
Leerpad
AI-toepassingen ontwikkelen
21 Hr
n8n is uitgegroeid tot een populair en krachtig framework in agentische AI. Het stelt ons in staat geautomatiseerde workflows te bouwen zonder complexe code.
In dit artikel leg ik stap voor stap uit hoe je het maximale uit dit robuuste platform haalt om twee verschillende processen te automatiseren:
We houden onze lezers op de hoogte van het laatste AI-nieuws met The Median, onze gratis vrijdagse nieuwsbrief die de belangrijkste verhalen van de week samenvat. Abonneer je en blijf scherp met slechts een paar minuten per week:
n8n is een open-source automatiseringstool die ons helpt verschillende apps en services te koppelen om workflows te creëren, vergelijkbaar met een digitale assemblagelijn. Je ontwerpt deze workflows visueel met nodes, die elk een stap in het proces voorstellen.
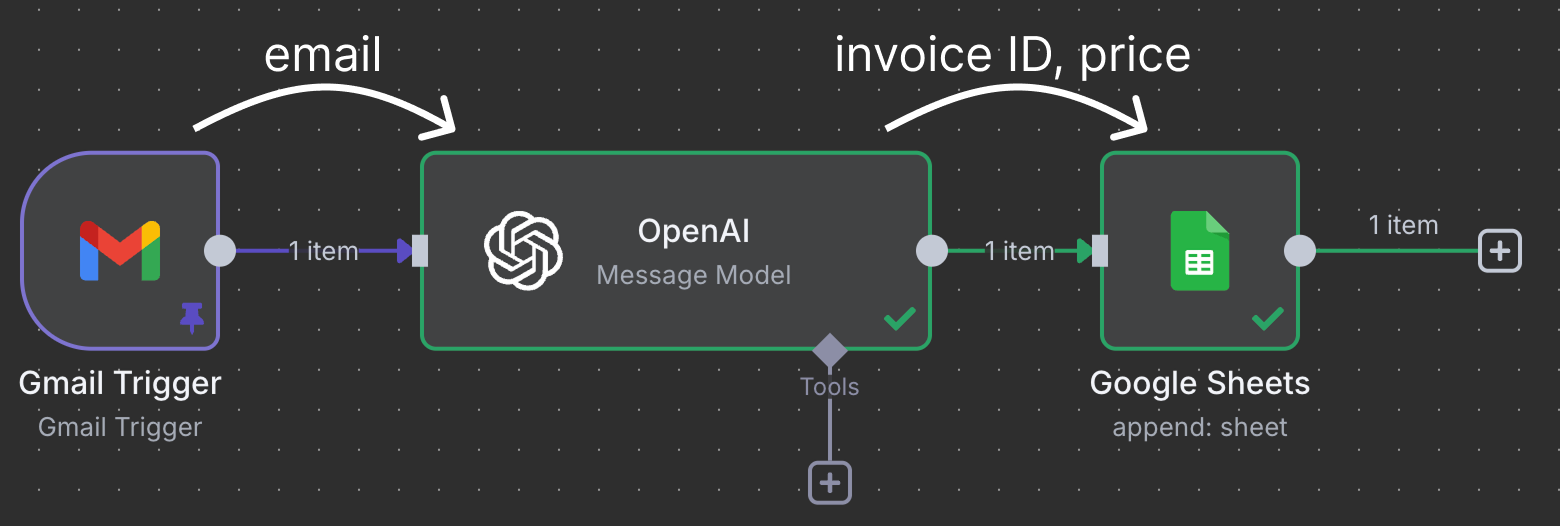
Met n8n kunnen we taken automatiseren, datastromen beheren en zelfs API's integreren, zonder uitgebreide programmeerkennis. Hier is een voorbeeld van een automatisering die we in deze tutorial bouwen:
Zonder in details te treden, is dit wat deze automatisering doet:
We hebben twee opties om n8n te gebruiken:
Met beide opties kun je deze tutorial kosteloos volgen. Wij draaien het lokaal, maar als je liever de webinterface gebruikt, zijn de stappen hetzelfde.
Opmerking: n8n 2.0 verscheen eind 2025 en introduceerde een Draft/Publish-workflowsysteem, autosave (januari 2026), een vernieuwd focuspaneel om nodes te bewerken zonder canvascontext te verliezen, en Task Runners die workflow-uitvoering isoleren voor betere beveiliging.
De onderstaande workflows draaien op 2.x — gebruik je 1.x, overweeg dan te upgraden voordat je verdergaat.
De officiële n8n-repository legt uit hoe je n8n lokaal instelt. De eenvoudigste manier is:
Download en installeer Node.js via de officiële website.
Open een terminal en voer het commando npx n8n uit.
Dat is alles! Na het uitvoeren van het commando zou je dit in de terminal moeten zien:
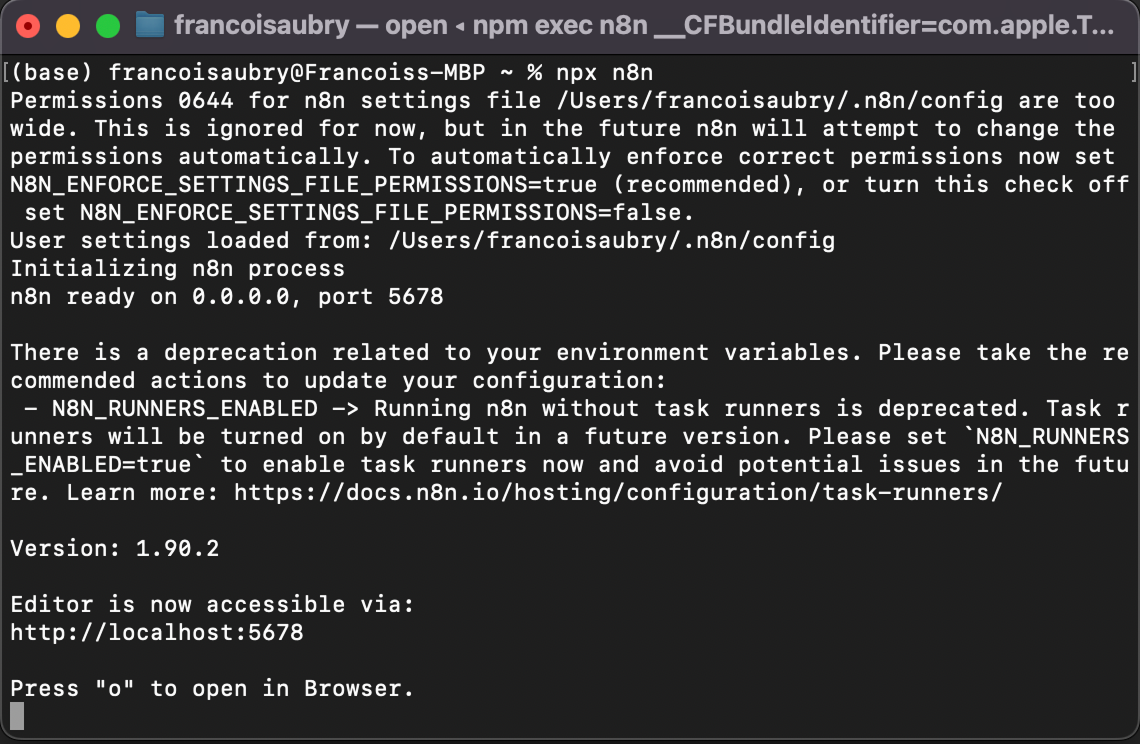
Om de interface te openen, druk je op "o" op je toetsenbord of open je de localhost-URL die in de terminal wordt weergegeven—bij mij is dat http://localhost:5678.
Voordat we onze eerste automatisering bouwen, is het goed te begrijpen hoe n8n werkt. Een n8n-workflow bestaat uit een reeks nodes. Het begint met een trigger-node die een voorwaarde opgeeft voor het uitvoeren van de workflow.
Nodes zijn met elkaar verbonden om data te verplaatsen en te verwerken. In dit voorbeeld is de Gmail-trigger-node verbonden met een OpenAI-node. Dit betekent dat de e-mail aan ChatGPT wordt gegeven voor verwerking. Tot slot wordt de output van ChatGPT naar een Google Sheet-node gestuurd, die verbinding maakt met een Google Sheet in onze Google Drive en een nieuwe regel in een spreadsheet schrijft.
Deze specifieke workflow gebruikt ChatGPT om facturen te identificeren die moeten worden betaald en voegt een regel toe aan het sheet met het factuurnummer en het bedrag.
n8n-workflows kunnen veel complexer zijn. n8n ondersteunt meer dan 400 officiële integraties (core-nodes), plus 600+ community-nodes en aangepaste koppelingen via de HTTP Request-node — dus we kunnen ze niet allemaal behandelen in een tutorial.
In plaats daarvan geef ik je een algemeen beeld van hoe het werkt en genoeg achtergrond om het zelf te verkennen. Als er een tool is die je vaak gebruikt, is de kans groot dat n8n die ondersteunt of dat je die handmatig kunt integreren.
In deze sectie leren we hoe we de bovenstaande workflow bouwen.
Dit is een echt gebruiksscenario dat ik inzet om mijn huurfacturen te beheren. Ik heb een huis met een paar kamers die ik verhuur. De rekeningen worden gelijk verdeeld over alle huurders. Telkens wanneer ik een factuur ontvang, moet ik het totaalbedrag toevoegen aan een spreadsheet die ik deel met mijn huurders.
