och vill bygga en AI‑agent som kan svara på frågor om det.
Jag gillar att spela brädspel, men mina vänner och jag hamnar ofta i diskussioner om reglerna och lägger sedan tid på att leta efter rätt regler i stället för att spela, vilket kan vara frustrerande. Att bygga en RAG‑agent baserad på spelets regler är en bra lösning på problemet, eftersom vi nästa gång vi har en fråga bara kan fråga agenten.
För att bygga denna agent gör vi två arbetsflöden:
Pinecone är en typ av databas som hanterar data i form av vektorer. En vektordatabas som Pinecone är utmärkt för vår RAG‑agent eftersom den hjälper agenten att snabbt slå upp och förstå relevant information, vilket gör den mer effektiv på att ge korrekta svar.
Eftersom vi bara behöver köra detta arbetsflöde en gång kan vi använda en manuell trigger‑nod. Det är en trigger‑nod som används för att köra ett arbetsflöde manuellt.
Koppla den manuella triggern till en "Google Drive"‑nod för att ladda ner data från Google Drive.

Använd följande konfiguration:
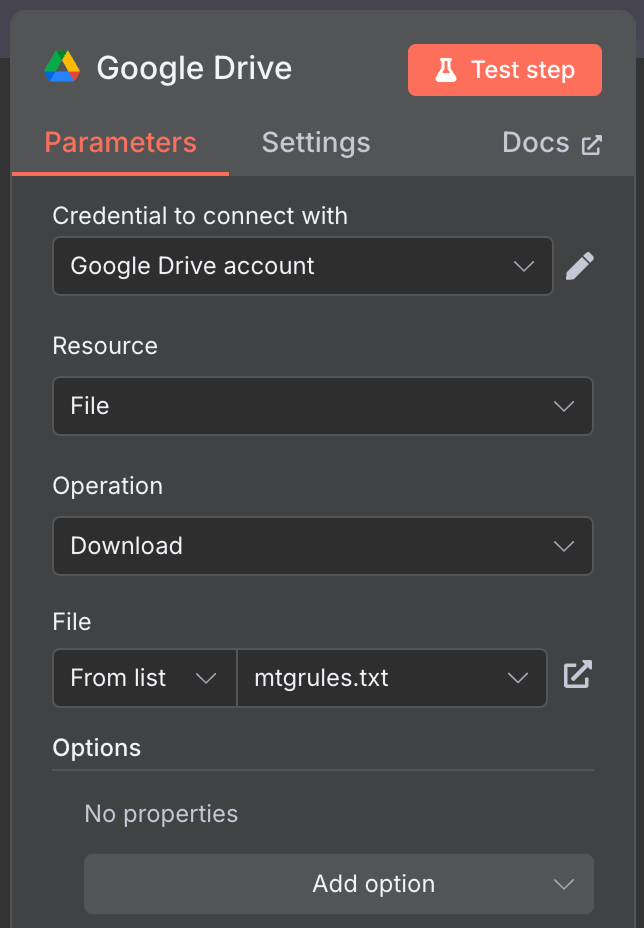
Jag använde den publikt tillgängliga filen mtgrules.txt med reglerna för samlarkortspelet Magic: The Gathering. Du kan använda valfri fil du vill ställa frågor om; arbetsflödet är detsamma.
För att konfigurera Pinecone, logga in på Pinecone, kopiera API‑nyckeln och skapa ett index genom att klicka på knappen "Create index". Jag kallade mitt index rules och valde modellen text-embedding-3-small.

Tillbaka i n8n, koppla utdata från Google Drive‑noden till en Pinecone Vector Store‑nod med åtgärden "Add documents to vector store":
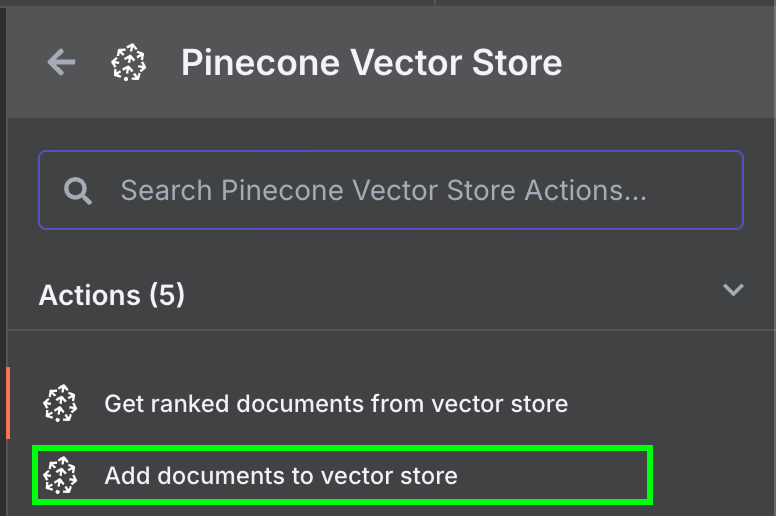
För att konfigurera noden skapar vi autentiseringsuppgifter genom att klistra in API‑nyckeln och välja Pinecone‑indexet vi nyss skapade. Under Pinecone Vector Store‑noden ser vi två saker vi behöver konfigurera: en embeddings‑modell och en data‑laddare.
