Track
Tworzenie aplikacji AI
21 godz.
n8n stał się popularnym i potężnym frameworkiem w agentic AI. Pozwala budować zautomatyzowane przepływy pracy bez potrzeby złożonego kodowania.
W tym artykule krok po kroku wyjaśnię, jak w pełni wykorzystać tę solidną platformę do automatyzacji dwóch różnych procesów:
Na bieżąco informujemy czytelników o nowościach w AI w The Median, naszym bezpłatnym piątkowym newsletterze, który rozkłada na czynniki pierwsze najważniejsze wydarzenia tygodnia. Zasubskrybuj i bądź na czasie w kilka minut tygodniowo:
n8n to narzędzie open source do automatyzacji, które pomaga łączyć różne aplikacje i usługi, aby tworzyć przepływy pracy, niczym cyfrową linię produkcyjną. Umożliwia wizualne projektowanie przepływów z węzłów, z których każdy reprezentuje kolejny krok procesu.
Z n8n możemy automatyzować zadania, zarządzać przepływem danych, a nawet integrować API — i to bez rozbudowanych umiejętności programistycznych. Oto przykład automatyzacji, którą zbudujemy w tym tutorialu:
Bez wchodzenia w szczegóły, oto opis działania tej automatyzacji:
Mamy dwie opcje korzystania z n8n:
Obie opcje pozwalają przerobić ten tutorial bez kosztów. My uruchomimy n8n lokalnie, ale jeśli wolisz interfejs webowy, kroki są takie same.
Uwaga: n8n 2.0 wyszło pod koniec 2025 roku i wprowadziło system wersji roboczych/publikacji, autosejw (styczeń 2026), odświeżony panel edycji węzłów bez utraty kontekstu płótna oraz Task Runners, które izolują wykonywanie przepływów dla lepszego bezpieczeństwa.
Przepływy poniżej działają na 2.x — jeśli masz 1.x, rozważ aktualizację przed dalszą pracą.
Oficjalne repozytorium n8n wyjaśnia, jak skonfigurować n8n lokalnie. Najprościej:
Pobierz i zainstaluj Node.js z oficjalnej strony.
Otwórz terminal i uruchom polecenie npx n8n.
I tyle! Po uruchomieniu komendy w terminalu zobaczysz coś takiego:
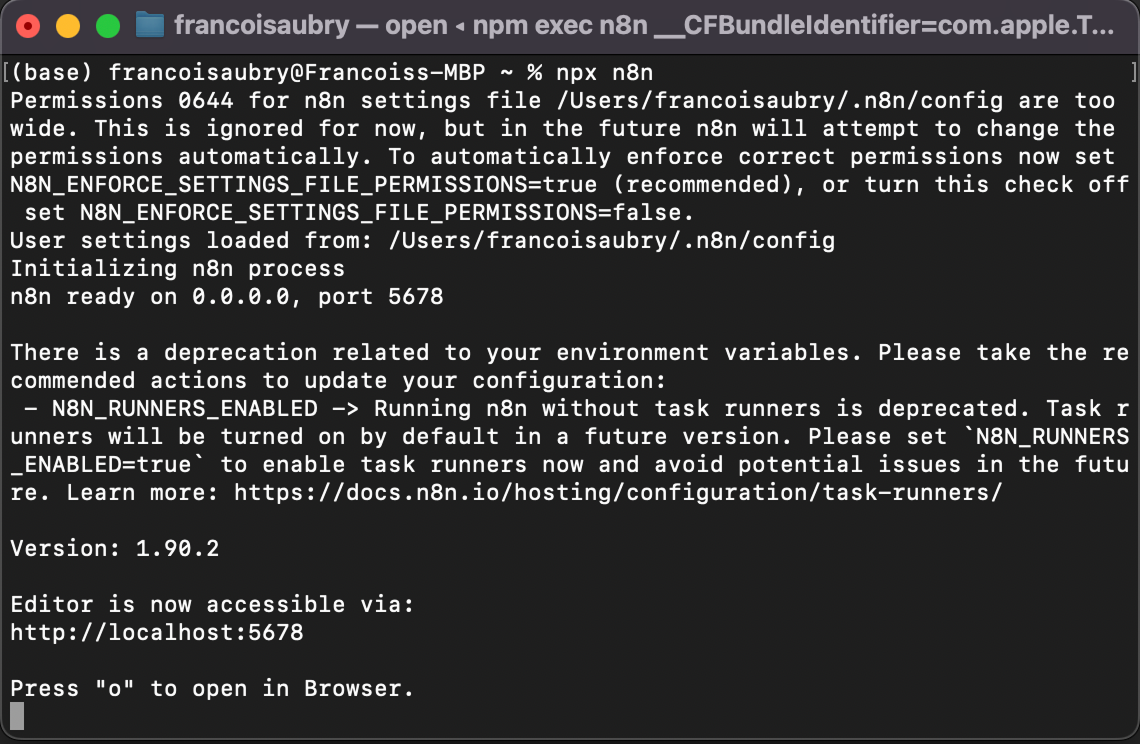
Aby otworzyć interfejs, naciśnij na klawiaturze „o” lub otwórz adres localhost wyświetlony w terminalu — u mnie to http://localhost:5678.
Zanim zbudujemy pierwszą automatyzację, warto zrozumieć, jak działa n8n. Przepływ pracy w n8n to sekwencja węzłów. Zaczyna się od węzła wyzwalającego (trigger), który określa warunek uruchomienia przepływu.
Węzły łączą się, aby przesyłać i przetwarzać dane. W tym przykładzie wyzwalacz Gmail łączy się z węzłem OpenAI. Oznacza to, że wiadomość e‑mail trafia do ChatGPT do przetworzenia. Na końcu wynik ChatGPT jest przekazywany do węzła Google Sheet, który łączy się z arkuszem w Google Drive i dopisuje nowy wiersz do arkusza kalkulacyjnego.
Ten konkretny przepływ używa ChatGPT do identyfikowania faktur do opłacenia i przypisuje w arkuszu wiersz z identyfikatorem faktury i kwotą.
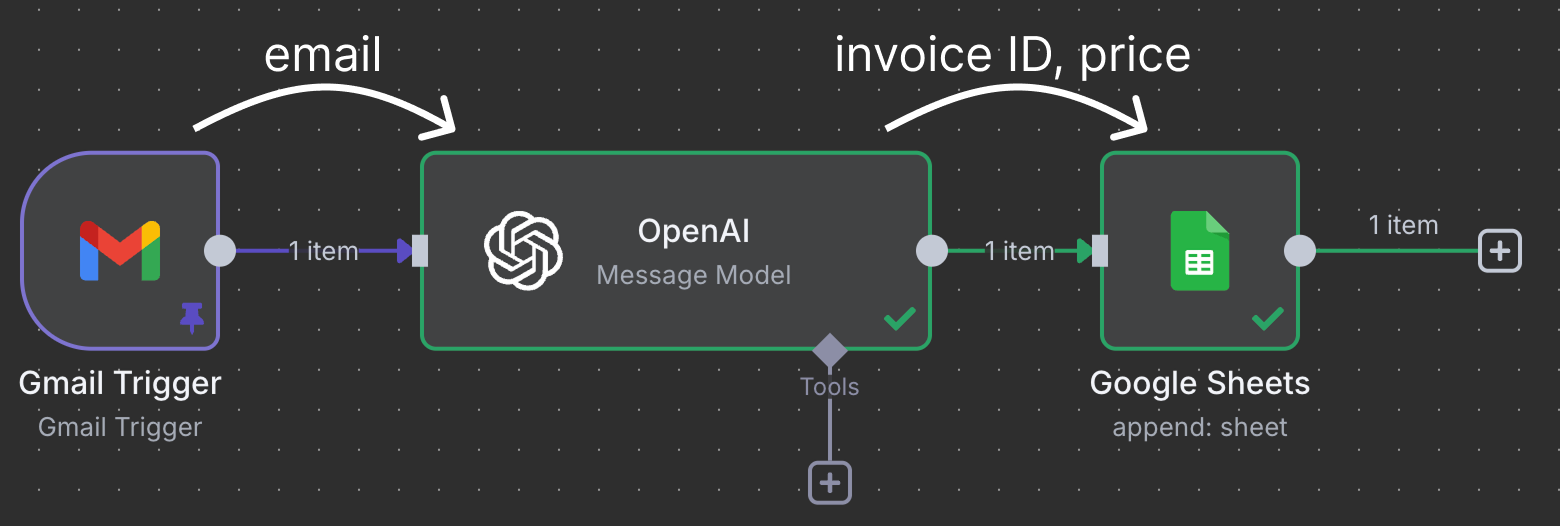
Przepływy w n8n mogą być znacznie bardziej złożone. n8n obsługuje ponad 400 oficjalnych integracji (węzły core), do tego 600+ węzłów społeczności i własne połączenia przez węzeł HTTP Request — nie da się więc omówić wszystkiego w jednym tutorialu.
Zamiast tego skupię się na ogólnym zrozumieniu działania i dam ci podstawy, by samodzielnie eksplorować. Jeśli jest narzędzie, z którego często korzystasz, najpewniej n8n je wspiera — a jeśli nie, możesz je zintegrować ręcznie.
W tej sekcji nauczymy się zbudować powyższy przepływ.
To realny przypadek użycia, którego używam do zarządzania moimi rachunkami za wynajem. Mam dom z kilkoma pokojami na wynajem. Rachunki dzielimy po równo między wszystkich najemców. Za każdym razem, gdy otrzymuję fakturę, muszę dodać sumę do arkusza współdzielonego z najemcami.
Mam osobny adres e‑mail, na który są przekazywane faktury za media. Dzięki temu wiem, że wszystkie wiadomości w tej skrzynce to faktury. Wysyłam treść e‑maila do ChatGPT, aby zidentyfikować numer faktury i łączną kwotę do zapłaty. Następnie te informacje trafiają do nowego wiersza we współdzielonym arkuszu.
Aby rozpocząć nowy przepływ, kliknij przycisk „Add first step...”

Ponieważ to pierwszy węzeł, musi być wyzwalaczem, więc pojawia się panel wyboru węzła wyzwalającego. Węzeł trigger definiuje warunki uruchomienia przepływu.