Ik heb een specifiek e-mailadres waarnaar facturen voor huishoudrekeningen worden doorgestuurd. Zo weet ik dat alle e-mails in die mailbox overeenkomen met een factuur. Ik stuur de inhoud van de e-mail naar ChatGPT om het factuurnummer en het totaalbedrag te identificeren. Vervolgens wordt deze informatie toegevoegd aan een nieuwe rij in de gedeelde spreadsheet.
Om een nieuwe workflow te starten, klikken we op de knop "Add first step...".

Omdat het de eerste node is, moet het een trigger zijn, dus krijgen we een paneel om een trigger-node te selecteren. Een trigger-node definieert de voorwaarden voor het uitvoeren van de workflow.
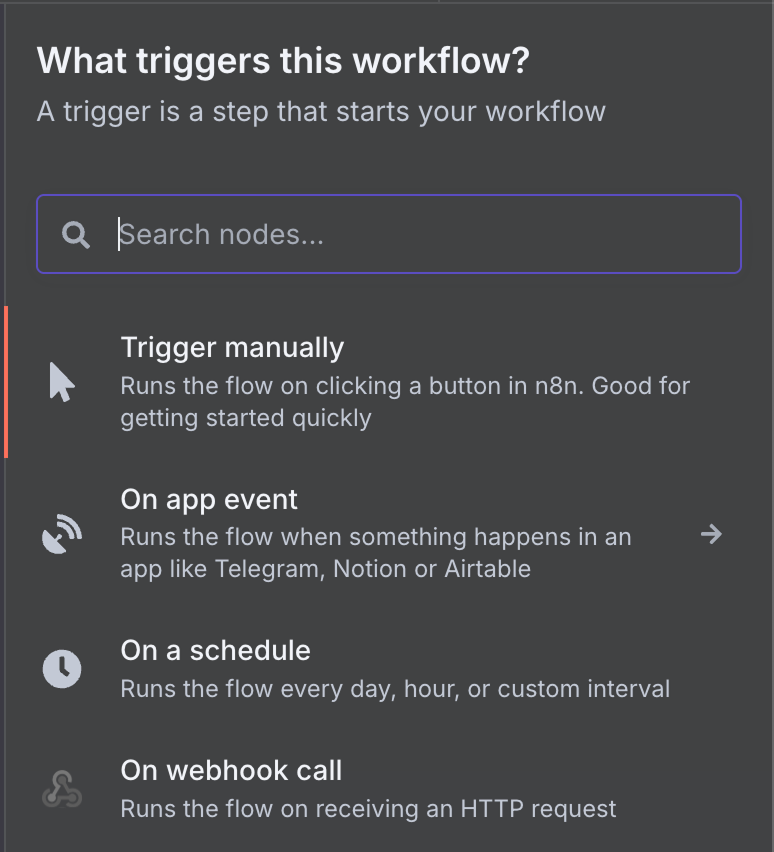
Er is een brede waaier aan mogelijke trigger-nodes. Laten we een Gmail-trigger-node kiezen door "gmail" in het zoekvak te typen en op de Gmail-node te klikken.
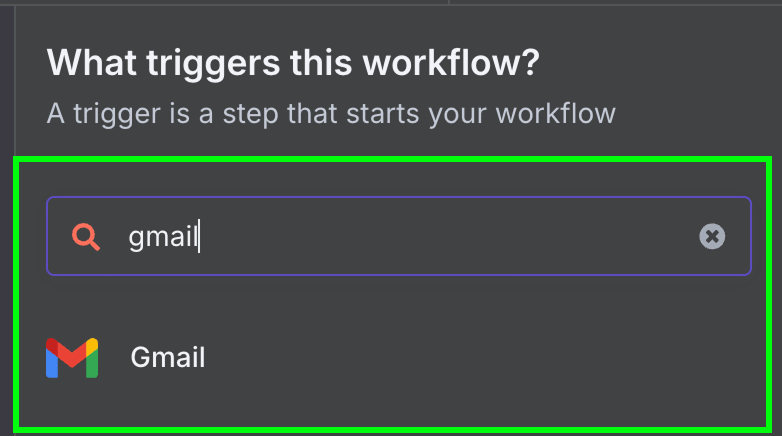
Vervolgens kiezen we de enige beschikbare trigger voor Gmail: "On message received".

Dit opent het configuratiepaneel van de node, waar we onze Gmail-credentials moeten configureren zodat de n8n-workflow toegang heeft tot onze Gmail-account. Klik daarvoor op "New credential". Dit opent het volgende venster:
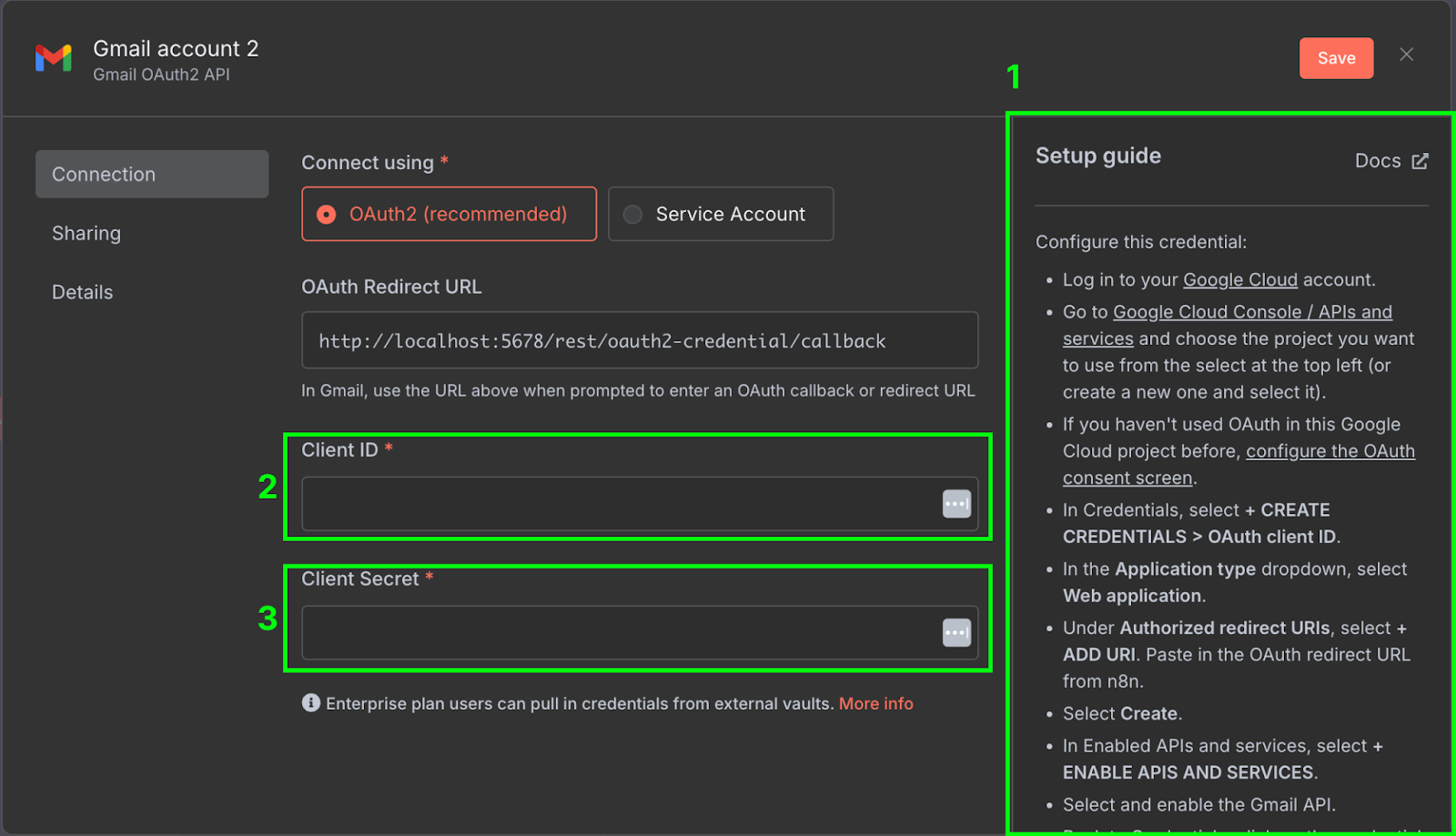
Aan de rechterkant (1) staat een installatiegids met de stappen om de credentials te configureren op Google Cloud. De handleidingen van n8n zijn vrij compleet, dus we herhalen de stappen hier niet. Zorg er ook voor dat je de Gmail API inschakelt in de Google Cloud Console.
Zodra dit is ingesteld, kopiëren we de client-ID (2) en client secret (3) uit Google Cloud naar de credentialconfiguratie van n8n.
Om te controleren of alles goed is geconfigureerd, kunnen we de node testen door op "Fetch Test Event" te klikken.

Na de test zouden we in de outputsectie de laatste e-mail moeten zien die we in onze inbox hebben ontvangen. De inhoud van de e-mail staat in het veld snippet.
