Track
Разработка приложений ИИ
21 ч
n8n стал популярным и мощным фреймворком в сфере агентного ИИ. Он позволяет строить автоматизированные рабочие процессы без сложного программирования.
В этой статье я шаг за шагом покажу, как максимально эффективно использовать эту платформу, чтобы автоматизировать два разных процесса:
Мы держим читателей в курсе последних событий в ИИ через The Median — нашу бесплатную еженедельную рассылку по пятницам, где мы разбираем ключевые новости недели. Подпишитесь и оставайтесь в тонусе, уделяя всего несколько минут в неделю:
n8n — это инструмент автоматизации с открытым исходным кодом, который помогает соединять разные приложения и сервисы для создания рабочих процессов — своего рода цифрового конвейера. Пользователи могут визуально проектировать такие процессы с помощью узлов, каждый из которых представляет отдельный шаг.
С n8n можно автоматизировать задачи, управлять потоками данных и даже интегрировать API — и при этом не нужны глубокие навыки программирования. Вот пример автоматизации, которую мы соберём в этом руководстве:
Не вдаваясь в подробности, вот что делает эта автоматизация:
У нас есть два варианта использования n8n:
Оба варианта позволяют пройти это руководство без затрат. Мы запустим локально, но если вам удобнее веб-интерфейс — шаги те же.
Примечание: n8n 2.0 вышел в конце 2025 года и принёс систему черновиков/публикаций, автосохранение (январь 2026), обновлённую панель фокуса для редактирования узлов без потери контекста холста и Task Runners, изолирующие выполнение рабочих процессов для повышения безопасности.
Приведённые ниже рабочие процессы запускаются на версии 2.x — если вы на 1.x, подумайте об обновлении перед тем, как продолжать.
Официальный репозиторий n8n описывает, как настроить n8n локально. Проще всего сделать так:
Скачать и установить Node.js с официального сайта.
Открыть терминал и выполнить команду npx n8n.
Готово! После запуска команды вы должны увидеть в терминале следующее:
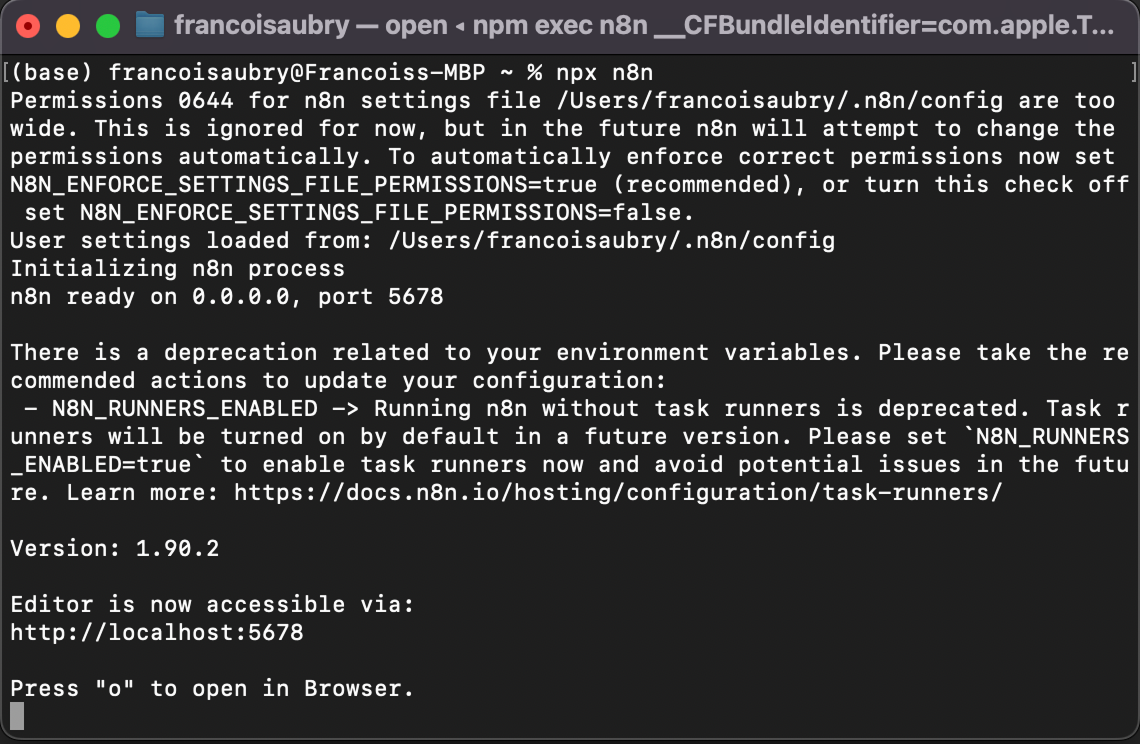
Чтобы открыть интерфейс, нажмите «o» на клавиатуре или откройте адрес localhost, показанный в терминале — в моём случае это http://localhost:5678.
Прежде чем собирать первую автоматизацию, полезно понять принцип работы n8n. Рабочий процесс в n8n — это последовательность узлов. Он начинается с триггер-узла, задающего условие запуска процесса.
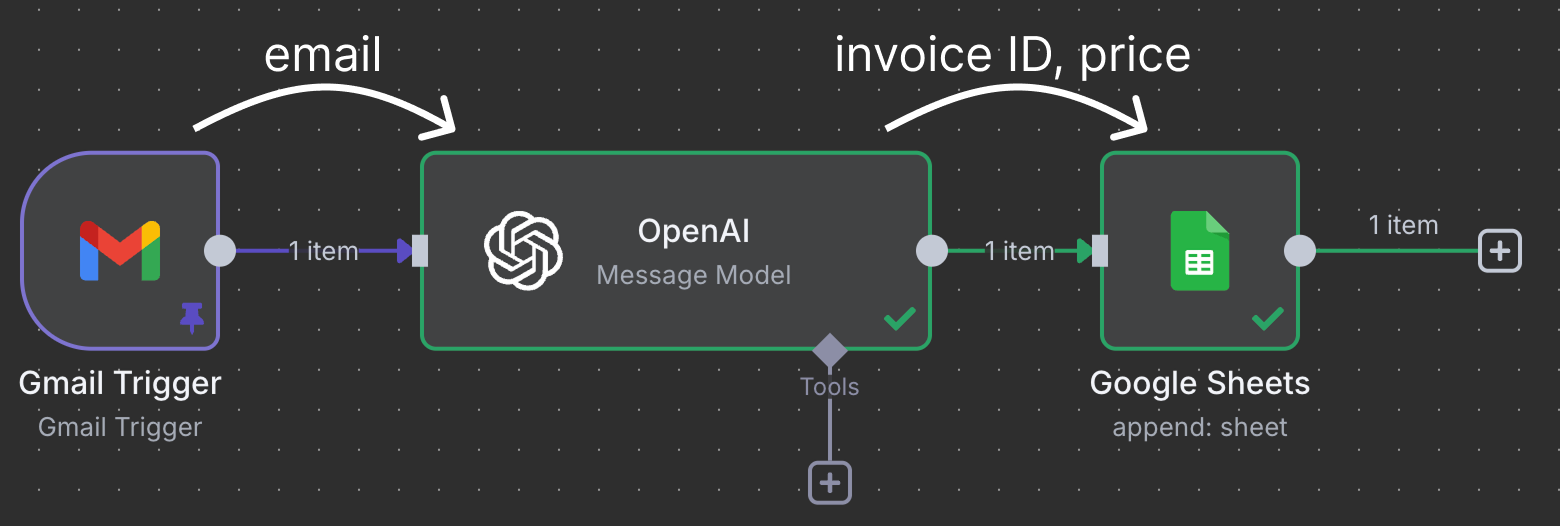
Узлы соединяются между собой, чтобы передавать и обрабатывать данные. В этом примере триггер Gmail подключается к узлу OpenAI. Это означает, что письмо передаётся в ChatGPT на обработку. Наконец, результат ChatGPT отправляется в узел Google Sheet, который подключается к таблице на Google Drive и записывает новую строку.
Этот конкретный процесс использует ChatGPT, чтобы находить счета к оплате, и добавляет в таблицу строку с ID счёта и суммой.
Рабочие процессы n8n могут быть куда сложнее. n8n поддерживает более 400 официальных интеграций (основных узлов), свыше 600 узлов от сообщества и собственные подключения через узел HTTP Request — так что в одном руководстве их не охватить.
Вместо этого я дам общее представление о принципах работы и необходимую базу, чтобы вы могли исследовать его самостоятельно. Если есть инструмент, которым вы часто пользуетесь, велика вероятность, что n8n его поддерживает или вы сможете подключить его вручную.
В этом разделе мы соберём рабочий процесс, показанный выше.
Это реальный кейс, который я использую для управления своими коммунальными счетами по аренде. У меня есть дом с несколькими комнатами, которые я сдаю. Счета делятся поровну между всеми жильцами. Каждый раз, получая счёт, мне нужно добавить итоговую сумму в таблицу, которой мы делимся с жильцами.
У меня есть отдельный адрес, на который пересылаются счета по дому. Так я знаю, что все письма в этом ящике — это счета. Содержимое письма я отправляю в ChatGPT, чтобы он определил ID счёта и итоговую сумму. Затем эта информация добавляется новой строкой в общую таблицу.
Чтобы создать новый рабочий процесс, нажмите кнопку «Add first step...».

Поскольку это первый узел, он должен быть триггером, поэтому откроется панель выбора узла-триггера. Триггер-узел задаёт условия для запуска процесса.