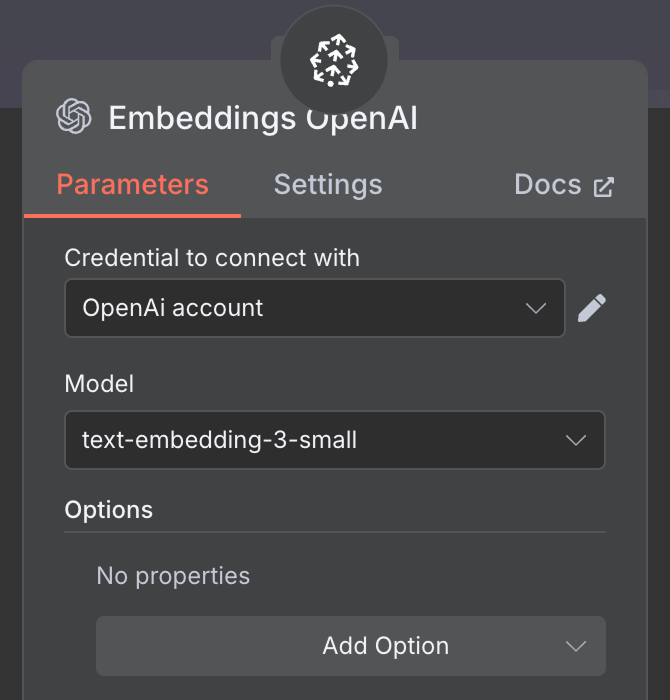
För embeddings skapar vi en OpenAI Embedding‑nod med modellen text-embedding-3-small:
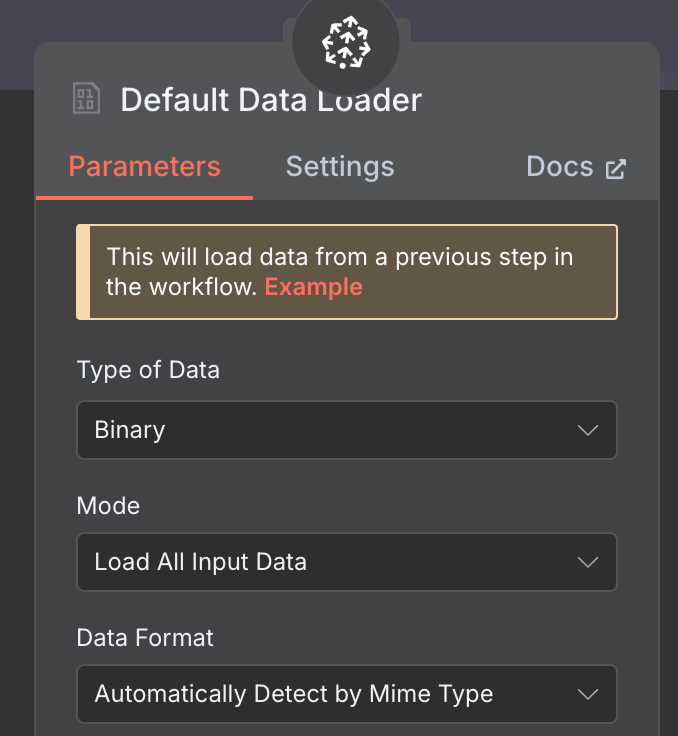
För data‑laddaren skapar vi en Default Data Loader‑nod med binär datatyp:
Slutligen kräver data‑laddaren en Text Splitter‑nod, som anger hur filens data ska delas upp när vektorlagret skapas. Vi använder Recursive Character Text Splitter‑noden, som rekommenderas för de flesta tillämpningar.