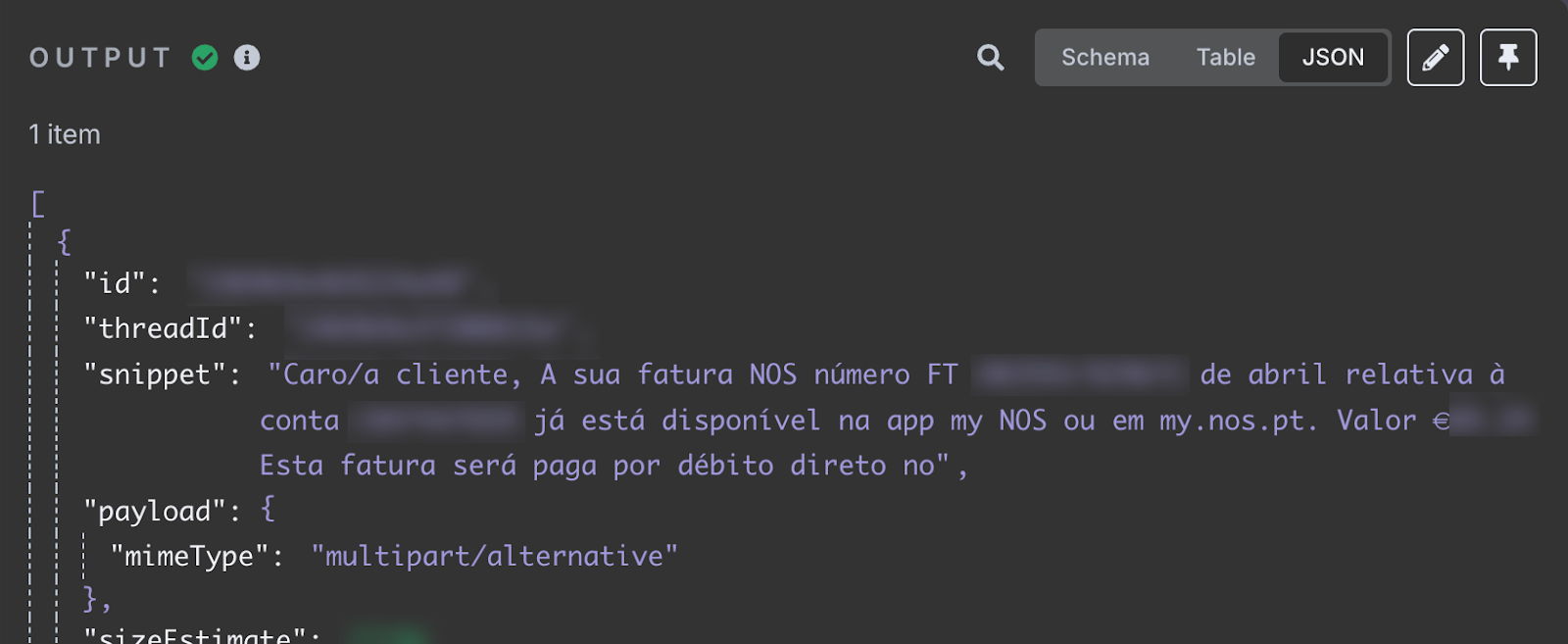
Het veld snippet bevat de e-mailinhoud. Daarin staat dat mijn internetfactuur voor april beschikbaar is. Het geeft het factuurnummer en het totaalbedrag dat moet worden betaald. Dit is de informatie die we aan het spreadsheet willen toevoegen.
Voor testdoeleinden raad ik aan de output te pinnen door op de pin-knop rechtsboven te klikken:
Dit vergrendelt het resultaat aan de trigger, wat betekent dat telkens wanneer we deze workflow draaien, dezelfde output wordt gebruikt. Zo is het eenvoudiger te testen, omdat nieuwe e-mails de resultaten niet beïnvloeden. We unpinnen dit zodra de workflow goed is ingesteld.
In dit stadium zou onze workflow één trigger-node moeten hebben (je herkent een trigger-node aan het kleine bliksemschicht-icoontje links).

Merk op dat je waarschijnlijk geen e-mailfactuur in je mailbox hebt, waardoor ChatGPT je later mogelijk een nietszeggend antwoord geeft. Als je precies deze workflow wilt testen, kun je jezelf een testmail sturen met de volgende inhoud (of iets dergelijks):
Dear customer,
Your internet invoice number FT 2025**/****** for April is now available in the attachment.
Amount
€**.**
This invoice must be paid by 19/05/2025.Nadat je dit hebt verstuurd, moet je het resultaat unpinnen, de Gmail-node opnieuw draaien en het nieuwe resultaat pinnen.
De volgende stap is het configureren van de OpenAI-node. Begin door op de "+"-knop rechts van de Gmail-trigger-node te klikken:

Typ "OpenAI" en selecteer de overeenkomstige optie uit de lijst.
Kies daarna onder "Text Actions" de node "Message a model". Deze node gebruik je om een LLM een bericht te sturen.

Zoals eerder moeten we een credential aanmaken om toegang te krijgen tot OpenAI. Let op: zodra een credential is aangemaakt, kun je die hergebruiken in elke workflow. Je hoeft dit niet elke keer opnieuw in te stellen.
Voor de OpenAI-credential hebben we alleen een API-sleutel nodig. Als je die niet hebt, kun je er hier een aanmaken. Als dit niet lukt, heeft n8n hier ook een handleiding voor.
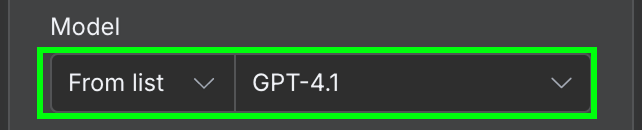
Qua configuratie selecteren we het AI-model dat we willen gebruiken en het bericht dat we naar het model sturen.
Voor het model gebruiken we GPT-4.1. OpenAI heeft sindsdien de GPT-5-familie uitgebracht (5.4, 5.4-mini, 5.5) en 4.1 uit ChatGPT gehaald, maar via de API is het nog beschikbaar en ruim voldoende voor eenvoudige extractie zoals dit.
In het message-veld geven we de prompt op. In dit voorbeeld geven we het model de inhoud van de e-mail en vragen we het om het factuurnummer en het totaalbedrag te identificeren. Dit is de prompt die ik gebruikte:
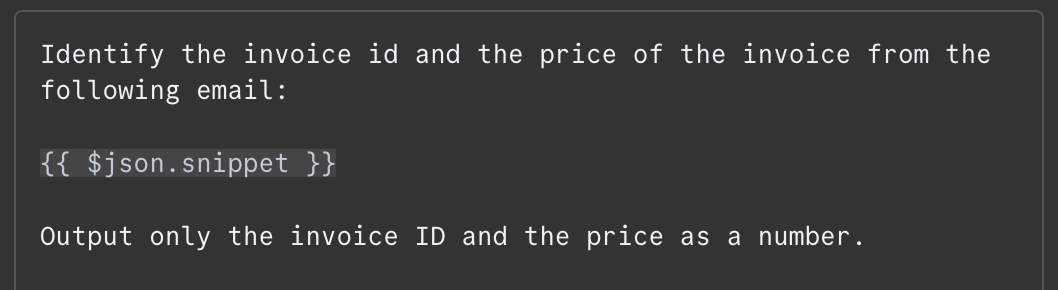
De inhoud van de e-mail wordt doorgegeven als {{ $json.snippet }}. In n8n kan de prompt variabelen bevatten die worden ingevuld met de output van eerdere nodes — in ons geval de e-mail. De lijst met beschikbare velden staat links. Je kunt het veld handmatig typen of slepen en neerzetten in de prompt.