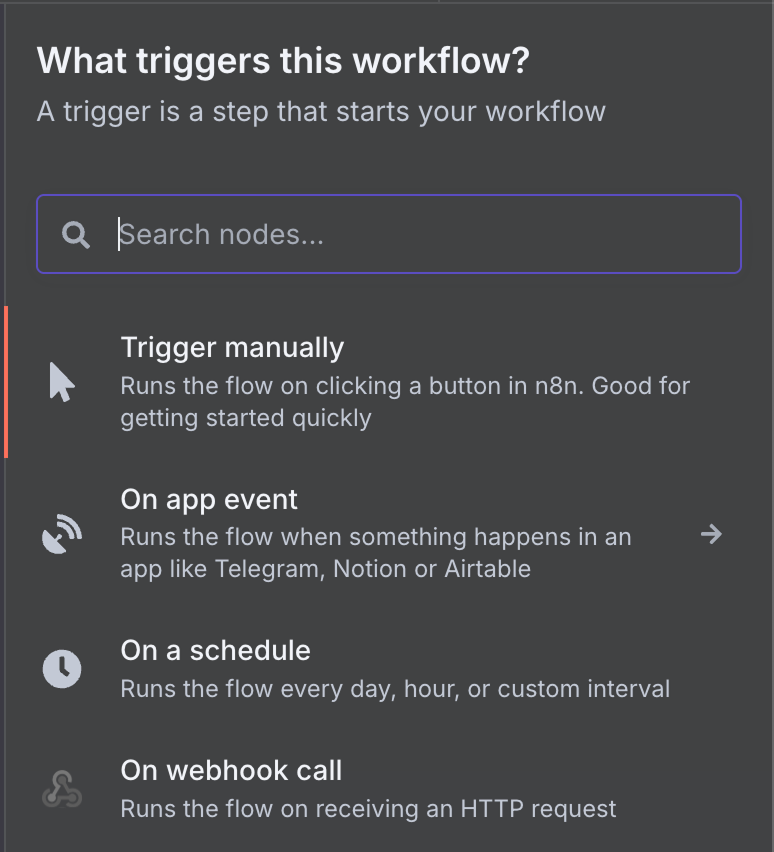
Dostępnych jest wiele rodzajów wyzwalaczy. Wybierzmy Gmail trigger, wpisując „gmail” w wyszukiwarkę i klikając węzeł Gmail.
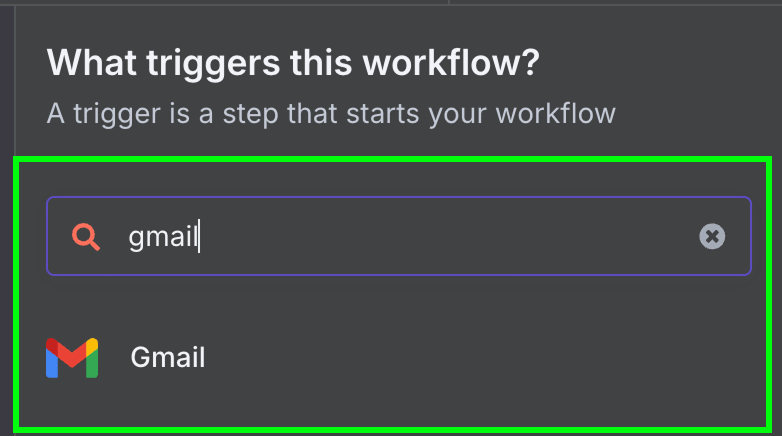
Następnie wybieramy jedyny dostępny trigger dla Gmaila: „On message received”.

To otworzy panel konfiguracji węzła, gdzie musimy dodać nasze dane logowania do Gmaila, by przepływ miał dostęp do konta. Kliknij „New credential”. Otworzy się następujące okno:
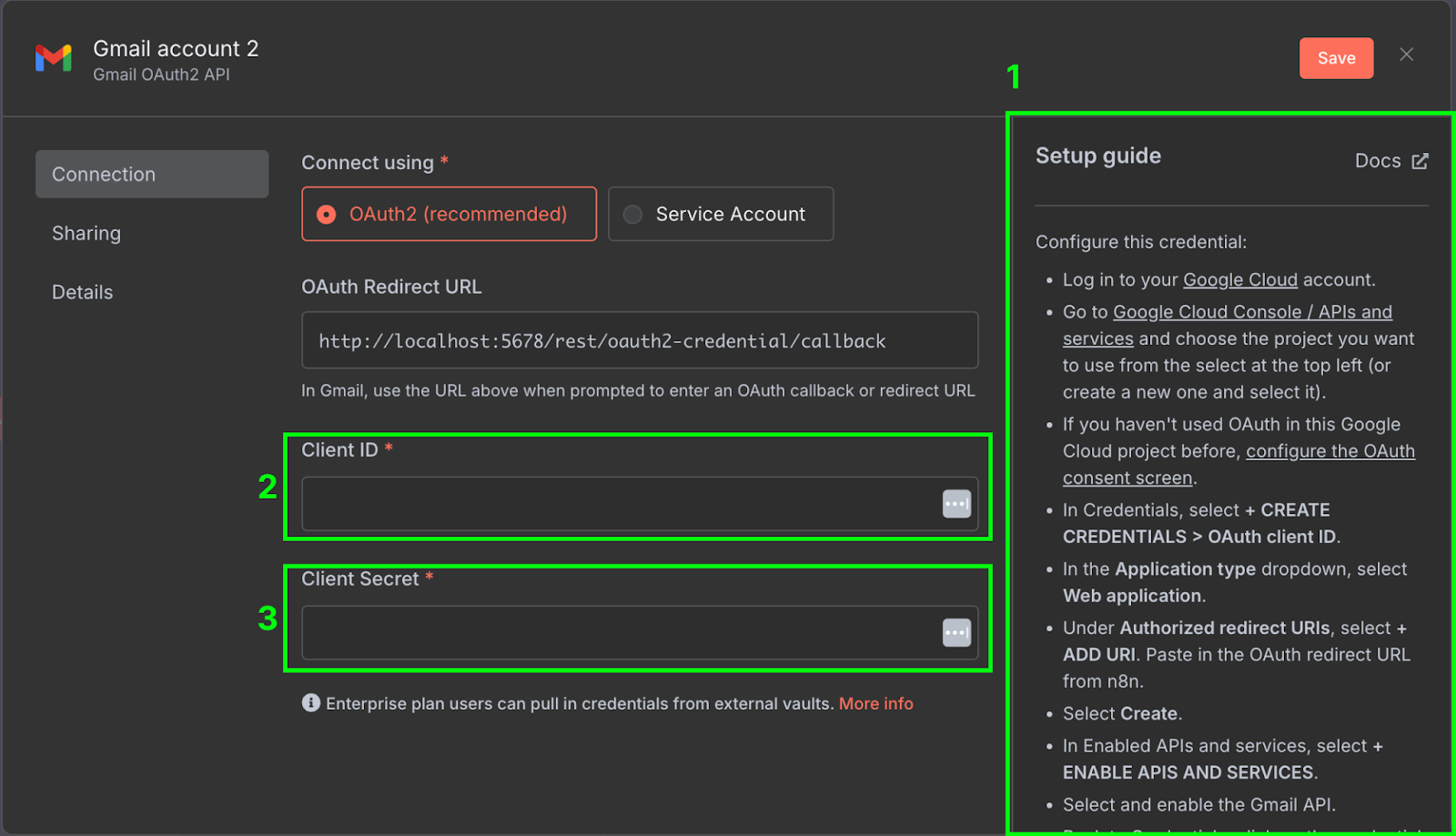
Po prawej stronie (1) jest instrukcja konfiguracji poświadczeń w Google Cloud. Poradniki n8n są dość wyczerpujące, więc nie będziemy ich powtarzać. Upewnij się też, że włączysz Gmail API w Google Cloud Console.
Gdy wszystko skonfigurujesz, skopiuj client ID (2) i client secret (3) z Google Cloud do konfiguracji poświadczeń w n8n.
Aby sprawdzić, czy konfiguracja jest poprawna, możemy przetestować węzeł, klikając „Fetch Test Event”.

Po teście w sekcji wyników powinniśmy zobaczyć najnowszego e‑maila z naszej skrzynki. Treść wiadomości to pole snippet.
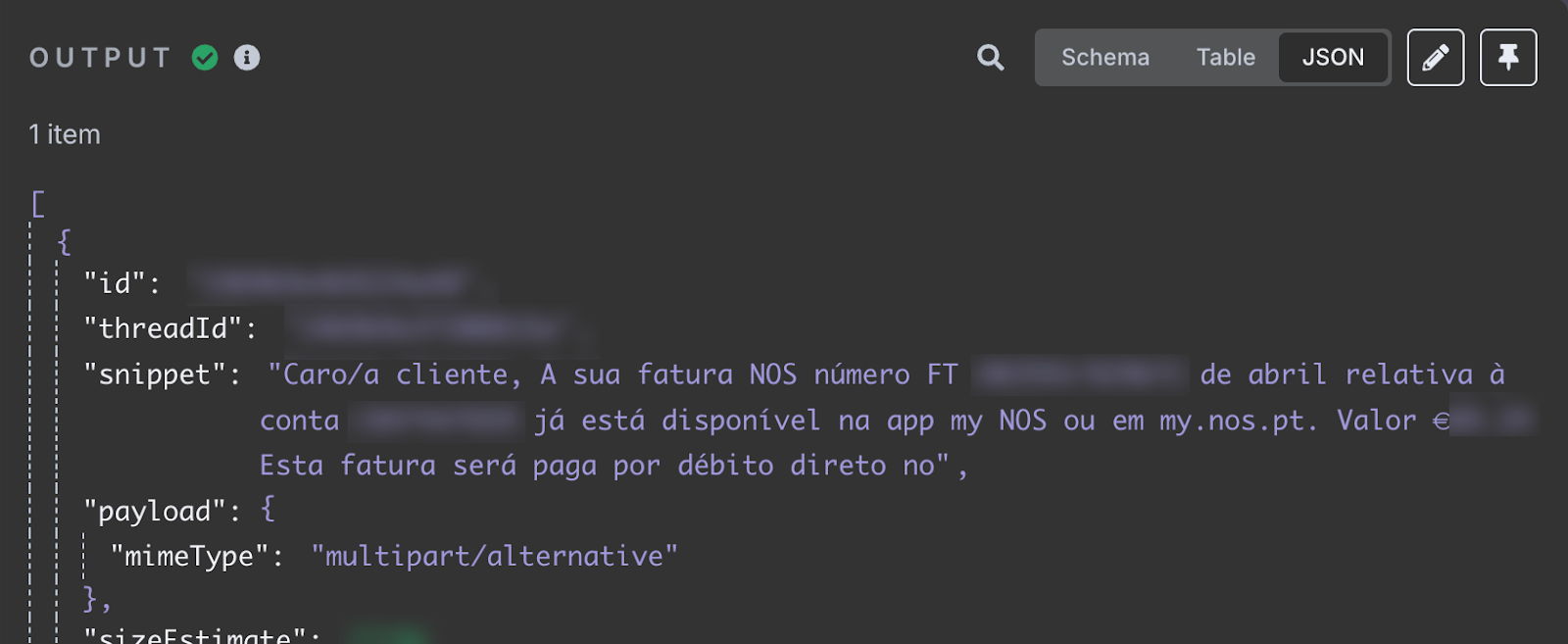
Pole snippet przechowuje treść e‑maila. Widać, że moja kwietniowa faktura za internet jest dostępna. Podaje identyfikator faktury i łączną kwotę do zapłaty. To właśnie informacje, które chcemy dodać do arkusza.