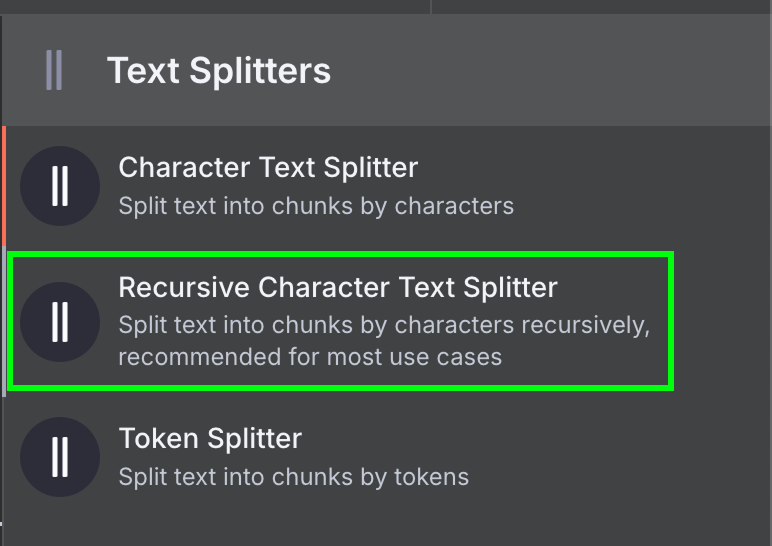
Vi konfigurerar den med chunk‑storlek 1 000 och överlappning 200:
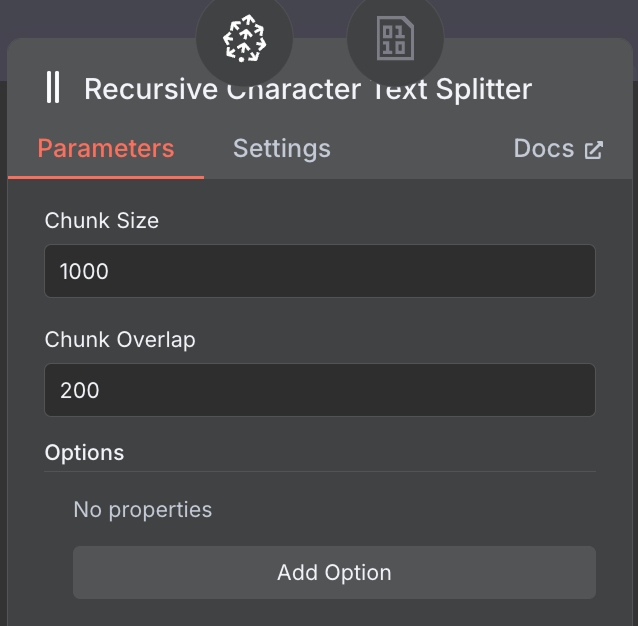
När du väljer chunk‑storlek och överlappning, överväg att använda större chunk‑storlek för långa dokument för att få med tillräckligt med innehåll och mindre överlappning för att bevara kontext mellan segment utan onödig upprepning.