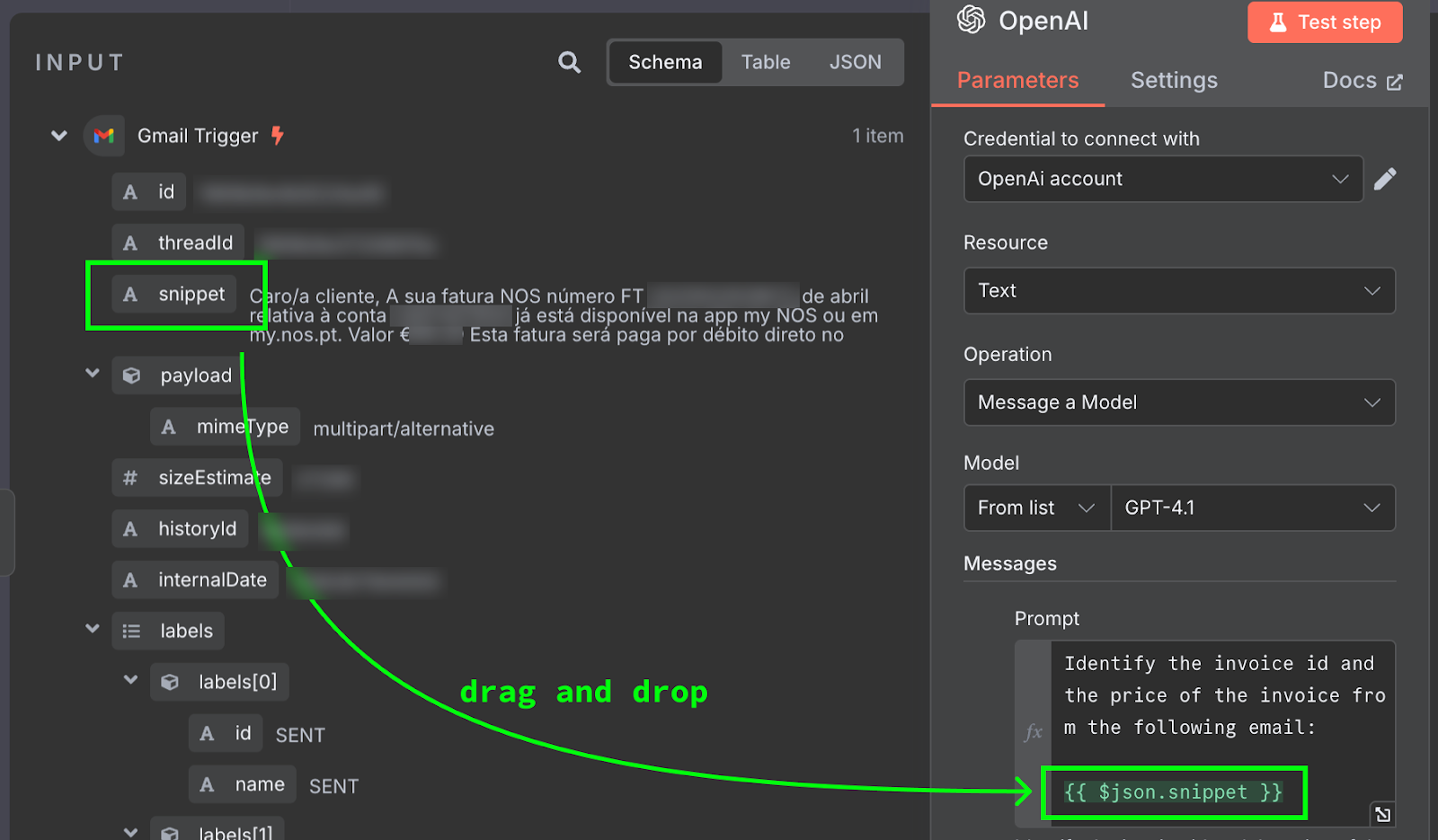
Om dit te testen, klikken we bovenaan het configuratiepaneel op de knop "Test Step". Het resultaat wordt rechts weergegeven:
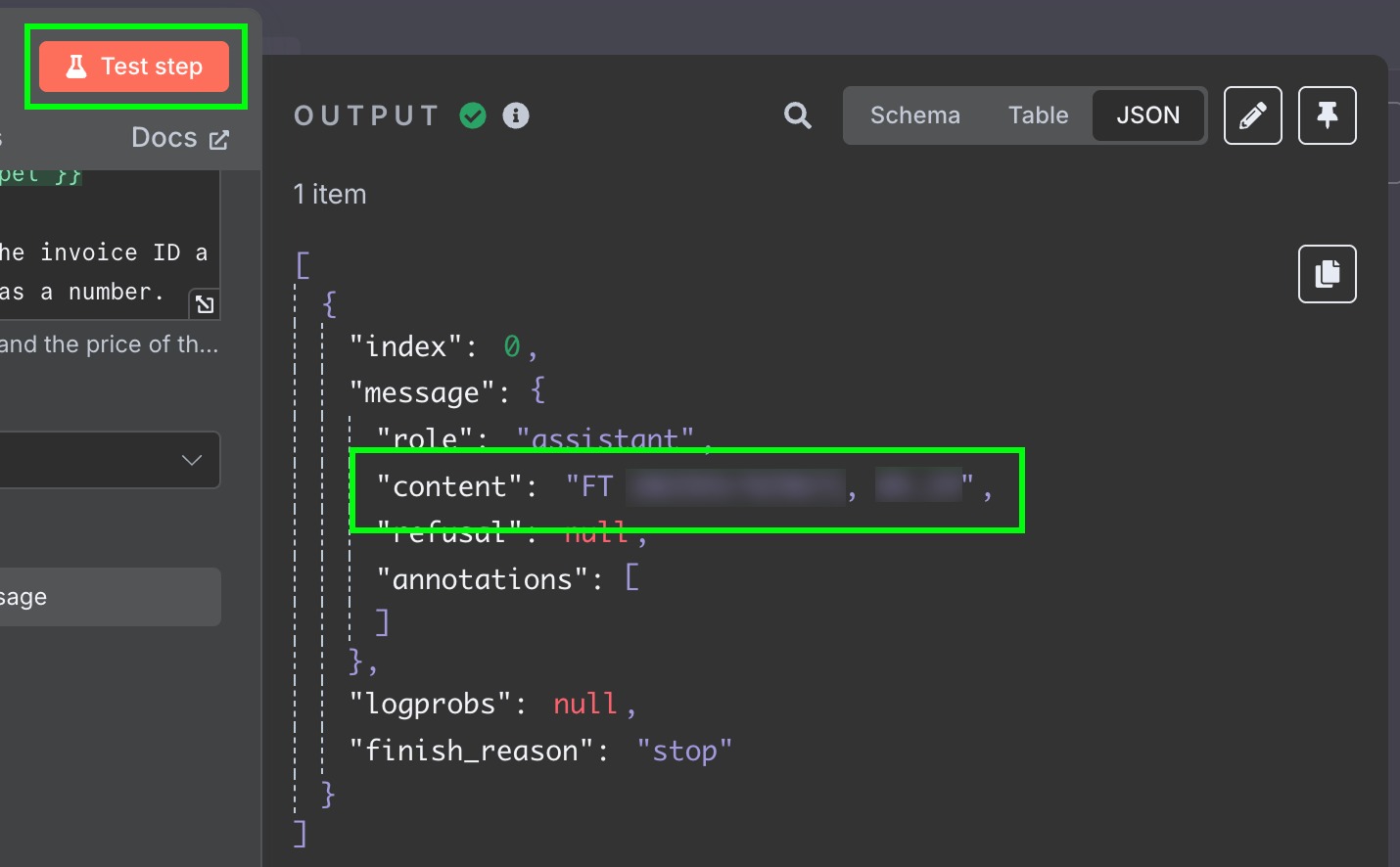
Het resultaat is een string met het antwoord van het model. We willen de twee velden graag apart hebben, zodat we het bericht niet verder hoeven te verwerken. Dat kan door de output van de LLM te wijzigen naar JSON:

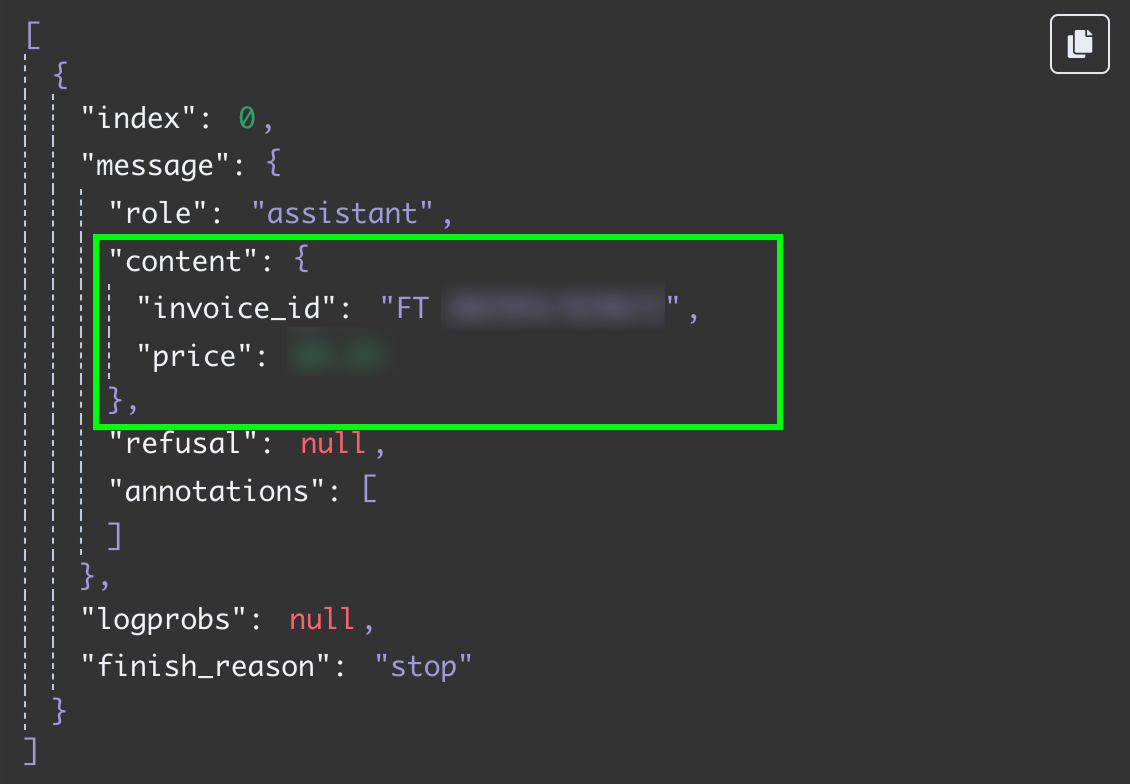
Als we deze stap opnieuw testen, krijgen we de twee velden als JSON-data:
De laatste stap in deze workflow is het factuurnummer en bedrag naar een nieuwe rij in een Google Sheet sturen. Op dit punt moeten we de output van de OpenAI-node verbinden met Google Sheets. Dat doen we zoals eerder door op de "+"-knop links van de node te klikken:
Hier typen we Google Sheets en selecteren we de node "Append row in sheet":
We kunnen dezelfde credentials gebruiken als voor Gmail-toegang. Maar we moeten de volgende API's inschakelen in de Google Cloud Console:
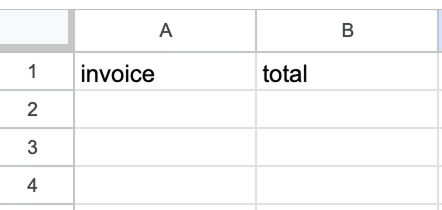
Om de Google Sheets-node te configureren, selecteren we het sheet en kiezen we de waarden om de velden te vullen. Het sheet moet handmatig worden aangemaakt met twee kolommen: één voor het factuurnummer en één voor het totaalbedrag.