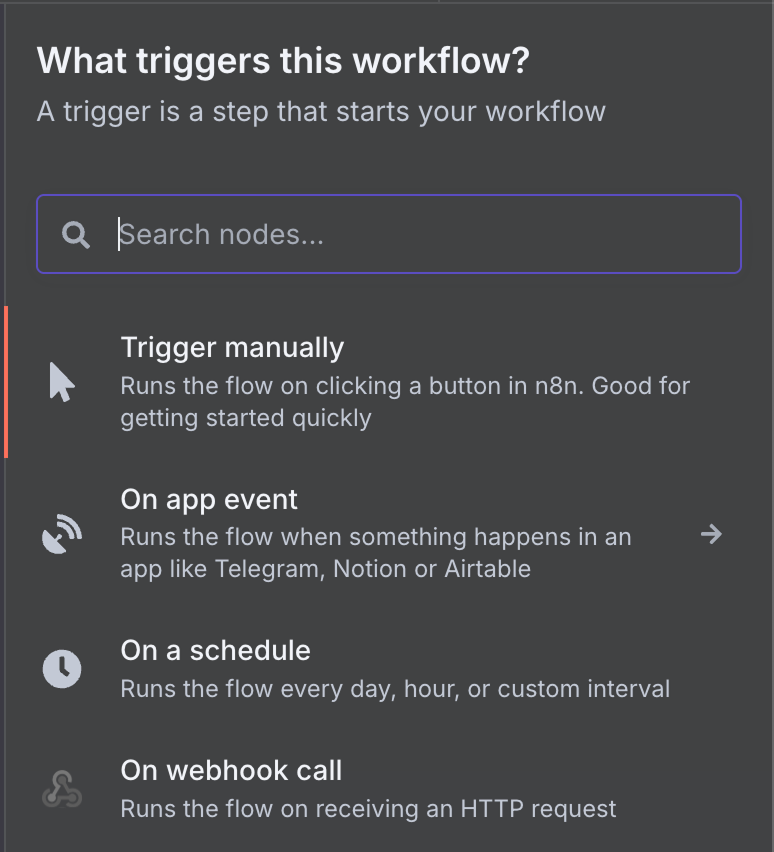
Доступен широкий набор триггеров. Выберем триггер Gmail: введите «gmail» в поиск и кликните по узлу Gmail.
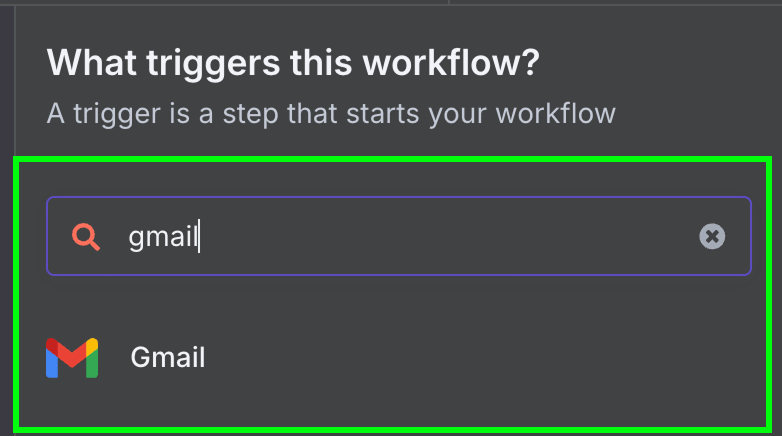
Затем выбираем единственный доступный триггер для Gmail: «On message received».

Откроется панель конфигурации узла, где нужно настроить учётные данные Gmail, чтобы рабочий процесс n8n мог получить доступ к вашему аккаунту. Нажмите «New credential». Откроется следующее окно:
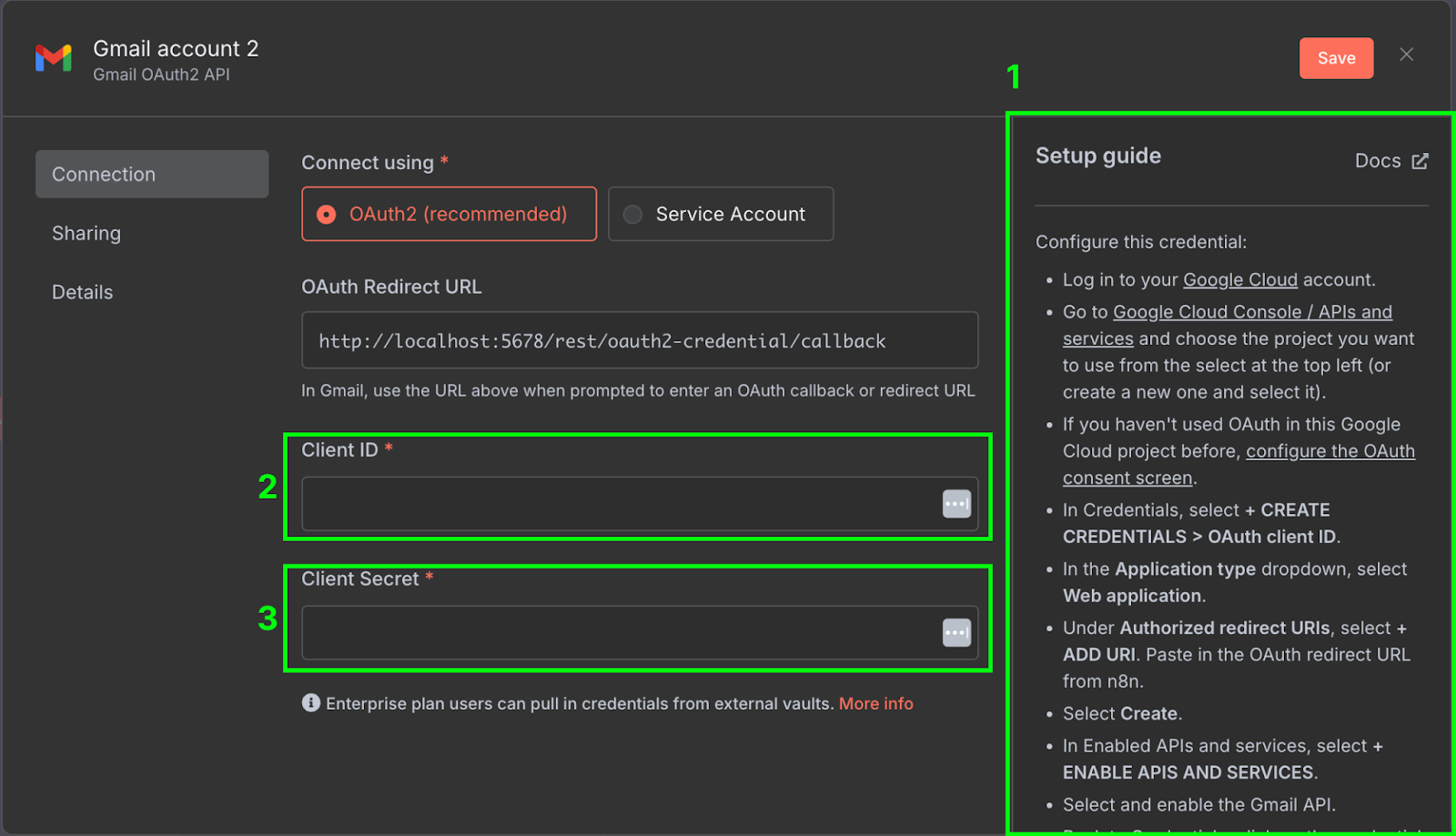
Справа (1) есть пошаговая инструкция по настройке учётных данных в Google Cloud. Гайды от n8n достаточно подробны, поэтому мы не будем их повторять. Обязательно включите Gmail API в консоли Google Cloud.
После настройки скопируйте client ID (2) и client secret (3) из Google Cloud в конфигурацию учётных данных n8n.
Чтобы убедиться, что всё настроено верно, протестируйте узел, нажав «Fetch Test Event».

После теста в выходных данных мы увидим последнее письмо из входящих. Содержимое письма находится в поле snippet.
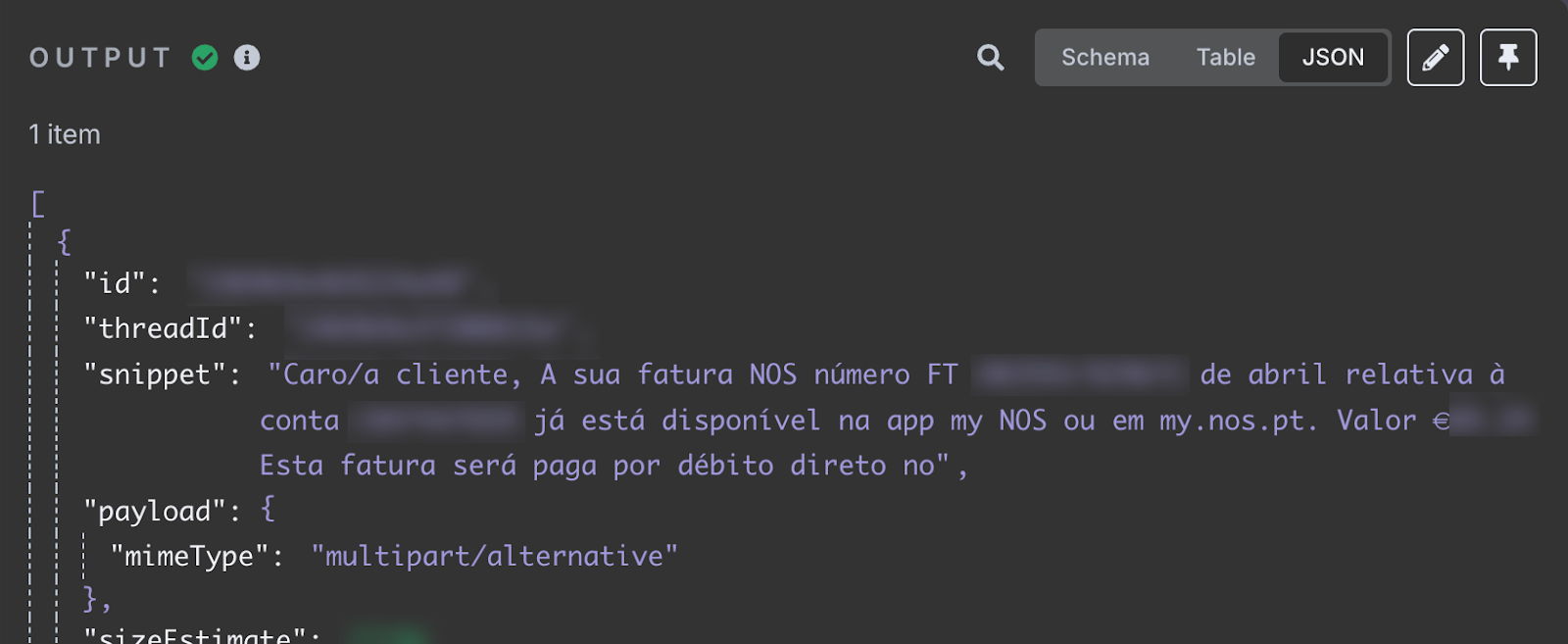
Поле snippet хранит содержимое письма. Здесь говорится, что доступен мой апрельский счёт за интернет. Указаны ID счёта и итоговая сумма к оплате. Именно эту информацию мы хотим добавить в таблицу.