Så här ser det slutliga arbetsflödet ut:
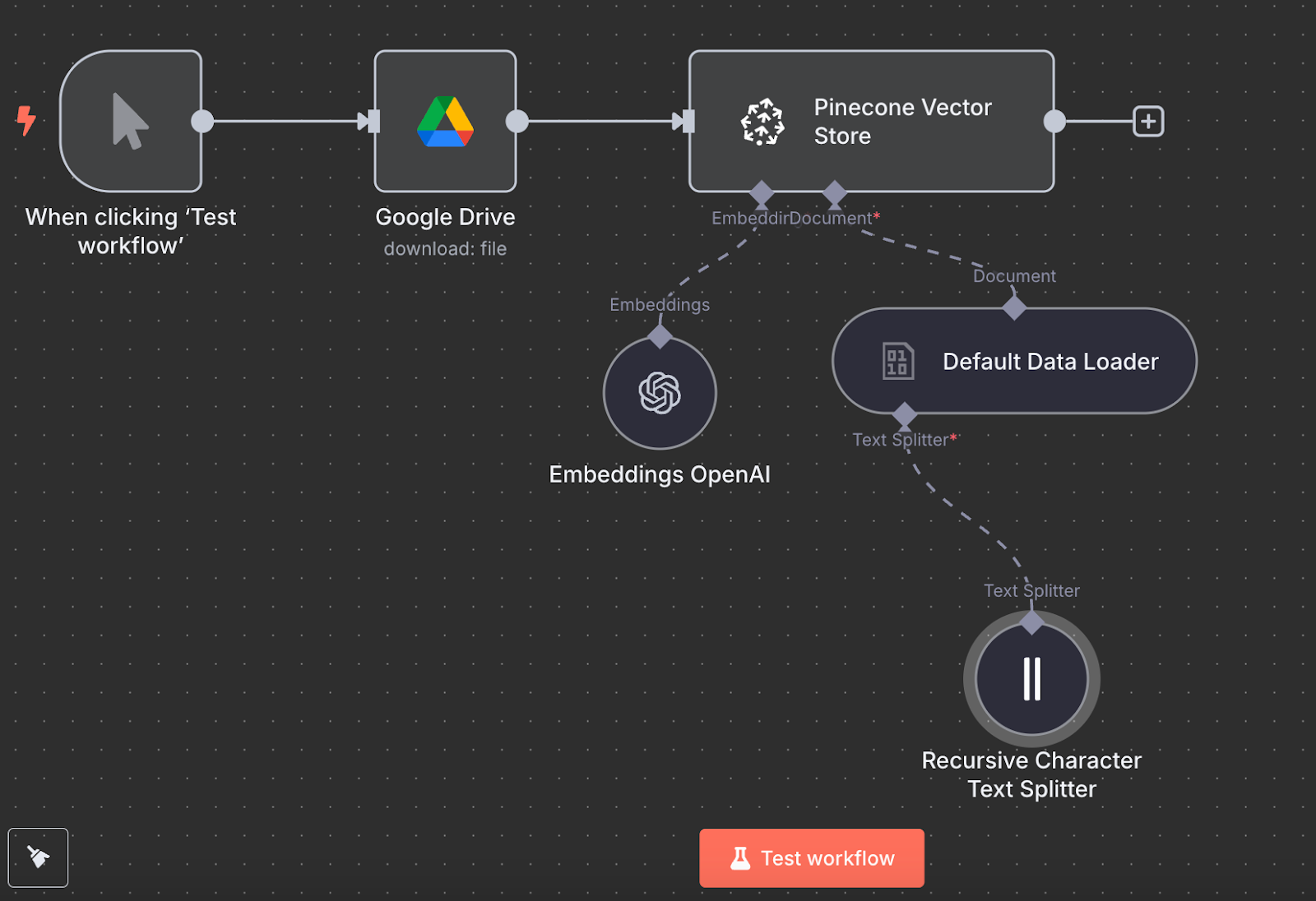
Vi kan köra det genom att klicka på "Test workflow", och när det är klart kan vi verifiera i Pinecone att data har laddats.
Här är det slutliga schemat för RAG‑agenten:
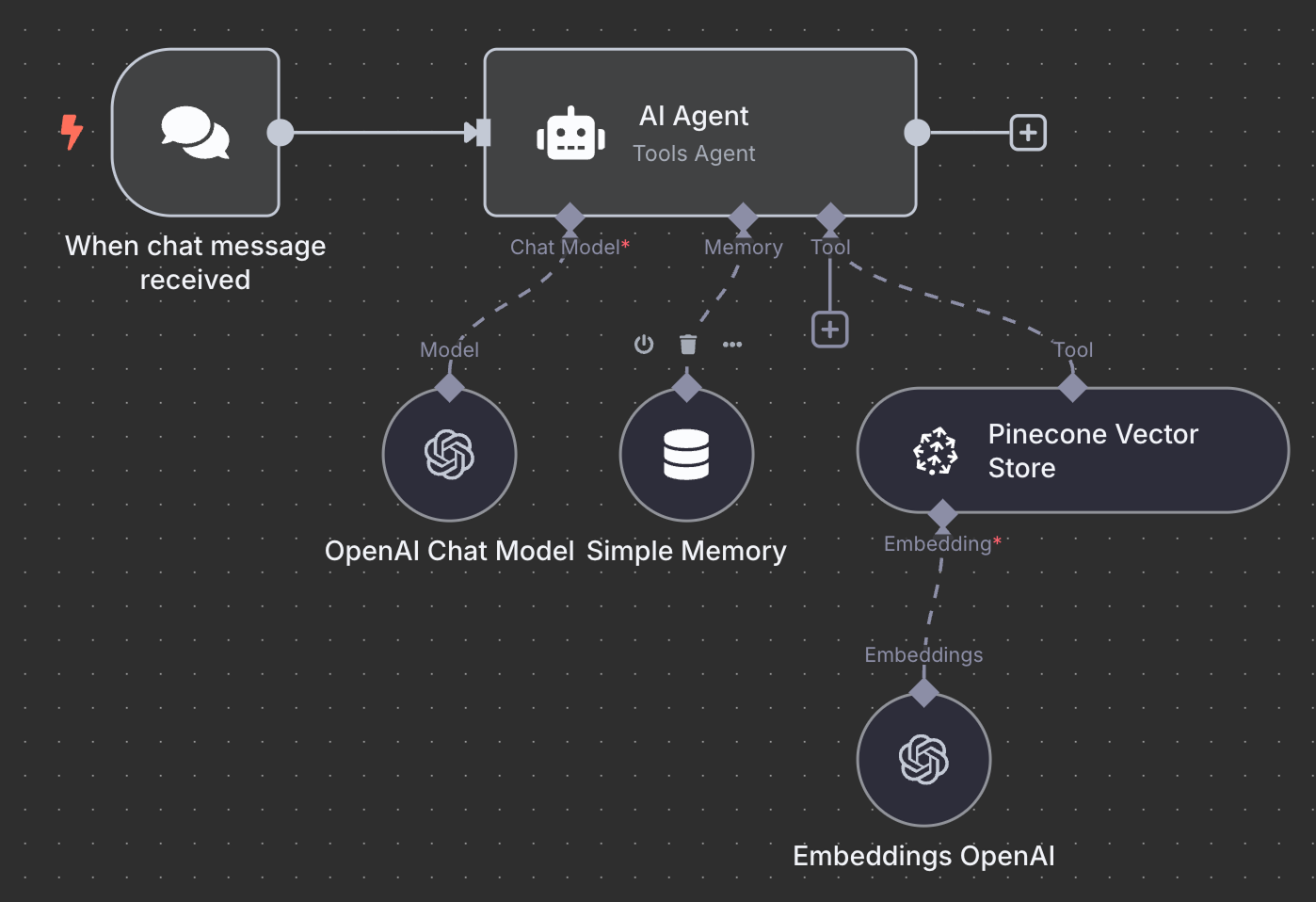