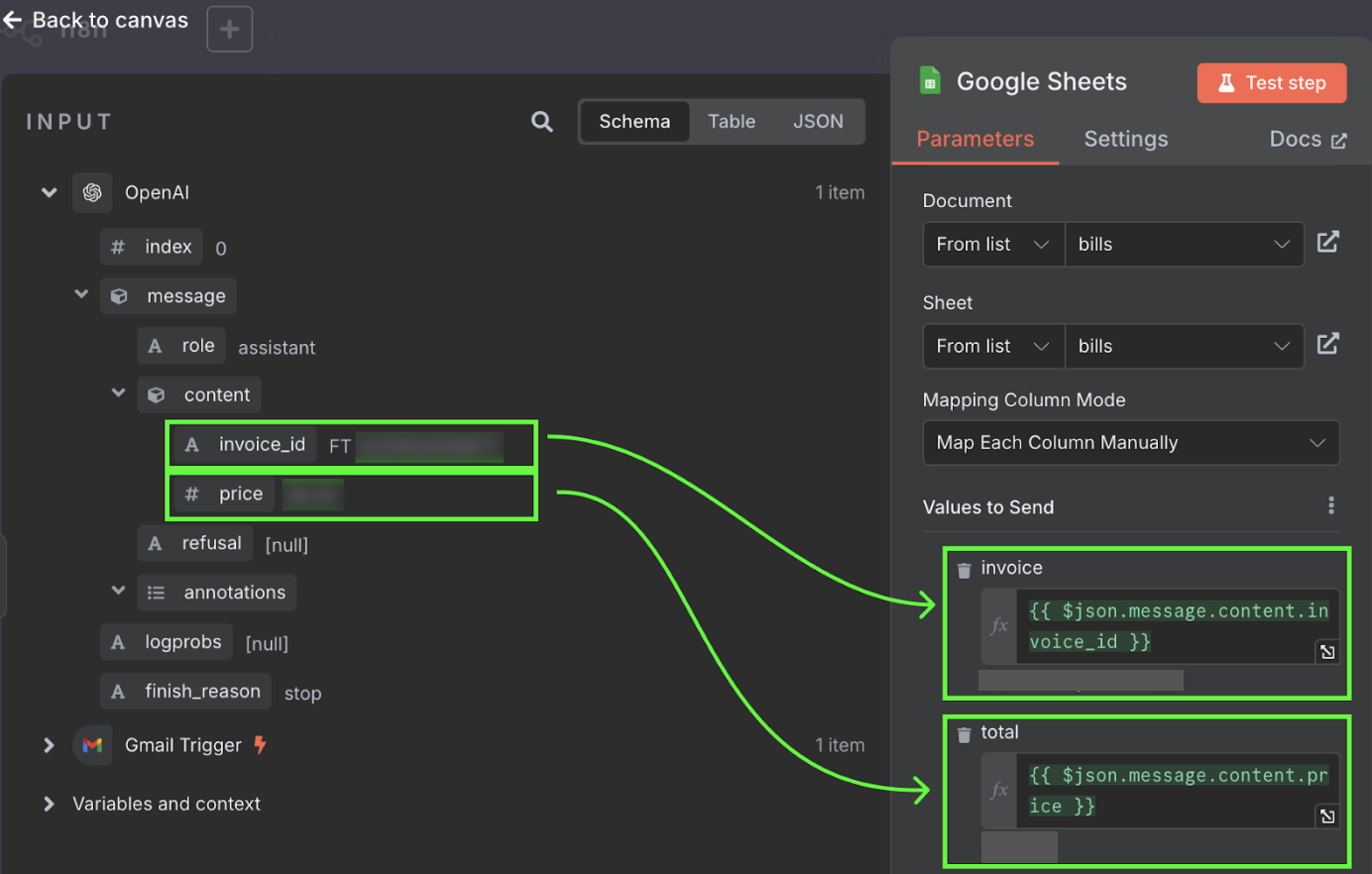
Die waarden halen we uit de output van de OpenAI-node. We kunnen ze naar de kolommen slepen en neerzetten.
Dat is het! We hebben een workflow die onze facturen automatisch verwerkt in een Google Sheet. We kunnen hem testen door onderaan op "Test workflow" te klikken:
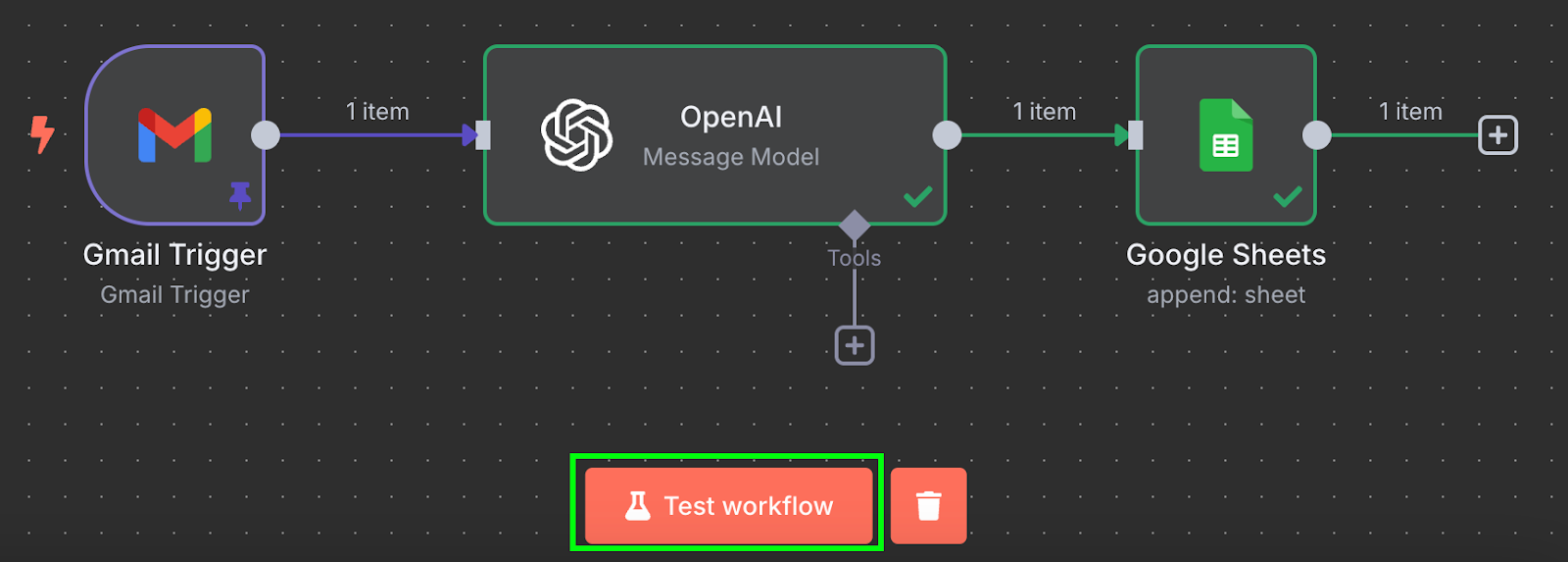
Na het draaien zien we in onze Google Sheet een nieuwe rij met de data:
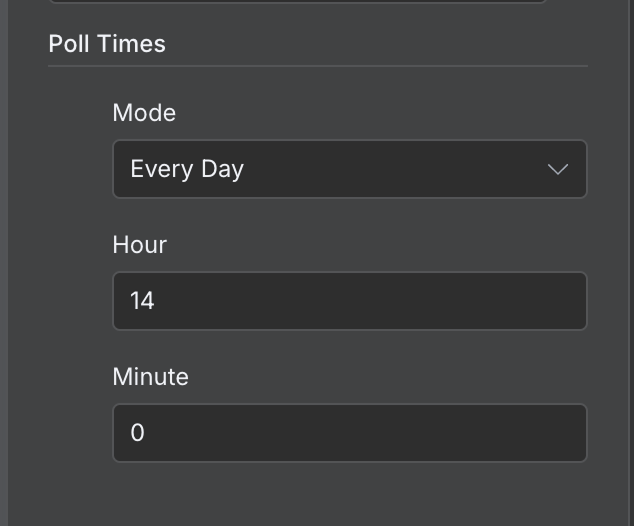
Standaard draait een workflow elke minuut. Afhankelijk van de workflow moeten we een passende frequentie instellen. In dit specifieke voorbeeld is eens per minuut veel te vaak. Eens per dag is passender.
Dat kunnen we instellen door dubbel te klikken op de trigger-node en een andere waarde in te stellen in het veld "Poll Times":
In deze sectie bouwen we een complexere RAG-agent-workflow. RAG staat voor retrieval-augmented generation, een techniek die het ophalen van relevante informatie uit een database of document combineert met een taalmodel dat antwoorden genereert op basis van de opgehaalde informatie.