Для удобства тестирования рекомендую закрепить результат, нажав кнопку с булавкой в правом верхнем углу:
Это «заморозит» результат триггера, то есть при запуске рабочего процесса будет использоваться один и тот же вывод. Так тестировать проще, потому что результат не будет меняться из‑за новых писем. Когда всё настроим, открепим.
На этом этапе в нашем процессе должен быть один триггер-узел (его легко узнать по маленькой молнии слева).

Учтите, что в вашем ящике, скорее всего, не будет письма со счётом, поэтому позже ChatGPT может вернуть бессмысленный ответ. Если хотите протестировать именно этот сценарий, отправьте себе тестовое письмо со следующим содержимым (или похожим):
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.После отправки снимите закрепление результата, снова запустите узел Gmail и закрепите новый результат.
Следующий шаг — настроить узел OpenAI. Нажмите кнопку «+» справа от триггер-узла Gmail:

Введите «OpenAI» и выберите соответствующий вариант из списка.
Затем в разделе «Text Actions» выберите узел «Message a model». Он используется для общения с LLM.

Как и прежде, нам нужно создать учётные данные для доступа к OpenAI. Обратите внимание: после создания их можно переиспользовать в любых процессах — настраивать каждый раз не требуется.
Для OpenAI достаточно API-ключа. Если у вас его нет, создайте его здесь. Если возникнут сложности, у n8n есть подробный гид.
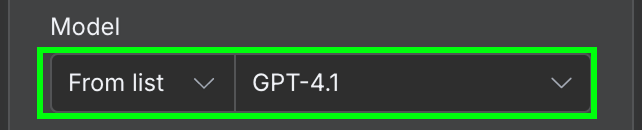
По конфигурации нам нужно выбрать модель ИИ и сообщение, которое мы ей отправим.
В качестве модели используем GPT-4.1. С тех пор OpenAI выпустила семейство GPT-5 (5.4, 5.4-mini, 5.5) и убрала 4.1 из ChatGPT, но через API она по-прежнему доступна и более чем достаточна для такой простой выборки.