Na potrzeby testów polecam przypiąć wynik, klikając pinezkę w prawym górnym rogu:
To zablokuje wynik dla wyzwalacza — gdy uruchomimy przepływ, użyty zostanie ten sam output, co ułatwia testowanie, bo wyniki nie będą zależeć od nowych e‑maili. Odpniemy go, gdy przepływ będzie gotowy.
Na tym etapie nasz przepływ powinien mieć pojedynczy węzeł wyzwalający (poznasz go po małej ikonie błyskawicy po lewej).

Pamiętaj, że ponieważ prawdopodobnie nie masz w skrzynce faktury, później ChatGPT może zwrócić odpowiedź bez sensu. Jeśli chcesz przetestować dokładnie ten przepływ, możesz wysłać sobie testowy e‑mail o następującej treści (albo podobnej):
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.Po wysłaniu musisz odpiąć wynik, ponownie uruchomić węzeł Gmail i przypiąć nowy wynik.
Kolejny krok to konfiguracja węzła OpenAI. Zacznij, klikając przycisk „+” po prawej stronie węzła Gmail trigger:

Wpisz „OpenAI” i wybierz odpowiednią opcję z listy.
Następnie, w sekcji „Text Actions”, wybierz węzeł „Message a model”. Tego węzła używa się do rozmowy z LLM.

Jak wcześniej, musimy utworzyć poświadczenia do OpenAI. Poświadczenia po utworzeniu można ponownie używać w dowolnym przepływie — nie trzeba ich ustawiać za każdym razem.
Do poświadczeń OpenAI potrzebny jest klucz API. Jeśli go nie masz, możesz utworzyć go tutaj. Jeśli napotkasz trudności, n8n ma też przewodnik.
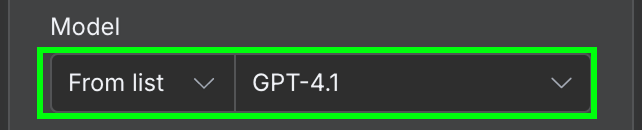
W konfiguracji musimy wybrać model AI i wiadomość, którą do niego wyślemy.
Jako model użyjemy GPT‑4.1. OpenAI wypuściło już rodzinę GPT‑5 (5.4, 5.4‑mini, 5.5) i wycofało 4.1 z ChatGPT, ale przez API nadal jest dostępny i w zupełności wystarczy do takiego prostego wydobywania informacji.