Dit is erg handig wanneer we een specifieke kennisbron hebben, zoals een lang tekstdocument, en een AI-agent willen bouwen die daar vragen over kan beantwoorden.
Ik speel graag bordspellen, maar mijn vrienden en ik discussiëren vaak over de regels en besteden dan tijd aan het zoeken naar de juiste regels in plaats van te spelen — best frustrerend. Een RAG-agent bouwen op basis van de spelregels is een goede oplossing, want de volgende keer dat we een vraag hebben, kunnen we die gewoon aan de agent stellen.
Om deze agent te bouwen, maken we twee workflows:
Pinecone is een type database dat data beheert in de vorm van vectoren. Een vector-database zoals Pinecone is ideaal voor onze RAG-agent omdat deze de agent helpt snel relevante informatie op te zoeken en te begrijpen, waardoor antwoorden nauwkeuriger en efficiënter worden.
Omdat we deze workflow maar één keer hoeven te draaien, kunnen we een handmatige trigger-node gebruiken. Dit is een trigger-node om een workflow handmatig te starten.
Verbind de handmatige trigger-node met een "Google Drive"-node om de data van Google Drive te downloaden.

Gebruik de volgende configuratie:
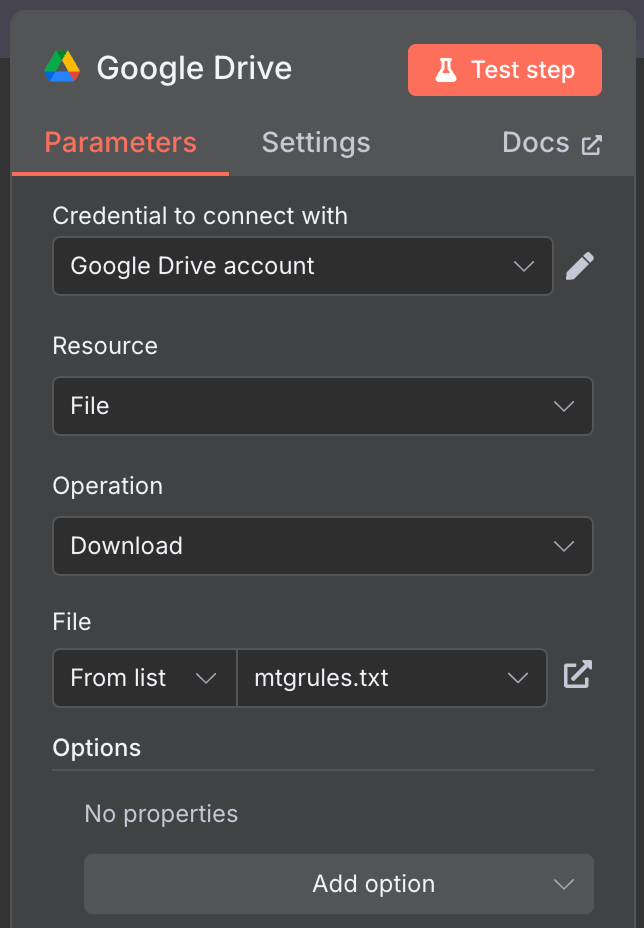
Ik heb het publiek beschikbare bestand mtgrules.txt gebruikt met de regels van het ruilkaartspel Magic: The Gathering. Je kunt elk bestand gebruiken waarover je vragen wilt stellen; de workflow is hetzelfde.
Om Pinecone te configureren, log je in op Pinecone, kopieer je de API-sleutel en maak je een index aan via de knop "Create index". Ik heb mijn index rules genoemd en het model text-embedding-3-small geselecteerd.

Terug in n8n verbinden we de output van de Google Drive-node met een Pinecone Vector Store-node met de actie "Add documents to vector store":
Om de node te configureren, maken we een credential aan door de API-sleutel te plakken en selecteren we de Pinecone-index die we zojuist hebben aangemaakt. Onder de Pinecone Vector Store-node zien we twee zaken die we moeten instellen: een embeddingmodel en een dataloader.
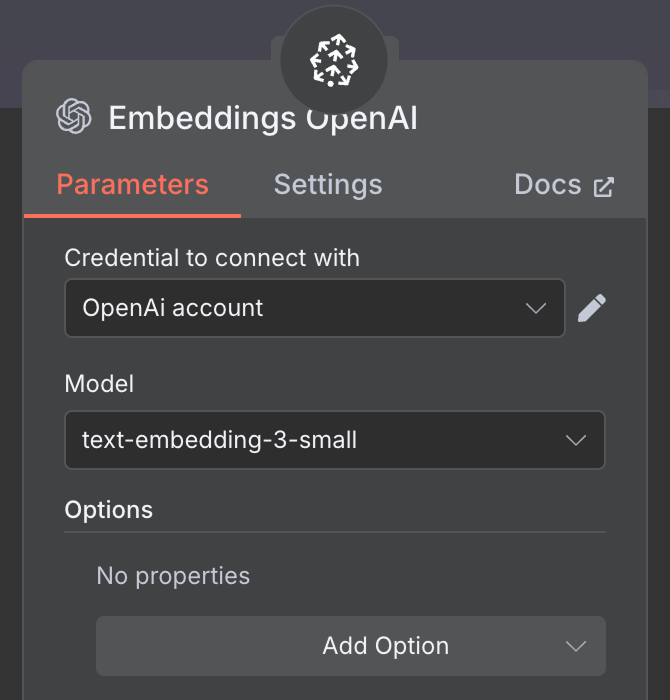
Voor de embedding maken we een OpenAI Embedding-node met het model text-embedding-3-small:
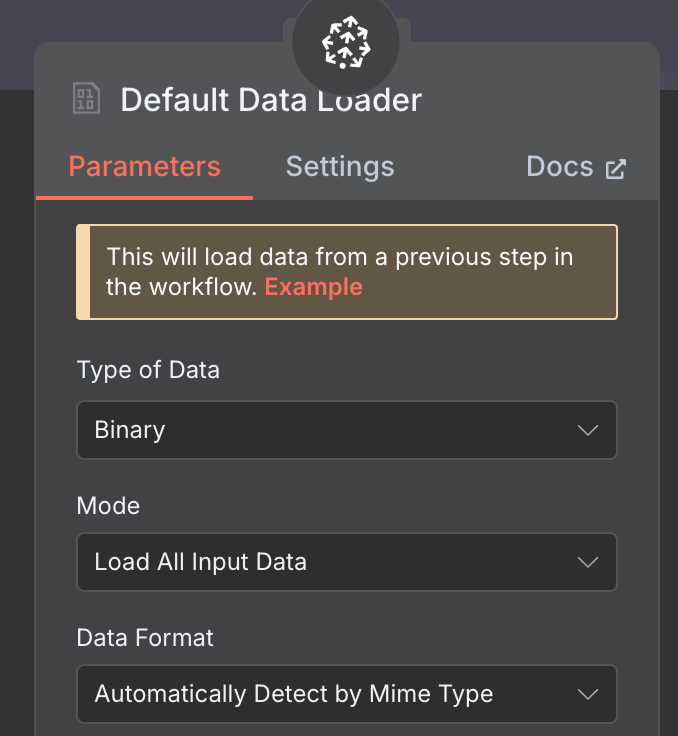
Voor de dataloader maken we een Default Data Loader-node met een binair datatype:
Tot slot heeft de dataloader een Text Splitter-node nodig, die bepaalt hoe de data uit het bestand wordt gesplitst bij het maken van de vector store. We gebruiken de Recursive Character Text Splitter-node, de aanbevolen node voor de meeste toepassingen.
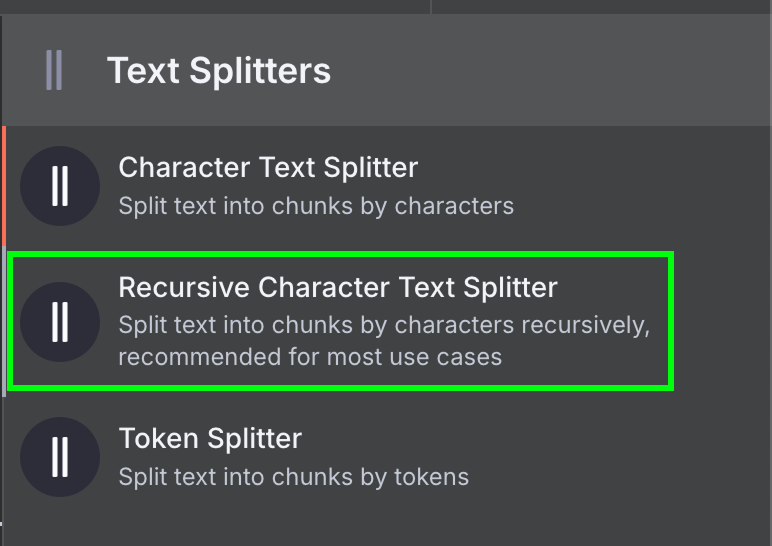
We configureren deze met een chunk size van 1.000 en een chunk overlap van 200:
Bij het kiezen van de chunk size en overlap kun je voor langere documenten een grotere chunk size gebruiken om voldoende inhoud te vangen en een kleinere overlap om context tussen segmenten te behouden zonder overbodigheid.