В поле сообщения укажем подсказку. В этом примере мы передаём модели содержимое письма и просим определить ID счёта и итоговую сумму. Вот подсказка, которую я использовал:
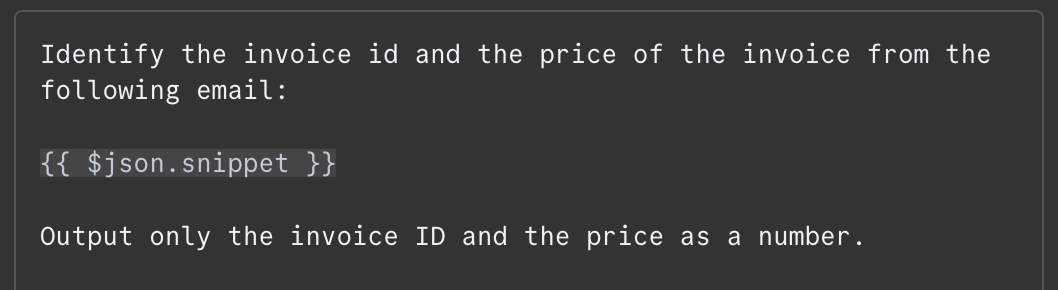
Содержимое письма подставляется как {{ $json.snippet }}. В n8n в подсказку можно вставлять переменные из вывода предыдущих узлов — в нашем случае это письмо. Список доступных полей виден слева. Поле можно ввести вручную или перетащить в подсказку.
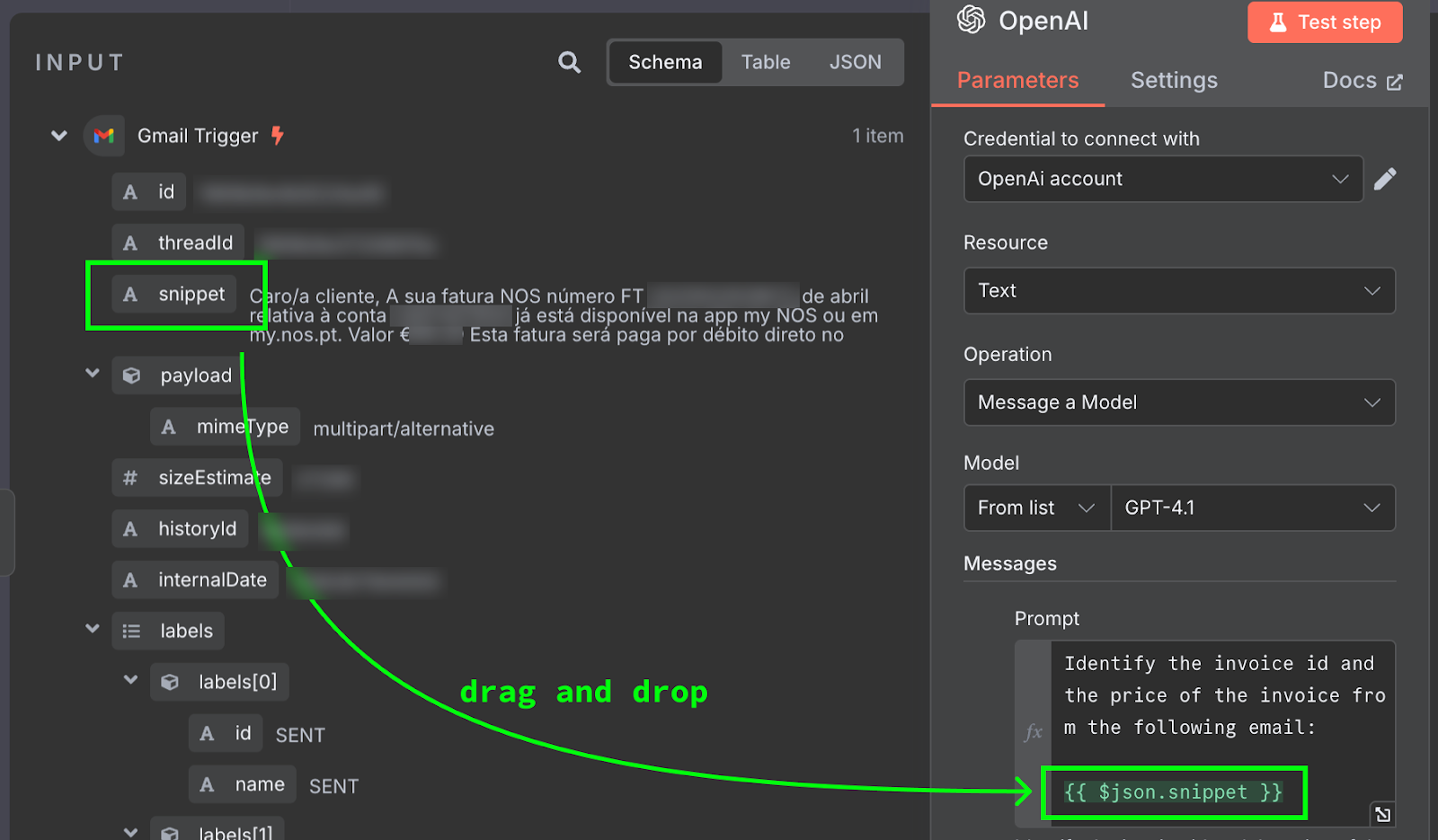
Чтобы протестировать, нажмите кнопку «Test Step» вверху панели конфигурации. Результат появится справа:
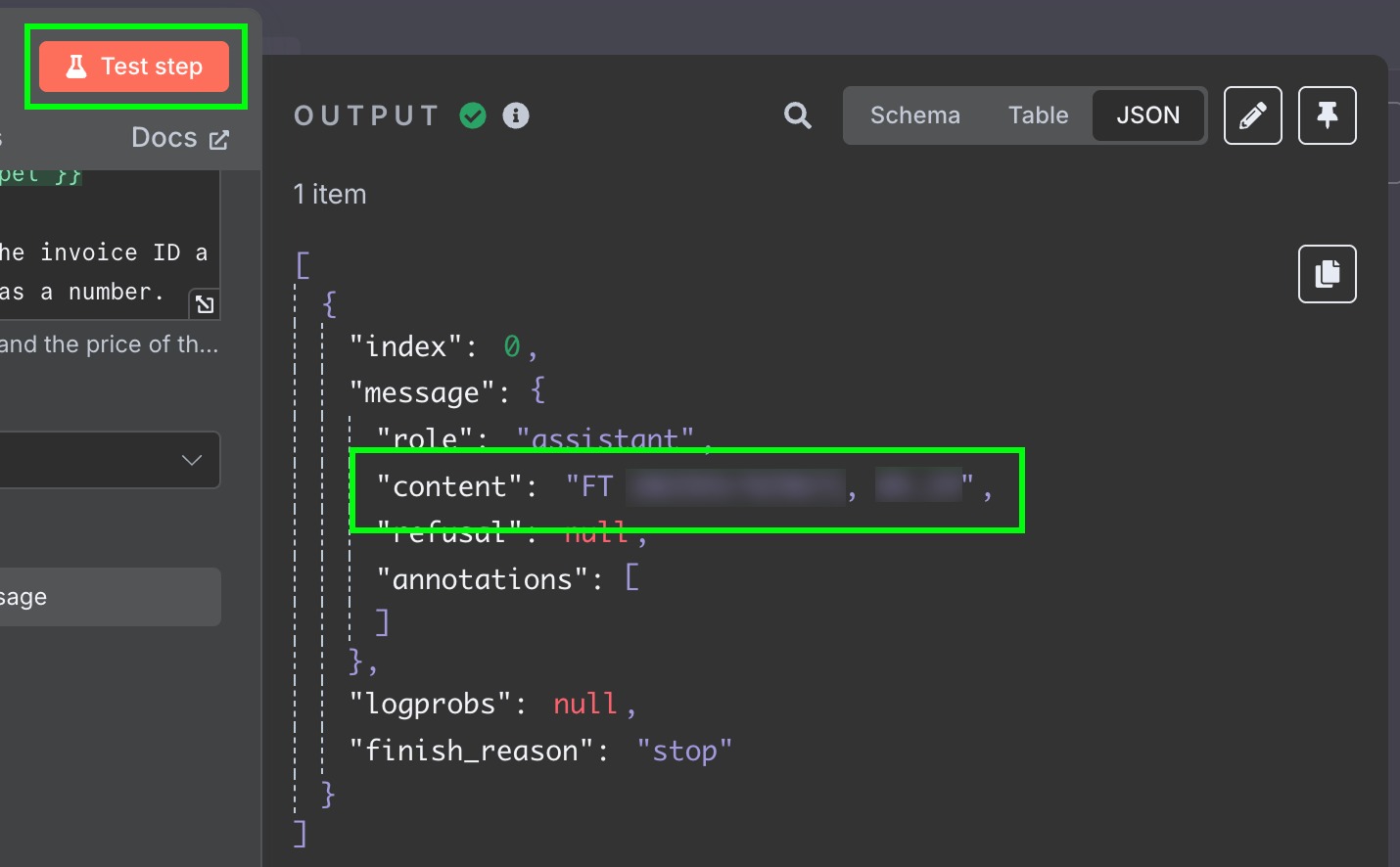
Результат — строка с ответом модели. Нам бы хотелось получить два поля отдельно, чтобы не обрабатывать строку далее. Это можно сделать, если изменить вывод LLM на JSON:

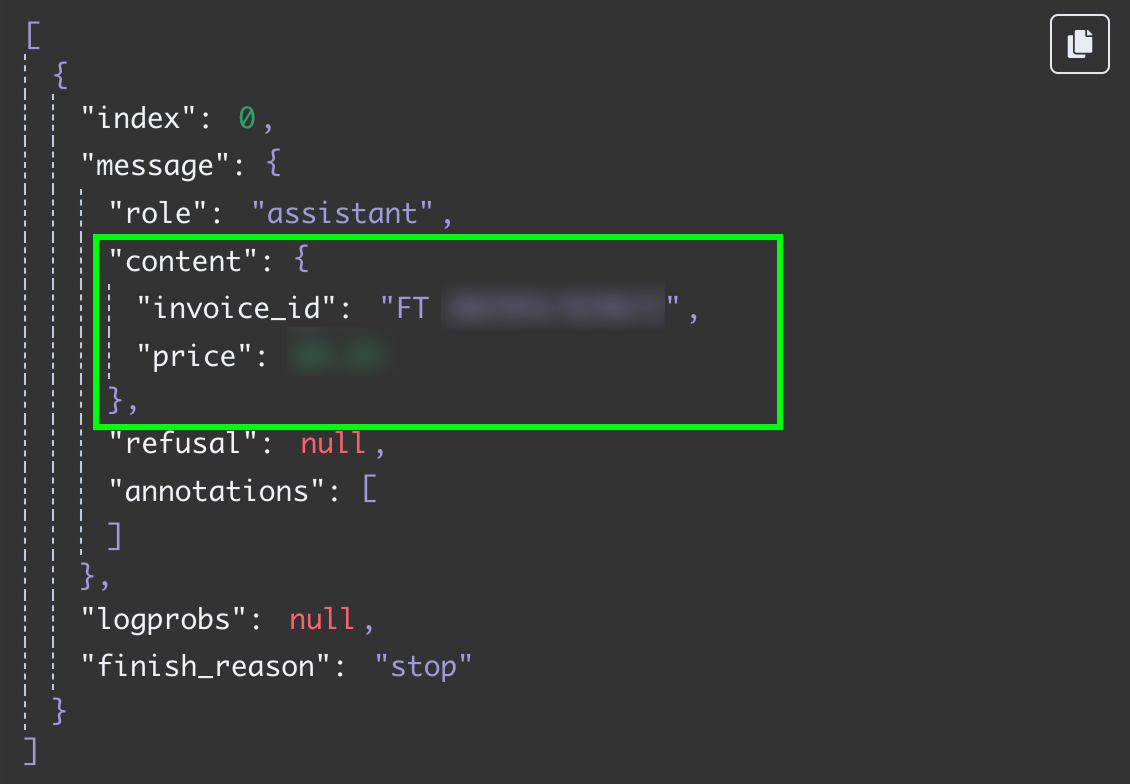
Повторно протестировав шаг, получим два поля в формате JSON:
Финальный шаг — отправить ID счёта и сумму в новую строку Google Sheets. На этом этапе подключим выходные данные узла OpenAI к Google Sheets. Как и раньше, нажимаем кнопку «+» слева от узла:
Здесь вводим Google Sheets и выбираем узел «Append row in sheet»:
Мы можем использовать те же учётные данные, что и для доступа к Gmail. Но необходимо включить следующие API в Google Cloud Console:
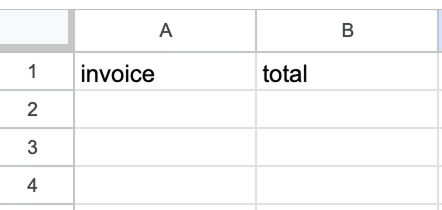
Чтобы настроить узел Google Sheets, выберите таблицу и укажите значения для заполнения столбцов. Таблицу нужно создать заранее с двумя столбцами: для ID счёта и для суммы.
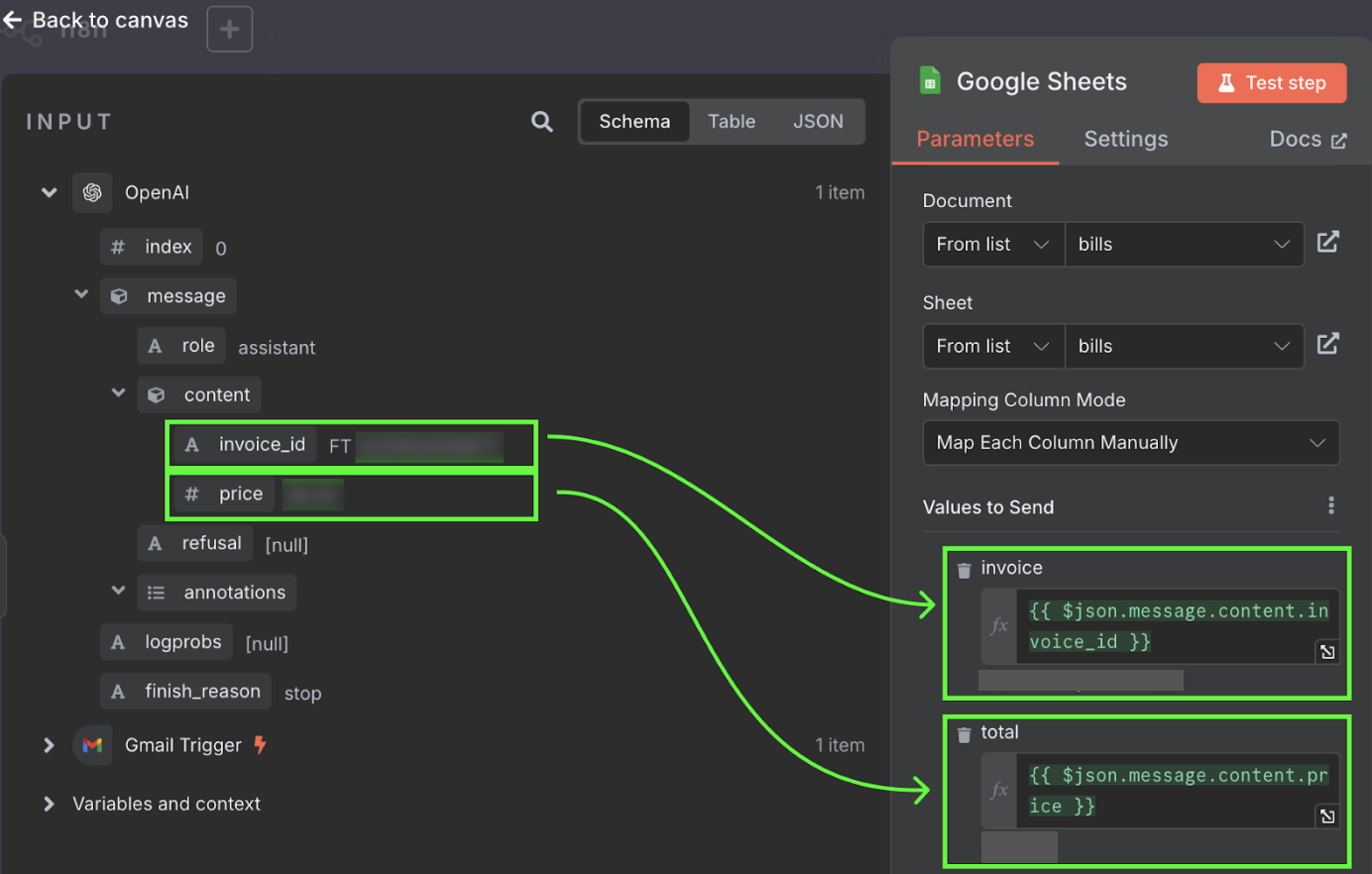
Эти значения берём из вывода узла OpenAI. Их можно перетащить в соответствующие столбцы.