W polu wiadomości musimy podać prompt. W tym przykładzie przekazujemy modelowi treść e‑maila i prosimy o wskazanie numeru faktury oraz łącznej kwoty do zapłaty. Oto prompt, którego użyłem:
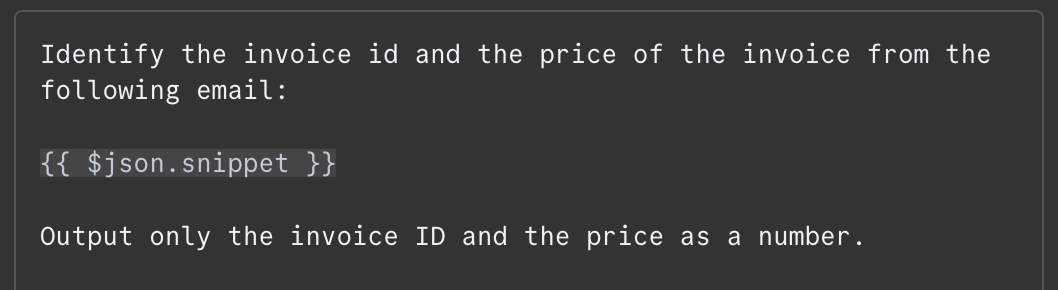
Treść e‑maila jest przekazywana jako {{ $json.snippet }}. W n8n prompt może zawierać zmienne wypełniane z outputu poprzednich węzłów — w naszym przypadku z e‑maila. Listę dostępnych pól widać po lewej. Możemy wpisać je ręcznie lub przeciągnąć do promptu.
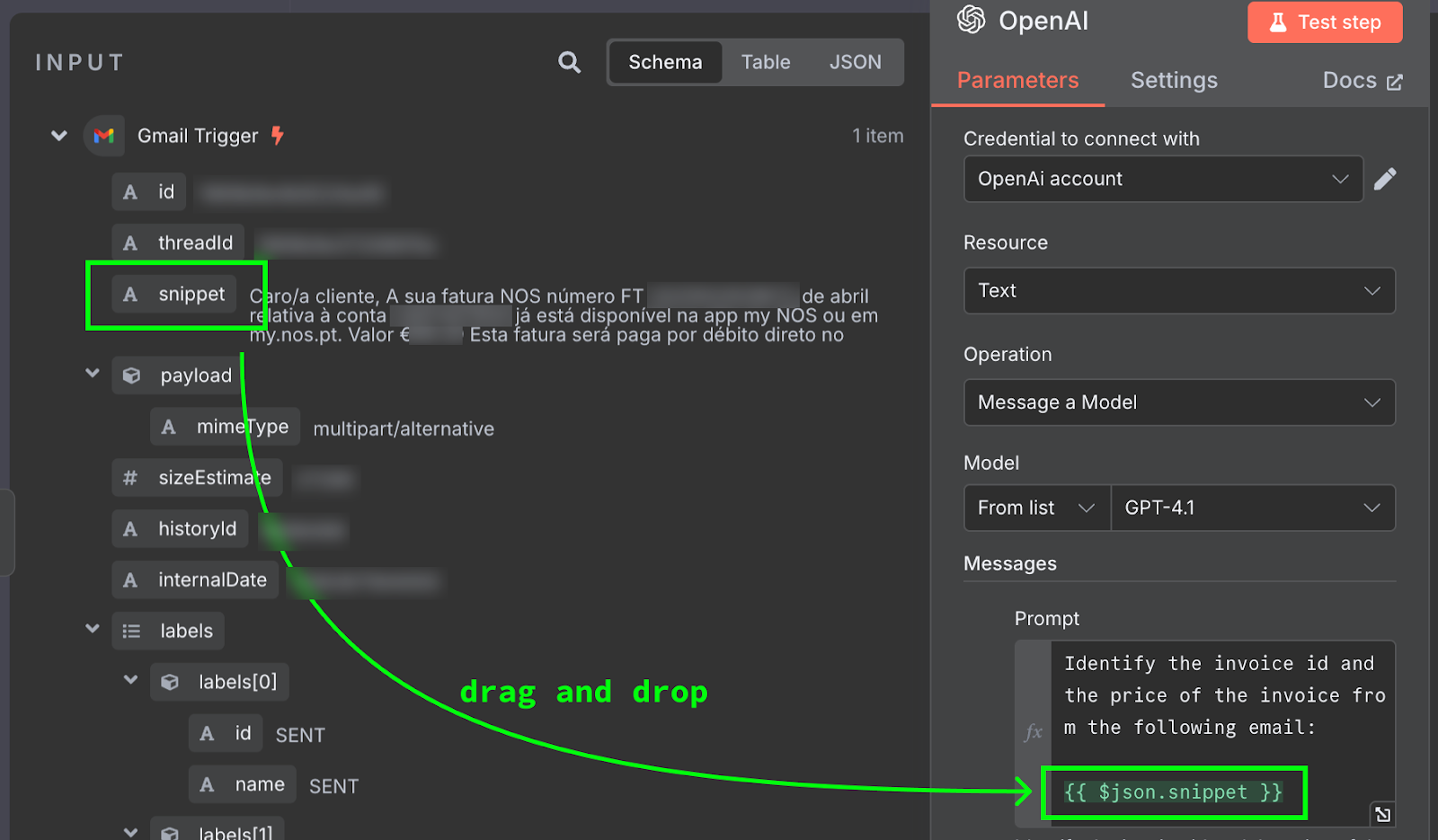
Aby to przetestować, klikamy u góry panelu konfiguracji „Test Step”. Wynik wyświetli się po prawej:
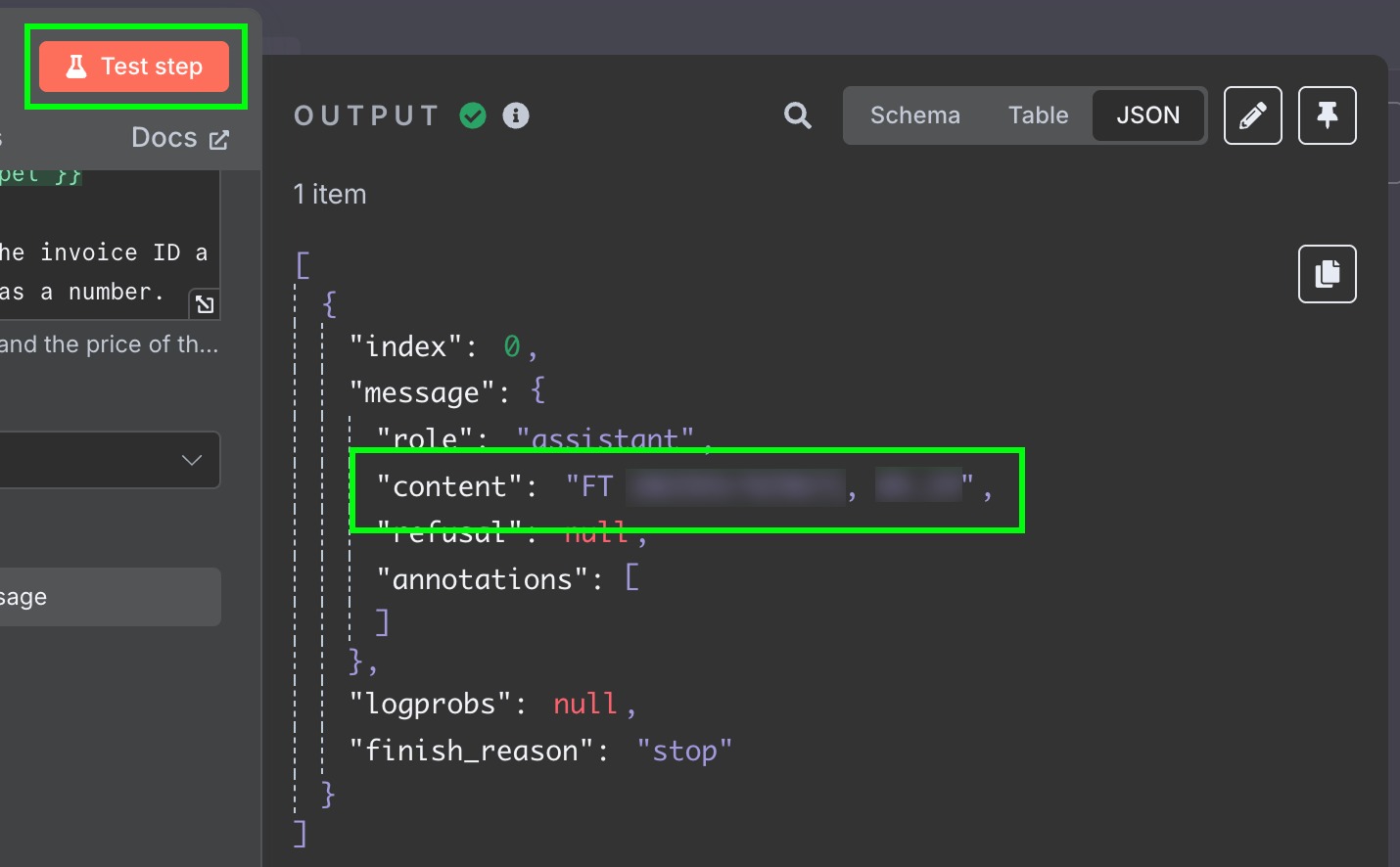
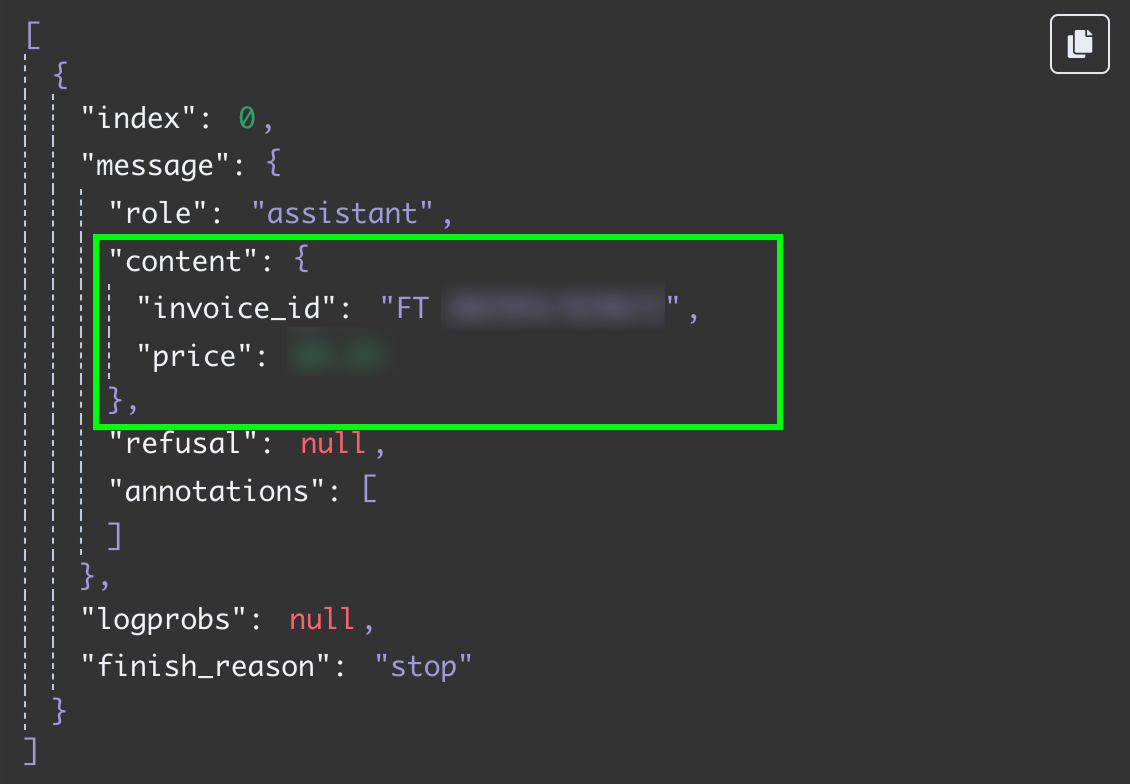
Wynik to string z odpowiedzią modelu. Chcielibyśmy mieć te dwa pola osobno, żeby nie trzeba było dalej parsować wiadomości. Możemy to osiągnąć, zmieniając output LLM na JSON:

Ponownie testując ten krok, otrzymujemy dwa pola jako dane JSON:
Ostatni krok tego przepływu to wysłanie ID faktury i kwoty do nowego wiersza w Google Sheet. Teraz musimy połączyć output węzła OpenAI z Google Sheets. Robimy to jak wcześniej, klikając „+” po lewej stronie węzła:
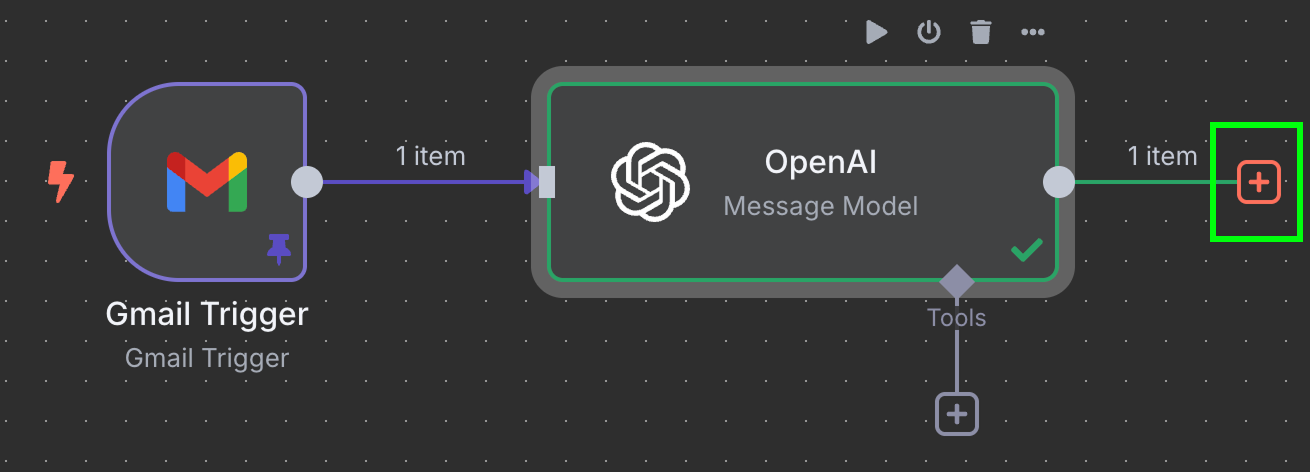
Wpisujemy Google Sheets i wybieramy węzeł „Append row in sheet”:
Możemy użyć tych samych poświadczeń, co do dostępu Gmail. Musimy jednak włączyć następujące API w Google Cloud Console:
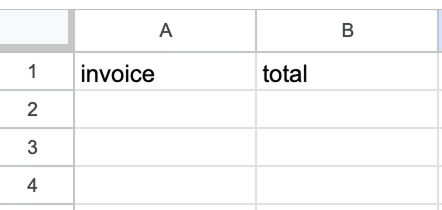
Aby skonfigurować węzeł Google Sheets, musimy wskazać arkusz i wybrać wartości do wypełnienia pól. Arkusz powinien być utworzony ręcznie z dwiema kolumnami — jedna na ID faktury, druga na jej łączną kwotę.
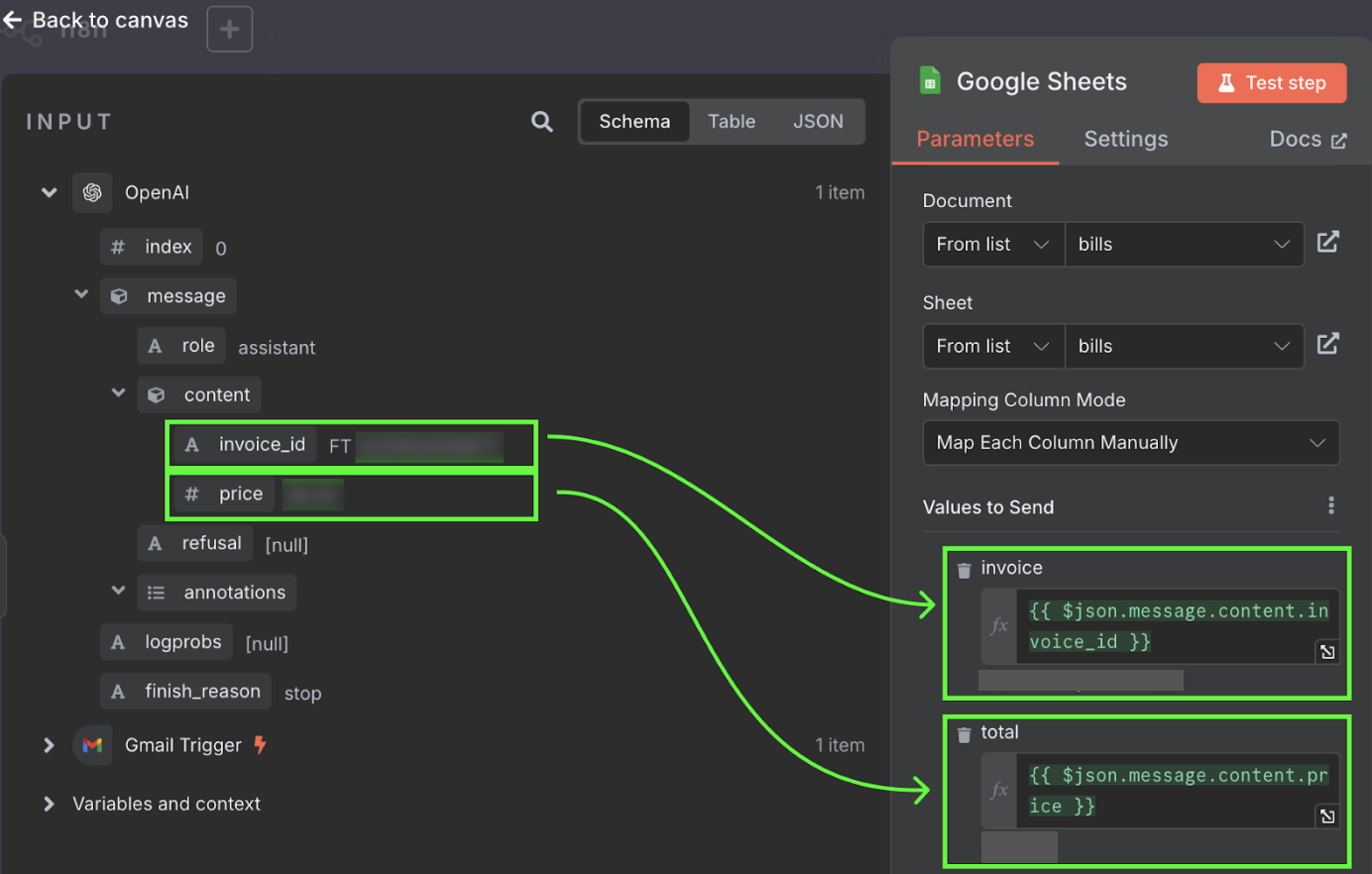
Wartości te pobieramy z outputu węzła OpenAI. Możemy przeciągnąć je do odpowiednich kolumn.