Zo ziet de uiteindelijke workflow eruit:
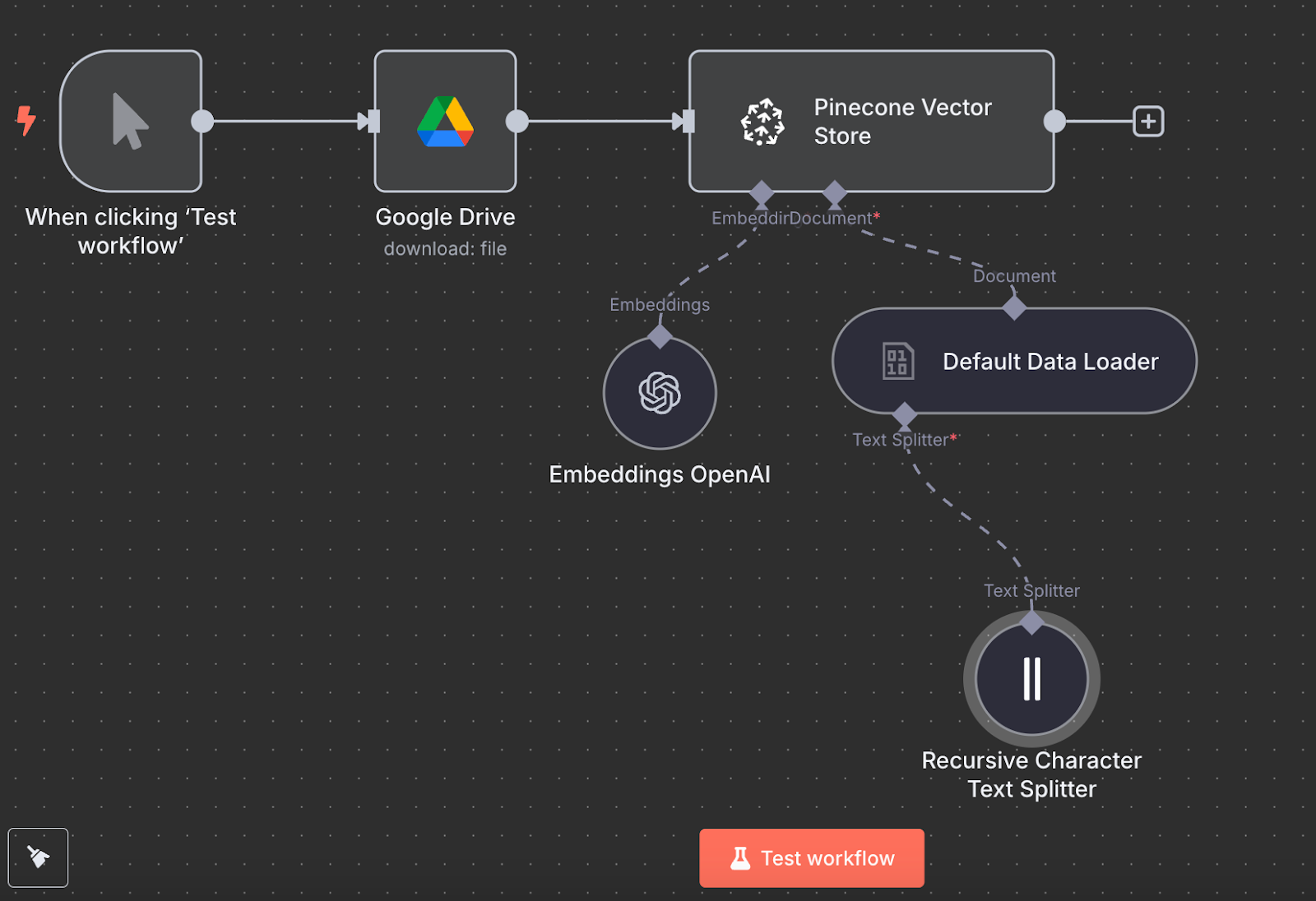
We kunnen hem draaien door op "Test workflow" te klikken, en zodra hij klaar is, kunnen we in Pinecone verifiëren dat de data is geladen.
Hier is het uiteindelijke schema voor de RAG-agent:
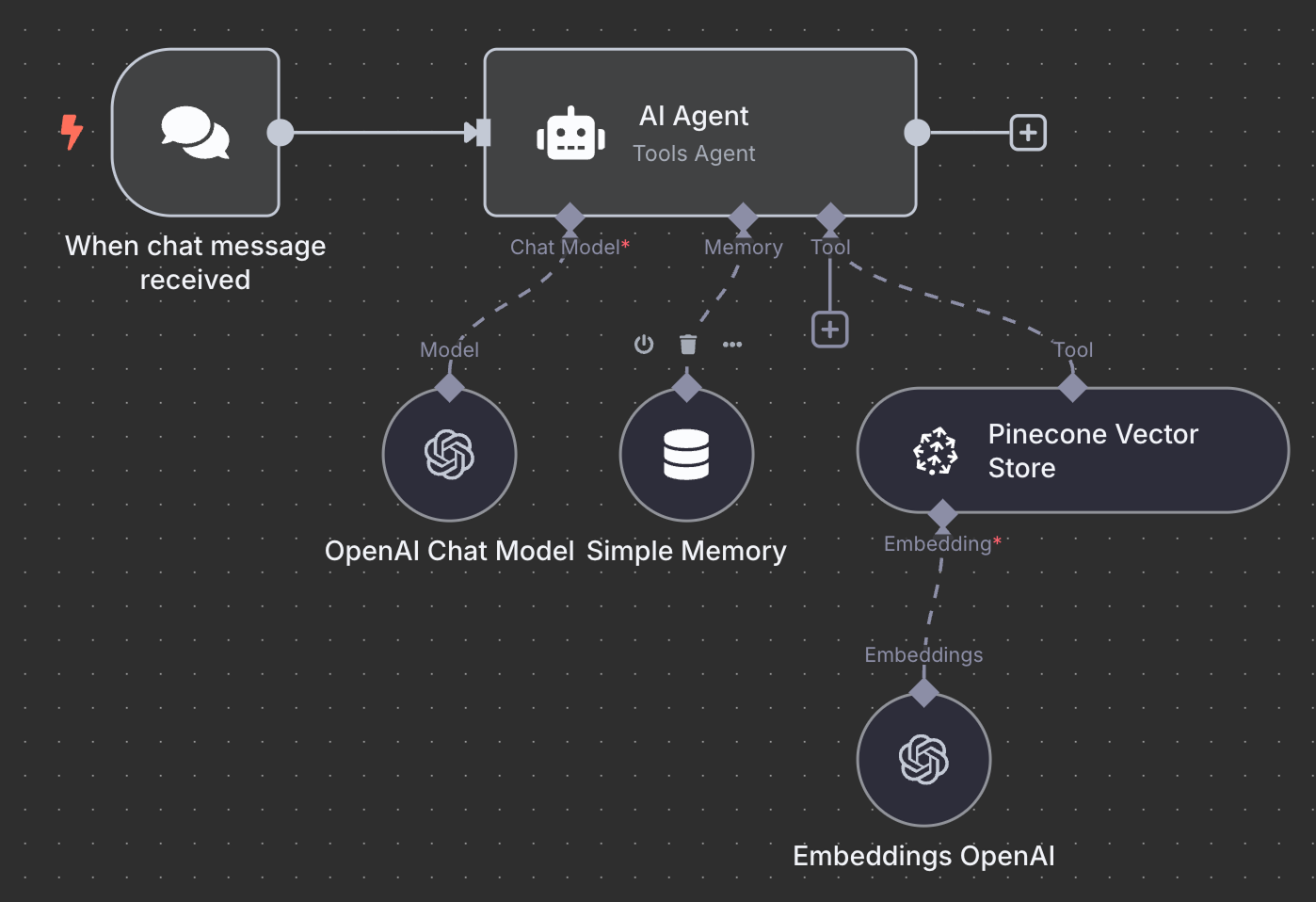
Als oefening raad ik je aan om te proberen deze te begrijpen en misschien zelfs lokaal na te bouwen voordat je verder leest.
We beginnen met een "On chat message"-trigger-node. Deze wordt gebruikt om een chat-workflow te maken.
Vervolgens verbinden we de chat-trigger met een "AI Agent"-node met de standaardopties.