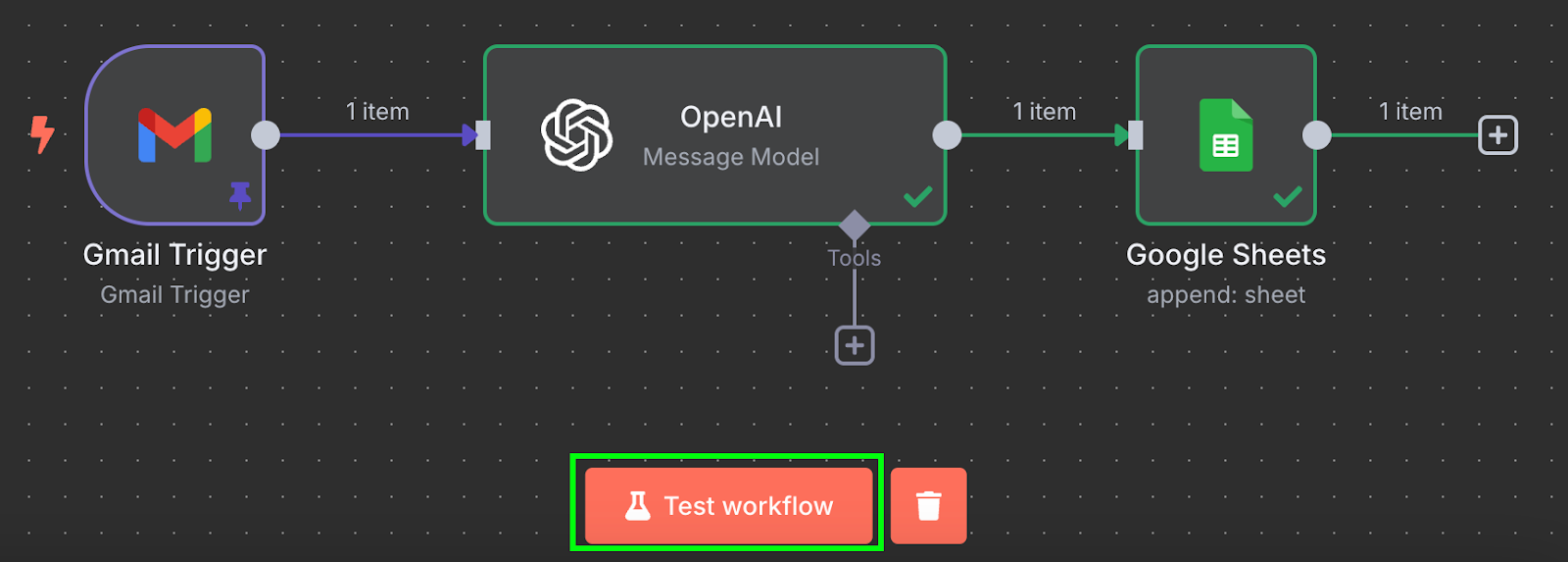
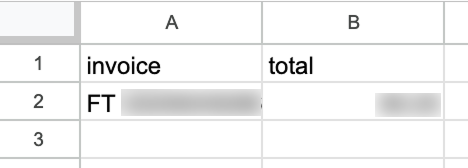
Готово! У нас есть процесс, который автоматически перенесёт данные по счетам в Google Sheets. Протестировать можно, нажав «Test workflow» внизу:
После запуска в Google Sheet появится новая строка с данными:
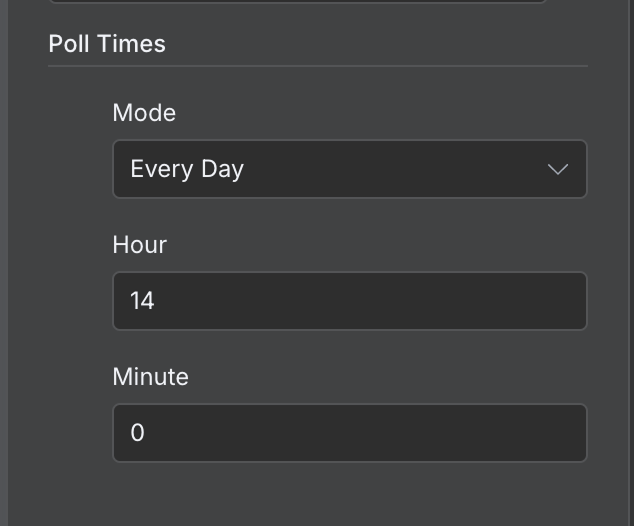
По умолчанию рабочий процесс выполняется каждую минуту. В зависимости от задачи стоит настроить подходящую частоту. В этом примере раз в минуту слишком часто. Раз в день — более уместно.
Это можно задать, дважды щёлкнув по триггеру и установив другое значение в поле «Poll Times»:
В этом разделе мы соберём более сложный рабочий процесс агента RAG. RAG — это retrieval-augmented generation, метод, который сочетает поиск релевантной информации в базе или документе и генерацию ответа языковой моделью на основе найденного.
Это очень полезно, когда у нас есть своя база знаний, например длинный текстовый документ, и мы хотим сделать ИИ-агента, который умеет отвечать на вопросы по нему.
Я люблю настольные игры, но мы с друзьями часто спорим о правилах и тратим время на поиски нужного пункта вместо игры — это утомляет. Агент RAG на базе правил игры — отличное решение: в следующий раз просто спросим агента.
Чтобы собрать этого агента, сделаем два рабочих процесса:
Pinecone — это тип базы данных, в которой данные хранятся в виде векторов. Такая база отлично подходит для агента RAG, потому что помогает быстро находить и понимать релевантную информацию, повышая точность ответов.
Поскольку этот процесс мы запускаем один раз, можно использовать ручной триггер. Это триггер-узел для ручного запуска процесса.
Подключите ручной триггер к узлу «Google Drive», чтобы скачать данные из Google Drive.

Используйте следующую конфигурацию:
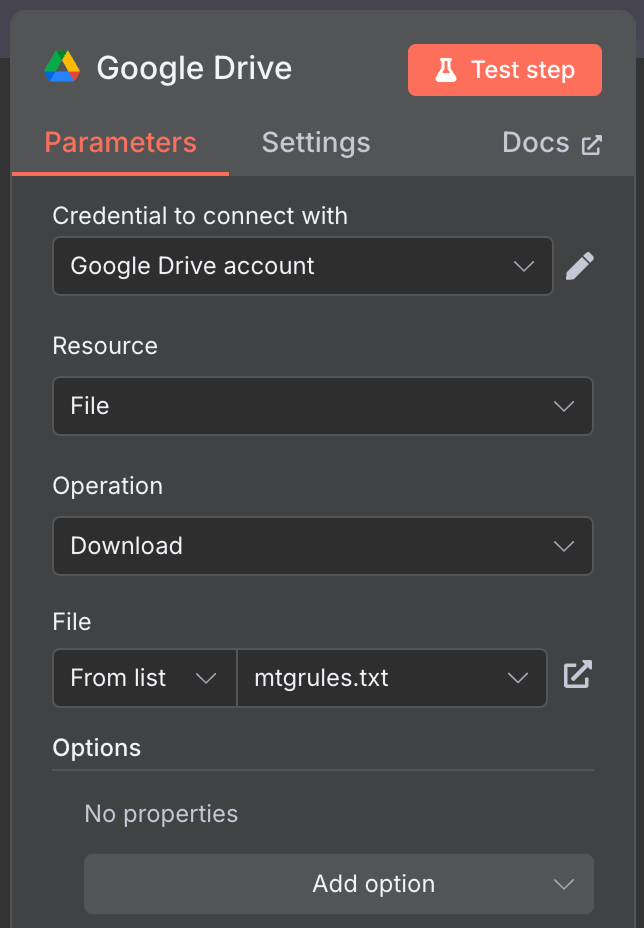
Я использовал общедоступный файл mtgrules.txt с правилами карточной игры Magic: The Gathering. Вы можете взять любой файл, по которому хотите задавать вопросы — процесс тот же.
Чтобы настроить Pinecone, войдите в Pinecone, скопируйте API-ключ и создайте индекс, нажав «Create index». Я назвал индекс rules и выбрал модель text-embedding-3-small.