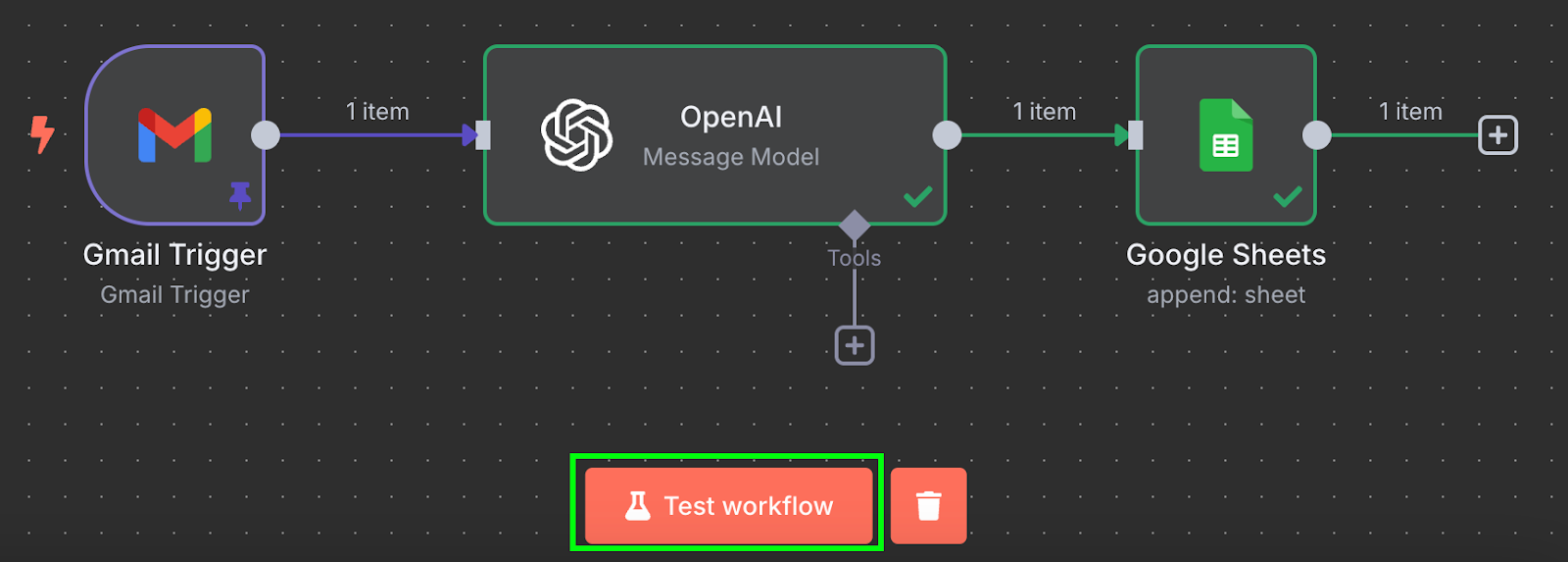
Gotowe! Mamy przepływ, który automatycznie przetwarza faktury do Google Sheet. Możemy go przetestować, klikając „Test workflow” na dole:
Po uruchomieniu, w naszym Google Sheet zobaczymy nowy wiersz z danymi:
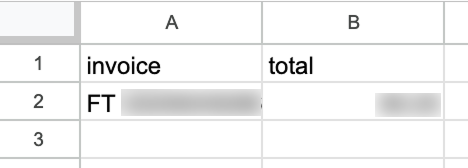
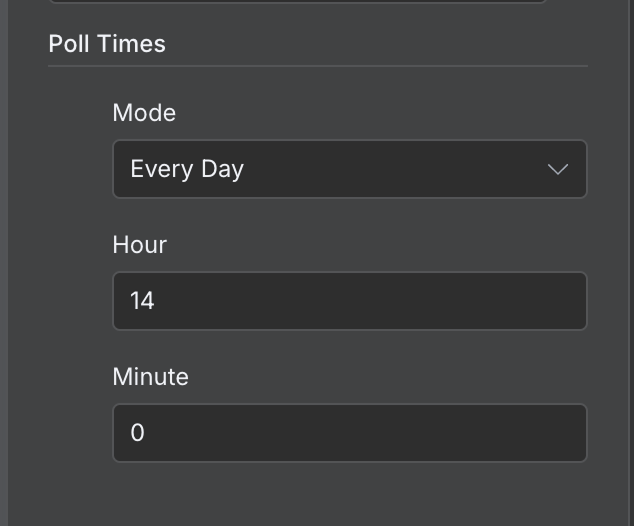
Domyślnie przepływ uruchamia się co minutę. W zależności od przypadku powinniśmy dobrać odpowiednią częstotliwość. W tym przykładzie raz na minutę to zdecydowanie za często. Raz dziennie będzie bardziej odpowiednie.
Możemy to ustawić, dwukrotnie klikając węzeł wyzwalający i zmieniając wartość w polu „Poll Times”:
W tej sekcji zbudujemy bardziej złożony przepływ agenta RAG. RAG to retrieval-augmented generation, technika łącząca wyszukiwanie istotnych informacji z bazy lub dokumentu z generowaniem odpowiedzi przez model językowy na podstawie tego kontekstu.
To bardzo przydatne, gdy mamy specyficzną bazę wiedzy, np. długi dokument, i chcemy zbudować agenta AI, który odpowiada na pytania na jego temat.
Lubię gry planszowe, ale ze znajomymi często spieramy się o zasady i marnujemy czas na ich szukanie zamiast grać — to frustrujące. Zbudowanie agenta RAG opartego na zasadach gry rozwiązuje problem: następnym razem po prostu spytamy agenta.
Aby go zbudować, przygotujemy dwa przepływy:
Pinecone to baza danych operująca na wektorach. Taka baza idealnie nadaje się do naszego agenta RAG, bo pozwala szybko wyszukać i zrozumieć istotne informacje, zwiększając trafność odpowiedzi.
Ponieważ ten przepływ uruchamiamy tylko raz, możemy użyć manual trigger. To węzeł do ręcznego uruchamiania przepływu.
Połącz manual trigger z węzłem „Google Drive”, aby pobrać dane z Dysku Google.

Użyj następującej konfiguracji:
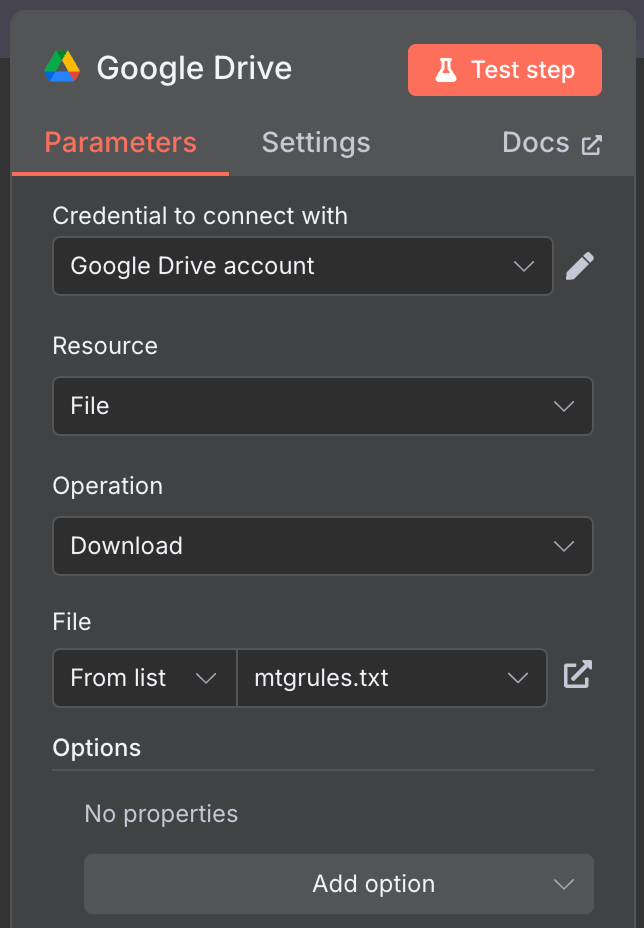
Użyłem publicznie dostępnego pliku mtgrules.txt z zasadami gry karcianej Magic: The Gathering. Ty możesz użyć dowolnego pliku, o który chcesz pytać — przepływ pozostaje ten sam.
Aby skonfigurować Pinecone, zaloguj się do Pinecone, skopiuj klucz API i utwórz indeks przyciskiem „Create index”. Mój indeks nazwałem rules i wybrałem model text-embedding-3-small.