Som en övning uppmuntrar jag dig att försöka förstå det och kanske till och med återskapa det lokalt själv innan du läser vidare.
Vi börjar med en "On chat message"‑trigger. Den används för att skapa ett chattarbetsflöde.
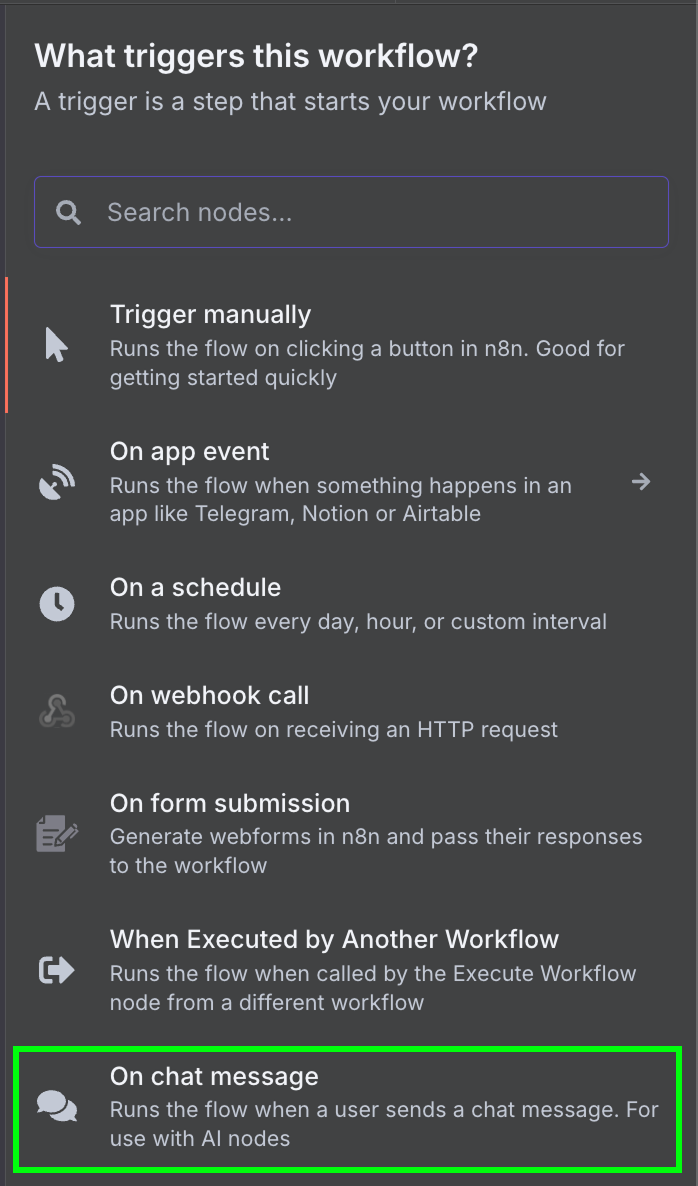
Sedan kopplar vi chattriggern till en "AI Agent"‑nod med standardinställningarna.