Возвращаемся в n8n и подключаем выход узла Google Drive к узлу Pinecone Vector Store с действием «Add documents to vector store»:
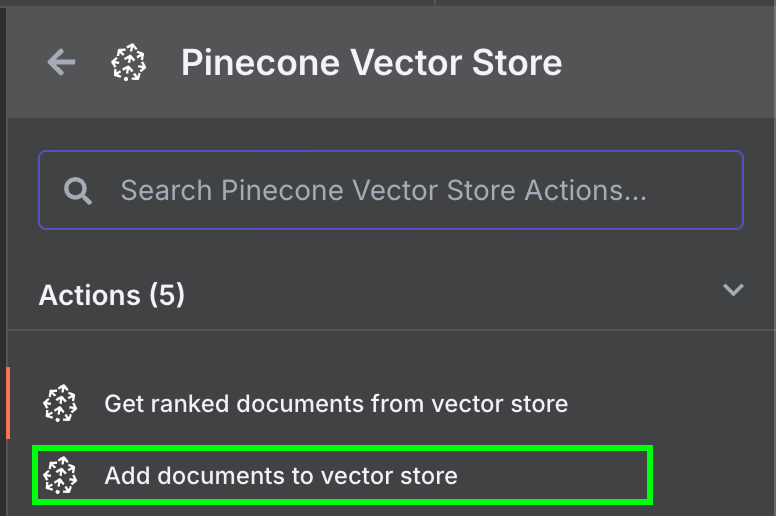
Чтобы настроить узел, создайте учётные данные, вставив API-ключ и выбрав только что созданный индекс Pinecone. Под узлом Pinecone Vector Store видны две вещи, которые нужно настроить: модель для эмбеддингов и загрузчик данных.
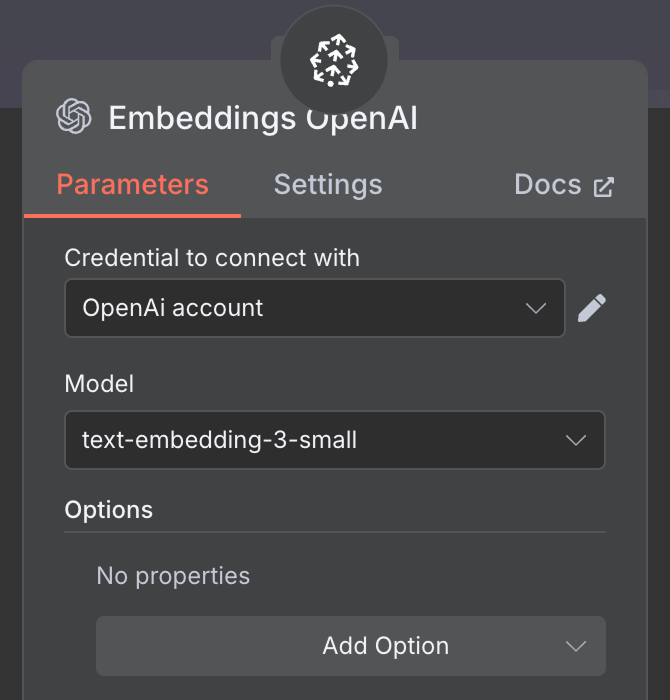
Для эмбеддингов создайте узел OpenAI Embedding с моделью text-embedding-3-small:
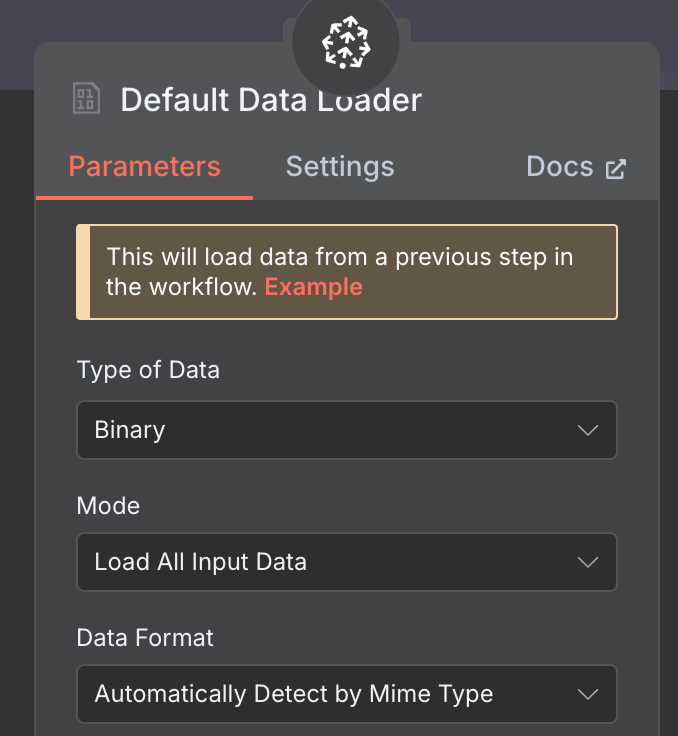
Для загрузчика данных создайте узел Default Data Loader с типом двоичных данных (binary):
Наконец, загрузчику данных требуется узел Text Splitter, который задаёт, как разбивать данные из файла при создании векторного хранилища. Используем узел Recursive Character Text Splitter — это рекомендуемый вариант для большинства задач.
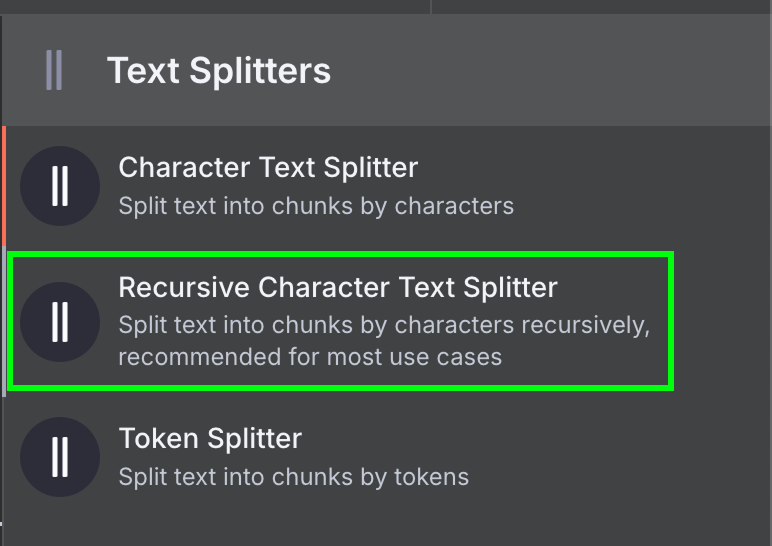
Настроим его с размером фрагмента 1000 и перекрытием 200:
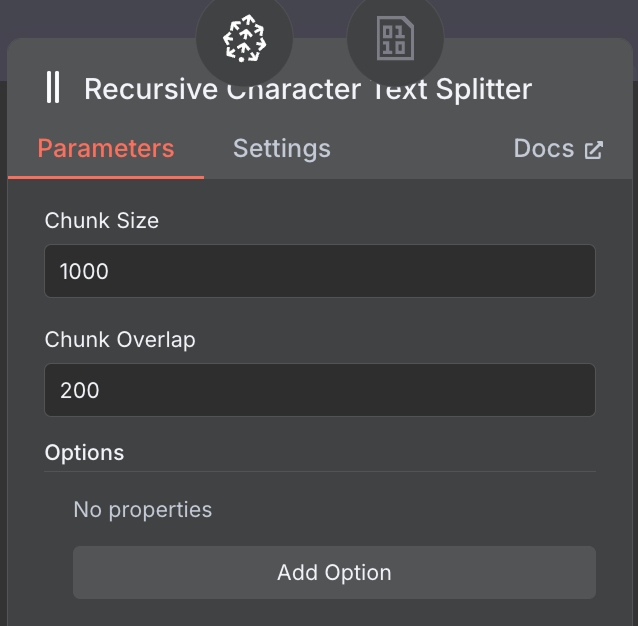
Выбирая размер фрагмента и перекрытие, для длинных документов берите больший размер, чтобы захватывать достаточно контекста, и меньшее перекрытие — чтобы сохранять связность между сегментами без избыточности.