Wracając do n8n, połącz output węzła Google Drive z węzłem Pinecone Vector Store i akcją „Add documents to vector store”:
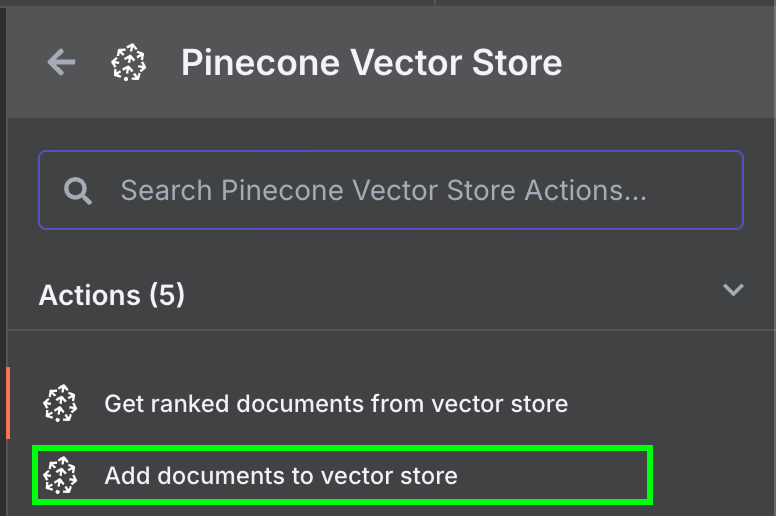
Aby go skonfigurować, musimy utworzyć poświadczenia, wklejając klucz API, i wybrać indeks Pinecone, który właśnie stworzyliśmy. Pod węzłem Pinecone Vector Store widać dwie rzeczy do konfiguracji: model embedding i loader danych.
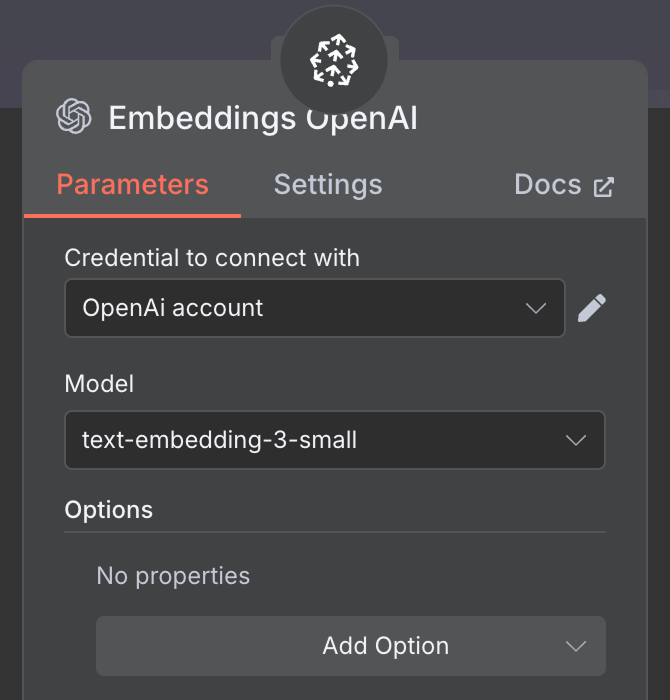
Dla embeddingu utwórz węzeł OpenAI Embedding z modelem text-embedding-3-small:
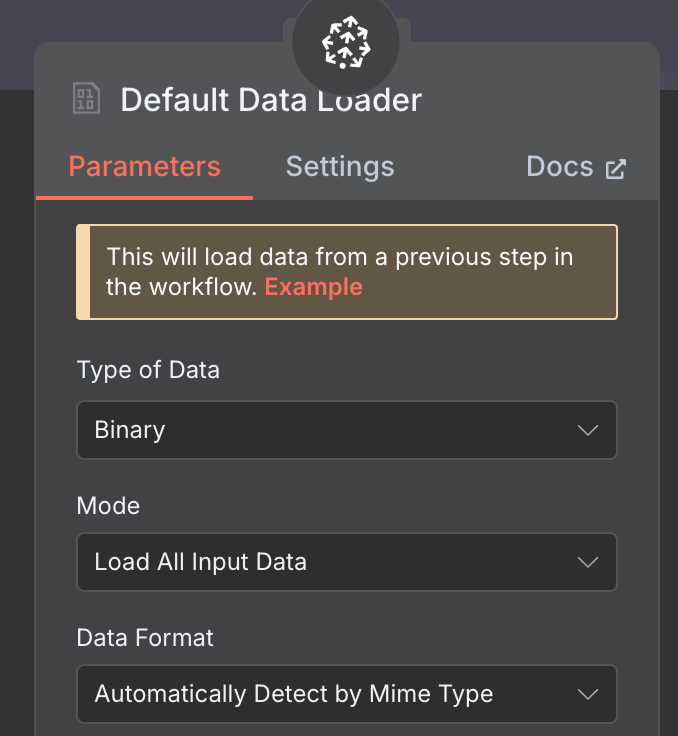
Dla loadera danych tworzymy węzeł Default Data Loader z typem danych binarnych:
Na końcu loader wymaga węzła Text Splitter, który określa, jak dzielić dane z pliku przy tworzeniu vector store. Używamy Recursive Character Text Splitter — zalecanego w większości przypadków.
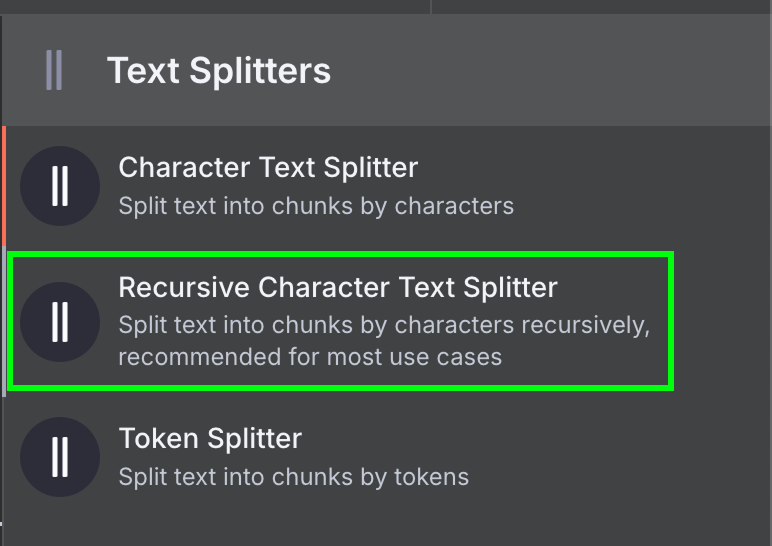
Konfigurujemy go na wielkość fragmentu 1000 i nakładanie 200:
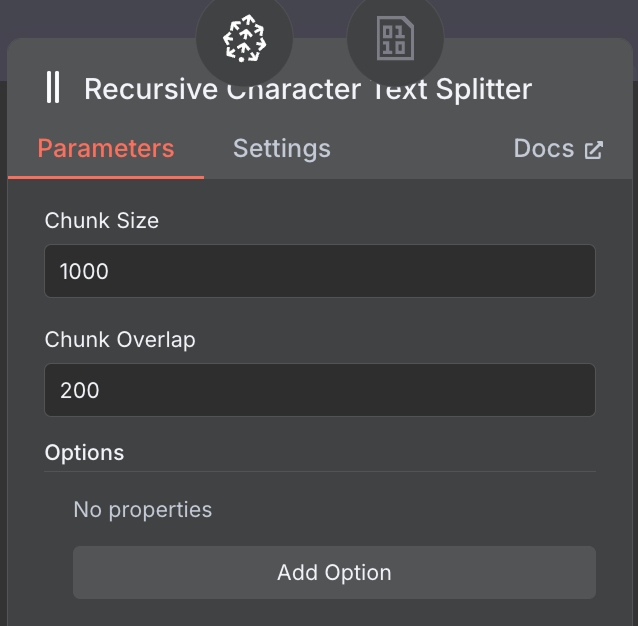
Wybierając rozmiar fragmentów i nakładanie, rozważ większe fragmenty dla długich dokumentów, by uchwycić wystarczającą treść, oraz mniejsze nakładanie, by utrzymać kontekst między częściami bez nadmiaru.
Tak wygląda finalny przepływ:
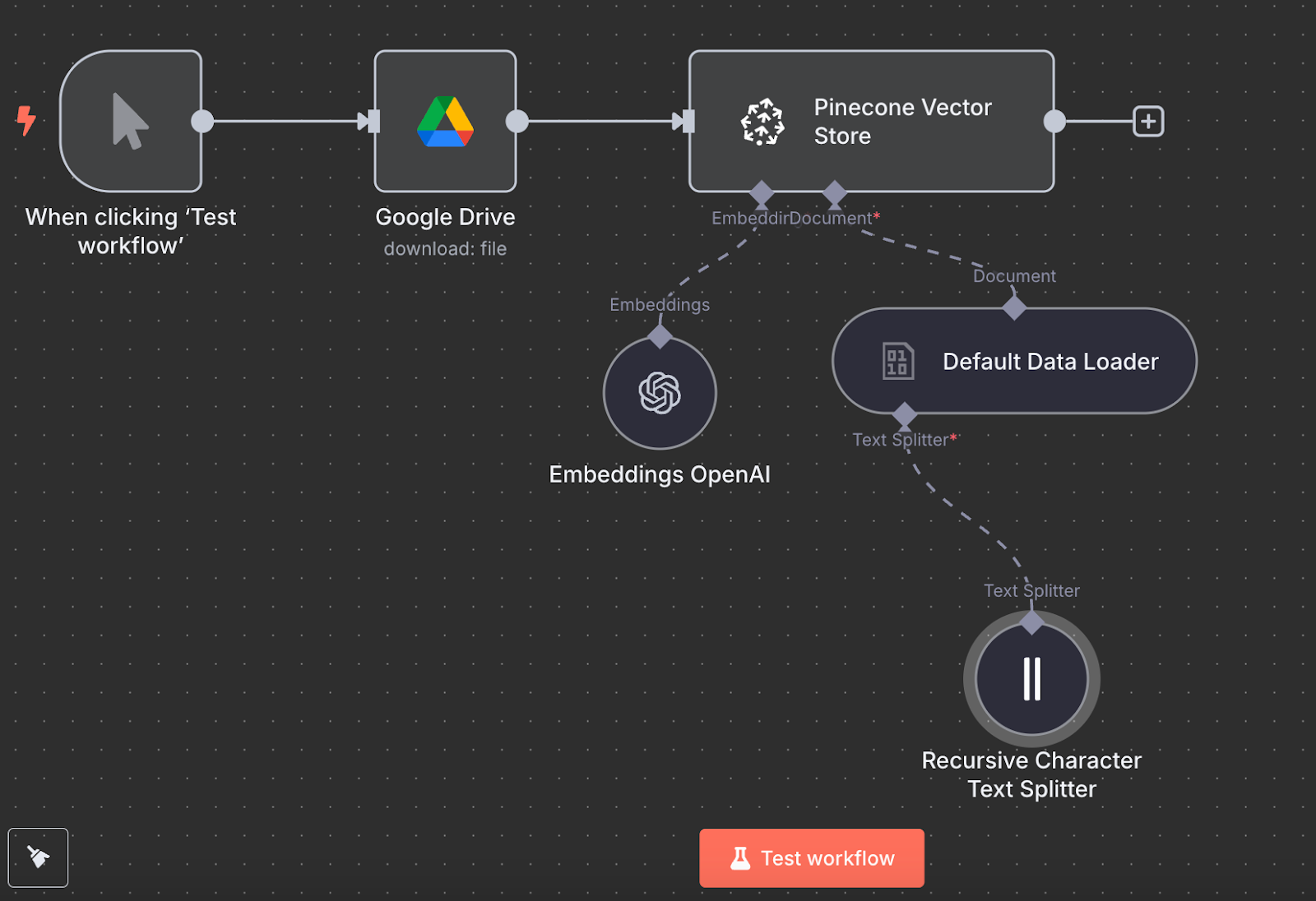
Uruchamiamy go, klikając „Test workflow”, a po zakończeniu możemy zweryfikować w Pinecone, że dane zostały wgrane.