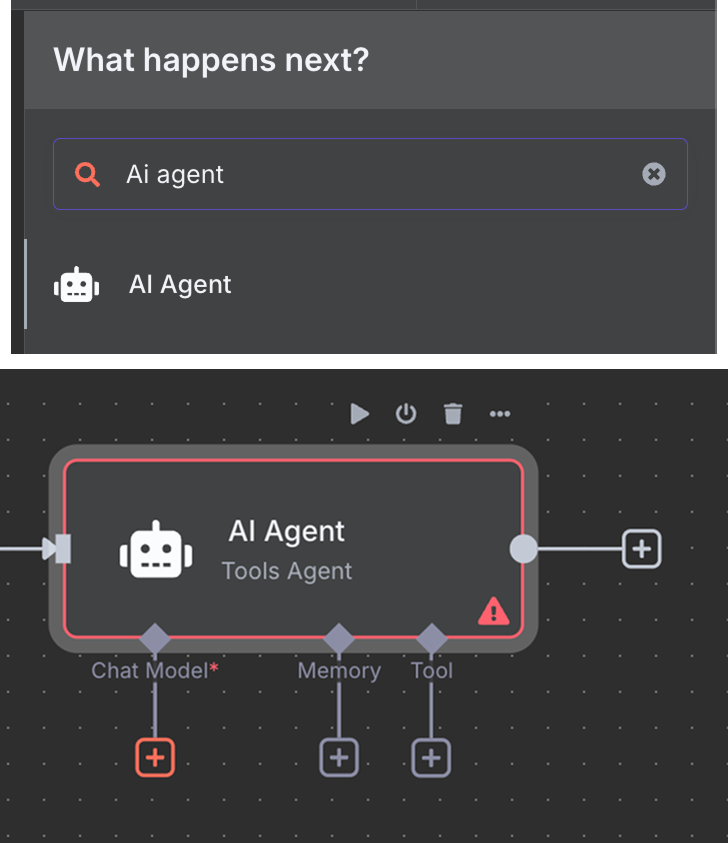
Under AI Agent ser vi att vi kan konfigurera tre saker:
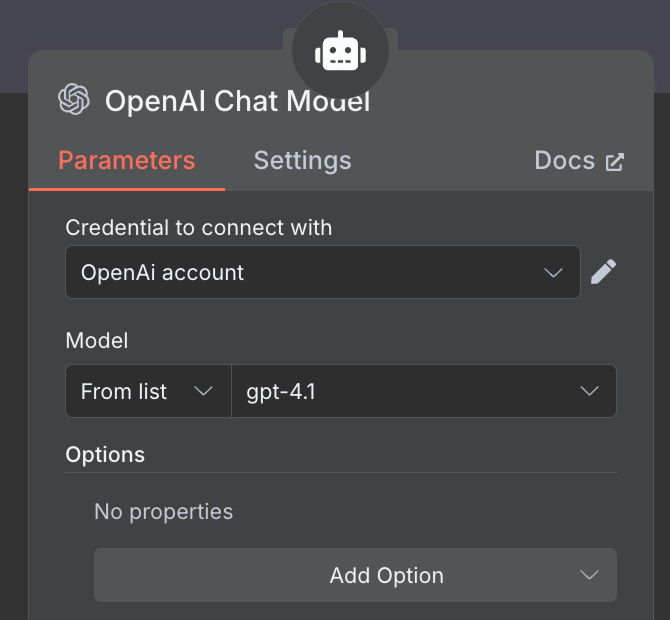
För AI‑modellen väljer vi en "OpenAI Chat Model"‑nod och använder GPT‑4.1, precis som tidigare. GPT‑5‑familjen är OpenAI:s nuvarande modellfamilj, men 4.1 har ett kontextfönster på 1M tokens och passar RAG väl.