Вот как выглядит финальный процесс загрузки данных:
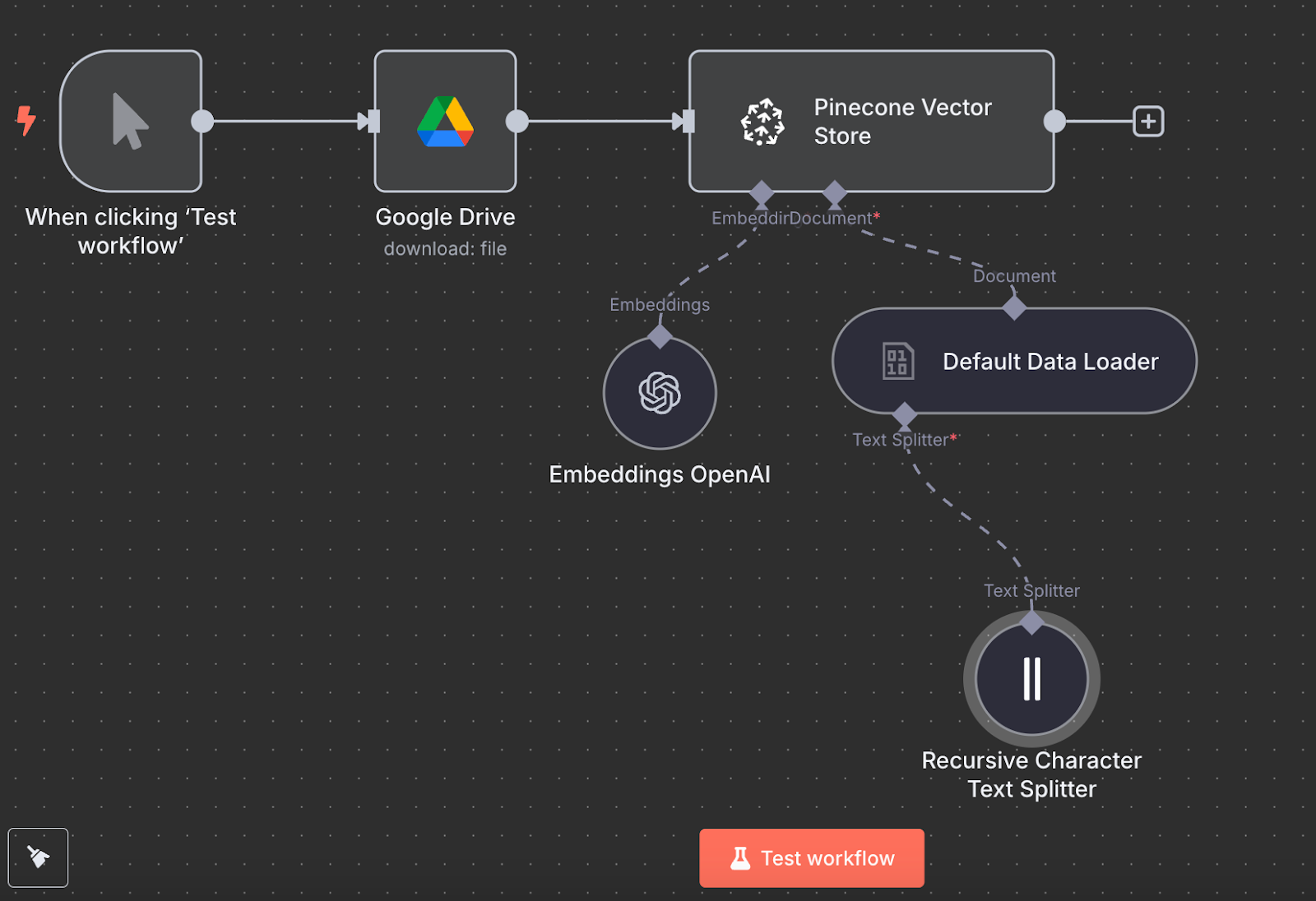
Запустите его, нажав «Test workflow», и по завершении проверьте в Pinecone, что данные загружены.
Вот финальная схема агента RAG:
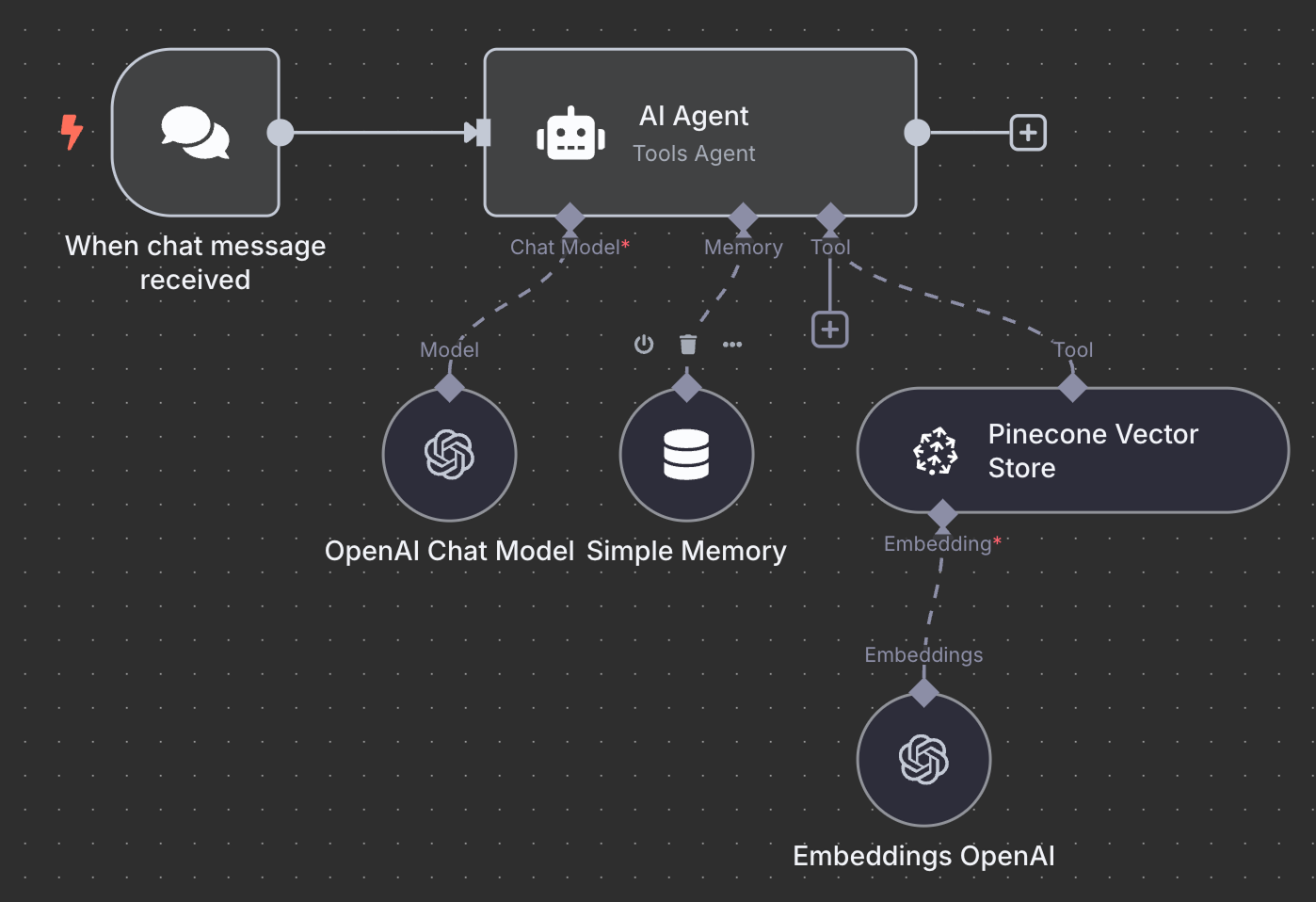
В качестве упражнения попробуйте понять его и даже воссоздать у себя локально, прежде чем читать дальше.
Начинаем с триггер-узла «On chat message». Он используется для создания чат-рабочего процесса.
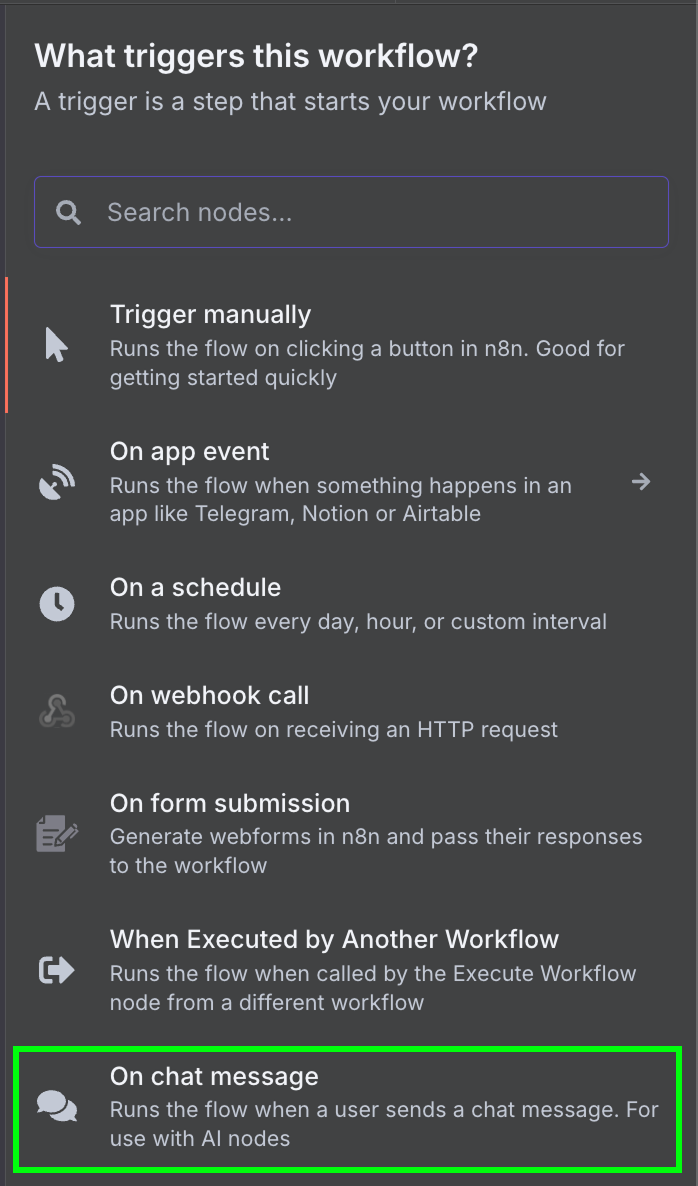
Далее подключаем чат-триггер к узлу «AI Agent» с настройками по умолчанию.