Oto finalny schemat agenta RAG:
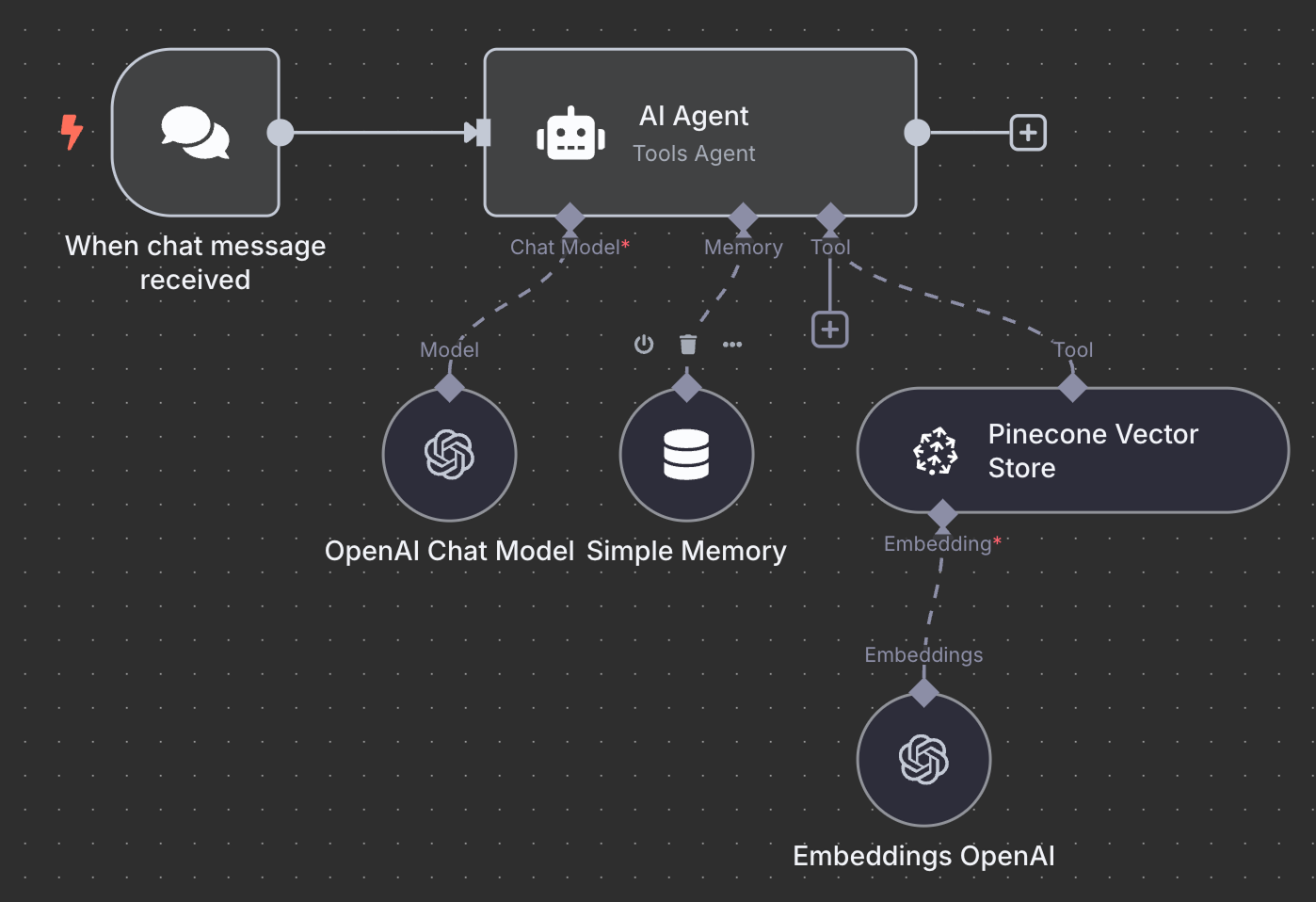
Jako ćwiczenie zachęcam cię, by spróbować go zrozumieć, a może nawet odtworzyć lokalnie, zanim czytasz dalej.
Zaczynamy od wyzwalacza „On chat message”. Służy on do tworzenia przepływu czatu.
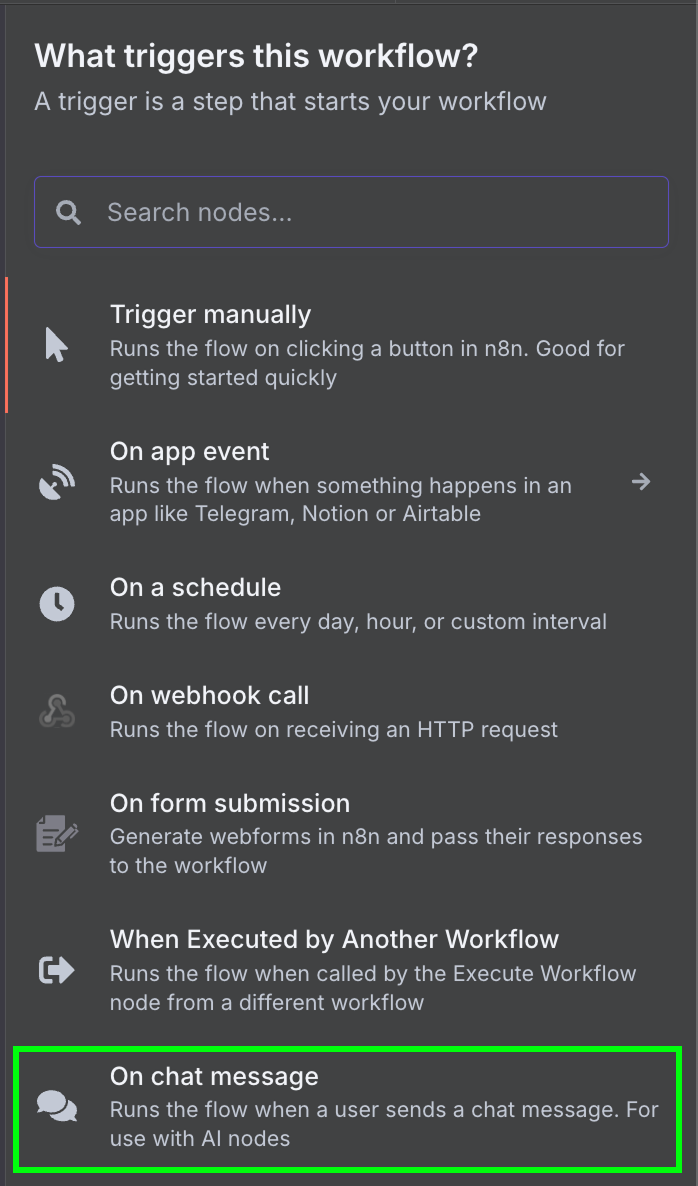
Następnie łączymy wyzwalacz czatu z węzłem „AI Agent” z domyślnymi opcjami.