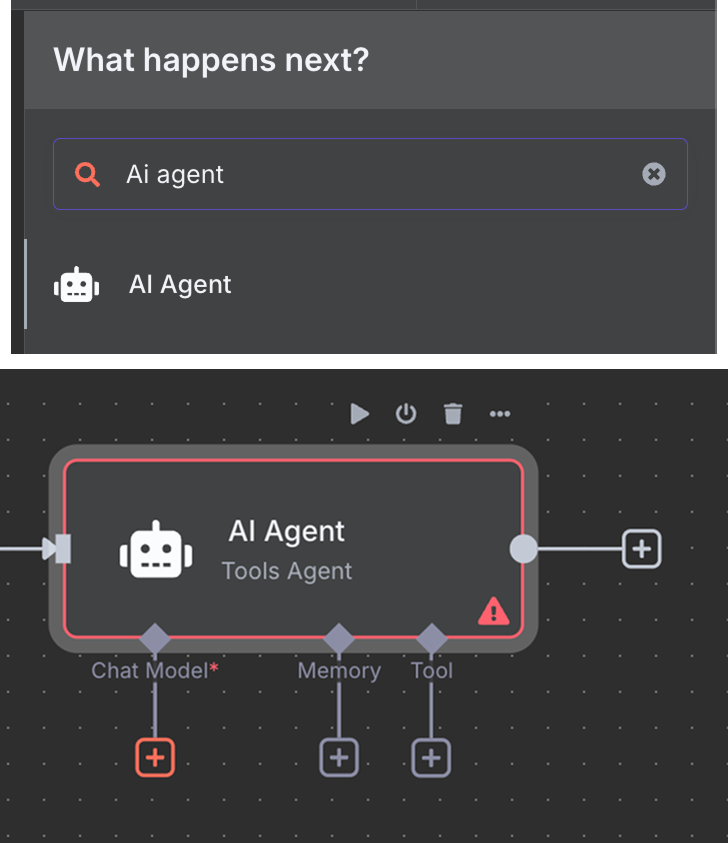
Onder de AI Agent zien we dat we drie dingen kunnen configureren:
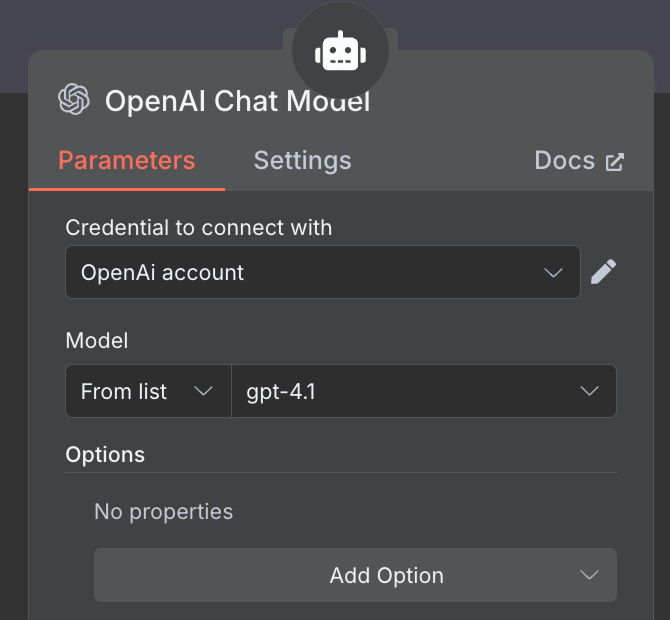
Voor het AI-model selecteren we een "OpenAI Chat Model"-node en gebruiken we, net als eerder, GPT-4.1. De GPT-5-familie is OpenAI's huidige modelfamilie, maar 4.1 heeft een contextvenster van 1M tokens en past goed bij RAG.
Voor het geheugen gebruiken we een "Simple Memory"-node met een contextvenster van lengte 5. Dit betekent dat de agent de vijf vorige interacties onthoudt en meeneemt in het antwoord.
Tot slot voegen we als tool een "Pinecone Vector Store"-node toe met de volgende configuratie:
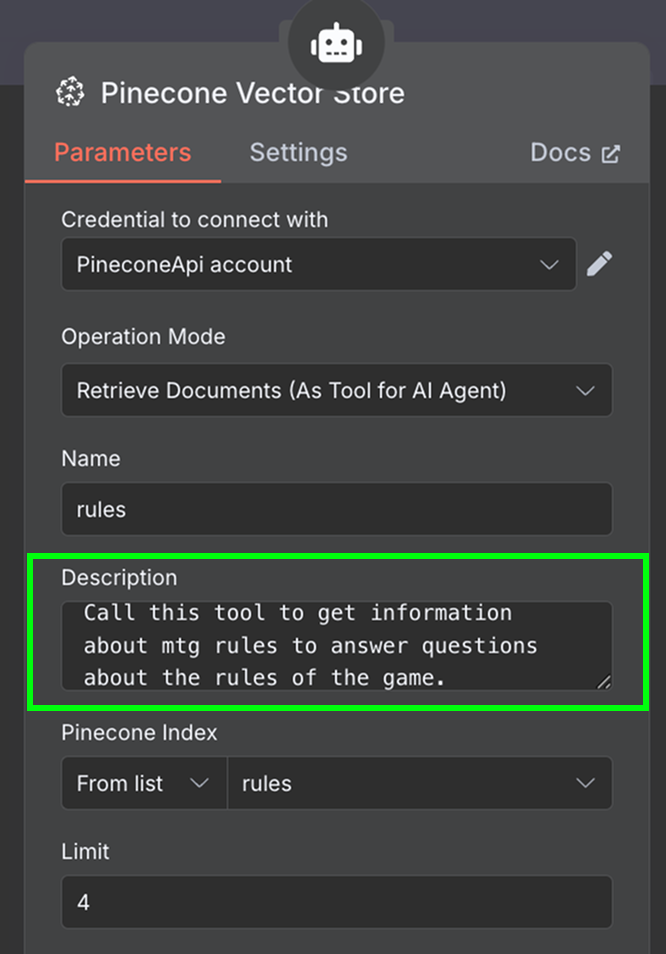
In het beschrijvingsveld is het belangrijk te specificeren wanneer de tools moeten worden gebruikt. De agent gebruikt dit om te bepalen of hij de tool moet aanroepen.
Het laatste wat we moeten doen is de embedding configureren die door de vector store wordt gebruikt. Zoals eerder gebruiken we een OpenAI Embedding-node met het model text-embedding-3-small:
De workflow is compleet en we kunnen met de agent chatten. Hier is een voorbeeld:
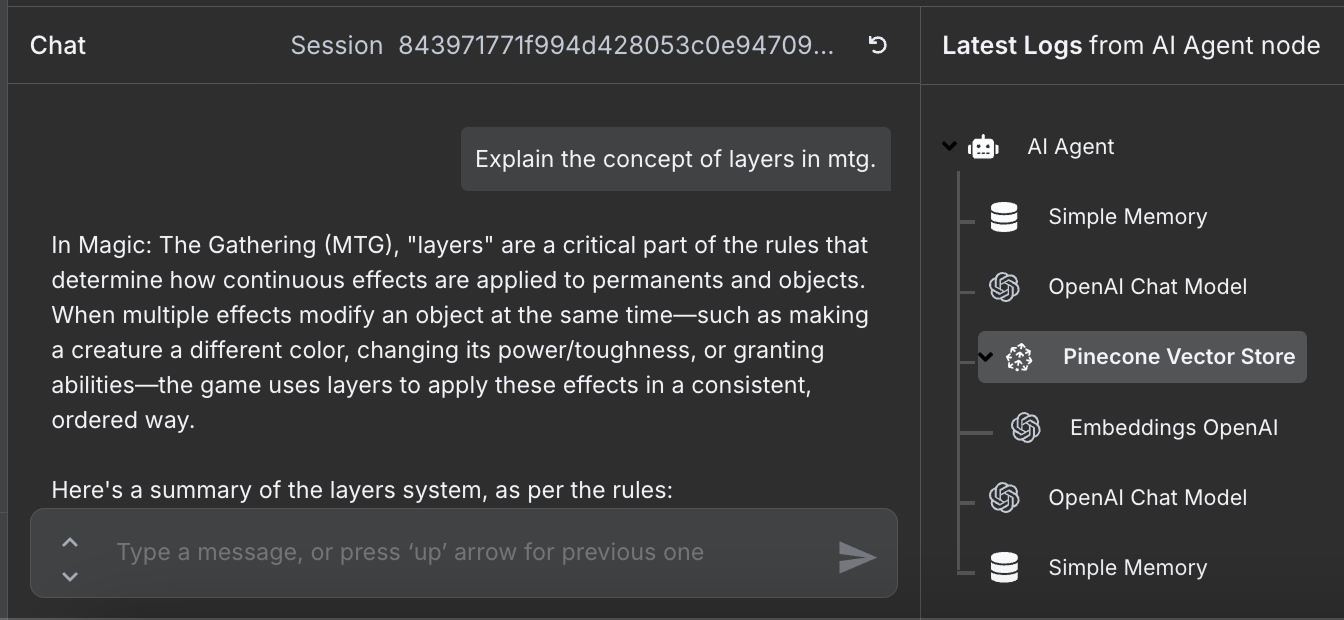
Rechts zien we de stappen die de agent nam om onze vraag te beantwoorden. Met name raadpleegde hij de Pinecone-database om de relevante informatie over de regels op te halen.
n8n biedt een handige functie die ons proces om workflows te maken flink kan versnellen: de n8n-templatebibliotheek.
Deze bibliotheek is een verzameling kant-en-klare workflows, samengesteld door de community en n8n-experts. Of we nu eenvoudige taken of complexere processen willen automatiseren, de kans is groot dat iemand al een passende workflow heeft gebouwd.
Een workflow importeren in onze n8n-omgeving betekent dat we niet altijd vanaf nul hoeven te beginnen. We kunnen profiteren van de creatieve oplossingen die andere gebruikers hebben ontwikkeld. Na het importeren hoeven we hem alleen nog te configureren met onze credentials en aan te passen aan onze exacte behoeften.
Voor vrijwel elke taak die we willen automatiseren — van e-mailverwerking tot socialmediamanagement — is er waarschijnlijk een template beschikbaar in de bibliotheek.
n8n biedt een enorm ecosysteem aan integraties, waarmee we meer dan duizend services en tools kunnen verbinden om AI-agents te bouwen. We hebben in deze tutorial slechts een tipje van de sluier opgelicht. Door te verkennen hoe je met n8n AI-agents bouwt om alledaagse taken te automatiseren, hebben we nog maar net aan het potentieel ervan geproefd.
Leer AI met deze cursussen!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