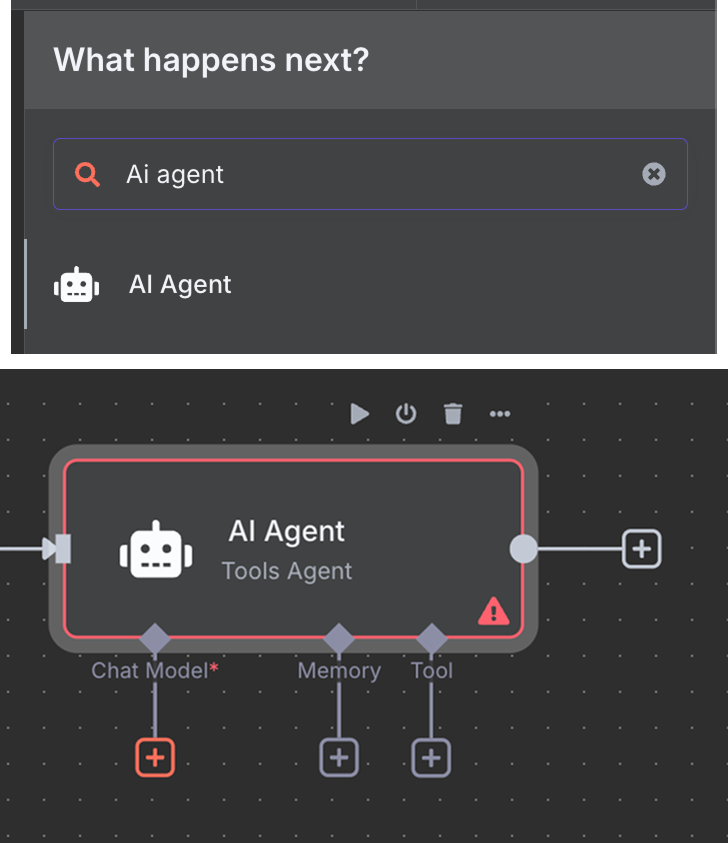
Под узлом AI Agent можно настроить три вещи:
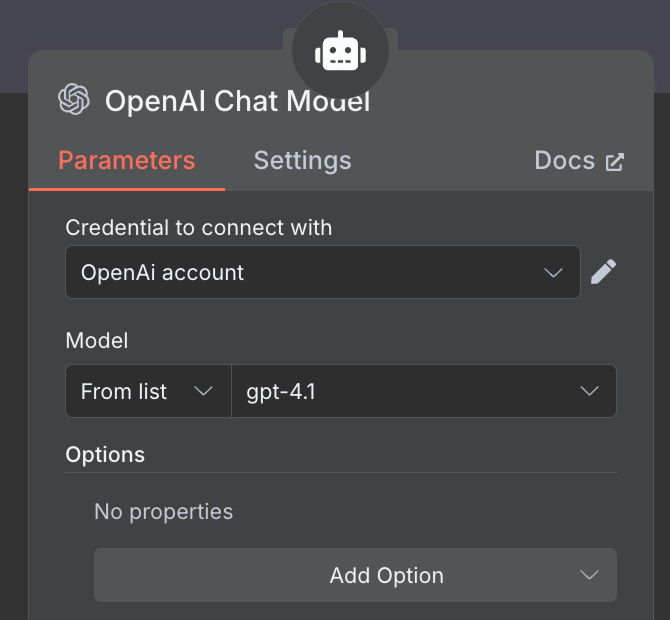
В качестве модели ИИ выбираем «OpenAI Chat Model» и используем GPT-4.1, как и ранее. Семейство GPT-5 — актуальная линейка OpenAI, но 4.1 имеет контекстное окно в 1 млн токенов и хорошо подходит для RAG.
Для памяти используем «Simple Memory» с окном контекста длиной 5. Это значит, что агент будет учитывать пять предыдущих взаимодействий при ответе.
В качестве инструмента добавляем узел «Pinecone Vector Store» со следующей конфигурацией:
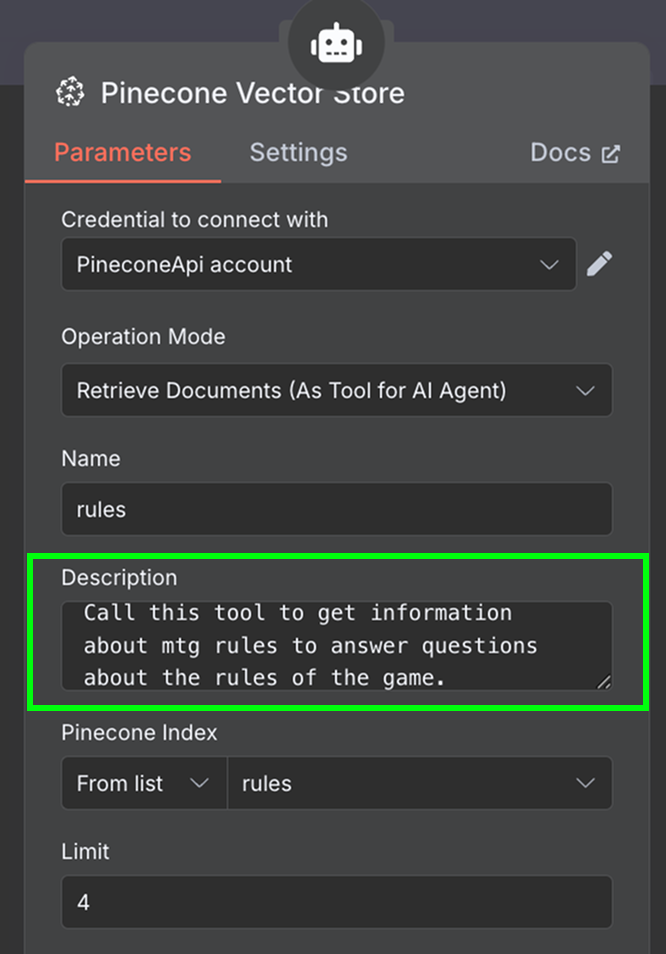
В поле описания важно указать, когда следует использовать инструмент. Агент будет опираться на это, решая, вызывать ли его.
Осталось настроить эмбеддинги, которые использует векторное хранилище. Как и раньше, используем узел OpenAI Embedding с моделью text-embedding-3-small:
Рабочий процесс готов, можно общаться с агентом. Вот пример:
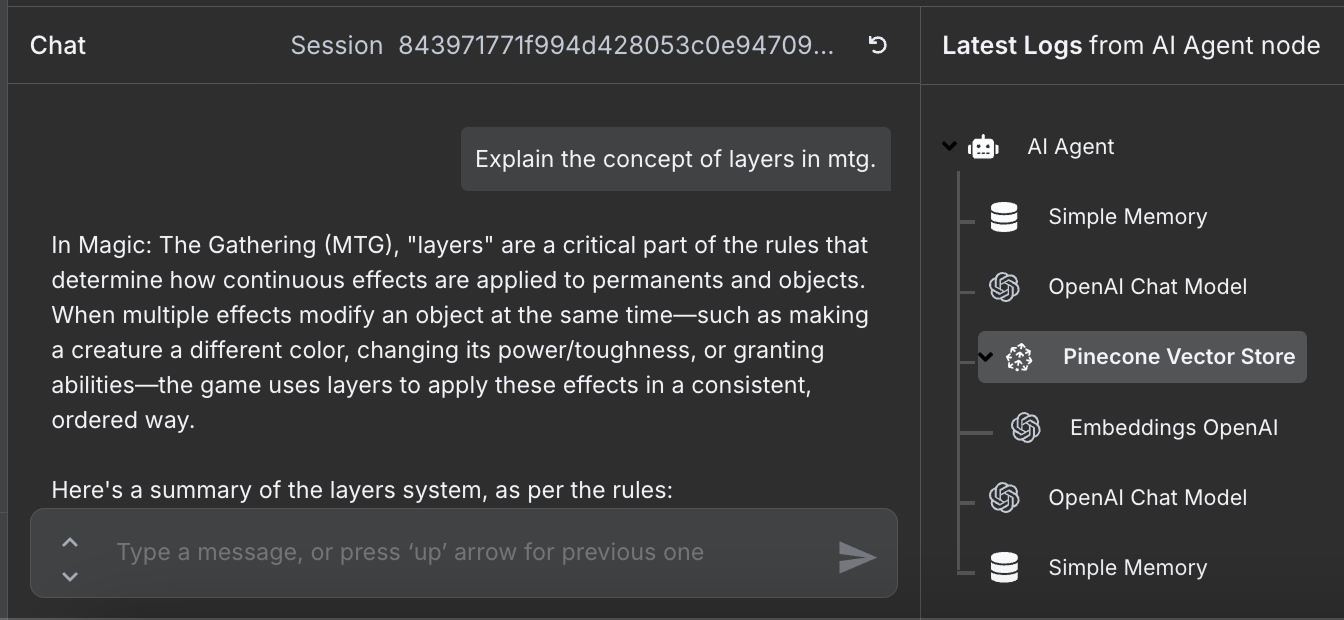
Справа видны шаги, которые агент предпринял, чтобы ответить на вопрос. В частности, он обратился к базе Pinecone за релевантными правилами.
n8n предлагает полезную функцию, которая может заметно ускорить создание процессов: библиотеку шаблонов n8n.
Это коллекция готовых рабочих процессов, созданных сообществом и экспертами n8n. Будь то простая автоматизация или сложные сценарии — велика вероятность, что кто-то уже сделал подходящий шаблон.
Импортируя рабочий процесс в свою установку n8n, мы не начинаем с нуля. Можно воспользоваться готовыми решениями других пользователей. После импорта останется лишь подставить свои учётные данные и подстроить под свои нужды.
Почти для любой задачи — от обработки писем до управления соцсетями — в библиотеке, скорее всего, найдётся шаблон.
n8n предлагает обширную экосистему интеграций, позволяя подключать более тысячи сервисов и инструментов для создания ИИ-агентов. В этом руководстве мы лишь немного коснулись возможностей n8n. Освоив подход к созданию ИИ-агентов для автоматизации повседневных задач, вы сделали первый шаг к раскрытию его потенциала.
Изучайте ИИ с этими курсами!
Track
Course
Course