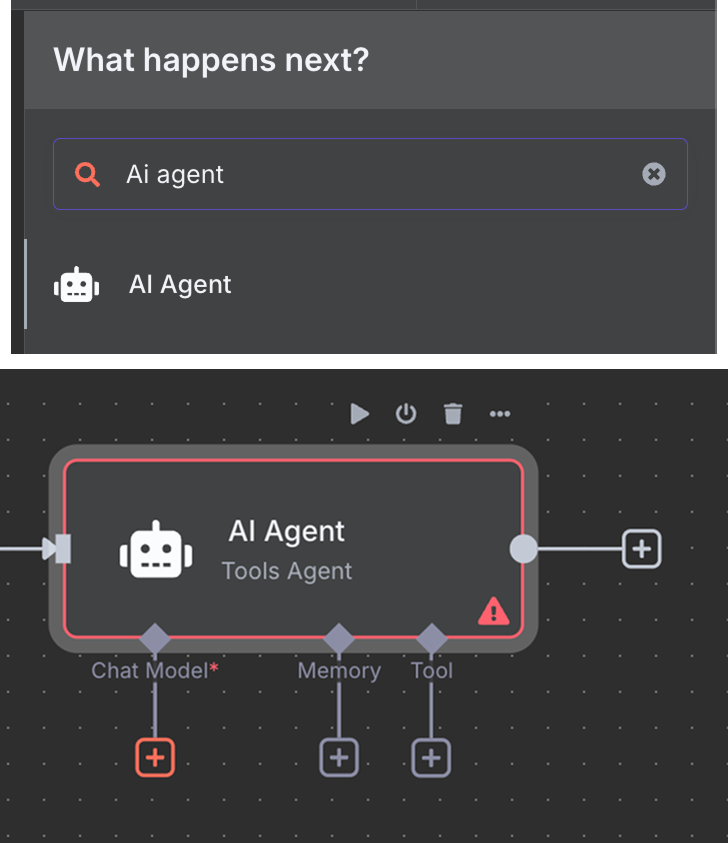
Poniżej AI Agenta możemy skonfigurować trzy rzeczy:
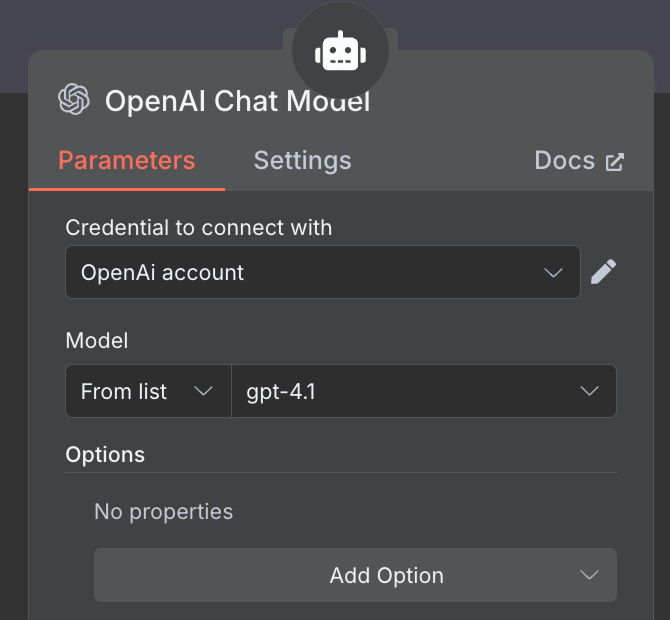
Jako model AI wybieramy węzeł „OpenAI Chat Model” i używamy GPT‑4.1, jak wcześniej. Rodzina GPT‑5 jest obecnie najnowsza u OpenAI, ale 4.1 ma okno kontekstu 1M tokenów i dobrze sprawdza się w RAG.
Jako pamięć używamy „Simple Memory” z oknem kontekstu długości 5. To znaczy, że agent będzie pamiętał i brał pod uwagę pięć poprzednich interakcji przy odpowiadaniu.
Na koniec jako narzędzie dodajemy „Pinecone Vector Store” z następującą konfiguracją:
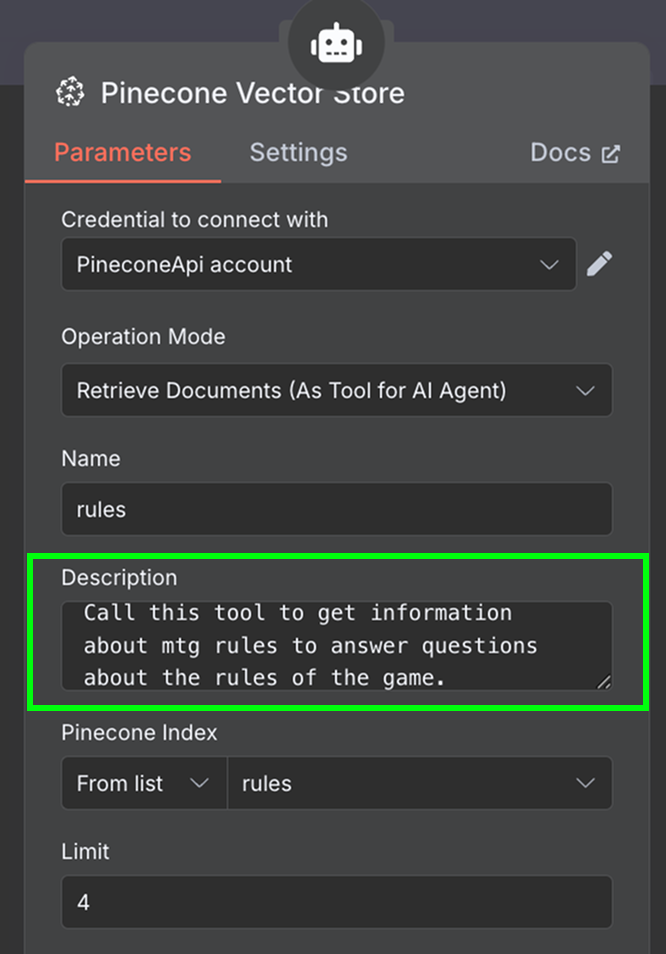
W polu opisu ważne jest określenie, kiedy narzędzie powinno być używane. Agent wykorzysta to do decyzji, czy wywołać narzędzie.
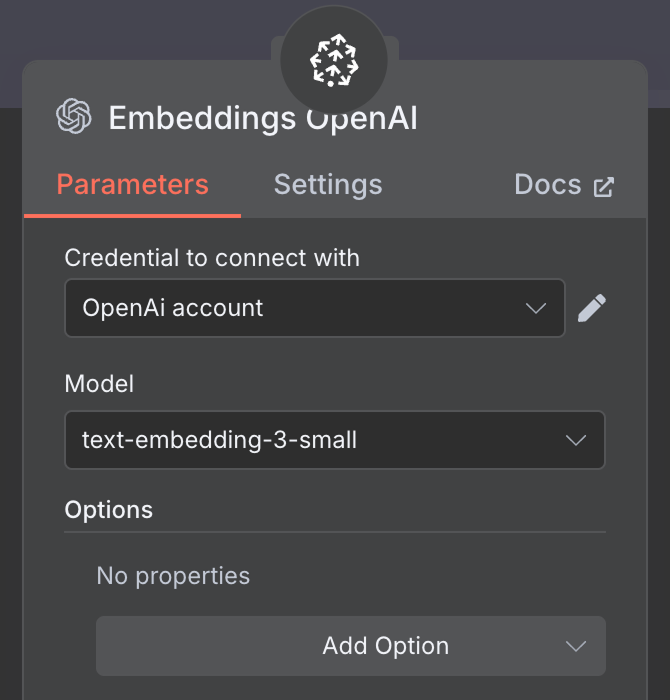
Ostatnia rzecz to konfiguracja embeddingu używanego przez vector store. Jak wcześniej, używamy węzła OpenAI Embedding z modelem text-embedding-3-small:
Przepływ jest kompletny i możemy rozmawiać z agentem. Oto przykład:
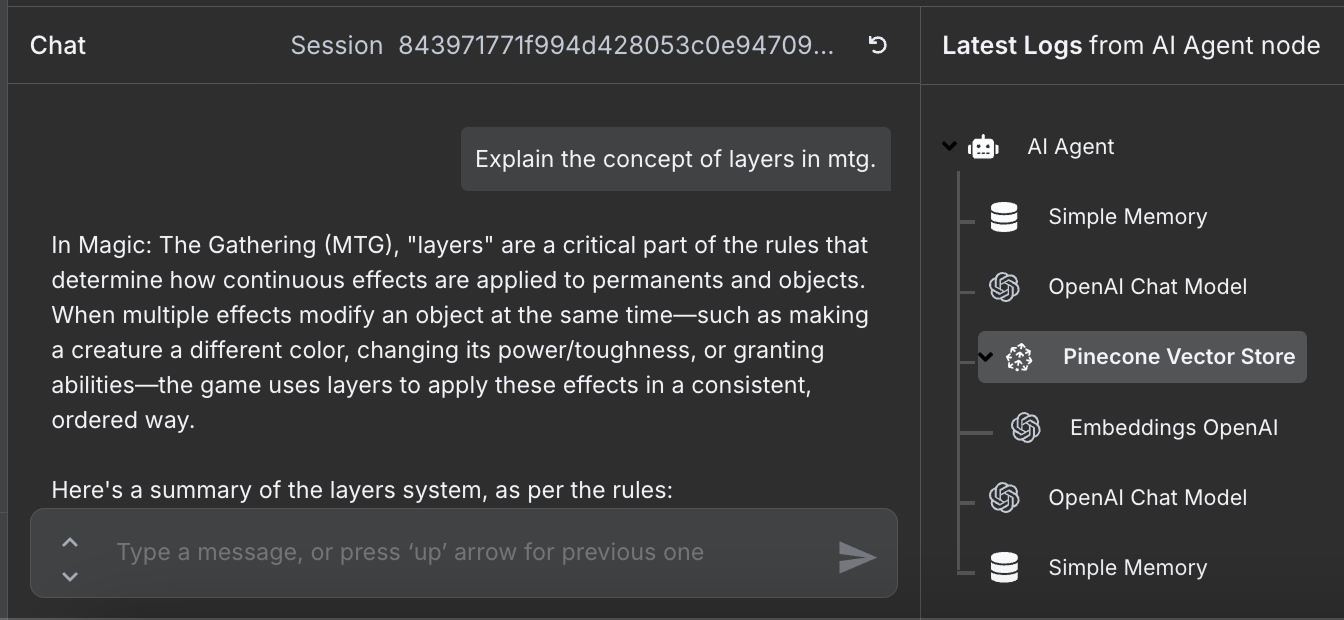
Po prawej widać kroki, które agent wykonał, by odpowiedzieć na nasze pytanie. W szczególności sięgnął do bazy Pinecone po odpowiednie informacje o zasadach.
n8n oferuje funkcję, która może znacząco przyspieszyć tworzenie przepływów: bibliotekę szablonów n8n.
To kolekcja gotowych przepływów, tworzonych przez społeczność i ekspertów n8n. Niezależnie, czy automatyzujemy proste zadanie, czy złożony proces, istnieje duża szansa, że ktoś już przygotował odpowiedni przepływ.
Importowanie przepływu do naszej instancji n8n oznacza, że nie zawsze musimy zaczynać od zera. Możemy skorzystać z gotowych rozwiązań innych użytkowników. Po imporcie wystarczy podać własne poświadczenia i dostosować szczegóły do naszych potrzeb.
Dla niemal każdego zadania, które chcesz zautomatyzować — od przetwarzania e‑maili po zarządzanie social mediami — w bibliotece prawdopodobnie znajdziesz szablon.
n8n oferuje ogromny ekosystem integracji, pozwalając łączyć ponad tysiąc usług i narzędzi, by tworzyć agentów AI. W tym tutorialu jedynie zarysowaliśmy możliwości n8n. Eksplorując budowę agentów AI do automatyzacji codziennych zadań, dopiero zaczęliśmy wykorzystywać jego potencjał.
Ucz się AI z tymi kursami!
Track
course
course