För minnet använder vi en "Simple Memory"‑nod med ett kontextfönster på 5. Det betyder att agenten kommer att minnas och beakta de fem föregående interaktionerna när den svarar.
Slutligen lägger vi till ett "Pinecone Vector Store"‑verktyg med följande konfiguration:
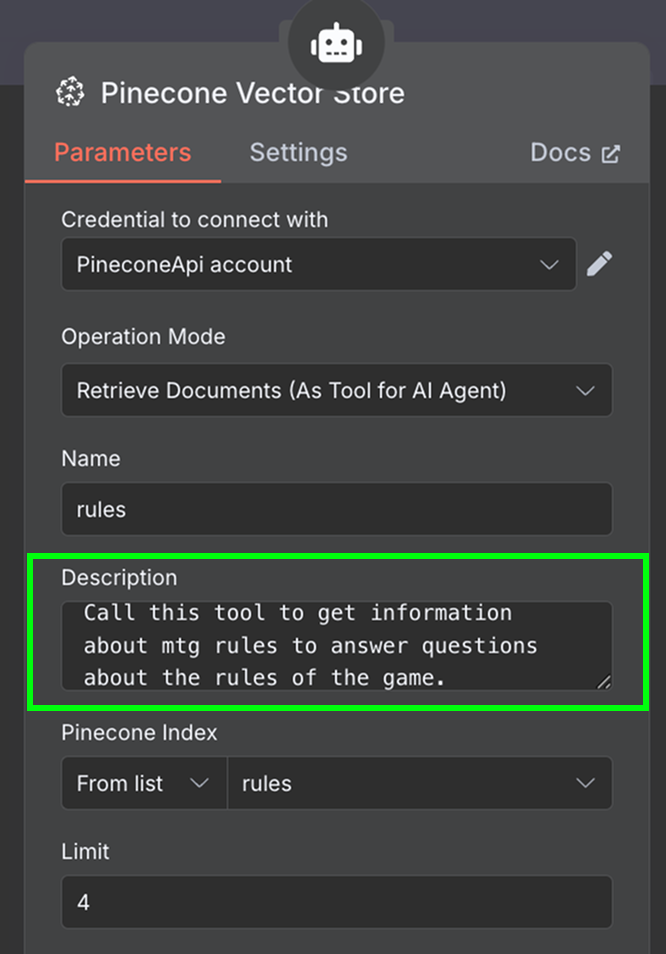
I beskrivningsfältet är det viktigt att ange när verktygen ska användas. Det är utifrån detta agenten avgör om den ska anropa verktyget.
Det sista vi behöver är att konfigurera embeddings som används av vektorlager. Precis som tidigare använder vi en OpenAI Embedding‑nod med modellen text-embedding-3-small:
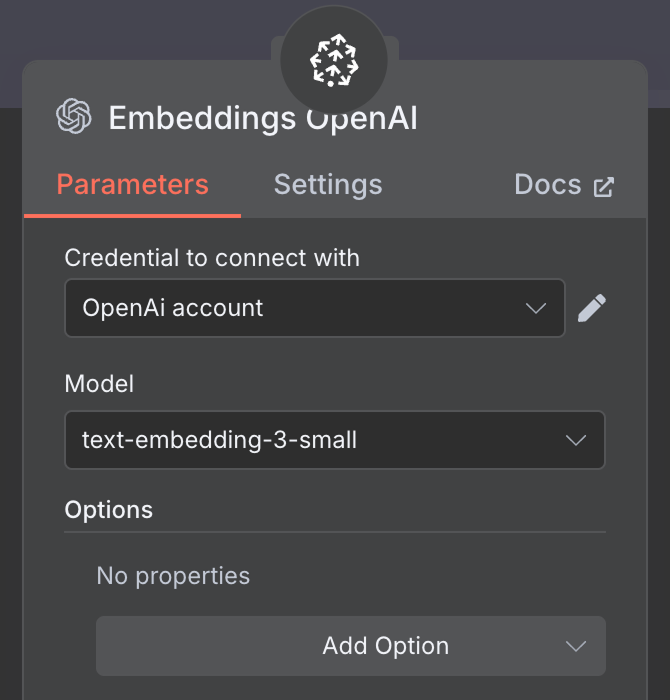
Arbetsflödet är klart, och vi kan chatta med agenten. Här är ett exempel:
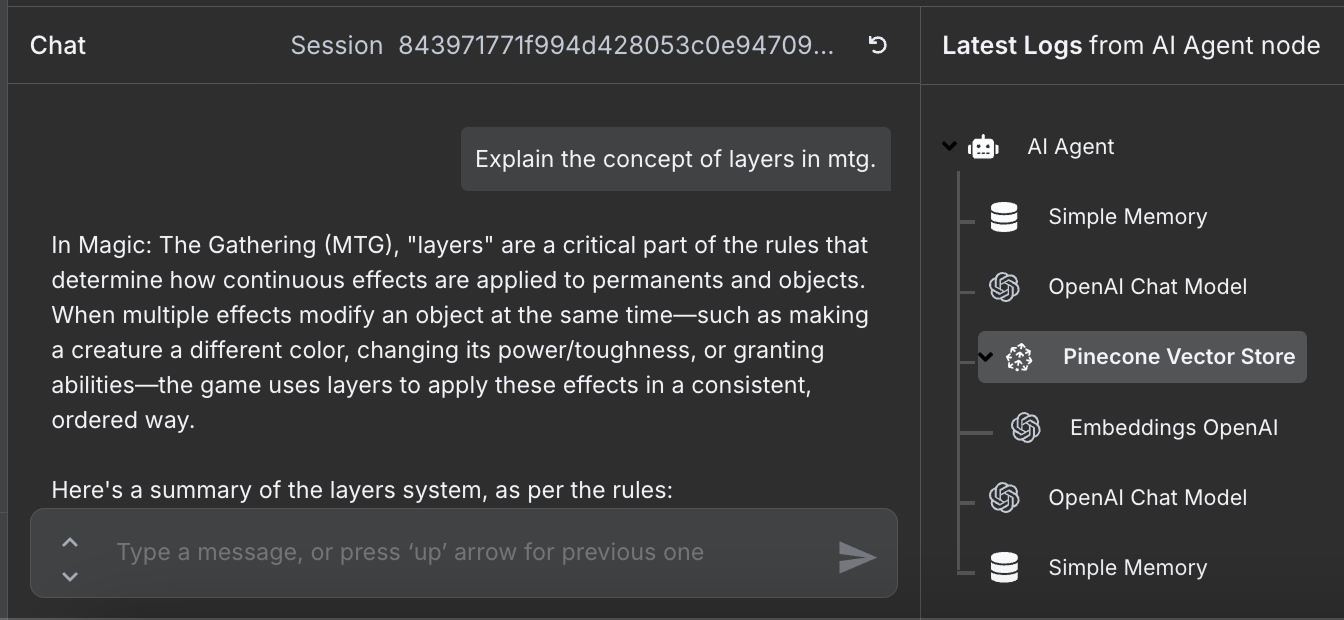
Till höger kan vi se stegen agenten tog för att svara på vår fråga. Särskilt att den gick till Pinecone‑databasen för att hämta relevant information om reglerna.
n8n erbjuder en användbar funktion som kan påskynda skapandet av våra arbetsflöden avsevärt: n8n:s mallbibliotek.
Detta bibliotek är en samling förbyggda arbetsflöden, skapade av communityn och n8n‑experter. Oavsett om vi försöker automatisera enkla uppgifter eller mer komplexa processer är chansen stor att någon redan har byggt ett arbetsflöde som passar våra behov.
Genom att importera ett arbetsflöde i vår n8n‑miljö behöver vi inte alltid börja från noll. I stället kan vi dra nytta av de kreativa lösningar som andra användare utvecklat. När vi väl importerat ett arbetsflöde behöver vi bara konfigurera det med våra uppgifter och justera det så att det passar våra exakta krav.
För vilken uppgift vi än vill automatisera, från e‑posthantering till sociala medier, är det mycket troligt att det finns en mall i biblioteket.
n8n erbjuder ett enormt ekosystem av integrationer och låter oss koppla ihop över tusen tjänster och verktyg för att skapa AI‑agenter. Vi har bara skrapat på ytan av vad n8n kan göra i den här guiden. Genom att utforska hur man använder n8n för att bygga AI‑agenter som automatiserar vardagliga uppgifter har vi bara börjat utnyttja dess potential.
Lär dig AI med de här kurserna!
track
course
course